Docs > Transforming data (#3103)
* Docs > Transforming data Cell editing page is up first. Ignore the "overview" page for now. * Add column-editing page * Update docs/docs/manual/cellediting.md Co-authored-by: Tom Morris <tfmorris@gmail.com> * Vairous updates from Tom's comments * Reconciling + Transposing * Mistakes! * Another mistake! * column editing > fetching URLs * Update cellediting.md * Update docs/docs/manual/reconciling.md Co-authored-by: Antonin Delpeuch <antonin@delpeuch.eu> * Move + edit reconciliation page * Update reconciling.md * Update columnediting.md * Edit transposing + fetch error message update + misc formatting * Title fix * Phrasing Co-authored-by: Tom Morris <tfmorris@gmail.com> Co-authored-by: Antonin Delpeuch <antonin@delpeuch.eu>
162
docs/docs/manual/cellediting.md
Normal file
@ -0,0 +1,162 @@
|
||||
---
|
||||
id: cellediting
|
||||
title: Cell editing
|
||||
sidebar_label: Cell editing
|
||||
---
|
||||
## Overview
|
||||
|
||||
OpenRefine offers a number of features to edit and improve the contents of cells automatically and efficiently.
|
||||
|
||||
One way of doing this is editing through a [text facet](facets#text-facet). Once you have created a facet on a column, hover over the displayed results in the sidebar. Click on the small “edit” button that appears to the right of the facet, and type in a new value. This will apply to all the cells in the facet.
|
||||
|
||||
## Transform
|
||||
|
||||
Select “Edit cells” → “Transforms” to open up an expressions window. From here, you can apply [expressions](expressions) to your data. The simplest examples are GREL functions such as `toUppercase` or `toLowercase`, used in expressions as `toUppercase(value)` or `toLowercase(value)`. In all of these cases, `value` is the value in each cell in the selected column.
|
||||
|
||||
Use the preview to ensure your data is being transformed correctly.
|
||||
|
||||
You can also switch to the “History” tab inside the expressions window to reuse expressions you’ve already attempted in this project, whether they have been undone or not.
|
||||
|
||||
OpenRefine offers you some frequently-used transformations in the next menu option, “Common transforms.” For more custom transforms, read up on [expressions](expressions).
|
||||
|
||||
## Common transforms
|
||||
|
||||
### Trim leading and trailing whitespace
|
||||
|
||||
Often cell contents that should be identical, and look identical, are different because of space or line-break characters that are invisible to users. This function will get rid of any characters that sit before or after visible text characters.
|
||||
|
||||
### Collapse consecutive whitespace
|
||||
|
||||
You may also find that some text cells contain what look like spaces but are actually tabs, or contain multiple spaces in a row. This function will remove all space characters that sit in sequence and replace them with a single space.
|
||||
|
||||
### Unescape HTML
|
||||
|
||||
Your data may come from an HTML-formatted source that expresses some characters through references (such as “&nbsp;” for a space, or “%u0107” for a ć) instead of the actual Unicode characters. You can use the “unescape HTML entities” transform to look for these codes and replace them with the characters they represent.
|
||||
|
||||
### Replace smart quotes with ASCII
|
||||
|
||||
Smart quotes (or curly quotes) recognize whether they come at the beginning or end of a string, and will generate an “open” quote (“) and a “close” quote (”). These characters are not ASCII-compliant (though they are UTF8-compliant) so you can use this tranform to replace them with a straight double quote character (") instead.
|
||||
|
||||
### Case transforms
|
||||
|
||||
You can transform an entire column of text into UPPERCASE, lowercase, or Title Case using these three options. This can be useful if you are planning to do textual analysis and wish to avoid case-sensitivity (which many functions are) causing problems in your analysis.
|
||||
|
||||
### Data-type transforms
|
||||
|
||||
As detailed in [Data types](exploring#data-types), OpenRefine recognizes different data types: string, number, boolean, and date. When you use these transforms, OpenRefine will check to see if the given values can be converted, then both transform the data in the cells (such as “3” as a text string to “3” as a number) and convert the data type on each successfully transformed cell. Cells that cannot be transformed will output the original value and maintain their original data type.
|
||||
|
||||
For example, the following column of strings on the left will transform into the values on the right:
|
||||
|
||||
|Input|>|Output|
|
||||
|---|---|---|
|
||||
|23/12/2019|>|2019-12-23T00:00:00Z|
|
||||
|14-10-2015|>|2015-10-14T00:00:00Z|
|
||||
|2012 02 16|>|2012-02-16T00:00:00Z|
|
||||
|August 2nd 1964|>|1964-08-02T00:00:00Z|
|
||||
|today|>|today|
|
||||
|never|>|never|
|
||||
|
||||
This is based on OpenRefine’s ability to recognize dates with the [`toDate()` function](expressions#dates).
|
||||
|
||||
Clicking the “today” cell and editing its data type manually will convert “today” into a value such as “2020-08-14T00:00:00Z”. Attempting the same data-type change on “never” will give you an error message and refuse to proceed.
|
||||
|
||||
Because these common transforms do not offer the ability to output an error instead of the original cell contents, be careful to look for unconverted and untransformed values. You will see a yellow alert at the top of screen that will tell you how many cells were converted - if this number does not match your current row set, you will need to look for and manually correct the remaining cells.
|
||||
|
||||
You can also convert cells into null values or empty strings. This can be useful if you wish to, for example, erase duplicates that you have identified and are analyzing as a subset.
|
||||
|
||||
## Fill down and blank down
|
||||
|
||||
Fill down and blank down are two functions most frequently used when encountering data organized into [records](exploring#row-types-rows-vs-records) - that is, multiple rows associated with one specific entity.
|
||||
|
||||
If you receive information in rows mode and want to convert it to records mode, the easiest way is to sort your first column by the value that you want to use as a unique records key, [make that sorting permanent](transforming#edit-rows), then blank down all the duplicates in that column. OpenRefine will retain the first unique value and erase the rest. Then you can switch from “Show as rows” to “Show as records” and OpenRefine will convert the data based on the remaining values in the first column. Be careful that your data is sorted properly before you begin blanking down - not just the first column but other columns you may want to have in a certain order. For example, you may have multiple identical entries in the first column, one with a value in the second column and one with an empty cell in the second column. In this case you want the value to come first, so that you can clean up empty rows later, once you blank down.
|
||||
|
||||
If, conversely, you’ve received data with empty cells because it was already in something akin to records mode, you can fill down information to the rest of the rows. This will duplicate whatever value exists in the topmost cell with a value: if the first row in the record is blank, it will take information from the next cell, or the cell after that, until it finds a value. The blank cells above this will remain blank.
|
||||
|
||||
## Split multi-valued cells
|
||||
|
||||
Splitting cells with more than one value in them is a common way to get your data from single rows into multi-row records. Survey data, for example, frequently allows respondents to “Select all that apply,” or an inventory list might have items filed under more than one category.
|
||||
|
||||
You can split a column based on any character or series of characters you input, such as a semi-colon (;) or a slash (/). The default is a comma. Splitting based on a separator will remove the separator characters, so you may wish to include a space with your separator (; ) if it exists in your data.
|
||||
|
||||
You can use [expressions](expressions) to design the point at which a cell should split itself into two or more rows. This can be used to identify special characters or create more advanced evaluations. You can split on a line-break by entering `\n` and checking the “regular expression” checkbox.
|
||||
|
||||
This can be useful if the split is not straightforward: say, if a capital letter indicates the beginning of a new string, or if you need to _not_ always split on a character that appears in both the strings and as a separator. Remember that this will remove all the matching characters.
|
||||
|
||||
You can also split based on the lengths of the strings you expect to find. This can be useful if you have predictable data in the cells: for example, a 10-digit phone number, followed by a space, followed by another 10-digit phone number. Any characters past the explicit length you’ve specified will be discarded: if you split by “11, 10” any characters that may come after the 21st character will disappear. If some cells only have one phone number, you will end up with blank rows.
|
||||
|
||||
If you have data that should be split into multiple columns instead of multiple rows, see [split into several columns(columnediting#split-into-several-columns).
|
||||
|
||||
## Join multi-valued cells
|
||||
|
||||
Joining will reverse the “split multi-valued cells” operation, or join up information from multiple rows into one row. All the strings will be compressed into the topmost cell in the record, in the order they appear. A window will appear where you can set the separator; the default is a comma and a space (, ). This separator is optional.
|
||||
|
||||
## Cluster and edit
|
||||
|
||||
Creating a facet on a column is a great way to look for inconsistencies in your data; clustering is a great way to fix those inconsistencies. Clustering uses a variety of comparison methods to find text entries that are similar but not exact, then shares those results with you so that you can merge the cells that should match. Where editing a single cell or text facet at a time can be time-consuming and difficult, clustering is quick and streamlined.
|
||||
|
||||
Clustering always requires the user to approve each suggested edit - it will display values it thinks are variations on the same thing, and you can select which version to keep and apply across all those matching cells (or type in your own version). OpenRefine will do a number of cleanup operations behind the scenes, in memory, in order to do its analysis, but only the merges you approve will modify your data.
|
||||
|
||||
You can start the process in two ways: using the dropdown menu on your column, select “Edit cells” → “Cluster and edit…” or create a text facet and then press the “Cluster” button that appears in the facet box.
|
||||
|
||||

|
||||
|
||||
The clustering pop-up window will take a small amount of time to analyze your column, and then make some suggestions based on the clustering method currently active.
|
||||
|
||||
For each cluster identified, you can pick one of the existing values to apply to all cells, or manually type in a new value in the text box. And, of course, you can choose not to cluster them at all. OpenRefine will keep analyzing every time you make a change, with “Merge selected & re-cluster,” and you can work through all the methods this way.
|
||||
|
||||
You can also export the currently identified clusters as a JSON file, or close the window with or without applying your changes. You can also use the histograms on the right to narrow down to, for example, clusters with lots of matching rows, or clusters of long or short values.
|
||||
|
||||
### Clustering methods
|
||||
|
||||
You don’t need to understand the details behind each clustering method to apply them successfully to your data. The order in which these methods are presented in the interface and on this page is the order we recommend - starting with the most strict rules and moving to the most lax, which require more human supervision to apply correctly.
|
||||
|
||||
The clustering pop-up window offers you a variety of clustering methods:
|
||||
|
||||
* key collision
|
||||
* fingerprint
|
||||
* ngram-fingerprint
|
||||
* metaphone3
|
||||
* cologne-phonetic
|
||||
* Daitch-Mokotoff
|
||||
* Beider-Morse
|
||||
* nearest neighbor
|
||||
* levenshtein
|
||||
* ppm
|
||||
|
||||
**Key collisions** are very fast and can process millions of cells in seconds:
|
||||
|
||||
**Fingerprinting** is the least likely to produce false positives, so it’s a good place to start. It does the same kind of data-cleaning behind the scenes that you might think to do manually: fix whitespace into single spaces, put all uppercase letters into lowercase, discard punctuation, remove diacritics (e.g. accents) from characters, split all strings (words) and sort them alphabetically (so “Zhenyi, Wang” becomes “Wang Zhenyi”). This makes comparing those types of name values very easy.
|
||||
|
||||
**N-gram fingerprinting** allows you to set the _n_ value to whatever number you’d like, and will create n-grams of _n_ size (after doing some cleaning), alphabetize them, then join them back together into a _fingerprint_. For example, a 1-gram fingerprint will simply organize all the letters in the cell into alphabetical order - by creating segments one character in length. A 2-gram fingerprint will find all the two-character segments, remove duplicates, alphabetize them, and join them back together (for example, “banana” generates “ba an na an na,” which becomes “anbana”). This can help match cells that have typos, or incorrect spaces (such as matching “lookout” and “look out,” which fingerprinting itself won’t identify). The higher the _n_ value, the fewer clusters will be identified. With 1-grams, keep an eye out for mismatched values that are near-anagrams of each other (such as “Wellington” and “Elgin Town”).
|
||||
|
||||
The next four methods are phonetic algorithsm: they know whether two letters sound the same when pronounced out loud, and assess text values based on that (such as knowing that a word with an “S” might be a mistype of a word with a “Z”). They are great for spotting mistakes made by not knowing the spelling of a word or name after only hearing it spoken aloud.
|
||||
|
||||
**Metaphone3 fingerprinting** is an English-language phonetic algorithm. For example, “Reuben Gevorkiantz” and “Ruben Gevorkyants” share the same phonetic fingerprint in English.
|
||||
|
||||
**Cologne fingerprinting** is another phonetic algorithm, but for German pronunciation.
|
||||
|
||||
**Daitch-Mokotoff** is a phonetic algorithm for Slavic and Yiddish words, especially names. **Baider-Morse** is a version of Daitch-Mokotoff that is slightly more strict.
|
||||
|
||||
Regardless of the language of your data, applying each of them might find different potential matches: for example, Metaphone clusters “Cornwall” and “Corn Hill” and “Green Hill,” while Cologne clusters “Greenvale” and “Granville” and “Cornwall” and “Green Wall.”
|
||||
|
||||
**Nearest neighbor** clustering methods are slower than key collision methods. They allow the user to set a radius - a threshold for matching or not matching. OpenRefine uses a “blocking” method first, which sorts values based on whether they have a certain amount of similarity (the default is “6” for a six-character string of identical characters) and then runs the nearest-neighbor operations on those sorted groups. We recommend setting the block number to at least 3, and then increasing it if you need to be more strict (for example, if every value with “river” is being matched, you should increase it to 6 or more). Note bigger block values will take much longer to process, while smaller blocks may miss matches. Increasing the radius will make the matches more lax, as bigger differences will be clustered:
|
||||
|
||||
**Levenshtein distance** counts the number of edits required to make one value perfectly match another. As in the key collision methods above, it will do things like change uppercase to lowercase, fix whitespace, change special characters, etc. Each character that gets changed counts as 1 “distance.” “New York” and “newyork” have an edit distance value of 3 (“N” to “n”, “Y” to “y,” remove the space). It can do relatively advanced edits, such as understand the distance between “M. Makeba” and “Miriam Makeba” (5), but it may create false positives if these distances are greater than other, simpler transformations (such as the one-character distance to “B. Makeba,” another person entirely).
|
||||
|
||||
**PPM (or Prediction by Partial Matching)** uses compression to see whether two values are similar or different. In practice, this method is very lax even for small radius values and tends to generate many false positives, but because it operates at a sub-character level it is capable of finding substructures that are not easily identifiable by distances that work at the character level. So it should be used as a 'last resort' clustering method. It is also more effective on longer strings than on shorter ones.
|
||||
|
||||
For more of the theory behind clustering, see [Clustering In Depth](https://github.com/OpenRefine/OpenRefine/wiki/Clustering-In-Depth).
|
||||
|
||||
## Replace
|
||||
|
||||
OpenRefine provides a find/replace function for you to edit your data. Selecting “Edit cells” → “Replace” will bring up a simple window where you can input a string to search and a string to replace it with. You can set case-sensitivity, and set it to only select whole words, defined by a string with spaces or punctuation around it (to prevent, for example, “house” selecting the “house” part of “doghouse”). You can use regular expressions in this field.
|
||||
|
||||
You may wish to preview the results of this operation by testing it with a [Text filter](facets#text-filter) first.
|
||||
|
||||
You can also perform a sort of find/replace operation by editing one cell, and selecting “apply to all identical cells.”
|
||||
|
||||
## Edit one cell at a time
|
||||
|
||||
You can edit individual cells by hovering your mouse over that cell. You should see a tiny blue button labeled “edit.” Click it to edit the cell. That pops up a window with a bigger text field for you to edit. You can change the data type of that cell, and you can apply these changes to all identical cells (in the same column), using this pop-up window.
|
||||
|
||||
You will likely want to avoid doing this except in rare cases - the more efficient means of improving your data will be through automated and bulk operations.
|
||||
125
docs/docs/manual/columnediting.md
Normal file
@ -0,0 +1,125 @@
|
||||
---
|
||||
id: columnediting
|
||||
title: Column editing
|
||||
sidebar_label: Column editing
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Column editing contains some of the most powerful data-improvement methods in OpenRefine. While we call it “edit column,” this includes using one column of data to add entirely new columns and fields to your dataset.
|
||||
|
||||
## Split or Join
|
||||
|
||||
Many users find that they frequently need to make their data more granular: for example, splitting a “Firstname Lastname” column into two columns, one for first names and one for last names. You may want to split out an address column into columns for street addresses, cities, territories, and postal codes.
|
||||
|
||||
The reverse is also often true: you may have several columns of category values that you want to join into one “category” column.
|
||||
|
||||
### Split into several columns...
|
||||
|
||||

|
||||
|
||||
Splitting one column into several columns requires you to identify the character, string lengths, or evaluating expression you want to split on. Just like [splitting multi-valued cells into rows](cellediting#split-multi-valued-cells), splitting cells into multiple columns will remove the separator character or string you indicate. Lengths will discard any information that comes after the specified total length.
|
||||
|
||||
You can also specify a maximum number of new columns to be made: separator characters after this limit will be ignored, and the remaining characters will end up in the last column.
|
||||
|
||||
New columns will be named after the original column, with a number: “Location 1,” “Location 2,” etc. You can have the original column removed with this operation, and you can have [data types](exploring#data-types) identified where possible. This function will work best with converting to numbers, and may not work with dates.
|
||||
|
||||
### Join columns…
|
||||
|
||||

|
||||
|
||||
You can join columns by selecting “Edit column” → “Join columns…”. All the columns currently in your dataset will appear in the pop-up window. You can select or un-select all the columns you want to join, and drag columns to put them in the order you want to join them in. You will define a separator character (optional) and define a string to insert into empty cells (nulls).
|
||||
|
||||
The joined data will appear in the column you originally selected, or you can create a new column based on this join and specify a name. You can delete all the columns that were used in this join operation.
|
||||
|
||||
## Add column based on this column
|
||||
|
||||
This selection will open up an [expressions](expressions) window where you can transform the data from this column (using `value`), or write a more complex expression that takes information from any number of columns or from external reconciliation sources.
|
||||
|
||||
The simplest way to use this operation is simply leave the default `value` in the expression field, to create an exact copy of your column.
|
||||
|
||||
For a reconciled column, you can use the variable `cell` instead, to copy both the original string and the existing reconciliation data. This will include matched values, candidates, and new items. You can learn other useful variables in the [Expressions section on GREL variables](expressions#variables).
|
||||
|
||||
You can create a column based on concatenating (merging) two other columns. Select either of the source columns, apply “Column editing” → “Add column based on this column...”, name your new column, and use the following format in the expression window:
|
||||
|
||||
```
|
||||
cells[“Column 1”].value + cells[“Column 2”].value
|
||||
```
|
||||
|
||||
If your column names do not contain spaces, you can use the following format:
|
||||
|
||||
```
|
||||
cells.Column1.value + cells.Column2.value
|
||||
```
|
||||
|
||||
If you are in records mode instead of rows mode, you can concatenate using the following format:
|
||||
|
||||
```
|
||||
row.record.cells.Column1.value + row.record.cells.Column2.value
|
||||
```
|
||||
|
||||
You may wish to add separators or spaces, or modify your input during this operation with more advanced GREL.
|
||||
|
||||
## Add column by fetching URLs
|
||||
|
||||
Through the “Add column by fetching URLs” function, OpenRefine supports the ability to fetch HTML or data from web pages or services. In this operation you will be taking strings from your selected column and inserting them into URL strings. This presumes your chosen column contains parts of paths to valid HTML pages or files online.
|
||||
|
||||
If you have a column of URLs and watch to fetch the information that they point to, you can simply run the expression as `value`. If your column has, for example, unique identifiers for Wikidata entities (numerical values starting with Q), you can download the JSON-formatted metadata about each entity with
|
||||
|
||||
```
|
||||
“https://www.wikidata.org/wiki/Special:EntityData/” + value + “.json”
|
||||
```
|
||||
|
||||
or whatever metadata format you prefer. [Information about these Wikidata options can be found here](https://www.wikidata.org/wiki/Wikidata:Data_access).
|
||||
|
||||
This service is more useful when getting metadata files instead of HTML, but you may wish to work with a page’s entire HTML contents and then parse out information from that.
|
||||
|
||||
Be aware that the fetching process can take quite some time and that servers may not want to fulfill hundreds or thousands of page requests in seconds. Fetching allows you to set a “throttle delay” which determines the amount of time between requests. The default is 5 seconds per row in your dataset (5000 milliseconds).
|
||||
|
||||

|
||||
|
||||
Note the following:
|
||||
|
||||
* Many systems prevent you from making too many requests per second. To avoid this problem, set the throttle delay, which tells OpenRefine to wait the specified number of milliseconds between URL requests.
|
||||
* Before pressing “OK,” copy and paste a URL or two from the preview and test them in another browser tab to make sure they work.
|
||||
* In some situations you may need to set [HTTP request headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers). To set these, click the small “Show” button next to “HTTP headers to be used when fetching URLs” in the settings window. The authorization credentials get logged in your operation history in plain text, which may be a security concern for you. You can set the following request headers:
|
||||
* [User-Agent](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent)
|
||||
* [Accept](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Accept)
|
||||
* [Authorization](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Authorization)
|
||||
|
||||
### Common errors
|
||||
|
||||
When OpenRefine attempts to fetch information from a web page or service, it can fail in a variety of ways. The following information is meant to help troubleshoot and fix problems encountered when using this function.
|
||||
|
||||
First, make sure that your fetching operation is storing errors (check “store error”). Then run the fetch and look at the error messages.
|
||||
|
||||
**“HTTP error 403 : Forbidden”** can be simply down to you not having access to the URL you are trying to use. If you can access the same URL with your browser, the remote site may be blocking OpenRefine because it doesn't recognize its request as valid. Changing the [User-Agent](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent) request header may help. If you believe you should have access to a site but are “forbidden,” you may wish to contract the administrators.
|
||||
|
||||
**“HTTP error 404 : Not Found”** indicates that the information you are requesting does not exist, perhaps due to a problem with your cell values if it only happening in certain rows.
|
||||
|
||||
**“HTTP error 500 : Internal Server Error”** indicates the remote server is having a problem filling your request. You may wish to simply wait and try again later, or double-check the URLs.
|
||||
|
||||
**“error: javax.net.ssl.SSLHandshakeException: Received fatal alert: handshake_failure”** can occur when you are trying to retrieve information over HTTPS but the remote site is using an encryption not supported by the Java virtual machine being used by OpenRefine.
|
||||
|
||||
You can check which encryption methods are supported by your OpenRefine/Java installation by using a service such as **How's my SSL**. Add the URL `https://www.howsmyssl.com/a/check` to an OpenRefine cell and run “Add column by fetching URLs” on it, which will provide a description of the SSL client being used.
|
||||
|
||||
You can try installing additional encryption supports by installing the [Java Cryptography Extension](https://www.oracle.com/java/technologies/javase-jce8-downloads.html).
|
||||
Note that for Mac users and for Windows users with the OpenRefine installation with bundled JRE, these updated cipher suites need to be dropped into the Java install within the OpenRefine application:
|
||||
|
||||
* On Mac, it will look something like `/Applications/OpenRefine.app/Contents/PlugIns/jdk1.8.0_60.jdk/Contents/Home/jre/lib/security`.
|
||||
* On Windows: `\server\target\jre\lib\security`.
|
||||
|
||||
An error that includes **“javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed”** can occur when you try to retrieve information over HTTPS but the remote site is using a certificate not trusted by your local Java installation. You will need to make sure that the certificate, or (more likely) the root certificate, is trusted.
|
||||
|
||||
The list of trusted certificates is stored in an encrypted file called `cacerts` in your local Java installation. This can be read and updated by a tool called “keytool.” You can find directions on how to add a security certificate to the list of trusted certificates for a Java installation [here](http://magicmonster.com/kb/prg/java/ssl/pkix_path_building_failed.html) and [here](http://javarevisited.blogspot.co.uk/2012/03/add-list-certficates-java-keystore.html).
|
||||
|
||||
Note that for Mac users and for Windows users with the OpenRefine installation with bundled JRE, the `cacerts` file within the OpenRefine application needs to be updated.
|
||||
|
||||
* On Mac, it will look something like `/Applications/OpenRefine.app/Contents/PlugIns/jdk1.8.0_60.jdk/Contents/Home/jre/lib/security/cacerts`.
|
||||
* On Windows: `\server\target\jre\lib\security\`.
|
||||
|
||||
## Rename, Remove, and Move
|
||||
|
||||
Any column can be repositioned, renamed, or deleted with these actions. They can be undone, but a removed column cannot be restored later if you keep modifying your data. If you wish to temporarily hide a column, go to “View” → “Collapse this column” instead.
|
||||
|
||||
Be cautious about moving columns in [records mode](cellediting#rows-vs-records): if you change the first column in your dataset (the key column), your records may change in unintended ways.
|
||||
220
docs/docs/manual/reconciling.md
Normal file
@ -0,0 +1,220 @@
|
||||
---
|
||||
id: reconciling
|
||||
title: Reconciling
|
||||
sidebar_label: Reconciling
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Reconciliation is the process of matching your dataset with that of an external source. Datasets are produced by libraries, archives, museums, academic organizations, scientific institutions, non-profits, and interest groups. You can also reconcile against user-edited data on [Wikidata](wikidata), or reconcile against [a local dataset that you yourself supply](https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources#local-services).
|
||||
|
||||
To reconcile your OpenRefine project against an external dataset, that dataset must offer a web service that conforms to the [Reconciliation Service API standards](https://reconciliation-api.github.io/specs/0.1/).
|
||||
|
||||
You may wish to reconcile in order to fix spelling or variations in proper names, to clean up manually-entered subject headings against authorities such as the [Library of Congress Subject Headings](https://id.loc.gov/authorities/subjects.html) (LCSH), to link your data to an existing set, to add it to an open and editable system such as [Wikidata](https://www.wikidata.org), or to see whether entities in your project appear in some specific list or not, such as the [Panama Papers](https://aleph.occrp.org/datasets/734).
|
||||
|
||||
Reconciliation is semi-automated: OpenRefine matches your cell values to the reconciliation information as best it can, but human judgment is required to ensure the process is successful. Reconciling happens by default through string searching, so typos, whitespace, and extraneous characters will have an effect on the results. You may wish to clean and cluster your data before reconciliaton.
|
||||
|
||||
We recommend planning your reconciliation operations as iterative: reconcile multiple times with different settings, and with different subgroups of your data.
|
||||
|
||||
## Sources
|
||||
|
||||
There is a [current list of reconcilable authorities](https://reconciliation-api.github.io/testbench/) that includes instructions for adding new services via Wikidata editing. OpenRefine maintains a [further list of sources on the wiki](https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources), which can be edited by anyone. This list includes ways that you can reconcile against a [local dataset](https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources#local-services).
|
||||
|
||||
Other services may exist that are not yet listed in these two places: for example, the [310 datasets hosted by the Organized Crime and Corruption Reporting Project (OCCRP)](https://aleph.occrp.org/datasets/) each have their own reconciliation URL, or you can reconcile against their entire database with the URL listed [here](https://reconciliation-api.github.io/testbench/). For another example, you can reconcile against the entire Virtual International Authority File (VIAF) dataset, or [only the contributions from certain institutions](http://refine.codefork.com/). Search online to see if the authority you wish to reconcile against has an available service, or whether you can download a copy to reconcile against locally.
|
||||
|
||||
OpenRefine offers Wikidata reconciliation by default - see the [Wikidata](wikidata) page for more information particular to that service.
|
||||
|
||||
:::info
|
||||
OpenRefine extensions can add reconciliation services, and can also add enhanced reconciliation capacities. Check the list of extensions on the [Downloads page](https://openrefine.org/download.html) for more information.
|
||||
:::
|
||||
|
||||
Each source will have its own documentation on how it provides reconciliation. Refer to the service itself if you have questions about its behaviors and which OpenRefine features it supports.
|
||||
|
||||
## Getting started
|
||||
|
||||
Select “Reconcile” → “Start reconciling” on a column. If you want to reconcile only some cells in that column, first use filters and facets to isolate them.
|
||||
|
||||
In the reconciliation window, you will see Wikidata offered as a default service. To add another service, click “Add Standard Service…” and paste in the URL of a [service](#sources). You should see the name of the service appear in the list of Services if the URL is correct.
|
||||
|
||||

|
||||
|
||||
Once you select a service, the service may sample your selected column and identify some [suggested categories (“types”)](#reconciling-by-type) to reconcile against. Other services will suggest their available types without sampling, and some services have no types.
|
||||
|
||||
For example, if you had a list of artists represented in a gallery collection, you could reconcile their names against the Getty Research Institute’s [Union List of Artist Names (ULAN)](https://www.getty.edu/research/tools/vocabularies/ulan/). The same Getty reconciliation URL will offer you ULAN, AAT (Art and Architecture Thesaurus), and TGN (Thesaurus of Geographic Names).
|
||||
|
||||

|
||||
|
||||
Refer to the documentation specific to the reconciliation service (from the testbench, for example) to learn whether types are offered, which types are offered, and which one is most appropriate for your column. You may wish to facet your data and reconcile batches against different types if available.
|
||||
|
||||
Reconciliation can be a time-consuming process, especially with large datasets. We suggest starting with a small test batch. There is no throttle (delay between requests) to set for the reconciliation process. The amount of time will vary for each service, and based on the options you select during the process.
|
||||
|
||||
When the process is done, you will see the reconciliation data in the cells.
|
||||
If the cell was successfully matched, it displays a single dark blue link. In this case, the reconciliation is confident that the match is correct, and you should not have to check it manually.
|
||||
If there is no clear match, a few candidates are displayed, together with their reconciliation score, with light blue links. You will need to select the correct one.
|
||||
|
||||
For each matching decision you make, you have two options: match this cell only , or also use the same identifier for all other cells containing the same original string .
|
||||
|
||||
For services that offer the [“preview entities” feature](https://reconciliation-api.github.io/testbench/), you can hover your mouse over the suggestions to see more information about the candidates or matches. Each participating service (and each type) will deliver different structured data that may help you compare the candidates.
|
||||
|
||||
For example, the Getty ULAN shows an artist’s discipline, nationality, and birth and death years:
|
||||
|
||||

|
||||
|
||||
Hovering over the suggestion will also offer the two matching options as buttons.
|
||||
|
||||
For matched values (those appearing as dark blue links), the underlying cell value has not been altered - the cell is storing both the original string and the matched entity link at the same time. If you were to copy your column to a new column at this point, for example, the reconcilation data would not transfer - only the original strings.
|
||||
|
||||
For each cell, you can manually “Create new item,” which will take the cell’s current value and apply it as though it is a match. This will not become a dark blue link, because at this time there is nothing to link to: it is like a draft entity stored only in your project. You can use this feature to prepare these entries for eventual upload to an editable service such as [Wikidata](wikidata), but most services do not yet support this feature.
|
||||
|
||||
### Reconciliation facets
|
||||
|
||||
Under “Reconcile” → “Facets” you can see a number of reconciliation-specific faceting options. OpenRefine automatically creates two facets for you when you reconcile a column.
|
||||
|
||||
One is a numeric facet for “best candidate's score,” the range of reconciliation scores of only the best candidate of each cell. Each service calculates scores differently and has a different range, but higher scores always mean better matches. You can facet for higher scores in the numeric facet, and then approve them all in bulk, by using “Reconcile” → “Actions” → “Match each cell to its best candidate.”
|
||||
|
||||
There is also a “judgment” facet created, which lets you filter for the cells that haven't been matched (pick “none” in the facet). As you process each cell, its judgment changes from “none” to “matched” and it disappears from the view.
|
||||
|
||||
You can add other reconciliation facets by selecting “Reconcile” → “Facets” on your column. You can facet by:
|
||||
|
||||
* your judgments (“matched,” or “none” for unreconciled cells, or “new” for entities you've created)
|
||||
* the action you’ve performed on that cell (chosen a “single” match, or no action, as “unknown”)
|
||||
* the timestamps on the edits you’ve made so far (these appear as millisecond counts since an arbitrary point: they can be sorted alphabetically to move forward and back in time).
|
||||
|
||||
You can facet only the best candidates for each cell, based on:
|
||||
* the score (calculated based on each service's own methods)
|
||||
* the edit distance (how many single-character edits would be required to get your original value to the candidate value)
|
||||
* the word similarity (calculated on individual word matching, not including [stop words](https://en.wikipedia.org/wiki/Stop_word)).
|
||||
|
||||
You can also look at each best candidate’s:
|
||||
* type (the ones you have selected in successive reconciliation attempts, or other types returned by the service based on the cell values)
|
||||
* type match (“true” if you selected a type and it succeeded, “false” if you reconciled against no particular type, and “(no type)” if it didn’t reconcile)
|
||||
* name match (“true” if you’ve matched, “false” if you haven’t yet chosen from the candidates, or “(unreconciled)” if it didn’t reconcile).
|
||||
|
||||
These facets are useful for doing successive reconciliation attempts, against different types, and with different supplementary information.
|
||||
|
||||
### Reconciliation actions
|
||||
|
||||
You can use the “Reconcile” → “Actions” menu options to perform bulk changes, which will apply only to your current set of rows or records:
|
||||
* Match each cell to its best candidate (by highest score)
|
||||
* Create a new item for each cell (discard any suggested matches)
|
||||
* Create one new item for similar cells (a new entity will be created for each unique string)
|
||||
* Match all filtered cells to... (a specific item from the chosen service, via a search box. For [services with the “suggest entities” property](https://reconciliation-api.github.io/testbench/).)
|
||||
* Discard all reconciliation judgments (reverts back to multiple candidates per cell, including cells that may have been auto-matched in the original reconciliation process)
|
||||
* Clear reconciliation data, reverting all cells back to their original values.
|
||||
|
||||
The other options available under “Reconcile” are:
|
||||
* Copy reconciliation data... (to an existing column: if the original values in your reconciliation column are identical to those in your chosen column, the matched and/or new cells will copy over. Unmatched values will not change.)
|
||||
* [Use values as identifiers](#reconciling-with-unique-identifiers) (if you are reconciling with unique identifiers instead of by doing string searches).
|
||||
* [Add entity identifiers column](#add-entity-identifiers-column).
|
||||
|
||||
## Reconciling with unique identifiers
|
||||
|
||||
Reconciliation services use unique identifiers for their entities. For example, the 14th Dalai Lama has the VIAF ID [38242123](https://viaf.org/viaf/38242123/) and the Wikidata ID [Q17293](https://www.wikidata.org/wiki/Q37349). You can supply these identifiers directly to your chosen reconciliation service in order to pull more data, but these strings will not be “reconciled” against the external dataset.
|
||||
|
||||
Select the column with unique identifiers and apply the operation “Reconcile” → “Use values as identifiers.” This will bring up the list of reconciliation services you have already added (to add a new service, open the “Start reconciling…” window first). If you use this operation on a column of IDs, you will not have access to the usual reconciliation settings.
|
||||
|
||||
Matching identifiers does not validate them. All cells will appear as dark blue “confirmed” matches. You should check before this operation that the identifiers in the column exist on the target service.
|
||||
|
||||
You may get false positives, which you will need to hover over or click on to identify:
|
||||
|
||||

|
||||
|
||||
## Reconciling by type
|
||||
|
||||
Reconciliation services, once added to OpenRefine, may suggest types from their databases. These types will usually be whatever the service specializes in: people, events, places, buildings, tools, plants, animals, organizations, etc.
|
||||
|
||||
Reconciling against a type may be faster and more accurate, but may result in fewer matches. Some services have hierarchical types (such as “mammal” as a subtype of “animal”). When you reconcile against a more specific type, unmatched values may fall back to more broad types. Other services will not do this, so you may need to perform successive reconciliation attempts against different types. Refer to the documentation specific to the reconciliation service to learn more.
|
||||
|
||||
When you select a service from the list, OpenRefine will load some or all available types. Some services will sample the first ten rows of your column to suggest types (check the [“Suggest types” column on this table of services](https://reconciliation-api.github.io/testbench/)). You will see a service’s types in the reconciliation window:
|
||||
|
||||

|
||||
|
||||
In this example, “Person” and “Corporate Name” are potential types offered by VIAF. You can also use the “Reconcile against type:” field to enter in another type that the service offers. When you start typing, this field may search and suggest existing types. For VIAF, you could enter “/book/book” if your column contained publications.
|
||||
|
||||
Types are structured to fit their content: the Wikidata “human” type, for example, can include fields for birth and death dates, nationality, etc. The VIAF “person” type can include nationality and gender. You can use this to [include more properties](#reconciling-with-additional-columns) and find better matches.
|
||||
|
||||
If your column doesn’t fit one specific type offered, you can “Reconcile against no particular type.” This may take longer for some services.
|
||||
|
||||
We recommend working in batches and reconciling against different types, moving from specific to broad. You can create a “best candidate’s type” facet to see which types are being represented. Some candidates may return more than one type, depending on the service.
|
||||
|
||||
## Reconciling with additional columns
|
||||
|
||||
Some of your cells may be ambiguous, in the sense that a string can point to more than one entity: there are dozens of places called “Paris” and many characters, people, and pieces of culture, too. Selecting non-geographic or more localized types can help narrow that down, but if your chosen service doesn't provide a useful type, you can include more properties that make it clear whether you're looking for Paris, France.
|
||||
|
||||

|
||||
|
||||
Including supplementary information can be useful, depending on the service (such as including birthdate information about each person you are trying to reconcile). The other columns in your project will appear in the reconciliation window, with an “Include?” checkbox available on each.
|
||||
|
||||
You can fill in the “As Property” field with the type of information you are including. When you start typing, potential fields may pop up (depending on the [“suggest properties” feature](https://reconciliation-api.github.io/testbench/)), such as “birthDate” in the case of ULAN or “Geburtsdatum” in the case of Integrated Authority File (GND). Use the documentation for your chosen service to identify the fields in their terms.
|
||||
|
||||
Some services will not be able to search for the exact name of your desired “As Property” entry, but you can still manually supply the field name. Refer to the service to make sure you enter it correctly.
|
||||
|
||||

|
||||
|
||||
## Fetching more data
|
||||
|
||||
One reason to reconcile to some external service is that it allows you to pull data from that service into your OpenRefine project. There are three ways to do this:
|
||||
|
||||
* Add identifiers for your values
|
||||
* Add columns from reconciled values
|
||||
* Add column by fetching URLs
|
||||
|
||||
### Add entity identifiers column
|
||||
|
||||
Once you have selected matches for your cells, you can retrieve the unique identifiers for those cells and create a new column for these, with “Reconcile” → “Add entity identifiers column.” You will be asked to supply a column name. New items and other unmatched cells will generate null values in this column.
|
||||
|
||||
### Add columns from reconciled values
|
||||
|
||||
If the reconciliation service supports [data extension](https://reconciliation-api.github.io/testbench/), then you can augment your reconciled data with new columns using “Edit column” → “Add columns from reconciled values....”
|
||||
|
||||
For example, if you have a column of chemical elements identified by name, you can fetch categorical information about them such as their atomic number and their element symbol, as the animation shows below:
|
||||
|
||||

|
||||
|
||||
Once you have pulled reconciliation values and selected one for each cell, selecting “Add column from reconciled values...” will bring up a window to choose which information you’d like to import into a new column. The quality of the suggested properties will depend on how you have reconciled your data beforehand: reconciling against a specific type will provide you with suggested properties of that type. For example, GND suggests elements about the “people” type after you've reconciled with it, such as their parents, native languages, children, etc.
|
||||
|
||||

|
||||
|
||||
If you have left any values unreconciled in your column, you will see “<not reconciled>” in the preview. These will generate blank cells if you continue with the column addition process. This process may pull more than one property per row in your data, so you may need to switch into records mode after you've added columns.
|
||||
|
||||
### Add columns by fetching URLs
|
||||
|
||||
If the reconciliation service cannot extend data, look for a generic web API for that data source, or a structured URL that points to their dataset entities via unique IDs (such as https://viaf.org/viaf/000000). You can use the “Edit column” → “[Add column by fetching URLs](columnediting#add-column-by-fetching-urls)” operation to call this API or URL with the IDs obtained from the reconciliation process. This will require using [GREL expressions](expressions#GREL).
|
||||
|
||||
You will likely not want to pull the entire HTML content of the pages at the ends of these URLs, so look to see whether the service offers a metadata endpoint, such as JSON-formatted data. You can either use a column of IDs, or you can pull the ID from each matched cell during the fetching process.
|
||||
|
||||
For example, if you have reconciled artists to the Getty's ULAN, and [have their unique ULAN IDs as a column](#add-entity-identifiers-column), you can generate a new column of JSON-formatted data by using “Add column by fetching URLs” and entering the GREL expression `“http://vocab.getty.edu/” + value + “.json”` in the window. For this service, the unique IDs are formatted “ulan/000000” and so the generated URLs look like “http://vocab.getty.edu/ulan/000000.json”.
|
||||
|
||||
You can alternatively insert the ID directly from the matched column using a GREL expression like `“http://vocab.getty.edu/” + cell.recon.match.id + “.json”` instead.
|
||||
|
||||
Remember to set an appropriate throttle and to refer to the service documentation to ensure your compliance with their terms. See [the section about this operation](columnediting#add-column-by-fetching-urls) to learn more about common errors with this process.
|
||||
|
||||
## Keep all the suggestions made
|
||||
|
||||
If you would like to generate a list of each suggestion made, rather than only the best candidate, you can use a [GREL expression](expressions#GREL). Go to “Edit column” → “Add column based on this column.” To create a list of all the possible matches, use
|
||||
|
||||
```forEach(cell.recon.candidates,c,c.name).join(“,”)```
|
||||
|
||||
To get the unique identifiers of these matches instead, use
|
||||
|
||||
```forEach(cell.recon.candidates,c,c.id).join(“,”)```
|
||||
|
||||
This information is stored as a string without any attached reconciliation information.
|
||||
|
||||
## Writing reconciliation expressions
|
||||
|
||||
OpenRefine's GREL supplies a number of variables related specifically to reconciled values.
|
||||
For example, some of the reconciliation variables are:
|
||||
|
||||
* `cell.recon.match.id` or `cell.recon.match.name` for matched values
|
||||
* `cell.recon.best.name` or `cell.recon.best.id` for best-candidate values
|
||||
* `cell.recon.candidates` for all listed candidates of each cell
|
||||
* `cell.recon.judgment` (the values used in the “judgment” facet)
|
||||
* `cell.recon.judgmentHistory` (the values used in the “judgment action timestamp” facet)
|
||||
* `cell.recon.matched` (a “true” or “false” value)
|
||||
|
||||
You can find out more in the [reconciliaton variables](expressions#reconciliaton-variables) section.
|
||||
|
||||
## Exporting your reconciled data
|
||||
|
||||
Once you have data that is reconciled to existing entities online, you may wish to export that data to a user-editable service such as Wikidata. See the section on [uploading your edits to Wikidata](wikidata#upload-edits-to-wikidata) for more information, or the section on [exporting](exporting) to see other formats OpenRefine can produce.
|
||||
@ -1,114 +1,33 @@
|
||||
---
|
||||
|
||||
id: transforming
|
||||
|
||||
title: Transforming data
|
||||
|
||||
sidebar_label: Transforming data
|
||||
|
||||
sidebar_label: Overview
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
* Permanent “view” changes (not data changes, quite) like rearranging columns, removing columns, and renaming columns.
|
||||
OpenRefine gives you powerful ways to clean, correct, codify, and extend your data. Without ever needing to type inside a single cell, you can automatically fix typos, convert things to the right format, and add structured categories from trusted sources.
|
||||
|
||||
The following ways to improve data are organized by their appearance in the menu options in OpenRefine. You can:
|
||||
|
||||
## Edit cells
|
||||
* change the order of rows or columns
|
||||
* edit cell contents within a particular column
|
||||
* edit cell contents across all rows and columns
|
||||
* transform rows into columns, and columns into rows
|
||||
* split or join columns
|
||||
* add new columns based on existing data or through reconciliation
|
||||
* convert your rows of data into multi-row records
|
||||
|
||||
## Edit rows
|
||||
|
||||
### Overview
|
||||
Moving rows around is a permanent change to your data.
|
||||
|
||||
You can [sort your data](sortview#sort) based on the values in one column, but that change is a temporary view setting. With that setting applied, you can make that new order permanent.
|
||||
|
||||
### Transform
|
||||

|
||||
|
||||
In the project grid header, the word “Sort” will appear when a sort operation is applied. Click on it to show the dropdown menu, and select “Reorder rows permanently.” You will see the numbering of the rows change under the “All” column.
|
||||
|
||||
Reordering rows permanently will affect all rows in the dataset, not just those currently viewed through facets and filters.
|
||||
|
||||
* Transform…
|
||||
* Common transforms
|
||||
* Trim / Collapse
|
||||
* Unescape
|
||||
* Replace
|
||||
* Case
|
||||
* Data type
|
||||
* To null/empty
|
||||
|
||||
|
||||
### Fill down
|
||||
|
||||
|
||||
### Blank down
|
||||
|
||||
|
||||
### Split multi-valued cells...
|
||||
|
||||
|
||||
### Join multi-valued cells...
|
||||
|
||||
|
||||
### Cluster and edit...
|
||||
|
||||
|
||||
### Replace
|
||||
|
||||
|
||||
## Edit column
|
||||
|
||||
|
||||
### Overview
|
||||
|
||||
|
||||
### Split or Join
|
||||
|
||||
|
||||
### Add column based on this column
|
||||
|
||||
|
||||
### Add column by fetching URLs
|
||||
|
||||
|
||||
### Add columns from reconciled values
|
||||
|
||||
|
||||
### Rename or Remove
|
||||
|
||||
|
||||
### Move
|
||||
|
||||
|
||||
## Transpose
|
||||
|
||||
|
||||
### Overview
|
||||
|
||||
|
||||
### Transpose cells across columns into rows
|
||||
|
||||
|
||||
### Transpose cells in rows into columns
|
||||
|
||||
|
||||
### Columnize by key/value columns
|
||||
|
||||
|
||||
## Reconcile
|
||||
|
||||
|
||||
### Overview
|
||||
|
||||
|
||||
### Sources
|
||||
|
||||
[https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources](https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources)
|
||||
|
||||
|
||||
### Functions
|
||||
|
||||
|
||||
|
||||
* Match each cell to its best candidate
|
||||
* Create a new item for each cell
|
||||
* Create one new item for similar cells
|
||||
* Match all filtered cells
|
||||
* Discard all reconciliation judgments
|
||||
* Clear reconciliation data
|
||||
* Copy reconciliation data
|
||||
* Use values as identifiers
|
||||
You can undo this action using the [“History” sidebar](running#history-undoredo).
|
||||
230
docs/docs/manual/transposing.md
Normal file
@ -0,0 +1,230 @@
|
||||
---
|
||||
id: transposing
|
||||
title: Transposing
|
||||
sidebar_label: Transposing
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
These functions were created to solve common problems with reshaping your data: pivoting cells from a row into a column, or pivoting cells from a column into a row. You can also transpose from a repeated set of values into multiple columns.
|
||||
|
||||
## Transpose cells across columns into rows
|
||||
|
||||
Imagine personal data with addresses in this format:
|
||||
|
||||
|Name|Street|City|State/Province|Country|Postal code|
|
||||
|---|---|---|---|---|---|
|
||||
|Jacques Cousteau|23, quai de Conti|Paris||France|75270|
|
||||
|Emmy Noether|010 N Merion Avenue|Bryn Mawr|Pennsylvania|USA|19010|
|
||||
|
||||
You can transpose the address information from this format into multiple rows. Go to the “Street” column and select “Transpose” → “Transpose cells across columns into rows.” From there you can select all of the five columns, starting with “Street” and ending with “Postal code,” that correspond to address information. Once you begin, you should put your project into [records mode](exploring#rows-vs-records) to associate the subsequent rows with “Name” as the key column.
|
||||
|
||||

|
||||
|
||||
### One column
|
||||
|
||||
You can transpose the multiple address columns into a series of rows instead:
|
||||
|
||||
|Name|Address|
|
||||
|---|---|
|
||||
|Jacques Cousteau|23, quai de Conti|
|
||||
| |Paris|
|
||||
| |France|
|
||||
| |75270|
|
||||
|Emmy Noether|010 N Merion Avenue|
|
||||
||Bryn Mawr|
|
||||
||Pennsylvania|
|
||||
||USA|
|
||||
||19010|
|
||||
|
||||
You can include the column-name information in each cell by prepending it to the value, with or without a separator:
|
||||
|
||||
|Name|Address|
|
||||
|---|---|
|
||||
|Jacques Cousteau|Street: 23, quai de Conti|
|
||||
| |City: Paris|
|
||||
| |Country: France|
|
||||
| |Postal code: 75270|
|
||||
|Emmy Noether|Street: 010 N Merion Avenue|
|
||||
||City: Bryn Mawr|
|
||||
||State/Province: Pennsylvania|
|
||||
||Country: USA|
|
||||
||Postal code: 19010|
|
||||
|
||||
### Two columns
|
||||
|
||||
You can retain the column names as separate cell values, by selecting “Two new columns” and naming the key and value columns.
|
||||
|
||||
|Name|Address part|Address|
|
||||
|---|---|---|
|
||||
|Jacques Cousteau|Street|23, quai de Conti|
|
||||
| |City|Paris|
|
||||
| |Country|France|
|
||||
| |Postal code|75270|
|
||||
|Emmy Noether|Street|010 N Merion Avenue|
|
||||
||City|Bryn Mawr|
|
||||
||State/Province|Pennsylvania|
|
||||
||Country|USA|
|
||||
||Postal code|19010|
|
||||
|
||||
## Transpose cells in rows into columns
|
||||
|
||||
Imagine employee data in this format:
|
||||
|
||||
|Column|
|
||||
|---|
|
||||
|Employee: Karen Chiu|
|
||||
|Job title: Senior analyst|
|
||||
|Office: New York|
|
||||
|Employee: Joe Khoury|
|
||||
|Job title: Junior analyst|
|
||||
|Office: Beirut|
|
||||
|Employee: Samantha Martinez|
|
||||
|Job title: CTO|
|
||||
|Office: Tokyo|
|
||||
|
||||
The goal is to sort out all of the information contained in one column into separate columns, but keep it organized by the person it represents:
|
||||
|
||||
|Name |Job title |Office|
|
||||
|---|---|---|
|
||||
|Karen Chiu |Senior analyst |New York|
|
||||
|Joe Khoury |Junior analyst |Beirut|
|
||||
|Samantha Martinez |CTO |Tokyo|
|
||||
|
||||
By selecting “Transpose” → “Transpose cells in rows into columns...” a window will appear that simply asks how many rows to transpose. In this case, each employee record has three rows, so input “3” (do not subtract one for the original column). The original column will disappear and be replaced with three columns, with the name of the original column plus a number appended.
|
||||
|
||||
|Column 1 |Column 2 |Column 3|
|
||||
|---|---|---|
|
||||
|Employee: Karen Chiu |Job title: Senior analyst |Office: New York|
|
||||
|Employee: Joe Khoury |Job title: Junior analyst |Office: Beirut|
|
||||
|Employee: Samantha Martinez |Job title: CTO |Office: Tokyo|
|
||||
|
||||
From here you can use “Cell editing” → “Replace” to remove “Employee: ”, “Job title: ”, and “Office: ”, or use [GREL functions](expressions#grel) with “Edit cells” → “Transform...” to clean out the extraneous characters: `value.replace('Employee: ', '')`, etc.
|
||||
|
||||
If your dataset doesn't have a predictable number of cells per intended row, such that you cannot specify easily how many columns to create, try “Columnize by key/value columns.“
|
||||
|
||||
## Columnize by key/value columns
|
||||
|
||||
This operation can be used to reshape a dataset that contains key and value columns: the repeating strings in the key column become new column names, and the contents of the value column are moved to new columns. This operation can be found at “Transpose” → “Columnize by key/value columns.”
|
||||
|
||||

|
||||
|
||||
Consider the following example, with flowers, their colours, and their International Union for Conservation of Nature (IUCN) identifiers:
|
||||
|
||||
|Field |Data |
|
||||
|--------|----------------------|
|
||||
|Name |Galanthus nivalis |
|
||||
|Color |White |
|
||||
|IUCN ID |162168 |
|
||||
|Name |Narcissus cyclamineus |
|
||||
|Color |Yellow |
|
||||
|IUCN ID |161899 |
|
||||
|
||||
In this format, each flower species is described by multiple attributes on consecutive rows. The “Field” column contains the keys and the “Data” column contains the values. In the “Columnize by key/value columns” window you can select each of these from the available columns. It transforms the table as follows:
|
||||
|
||||
| Name | Color | IUCN ID |
|
||||
|-----------------------|----------|---------|
|
||||
| Galanthus nivalis | White | 162168 |
|
||||
| Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
### Entries with multiple values in the same column
|
||||
|
||||
If a new row would have multiple values for a given key, then these values will be grouped on consecutive rows, to form a [record structure](exploring#rows-vs-records).
|
||||
|
||||
For instance, flowers can have multiple colors:
|
||||
|
||||
| Field | Data |
|
||||
|-------------|-----------------------|
|
||||
| Name | Galanthus nivalis |
|
||||
| _Color_ | _White_ |
|
||||
| _Color_ | _Green_ |
|
||||
| IUCN ID | 162168 |
|
||||
| Name | Narcissus cyclamineus |
|
||||
| Color | Yellow |
|
||||
| IUCN ID | 161899 |
|
||||
|
||||
This table is transformed by the Columnize operation to:
|
||||
|
||||
| Name | Color | IUCN ID |
|
||||
|-----------------------|----------|---------|
|
||||
| Galanthus nivalis | White | 162168 |
|
||||
| | Green | |
|
||||
| Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
The first key encountered by the operation serves as the record key, so the “Green” value is attached to the “Galanthus nivalis” name. See the [Row order](#row-order) section for more details about the influence of row order on the results of the operation.
|
||||
|
||||
### Notes column
|
||||
|
||||
In addition to the key and value columns, you can optionally add a column for notes. This can be used to store extra metadata associated to a key/value pair.
|
||||
|
||||
Consider the following example:
|
||||
|
||||
| Field | Data | Source |
|
||||
|---------|---------------------|-----------------------|
|
||||
| Name | Galanthus nivalis | IUCN |
|
||||
| Color | White | Contributed by Martha |
|
||||
| IUCN ID | 162168 | |
|
||||
| Name | Narcissus cyclamineus | Legacy |
|
||||
| Color | Yellow | 2009 survey |
|
||||
| IUCN ID | 161899 | |
|
||||
|
||||
If the “Source” column is selected as the notes column, this table is transformed to:
|
||||
|
||||
| Name | Color | IUCN ID | Source: Name | Source: Color |
|
||||
|-----------------------|----------|---------|---------------|-----------------------|
|
||||
| Galanthus nivalis | White | 162168 | IUCN | Contributed by Martha |
|
||||
| Narcissus cyclamineus | Yellow | 161899 | Legacy | 2009 survey |
|
||||
|
||||
Notes columns can therefore be used to preserve provenance or other context about a particular key/value pair.
|
||||
|
||||
### Row order
|
||||
|
||||
The order in which the key/value pairs appear matters. The Columnize operation will use the first key it encounters as the delimiter for entries: every time it encounters this key again, it will produce a new row, and add the following key/value pairs to that row.
|
||||
|
||||
Consider for instance the following table:
|
||||
|
||||
| Field | Data |
|
||||
|----------|-----------------------|
|
||||
| _Name_ | Galanthus nivalis |
|
||||
| Color | White |
|
||||
| IUCN ID | 162168 |
|
||||
| _Name_ | Crinum variabile |
|
||||
| _Name_ | Narcissus cyclamineus |
|
||||
| Color | Yellow |
|
||||
| IUCN ID | 161899 |
|
||||
|
||||
The occurrences of the “Name” value in the “Field” column define the boundaries of the entries. Because there is no other row between the “Crinum variabile” and the “Narcissus cyclamineus” rows, the “Color” and “IUCN ID” columns for the “Crinum variabile” entry will be empty:
|
||||
|
||||
| Name | Color | IUCN ID |
|
||||
|-----------------------|----------|---------|
|
||||
| Galanthus nivalis | White | 162168 |
|
||||
| Crinum variabile | | |
|
||||
| Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
This sensitivity to order is removed if there are extra columns: in that case, the first extra column will serve as the key for the new rows.
|
||||
|
||||
### Extra columns
|
||||
|
||||
If your dataset contains extra columns, that are not being used as the key, value, or notes columns, they can be preserved by the operation. For this to work, they must have the same value in all old rows corresponding to a new row.
|
||||
|
||||
In the following example, the “Field” and “Data” columns are used as key and value columns respectively, and the “Wikidata ID” column is not selected:
|
||||
|
||||
| Field | Data | Wikidata ID |
|
||||
|---------|-----------------------|-------------|
|
||||
| Name | Galanthus nivalis | Q109995 |
|
||||
| Color | White | Q109995 |
|
||||
| IUCN ID | 162168 | Q109995 |
|
||||
| Name | Narcissus cyclamineus | Q1727024 |
|
||||
| Color | Yellow | Q1727024 |
|
||||
| IUCN ID | 161899 | Q1727024 |
|
||||
|
||||
This will be transformed to:
|
||||
|
||||
| Wikidata ID | Name | Color | IUCN ID |
|
||||
|-------------|-----------------------|----------|---------|
|
||||
| Q109995 | Galanthus nivalis | White | 162168 |
|
||||
| Q1727024 | Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
This actually changes the operation: OpenRefine no longer looks for the first key (“Name”) but simply pivots all information based on the first extra column's values. Every old row with the same value gets transposed into one new row. If you have more than one extra column, they are pivoted as well but not used as the new key.
|
||||
|
||||
You can use [“Fill down”](cellediting#fill-down) to put identical values in the extra columns if you need to.
|
||||
@ -10,9 +10,15 @@ module.exports = {
|
||||
label: 'Exploring data',
|
||||
items: ['manual/exploring', 'manual/facets', 'manual/sortview'],
|
||||
},
|
||||
'manual/transforming',
|
||||
{
|
||||
type: 'category',
|
||||
label: 'Transforming data',
|
||||
items: ['manual/transforming', 'manual/cellediting','manual/columnediting','manual/transposing'],
|
||||
},
|
||||
'manual/reconciling',
|
||||
'manual/expressions',
|
||||
'manual/wikidata',
|
||||
'manual/expressions',
|
||||
'manual/exporting',
|
||||
'manual/glossary',
|
||||
'manual/troubleshooting'
|
||||
|
||||
BIN
docs/static/img/cluster.png
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 51 KiB |
BIN
docs/static/img/columnjoin.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 27 KiB |
BIN
docs/static/img/columnreconciled.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 27 KiB |
BIN
docs/static/img/columnsplit.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 14 KiB |
BIN
docs/static/img/fetchingURLs.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 48 KiB |
BIN
docs/static/img/reconcile-ambiguous.gif
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 86 KiB |
BIN
docs/static/img/reconcile-by-type.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 20 KiB |
BIN
docs/static/img/reconcileGND.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 17 KiB |
BIN
docs/static/img/reconcileIDerror.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 29 KiB |
BIN
docs/static/img/reconcileParis.gif
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 158 KiB |
BIN
docs/static/img/reconcileelements.gif
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 238 KiB |
BIN
docs/static/img/reconcilehover.PNG
vendored
Normal file
{kind=link}
|
After 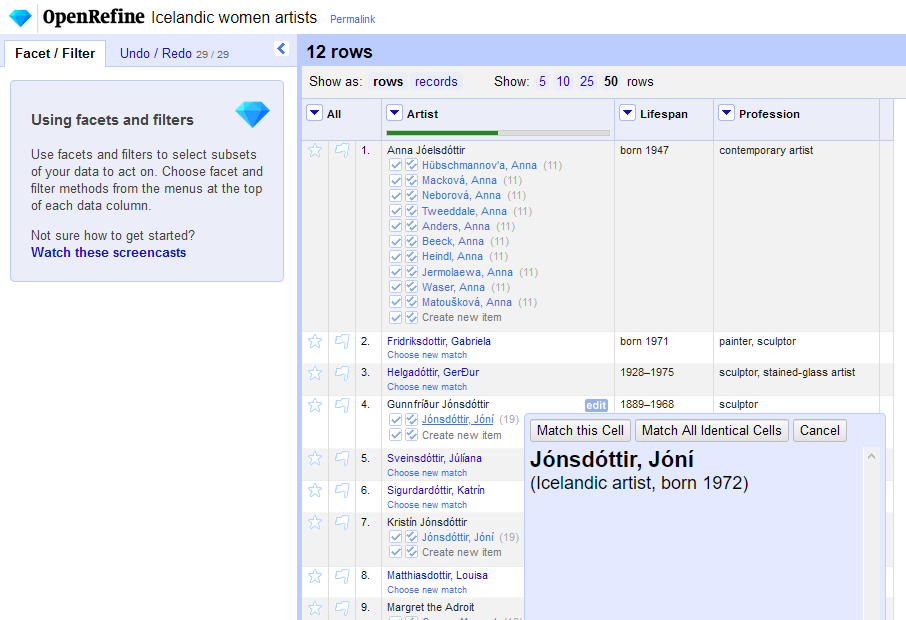
(image error) Size: 66 KiB |
BIN
docs/static/img/reconcilewindow.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 19 KiB |
BIN
docs/static/img/reconcilewindow2.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 25 KiB |
BIN
docs/static/img/sortPermanent.PNG
vendored
Normal file
{kind=link}
|
After 
(image error) Size: 22 KiB |
BIN
docs/static/img/transpose1.PNG
vendored
Normal file
{kind=link}
|
After (image error) Size: 30 KiB |
BIN
docs/static/img/transpose2.PNG
vendored
Normal file
{kind=link}
|
After (image error) Size: 13 KiB |