Merge branch 'Oskar-ML' of https://git.wmi.amu.edu.pl/s425077/PotatoPlan into Oskar-ML
This commit is contained in:
commit
42e1212b0b
@ -287,7 +287,7 @@ class Crops
|
|||||||
|
|
||||||
r = (1.0f - productionRate) * 4;
|
r = (1.0f - productionRate) * 4;
|
||||||
g = 0.0f + productionRate;
|
g = 0.0f + productionRate;
|
||||||
b = 0.0f + (float)Math.Pow((double)overhead * 10, 2);
|
b = 0.0f + overhead * 3;
|
||||||
a = 255;
|
a = 255;
|
||||||
|
|
||||||
return new Vector4(r, g, b, a);
|
return new Vector4(r, g, b, a);
|
||||||
|
|||||||
@ -1,4 +1,5 @@
|
|||||||
# Machine Learning Method implementation report - Oskar Nastały
|
# Machine Learning implementation report
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Introduction
|
## Introduction
|
||||||
@ -8,7 +9,7 @@ It's decision is mostly based on nutrients in soil, but also on few other proper
|
|||||||
Dataset is very small, it contains only 100 entries.
|
Dataset is very small, it contains only 100 entries.
|
||||||
There are 7 types of fertilizers, each of them adding a specific amount of nutrients to the soil.
|
There are 7 types of fertilizers, each of them adding a specific amount of nutrients to the soil.
|
||||||
Example:
|
Example:
|
||||||
'''
|
|
||||||
FertilizerType[6] = new Fertilizer
|
FertilizerType[6] = new Fertilizer
|
||||||
{
|
{
|
||||||
ID = 5,
|
ID = 5,
|
||||||
@ -17,14 +18,12 @@ Example:
|
|||||||
Phosphorus = 1.77f / 5,
|
Phosphorus = 1.77f / 5,
|
||||||
Potassium = 9.5f / 5
|
Potassium = 9.5f / 5
|
||||||
};
|
};
|
||||||
'''
|
|
||||||
|
|
||||||
Unfortunately values of nutrients are not based on real values.
|
Unfortunately values of nutrients are not based on real values.
|
||||||
That is because even though dataset intention (by it's creator) was to be used to classify fertilizers, it looks like instead it says what fertilizer WAS used and what will be the results of using that fertilizer on some field.
|
That is because even though dataset intention (by it's creator) was to be used to classify fertilizers, it looks like instead it says what fertilizer WAS used and what will be the results of using that fertilizer on some field.
|
||||||
E.g: Urea has 46% of Nitrogen in it and nothing else. In dataset it was classified as best fertilizer to be used on fields with already really high Nitrogen levels. That would lead to oversaturation with Nitrogen and lack of other nutrients.
|
E.g: Urea has 46% of Nitrogen in it and nothing else. In dataset it was classified as best fertilizer to be used on fields with already really high Nitrogen levels. That would lead to oversaturation with Nitrogen and lack of other nutrients.
|
||||||
So i did some calculations and Urea now looks like this:
|
So i did some calculations and Urea now looks like this:
|
||||||
|
|
||||||
'''
|
|
||||||
FertilizerType[7] = new Fertilizer
|
FertilizerType[7] = new Fertilizer
|
||||||
{
|
{
|
||||||
ID = 6,
|
ID = 6,
|
||||||
@ -34,7 +33,7 @@ So i did some calculations and Urea now looks like this:
|
|||||||
Potassium = 9.5f / 5
|
Potassium = 9.5f / 5
|
||||||
};
|
};
|
||||||
// an "inversed" and little modified counterpart of real-world version of this fertilizer.
|
// an "inversed" and little modified counterpart of real-world version of this fertilizer.
|
||||||
'''
|
|
||||||
|
|
||||||
## Implementation
|
## Implementation
|
||||||
|
|
||||||
@ -42,15 +41,13 @@ I used Gradient Boosting Decision Tree Algorithm for this task due to many featu
|
|||||||
|
|
||||||
First a csv file is loaded:
|
First a csv file is loaded:
|
||||||
|
|
||||||
'''
|
|
||||||
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<ModelInput>(
|
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<ModelInput>(
|
||||||
path: path,
|
path: path,
|
||||||
hasHeader: true,
|
hasHeader: true,
|
||||||
separatorChar: ',',
|
separatorChar: ',',
|
||||||
allowQuoting: true,
|
allowQuoting: true,
|
||||||
allowSparse: false);
|
allowSparse: false);
|
||||||
'''
|
|
||||||
|
|
||||||
Then it is passed to next function which will train, evaluate and build a model.
|
Then it is passed to next function which will train, evaluate and build a model.
|
||||||
Also trainer parameters will be fine-tuned here to prevent overfitting as much as possible by:
|
Also trainer parameters will be fine-tuned here to prevent overfitting as much as possible by:
|
||||||
- limiting number of leaves,
|
- limiting number of leaves,
|
||||||
@ -60,7 +57,6 @@ while maintaining high accuracy by:
|
|||||||
- low learning rate combine with
|
- low learning rate combine with
|
||||||
- high number of iterations.
|
- high number of iterations.
|
||||||
|
|
||||||
'''
|
|
||||||
var options = new LightGbmMulticlassTrainer.Options
|
var options = new LightGbmMulticlassTrainer.Options
|
||||||
{
|
{
|
||||||
MaximumBinCountPerFeature = 8,
|
MaximumBinCountPerFeature = 8,
|
||||||
@ -75,11 +71,9 @@ while maintaining high accuracy by:
|
|||||||
MaximumTreeDepth = 10
|
MaximumTreeDepth = 10
|
||||||
}
|
}
|
||||||
};
|
};
|
||||||
'''
|
|
||||||
|
|
||||||
Creating pipeline for the model:
|
Creating pipeline for the model:
|
||||||
|
|
||||||
'''
|
|
||||||
var pipeline = mlContext.Transforms
|
var pipeline = mlContext.Transforms
|
||||||
.Text.FeaturizeText("Soil_TypeF", "Soil_Type")
|
.Text.FeaturizeText("Soil_TypeF", "Soil_Type")
|
||||||
.Append(mlContext.Transforms.Text.FeaturizeText("Crop_TypeF", "Crop_Type"))
|
.Append(mlContext.Transforms.Text.FeaturizeText("Crop_TypeF", "Crop_Type"))
|
||||||
@ -88,16 +82,13 @@ Creating pipeline for the model:
|
|||||||
.AppendCacheCheckpoint(mLContext)
|
.AppendCacheCheckpoint(mLContext)
|
||||||
.Append(mLContext.MulticlassClassification.Trainers.LightGbm(options))
|
.Append(mLContext.MulticlassClassification.Trainers.LightGbm(options))
|
||||||
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
|
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
|
||||||
'''
|
|
||||||
|
|
||||||
Evaluation of the pipeline is done with cross-validation method with 10 folds.
|
Evaluation of the pipeline is done with cross-validation method with 10 folds.
|
||||||
Results are as follow:
|
Results are as follow:
|
||||||
|
|
||||||
'''
|
|
||||||
Micro Accuracy: 0.95829
|
Micro Accuracy: 0.95829
|
||||||
LogLoss Average: 0.100171
|
LogLoss Average: 0.100171
|
||||||
LogLoss Reduction: 0.933795
|
LogLoss Reduction: 0.933795
|
||||||
'''
|
|
||||||
|
|
||||||
Model is created and saved for later use, to skip long trainig and evaluation times.
|
Model is created and saved for later use, to skip long trainig and evaluation times.
|
||||||
Later that model is loaded and prediction engine is created when program is started.
|
Later that model is loaded and prediction engine is created when program is started.
|
||||||
@ -107,8 +98,23 @@ Later that model is loaded and prediction engine is created when program is star
|
|||||||
|
|
||||||
Agent (tractor) navigates trough the grid looking for tiles where it can plant some plants.
|
Agent (tractor) navigates trough the grid looking for tiles where it can plant some plants.
|
||||||
Upon planting and visitin already growing plants agent decides if any fertilizer is needed (rule based decision), and what fertilizer to use (using ML prediction engine).
|
Upon planting and visitin already growing plants agent decides if any fertilizer is needed (rule based decision), and what fertilizer to use (using ML prediction engine).
|
||||||
|
|
||||||
|
if (farm.getCrop(x, y).getStatus() >= 2)
|
||||||
|
{
|
||||||
|
fertilizer = fertilizerHolder.GetFertilizer(Engine.PredictFertilizer(farm.getCrop(x, y), farm.getPresetCropTypes(farm.getCrop(x, y).getCropType())));
|
||||||
|
while (!(farm.getCrop(x, y).isSaturated(-1)) && farm.getCrop(x, y).belowCapacity() && inventory.useItem(fertilizerHolder.GetFertilizerID(fertilizer.Name), 0))
|
||||||
|
{
|
||||||
|
farm.getCrop(x, y).Fertilize(fertilizer);
|
||||||
|
fertilizer = fertilizerHolder.GetFertilizer(Engine.PredictFertilizer(farm.getCrop(x, y), farm.getPresetCropTypes(farm.getCrop(x, y).getCropType())));
|
||||||
|
WaitTwoFrames = true;
|
||||||
|
}
|
||||||
|
|
||||||
If field is properly fertilized it will have higher production rate, resulting in faster growth of a plant.
|
If field is properly fertilized it will have higher production rate, resulting in faster growth of a plant.
|
||||||
Production rate value is shown in the UI as well as it is represented by the colour of progression bar (right side of every tile).
|
Production rate value is shown in the UI as well as it is represented by the colour of progression bar (right side of every tile).
|
||||||
At 100% bar will pure **Green**. Any value below will make bar more **Red**, while any value above will add **Blue**, eventually turning bar colour into cyan.
|
At 100% bar will pure **Green**. Any value below will make bar more **Red**, while any value above will add **Blue**, eventually turning bar colour into cyan.
|
||||||
|
|
||||||

|
Example:
|
||||||
|
|
||||||
|
|
||||||
|
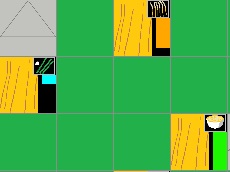
|
||||||
|
|
||||||
|
|||||||
BIN
example_img.jpg
Normal file
BIN
example_img.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 11 KiB |
BIN
example_img.png
BIN
example_img.png
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 4.5 KiB |
Loading…
Reference in New Issue
Block a user