23 KiB
23 KiB

Ekstrakcja informacji
8. word2vec i gotowe biblioteki [ćwiczenia]
Jakub Pokrywka (2021)

!pip install gensim Requirement already satisfied: gensim in /home/kuba/anaconda3/envs/zajeciaei/lib/python3.10/site-packages (4.2.0) Requirement already satisfied: smart-open>=1.8.1 in /home/kuba/anaconda3/envs/zajeciaei/lib/python3.10/site-packages (from gensim) (6.0.0) Requirement already satisfied: scipy>=0.18.1 in /home/kuba/anaconda3/envs/zajeciaei/lib/python3.10/site-packages (from gensim) (1.8.0) Requirement already satisfied: numpy>=1.17.0 in /home/kuba/anaconda3/envs/zajeciaei/lib/python3.10/site-packages (from gensim) (1.22.3)
import gensim.downloaderfrom IPython.display import Image
from IPython.core.display import display, HTML/tmp/ipykernel_5965/1831104553.py:2: DeprecationWarning: Importing display from IPython.core.display is deprecated since IPython 7.14, please import from IPython display from IPython.core.display import display, HTML
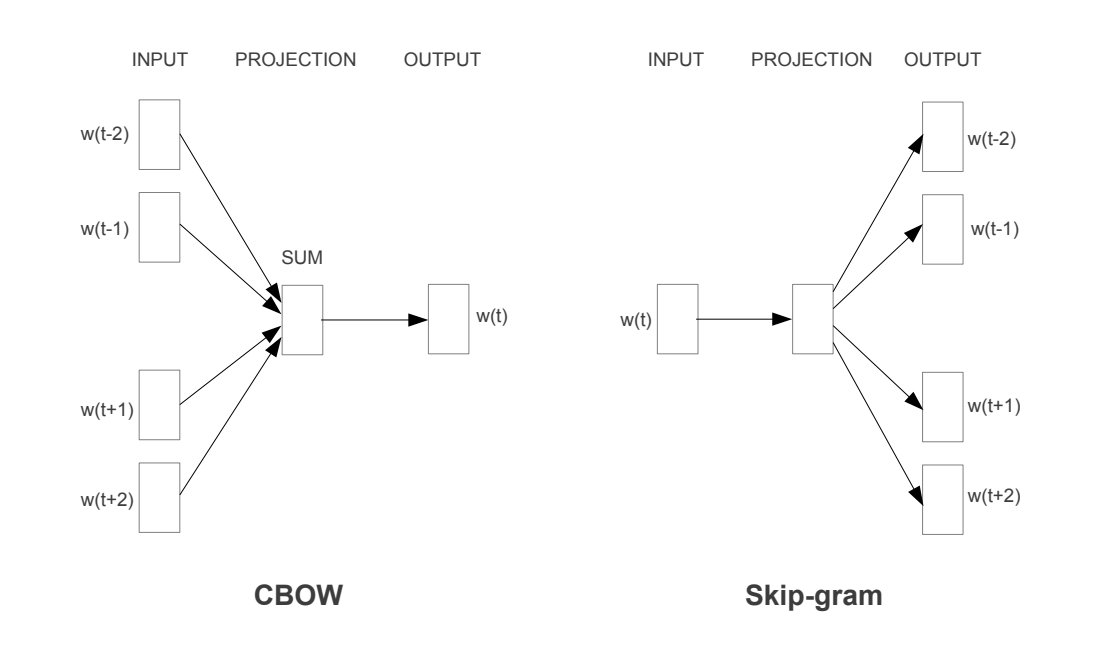
Mikolov et al., Efficient Estimation of Word Representations in Vector Space (2013)
word_vectors = gensim.downloader.load("glove-wiki-gigaword-100")word_vectors['dog']array([ 0.30817 , 0.30938 , 0.52803 , -0.92543 , -0.73671 ,
0.63475 , 0.44197 , 0.10262 , -0.09142 , -0.56607 ,
-0.5327 , 0.2013 , 0.7704 , -0.13983 , 0.13727 ,
1.1128 , 0.89301 , -0.17869 , -0.0019722, 0.57289 ,
0.59479 , 0.50428 , -0.28991 , -1.3491 , 0.42756 ,
1.2748 , -1.1613 , -0.41084 , 0.042804 , 0.54866 ,
0.18897 , 0.3759 , 0.58035 , 0.66975 , 0.81156 ,
0.93864 , -0.51005 , -0.070079 , 0.82819 , -0.35346 ,
0.21086 , -0.24412 , -0.16554 , -0.78358 , -0.48482 ,
0.38968 , -0.86356 , -0.016391 , 0.31984 , -0.49246 ,
-0.069363 , 0.018869 , -0.098286 , 1.3126 , -0.12116 ,
-1.2399 , -0.091429 , 0.35294 , 0.64645 , 0.089642 ,
0.70294 , 1.1244 , 0.38639 , 0.52084 , 0.98787 ,
0.79952 , -0.34625 , 0.14095 , 0.80167 , 0.20987 ,
-0.86007 , -0.15308 , 0.074523 , 0.40816 , 0.019208 ,
0.51587 , -0.34428 , -0.24525 , -0.77984 , 0.27425 ,
0.22418 , 0.20164 , 0.017431 , -0.014697 , -1.0235 ,
-0.39695 , -0.0056188, 0.30569 , 0.31748 , 0.021404 ,
0.11837 , -0.11319 , 0.42456 , 0.53405 , -0.16717 ,
-0.27185 , -0.6255 , 0.12883 , 0.62529 , -0.52086 ],
dtype=float32)len(word_vectors['dog'])100
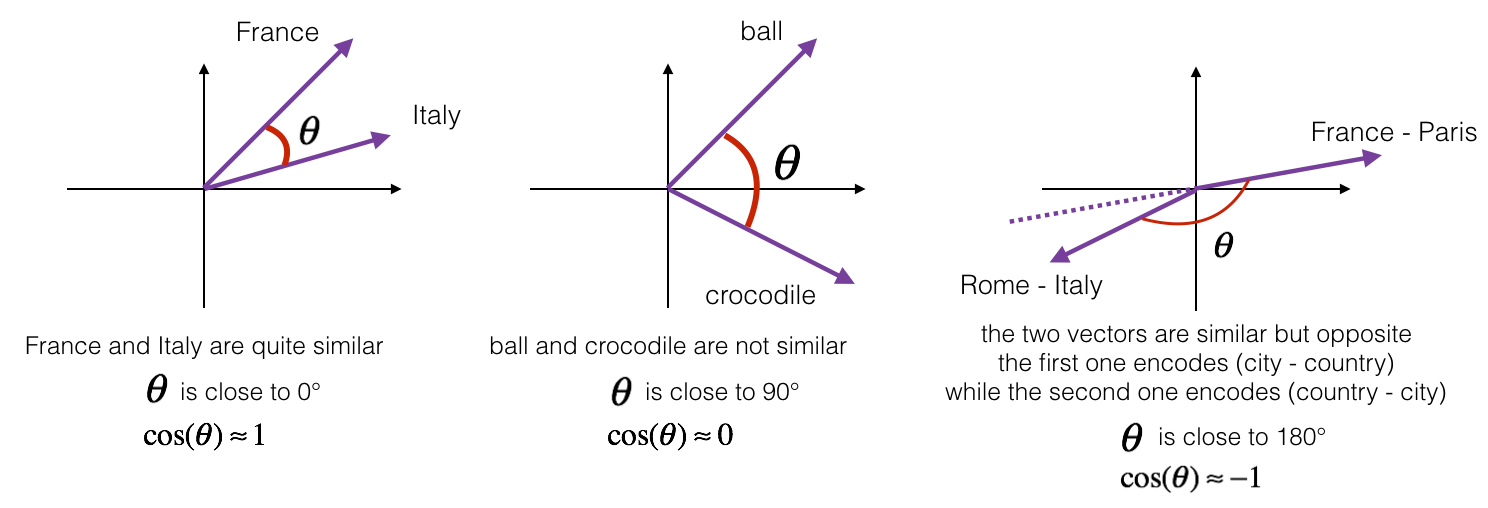
$ A = (a_1, a_2, \ldots, a_n)$
$ B = (b_1, b_2, \ldots, b_n)$
$A \cdot B = a_1* b_1 + a_2_b_2 + \ldots a_nb_n$
$A \cdot B = |A| |B| cos(\theta)$
cosine_similarity = $\frac{A \cdot B}{|A||B|}$
word_vectors['dog'] + word_vectors['dog'] - word_vectors['man']array([ 0.24340999, 0.23372999, 0.34519994, -1.19175 , -1.4724072 ,
0.34235 , 0.60779 , 0.261443 , 0.06009999, -1.37846 ,
-0.88091004, 0.08861998, 1.05097 , -0.37221998, -0.05504 ,
2.07504 , 1.2128501 , -0.17209001, 0.5188256 , 0.68386996,
0.26919997, 0.977559 , -0.41735998, -2.29253 , 0.06891 ,
1.9723799 , -1.7875899 , -0.1394 , -0.08426201, 0.73421997,
0.449713 , 0.27947 , 1.1328939 , 1.48901 , 1.44769 ,
2.25301 , -0.23492998, -0.721868 , 0.78779006, -0.73836505,
0.88069 , -0.447323 , -1.29005 , -1.39741 , -1.10009 ,
0.50502 , -1.6576351 , -0.055184 , 0.38991004, -0.76956004,
0.185334 , 0.43640798, -0.882702 , 0.83290005, 0.13615999,
-0.23210001, 0.58739203, 0.24005997, 0.05180001, -0.398276 ,
0.99437 , 1.40552 , 1.3153701 , 1.20883 , 1.23647 ,
1.692517 , -1.5952799 , -0.22698998, 2.10365 , 0.15522999,
-1.87457 , -0.01184002, 0.03998601, 1.0829899 , -0.315964 ,
0.98266095, -0.86874 , 0.09540001, -1.0042601 , 0.83836997,
-0.29442003, 0.05798 , 0.063619 , 0.197066 , -0.7356999 ,
-0.222 , 0.5118224 , 0.73807997, 0.733638 , 0.577438 ,
-0.04933 , 0.14863001, 0.39170003, 1.022125 , -0.08759001,
-0.589356 , -0.86798 , 1.19477 , 1.211442 , -0.50261 ],
dtype=float32)word_vectors.most_similar(positive=['orange'])[('yellow', 0.7358633279800415),
('red', 0.7140780091285706),
('blue', 0.7118036150932312),
('green', 0.7111418843269348),
('pink', 0.677507221698761),
('purple', 0.6774231791496277),
('black', 0.6709616780281067),
('colored', 0.665260910987854),
('lemon', 0.6251963973045349),
('peach', 0.6168624758720398)]word_vectors.most_similar(positive=['woman', 'king'], negative=['man'])[('queen', 0.7698540687561035),
('monarch', 0.6843381524085999),
('throne', 0.6755736470222473),
('daughter', 0.6594556570053101),
('princess', 0.6520534157752991),
('prince', 0.6517034769058228),
('elizabeth', 0.6464517712593079),
('mother', 0.631171703338623),
('emperor', 0.6106470823287964),
('wife', 0.6098655462265015)]word_vectors.most_similar(positive=['paris', 'germany'], negative=['france'])[('berlin', 0.8846380710601807),
('frankfurt', 0.7985543608665466),
('vienna', 0.7675994038581848),
('munich', 0.7542588114738464),
('hamburg', 0.7182371616363525),
('bonn', 0.6890878081321716),
('prague', 0.6842440962791443),
('cologne', 0.6762093305587769),
('zurich', 0.6653268933296204),
('leipzig', 0.6619253754615784)]word_vectors.most_similar(positive=['walking', 'swam'], negative=['swimming'])[('walked', 0.6780266761779785),
('crawled', 0.6523419618606567),
('wandered', 0.6384280323982239),
('hopped', 0.6131909489631653),
('walks', 0.6122221946716309),
('walk', 0.6120144724845886),
('strolled', 0.6010454893112183),
('slept', 0.5912748575210571),
('wandering', 0.5861443877220154),
('waited', 0.5791574716567993)]word_vectors.most_similar(positive=['puppy', 'cat'], negative=['dog'])[('puppies', 0.6867596507072449),
('kitten', 0.6866797208786011),
('kittens', 0.6383703947067261),
('monkey', 0.6171091198921204),
('rabbit', 0.6136822700500488),
('pup', 0.6054644584655762),
('tabby', 0.5937005281448364),
('retriever', 0.5934329628944397),
('bitch', 0.5817775130271912),
('hound', 0.57785564661026)]word_vectors.most_similar(positive=['cat'])[('dog', 0.8798074722290039),
('rabbit', 0.7424427270889282),
('cats', 0.732300341129303),
('monkey', 0.7288709878921509),
('pet', 0.719014048576355),
('dogs', 0.7163872718811035),
('mouse', 0.6915250420570374),
('puppy', 0.6800068020820618),
('rat', 0.6641027331352234),
('spider', 0.6501135230064392)]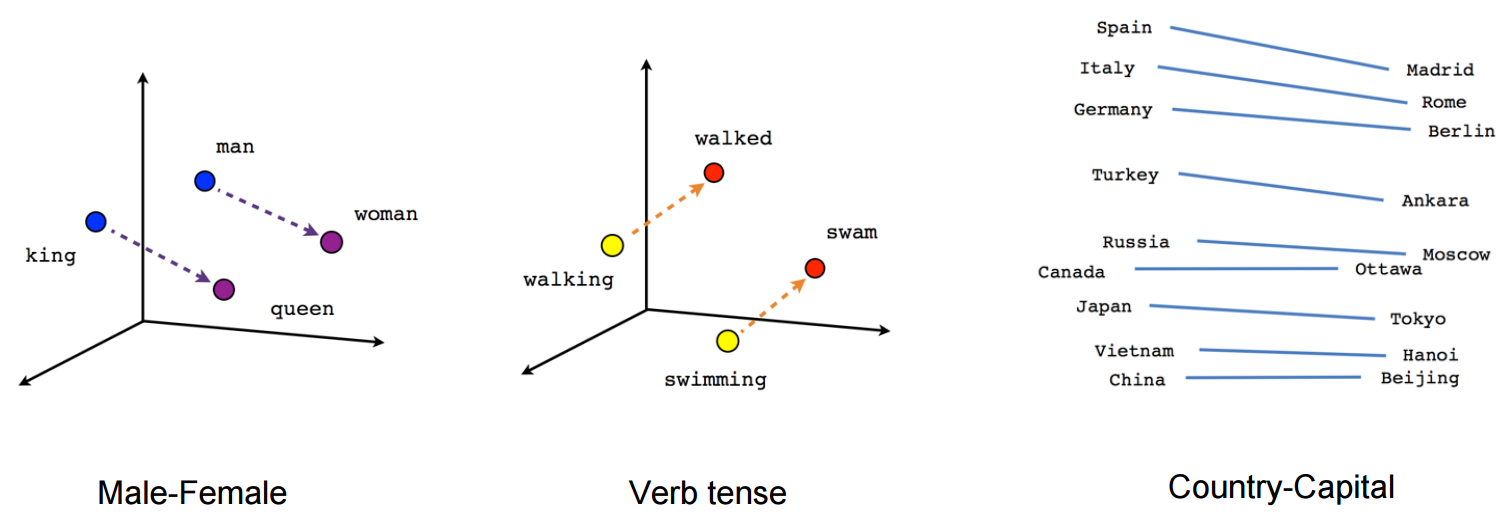
vowpal wabbit
from sklearn.datasets import fetch_20newsgroupsnewsgroups_train = fetch_20newsgroups(subset = 'train')
newsgroups_test = fetch_20newsgroups(subset = 'test')with open('vw_20_newsgroup_train', 'w') as f:
for target, text in zip(newsgroups_train['target'],newsgroups_train['data']):
f.write(str(target + 1) + ' |text ' + text.replace('\n',' ').replace(':','') + '\n')with open('vw_20_newsgroup_test', 'w') as f, open('20_newsgroup_test_targets', 'w') as f_targets:
for target, text in zip(newsgroups_test['target'],newsgroups_test['data']):
f.write('1 |text ' + text.replace('\n',' ').replace(':','') + '\n')
f_targets.write(str(target + 1) + '\n')!vw --oaa 20 -d 'vw_20_newsgroup_train' -f vw_newsgroup_model.vwfinal_regressor = vw_newsgroup_model.vw Num weight bits = 18 learning rate = 0.5 initial_t = 0 power_t = 0.5 using no cache Reading datafile = vw_20_newsgroup_train num sources = 1 average since example example current current current loss last counter weight label predict features 1.000000 1.000000 1 1.0 8 1 124 1.000000 1.000000 2 2.0 5 8 124 0.750000 0.500000 4 4.0 2 5 114 0.875000 1.000000 8 8.0 4 15 417 0.937500 1.000000 16 16.0 1 15 203 0.968750 1.000000 32 32.0 14 7 236 0.953125 0.937500 64 64.0 7 5 50 0.875000 0.796875 128 128.0 17 15 416 0.828125 0.781250 256 256.0 3 1 251 0.757812 0.687500 512 512.0 4 5 163 0.680664 0.603516 1024 1024.0 14 1 183 0.559570 0.438477 2048 2048.0 7 13 65 0.440918 0.322266 4096 4096.0 15 15 94 0.337402 0.233887 8192 8192.0 16 16 384 finished run number of examples = 11314 weighted example sum = 11314.000000 weighted label sum = 0.000000 average loss = 0.300601 total feature number = 3239430
!vw -i vw_newsgroup_model.vw -t -d vw_20_newsgroup_train -p vw_20_newsgroup_train_predonly testing predictions = vw_20_newsgroup_train_pred Num weight bits = 18 learning rate = 0.5 initial_t = 0 power_t = 0.5 using no cache Reading datafile = vw_20_newsgroup_train num sources = 1 average since example example current current current loss last counter weight label predict features 0.000000 0.000000 1 1.0 8 8 124 0.000000 0.000000 2 2.0 5 5 124 0.000000 0.000000 4 4.0 2 2 114 0.000000 0.000000 8 8.0 4 4 417 0.000000 0.000000 16 16.0 1 1 203 0.000000 0.000000 32 32.0 14 14 236 0.000000 0.000000 64 64.0 7 7 50 0.015625 0.031250 128 128.0 17 17 416 0.015625 0.015625 256 256.0 3 3 251 0.011719 0.007812 512 512.0 4 4 163 0.018555 0.025391 1024 1024.0 14 14 183 0.017578 0.016602 2048 2048.0 7 7 65 0.018555 0.019531 4096 4096.0 15 15 94 0.020264 0.021973 8192 8192.0 16 16 384 finished run number of examples = 11314 weighted example sum = 11314.000000 weighted label sum = 0.000000 average loss = 0.020771 total feature number = 3239430
!vw -i vw_newsgroup_model.vw -t -d vw_20_newsgroup_test -p 20_newsgroup_test_predonly testing predictions = 20_newsgroup_test_pred Num weight bits = 18 learning rate = 0.5 initial_t = 0 power_t = 0.5 using no cache Reading datafile = vw_20_newsgroup_test num sources = 1 average since example example current current current loss last counter weight label predict features 1.000000 1.000000 1 1.0 1 10 118 0.500000 0.000000 2 2.0 1 1 145 0.250000 0.000000 4 4.0 1 1 885 0.625000 1.000000 8 8.0 1 14 112 0.750000 0.875000 16 16.0 1 4 427 0.843750 0.937500 32 32.0 1 6 111 0.906250 0.968750 64 64.0 1 20 65 0.921875 0.937500 128 128.0 1 1 322 0.933594 0.945312 256 256.0 1 18 183 0.933594 0.933594 512 512.0 1 10 507 0.935547 0.937500 1024 1024.0 1 5 139 0.937500 0.939453 2048 2048.0 1 6 154 0.933350 0.929199 4096 4096.0 1 10 180 finished run number of examples = 7532 weighted example sum = 7532.000000 weighted label sum = 0.000000 average loss = 0.932953 total feature number = 2086305
!geval --metric Accuracy -o 20_newsgroup_test_pred -e 20_newsgroup_test_targets0.68441317047265
starspace
with open('ss_20_newsgroup_train', 'w') as f:
for target, text in zip(newsgroups_train['target'],newsgroups_train['data']):
f.write(text.replace('\n',' ').replace(':','') + '__label__'+ str(target + 1) + '\n')with open('ss_20_newsgroup_test', 'w') as f:
for target, text in zip(newsgroups_test['target'],newsgroups_test['data']):
f.write(text.replace('\n',' ').replace(':','') +'\n')
!/home/kuba/fastText/fasttext supervised -input ss_20_newsgroup_train -output ss_model -epoch 50Read 3M words Number of words: 275356 Number of labels: 20 Progress: 100.0% words/sec/thread: 1010736 lr: 0.000000 avg.loss: 0.817885 ETA: 0h 0m 0s
!/home/kuba/fastText/fasttext predict ss_model.bin ss_20_newsgroup_test > ss_20_newsgroup_test_pred! cat ss_20_newsgroup_test_pred | sed 's|__label__||' > ss_20_newsgroup_test_pred_label_only!geval --metric Accuracy -o ss_20_newsgroup_test_pred_label_only -e 20_newsgroup_test_targets0.719198088157196
Zadanie
Ireland news na gonito. Proszę użyć gotowej biblioteki, innej niż w sklearn (np starspace, fasttext, vw). Reguły jak zawsze. Wynik powyżej 55 accuracy.