{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Wygładzanie w n-gramowych modelach języka\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Dlaczego wygładzanie?\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wyobraźmy sobie urnę, w której znajdują się kule w $m$ kolorach\n",
"(ściślej: w co najwyżej $m$ kolorach, może w ogóle nie być kul w danym\n",
"kolorze). Nie wiemy, ile jest ogółem kul w urnie i w jakiej liczbie\n",
"występuje każdy z kolorów.\n",
"\n",
"Losujemy ze zwracaniem (to istotne!) $T$ kul, załóżmy, że\n",
"wylosowaliśmy w poszczególnych kolorach $\\{k_1,\\dots,k_m\\}$ kul\n",
"(tzn. pierwszą kolor wylosowaliśmy $k_1$ razy, drugi kolor — $k_2$ razy itd.).\n",
"Rzecz jasna, $\\sum_{i=1}^m k_i = T$.\n",
"\n",
"Jak powinniśmy racjonalnie szacować prawdopodobieństwa wylosowania kuli w $i$-tym kolorze ($p_i$)?\n",
"\n",
"Wydawałoby się, że wystarczy liczbę wylosowanych kul w danym kolorze\n",
"podzielić przez liczbę wszystkich prób:\n",
"\n",
"$$p_i = \\frac{k_i}{T}.$$\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Wygładzanie — przykład\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Rozpatrzmy przykład z 3 kolorami (wiemy, że w urnie mogą być kule\n",
"żółte, zielone i czerwone, tj. $m=3$) i 4 losowaniami ($T=4$):\n",
"\n",
"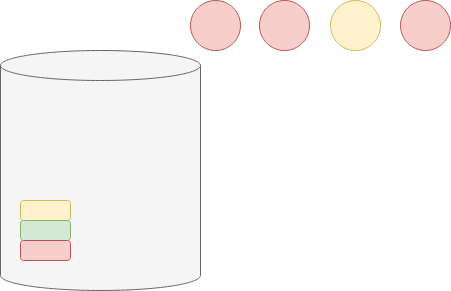\n",
"\n",
"Gdybyśmy w prosty sposób oszacowali prawdopodobieństwa, doszlibyśmy do\n",
"wniosku, że prawdopodobieństwo wylosowania kuli czerwonej wynosi 3/4, żółtej — 1/4,\n",
"a zielonej — 0. Wartości te są jednak dość problematyczne:\n",
"\n",
"- Za bardzo przywiązujemy się do naszej skromnej próby,\n",
" potrzebowalibyśmy większej liczby losowań, żeby być bardziej pewnym\n",
" naszych estymacji.\n",
"- W szczególności stwierdzenie, że prawdopodobieństwo wylosowania kuli\n",
" zielonej wynosi 0, jest bardzo mocnym stwierdzeniem (twierdzimy, że\n",
" **NIEMOŻLIWE** jest wylosowanie kuli zielonej), dopiero większa liczba\n",
" prób bez wylosowania zielonej kuli mogłaby sugerować\n",
" prawdopodobieństwo bliskie zeru.\n",
"- Zauważmy, że niemożliwe jest wylosowanie ułamka kuli, jeśli w\n",
" rzeczywistości 10% kul jest żółtych, to nie oznacza się wylosujemy\n",
" $4\\frac{1}{10} = \\frac{2}{5}$ kuli. Prawdopodobnie wylosujemy jedną\n",
" kulę żółtą albo żadną. Wylosowanie dwóch kul żółtych byłoby możliwe,\n",
" ale mniej prawdopodobne. Jeszcze mniej prawdopodobne byłoby\n",
" wylosowanie 3 lub 4 kul żółtych.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Idea wygładzania\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wygładzanie (ang. *smoothing*) polega na tym, że „uszczknąć” nieco\n",
"masy prawdopodobieństwa zdarzeniom wskazywanym przez eksperyment czy\n",
"zbiór uczący i rozdzielić ją między mniej prawdopodobne zdarzenia.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Wygładzanie +1\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Najprostszy sposób wygładzania to wygładzania +1, nazywane też wygładzaniem\n",
"Laplace'a, zdefiniowane za pomocą następującego wzoru:\n",
"\n",
"$$p_i = \\frac{k_i+1}{T+m}.$$\n",
"\n",
"W naszym przykładzie z urną prawdopodobieństwo wylosowania kuli\n",
"czerwonej określimy na $\\frac{3+1}{4+3} = \\frac{4}{7}$, kuli żółtej —\n",
"$\\frac{1+1}{4+3}=2/7$, zielonej — $\\frac{0+1}{4+3}=1/7$. Tym samym,\n",
"kula zielona uzyskała niezerowe prawdopodobieństwo, żółta — nieco\n",
"zyskała, zaś czerwona — straciła.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Własności wygładzania +1\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Zauważmy, że większa liczba prób $m$, tym bardziej ufamy naszemu eksperymentowi\n",
"(czy zbiorowi uczącemu) i tym bardziej zbliżamy się do niewygładzonej wartości:\n",
"\n",
"$$\\lim_{m \\rightarrow \\infty} \\frac{k_i +1}{T + m} = \\frac{k_i}{T}.$$\n",
"\n",
"Inna dobra, zdroworozsądkowo, własność to to, że prawdopodobieństwo nigdy nie będzie zerowe:\n",
"\n",
"$$\\frac{k_i + 1}{T + m} > 0.$$\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Wygładzanie w unigramowym modelu języku\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Analogia do urny\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Unigramowy model języka, abstrakcyjnie, dokładnie realizuje scenariusz\n",
"losowania kul z urny: $m$ to liczba wszystkich wyrazów (czyli rozmiar słownika $|V|$),\n",
"$k_i$ to ile razy w zbiorze uczącym pojawił się $i$-ty wyraz słownika,\n",
"$T$ — długość zbioru uczącego.\n",
"\n",
"\n",
"\n",
"A zatem przy użyciu wygładzania +1 w następujący sposób estymować\n",
"będziemy prawdopodobieństwo słowa $w$:\n",
"\n",
"$$P(w) = \\frac{\\# w + 1}{|C| + |V|}.$$\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Wygładzanie $+\\alpha$\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"W modelowaniu języka wygładzanie $+1$ daje zazwyczaj niepoprawne\n",
"wyniki, dlatego częściej zamiast wartości 1 używa się współczynnika $0\n",
"< \\alpha < 1$:\n",
"\n",
"$$P(w) = \\frac{\\# w + \\alpha}{|C| + \\alpha|V|}.$$\n",
"\n",
"W innych praktycznych zastosowaniach statystyki\n",
"przyjmuje się $\\alpha = \\frac{1}{2}$, ale w przypadku n-gramowych\n",
"modeli języka i to będzie zbyt duża wartość.\n",
"\n",
"W jaki sposób ustalić wartość $\\alpha$? Można $\\alpha$ potraktować $\\alpha$\n",
"jako hiperparametr i dostroić ją na odłożonym zbiorze.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Jak wybrać wygładzanie?\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Jak ocenić, który sposób wygładzania jest lepszy? Jak wybrać $\\alpha$\n",
"w czasie dostrajania?\n",
"\n",
"Najprościej można sprawdzić estymowane prawdopodobieństwa na zbiorze\n",
"strojącym (developerskim). Dla celów poglądowych bardziej czytelny\n",
"będzie podział zbioru uczącego na dwie równe części — będziemy\n",
"porównywać częstości estymowane na jednej połówce korpusu z\n",
"rzeczywistymi, empirycznymi częstościami z drugiej połówki.\n",
"\n",
"Wyniki będziemy przedstawiać w postaci tabeli, gdzie w poszczególnych\n",
"wierszach będziemy opisywać częstości estymowane dla wszystkich\n",
"wyrazów, które pojawiły się określoną liczbę razy w pierwszej połówce korpusu.\n",
"\n",
"Ostatecznie możemy też po prostu policzyć perplexity na zbiorze testowym\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Przykład\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Użyjemy polskiej części z korpusu równoległego Open Subtitles:\n",
"\n",
" wget -O en-pl.txt.zip 'https://opus.nlpl.eu/download.php?f=OpenSubtitles/v2018/moses/en-pl.txt.zip'\n",
" unzip en-pl.txt.zip\n",
"\n",
"Usuńmy duplikaty (zachowując kolejność):\n",
"\n",
" nl OpenSubtitles.en-pl.pl | sort -k 2 -u | sort -k 1 | cut -f 2- > opensubtitles.pl.txt\n",
"\n",
"Korpus zawiera ponad 28 mln słów, zdania są krótkie, jest to język potoczny, czasami wulgarny.\n",
"\n",
" $ wc opensubtitles.pl.txt\n",
" 28154303 178866171 1206735898 opensubtitles.pl.txt\n",
" $ head -n 10 opensubtitles.pl.txt\n",
" Lubisz curry, prawda?\n",
" Nałożę ci więcej.\n",
" Hey!\n",
" Smakuje ci?\n",
" Hey, brzydalu.\n",
" Spójrz na nią.\n",
" - Wariatka.\n",
" - Zadałam ci pytanie!\n",
" No, tak lepiej!\n",
" - Wygląda dobrze!\n",
"\n",
"Podzielimy korpus na dwie części:\n",
"\n",
" head -n 14077151 < opensubtitles.pl.txt > opensubtitlesA.pl.txt\n",
" tail -n 14077151 < opensubtitles.pl.txt > opensubtitlesB.pl.txt\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Tokenizacja\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Stwórzmy generator, który będzie wczytywał słowa z pliku, dodatkowo:\n",
"\n",
"- ciągi znaków interpunkcyjnych będziemy traktować jak tokeny,\n",
"- sprowadzimy wszystkie litery do małych,\n",
"- dodamy specjalne tokeny na początek i koniec zdania (`` i ``).\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"['',\n",
" 'lubisz',\n",
" 'curry',\n",
" ',',\n",
" 'prawda',\n",
" '?',\n",
" '',\n",
" '',\n",
" 'nałożę',\n",
" 'ci',\n",
" 'więcej',\n",
" '.',\n",
" '',\n",
" '',\n",
" 'hey',\n",
" '!',\n",
" '',\n",
" '',\n",
" 'smakuje',\n",
" 'ci',\n",
" '?',\n",
" '',\n",
" '',\n",
" 'hey',\n",
" ',',\n",
" 'brzydalu',\n",
" '.',\n",
" '',\n",
" '',\n",
" 'spójrz',\n",
" 'na',\n",
" 'nią',\n",
" '.',\n",
" '',\n",
" '',\n",
" '-',\n",
" 'wariatka',\n",
" '.',\n",
" '',\n",
" '',\n",
" '-',\n",
" 'zadałam',\n",
" 'ci',\n",
" 'pytanie',\n",
" '!',\n",
" '',\n",
" '',\n",
" 'no',\n",
" ',',\n",
" 'tak',\n",
" 'lepiej',\n",
" '!',\n",
" '',\n",
" '',\n",
" '-',\n",
" 'wygląda',\n",
" 'dobrze',\n",
" '!',\n",
" '',\n",
" '',\n",
" '-',\n",
" 'tak',\n",
" 'lepiej',\n",
" '!',\n",
" '',\n",
" '',\n",
" 'pasuje',\n",
" 'jej',\n",
" '.',\n",
" '',\n",
" '',\n",
" '-',\n",
" 'hey',\n",
" '.',\n",
" '',\n",
" '',\n",
" '-',\n",
" 'co',\n",
" 'do',\n",
" '...?',\n",
" '',\n",
" '',\n",
" 'co',\n",
" 'do',\n",
" 'cholery',\n",
" 'robisz',\n",
" '?',\n",
" '',\n",
" '',\n",
" 'zejdź',\n",
" 'mi',\n",
" 'z',\n",
" 'oczu',\n",
" ',',\n",
" 'zdziro',\n",
" '.',\n",
" '',\n",
" '',\n",
" 'przestań',\n",
" 'dokuczać']"
]
},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from itertools import islice\n",
"import regex as re\n",
"import sys\n",
"\n",
"def get_words_from_file(file_name):\n",
" with open(file_name, 'r') as fh:\n",
" for line in fh:\n",
" line = line.rstrip()\n",
" yield ''\n",
" for m in re.finditer(r'[\\p{L}0-9\\*]+|\\p{P}+', line):\n",
" yield m.group(0).lower()\n",
" yield ''\n",
"\n",
"list(islice(get_words_from_file('opensubtitlesA.pl.txt'), 0, 100))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Empiryczne wyniki\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Zobaczmy, ile razy, średnio w drugiej połówce korpusu występują\n",
"wyrazy, które w pierwszej wystąpiły określoną liczbę razy.\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"from collections import Counter\n",
"\n",
"counterA = Counter(get_words_from_file('opensubtitlesA.pl.txt'))"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"48113"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"counterA['taki']"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [],
"source": [
"max_r = 10\n",
"\n",
"buckets = {}\n",
"for token in counterA:\n",
" buckets.setdefault(counterA[token], 0)\n",
" buckets[counterA[token]] += 1\n",
"\n",
"bucket_counts = {}\n",
"\n",
"counterB = Counter(get_words_from_file('opensubtitlesB.pl.txt'))\n",
"\n",
"for token in counterB:\n",
" bucket_id = counterA[token] if token in counterA else 0\n",
" if bucket_id <= max_r:\n",
" bucket_counts.setdefault(bucket_id, 0)\n",
" bucket_counts[bucket_id] += counterB[token]\n",
" if bucket_id == 0:\n",
" buckets.setdefault(0, 0)\n",
" buckets[0] += 1\n",
"\n",
"nb_of_types = [buckets[ix] for ix in range(0, max_r+1)]\n",
"empirical_counts = [bucket_counts[ix] / buckets[ix] for ix in range(0, max_r)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Policzmy teraz jakiej liczby wystąpień byśmy oczekiwali, gdyby użyć wygładzania +1 bądź +0.01.\n",
"(Uwaga: zwracamy liczbę wystąpień, a nie względną częstość, stąd przemnażamy przez rozmiar całego korpusu).\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"926594"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"def plus_alpha_smoothing(alpha, m, t, k):\n",
" return t*(k + alpha)/(t + alpha * m)\n",
"\n",
"def plus_one_smoothing(m, t, k):\n",
" return plus_alpha_smoothing(1.0, m, t, k)\n",
"\n",
"vocabulary_size = len(counterA)\n",
"corpus_size = counterA.total()\n",
"\n",
"plus_one_counts = [plus_one_smoothing(vocabulary_size, corpus_size, ix) for ix in range(0, max_r)]\n",
"\n",
"plus_alpha_counts = [plus_alpha_smoothing(0.01, vocabulary_size, corpus_size, ix) for ix in range(0, max_r)]\n",
"\n",
"data = list(zip(nb_of_types, empirical_counts, plus_one_counts, plus_alpha_counts))\n",
"\n",
"vocabulary_size"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" liczba tokenów | \n",
" średnia częstość w części B | \n",
" estymacje +1 | \n",
" estymacje +0.01 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 388334 | \n",
" 1.900495 | \n",
" 0.993586 | \n",
" 0.009999 | \n",
"
\n",
" \n",
" | 1 | \n",
" 403870 | \n",
" 0.592770 | \n",
" 1.987172 | \n",
" 1.009935 | \n",
"
\n",
" \n",
" | 2 | \n",
" 117529 | \n",
" 1.565809 | \n",
" 2.980759 | \n",
" 2.009870 | \n",
"
\n",
" \n",
" | 3 | \n",
" 62800 | \n",
" 2.514268 | \n",
" 3.974345 | \n",
" 3.009806 | \n",
"
\n",
" \n",
" | 4 | \n",
" 40856 | \n",
" 3.504944 | \n",
" 4.967931 | \n",
" 4.009741 | \n",
"
\n",
" \n",
" | 5 | \n",
" 29443 | \n",
" 4.454098 | \n",
" 5.961517 | \n",
" 5.009677 | \n",
"
\n",
" \n",
" | 6 | \n",
" 22709 | \n",
" 5.232023 | \n",
" 6.955103 | \n",
" 6.009612 | \n",
"
\n",
" \n",
" | 7 | \n",
" 18255 | \n",
" 6.157929 | \n",
" 7.948689 | \n",
" 7.009548 | \n",
"
\n",
" \n",
" | 8 | \n",
" 15076 | \n",
" 7.308039 | \n",
" 8.942276 | \n",
" 8.009483 | \n",
"
\n",
" \n",
" | 9 | \n",
" 12859 | \n",
" 8.045649 | \n",
" 9.935862 | \n",
" 9.009418 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" liczba tokenów | \n",
" średnia częstość w części B | \n",
" estymacje +1 | \n",
" Good-Turing | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 388334 | \n",
" 1.900495 | \n",
" 0.993586 | \n",
" 1.040007 | \n",
"
\n",
" \n",
" | 1 | \n",
" 403870 | \n",
" 0.592770 | \n",
" 1.987172 | \n",
" 0.582014 | \n",
"
\n",
" \n",
" | 2 | \n",
" 117529 | \n",
" 1.565809 | \n",
" 2.980759 | \n",
" 1.603009 | \n",
"
\n",
" \n",
" | 3 | \n",
" 62800 | \n",
" 2.514268 | \n",
" 3.974345 | \n",
" 2.602293 | \n",
"
\n",
" \n",
" | 4 | \n",
" 40856 | \n",
" 3.504944 | \n",
" 4.967931 | \n",
" 3.603265 | \n",
"
\n",
" \n",
" | 5 | \n",
" 29443 | \n",
" 4.454098 | \n",
" 5.961517 | \n",
" 4.627721 | \n",
"
\n",
" \n",
" | 6 | \n",
" 22709 | \n",
" 5.232023 | \n",
" 6.955103 | \n",
" 5.627064 | \n",
"
\n",
" \n",
" | 7 | \n",
" 18255 | \n",
" 6.157929 | \n",
" 7.948689 | \n",
" 6.606847 | \n",
"
\n",
" \n",
" | 8 | \n",
" 15076 | \n",
" 7.308039 | \n",
" 8.942276 | \n",
" 7.676506 | \n",
"
\n",
" \n",
" | 9 | \n",
" 12859 | \n",
" 8.045649 | \n",
" 9.935862 | \n",
" 8.557431 | \n",
"
\n",
" \n",
"
\n",
"