Compare commits
76 Commits
RANDOMSEC-
...
master
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
385080c25d | ||
|
|
ef4717415e | ||
|
|
c6b27c95b3 | ||
| ddc8e485c7 | |||
| cc0d2aefe5 | |||
|
|
7e8d4e07bd | ||
|
|
36e2438bf8 | ||
|
|
d709383df5 | ||
| 226b1d6dc9 | |||
| 09b99f022a | |||
|
|
173accd866 | ||
|
|
5a1ba3754d | ||
| a200caaf17 | |||
| 9457642206 | |||
|
|
378f0156f9 | ||
|
|
d646c6c24f | ||
|
|
4b07d105e3 | ||
|
|
4202a72988 | ||
|
|
d66b75671d | ||
|
|
d9c54afa4b | ||
|
|
7eecff0b54 | ||
|
|
3078223eb1 | ||
|
|
330873e420 | ||
|
|
238247a5d5 | ||
|
|
2a7e2e66b5 | ||
|
|
8694374775 | ||
| 098564e333 | |||
| 5ac24962c5 | |||
| f6e4a1f7e4 | |||
| b37b4153bf | |||
|
|
b633a4c51e | ||
|
|
1888dd2c9a | ||
|
|
0c7b221f3f | ||
|
|
de8925fe9a | ||
|
|
e3c124df80 | ||
|
|
b466d09c18 | ||
|
|
f4cf7fea8b | ||
|
|
b90ba1271c | ||
|
|
a6999dad38 | ||
|
|
5d020957b7 | ||
|
|
767091c4b8 | ||
|
|
cf9eb34e96 | ||
|
|
415e3e1f9d | ||
|
|
cfcdc0547b | ||
|
|
8f794f1e12 | ||
|
|
2b191b5f19 | ||
|
|
4936a15f72 | ||
|
|
e5eade040d | ||
|
|
8e476f0c7d | ||
|
|
6d46a2a5de | ||
|
|
f8461d47a9 | ||
|
|
5c9b73492e | ||
|
|
b6c99a4f02 | ||
|
|
1727ac9e01 | ||
|
|
117222cafd | ||
|
|
e30255f504 | ||
|
|
dd7ef6f600 | ||
|
|
8bba3ad255 | ||
|
|
b100058ba3 | ||
|
|
003937d4cd | ||
|
|
819139c42a | ||
|
|
b4e184c4d7 | ||
|
|
d5162ce41b | ||
|
|
3f25594788 | ||
|
|
c39ad275ff | ||
|
|
7f10c50614 | ||
|
|
14288de087 | ||
|
|
14a2e7d185 | ||
|
|
6c078fda8b | ||
|
|
5243b24a5a | ||
|
|
5ab91ec250 | ||
|
|
1c67dc4ae3 | ||
| 5416298d8a | |||
|
|
0d5201a575 | ||
|
|
455593c933 | ||
|
|
143282b656 |
1
.gitignore
vendored
1
.gitignore
vendored
@ -1 +1,2 @@
|
||||
/MUOR/.idea/*
|
||||
db.sqlite3
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
import docker
|
||||
import hashlib
|
||||
from django.conf import settings
|
||||
|
||||
|
||||
class DockerManager:
|
||||
def __init__(self):
|
||||
self.client = docker.from_env()
|
||||
self.image = 'felixlohmeier/openrefine'
|
||||
self.image = settings.DOCKER_IMAGE
|
||||
|
||||
def create_new_volume(self, username):
|
||||
# Hashing username to get volume name
|
||||
@ -26,3 +27,11 @@ class DockerManager:
|
||||
container = self.client.containers.get(container_id)
|
||||
container.stop()
|
||||
container.remove()
|
||||
|
||||
def remove_volume(self, volume_id):
|
||||
|
||||
volume = self.client.volumes.get(volume_id)
|
||||
|
||||
if volume is not None:
|
||||
volume.remove(force=True)
|
||||
|
||||
|
||||
8
MUOR/MUOR/celery.py
Normal file
8
MUOR/MUOR/celery.py
Normal file
@ -0,0 +1,8 @@
|
||||
import os
|
||||
from celery import Celery
|
||||
|
||||
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MUOR.settings')
|
||||
|
||||
app = Celery('MUOR')
|
||||
app.config_from_object('django.conf:settings', namespace='CELERY')
|
||||
app.autodiscover_tasks()
|
||||
53
MUOR/MUOR/configs/loader.html
Normal file
53
MUOR/MUOR/configs/loader.html
Normal file
@ -0,0 +1,53 @@
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<link rel="stylesheet"
|
||||
href="https://stackpath.bootstrapcdn.com/bootstrap/4.2.1/css/bootstrap.min.css"
|
||||
integrity="sha384-GJzZqFGwb1QTTN6wy59ffF1BuGJpLSa9DkKMp0DgiMDm4iYMj70gZWKYbI706tWS"
|
||||
crossorigin="anonymous">
|
||||
<meta charset="utf-8">
|
||||
<title>MultiUserOpenRefine}</title>
|
||||
</head>
|
||||
<body>
|
||||
<main>
|
||||
<div class="container">
|
||||
<div style="position: page; vertical-align: center">
|
||||
<div class="row justify-content-center">
|
||||
<div class="col-8">
|
||||
<img src="static/images/logo.png" alt="logo"
|
||||
style="padding-top: 10px; height: auto; width: 50%; display: block; margin-left: auto; margin-right: auto;">
|
||||
<h1 class="mt-2"
|
||||
style="text-align: center; padding-bottom: 10px">
|
||||
MultiUserOpenRefine</h1>
|
||||
<div style="border-radius: 25px; border: 4px solid #e0e0e0; padding: 20px; box-shadow: rgba(0, 0, 0, 0.24) 0 3px 8px;">
|
||||
<h3 style="text-align: center;">Your instance is getting
|
||||
ready. Please wait... </h3>
|
||||
<div class="d-flex justify-content-center">
|
||||
<div class="spinner-grow"
|
||||
style="width: 3rem; height: 3rem;"
|
||||
role="status">
|
||||
<span class="sr-only">Loading...</span>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<meta http-equiv="refresh"
|
||||
content="3; URL=http://randomsec.projektstudencki.pl/"/>
|
||||
</main>
|
||||
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js"
|
||||
integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo"
|
||||
crossorigin="anonymous"></script>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.6/umd/popper.min.js"
|
||||
integrity="sha384-wHAiFfRlMFy6i5SRaxvfOCifBUQy1xHdJ/yoi7FRNXMRBu5WHdZYu1hA6ZOblgut"
|
||||
crossorigin="anonymous"></script>
|
||||
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.2.1/js/bootstrap.min.js"
|
||||
integrity="sha384-B0UglyR+jN6CkvvICOB2joaf5I4l3gm9GU6Hc1og6Ls7i6U/mkkaduKaBhlAXv9k"
|
||||
crossorigin="anonymous"></script>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
|
||||
|
||||
@ -7,6 +7,7 @@ upstream django {
|
||||
server localhost:8080;
|
||||
}
|
||||
|
||||
|
||||
server {
|
||||
if ($host = randomsec.projektstudencki.pl) {
|
||||
return 301 https://$host$request_uri;
|
||||
@ -17,41 +18,43 @@ server {
|
||||
return 404;
|
||||
}
|
||||
|
||||
# configuration of the server
|
||||
server {
|
||||
# the port your site will be served on
|
||||
listen 443 ssl http2 reuseport;
|
||||
# the domain name it will serve for
|
||||
server_name randomsec.projektstudencki.pl
|
||||
charset utf-8;
|
||||
|
||||
# max upload size
|
||||
client_max_body_size 75M; # adjust to taste
|
||||
|
||||
# location /static {
|
||||
# alias /path/to/static; #TODO add path
|
||||
# expires 30d;
|
||||
# access_log off;
|
||||
# add_header Pragma public;
|
||||
# add_header Cache-Control "public";
|
||||
# }
|
||||
error_page 502 /loader.html;
|
||||
|
||||
error_page 500 502 503 504 404 /error.html;
|
||||
location = /loader.html {
|
||||
root /home/randomsec/RandomSec/MUOR/MUOR/configs;
|
||||
}
|
||||
|
||||
location = /error.html {
|
||||
add_header Content-Type text/html;
|
||||
return 200 '<meta http-equiv="refresh" content="1; URL=http://randomsec.projektstudencki.pl/" />';
|
||||
location /static/ {
|
||||
alias /home/randomsec/RandomSec/MUOR/staticfiles/;
|
||||
expires 2d;
|
||||
access_log off;
|
||||
add_header Pragma public;
|
||||
add_header Cache-Control "public";
|
||||
}
|
||||
|
||||
location /logout/ {
|
||||
proxy_pass http://django;
|
||||
}
|
||||
|
||||
# Finally, send all non-media requests to the Django server.
|
||||
location /session-refresh/ {
|
||||
proxy_pass http://django;
|
||||
}
|
||||
|
||||
location / {
|
||||
proxy_pass http://django;
|
||||
|
||||
if ($cookie_sessionid = ""){
|
||||
proxy_pass http://django; # TODO prolly change that to uwsgi_pass
|
||||
proxy_pass http://django;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
ssl_certificate /etc/letsencrypt/live/randomsec.projektstudencki.pl/fullchain.pem; # managed by Certbot
|
||||
@ -59,6 +62,5 @@ server {
|
||||
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
|
||||
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
|
||||
|
||||
|
||||
# add_header Strict-Transport-Security max-age=31536000;
|
||||
}
|
||||
@ -1,6 +1,6 @@
|
||||
|
||||
if ($cookie_sessionid = ""){
|
||||
proxy_pass http://django; # TODO prolly change that to uwsgi_pass
|
||||
proxy_pass http://django;
|
||||
}
|
||||
}
|
||||
|
||||
@ -9,6 +9,5 @@
|
||||
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
|
||||
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
|
||||
|
||||
|
||||
# add_header Strict-Transport-Security max-age=31536000;
|
||||
}
|
||||
@ -1,5 +1,3 @@
|
||||
|
||||
|
||||
map $http_upgrade $connection_upgrade {
|
||||
default upgrade;
|
||||
'' close;
|
||||
@ -9,6 +7,7 @@ upstream django {
|
||||
server localhost:8080;
|
||||
}
|
||||
|
||||
|
||||
server {
|
||||
if ($host = randomsec.projektstudencki.pl) {
|
||||
return 301 https://$host$request_uri;
|
||||
@ -19,35 +18,36 @@ server {
|
||||
return 404;
|
||||
}
|
||||
|
||||
# configuration of the server
|
||||
server {
|
||||
# the port your site will be served on
|
||||
listen 443 ssl http2 reuseport;
|
||||
# the domain name it will serve for
|
||||
server_name randomsec.projektstudencki.pl
|
||||
charset utf-8;
|
||||
|
||||
# max upload size
|
||||
client_max_body_size 75M; # adjust to taste
|
||||
|
||||
# location /static {
|
||||
# alias /path/to/static; #TODO add path
|
||||
# expires 30d;
|
||||
# access_log off;
|
||||
# add_header Pragma public;
|
||||
# add_header Cache-Control "public";
|
||||
# }
|
||||
error_page 502 /loader.html;
|
||||
|
||||
error_page 500 502 503 504 404 /error.html;
|
||||
location = /loader.html {
|
||||
root /home/randomsec/RandomSec/MUOR/MUOR/configs;
|
||||
}
|
||||
|
||||
location = /error.html {
|
||||
add_header Content-Type text/html;
|
||||
return 200 '<meta http-equiv="refresh" content="1; URL=http://randomsec.projektstudencki.pl/" />';
|
||||
location /static/ {
|
||||
alias /home/randomsec/RandomSec/MUOR/staticfiles/;
|
||||
expires 2d;
|
||||
access_log off;
|
||||
add_header Pragma public;
|
||||
add_header Cache-Control "public";
|
||||
}
|
||||
|
||||
location /logout/ {
|
||||
proxy_pass http://django;
|
||||
}
|
||||
|
||||
# Finally, send all non-media requests to the Django server.
|
||||
location /session-refresh/ {
|
||||
proxy_pass http://django;
|
||||
}
|
||||
|
||||
location / {
|
||||
proxy_pass http://django;
|
||||
|
||||
|
||||
10
MUOR/MUOR/configs/uwsgi.ini
Normal file
10
MUOR/MUOR/configs/uwsgi.ini
Normal file
@ -0,0 +1,10 @@
|
||||
[uwsgi]
|
||||
chdir=/home/randomsec/RandomSec/MUOR/
|
||||
module=MUOR.wsgi
|
||||
master=True
|
||||
pidfile=/home/randomsec/uwsgi-file/project-master.pid
|
||||
vacuum=True
|
||||
max-requests=5000
|
||||
daemonize=/home/randomsec/RandomSec/log/logs.log
|
||||
http=:8080
|
||||
|
||||
@ -25,7 +25,7 @@ SECRET_KEY = 'django-insecure-t52#vo-k9ty*$@u9bf75hrkd#^o_)gadrz9$7w%xnkb-0#y!bi
|
||||
# SECURITY WARNING: don't run with debug turned on in production!
|
||||
DEBUG = True
|
||||
|
||||
ALLOWED_HOSTS = ['django']
|
||||
ALLOWED_HOSTS = ['django', 'localhost', 'randomsec.projektstudencki.pl']
|
||||
|
||||
# Application definition
|
||||
|
||||
@ -126,7 +126,7 @@ STATICFILES_DIRS = (
|
||||
STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')
|
||||
|
||||
|
||||
LOGIN_REDIRECT_URL = 'loader'
|
||||
LOGIN_REDIRECT_URL = '/loader.html'
|
||||
LOGOUT_REDIRECT_URL = 'home'
|
||||
|
||||
# Default primary key field type
|
||||
@ -139,4 +139,18 @@ AUTH_USER_MODEL = "MUOR.Profile"
|
||||
|
||||
AVAILABLE_PORTS_RANGE = (6000, 7000)
|
||||
|
||||
DOCKER_IMAGE = 'openrefine:latest'
|
||||
|
||||
SESSION_EXPIRE_AT_BROWSER_CLOSE = True
|
||||
SESSION_COOKIE_AGE = 2 * 60
|
||||
|
||||
CELERY_BROKER_URL = 'redis+socket:///var/run/redis/redis-server.sock'
|
||||
CELERY_TIMEZONE = "Europe/Warsaw"
|
||||
CELERY_BEAT_SCHEDULE = {
|
||||
'clear_sessions': {
|
||||
'task': 'clear_sessions',
|
||||
'schedule': 20.0,
|
||||
}
|
||||
}
|
||||
X_FRAME_OPTIONS = 'ALLOW-FROM https://randomsec.projektstudencki.pl/'
|
||||
SESSION_SAVE_EVERY_REQUEST = True
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
from django.db.models.signals import post_save
|
||||
from django.db.models.signals import post_save, pre_delete
|
||||
from django.dispatch import receiver
|
||||
from .DockerManager import DockerManager
|
||||
from .NGINXConfigurator import NGINXConfigurator
|
||||
from .models import Profile, Session
|
||||
from django.contrib.auth.signals import user_logged_in, user_logged_out
|
||||
from django.conf import settings
|
||||
from django.contrib.sessions.models import Session as DjangoSession
|
||||
|
||||
|
||||
def get_sessions_data():
|
||||
@ -57,11 +58,11 @@ def profile_start_up(sender, user, request, **kwargs):
|
||||
NGINXConfigurator.refresh_config(get_sessions_data())
|
||||
|
||||
|
||||
@receiver(user_logged_out)
|
||||
def profile_logged_out(sender, user, request, **kwargs):
|
||||
@receiver(pre_delete, sender=DjangoSession)
|
||||
def close_session(sender, instance, **kwargs):
|
||||
# Obtaining container_id
|
||||
try:
|
||||
session = Session.objects.get(user=user)
|
||||
session = Session.objects.get(sessionid=instance.session_key)
|
||||
container_id = session.container_id
|
||||
|
||||
# Turn off and delete container
|
||||
@ -70,6 +71,19 @@ def profile_logged_out(sender, user, request, **kwargs):
|
||||
|
||||
# Delete session
|
||||
session.delete()
|
||||
print("Closed session!")
|
||||
except Session.DoesNotExist:
|
||||
pass
|
||||
NGINXConfigurator.refresh_config(get_sessions_data())
|
||||
|
||||
|
||||
@receiver(pre_delete, sender=Profile)
|
||||
def clean_up_volume(sender, instance, **kwargs):
|
||||
try:
|
||||
volume_id = instance.volume
|
||||
|
||||
docker_manager = DockerManager()
|
||||
docker_manager.remove_volume(volume_id)
|
||||
|
||||
except :
|
||||
pass
|
||||
|
||||
7
MUOR/MUOR/tasks.py
Normal file
7
MUOR/MUOR/tasks.py
Normal file
@ -0,0 +1,7 @@
|
||||
from celery import shared_task
|
||||
from django.core import management
|
||||
|
||||
|
||||
@shared_task(name="clear_sessions")
|
||||
def clear_sessions():
|
||||
management.call_command('clearsessions')
|
||||
@ -25,8 +25,8 @@ urlpatterns = [
|
||||
path('admin/', admin.site.urls),
|
||||
path('', include('django.contrib.auth.urls')),
|
||||
path('signup/', SignUpView.as_view(), name='signup'),
|
||||
path('loader/', TemplateView.as_view(template_name='loader.html'), name='loader'),
|
||||
path('welcome/', TemplateView.as_view(template_name='home.html'), name='home'),
|
||||
path('favicon.ico', RedirectView.as_view(url=staticfiles_storage.url('images/favicon.ico'))),
|
||||
path('', views.home, name='home')
|
||||
path('', TemplateView.as_view(template_name='home.html'), name='home'),
|
||||
path("session-refresh/", TemplateView.as_view(template_name='session_refresh.html'), name='session-refresh'),
|
||||
path('favicon.ico', RedirectView.as_view(
|
||||
url=staticfiles_storage.url('images/favicon.ico'))),
|
||||
]
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
from django.contrib.auth.forms import UserCreationForm
|
||||
from django.shortcuts import redirect
|
||||
from django.urls import reverse_lazy
|
||||
from django.views import generic
|
||||
|
||||
@ -20,9 +19,3 @@ class SignUpView(generic.CreateView):
|
||||
success_url = reverse_lazy('login')
|
||||
template_name = 'registration/signup.html'
|
||||
|
||||
|
||||
def home(request):
|
||||
# if request.user.is_authenticated:
|
||||
# logout(request)
|
||||
|
||||
return redirect("/welcome")
|
||||
|
||||
BIN
MUOR/db.sqlite3
BIN
MUOR/db.sqlite3
Binary file not shown.
@ -1,3 +1,7 @@
|
||||
Django
|
||||
django-crispy-forms
|
||||
docker
|
||||
uwsgi
|
||||
celery
|
||||
redis
|
||||
django-redis
|
||||
|
||||
@ -2,8 +2,10 @@
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.2.1/css/bootstrap.min.css"
|
||||
integrity="sha384-GJzZqFGwb1QTTN6wy59ffF1BuGJpLSa9DkKMp0DgiMDm4iYMj70gZWKYbI706tWS" crossorigin="anonymous">
|
||||
<link rel="stylesheet"
|
||||
href="https://stackpath.bootstrapcdn.com/bootstrap/4.2.1/css/bootstrap.min.css"
|
||||
integrity="sha384-GJzZqFGwb1QTTN6wy59ffF1BuGJpLSa9DkKMp0DgiMDm4iYMj70gZWKYbI706tWS"
|
||||
crossorigin="anonymous">
|
||||
<meta charset="utf-8">
|
||||
<title>{% block title %}MultiUserOpenRefine{% endblock %}</title>
|
||||
</head>
|
||||
@ -13,9 +15,12 @@
|
||||
<div style="position: page; vertical-align: center">
|
||||
<div class="row justify-content-center">
|
||||
<div class="col-8">
|
||||
<img src="../static/images/logo.png" alt="logo"
|
||||
{% load static %}
|
||||
<img src="{% static 'images/logo.png' %}" alt="logo"
|
||||
style="padding-top: 10px; height: auto; width: 50%; display: block; margin-left: auto; margin-right: auto;">
|
||||
<h1 class="mt-2" style="text-align: center; padding-bottom: 10px">MultiUserOpenRefine</h1>
|
||||
<h1 class="mt-2"
|
||||
style="text-align: center; padding-bottom: 10px">
|
||||
MultiUserOpenRefine</h1>
|
||||
<div style="border-radius: 25px; border: 4px solid #e0e0e0; padding: 20px; box-shadow: rgba(0, 0, 0, 0.24) 0 3px 8px;">
|
||||
{% block content %}
|
||||
{% endblock %}
|
||||
|
||||
@ -4,12 +4,14 @@
|
||||
{% block title %}Home{% endblock %}
|
||||
|
||||
{% block content %}
|
||||
{% if user.is_authenticated %}
|
||||
<p>Hi {{ user.username }}!</p>
|
||||
<p><a href="{% url 'logout' %}" class="btn btn-light">Log Out</a></p>
|
||||
{% else %}
|
||||
<p>You are not logged in</p>
|
||||
<p><a href="{% url 'login' %}" class="btn btn-light">Log In</a></p>
|
||||
<p><a href="{% url 'signup' %}" class="btn btn-light">Create an account</a></p>
|
||||
{% endif %}
|
||||
{% if user.is_authenticated %}
|
||||
<p>Hi {{ user.username }}!</p>
|
||||
<p><a href="/">Go to your instance</a></p>
|
||||
<p><a href="{% url 'logout' %}" class="btn btn-light">Log Out</a></p>
|
||||
{% else %}
|
||||
<p>You are not logged in</p>
|
||||
<p><a href="{% url 'login' %}" class="btn btn-light">Log In</a></p>
|
||||
<p><a href="{% url 'signup' %}" class="btn btn-light">Create an
|
||||
account</a></p>
|
||||
{% endif %}
|
||||
{% endblock %}
|
||||
@ -1,13 +0,0 @@
|
||||
<!-- templates/loader.html -->
|
||||
{% extends 'base.html' %}
|
||||
|
||||
{% block title %}Loader{% endblock %}
|
||||
|
||||
{% block content %}
|
||||
<h3 style="text-align: center;">Your instance is getting ready. Please wait... </h3>
|
||||
<div class="d-flex justify-content-center">
|
||||
<div class="spinner-grow" style="width: 3rem; height: 3rem;" role="status">
|
||||
<span class="sr-only">Loading...</span>
|
||||
</div>
|
||||
</div>
|
||||
{% endblock %}
|
||||
@ -4,10 +4,13 @@
|
||||
{% block title %}Login{% endblock %}
|
||||
|
||||
{% block content %}
|
||||
<h2>Log In</h2>
|
||||
<form method="post">
|
||||
{% csrf_token %}
|
||||
{{ form.as_p }}
|
||||
<button class="btn btn-light" type="submit">Log In</button>
|
||||
</form>
|
||||
<h2>Log In</h2>
|
||||
<form method="post">
|
||||
{% csrf_token %}
|
||||
{{ form.as_p }}
|
||||
<button class="btn btn-light" type="submit">Log In</button>
|
||||
<p></p>
|
||||
<span style="white-space: nowrap">New to MultiUserOpenRefine?</span>
|
||||
<a href="{% url 'signup' %}">Create an account.</a>
|
||||
</form>
|
||||
{% endblock %}
|
||||
@ -4,10 +4,13 @@
|
||||
{% block title %}Sign Up{% endblock %}
|
||||
|
||||
{% block content %}
|
||||
<h2>Sign Up</h2>
|
||||
<form method="post">
|
||||
{% csrf_token %}
|
||||
{{ form.as_p }}
|
||||
<button class="btn btn-light" type="submit">Sign Up</button>
|
||||
</form>
|
||||
<h2>Sign Up</h2>
|
||||
<form method="post">
|
||||
{% csrf_token %}
|
||||
{{ form.as_p }}
|
||||
<button class="btn btn-light" type="submit">Sign Up</button>
|
||||
<p></p>
|
||||
<span style="white-space: nowrap">Already have an account?</span>
|
||||
<a href="{% url 'login' %}">Back to login.</a>
|
||||
</form>
|
||||
{% endblock %}
|
||||
9
MUOR/templates/session_refresh.html
Normal file
9
MUOR/templates/session_refresh.html
Normal file
@ -0,0 +1,9 @@
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta http-equiv="refresh" content="30; URL=."/>
|
||||
<title>session_refresh</title>
|
||||
</head>
|
||||
<body>
|
||||
</body>
|
||||
</html>
|
||||
22
OpenRefine/.gitattributes
vendored
22
OpenRefine/.gitattributes
vendored
@ -1,22 +0,0 @@
|
||||
# Auto detect text files and perform LF normalization
|
||||
* text=off
|
||||
|
||||
# Custom for Visual Studio
|
||||
*.cs diff=csharp
|
||||
*.sln merge=union
|
||||
*.csproj merge=union
|
||||
*.vbproj merge=union
|
||||
*.fsproj merge=union
|
||||
*.dbproj merge=union
|
||||
|
||||
# Standard to msysgit
|
||||
*.doc diff=astextplain
|
||||
*.DOC diff=astextplain
|
||||
*.docx diff=astextplain
|
||||
*.DOCX diff=astextplain
|
||||
*.dot diff=astextplain
|
||||
*.DOT diff=astextplain
|
||||
*.pdf diff=astextplain
|
||||
*.PDF diff=astextplain
|
||||
*.rtf diff=astextplain
|
||||
*.RTF diff=astextplain
|
||||
1
OpenRefine/.github/FUNDING.yml
vendored
1
OpenRefine/.github/FUNDING.yml
vendored
@ -1 +0,0 @@
|
||||
github: OpenRefine
|
||||
40
OpenRefine/.github/ISSUE_TEMPLATE/bug_report.md
vendored
40
OpenRefine/.github/ISSUE_TEMPLATE/bug_report.md
vendored
@ -1,40 +0,0 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Create a report to help us improve OpenRefine
|
||||
title: ''
|
||||
labels: bug, to be reviewed
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
<!-- Describe the bug - Please add a clear and concise description of the bug above this line. You can delete this line if you want. It will be hidden in the final bug report -->
|
||||
|
||||
### To Reproduce
|
||||
Steps to reproduce the behavior:
|
||||
1. First, do ...
|
||||
2. Then, ...
|
||||
3. Finally, ...
|
||||
|
||||
|
||||
|
||||
### Current Results
|
||||
<!-- What results occurred or were shown. -->
|
||||
|
||||
### Expected Behavior
|
||||
<!-- A clear and concise description of what you expected to happen or to show. -->
|
||||
|
||||
### Screenshots
|
||||
<!-- If applicable, add screenshots to help explain your problem. -->
|
||||
|
||||
### Versions<!-- (please complete the following information)-->
|
||||
- Operating System: <!-- e.g. iOS, Windows 10, Linux, Ubuntu 18.04 -->
|
||||
- Browser Version: <!-- e.g. Chrome 19, Firefox 61, Safari, NOTE: OpenRefine does not support IE but works OK in most cases -->
|
||||
- JRE or JDK Version: <!-- output of "java -version" e.g. JRE 1.8.0_181 -->
|
||||
- OpenRefine: <!-- e.g. OpenRefine 3.0 Beta] -->
|
||||
|
||||
### Datasets
|
||||
<!-- If you are allowed and are OK with making your data public, it would be awesome if you can include or attach the data causing the issue or a URL pointing to where the data is.
|
||||
If you are concerned about keeping your data private, ping us on our [mailing list](https://groups.google.com/forum/#!forum/openrefine) -->
|
||||
|
||||
### Additional context
|
||||
<!-- Add any other context about the problem here. -->
|
||||
8
OpenRefine/.github/ISSUE_TEMPLATE/config.yml
vendored
8
OpenRefine/.github/ISSUE_TEMPLATE/config.yml
vendored
@ -1,8 +0,0 @@
|
||||
blank_issues_enabled: false
|
||||
contact_links:
|
||||
- name: Ask a question (mailing list)
|
||||
url: https://groups.google.com/d/forum/openrefine
|
||||
about: Please ask and answer questions here.
|
||||
- name: Gitter chat
|
||||
url: https://gitter.im/OpenRefine/OpenRefine
|
||||
about: General and developer discussions
|
||||
@ -1,19 +0,0 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for OpenRefine
|
||||
title: ''
|
||||
labels: enhancement, to be reviewed
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
<!-- Please provide a clear and concise description of your problem or unsatisfied needs. Ex. I'm always frustrated when [...] or, It would be easier if OpenRefine did [...]. This comment can be deleted, if desired, but it will be hidden in your final submission. Please make sure that your new text is outside the enclosing angle brackets. -->
|
||||
|
||||
### Proposed solution
|
||||
<!-- If you have a proposal for how this need could be met, please provide a clear and concise description of what you want to happen. -->
|
||||
|
||||
### Alternatives considered
|
||||
<!-- If there alternative solutions that you have considered or think should be considered, please list them here -->
|
||||
|
||||
### Additional context
|
||||
<!-- Add any other context or screenshots about the feature request here. -->
|
||||
5
OpenRefine/.github/SUPPORT.md
vendored
5
OpenRefine/.github/SUPPORT.md
vendored
@ -1,5 +0,0 @@
|
||||
If you are having trouble with OpenRefine we suggest the following steps:
|
||||
|
||||
1. Read through our [FAQ (frequently Asked Questions)](https://github.com/OpenRefine/OpenRefine/wiki/FAQ)
|
||||
2. Search for similar issues in our community email list archives: http://groups.google.com/group/openrefine/
|
||||
3. Send an email to our community mailing list: openrefine@googlegroups.com
|
||||
3
OpenRefine/.github/autolabeler.yml
vendored
3
OpenRefine/.github/autolabeler.yml
vendored
@ -1,3 +0,0 @@
|
||||
documentation: ["/docs"]
|
||||
"current docs": ["/docs/docs"]
|
||||
"historical docs": ["/docs/versioned_docs"]
|
||||
31
OpenRefine/.github/dependabot.yml
vendored
31
OpenRefine/.github/dependabot.yml
vendored
@ -1,31 +0,0 @@
|
||||
# Documentation for all configuration options:
|
||||
# https://help.github.com/github/administering-a-repository/configuration-options-for-dependency-updates
|
||||
|
||||
version: 2
|
||||
updates:
|
||||
# For openrefine java deps
|
||||
- package-ecosystem: maven
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: daily
|
||||
open-pull-requests-limit: 10
|
||||
ignore:
|
||||
- dependency-name: com.thoughtworks.xstream:xstream
|
||||
versions:
|
||||
- "> 1.4.12"
|
||||
- "< 2"
|
||||
# For documentation website
|
||||
- package-ecosystem: "npm" # For Yarn
|
||||
directory: "docs/"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
# For github actions
|
||||
- package-ecosystem: "github-actions"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
# For cypress test_suite
|
||||
- package-ecosystem: "npm"
|
||||
directory: "main/tests/cypress"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
6
OpenRefine/.github/pull_request_template.md
vendored
6
OpenRefine/.github/pull_request_template.md
vendored
@ -1,6 +0,0 @@
|
||||
Fixes #{issue number here}
|
||||
|
||||
Changes proposed in this pull request:
|
||||
-
|
||||
-
|
||||
-
|
||||
26
OpenRefine/.github/workflows/label_transfer.yml
vendored
26
OpenRefine/.github/workflows/label_transfer.yml
vendored
@ -1,26 +0,0 @@
|
||||
|
||||
name: Copy labels from issue to pull request
|
||||
|
||||
on:
|
||||
pull_request_target:
|
||||
types: [opened, edited]
|
||||
|
||||
jobs:
|
||||
transfer_tags:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip setuptools
|
||||
pip install -r .github/workflows/label_transfer/requirements.txt
|
||||
pip freeze
|
||||
- name: Run Python label transfer script
|
||||
run: python .github/workflows/label_transfer/script.py ${{ github.event.number }}
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
GITHUB_REPO: ${{ github.repository }}
|
||||
@ -1,2 +0,0 @@
|
||||
requests
|
||||
lxml
|
||||
@ -1,76 +0,0 @@
|
||||
import requests
|
||||
import os
|
||||
from lxml import html
|
||||
import sys
|
||||
import json
|
||||
|
||||
# Config
|
||||
|
||||
# list of labels that should not be transferred to PRs
|
||||
do_not_transfer = [
|
||||
'good first issue',
|
||||
'good second issue',
|
||||
'imported from old code repo',
|
||||
'help wanted',
|
||||
'duplicate',
|
||||
'invalid',
|
||||
'question',
|
||||
'to be reviewed',
|
||||
]
|
||||
|
||||
# Internal
|
||||
|
||||
repo = os.environ.get('GITHUB_REPO')
|
||||
github_token = os.environ.get('GITHUB_TOKEN')
|
||||
|
||||
headers = {
|
||||
'Accept': 'application/vnd.github.v3+json',
|
||||
}
|
||||
|
||||
if github_token:
|
||||
headers['Authorization'] = 'Bearer '+github_token
|
||||
|
||||
def get_linked_issues(pr_number):
|
||||
"""
|
||||
Given a PR number, extract all the linked issue numbers from it.
|
||||
Sadly this is not supported by the API yet, so we just scrape the web UI.
|
||||
"""
|
||||
url = f'https://github.com/{repo}/pull/{pr_number}'
|
||||
page = requests.get(url)
|
||||
page.raise_for_status()
|
||||
parsed = html.document_fromstring(page.text)
|
||||
matches = parsed.xpath('//form/div[@class="css-truncate my-1"]/a')
|
||||
for match in matches:
|
||||
yield int(match.attrib['href'].split('/')[-1])
|
||||
|
||||
def get_issue_labels(issue_number):
|
||||
"""
|
||||
Returns all the labels in a given issue / PR
|
||||
"""
|
||||
url = f'https://api.github.com/repos/{repo}/issues/{issue_number}/labels'
|
||||
response = requests.get(url, headers=headers)
|
||||
response.raise_for_status()
|
||||
return [ tag['name'] for tag in response.json() ]
|
||||
|
||||
def transfer_issue_labels(pr_number):
|
||||
"""
|
||||
Transfers labels from all the linked issues to the PR
|
||||
"""
|
||||
linked_issues = get_linked_issues(pr_number)
|
||||
all_labels = [ label for issue in linked_issues for label in get_issue_labels(issue) ]
|
||||
to_transfer = [ label for label in all_labels if label not in do_not_transfer ]
|
||||
current_labels = get_issue_labels(pr_number)
|
||||
missing_labels = [ label for label in to_transfer if label not in current_labels ]
|
||||
if not missing_labels:
|
||||
return
|
||||
new_labels = current_labels + missing_labels
|
||||
url = f'https://api.github.com/repos/{repo}/issues/{pr_number}/labels'
|
||||
print(f'adding {missing_labels} to PR #{pr_number}')
|
||||
if not github_token:
|
||||
print('no GITHUB_TOKEN, skipping')
|
||||
else:
|
||||
resp = requests.put(url, headers=headers, data=json.dumps({'labels':new_labels}))
|
||||
resp.raise_for_status()
|
||||
|
||||
if __name__ == '__main__':
|
||||
transfer_issue_labels(sys.argv[1])
|
||||
166
OpenRefine/.github/workflows/pull_request.yml
vendored
166
OpenRefine/.github/workflows/pull_request.yml
vendored
@ -1,166 +0,0 @@
|
||||
name: Continuous Integration
|
||||
|
||||
on:
|
||||
pull_request_target:
|
||||
paths-ignore:
|
||||
- 'docs/**'
|
||||
branches:
|
||||
- master
|
||||
- '4.0'
|
||||
|
||||
permissions: read-all
|
||||
|
||||
jobs:
|
||||
server_tests:
|
||||
strategy:
|
||||
matrix:
|
||||
java: [ 11, 14 ]
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
services:
|
||||
postgres:
|
||||
image: postgres
|
||||
ports:
|
||||
- 5432
|
||||
env:
|
||||
POSTGRES_USER: postgres
|
||||
POSTGRES_PASSWORD: 'postgres'
|
||||
POSTGRES_DB: test_db
|
||||
options: >-
|
||||
--health-cmd pg_isready
|
||||
--health-interval 10s
|
||||
--health-timeout 5s
|
||||
--health-retries 5
|
||||
mysql:
|
||||
image: mysql:8
|
||||
ports:
|
||||
- 3306
|
||||
env:
|
||||
MYSQL_ROOT_PASSWORD: root
|
||||
options: >-
|
||||
--health-cmd "mysqladmin ping"
|
||||
--health-interval 5s
|
||||
--health-timeout 2s
|
||||
--health-retries 3
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
|
||||
- name: Restore dependency cache
|
||||
uses: actions/cache@v2.1.7
|
||||
with:
|
||||
path: ~/.m2/repository
|
||||
key: ${{ runner.os }}-maven-${{ hashFiles('**/pom.xml') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-maven-
|
||||
|
||||
- name: Set up Java ${{ matrix.java }}
|
||||
uses: actions/setup-java@v2
|
||||
with:
|
||||
distribution: 'adopt'
|
||||
java-version: ${{ matrix.java }}
|
||||
|
||||
- name: Configure connections to databases
|
||||
id: configure_db_connections
|
||||
run: cat extensions/database/tests/conf/github_actions_tests.xml | sed -e "s/MYSQL_PORT/${{ job.services.mysql.ports[3306] }}/g" | sed -e "s/POSTGRES_PORT/${{ job.services.postgres.ports[5432] }}/g" > extensions/database/tests/conf/tests.xml
|
||||
|
||||
- name: Populate databases with test data
|
||||
id: populate_databases_with_test_data
|
||||
run: |
|
||||
mysql -u root -h 127.0.0.1 -P ${{ job.services.mysql.ports[3306] }} -proot -e 'CREATE DATABASE test_db;'
|
||||
mysql -u root -h 127.0.0.1 -P ${{ job.services.mysql.ports[3306] }} -proot < extensions/database/tests/conf/test-mysql.sql
|
||||
psql -U postgres test_db -h 127.0.0.1 -p ${{ job.services.postgres.ports[5432] }} < extensions/database/tests/conf/test-pgsql.sql
|
||||
env:
|
||||
PGPASSWORD: postgres
|
||||
|
||||
- name: Build and test with Maven
|
||||
run: mvn jacoco:prepare-agent test
|
||||
|
||||
- name: Submit test coverage to Coveralls
|
||||
run: |
|
||||
mvn prepare-package -DskipTests=true
|
||||
mvn jacoco:report coveralls:report -DrepoToken=${{ secrets.COVERALLS_TOKEN }} -DpullRequest=${{ github.event.number }}
|
||||
|
||||
prepare_ui_test_matrix:
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||
steps:
|
||||
- uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
- name: Setup Node
|
||||
uses: actions/setup-node@v2
|
||||
with:
|
||||
node-version: '12'
|
||||
- id: set-matrix
|
||||
run: npm install --save glob && node main/tests/cypress/build-test-matrix.js
|
||||
env:
|
||||
browsers: chrome
|
||||
ui_test:
|
||||
needs: prepare_ui_test_matrix
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix: ${{fromJSON(needs.prepare_ui_test_matrix.outputs.matrix)}}
|
||||
steps:
|
||||
- uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
|
||||
- name: Restore dependency cache
|
||||
uses: actions/cache@v2.1.7
|
||||
with:
|
||||
path: ~/.m2/repository
|
||||
key: ${{ runner.os }}-maven-${{ hashFiles('**/pom.xml') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-maven-
|
||||
|
||||
- name: Set up Java 11
|
||||
uses: actions/setup-java@v2
|
||||
with:
|
||||
distribution: 'adopt'
|
||||
java-version: 11
|
||||
|
||||
- name: Build OpenRefine
|
||||
run: ./refine build
|
||||
|
||||
- name: Setup Node
|
||||
uses: actions/setup-node@v2
|
||||
with:
|
||||
node-version: '12'
|
||||
|
||||
- name: Restore Tests dependency cache
|
||||
uses: actions/cache@v2.1.7
|
||||
with:
|
||||
path: |
|
||||
~/cache
|
||||
~/.cache
|
||||
**/node_modules
|
||||
!~/cache/exclude
|
||||
key: ${{ runner.os }}-modules-${{ hashFiles('**/yarn.lock') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-yarn
|
||||
|
||||
- name: Install test dependencies
|
||||
run: |
|
||||
cd ./main/tests/cypress
|
||||
npm i -g yarn
|
||||
yarn install
|
||||
|
||||
- name: Test with Cypress on ${{ matrix.browser }}
|
||||
run: |
|
||||
echo REFINE_MIN_MEMORY=1400M >> ./refine.ini
|
||||
echo REFINE_MEMORY=4096M >> ./refine.ini
|
||||
./refine ui_tests
|
||||
env:
|
||||
CYPRESS_BROWSER: ${{ matrix.browser }}
|
||||
CYPRESS_RECORD_KEY: ${{ secrets.CYPRESS_RECORD_KEY }}
|
||||
CYPRESS_PROJECT_ID: ${{ secrets.CYPRESS_PROJECT_ID }}
|
||||
CYPRESS_CI_BUILD_ID: '${{ github.run_id }}'
|
||||
CYPRESS_SPECS: ${{ matrix.specs }}
|
||||
177
OpenRefine/.github/workflows/snapshot_release.yml
vendored
177
OpenRefine/.github/workflows/snapshot_release.yml
vendored
@ -1,177 +0,0 @@
|
||||
name: Snapshot release
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- 'master'
|
||||
- '4.0'
|
||||
paths-ignore:
|
||||
- 'docs/**'
|
||||
|
||||
jobs:
|
||||
prepare_ui_test_matrix:
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||
steps:
|
||||
- uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
- name: Setup Node
|
||||
uses: actions/setup-node@v2
|
||||
with:
|
||||
node-version: '12'
|
||||
- id: set-matrix
|
||||
run: npm install --save glob && node main/tests/cypress/build-test-matrix.js
|
||||
env:
|
||||
browsers: chrome
|
||||
ui_test:
|
||||
needs: prepare_ui_test_matrix
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix: ${{fromJSON(needs.prepare_ui_test_matrix.outputs.matrix)}}
|
||||
steps:
|
||||
- uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
repository: ${{ github.event.pull_request.head.repo.full_name }}
|
||||
|
||||
- name: Restore dependency cache
|
||||
uses: actions/cache@v2.1.7
|
||||
with:
|
||||
path: ~/.m2/repository
|
||||
key: ${{ runner.os }}-maven-${{ hashFiles('**/pom.xml') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-maven-
|
||||
|
||||
- name: Set up Java 11
|
||||
uses: actions/setup-java@v2
|
||||
with:
|
||||
distribution: 'adopt'
|
||||
java-version: 11
|
||||
|
||||
- name: Build OpenRefine
|
||||
run: ./refine build
|
||||
|
||||
- name: Setup Node
|
||||
uses: actions/setup-node@v2
|
||||
with:
|
||||
node-version: '12'
|
||||
|
||||
- name: Restore Tests dependency cache
|
||||
uses: actions/cache@v2.1.7
|
||||
with:
|
||||
path: |
|
||||
~/cache
|
||||
~/.cache
|
||||
**/node_modules
|
||||
!~/cache/exclude
|
||||
key: ${{ runner.os }}-modules-${{ hashFiles('**/yarn.lock') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-yarn
|
||||
|
||||
- name: Install test dependencies
|
||||
run: |
|
||||
cd ./main/tests/cypress
|
||||
npm i -g yarn
|
||||
yarn install
|
||||
|
||||
- name: Test with Cypress on ${{ matrix.browser }}
|
||||
run: |
|
||||
echo REFINE_MIN_MEMORY=1400M >> ./refine.ini
|
||||
echo REFINE_MEMORY=4096M >> ./refine.ini
|
||||
./refine ui_tests
|
||||
env:
|
||||
CYPRESS_BROWSER: ${{ matrix.browser }}
|
||||
CYPRESS_RECORD_KEY: ${{ secrets.CYPRESS_RECORD_KEY }}
|
||||
CYPRESS_PROJECT_ID: ${{ secrets.CYPRESS_PROJECT_ID }}
|
||||
CYPRESS_CI_BUILD_ID: '${{ github.run_id }}'
|
||||
CYPRESS_SPECS: ${{ matrix.specs }}
|
||||
|
||||
|
||||
build:
|
||||
|
||||
services:
|
||||
postgres:
|
||||
image: postgres
|
||||
ports:
|
||||
- 5432
|
||||
env:
|
||||
POSTGRES_USER: postgres
|
||||
POSTGRES_PASSWORD: 'postgres'
|
||||
POSTGRES_DB: test_db
|
||||
options: >-
|
||||
--health-cmd pg_isready
|
||||
--health-interval 10s
|
||||
--health-timeout 5s
|
||||
--health-retries 5
|
||||
mysql:
|
||||
image: mysql:8
|
||||
ports:
|
||||
- 3306
|
||||
env:
|
||||
MYSQL_ROOT_PASSWORD: root
|
||||
options: >-
|
||||
--health-cmd "mysqladmin ping"
|
||||
--health-interval 5s
|
||||
--health-timeout 2s
|
||||
--health-retries 3
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
fetch-depth: 0 # This is wasteful, but needed for git describe
|
||||
|
||||
- name: Restore dependency cache
|
||||
uses: actions/cache@v2.1.7
|
||||
with:
|
||||
path: ~/.m2/repository
|
||||
key: ${{ runner.os }}-maven-${{ hashFiles('**/pom.xml') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-maven-
|
||||
|
||||
- name: Set up Java 11
|
||||
uses: actions/setup-java@v2
|
||||
with:
|
||||
distribution: 'adopt'
|
||||
java-version: 11
|
||||
server-id: ossrh
|
||||
server-username: OSSRH_USER
|
||||
server-password: OSSRH_PASS
|
||||
|
||||
- name: Install genisoimage and jq
|
||||
run: sudo apt-get install genisoimage jq
|
||||
|
||||
- name: Configure connections to databases
|
||||
id: configure_db_connections
|
||||
run: cat extensions/database/tests/conf/github_actions_tests.xml | sed -e "s/MYSQL_PORT/${{ job.services.mysql.ports[3306] }}/g" | sed -e "s/POSTGRES_PORT/${{ job.services.postgres.ports[5432] }}/g" > extensions/database/tests/conf/tests.xml
|
||||
|
||||
- name: Populate databases with test data
|
||||
id: populate_databases_with_test_data
|
||||
run: |
|
||||
mysql -u root -h 127.0.0.1 -P ${{ job.services.mysql.ports[3306] }} -proot -e 'CREATE DATABASE test_db;'
|
||||
mysql -u root -h 127.0.0.1 -P ${{ job.services.mysql.ports[3306] }} -proot < extensions/database/tests/conf/test-mysql.sql
|
||||
psql -U postgres test_db -h 127.0.0.1 -p ${{ job.services.postgres.ports[5432] }} < extensions/database/tests/conf/test-pgsql.sql
|
||||
env:
|
||||
PGPASSWORD: postgres
|
||||
|
||||
- name: Build and test with Maven
|
||||
run: mvn jacoco:prepare-agent test
|
||||
|
||||
- name: Submit test coverage to Coveralls
|
||||
run: |
|
||||
mvn prepare-package -DskipTests=true
|
||||
mvn jacoco:report coveralls:report -DrepoToken=${{ secrets.COVERALLS_TOKEN }} -DpullRequest=${{ github.event.number }} -DserviceName="GitHub Actions" -DserviceBuildNumber=${{ env.GITHUB_RUN_ID }} -Dbranch=master
|
||||
|
||||
- name: Generate dist files
|
||||
run: mvn package -DskipTests=true
|
||||
|
||||
- name: Upload snapshot releases to OSSRH
|
||||
run: mvn deploy -DskipTests=true
|
||||
env:
|
||||
OSSRH_USER: ${{ secrets.OSSRH_USER }}
|
||||
OSSRH_PASS: ${{ secrets.OSSRH_PASS }}
|
||||
|
||||
72
OpenRefine/.gitignore
vendored
72
OpenRefine/.gitignore
vendored
@ -1,72 +0,0 @@
|
||||
.idea/
|
||||
*.log
|
||||
logs
|
||||
*~
|
||||
\#*#
|
||||
.*.swp
|
||||
*.DS_Store
|
||||
*.class
|
||||
*.patch
|
||||
.com.apple.timemachine.supported
|
||||
.import-temp/
|
||||
build/
|
||||
dist/
|
||||
server/classes/
|
||||
main/webapp/WEB-INF/classes/
|
||||
main/tests/server/classes/
|
||||
main/test-output/
|
||||
appengine/classes/
|
||||
tools/
|
||||
broker/appengine/module/MOD-INF/classes/
|
||||
broker/core/module/MOD-INF/classes/
|
||||
broker/core/WEB-INF/lib/
|
||||
broker/core/data/
|
||||
broker/core/test-output/
|
||||
tmp/
|
||||
/test-output
|
||||
test-out/
|
||||
/bin
|
||||
open-refine.log
|
||||
.vscode
|
||||
.metadata # Eclipse plugins specific
|
||||
|
||||
# Locally stored "Eclipse launch configurations"
|
||||
*.launch
|
||||
|
||||
.idea
|
||||
*.iml
|
||||
|
||||
main/target/
|
||||
main/webapp/WEB-INF/lib/
|
||||
server/target/
|
||||
extensions/*/target/
|
||||
extensions/*/module/MOD-INF/classes/
|
||||
extensions/*/module/MOD-INF/lib/
|
||||
extensions/target
|
||||
target/
|
||||
**/test-output/*
|
||||
*.versionsBackup
|
||||
|
||||
# Ignore classpath as it is automatically generated by Maven integrations in IDEs
|
||||
*.classpath
|
||||
*.project
|
||||
*.settings
|
||||
|
||||
# Ignore Apache Maven default download path
|
||||
apache-maven-*/
|
||||
apache-maven-*-bin.tar.gz
|
||||
|
||||
# Ignore refine-dev.ini
|
||||
refine-dev.ini
|
||||
|
||||
# Java annotation processor (APT)
|
||||
.factorypath
|
||||
|
||||
# Code Recommenders
|
||||
.recommenders/
|
||||
|
||||
# STS (Spring Tool Suite)
|
||||
.springBeans
|
||||
|
||||
# Ignore Node modules that might inadvertently install at current path instead of user or configured env var NODE_PATH
|
||||
node_modules/
|
||||
@ -1,78 +0,0 @@
|
||||
This file lists the contributors to OpenRefine.
|
||||
|
||||
EMERITUS CREATORS
|
||||
---------------------
|
||||
No longer active but honored for bringing OpenRefine to life.
|
||||
- David Huynh
|
||||
- Stefano Mazzocchi
|
||||
|
||||
EMERITUS CONTRIBUTORS
|
||||
---------------------
|
||||
No longer active but honored here for their previous contributions
|
||||
|
||||
- Vishal Talwar
|
||||
- Jeff Fry
|
||||
- Will Moffat
|
||||
- James Home
|
||||
- Heather Campbell
|
||||
|
||||
CURRENT CONTRIBUTORS
|
||||
--------------------
|
||||
|
||||
See up to date list at https://github.com/OpenRefine/OpenRefine/graphs/contributors
|
||||
|
||||
- Iain Sproat
|
||||
- Tom Morris
|
||||
- Thad Guidry
|
||||
- Martin Magdinier
|
||||
- Paul Makepeace
|
||||
- Tomaž Šolc
|
||||
- Gabriel Sjoberg
|
||||
- Rod Salazar
|
||||
- pxb
|
||||
- Qi
|
||||
- Antonin Delpeuch
|
||||
- Owen Stephens
|
||||
- Ettore Rizza
|
||||
- Fabio Tacchelli
|
||||
- noamoss
|
||||
- ROMitat
|
||||
- Jesus M. Castagnetto
|
||||
- Pablo Moyano
|
||||
- David Leoni
|
||||
- Cora Johnson-Roberson
|
||||
- Pei Long Hui
|
||||
- Rudy Alvarez
|
||||
- Mateja Verlic Bruncic
|
||||
- nestorjal
|
||||
- Alexey Medvetsky
|
||||
- Remi Rampin
|
||||
- lispc
|
||||
- Bob Harper
|
||||
- Felix Lohmeier
|
||||
- Shixiong Zhu
|
||||
- Ankit Sardesai
|
||||
- Scott Wiedemann
|
||||
- Ryo Yamazaki
|
||||
- Ralf Claussnitzer
|
||||
- Charles Pritchard
|
||||
- Maxim Galushka
|
||||
- Evelyn Mitchell
|
||||
- Andreas Kohn
|
||||
- Honza
|
||||
- Ram Ezrach
|
||||
- Daniel Berthereau
|
||||
- Gideon Thomas
|
||||
- José Vitor Hisse
|
||||
- Vitor Baptista
|
||||
- Joe Wicentowski
|
||||
- mpc9000
|
||||
- Dan Michael O.
|
||||
- Adi Eyal
|
||||
- Shrubhra Sharma
|
||||
- Fadi Maali
|
||||
- Aubrey Mcfato
|
||||
- Matthias Findeisen
|
||||
- Mathieu Saby
|
||||
- Allan Nordhøy
|
||||
- Tony Opara
|
||||
@ -1,284 +0,0 @@
|
||||
2.6 Release (TBD) - First release as OpenRefine - Maintenance release
|
||||
|
||||
Features:
|
||||
|
||||
- Issue 144: Use subdirectory for archives (tar, zip)
|
||||
- Issue 467: Provide feedback to user on JVM heap memory usage
|
||||
- Issue 524: Shorten name of anonymous JSON nodes in column names
|
||||
|
||||
Bugs fixed:
|
||||
|
||||
- Issue 154: Can't import RDF/XML Data
|
||||
- Issue 226: Load into freebase: date objects are not converted into proper freebase dates
|
||||
- Issue 361: Headless operation on OS X leaves Dock icon bouncing
|
||||
- Issue 390: Latest POI fixes some import issues
|
||||
- Issue 432: cross() failing
|
||||
- Issue 436: Google refine don't start on debian squeeze
|
||||
- Issue 490: Unable to guess filetype is CSV when importing a simple CSV file
|
||||
- Issue 496: google-refine-2.5-rc2-r2379 failed to start if using refine.ini
|
||||
- Issue 515: "Open Project" page shows negative interval for "Last Modified"
|
||||
- Issue 517: Combin() function does not work as intended
|
||||
- Issue 521: Machine readable string (/type/rawstring) missing
|
||||
- Issue 523: Return all available HTTP error information on when Fetch URL fails
|
||||
- Issue 535: Refine fails to import Excel 2010 XLSX file with null hyperlinks
|
||||
- Issue 537: ToNumber should try to convert to integer first
|
||||
- Issue 541: Can't constrain a Freebase key query when using add column
|
||||
- Issue 542: ToDate should work on integers
|
||||
- Issue 543: Project creation from URL can't handle gzip Content-Encoding
|
||||
- Issue 544: FileNotFound exception when importing archive from URL
|
||||
- Issue 548: escape(value, encoding) returns "null" for non-string values
|
||||
- Issue 551: MQL preview missing "insert" clause
|
||||
- Issue 553: Upload Error - Not a directory
|
||||
- Issue 554: Format guesser ranking isn't working correctly in some cases
|
||||
- Issue 558: 'refine windows_dist' does not work on MacOS Lion
|
||||
- Issue 559: Deadlock between autosave thread and history code
|
||||
- Issue 578: json import on create project deletes useful blank data from arrays
|
||||
- Issue 586: Only one parse date format is attempted from list in toDate(format1,format2)
|
||||
- Issue 594: Date diff function doesn't work for two Calendar objects
|
||||
- Issue 596: JSON importer should not deserialize nulls as the string "null"
|
||||
- Issue 597: Deselect all button on Custom Tabular Exporter dialog doesn't work
|
||||
- Issue 599: RDF/XML parser preview not wired up
|
||||
- Issue 601: Allow selection of root element on JSON import
|
||||
- Issue 604: The common transform “Trim leading and trailing whitespace” doesn’t trim non-breaking spaces
|
||||
|
||||
|
||||
2.5 Release (December 11, 2011)
|
||||
|
||||
Major changes:
|
||||
- Entirely new importer architecture and user interface for Create Project
|
||||
- New import/export formats: Google Fusion Tables, OpenOffice Calc,
|
||||
and fixed width (import only)
|
||||
|
||||
Features:
|
||||
|
||||
- Issue 131: Read multiple files in a directory
|
||||
- Issue 179: Progress feedback during upload
|
||||
- Issue 260: XML Importer silently fails if file doesn't meet its criteria
|
||||
- Issue 279: Add support for reading from non-public Google Spreadsheets docs
|
||||
- Issue 280: Spreadsheet/table importers should allow selection of sheet/table to import
|
||||
- Issue 281: Add sheet selection support to Google Spreadsheet importer
|
||||
- Issue 31: Maximum number of facet values should be configurable.
|
||||
- Issue 38: Fix the table header so that it's always visible when scrolling a long page
|
||||
- Issue 433: Usability: use HTML <label> (e.g., for checkboxes
|
||||
- Issue 447: Extend toTitlecase() function with support for char[] delimiters in Apache WordUtils
|
||||
- Issue 452: Importing using Clipboard function does not guess structure correctly for XML or JSON
|
||||
- Issue 483: Project custom metadata while importing
|
||||
- Issue 504: Allow "sort" keyword in constraint subquery for "Add from Freebase"
|
||||
- Issue 84: Add a cut and paste textbox importer
|
||||
- Issue 85: Fixed width column importer
|
||||
- Issue 88: Improve operation history robustness by fixing Json.
|
||||
- Issue 92: Add Columns From Freebase dialog should support constraints
|
||||
- Issue 97: Exporting CSV should allow for optional columns
|
||||
|
||||
Bugs fixed:
|
||||
|
||||
- Issue 149: rows button stays strike-through when clicking on it
|
||||
- Issue 229: 'Ignore lines on import' bug when import from URL?
|
||||
- Issue 232: Stray characters before <?xml> (including blank lines) causes XML import to fail
|
||||
- Issue 233: 404 Error upon Launch
|
||||
- Issue 313: Excel export loses date cell format
|
||||
- Issue 314: Reconciliation (Freebase) of accented characters doesn't work
|
||||
- Issue 330: On Project creation - Unchecked Split Columns Box still splits by comma
|
||||
- Issue 366: Error when using Add column from Freebase on restored project
|
||||
- Issue 375: Importing data from Google spreadsheet via visualisation API query
|
||||
- Issue 378: Transform involving NaN causes crash
|
||||
- Issue 383: Updating Preview hangs on 2.5 branch when checking Load at most...
|
||||
- Issue 410: Convert line-endings to DOS format
|
||||
- Issue 419: Values with Characters like é split across several lines
|
||||
- Issue 424: Duplicate column names don't allow user to recover
|
||||
- Issue 426: filter with custom facet adds zero lines choice
|
||||
- Issue 428: Excel import sometimes drops last row of data
|
||||
- Issue 430: Timeline Facet not working
|
||||
- Issue 435: refine sh script only checks for java 1.6, not > 1.6
|
||||
- Issue 440: Fetch URLs aborts while saving/loading/computing facets
|
||||
- Issue 441: onError - "keep-original" / "store-blank" working oddly for value.toDate()
|
||||
- Issue 442: Two column transforms to date on the same column turns the cells blank
|
||||
- Issue 449: Uncaught exception from Excel importer
|
||||
- Issue 450: Parse error uploading to Fusion Table
|
||||
- Issue 454: Reselect Files after Configuring Parsing Options does not allow Select
|
||||
- Issue 459: Undefined error with some CSV files (incorrectly detected as EXCEL)
|
||||
- Issue 462: Don't trim whitespace in Excel importer
|
||||
- Issue 465: Data text file with extension .dta within a .ZIP is not automatically extracted
|
||||
- Issue 473: Cancel button doesn't work during project creation
|
||||
- Issue 474: XML importer ignores record limit
|
||||
- Issue 475: New Importer does not accept special separator characters completely such as Unicode chars
|
||||
- Issue 477: Implement or remove the line separator option
|
||||
- Issue 487: Transform -> To Date doesn't support ISO 8601 date parsing
|
||||
- Issue 488: ISO 8601 dates not supported in cell editing - cell-ui.js
|
||||
- Issue 489: Custom Exporter no longer behaves as expected with line & field separators
|
||||
- Issue 491: Importing Excel files - blank columns and time formatting
|
||||
- Issue 492: Table header cells misaligning with table cells
|
||||
- Issue 502: Fetch URLs does not return the exact HTTP payload, like Create Project from URLs does.
|
||||
- Issue 513: No more Json Tokens in stream ERROR
|
||||
|
||||
|
||||
2.1 Release (July 10, 2011) - Maintenance release
|
||||
|
||||
Features:
|
||||
|
||||
- Issue 157: Google Spreadsheet import/export plugin integrated
|
||||
- Issue 220: HTML parsing functions added to GREL (using Jsoup)
|
||||
- Issue 222: Added the ability to save favorite transforms
|
||||
- Issue 224: added ABS math function
|
||||
- Issue 349: Clustering not finding duplicates when facet is showing groupings
|
||||
- Issue 399: Added Cologne Phonetic clustering for German names
|
||||
|
||||
Bugs fixed:
|
||||
|
||||
- Issue 102: Process-Panel div sometimes disappears in Google Chrome
|
||||
- Issue 107: Reconciliation options not showing international characters correctly
|
||||
- Issue 143: Windows refine.bat file gives NoClassDefFoundError
|
||||
- Issue 163: Refine doesn't retain the characters for flat or sharp
|
||||
- Issue 172: inconsistencies in encoding guessing during load
|
||||
- Issue 184: Support formatting dates into strings
|
||||
- Issue 185: same reconciliation candidate for two cells seems to be overridden
|
||||
- Issue 187: Linux start instruction incorrect
|
||||
- Issue 188: ArrayIndexOutOfBoundsException when importing excel file
|
||||
- Issue 196: failure and error dialog attempting to remove columns
|
||||
- Issue 197: New project was modified "0 years ago"
|
||||
- Issue 202: Sort text with accents
|
||||
- Issue 203: Please add TextPipe to Related Software page
|
||||
- Issue 227: Documentation states extensions are mounted at /extensions, but they are really mounted at /extension.
|
||||
- Issue 228: Import .zip archive fails
|
||||
- Issue 237: reinterpret() no longer seems to work as expected
|
||||
- Issue 258: JAVA_HOME ignored if "which java" returns nonzero
|
||||
- Issue 262: Refine does not start
|
||||
- Issue 263: & symbol being parsed in url's in xml
|
||||
- Issue 276: strange character while create new project with a chinese project name
|
||||
- Issue 294: Exporting date type column to TSV/CSV shows java debugging information instead of value
|
||||
- Issue 295: Binaries under 'root' user on *nix
|
||||
- Issue 304: CsvExporter tests fail after commit for issue 294
|
||||
- Issue 311: "Ignore" and "Skip" fields in the "Create a New Project" form have the same input[name]
|
||||
- Issue 312: toString(date_val, 'yyyy-MM-dd') doesn't seem to work
|
||||
- Issue 325: Refine cannot load data from URL when run behind Proxy Server
|
||||
- Issue 328: Don't retry failed key-based reconciliations
|
||||
- Issue 334: Fusion Tables CSV import produces NullPointerException
|
||||
- Issue 351: Error 500 STREAM on Excel export
|
||||
- Issue 355: Broken images for SchemaAlignment page
|
||||
- Issue 358: org.json.JSONException: JSON does not allow non-finite numbers.
|
||||
- Issue 364: Build is broken
|
||||
- Issue 374: Problems with date functions INC
|
||||
- Issue 391: Patch to refine.{bat,ini}
|
||||
- Issue 401: Error in exception handling for ExportRows command
|
||||
- Issue 404: Intermittent charset detection failure
|
||||
- Issue 415: Evaluation precedence wrong for arithmetic expressions
|
||||
- Issue 61: multiple rows per column from 1 xml element
|
||||
|
||||
|
||||
2.0 Release (November 10, 2010 - first release as Google Refine)
|
||||
|
||||
Major Changes:
|
||||
- New extension architecture.
|
||||
- Generalized reconciliation framework that allows plugging in standard reconciliation services.
|
||||
- Support for QA on data loads into Freebase.
|
||||
- Timeline Facet (Issue 40 and 95)
|
||||
|
||||
Features:
|
||||
- New commands:
|
||||
- Fill Down
|
||||
- Blank Down
|
||||
- Transpose Cells in Columns into Rows
|
||||
- Transpose Cells in Rows into Columns (Issue 82)
|
||||
- Move Column to Beginning, Move Column to End, Move Column Left, Move Column Right, Reorder Columns
|
||||
- Add Column by Fetching URLs
|
||||
- Recon commands:
|
||||
- Clear recon data for all matching rows
|
||||
- Clear recon data for one cell
|
||||
- Clear recon data for similar cells
|
||||
- Copy recon judgments across columns
|
||||
- GREL:
|
||||
- JSON support
|
||||
- New functions: smartSplit, escape, parseJson, hasField, uniques
|
||||
- New controls: forEachIndex, forRange, filter
|
||||
- New parameters:
|
||||
- preserveAllTokens on split function
|
||||
- Regexp groups capturing GEL function
|
||||
- Importers
|
||||
- New: RDF exporter (as extension)
|
||||
- New: Json importer
|
||||
- CSV and TSV importers: added support for ignoring quotation marks
|
||||
- Added support for creating a project by pointing to a data file URL.
|
||||
- Text facet's choice count limit is now configurable through preference page
|
||||
- Select All and Unselect All buttons in History Extract dialog
|
||||
- Schema skeleton: support for multiple cells per cell-as nodes, and for conditional links
|
||||
- Optionally convert strings to numbers during split columns operation
|
||||
|
||||
Fixes:
|
||||
- TSV/CSV exporter bug: Gridworks crashed when there were empty cells.
|
||||
- Issue 29: Delivered "Collapse whitespace" transformation does not work
|
||||
- Issue 57: Schema skeleton disappears
|
||||
- Issue 66: Records not excluded with inverted text facet
|
||||
- Issue 69: ControlFunctionRegistry now correctly registers Chomp expression as "chomp" key.
|
||||
- Issue 99: Diff for dates fails with "unknown error" always
|
||||
- Issue 110: Import of single column text file with Postal Codes shows only 1 row with lots of <20> chars (?)
|
||||
- Issue 113: Export filtered rows as tsv or csv fails; html and excel OK
|
||||
- Issue 115: datePart(value,"month") gives zero-based month numbers
|
||||
- Issue 116: CSV/TSV export data includes blank fields for deleted columns
|
||||
- Issue 121: Importing attached file strips backslashes
|
||||
- Issue 122: Exporting to Excel on attached project raises server exception
|
||||
- Issue 125: jsonize not serializing arrays
|
||||
- Issue 126: Large integers formatted in scientific notation in formulas
|
||||
- Issue 127: Add column from Freebase raises exception
|
||||
- Issue 135: Hangs when setting cell value to large JSON string
|
||||
- Issue 138: Numbers should be right-justified
|
||||
- Issue 140: Fix Open Workspace Directory command to work on Windows and Linux
|
||||
- Issue 146: In "Cluster and Edit Column", clicking on entry value to set "Merge?" checkbox does not reflect the final value of operation
|
||||
- Issue 155: Blank browser shown when non-GZIP format is detected during import
|
||||
- Issue 160: Cancel button on Search for Match dialog sometimes not working
|
||||
- Issue 161: Authorize error when trying to Sign In before loading to Freebase
|
||||
- Issue 166: Expression Editor dialog needs UI cleanup on long expressions
|
||||
|
||||
|
||||
1.1 Release (May 27, 2010)
|
||||
|
||||
Features:
|
||||
- Row/record sorting (Issue 32)
|
||||
- CSV exporter (Issue 59)
|
||||
- Mqlwrite exporter
|
||||
- Templating exporter (experimental)
|
||||
|
||||
Fixes:
|
||||
- Issue 34: "Behavior of Text Filter is unpredictable when "regular expression" mode is enabled."
|
||||
Regex was not compiled with case insensitivity flag.
|
||||
- Issue 4: "Match All bug with ZIP code". Numeric values in cells were not stringified first
|
||||
before comparison.
|
||||
- Issue 41: "Envelope quotation marks are removed by CSV importer"
|
||||
- Issue 19: "CSV import is too basic"
|
||||
- Issue 15: "Ability to rename projects"
|
||||
- Issue 16: "Column name collision when adding data from Freebase"
|
||||
- Issue 28: "mql-like preview is not properly unquoting numbers"
|
||||
- Issue 45: "Renaming Cells with Ctrl-Enter produced ERROR"
|
||||
Tentative fix for a concurrent bug.
|
||||
- Issue 46: "Array literals in GEL"
|
||||
- Issue 55: "Use stable sorting for text facets sorted by count"
|
||||
- Issue 53: "Moving the cursor inside the Text Filter box by clicking"
|
||||
- Issue 58: "Meta facet"
|
||||
Supported by the function facetCount()
|
||||
- Issue 14: "Limiting Freebase load to starred records"
|
||||
We load whatever rows that are filtered through, not particularly starred rows.
|
||||
- Issue 49: "Add Edit Cells / Set Null"
|
||||
- Issue 30: "Transform dialog should remember preferred language."
|
||||
- Issue 62: "It'd be nice if URIs were hyperlinked in the data cells"
|
||||
|
||||
Other Changes:
|
||||
- Moved unit tests from JUnit to TestNG
|
||||
|
||||
|
||||
1.0.1 Release (May 12, 2010)
|
||||
|
||||
Fixes:
|
||||
- Issue 2: "Undo History bug" - bulk row starring and flagging operations could not be undone.
|
||||
- Issue 5: "Localized Windows cause save problems for Gridworks" -
|
||||
Windows user IDs that contain unicode characters were not retrieved correctly.
|
||||
- Issue 10: "OAuth fails on sign in" - due to clock offset.
|
||||
- Issue 11: "missing "lang" attribute in MQL generated in schema alignment"
|
||||
- Issue 13: "float rejected from sandbox upload as Json object" - everything was sent as a string.
|
||||
- Issue 17: "Conflated triples - all rows are producing triple with "s" :" $Name_0"" -
|
||||
The Create A New Topic for Each Cell command created shared recon objects.
|
||||
- Issue 18: "Error converting russian characters during edit of single cell"
|
||||
- [partial fix] Issue 19: "CSV import is too basic" - fixed for CSV, not for TSV
|
||||
|
||||
1.0 Release (May 10, 2010)
|
||||
|
||||
First Public Release as Freebase Gridworks
|
||||
|
||||
@ -1,82 +0,0 @@
|
||||
# OpenRefine Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
In the interest of fostering an open and welcoming environment, we as OpenRefine
|
||||
contributors and maintainers pledge to making participation in our project and
|
||||
our community a harassment-free experience for everyone, regardless of age, body
|
||||
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
||||
level of experience, education, socio-economic status, nationality, personal
|
||||
appearance, race, religion, or sexual identity and orientation.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to creating a positive environment
|
||||
include:
|
||||
|
||||
* Using welcoming and inclusive language
|
||||
* Being respectful of differing viewpoints and experiences
|
||||
* Gracefully accepting constructive criticism
|
||||
* Focusing on what is best for the community
|
||||
* Showing empathy towards other community members
|
||||
|
||||
Examples of unacceptable behavior by participants include:
|
||||
|
||||
* The use of sexualized language or imagery and unwelcome sexual attention or
|
||||
advances
|
||||
* Trolling, insulting/derogatory comments, and personal or political attacks
|
||||
* Public or private harassment
|
||||
* Publishing others' private information, such as a physical or electronic
|
||||
address, without explicit permission
|
||||
* Other conduct which could reasonably be considered inappropriate in a
|
||||
professional setting
|
||||
|
||||
## Our Responsibilities
|
||||
|
||||
Project maintainers are responsible for clarifying the standards of acceptable
|
||||
behavior and are expected to take appropriate and fair corrective action in
|
||||
response to any instances of unacceptable behavior.
|
||||
|
||||
Project maintainers have the right and responsibility to remove, edit, or
|
||||
reject comments, commits, code, wiki edits, issues, and other contributions
|
||||
that are not aligned to this Code of Conduct, or to ban temporarily or
|
||||
permanently any contributor for other behaviors that they deem inappropriate,
|
||||
threatening, offensive, or harmful.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all project spaces, and it also applies when
|
||||
an individual is representing the project or its community in public spaces.
|
||||
Examples of representing a project or community include using an official
|
||||
project e-mail address, posting via an official social media account, or acting
|
||||
as an appointed representative at an online or offline event. Representation of
|
||||
a project may be further defined and clarified by project maintainers.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
||||
reported by contacting the Code of Conduct Committee at code-of-conduct@openrefine.org.
|
||||
The committee consists of:
|
||||
* Lozanna Rossenova
|
||||
* Chris Erdmann
|
||||
* Jessica Hardwicke
|
||||
|
||||
All complaints will be reviewed and investigated and will result in a response that
|
||||
is deemed necessary and appropriate to the circumstances. The code of conduct is
|
||||
obligated to maintain confidentiality with regard to the reporter of an incident.
|
||||
Further details of specific enforcement policies may be posted separately.
|
||||
|
||||
Project maintainers who do not follow or enforce the Code of Conduct in good
|
||||
faith may face temporary or permanent repercussions as determined by other
|
||||
members of the project's leadership.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
||||
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
||||
For answers to common questions about this code of conduct, see
|
||||
https://www.contributor-covenant.org/faq
|
||||
|
||||
@ -1,62 +0,0 @@
|
||||
This document presents how you can contribute to the OpenRefine project. Please also review our [Governance model](https://github.com/OpenRefine/OpenRefine/blob/master/GOVERNANCE.md)
|
||||
|
||||
## Documentation, Questions or Problem
|
||||
|
||||
Our issue list is only for reporting specific bugs and requesting specific features. If you just don't know how to do something using OpenRefine, or want to discuss some ideas, please
|
||||
- try the [documentation wiki](https://github.com/OpenRefine/OpenRefine/wiki/Documentation-For-Users)
|
||||
- ask on the [OpenRefine mailing list](https://groups.google.com/d/forum/openrefine).
|
||||
|
||||
If you really want to file a bug or request a feature, go to this [issue list](https://github.com/OpenRefine/OpenRefine/issues). Please use the search function first to make sure a similar issue doesn't already exist.
|
||||
|
||||
## Promote OpenRefine
|
||||
|
||||
You don't need to be a coder to contribute to OpenRefine. Did you write a tutorial or article about OpenRefine on your blog or site? Are you organizing a workshop or presentation for OpenRefine in your city? Let us know via our [user discussion list](https://groups.google.com/d/forum/openrefine) or Twitter account ([@OpenRefine](http://twitter.com/OpenRefine)). We will share the news via our monthly update and via our Twitter handle.
|
||||
|
||||
## Contributing translations
|
||||
|
||||
You can help us [translate OpenRefine](https://github.com/OpenRefine/OpenRefine/wiki/Translate-OpenRefine) in as many languages as possible [via Weblate](https://hosted.weblate.org/engage/openrefine/?utm_source=widget).
|
||||
|
||||
## Contributing code
|
||||
|
||||
You can contribute code in three different ways:
|
||||
- Fix minor bugs - you can check the issues flagged as [help wanted](https://github.com/OpenRefine/OpenRefine/labels/help%20wanted) or [good first issue](https://github.com/OpenRefine/OpenRefine/labels/good%20first%20issue) or [good second issue](https://github.com/OpenRefine/OpenRefine/labels/good%20second%20issue)
|
||||
- Develop an OpenRefine extension
|
||||
- Start your own distribution or fork
|
||||
|
||||
All developers including new distributions and plugin developers are invited to leverage the following OpenRefine project management areas to avoid splitting the community in different communication channels.
|
||||
- the [wiki](https://github.com/OpenRefine/OpenRefine/wiki) for shared documentation between both user docs and [documentation for developer](https://github.com/OpenRefine/OpenRefine/wiki/Documentation-For-Developers)
|
||||
- the [developer mailing list](https://groups.google.com/forum/?fromgroups#!forum/openrefine-dev) for technical questions, new feature development and anything code related. We invite you to share you idea first via the developer mailing list. Someone may be able to point out to existing development saving you hours of research and development.
|
||||
- [OpenRefine github issue tracker](https://github.com/OpenRefine/OpenRefine/issues) for requesting new features and bug reports.
|
||||
- [Gitter Chat](https://gitter.im/OpenRefine/OpenRefine)
|
||||
|
||||
### How to submit PR's (pull requests), patches, and bug fixes
|
||||
|
||||
- Read [Your first pull request](https://github.com/OpenRefine/OpenRefine/wiki/Your-first-pull-request)
|
||||
- Avoid merging master in your branch because it makes code review a lot harder.
|
||||
- If you want to keep your branch up to date with our master, it would be nicer if you could just rebase your branch instead. That would keep the history a lot cleaner.
|
||||
- Please avoid adding unrelated changes in the PR. Do a separate PR and rebase once they get merged can work really well.
|
||||
- It is important that pull requests are used systematically, even by those who have the rights to merge them.
|
||||
|
||||
If you make trivial changes, you can send them directly via a pull request. **Please make your changes in a new git branch and send your patch**, including appropriate test cases.
|
||||
|
||||
We want to keep the quality of the trunk at a very high level, since this is ultimately where the Stable Releases are built from after bugs are fixed. Please take the time to test your changes (including travis-ci) before sending a pull request.
|
||||
|
||||
OpenRefine is volunteer supported. Pull Requests are reviewed and merged by volunteers. All Pull Requests will be answered, however it may take some time to get back to you. Thank you in advance for your patience.
|
||||
|
||||
If you don't know where to start and are looking for a bug to fix, please see our [issue list](https://github.com/OpenRefine/OpenRefine/issues).
|
||||
|
||||
### New functionalities via extensions
|
||||
|
||||
OpenRefine support a plugin architecture to extend its functionality. You can find more information on how to write extension on [our wiki](https://github.com/OpenRefine/OpenRefine/wiki/Write-An-Extension). Giuliano Tortoreto wrote a separate documentation detailing how to build an extension for OpenRefine. A [LaTeX](https://github.com/OpenRefine/OpenRefineExtensionDoc) and [PDF version](https://github.com/OpenRefine/OpenRefineExtensionDoc/blob/master/main.pdf) are available.
|
||||
|
||||
If you want to list your extension on the download page, please edit [this file](https://github.com/OpenRefine/openrefine.github.com/blob/master/download.md).
|
||||
|
||||
### New distributions
|
||||
|
||||
OpenRefine is already available in many different distributions (see the [download page](http://openrefine.org/download.html)). New distributions often package OpenRefine for a specific usage or port it. We are fine with new forks ([see discussion](https://groups.google.com/forum/#!msg/openrefine/pasNnMDJ3p8/LrZz_GiFCwAJ)) but we invite you to engage with the community to share your roadmap and progress.
|
||||
|
||||
Github offers a powerful system to work between different repositories and we encourage you to leverage it:
|
||||
- You can cross reference issues and pull requests between Github repository using `user/repository#number` ([see more here](https://github.com/blog/967-github-secrets#cross-repository-issue-references))
|
||||
- If you want to merge a Pull Request that is pending for review to your own repository check the pull request locally ([see more here](https://help.github.com/articles/checking-out-pull-requests-locally/)).
|
||||
|
||||
Don't forget to contribute to the upstream ([main OpenRefine repository](https://github.com/openrefine/openrefine.git)) so your changes from your distribution can be reviewed and merged and to keep other developers aware of your progress. If you want to list your distribution on the download page, please edit [this file](https://github.com/OpenRefine/openrefine.github.com/blob/master/download.md).
|
||||
@ -1,128 +0,0 @@
|
||||
# OpenRefine Governance Model
|
||||
|
||||
## Summary / Overview
|
||||
OpenRefine is a free, open-source, powerful tool for working with messy data. OpenRefine has a plugin architecture and is distributed under the [new BSD license](http://opensource.org/licenses/BSD-3-Clause) allowing modification, distribution and name changes.
|
||||
|
||||
## Roles and responsibilities
|
||||
OpenRefine development is based on user consensus and open discussion between users. Decision making must be done in a transparent, open fashion (ie. using discussion list and issue list). No decisions about the project’s direction, bug fixes or features may be done in private without community involvement and participation. Discussions must begin at the earliest possible point on a topic; the community’s participation is vital during the entire decision-making process.
|
||||
|
||||
All project participants abide by the [Code of Conduct](https://github.com/OpenRefine/OpenRefine/blob/master/CODE_OF_CONDUCT.md).
|
||||
|
||||
Anyone with an interest in the project can join the community, contribute to the project design, and participate in the decision making process. This document describes how that participation takes place.
|
||||
|
||||
### Users
|
||||
Users are community members who have a need for the project. Through their usage, they give the project a purpose. Users are encouraged to participate in the project life by providing feedback on how their needs are satisfied.
|
||||
|
||||
Users can help the project by:
|
||||
|
||||
- Advertising and advocating for the project
|
||||
- Informing developers of strengths and weaknesses of the tool through the [user discussion list](https://groups.google.com/forum/?fromgroups#!forum/openrefine) or the [issue list](https://github.com/OpenRefine/OpenRefine/issues?state=open)
|
||||
- Providing moral support (a ‘thank you’ goes a long way)
|
||||
- Writing tutorials
|
||||
|
||||
How to become an OpenRefine user? [Download OpenRefine](http://openrefine.org/download.html) and start refining!
|
||||
|
||||
### Contributors
|
||||
Contributors are users getting involved in the project more closely. Contributions can take many forms:
|
||||
|
||||
- Supporting new users via the [user discussion list](https://groups.google.com/forum/?fromgroups#!forum/openrefine)
|
||||
- Submitting patches to fix bugs or add features via pull requests
|
||||
- Maintaining and improving the [website](https://openrefine.org/)
|
||||
- Writing and maintaining the [documentation](https://github.com/OpenRefine/OpenRefine/tree/master/docs)
|
||||
|
||||
How to become an OpenRefine contributor? You will find more details in our [contributing guideline](https://github.com/OpenRefine/OpenRefine/blob/master/CONTRIBUTING.md)
|
||||
|
||||
### Committers
|
||||
If you make regular contribution to OpenRefine, you will most likely become a Committer.
|
||||
|
||||
Committers have earned enough trust from the community to review and merge pull requests.
|
||||
|
||||
Therefore Committers:
|
||||
- Help contributors via the [developer discussion list](https://groups.google.com/forum/?fromgroups#!forum/openrefine-dev).
|
||||
- Triage issues, pull requests and [projects](https://github.com/OpenRefine/OpenRefine/projects)
|
||||
- Have direct access to the code base to create new branches
|
||||
- Organize the wiki
|
||||
- Review and merge pull requests submitted by contributors
|
||||
- Are part of the OpenRefine organization and have the OpenRefine badge on their GitHub profile
|
||||
|
||||
#### How to become a Committer?
|
||||
|
||||
Be a contributor and be nominated as a Committer. Current Committer selects and elects new Committer. You may nominate yourself. Nomination should be sent to the [developer discussion list](https://groups.google.com/forum/?fromgroups#!forum/openrefine-dev)
|
||||
|
||||
#### Current list of Committers
|
||||
The list is available here: https://github.com/orgs/OpenRefine/people.
|
||||
|
||||
### Release Manager
|
||||
The Release Manager is responsible to
|
||||
* Coordinate with the community to select which issue and pull request are part of the release
|
||||
* Prepare and coordinate publishing the release
|
||||
|
||||
The current Release Manager is Antonin Delpeuch
|
||||
|
||||
### Steering Committee
|
||||
The steering committee oversees the general direction of the project and initates links with other organizations and projects.
|
||||
|
||||
* Advise the Project’s staff on processes, strategy, and operations;
|
||||
* Participate in decision making and/or review of roadmaps, as time allows;
|
||||
* Participate to some Steering Committee meetings, when time allows;
|
||||
* Help the Project build connections and partnerships by helping project leadership to steward relationships with funders and partners, making strategic introductions for project leadership, reviewing documents when needed, as time allows;
|
||||
* Act as an advocate for the Project in events and support the project’s communication online, as time allows.
|
||||
|
||||
#### How to be part of the Steering Committee
|
||||
Steering Committee are invited by the Advisory Committee
|
||||
|
||||
#### Current list of Steering Committee members
|
||||
* Chris Erdmann (University of North Carolina, RENCI)
|
||||
* Alicia Fagerving (Wikimedia Sverige)
|
||||
* Sandra Fauconnier (Wikimedia Foundation)
|
||||
* Rufus Pollock (Datopian, Open Knowledge Foundation)
|
||||
* Simon Rogers (Google News Initiative)
|
||||
* Lozana Rossenova (Rhizome)
|
||||
* Juliane Schneider (Harvard Catalyst, Clinical and Translational Science Center)
|
||||
* Wesley Sherperd (Unifyd Insights)
|
||||
* Fabio Tacchelli (Siren Solutions)
|
||||
|
||||
### Advisory Committee
|
||||
The Advisory Committee runs the adminstrative aspect of the project on a day to day basis with the support of Code for Science and Society (CS&S). Its member are bound by the fiscal sponsorship agreement with Code for Science and Society. They meet once per month with Code for Science and Society.
|
||||
|
||||
It is composed of at least three members. No more than 49 percent of the members of the Advisory Committee may be paid by the project.
|
||||
|
||||
Advisory Committee members:
|
||||
* Represent OpenRefine with Code for Science and Society
|
||||
* Provide guidance and oversight of the Project’s staff and operations;
|
||||
* Approve budgets, and contracts
|
||||
* Vote to terminate contracts when necessary.
|
||||
* Participate in at least one call per quarter;
|
||||
* Help advocate for the Project;
|
||||
* Help the Project build connections and partnerships;
|
||||
* Can be part of the Admin team for the project on GitHub
|
||||
|
||||
#### Conflict of Interest
|
||||
In the event of any conflict of interest (a Committee Member, their family member, or someone with whom the Committee Member has a close academic or employment relationship is involved in a decision), the Committee Member must immediately notify other Committee Members. The Committee Member will be asked to recuse themselves from ongoing conversations, and decision process regarding the Transaction.
|
||||
|
||||
#### Current list of Advisory Committee members
|
||||
* Martin Magdinier
|
||||
* Antonin Delpeuch.
|
||||
|
||||
## Code For Science and Society
|
||||
|
||||
Since January 2020, OpenRefine is a member project of the Code For Science and Society (CS&S).
|
||||
|
||||
CS&S provides administrative and fiscal infrastructure to receive and manage funds under CS&S Fiscal Sponsorship Agreement. CS&S is a USA based organization qualified as exempt from federal income tax under Section 501(c)(3) of the Internal Revenue Code (IRC) and classified as a public charity under IRC Sections 509(a)(1) and 170(b)(1)(A)(vi).
|
||||
|
||||
### Manage funds
|
||||
|
||||
While the vast majority of OpenRefine contributors are volunteers, we recognize the need to attract and retain contributors to help:
|
||||
- perform time critical maintenance tasks for the project (for example release management, security update, pull request review and comments)
|
||||
- address issues that will not be naturally done by the community (for example documentation or working on large or long term projects)
|
||||
|
||||
CS&S currently manages the current funding sources:
|
||||
- **Grants**: Funds are allocated based on the grants requirements. Grants help to secure resources to achieve long term goal or supports software maintenance, growth, development, and community engagement.
|
||||
- **Google Summer of Code**: Google Summer of Code mentors are eligible for USD 500 compensation for their work.
|
||||
- **Donations made through GitHub Sponsors or made directly to CS&S on behalf of OpenRefine**: Decisions on usage of funds is made by the Advisory committee with guidance from the community.
|
||||
|
||||
Combined with CS&S, the Steering and Advisory committees have experience applying and managing grants. If you are interested in applying to a grant to improve OpenRefine, please share your idea early on the Developer mailing list. It will be a pleasure helping you through your grant application. New grants must be approved by the Advisory Committee. that CS&S retains a 15% handling fees on any donation to finance their operations (20% for government funding).
|
||||
|
||||
### Other assets
|
||||
|
||||
CS&S owns and manages the domain openrefine.org
|
||||
@ -1,29 +0,0 @@
|
||||
|
||||
OpenRefine for Eclipse
|
||||
-------------------------
|
||||
|
||||
|
||||
This file contains Eclipse-specific help files that can get simplify your life
|
||||
developing OpenRefine with Eclipse (http://www.eclipse.org/).
|
||||
|
||||
|
||||
|
||||
Code Style Format Configurations (Refine.style.xml)
|
||||
------------------------------------------------------
|
||||
|
||||
This is the code formatting configurations that all OpenRefine developers should follow.
|
||||
|
||||
To import, open the Eclipse preferences, then follow to "Java > Code Style > Formatter"
|
||||
and click the "Import" button and load the file.
|
||||
|
||||
|
||||
|
||||
- o -
|
||||
|
||||
|
||||
Thank you for your interest.
|
||||
|
||||
|
||||
The OpenRefine Development Team
|
||||
http://github.com/OpenRefine/OpenRefine
|
||||
|
||||
@ -1,62 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?><templates><template autoinsert="true" context="gettercomment_context" deleted="false" description="Comment for getter method" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.gettercomment" name="gettercomment">/**
|
||||
* @return the ${bare_field_name}
|
||||
*/</template><template autoinsert="true" context="settercomment_context" deleted="false" description="Comment for setter method" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.settercomment" name="settercomment">/**
|
||||
* @param ${param} the ${bare_field_name} to set
|
||||
*/</template><template autoinsert="true" context="constructorcomment_context" deleted="false" description="Comment for created constructors" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.constructorcomment" name="constructorcomment">/**
|
||||
* ${tags}
|
||||
*/</template><template autoinsert="false" context="filecomment_context" deleted="false" description="Comment for created Java files" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.filecomment" name="filecomment">/*
|
||||
|
||||
Copyright ${year}, ${user}
|
||||
All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are
|
||||
met:
|
||||
|
||||
* Redistributions of source code must retain the above copyright
|
||||
notice, this list of conditions and the following disclaimer.
|
||||
* Redistributions in binary form must reproduce the above
|
||||
copyright notice, this list of conditions and the following disclaimer
|
||||
in the documentation and/or other materials provided with the
|
||||
distribution.
|
||||
* Neither the name of Google Inc. nor the names of its
|
||||
contributors may be used to endorse or promote products derived from
|
||||
this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
*/</template><template autoinsert="true" context="typecomment_context" deleted="false" description="Comment for created types" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.typecomment" name="typecomment">/**
|
||||
* @author ${user}
|
||||
*
|
||||
* ${tags}
|
||||
*/</template><template autoinsert="true" context="fieldcomment_context" deleted="false" description="Comment for fields" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.fieldcomment" name="fieldcomment">/**
|
||||
*
|
||||
*/</template><template autoinsert="true" context="methodcomment_context" deleted="false" description="Comment for non-overriding methods" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.methodcomment" name="methodcomment">/**
|
||||
* ${tags}
|
||||
*/</template><template autoinsert="true" context="overridecomment_context" deleted="false" description="Comment for overriding methods" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.overridecomment" name="overridecomment">/* (non-Javadoc)
|
||||
* ${see_to_overridden}
|
||||
*/</template><template autoinsert="true" context="delegatecomment_context" deleted="false" description="Comment for delegate methods" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.delegatecomment" name="delegatecomment">/**
|
||||
* ${tags}
|
||||
* ${see_to_target}
|
||||
*/</template><template autoinsert="true" context="newtype_context" deleted="false" description="Newly created files" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.newtype" name="newtype">${filecomment}
|
||||
${package_declaration}
|
||||
|
||||
${typecomment}
|
||||
${type_declaration}</template><template autoinsert="true" context="classbody_context" deleted="false" description="Code in new class type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.classbody" name="classbody">
|
||||
</template><template autoinsert="true" context="interfacebody_context" deleted="false" description="Code in new interface type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.interfacebody" name="interfacebody">
|
||||
</template><template autoinsert="true" context="enumbody_context" deleted="false" description="Code in new enum type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.enumbody" name="enumbody">
|
||||
</template><template autoinsert="true" context="annotationbody_context" deleted="false" description="Code in new annotation type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.annotationbody" name="annotationbody">
|
||||
</template><template autoinsert="true" context="catchblock_context" deleted="false" description="Code in new catch blocks" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.catchblock" name="catchblock">// ${todo} Auto-generated catch block
|
||||
${exception_var}.printStackTrace();</template><template autoinsert="true" context="methodbody_context" deleted="false" description="Code in created method stubs" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.methodbody" name="methodbody">// ${todo} Auto-generated method stub
|
||||
${body_statement}</template><template autoinsert="true" context="constructorbody_context" deleted="false" description="Code in created constructor stubs" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.constructorbody" name="constructorbody">${body_statement}
|
||||
// ${todo} Auto-generated constructor stub</template><template autoinsert="true" context="getterbody_context" deleted="false" description="Code in created getters" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.getterbody" name="getterbody">return ${field};</template><template autoinsert="true" context="setterbody_context" deleted="false" description="Code in created setters" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.setterbody" name="setterbody">${field} = ${param};</template></templates>
|
||||
@ -1,269 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<profiles version="11">
|
||||
<profile kind="CodeFormatterProfile" name="OpenRefine" version="11">
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_if" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_assert" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_enum_constant" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_semicolon" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.align_type_members_on_columns" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_case" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.format_line_comments" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.number_of_empty_lines_to_preserve" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_brackets_in_array_type_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_switch" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_between_type_declarations" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_parenthesized_expression_in_return" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_method_body" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_annotation_type_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_statements_compare_to_body" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_opening_brace_in_array_initializer" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_member" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.format_guardian_clause_on_one_line" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.insert_new_line_before_root_tags" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_for" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.tabulation.size" value="8"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_angle_bracket_in_type_parameters" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_imports" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_case" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_enum_constant_arguments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_new_chunk" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.continuation_indentation" value="2"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_binary_operator" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_constructor_declaration_parameters" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_for" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_superinterfaces" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_parameters_in_method_declaration" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_assignment" value="0"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_member_type" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_constructor_declaration_throws" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_conditional_expression" value="80"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_while" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.indent_parameter_description" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.format_html" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_allocation_expression" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_method_declaration_throws" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_enum_constant" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.format_source_code" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_enum_declarations" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_angle_bracket_in_parameterized_type_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_annotation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_method_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_conditional" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_unary_operator" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_question_in_conditional" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_annotation_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indentation.size" value="4"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_multiple_local_declarations" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_postfix_operator" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_superinterfaces_in_enum_declaration" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_enum_constant_arguments" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_semicolon_in_for" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_constructor_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_at_in_annotation_type_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_explicitconstructorcall_arguments" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_anonymous_type_declaration" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.lineSplit" value="120"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_type_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_block" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_type_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_invocation_arguments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_while" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_enum_constant" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.clear_blank_lines_in_block_comment" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_at_in_annotation_type_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_enum_constant" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_angle_bracket_in_type_arguments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_angle_bracket_in_type_parameters" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_closing_brace_in_array_initializer" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_array_initializer" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_superclass_in_type_declaration" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_cast" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_enum_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_synchronized" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.format_header" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_for" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_at_in_annotation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_else_in_if_statement" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_explicit_constructor_call" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_method_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_allocation_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_multiple_fields" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_at_end_of_file_if_missing" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_explicitconstructorcall_arguments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_block" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.join_wrapped_lines" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_paren_in_cast" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_finally_in_try_statement" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.keep_then_statement_on_same_line" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_binary_operator" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_annotation_declaration_header" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_constructor_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_method_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_expressions_in_array_initializer" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_declaration_parameters" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_method_declaration" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_enum_constant" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_annotation_type_member_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_angle_bracket_in_type_arguments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_angle_bracket_in_parameterized_type_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_annotation_type_member_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_field" value="0"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_throws_clause_in_method_declaration" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_method_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_constructor_declaration_parameters" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_type_parameters" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_switch" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.format_javadoc_comments" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_bracket_in_array_allocation_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_annotation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.format_block_comments" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_array_initializer" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_anonymous_type_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_binary_expression" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_braces_in_array_initializer" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.wrap_before_binary_operator" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_after_package" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_catch" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_superinterfaces_in_type_declaration" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_labeled_statement" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.compiler.codegen.inlineJsrBytecode" value="enabled"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_semicolon_in_for" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_and_in_type_parameter" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_catch" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_while_in_do_statement" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_between_import_groups" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_declaration_throws" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_prefix_operator" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_ellipsis" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_constructor_declaration" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_question_in_wildcard" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.clear_blank_lines_in_javadoc_comment" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_allocation_expression" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_type_parameters" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_after_imports" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_conditional" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_enum_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_parameterized_type_reference" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_catch_in_try_statement" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.compiler.problem.assertIdentifier" value="error"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_enum_constant" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_block_in_case" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_enum_declaration" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_for_increments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_for" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_first_class_body_declaration" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.keep_else_statement_on_same_line" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_empty_lines" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.insert_new_line_for_parameter" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_parenthesized_expression_in_throw" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_while" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_brace_in_block" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.compiler.source" value="1.5"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_for_increments" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_enum_declaration_header" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_constructor_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.line_length" value="80"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_prefix_operator" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_type_declaration" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_assignment_operator" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_parameter" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.compiler.compliance" value="1.5"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_method_invocation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_angle_bracket_in_type_arguments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.compact_else_if" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_bracket_in_array_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_enum_declarations" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_question_in_conditional" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_angle_bracket_in_type_parameters" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_method_invocation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.use_tabs_only_for_leading_indentations" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_type_arguments" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_switch" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_parameters_in_constructor_declaration" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_brackets_in_array_allocation_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_for" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_constructor_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_synchronized" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.number_of_blank_lines_at_beginning_of_method_body" value="0"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_annotation" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_angle_bracket_in_parameterized_type_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_switchstatements_compare_to_switch" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_constructor_declaration" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.join_lines_in_comments" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_annotation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_if" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_default" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.compiler.problem.enumIdentifier" value="error"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_annotation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_enum_constant" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_bracket_in_array_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_local_variable" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_bracket_in_array_type_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_array_initializer" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_catch" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_synchronized" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.keep_empty_array_initializer_on_one_line" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.compiler.codegen.targetPlatform" value="1.5"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_bracket_in_array_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_switch" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_brace_in_array_initializer" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_compact_if" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_question_in_wildcard" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_assert" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_method_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_ellipsis" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_qualified_allocation_expression" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_statements_compare_to_block" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_parenthesized_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_type_header" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_angle_bracket_in_type_parameters" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_type_arguments" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.keep_imple_if_on_one_line" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_method_invocation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_multiple_local_declarations" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_annotation_type_declaration" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_selector_in_method_invocation" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_enum_constant_header" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_switch" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_assignment_operator" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.never_indent_line_comments_on_first_column" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_unary_operator" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_if" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_labeled_statement" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_bracket_in_array_allocation_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_switchstatements_compare_to_cases" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.continuation_indentation_for_array_initializer" value="2"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.comment.indent_root_tags" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_enum_constants" value="0"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_parameterized_type_reference" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_parenthesized_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_constructor_declaration_throws" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_throws_clause_in_constructor_declaration" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_method_invocation" value="16"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.tabulation.char" value="space"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_package" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_method_invocation_arguments" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.indent_breaks_compare_to_cases" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_for_inits" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_multiple_field_declarations" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_superinterfaces" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.put_empty_statement_on_new_line" value="true"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_method_declaration_parameters" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_method" value="1"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_multiple_field_declarations" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_for_inits" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_anonymous_type_declaration" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_cast" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_angle_bracket_in_type_arguments" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.never_indent_block_comments_on_first_column" value="false"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_array_initializer" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_parenthesized_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_enum_constant" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_method_invocation" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_postfix_operator" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_block" value="end_of_line"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_brace_in_array_initializer" value="insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_bracket_in_array_allocation_expression" value="do not insert"/>
|
||||
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_and_in_type_parameter" value="insert"/>
|
||||
</profile>
|
||||
</profiles>
|
||||
@ -1,11 +0,0 @@
|
||||
Copyright 2010, Google Inc. All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
||||
|
||||
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
||||
|
||||
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
||||
|
||||
3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
@ -1,75 +0,0 @@
|
||||
# MultiUserOpenRefine
|
||||

|
||||
|
||||
MultiUserOpenRefine is an extension to open-source tool that, in addition to
|
||||
all the features described below, allows creating user accounts, each providing
|
||||
private workspace and leaving the convenience of running the basic OpenRefine
|
||||
tool on a remote server.
|
||||
|
||||
Project is being developed at Adam Mickiewicz University in Poznań by students.
|
||||
|
||||
# OpenRefine
|
||||
|
||||
[](https://zenodo.org/badge/latestdoi/6220644)
|
||||
[](https://gitter.im/OpenRefine/OpenRefine)  [](https://coveralls.io/github/OpenRefine/OpenRefine?branch=master) [](https://hosted.weblate.org/engage/openrefine/?utm_source=widget) [](https://lgtm.com/projects/g/OpenRefine/OpenRefine/alerts/)
|
||||
|
||||
OpenRefine is a Java-based power tool that allows you to load data, understand it,
|
||||
clean it up, reconcile it, and augment it with data coming from
|
||||
the web. All from a web browser and the comfort and privacy of your own computer.
|
||||
|
||||
[<img src="https://github.com/OpenRefine/OpenRefine/blob/master/graphics/icon/open-refine-320px.png" align="right">](http://openrefine.org)
|
||||
|
||||
## Download
|
||||
|
||||
* [OpenRefine Releases](https://github.com/OpenRefine/OpenRefine/releases)
|
||||
|
||||
## Snapshot releases
|
||||
|
||||
Latest development version, packaged for:
|
||||
* [Linux](https://oss.sonatype.org/service/local/artifact/maven/content?r=snapshots&g=org.openrefine&a=openrefine&v=3.6-SNAPSHOT&c=linux&p=tar.gz)
|
||||
* [Windows](https://oss.sonatype.org/service/local/artifact/maven/content?r=snapshots&g=org.openrefine&a=openrefine&v=3.6-SNAPSHOT&c=mac&p=dmg)
|
||||
* [MacOS](https://oss.sonatype.org/service/local/artifact/maven/content?r=snapshots&g=org.openrefine&a=openrefine&v=3.6-SNAPSHOT&c=win&p=zip)
|
||||
|
||||
## Run from source
|
||||
|
||||
If you have cloned this repository to your computer, you can run OpenRefine with:
|
||||
|
||||
* `./refine` on Mac OS and Linux
|
||||
* `refine.bat` on Windows
|
||||
|
||||
This requires [JDK 8](https://jdk.java.net) and [Apache Maven](https://maven.apache.org/).
|
||||
|
||||
## Documentation and Videos
|
||||
|
||||
* [User Manual](https://docs.openrefine.org)
|
||||
* [FAQ](https://github.com/OpenRefine/OpenRefine/wiki/FAQ)
|
||||
* [Official Website and tutorial videos](http://openrefine.org)
|
||||
|
||||
## Contributing to the project
|
||||
|
||||
* [Developers Guide & Architecture](https://github.com/OpenRefine/OpenRefine/wiki/Documentation-For-Developers)
|
||||
* [Contributing Guide](https://github.com/OpenRefine/OpenRefine/blob/master/CONTRIBUTING.md)
|
||||
* [Project Governance](https://github.com/OpenRefine/OpenRefine/blob/master/GOVERNANCE.md)
|
||||
|
||||
## Contact us
|
||||
|
||||
* [Mailing List](https://groups.google.com/forum/#!forum/openrefine)
|
||||
* [Twitter](http://www.twitter.com/openrefine)
|
||||
* [Gitter](https://gitter.im/OpenRefine/OpenRefine)
|
||||
* [Matrix (bridged from Gitter)](https://matrix.to/#/#OpenRefine_OpenRefine:gitter.im)
|
||||
|
||||
## Licensing and legal issues
|
||||
|
||||
OpenRefine is open source software and is licensed under the BSD license
|
||||
located in the [LICENSE.txt](LICENSE.txt). See the folder `licenses` for information on open source
|
||||
libraries that OpenRefine depends on.
|
||||
|
||||
## Credits
|
||||
|
||||
This software was created by Metaweb Technologies, Inc. and originally written
|
||||
and conceived by David Huynh <dfhuynh@google.com>. Metaweb Technologies, Inc.
|
||||
was acquired by Google, Inc. in July 2010 and the product was renamed Google Refine.
|
||||
In October 2012, it was renamed OpenRefine as it transitioned to a
|
||||
community-supported product.
|
||||
|
||||
See [AUTHORS.md](./AUTHORS.md) for the list of OpenRefine contributors and [CONTRIBUTING.md](./CONTRIBUTING.md) for instructions on how to contribute yourself.
|
||||
@ -1,18 +0,0 @@
|
||||
# OpenRefine Security Policy
|
||||
|
||||
## Supported Versions
|
||||
|
||||
| Version | Supported |
|
||||
| ------- | ------------------ |
|
||||
| 3.4.x | :white_check_mark: |
|
||||
| <= 3.3 | :x: |
|
||||
|
||||
## Reporting a Vulnerability
|
||||
|
||||
You can privately report a vulnerability to us by sending a report to this private mailing list [mailto:openrefine-coredev@googlegroups.com](mailto:openrefine-coredev@googlegroups.com)
|
||||
|
||||
Our core team will try their best to fix any valid vulnerability that is reported to them.
|
||||
|
||||
Keep in mind that OpenRefine is designed to run locally on a users PC, while also making network calls across the internet only upon a users choice or command.
|
||||
|
||||
As such, certain vulnerabilities might not apply to OpenRefine's design.
|
||||
@ -1,8 +0,0 @@
|
||||
An evergrowing list of our forever immortalized OpenRefine Backers that we LOVE because they help support further development !
|
||||
|
||||
1. Owen Stephens - Wiki contributor, extension author, and supporting you in our mailing list.
|
||||
2. PaulZH -
|
||||
3. Jens Willmer -
|
||||
4. mroswell -
|
||||
5. Google News Initiative - https://newsinitiative.withgoogle.com/
|
||||
6. Chan Zuckerberg Initiative - https://chanzuckerberg.com/
|
||||
@ -1,63 +0,0 @@
|
||||
version: 1.0.{build}
|
||||
|
||||
services:
|
||||
- mysql
|
||||
- postgresql96
|
||||
|
||||
init:
|
||||
- cmd: java -version 2>&1 | find "version"
|
||||
|
||||
clone_depth: 5
|
||||
skip_branch_with_pr: true
|
||||
skip_commits:
|
||||
files:
|
||||
- docs/
|
||||
|
||||
environment:
|
||||
JAVA_HOME: C:\Program Files\Java\jdk11
|
||||
MAVEN_HOME: C:\Program Files (x86)\Apache\Maven
|
||||
|
||||
matrix:
|
||||
fast_finish: true
|
||||
|
||||
build: off
|
||||
|
||||
# scripts to run before test
|
||||
before_test:
|
||||
- cmd: echo Running scripts before build...
|
||||
- cmd: |-
|
||||
PATH=C:\Program Files\PostgreSQL\9.6\bin\;C:\Program Files\MySQL\MySQL Server 5.7\bin\;%PATH%
|
||||
SET MYSQL_PWD=Password12!
|
||||
mysql -u root --password=Password12! -e "create database test_db;"
|
||||
mysql -u root test_db --password=Password12! < extensions\database\tests\conf\test-mysql.sql
|
||||
echo "localhost:*:test_db:postgres:Password12!" > C:\Program Files\PostgreSQL\9.6\pgpass.conf
|
||||
echo "localhost:*:test_db:postgres:Password12!" > pgpass.conf
|
||||
echo "localhost:*:test_db:postgres:Password12!" > %userprofile%\pgpass.conf
|
||||
SET PGPASSFILE=C:\Program Files\PostgreSQL\9.6\pgpass.conf
|
||||
SET PGPASSWORD=Password12!
|
||||
SET PGUSER=postgres
|
||||
createdb test_db
|
||||
psql -U postgres test_db < extensions\database\tests\conf\test-pgsql.sql
|
||||
|
||||
copy extensions\database\tests\conf\appveyor_tests.xml extensions\database\tests\conf\tests.xml
|
||||
copy packaging\test_pom.xml packaging\pom.xml
|
||||
- cmd: |-
|
||||
mvn process-resources
|
||||
mvn package -DskipTests=true -Dmaven.javadoc.skip=true -B -V
|
||||
|
||||
test_script:
|
||||
- cmd: echo Running test_script...
|
||||
- cmd: >-
|
||||
echo PATH is:
|
||||
|
||||
path
|
||||
|
||||
refine test
|
||||
|
||||
on_failure:
|
||||
- cmd: |-
|
||||
dir
|
||||
|
||||
cache:
|
||||
- C:\Users\appveyor\.m2
|
||||
|
||||
@ -1,159 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
<parent>
|
||||
<artifactId>openrefine</artifactId>
|
||||
<groupId>org.openrefine</groupId>
|
||||
<version>3.6-SNAPSHOT</version>
|
||||
</parent>
|
||||
|
||||
<artifactId>benchmark</artifactId>
|
||||
<packaging>jar</packaging>
|
||||
|
||||
<name>OpenRefine Java JMH benchmarks</name>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>${project.groupId}</groupId>
|
||||
<artifactId>main</artifactId>
|
||||
<version>${project.version}</version>
|
||||
<scope>provided</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>javax.servlet</groupId>
|
||||
<artifactId>javax.servlet-api</artifactId>
|
||||
<version>${servlet-api.version}</version>
|
||||
<scope>provided</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.openjdk.jmh</groupId>
|
||||
<artifactId>jmh-core</artifactId>
|
||||
<version>${jmh.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.openjdk.jmh</groupId>
|
||||
<artifactId>jmh-generator-annprocess</artifactId>
|
||||
<version>${jmh.version}</version>
|
||||
<scope>provided</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.testng</groupId>
|
||||
<artifactId>testng</artifactId>
|
||||
<version>7.4.0</version>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<jmh.version>1.33</jmh.version>
|
||||
<javac.target>${java.minversion}</javac.target>
|
||||
<uberjar.name>openrefine-benchmarks</uberjar.name>
|
||||
</properties>
|
||||
|
||||
<build>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<groupId>org.apache.maven.plugins</groupId>
|
||||
<artifactId>maven-compiler-plugin</artifactId>
|
||||
<version>3.8.0</version>
|
||||
<configuration>
|
||||
<compilerVersion>${javac.target}</compilerVersion>
|
||||
<source>${javac.target}</source>
|
||||
<target>${javac.target}</target>
|
||||
</configuration>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<groupId>org.apache.maven.plugins</groupId>
|
||||
<artifactId>maven-shade-plugin</artifactId>
|
||||
<version>3.2.4</version>
|
||||
<executions>
|
||||
<execution>
|
||||
<phase>package</phase>
|
||||
<goals>
|
||||
<goal>shade</goal>
|
||||
</goals>
|
||||
<configuration>
|
||||
<finalName>${uberjar.name}</finalName>
|
||||
<transformers>
|
||||
<transformer
|
||||
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
|
||||
<mainClass>org.openjdk.jmh.Main</mainClass>
|
||||
</transformer>
|
||||
<transformer
|
||||
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
|
||||
</transformers>
|
||||
<filters>
|
||||
<filter>
|
||||
<!-- Shading signed JARs will fail without this. http://stackoverflow.com/questions/999489/invalid-signature-file-when-attempting-to-run-a-jar -->
|
||||
<artifact>*:*</artifact>
|
||||
<excludes>
|
||||
<exclude>META-INF/*.SF</exclude>
|
||||
<exclude>META-INF/*.DSA</exclude>
|
||||
<exclude>META-INF/*.RSA</exclude>
|
||||
</excludes>
|
||||
</filter>
|
||||
</filters>
|
||||
<artifactSet>
|
||||
<includes>
|
||||
<include>${project.groupId}:main:*:*</include>
|
||||
<include>*:*</include>
|
||||
</includes>
|
||||
</artifactSet>
|
||||
</configuration>
|
||||
</execution>
|
||||
</executions>
|
||||
</plugin>
|
||||
</plugins>
|
||||
<pluginManagement>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<artifactId>maven-clean-plugin</artifactId>
|
||||
<version>2.5</version>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<artifactId>maven-install-plugin</artifactId>
|
||||
<version>2.5.2</version>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<artifactId>maven-jar-plugin</artifactId>
|
||||
<version>2.4</version>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<artifactId>maven-javadoc-plugin</artifactId>
|
||||
<version>3.3.1</version>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<artifactId>maven-resources-plugin</artifactId>
|
||||
<version>3.2.0</version>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<artifactId>maven-site-plugin</artifactId>
|
||||
<version>3.9.1</version>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<artifactId>maven-source-plugin</artifactId>
|
||||
<version>3.2.1</version>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<artifactId>maven-surefire-plugin</artifactId>
|
||||
<version>2.17</version>
|
||||
<configuration>
|
||||
<skipTests>true</skipTests>
|
||||
</configuration>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<groupId>org.apache.maven.plugins</groupId>
|
||||
<artifactId>maven-deploy-plugin</artifactId>
|
||||
<version>${maven-deploy-plugin.version}</version>
|
||||
<configuration>
|
||||
<skip>true</skip>
|
||||
</configuration>
|
||||
</plugin>
|
||||
</plugins>
|
||||
</pluginManagement>
|
||||
</build>
|
||||
|
||||
</project>
|
||||
@ -1,94 +0,0 @@
|
||||
/*******************************************************************************
|
||||
* Copyright (C) 2020, OpenRefine contributors
|
||||
* All rights reserved.
|
||||
*
|
||||
* Redistribution and use in source and binary forms, with or without
|
||||
* modification, are permitted provided that the following conditions are met:
|
||||
*
|
||||
* 1. Redistributions of source code must retain the above copyright notice,
|
||||
* this list of conditions and the following disclaimer.
|
||||
*
|
||||
* 2. Redistributions in binary form must reproduce the above copyright notice,
|
||||
* this list of conditions and the following disclaimer in the documentation
|
||||
* and/or other materials provided with the distribution.
|
||||
*
|
||||
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
||||
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
||||
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
|
||||
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE
|
||||
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
|
||||
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
|
||||
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
|
||||
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
|
||||
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
|
||||
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
|
||||
* POSSIBILITY OF SUCH DAMAGE.
|
||||
******************************************************************************/
|
||||
package org.openrefine.benchmark;
|
||||
|
||||
import java.util.Properties;
|
||||
import java.util.Random;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
import org.openjdk.jmh.annotations.Benchmark;
|
||||
import org.openjdk.jmh.annotations.BenchmarkMode;
|
||||
import org.openjdk.jmh.annotations.Fork;
|
||||
import org.openjdk.jmh.annotations.Level;
|
||||
import org.openjdk.jmh.annotations.Measurement;
|
||||
import org.openjdk.jmh.annotations.Mode;
|
||||
import org.openjdk.jmh.annotations.OutputTimeUnit;
|
||||
import org.openjdk.jmh.annotations.Param;
|
||||
import org.openjdk.jmh.annotations.Scope;
|
||||
import org.openjdk.jmh.annotations.Setup;
|
||||
import org.openjdk.jmh.annotations.State;
|
||||
import org.openjdk.jmh.annotations.Warmup;
|
||||
import org.openjdk.jmh.infra.Blackhole;
|
||||
|
||||
import com.google.refine.expr.functions.ToNumber;
|
||||
|
||||
public class ToNumberBenchmark {
|
||||
|
||||
static Properties bindings = new Properties();
|
||||
|
||||
@State(Scope.Benchmark)
|
||||
public static class ExecutionPlan {
|
||||
|
||||
@Param({"1000", "10000" })
|
||||
public int iterations;
|
||||
|
||||
public ToNumber f;
|
||||
String[] args = new String[1];
|
||||
String testData;
|
||||
String testDataInt;
|
||||
Random rnd = new Random();
|
||||
|
||||
@Setup(Level.Invocation)
|
||||
public void setUp() {
|
||||
f = new ToNumber();
|
||||
testData = Double.toString(rnd.nextDouble() * 10000);
|
||||
testDataInt = testData.replace(".", "");
|
||||
}
|
||||
}
|
||||
|
||||
@Benchmark
|
||||
@BenchmarkMode(Mode.AverageTime)
|
||||
@OutputTimeUnit(TimeUnit.NANOSECONDS)
|
||||
@Warmup(iterations = 3, time = 200, timeUnit = TimeUnit.MILLISECONDS)
|
||||
@Measurement(iterations = 5, time = 200, timeUnit = TimeUnit.MILLISECONDS)
|
||||
public void toDoubleNew(ExecutionPlan plan, Blackhole blackhole) {
|
||||
plan.args[0] = plan.testData;
|
||||
blackhole.consume(plan.f.call(bindings, plan.args));
|
||||
}
|
||||
|
||||
@Benchmark
|
||||
@BenchmarkMode(Mode.AverageTime)
|
||||
@OutputTimeUnit(TimeUnit.NANOSECONDS)
|
||||
@Warmup(iterations = 3, time = 200, timeUnit = TimeUnit.MILLISECONDS)
|
||||
@Measurement(iterations = 5, time = 200, timeUnit = TimeUnit.MILLISECONDS)
|
||||
@Fork(1)
|
||||
public void toLongNew(ExecutionPlan plan, Blackhole blackhole) {
|
||||
plan.args[0] = plan.testDataInt;
|
||||
blackhole.consume(plan.f.call(bindings, plan.args));
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,13 +0,0 @@
|
||||
# Launch4j runtime config
|
||||
|
||||
# initial memory heap size
|
||||
-Xms256M
|
||||
|
||||
# max memory memory heap size
|
||||
-Xmx1024M
|
||||
|
||||
# Use system defined HTTP proxies
|
||||
-Djava.net.useSystemProxies=true
|
||||
|
||||
#-XX:+UseLargePages
|
||||
#-Dsomevar="%SOMEVAR%"
|
||||
@ -1,32 +0,0 @@
|
||||
<?xml version="1.0"?>
|
||||
<ruleset name="OpenRefine PMD Ruleset"
|
||||
xmlns="http://pmd.sf.net/ruleset/1.0.0"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://pmd.sf.net/ruleset/1.0.0 http://pmd.sf.net/ruleset_xml_schema.xsd"
|
||||
xsi:noNamespaceSchemaLocation="http://pmd.sf.net/ruleset_xml_schema.xsd">
|
||||
<description>OpenRefine PMD Ruleset</description>
|
||||
|
||||
<rule ref="rulesets/basic.xml">
|
||||
<exclude name="EmptyCatchBlock"/>
|
||||
<exclude name="AvoidUsingHardCodedIP"/>
|
||||
</rule>
|
||||
|
||||
<rule ref="rulesets/braces.xml">
|
||||
<exclude name="IfStmtsMustUseBraces"/>
|
||||
</rule>
|
||||
|
||||
<rule ref="rulesets/unusedcode.xml"/>
|
||||
<rule ref="rulesets/imports.xml"/>
|
||||
<rule ref="rulesets/strings.xml">
|
||||
<exclude name="ConsecutiveLiteralAppends"/>
|
||||
<exclude name="AvoidDuplicateLiterals"/>
|
||||
</rule>
|
||||
|
||||
<rule ref="rulesets/unusedcode.xml"/>
|
||||
<rule ref="rulesets/clone.xml"/>
|
||||
|
||||
<rule ref="rulesets/migrating.xml">
|
||||
<exclude name="JUnit4TestShouldUseTestAnnotation"/>
|
||||
</rule>
|
||||
|
||||
</ruleset>
|
||||
24
OpenRefine/docs/.gitignore
vendored
24
OpenRefine/docs/.gitignore
vendored
@ -1,24 +0,0 @@
|
||||
node_modules
|
||||
|
||||
lib/core/metadata.js
|
||||
lib/core/MetadataBlog.js
|
||||
|
||||
translated_docs
|
||||
build/
|
||||
package-lock.json
|
||||
i18n/*
|
||||
|
||||
# generated files
|
||||
.docusaurus
|
||||
.cache-loader
|
||||
|
||||
# misc
|
||||
.DS_Store
|
||||
.env.local
|
||||
.env.development.local
|
||||
.env.test.local
|
||||
.env.production.local
|
||||
|
||||
npm-debug.log*
|
||||
yarn-debug.log*
|
||||
yarn-error.log*
|
||||
@ -1 +0,0 @@
|
||||
14
|
||||
@ -1,94 +0,0 @@
|
||||
How to build these docs
|
||||
=======================
|
||||
|
||||
We use [Docusaurus 2](https://v2.docusaurus.io/) for our docs, a modern static website generator.
|
||||
|
||||
### Requirements
|
||||
|
||||
Assuming you have [Node.js](https://nodejs.org/en/download/) installed (which includes npm), you can install Docusaurus with:
|
||||
|
||||
You will need to install [Yarn](https://yarnpkg.com/getting-started/install) before you can build the site.
|
||||
|
||||
```sh
|
||||
npm install -g yarn
|
||||
```
|
||||
|
||||
### Installation
|
||||
|
||||
Once you have installed yarn, navigate to docs directory & set-up the dependencies.
|
||||
|
||||
```sh
|
||||
cd docs
|
||||
yarn
|
||||
```
|
||||
|
||||
### Local Development
|
||||
|
||||
```sh
|
||||
yarn start
|
||||
```
|
||||
|
||||
This command starts a local development server and opens up a browser window. Usually at the URL <http://localhost:3000>
|
||||
Most changes are reflected live without having to restart the server.
|
||||
|
||||
If you get an error starting yarn mentioning `update.latest` such as
|
||||
|
||||
```sh
|
||||
>yarn start
|
||||
|
||||
if (notifier.update && semver.gt(this.update.latest, this.update.current)) {
|
||||
TypeError: Cannot read property 'latest' of undefined
|
||||
at Object.<anonymous> (E:\GitHubRepos\OpenRefine\docs\node_modules\@docusaurus\core\bin\docusaurus.js:49:46)
|
||||
error Command failed with exit code 1.
|
||||
```
|
||||
|
||||
then it is likely that you will need to first run
|
||||
|
||||
```sh
|
||||
yarn upgrade
|
||||
```
|
||||
|
||||
which will update all dependencies and store them in the `yarn.lock` file to also be committed.
|
||||
|
||||
### Next version of OpenRefine docs
|
||||
|
||||
If you wish to work on the next version of docs for OpenRefine (`master` branch) then you will need to:
|
||||
|
||||
1. Git checkout our `master` branch
|
||||
2. Edit files under `docs/docs/`
|
||||
3. Preview changes with the URL kept pointing to <http://localhost:3000/next> which will automatically
|
||||
show changes live with yarn after you save a file.
|
||||
|
||||
### Build
|
||||
|
||||
```sh
|
||||
yarn build
|
||||
```
|
||||
|
||||
This command generates static content into the `build` directory and can be served using any static contents hosting service.
|
||||
|
||||
### Deployment
|
||||
|
||||
```sh
|
||||
GIT_USER=<Your GitHub username> USE_SSH=true yarn deploy
|
||||
```
|
||||
|
||||
If you are using GitHub pages for hosting, this command is a convenient way to build the website
|
||||
and push to the `gh-pages` branch.
|
||||
|
||||
### Translations
|
||||
|
||||
It is now possible to translate the [OpenRefine docs](https://docs.openrefine.org/) via the
|
||||
Crowdin platform:
|
||||
|
||||
<https://crowdin.com/project/openrefine>
|
||||
|
||||
Unfortunately, unlike Weblate, we need to manually invite anyone who
|
||||
wants to contribute translations. Feel free to request an invite by emailing us at openrefine-dev@googlegroups.com
|
||||
We can also add languages, depending on interest.
|
||||
|
||||
Your translations will not be immediately published on <https://docs.openrefine.org>, it will take a few days
|
||||
(at the next commit on the master branch).
|
||||
The translated pages will first appear under <https://docs.openrefine.org/next/> (the documentation for the development version).
|
||||
When we publish a version, the translations for that version, we will take a snapshot of the translations during that time.
|
||||
We will trial this process for 3.5.
|
||||
@ -1,16 +0,0 @@
|
||||
project_id: '455186'
|
||||
api_token_env: 'CROWDIN_PERSONAL_TOKEN'
|
||||
preserve_hierarchy: true
|
||||
files: [
|
||||
# Markdown files for the user manual
|
||||
{
|
||||
source: '/docs/manual/**/*',
|
||||
translation: '/i18n/%two_letters_code%/docusaurus-plugin-content-docs/current/**/%original_file_name%',
|
||||
},
|
||||
# Docs home page
|
||||
{
|
||||
source: '/docs/index.md',
|
||||
translation: '/i18n/%two_letters_code%/docusaurus-plugin-content-docs/current/%original_file_name%',
|
||||
},
|
||||
|
||||
]
|
||||
@ -1,25 +0,0 @@
|
||||
---
|
||||
slug: /
|
||||
id: index
|
||||
title: OpenRefine user manual
|
||||
sidebar_label: Introduction
|
||||
---
|
||||
|
||||
|
||||
This manual is designed to comprehensively walk through every aspect of setting up and using OpenRefine 3.4.1, including every interface function and feature.
|
||||
|
||||
<!--
|
||||
This documentation platform provides a separate version of the user manual for each version of OpenRefine (from 3.4.1 onwards) - if you're looking for a later version than 3.4.1, please select the correct version from the dropdown menu in the top bar of this page.
|
||||
-->
|
||||
|
||||
This user manual starts with instructions for [installing or upgrading OpenRefine on Windows, Mac, and Linux computers](manual/installing). It then walks you through [the interface and how to run OpenRefine](manual/running#jvm-preferences) from a program or command line, with or without setting custom preferences and modifications.
|
||||
|
||||
The manual then teaches you how to [start a project](manual/starting) by importing an existing dataset. We work through how to [view and learn about your data](manual/exploring) using facets, filters, and sorting.
|
||||
|
||||
Then we launch into [transforming that data permanently](manual/transforming) through common and custom transformations, clustering, pulling data from the web, [reconciling](manual/reconciling), and [writing expressions](manual/expressions).
|
||||
|
||||
Finally we discuss what to do with your improved dataset, whether [exporting](manual/exporting) it to a file or [uploading statements to Wikidata or another Wikibase instance](manual/wikibase/overview).
|
||||
|
||||
If you're stuck on any aspect and can't find an answer in the manual, try the [Troubleshooting page](manual/troubleshooting) for links to various places to find help.
|
||||
|
||||
If you are new and want to learn how to use OpenRefine using an example dataset, you may wish to start with a user-contributed tutorial from our [recommendations list](https://github.com/OpenRefine/OpenRefine/wiki/External-Resources).
|
||||
@ -1,165 +0,0 @@
|
||||
---
|
||||
id: cellediting
|
||||
title: Cell editing
|
||||
sidebar_label: Cell editing
|
||||
---
|
||||
## Overview {#overview}
|
||||
|
||||
OpenRefine offers a number of features to edit and improve the contents of cells automatically and efficiently.
|
||||
|
||||
One way of doing this is editing through a [text facet](facets#text-facet). Once you have created a facet on a column, hover over the displayed results in the sidebar. Click on the small “edit” button that appears to the right of the facet, and type in a new value. This will apply to all the cells in the facet.
|
||||
|
||||
You can apply a text facet on numbers, boolean values, and dates, but if you edit a value it will be converted into the text [data type](exploring#data-types) (regardless of whether you edit a date into another correctly-formatted date, or a “true” value into “false”, etc.).
|
||||
|
||||
## Transform {#transform}
|
||||
|
||||
Select <span class="menuItems">Edit cells</span> → <span class="menuItems">Transform...</span> to open up an expressions window. From here, you can apply [expressions](expressions) to your data. The simplest examples are GREL functions such as [`toUppercase()`](grelfunctions#touppercases) or [`toLowercase()`](grelfunctions#tolowercases), used in expressions as `toUppercase(value)` or `toLowercase(value)`. When used on a column operation, `value` is the information in each cell in the selected column.
|
||||
|
||||
Use the preview to ensure your data is being transformed correctly.
|
||||
|
||||
You can also switch to the <span class="tabLabels">Undo / Redo</span> tab inside the expressions window to reuse expressions you’ve already attempted in this project, whether they have been undone or not.
|
||||
|
||||
OpenRefine offers you some frequently-used transformations in the next menu option, <span class="menuItems">Common transforms</span>. For more custom transforms, read up on [expressions](expressions).
|
||||
|
||||
## Common transforms {#common-transforms}
|
||||
|
||||
### Trim leading and trailing whitespace {#trim-leading-and-trailing-whitespace}
|
||||
|
||||
Often cell contents that should be identical, and look identical, are different because of space or line-break characters that are invisible to users. This function will get rid of any characters that sit before or after visible text characters.
|
||||
|
||||
### Collapse consecutive whitespace {#collapse-consecutive-whitespace}
|
||||
|
||||
You may find that some text cells contain what look like spaces but are actually tabs, or contain multiple spaces in a row. This function will remove all space characters that sit in sequence and replace them with a single space.
|
||||
|
||||
### Unescape HTML {#unescape-html}
|
||||
|
||||
Your data may come from an HTML-formatted source that expresses some characters through references (such as “&nbsp;” for a space, or “%u0107” for a ć) instead of the actual Unicode characters. You can use the “unescape HTML entities” transform to look for these codes and replace them with the characters they represent. For other formatting that needs to be escaped, try a custom transformation with [`escape()`](grelfunctions#escapes-s-mode).
|
||||
|
||||
### Replace smart quotes with ASCII {#replace-smart-quotes-with-ascii}
|
||||
|
||||
Smart quotes (or curly quotes) recognize whether they come at the beginning or end of a string, and will generate an “open” quote (“) and a “close” quote (”). These characters are not ASCII-compliant (though they are UTF8-compliant) so you can use this tranform to replace them with a straight double quote character (") instead.
|
||||
|
||||
### Case transforms {#case-transforms}
|
||||
|
||||
You can transform an entire column of text into UPPERCASE, lowercase, or Title Case using these three options. This can be useful if you are planning to do textual analysis and wish to avoid case-sensitivity (which some functions are) causing problems in your analysis. Consider also using a [custom facet](facets#custom-text-facet) to temporarily modify cases instead of this permanent operation if appropriate.
|
||||
|
||||
### Data-type transforms {#data-type-transforms}
|
||||
|
||||
As detailed in [Data types](exploring#data-types), OpenRefine recognizes different data types: string, number, boolean, and date. When you use these transforms, OpenRefine will check to see if the given values can be converted, then both transform the data in the cells (such as “3” as a text string to “3” as a number) and convert the data type on each successfully transformed cell. Cells that cannot be transformed will output the original value and maintain their original data type.
|
||||
|
||||
:::caution
|
||||
Be aware that dates may require manual intervention to transform successfully: see the section on [Dates](exploring#dates) for more information.
|
||||
:::
|
||||
|
||||
Because these common transforms do not offer the ability to output an error instead of the original cell contents, be careful to look for unconverted and untransformed values. You will see a yellow alert at the top of screen that will tell you how many cells were converted - if this number does not match your current row set, you will need to look for and manually correct the remaining cells. Also consider faceting by data type, with the GREL function [`type()`](grelfunctions#typeo).
|
||||
|
||||
You can also convert cells into null values or empty strings. This can be useful if you wish to, for example, erase duplicates that you have identified and are analyzing as a subset.
|
||||
|
||||
## Fill down and blank down {#fill-down-and-blank-down}
|
||||
|
||||
Fill down and blank down are two functions most frequently used when encountering data organized into [records](exploring#row-types-rows-vs-records) - that is, multiple rows associated with one specific entity.
|
||||
|
||||
If you receive information in rows mode and want to convert it to records mode, the easiest way is to sort your first column by the value that you want to use as a unique records key, [make that sorting permanent](transforming#edit-rows), then blank down all the duplicates in that column. OpenRefine will retain the first unique value and erase the rest. Then you can switch from “Show as rows” to “Show as records” and OpenRefine will associate rows to each other based on the remaining values in the first column.
|
||||
|
||||
Be careful that your data is sorted properly before you begin blanking down - not just the first column but other columns you may want to have in a certain order. For example, you may have multiple identical entries in the first column, one with a value in the second column and one with an empty cell in the second column. In this case you want the row with the second-column value to come first, so that you can clean up empty rows later, once you blank down.
|
||||
|
||||
If, conversely, you’ve received data with empty cells because it was already in something akin to records mode, you can fill down information to the rest of the rows. This will duplicate whatever value exists in the topmost cell with a value: if the first row in the record is blank, it will take information from the next cell, or the cell after that, until it finds a value. The blank cells above this will remain blank.
|
||||
|
||||
## Split multi-valued cells {#split-multi-valued-cells}
|
||||
|
||||
Splitting cells with more than one value in them is a common way to get your data from single rows into [multi-row records](exploring#rows-vs-records). Survey data, for example, frequently allows respondents to “Select all that apply,” or an inventory list might have items filed under more than one category.
|
||||
|
||||
You can split a column based on any character or series of characters you input, such as a semi-colon (;) or a slash (/). The default is a comma. Splitting based on a separator will remove the separator characters, so you may wish to include a space with your separator (; ) if it exists in your data.
|
||||
|
||||
You can use [expressions](expressions) to design the point at which a cell should split itself into two or more rows. This can be used to identify special characters or create more advanced evaluations. You can split on a line-break by entering `\n` and checking the “[regular expression](expressions#regular-expressions)” checkbox.
|
||||
|
||||
Regular expressions can be useful if the split is not straightforward: say, if a capital letter (`[A-Z]`) indicates the beginning of a new string, or if you need to _not_ always split on a character that appears in both the strings and as a separator. Remember that this will remove all the matching characters.
|
||||
|
||||
You can also split based on the lengths of the strings you expect to find. This can be useful if you have predictable data in the cells: for example, a 10-digit phone number, followed by a space, followed by another 10-digit phone number. Any characters past the explicit length you’ve specified will be discarded: if you split by “11, 10” any characters that may come after the 21st character will disappear. If some cells only have one phone number, you will end up with blank rows.
|
||||
|
||||
If you have data that should be split into multiple columns instead of multiple rows, see [Split into several columns](columnediting#split-into-several-columns).
|
||||
|
||||
## Join multi-valued cells {#join-multi-valued-cells}
|
||||
|
||||
Joining will reverse the “split multi-valued cells” operation, or join up information from multiple rows into one row. All the strings will be compressed into the topmost cell in the record, in the order they appear. A window will appear where you can set the separator; the default is a comma and a space (, ). This separator is optional. We suggest the separator | as a sufficiently rare character.
|
||||
|
||||
## Cluster and edit {#cluster-and-edit}
|
||||
|
||||
Creating a facet on a column is a great way to look for inconsistencies in your data; clustering is a great way to fix those inconsistencies. Clustering uses a variety of comparison methods to find text entries that are similar but not exact, then shares those results with you so that you can merge the cells that should match. Where editing a single cell or text facet at a time can be time-consuming and difficult, clustering is quick and streamlined.
|
||||
|
||||
Clustering always requires the user to approve each suggested edit - it will display values it thinks are variations on the same thing, and you can select which version to keep and apply across all the matching cells (or type in your own version).
|
||||
|
||||
OpenRefine will do a number of cleanup operations behind the scenes in order to do its analysis, but only the merges you approve will modify your data. Understanding those different behind-the-scenes cleanups can help you choose which clustering method will be more accurate and effective.
|
||||
|
||||
You can start the process in two ways: using the dropdown menu on your column, select <span class="menuItems">Edit cells</span> → <span class="menuItems">Cluster and edit…</span>; or create a text facet and then press the “Cluster” button that appears in the facet box.
|
||||
|
||||

|
||||
|
||||
The clustering pop-up window will take a small amount of time to analyze your column, and then make some suggestions based on the clustering method currently active.
|
||||
|
||||
For each cluster identified, you can pick one of the existing values to apply to all cells, or manually type in a new value in the text box. And, of course, you can choose not to cluster them at all. OpenRefine will keep analyzing every time you make a change, with <span class="buttonLabels">Merge selected & re-cluster</span>, and you can work through all the methods this way.
|
||||
|
||||
You can also export the currently identified clusters as a JSON file, or close the window with or without applying your changes. You can also use the histograms on the right to narrow down to, for example, clusters with lots of matching rows, or clusters of long or short values.
|
||||
|
||||
### Clustering methods {#clustering-methods}
|
||||
|
||||
You don’t need to understand the details behind each clustering method to apply them successfully to your data. The order in which these methods are presented in the interface and on this page is the order we recommend - starting with the most strict rules and moving to the most lax, which require more human supervision to apply correctly.
|
||||
|
||||
The clustering pop-up window offers you a variety of clustering methods:
|
||||
|
||||
* key collision
|
||||
* fingerprint
|
||||
* ngram-fingerprint
|
||||
* metaphone3
|
||||
* cologne-phonetic
|
||||
* Daitch-Mokotoff
|
||||
* Beider-Morse
|
||||
* nearest neighbor
|
||||
* levenshtein
|
||||
* ppm
|
||||
|
||||
#### Key collision {#key-collision}
|
||||
|
||||
**Key collisions** are very fast and can process millions of cells in seconds:
|
||||
|
||||
**Fingerprinting** is the least likely to produce false positives, so it’s a good place to start. It does the same kind of data-cleaning behind the scenes that you might think to do manually: fix whitespace into single spaces, put all uppercase letters into lowercase, discard punctuation, remove diacritics (e.g. accents) from characters, split up all strings (words) and sort them alphabetically (so “Zhenyi, Wang” becomes “wang zhenyi”).
|
||||
|
||||
**N-gram fingerprinting** allows you to set the _n_ value to whatever number you’d like, and will create n-grams of _n_ size (after doing some cleaning), alphabetize them, then join them back together into a fingerprint. For example, a 1-gram fingerprint will simply organize all the letters in the cell into alphabetical order - by creating segments one character in length. A 2-gram fingerprint will find all the two-character segments, remove duplicates, alphabetize them, and join them back together (for example, “banana” generates “ba an na an na,” which becomes “anbana”).
|
||||
|
||||
This can help match cells that have typos, or incorrect spaces (such as matching “lookout” and “look out,” which fingerprinting itself won’t identify because it separates words). The higher the _n_ value, the fewer clusters will be identified. With 1-grams, keep an eye out for mismatched values that are near-anagrams of each other (such as “Wellington” and “Elgin Town”).
|
||||
|
||||
##### Phonetic clustering {#phonetic-clustering}
|
||||
|
||||
The next four methods are phonetic algorithms: they identify letters that sound the same when pronounced out loud, and assess text values based on that (such as knowing that a word with an “S” might be a mistype of a word with a “Z”). They are great for spotting mistakes made by not knowing the spelling of a word or name after hearing it spoken aloud.
|
||||
|
||||
**Metaphone3 fingerprinting** is an English-language phonetic algorithm. For example, “Reuben Gevorkiantz” and “Ruben Gevorkyants” share the same phonetic fingerprint in English.
|
||||
|
||||
**Cologne fingerprinting** is another phonetic algorithm, but for German pronunciation.
|
||||
|
||||
**Daitch-Mokotoff** is a phonetic algorithm for Slavic and Yiddish words, especially names. **Baider-Morse** is a version of Daitch-Mokotoff that is slightly more strict.
|
||||
|
||||
Regardless of the language of your data, applying each of them might find different potential matches: for example, Metaphone clusters “Cornwall” and “Corn Hill” and “Green Hill,” while Cologne clusters “Greenvale” and “Granville” and “Cornwall” and “Green Wall.”
|
||||
|
||||
#### Nearest neighbor {#nearest-neighbor}
|
||||
|
||||
**Nearest neighbor** clustering methods are slower than key collision methods. They allow the user to set a radius - a threshold for matching or not matching. OpenRefine uses a “blocking” method first, which sorts values based on whether they have a certain amount of similarity (the default is “6” for a six-character string of identical characters) and then runs the nearest-neighbor operations on those sorted groups.
|
||||
|
||||
We recommend setting the block number to at least 3, and then increasing it if you need to be more strict (for example, if every value with “river” is being matched, you should increase it to 6 or more). Note that bigger block values will take much longer to process, while smaller blocks may miss matches. Increasing the radius will make the matches more lax, as bigger differences will be clustered.
|
||||
|
||||
**Levenshtein distance** counts the number of edits required to make one value perfectly match another. As in the key collision methods above, it will do things like change uppercase to lowercase, fix whitespace, change special characters, etc. Each character that gets changed counts as 1 “distance.” “New York” and “newyork” have an edit distance value of 3 (“N” to “n”; “Y” to “y”; remove the space). It can do relatively advanced edits, such as understand the distance between “M. Makeba” and “Miriam Makeba” (5), but it may create false positives if these distances are greater than other, simpler transformations (such as the one-character distance to “B. Makeba,” another person entirely).
|
||||
|
||||
**PPM (Prediction by Partial Matching)** uses compression to see whether two values are similar or different. In practice, this method is very lax even for small radius values and tends to generate many false positives, but because it operates at a sub-character level it is capable of finding substructures that are not easily identifiable by distances that work at the character level. So it should be used as a “last resort” clustering method. It is also more effective on longer strings than on shorter ones.
|
||||
|
||||
For more of the theory behind clustering, see [Clustering In Depth](https://github.com/OpenRefine/OpenRefine/wiki/Clustering-In-Depth).
|
||||
|
||||
## Replace {#replace}
|
||||
|
||||
OpenRefine provides a find/replace function for you to edit your data. Selecting <span class="menuItems">Edit cells</span> → <span class="menuItems">Replace</span> will bring up a simple window where you can input a string to search and a string to replace it with. You can set case-sensitivity, and set it to only select whole words, defined by a string with spaces or punctuation around it (to prevent, for example, “house” selecting the “house” part of “doghouse”). You can use [regular expressions](expressions#regular-expressions) in this field. You may wish to preview the results of this operation by testing it with a [Text filter](facets#text-filter) first.
|
||||
|
||||
You can also perform a sort of find/replace operation by editing one cell, and selecting “apply to all identical cells.”
|
||||
|
||||
## Edit one cell at a time {#edit-one-cell-at-a-time}
|
||||
|
||||
You can edit individual cells by hovering your mouse over that cell. You should see a tiny blue link labeled “edit.” Click it to edit the cell. That pops up a window with a bigger text field for you to edit. You can change the [data type](exploring#data-types) of that cell, and you can apply these changes to all identical cells (in the same column), using this pop-up window.
|
||||
|
||||
You will likely want to avoid doing this except in rare cases - the more efficient means of improving your data will be through automated and bulk operations.
|
||||
@ -1,124 +0,0 @@
|
||||
---
|
||||
id: columnediting
|
||||
title: Column editing
|
||||
sidebar_label: Column editing
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
Column editing contains some of the most powerful data-improvement methods in OpenRefine. The operations in the <span class="menuItems">Edit column</span> menu involve using one column of data to add entirely new columns and fields to your dataset.
|
||||
|
||||
## Splitting or joining {#splitting-or-joining}
|
||||
|
||||
Many users find that they frequently need to make their data more granular: for example, splitting a “Firstname Lastname” column into two columns, one for first names and one for last names. The reverse is also often true: you may have several columns of category values that you want to join into one “category” column.
|
||||
.
|
||||
### Split into several columns {#split-into-several-columns}
|
||||
|
||||

|
||||
|
||||
You can find this operation at <span class="menuItems">Edit column</span> → <span class="menuItems">Split into several columns...</span>. Splitting one column into several columns requires you to identify the character, string lengths, or evaluating expression you want to split on. Just like [splitting multi-valued cells into rows](cellediting#split-multi-valued-cells), splitting cells into multiple columns will remove the separator character or string you indicate. Splitting by lengths will discard any information that comes after the specified total length.
|
||||
|
||||
You can also specify a maximum number of new columns to be made: separator characters after this limit will be ignored, and the remaining characters will end up in the last column.
|
||||
|
||||
New columns will be named after the original column, with a number: “Location 1,” “Location 2,” etc. You can choose to remove the original column with this operation, and you can have [data types](exploring#data-types) identified where possible. This function will work best with converting strings to numbers, and may not work with [dates](exploring#dates).
|
||||
|
||||
### Join columns {#join-columns}
|
||||
|
||||

|
||||
|
||||
You can join columns by selecting <span class="menuItems">Edit column</span> → <span class="menuItems">Join columns...</span>. All the columns currently in your dataset will appear in the pop-up window. You can select or un-select all the columns you want to join, and drag columns to put them in the order you want to join them in. You will define a separator character (optional) and define a string to insert into empty cells (nulls).
|
||||
|
||||
The joined data will appear in the column you originally selected, or you can create a new column for this content and specify a name. You can delete all the columns that were used in this join operation.
|
||||
|
||||
## Add column based on this column {#add-column-based-on-this-column}
|
||||
|
||||
Selecting <span class="menuItems">Edit column</span> → <span class="menuItems">Add column based on this column...</span> will open up an [expressions](expressions) window where you can transform the data from this column (using `value`), or write a more complex expression that takes information from any number of columns or from external sources.
|
||||
|
||||
Expressions used in this operation will rely on your knowledge of variables. You can learn more in the [Expressions section on variables](expressions#variables).
|
||||
|
||||
The simplest way to use this operation is simply leave the default `value` in the expression field, to create an exact copy of your column. For a column of [reconciled data](reconciling), you can use the variable `cell` instead, to copy both the original string and the existing reconciliation data. This will include matched values, candidates, and new items.
|
||||
|
||||
One useful expression is to create a column based on concatenating (merging) two other columns. Select either of the source columns, choose <span class="menuItems">Edit column</span> → <span class="menuItems">Add column based on this column...</span>, name your new column, and use the following format in the expression window:
|
||||
|
||||
```
|
||||
cells["Column 1"].value + cells["Column 2"].value
|
||||
```
|
||||
|
||||
If your column names do not contain spaces, you can use the following format instead:
|
||||
|
||||
```
|
||||
cells.Column1.value + cells.Column2.value
|
||||
```
|
||||
|
||||
If you are in records mode instead of rows mode, you can concatenate using the following format:
|
||||
|
||||
```
|
||||
row.record.cells.Column1.value + row.record.cells.Column2.value
|
||||
```
|
||||
|
||||
You may wish to add separators or spaces, or modify your input during this operation with more advanced expressions.
|
||||
|
||||
## Add column by fetching URLs {#add-column-by-fetching-urls}
|
||||
|
||||
Through the <span class="menuItems">Add column by fetching URLs</span> function, OpenRefine supports the ability to fetch HTML or data from web pages or services. In this operation you will be building URL strings based on your column of data, by using `value` to insert a relevant substring. Your chosen column needs to contains parts of paths to valid HTML pages or files online.
|
||||
|
||||
If you have a column of URLs and want to fetch the information that they point to, you can simply run the expression as `value`. If your column has, for example, unique identifiers for Wikidata entities (numerical values starting with Q), you can download the JSON-formatted metadata about each entity with
|
||||
|
||||
```
|
||||
"https://www.wikidata.org/wiki/Special:EntityData/" + value + ".json"
|
||||
```
|
||||
|
||||
or whatever metadata format you prefer. Information about the format options in Wikidata can be found [here](https://www.wikidata.org/wiki/Wikidata:Data_access). The service you are fetching data from may have similar documentation on its provided options.
|
||||
|
||||

|
||||
|
||||
This service is more useful when getting metadata files instead of HTML, but you may wish to work with a page’s entire HTML contents and then parse out information from that.
|
||||
|
||||
:::caution
|
||||
Be aware that the fetching process can take quite some time and that servers may not want to fulfill hundreds or thousands of page requests in seconds. Fetching allows you to set a “throttle delay” which determines the amount of time between requests. The default is 5 seconds per row in your dataset (5000 milliseconds). We recommend leaving this at 1000 or greater.
|
||||
:::
|
||||
|
||||
Note the following:
|
||||
* Before pressing “OK,” copy and paste a URL or two from the preview and test them in another browser tab to make sure they work.
|
||||
* In some situations you may need to set [HTTP request headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers). To set these, click the small “Show” button next to “HTTP headers to be used when fetching URLs” in the settings window. The authorization credentials get logged in your operation history in plain text, which may be a security concern for you. You can set the following request headers:
|
||||
* [User-Agent](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent)
|
||||
* [Accept](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Accept)
|
||||
* [Authorization](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Authorization)
|
||||
|
||||
### Common errors {#common-errors}
|
||||
|
||||
When OpenRefine attempts to fetch information from a web service, it can fail in a variety of ways. The following information is meant to help troubleshoot and fix problems encountered when using this function.
|
||||
|
||||
First, make sure that your fetching operation is storing errors (check “store error”). Then run the fetch and look at the error messages.
|
||||
|
||||
**“HTTP error 403 : Forbidden”** can be simply down to you not having access to the URL you are trying to use. If you can access the same URL with your browser, the remote site may be blocking OpenRefine because it doesn't recognize its request as valid. Changing the [User-Agent](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent) request header may help. If you believe you should have access to a site but are “forbidden,” you may wish to contract the administrators.
|
||||
|
||||
**“HTTP error 404 : Not Found”** indicates that the information you are requesting does not exist, perhaps due to a problem with your cell values if it only happening in certain rows.
|
||||
|
||||
**“HTTP error 500 : Internal Server Error”** indicates the remote server is having a problem filling your request. You may wish to simply wait and try again later, or double-check the URLs.
|
||||
|
||||
**“error: javax.net.ssl.SSLHandshakeException: Received fatal alert: handshake_failure”** can occur when you are trying to retrieve information over HTTPS but the remote site is using an encryption not supported by the Java virtual machine being used by OpenRefine.
|
||||
|
||||
You can check which encryption methods are supported by your OpenRefine/Java installation by using a service such as **How's my SSL**. Add the URL `https://www.howsmyssl.com/a/check` to an OpenRefine cell and run “Add column by fetching URLs” on it, which will provide a description of the SSL client being used.
|
||||
|
||||
You can try installing additional encryption supports by installing the [Java Cryptography Extension](https://www.oracle.com/java/technologies/javase-jce8-downloads.html).
|
||||
Note that for Mac users and for Windows users with the OpenRefine installation with bundled JRE, these updated cipher suites need to be dropped into the Java install within the OpenRefine application:
|
||||
|
||||
* On Mac, it will look something like `/Applications/OpenRefine.app/Contents/PlugIns/jdk1.8.0_60.jdk/Contents/Home/jre/lib/security`.
|
||||
* On Windows: `\server\target\jre\lib\security`.
|
||||
|
||||
**“javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed”** can appear when the remote site is using an HTTPS certificate not trusted by your local Java installation. You will need to make sure that the certificate, or (more likely) the root certificate, is trusted.
|
||||
|
||||
The list of trusted certificates is stored in an encrypted file called `cacerts` in your local Java installation. This can be read and updated by a tool called “keytool.” You can find directions on how to add a security certificate to the list of trusted certificates for a Java installation [here](http://magicmonster.com/kb/prg/java/ssl/pkix_path_building_failed.html) and [here](http://javarevisited.blogspot.co.uk/2012/03/add-list-certficates-java-keystore.html).
|
||||
|
||||
Note that for Mac users and for Windows users with the OpenRefine installation with bundled JRE, the `cacerts` file within the OpenRefine application needs to be updated.
|
||||
|
||||
* On Mac, it will look something like `/Applications/OpenRefine.app/Contents/PlugIns/jdk1.8.0_60.jdk/Contents/Home/jre/lib/security/cacerts`.
|
||||
* On Windows: `\server\target\jre\lib\security\`.
|
||||
|
||||
## Renaming, removing, and moving {#renaming-removing-and-moving}
|
||||
|
||||
Every column's <span class="menuItems">Edit column</span> dropdown contains options to move it (to the beginning, end, left, or right), rename it, and delete it.
|
||||
These operations can be undone, but a removed column cannot be restored later if you keep modifying your data. If you wish to temporarily hide a column, go to <span class="menuItems">[View](sortview#view)</span> → <span class="menuItems">Collapse this column</span> instead.
|
||||
|
||||
Be cautious about moving columns in [records mode](cellediting#rows-vs-records): if you change the first column in your dataset (the key column), your records may change in unintended ways.
|
||||
@ -1,116 +0,0 @@
|
||||
---
|
||||
id: exploring
|
||||
title: Exploring data
|
||||
sidebar_label: Overview
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
OpenRefine offers lots of features to help you learn about your dataset, even if you don’t change a single character. In this section we cover different ways for sorting through, filtering, and viewing your data.
|
||||
|
||||
Unlike spreadsheets, OpenRefine doesn’t store formulas and display the output of those calculations; it only shows the value inside each cell. It doesn’t support cell colors or text formatting.
|
||||
|
||||
## Data types {#data-types}
|
||||
|
||||
Each piece of information (each cell) in OpenRefine is assigned a data type. Some file formats, when imported, can set data types that are recognized by OpenRefine. Cells without an associated data type on import will be considered a “string” at first, but you can have OpenRefine convert cell contents into other data types later. This is set at the cell level, not at the column level.
|
||||
|
||||
You can see data types in action when you preview a new project: check the box next to <span class="fieldLabels">Attempt to parse cell text into numbers</span>, and cells will be converted to the “number” data type based on their contents. You’ll see numbers change from black text to green if they are recognized.
|
||||
|
||||
The data type will determine what you can do with the value. For example, if you want to add two values together, they must both be recognized as the number type.
|
||||
|
||||
You can check data types at any time by:
|
||||
* clicking “edit” on a single cell (where you can also edit the type)
|
||||
* creating a <span class="menuItems">Custom Text Facet</span> on a column, and inserting `type(value)` into the <span class="fieldLabels">Expression</span> field. This will generate the data type in the preview, and you can facet by data type if you press <span class="buttonLabels">OK</span>.
|
||||
|
||||
The data types supported are:
|
||||
* string (one or more text characters)
|
||||
* number (one or more characters of numbers only)
|
||||
* boolean (values of “true” or “false”)
|
||||
* [date](#dates) (ISO-8601-compliant extended format with time in UTC: YYYY-MM-DDTHH:MM:SSZ)
|
||||
|
||||
OpenRefine recognizes two further data types as a result of its own processes:
|
||||
* error
|
||||
* null
|
||||
|
||||
An “error” data type is created when the cell is storing an error generated during a transformation in OpenRefine.
|
||||
|
||||
A “null” data type is a special type that means “this cell has no value.” It’s distinct from cells that have values such as “0” or “false”, or cells that look empty but have whitespace in them, or cells that contain empty strings. When you use `type(value)`, it will show you that the cell’s value is “null” and its type is “undefined.” You can opt to [show “null” values](sortview#showhide-null), by going to <span class="menuItems">All</span> → <span class="menuItems">View</span> → <span class="menuItems">Show/Hide ‘null’ values in cells</span>.
|
||||
|
||||
Changing a cell's data type is not the same operation as transforming its contents. For example, using a column-wide transform such as <span class="menuItems">Transform</span> → <span class="menuItems">Common transforms</span> → <span class="menuItems">To date</span> may not convert all values successfully, but going to an individual cell, clicking “edit”, and changing the data type can successfully convert text to a date. These operations use different underlying code. Learn more about date formatting and transformations in the next section.
|
||||
|
||||
To transform data from one type to another, see [Transforming data](cellediting#data-type-transforms) for information on using common tranforms, and see [Expressions](expressions) for information on using [toString()](grelfunctions#tostringo-string-format-optional), [toDate()](grelfunctions#todateo-b-monthfirst-s-format1-s-format2-), and other functions.
|
||||
|
||||
|
||||
### Dates {#dates}
|
||||
|
||||
A “date” type is created when a column is [transformed into dates](transforming#to-date), when an expression is used to [convert cells to dates](grelfunctions#todateo-b-monthfirst-s-format1-s-format2-) or when individual cells are set to have the data type “date”.
|
||||
|
||||
Date-formatted data in OpenRefine relies on a number of conversion tools and standards. For something to be considered a date in OpenRefine, it will be converted into the ISO-8601-compliant extended format with time in UTC: YYYY-MM-DDTHH:MM:SSZ.
|
||||
|
||||
When you run <span class="menuItems">Edit cells</span> → <span class="menuItems">Common transforms</span> → <span class="menuItems">To date</span>, the following column of strings on the left will transform into the values on the right:
|
||||
|
||||
|Input|→|Output|
|
||||
|---|---|---|
|
||||
|23/12/2019|→|2019-12-23T00:00:00Z|
|
||||
|14-10-2015|→|2015-10-14T00:00:00Z|
|
||||
|2012 02 16|→|2012-02-16T00:00:00Z|
|
||||
|August 2nd 1964|→|1964-08-02T00:00:00Z|
|
||||
|today|→|today|
|
||||
|never|→|never|
|
||||
|
||||
OpenRefine uses a variety of tools to recognize, convert, and format [dates](exploring#dates) and so some of the values above can be reformatted using other methods. In this case, clicking the “today” cell and editing its data type manually will convert “today” into a value such as “2020-08-14T00:00:00Z”. Attempting the same data-type change on “never” will give you an error message and refuse to proceed.
|
||||
|
||||
You can do more precise conversion and formatting using expressions and arguments based on the state of your data: see the GREL functions reference section on [Date functions](grelfunctions#date-functions) for more help.
|
||||
|
||||
You can convert dates into a more human-readable format when you [export your data using the custom tabular exporter](exporting#custom-tabular-exporter). You are given the option to keep your dates in the ISO 8601 format, to output short, medium, long, or full locale formats, or to specify a custom format. This means that you can format your dates into, for example, MM/DD/YY (the US short standard) with or without including the time, after working with ISO-8601-formatted dates in your project.
|
||||
|
||||
The following table shows some example [date and time formatting styles for the U.S. and French locales](https://docs.oracle.com/javase/tutorial/i18n/format/dateFormat.html):
|
||||
|
||||
|Style |U.S. Locale |French Locale|
|
||||
|---|---|---|
|
||||
|Default |Jun 30, 2009 7:03:47 AM |30 juin 2009 07:03:47|
|
||||
|Short |6/30/09 7:03 AM |30/06/09 07:03|
|
||||
|Medium |Jun 30, 2009 7:03:47 AM |30 juin 2009 07:03:47|
|
||||
|Long |June 30, 2009 7:03:47 AM PDT |30 juin 2009 07:03:47 PDT|
|
||||
|Full |Tuesday, June 30, 2009 7:03:47 AM PDT |mardi 30 juin 2009 07 h 03 PDT|
|
||||
|
||||
## Rows vs. records {#rows-vs-records}
|
||||
|
||||
A row is a simple way to organize data: a series of cells, one cell per column. Sometimes there are multiple pieces of information in one cell, such as when a survey respondent can select more than one response.
|
||||
|
||||
In cases where there is more than one value for a single column in one or more rows, you may wish to use OpenRefine’s records mode: this defines a single record as potentially containing more than one row. From there you can transform cells into multiple rows, each cell containing one value you’d like to work with.
|
||||
|
||||
Generally, when you import some data, OpenRefine reads that data in row mode. From the project screen, you can convert the project into records mode. OpenRefine remembers this action and will present you with records mode each time you open the project from then on.
|
||||
|
||||
OpenRefine understands records based on the content of the first column, what we call the “key column.” Splitting a row into a multi-row record will base all association on the first column in your dataset.
|
||||
|
||||
If you have more than one column to split out into multiple rows, OpenRefine will keep your data associated with its original record, and associate subgroups based on the top-most row in each group.
|
||||
|
||||
You can imagine the structure as a tree with many branches, all leading back to the same trunk.
|
||||
|
||||
For example, your key column may be a film or television show, with multiple cast members identified by name, associated to that work. You may have one or more roles listed for each person. The roles are linked to the actors, which are linked to the title.
|
||||
|
||||
|Work|Actor|Role|
|
||||
|---|---|---|
|
||||
|The Wizard of Oz|Judy Garland|Dorothy Gale|
|
||||
||Ray Bolger|"Hunk"|
|
||||
|||The Scarecrow|
|
||||
||Jack Haley|"Hickory"|
|
||||
|||The Tin Man|
|
||||
||Bert Lahr|"Zeke"|
|
||||
|||The Cowardly Lion|
|
||||
||Frank Morgan|Professor Marvel|
|
||||
|||The Gatekeeper|
|
||||
|||The Carriage Driver|
|
||||
|||The Guard|
|
||||
|||The Wizard of Oz|
|
||||
||Margaret Hamilton|Miss Almira Gulch|
|
||||
|||The Wicked Witch of the West|
|
||||
|
||||
Once you are in records mode, you can still move some columns around, but if you move a column to the beginning, you may find your data becomes misaligned. The new key column will sort into records based on empty cells, and values in the old key column will be assigned to the last row in the old record (the key value sitting above those values).
|
||||
|
||||
OpenRefine assigns a unique key behind the scenes, so your records don’t need a unique identifier in the key column. You can keep track of which rows are assigned to each record by the record number that appears under the <span class="menuItems">All</span> column.
|
||||
|
||||
To [split multi-valued cells](transforming#split-multi-valued-cells) and apply other operations that take advantage of records mode, see [Transforming data](transforming).
|
||||
|
||||
Be careful when in records mode that you do not accidentally delete rows based on being blank in one column where there is a value in another.
|
||||
@ -1,134 +0,0 @@
|
||||
---
|
||||
id: exporting
|
||||
title: Exporting your work
|
||||
sidebar_label: Exporting
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
Once your dataset is ready, you will need to get it out of OpenRefine and into the system of your choice. OpenRefine outputs a number of file formats, can upload your data directly into Google Sheets, and can create or update statements on Wikidata.
|
||||
|
||||
You can also [export your full project data](#export-a-project) so that it can be opened by someone else using OpenRefine (or yourself, on another computer).
|
||||
|
||||
## Export data {#export-data}
|
||||
|
||||

|
||||
|
||||
Many of the options only export data in the current view - that is, with current filters and facets applied. Some will give you the choice to export your entire dataset or just the currently-viewed rows.
|
||||
|
||||
To export data from a project, click the <span class="menuItems">Export</span> dropdown button in the top right corner and pick the format you want. Your options are:
|
||||
|
||||
* Tab-separated value (TSV) or Comma-separated value (CSV)
|
||||
* HTML-formatted table
|
||||
* Excel spreadsheet (XLS or XLSX)
|
||||
* Open Document Format (ODF) spreadsheet (ODS)
|
||||
* Upload to Google Sheets (requires [Google account authorization](starting#google-sheet-from-drive))
|
||||
* [Custom tabular exporter](#custom-tabular-exporter)
|
||||
* [SQL statement exporter](#sql-statement-exporter)
|
||||
* [Templating exporter](#templating-exporter), which generates JSON by default
|
||||
|
||||
You can also export reconciled data to Wikidata, or export your Wikidata schema for future use with other OpenRefine projects:
|
||||
|
||||
* [Upload edits to Wikidata](wikibase/uploading#uploading-with-openrefine)
|
||||
* [Export to QuickStatements](wikibase/uploading#uploading-with-quickstatements) (version 1)
|
||||
* [Export Wikidata schema](wikibase/overview#import-and-export-schema)
|
||||
|
||||
### Custom tabular exporter {#custom-tabular-exporter}
|
||||
|
||||

|
||||
|
||||
With the custom tabular exporter, you can choose which of your data to export, the separator you wish to use, and whether you'd like to download the result to your computer or upload it into a Google Sheet.
|
||||
|
||||
On the <span class="tabLabels">Content</span> tab, you can drag and drop the columns appearing in the column list to reorder the output. The options for reconciled and date data are applied to each column individually.
|
||||
|
||||
This exporter is especially useful with reconciled data, as you can choose whether you wish to output the cells' original values, the matched values, or the matched IDs. Ouputting “match entity's name”, “matched entity's ID”, or “cell's content” will output, respectively, the contents of `cell.recon.match.name`, `cell.recon.match.id`, and `cell.value`.
|
||||
|
||||
“Output nothing for unmatched cells” will export empty cells for both newly-created matches and cells with no chosen matches. “Link to matched entity's page” will produce hyperlinked text in an HTML table output, but have no effect in other formats.
|
||||
|
||||
At this time, the date-formatting options in this window do not work. You can [keep track of this issue on Github](https://github.com/OpenRefine/OpenRefine/issues/3368).
|
||||
In the future, you will be able to choose how to [output date-formatted cells](exploring#dates). You can create a custom date output by using [formatting according to the SimpleDateFormat parsing key found here](grelfunctions#todateo-b-monthfirst-s-format1-s-format2-).
|
||||
|
||||

|
||||
|
||||
On the <span class="tabLabels">Download</span> tab, you can generate a preview of how the first ten rows of your dataset will output. If you do not choose one of the file formats on the right, the <span class="buttonLabels">Download</span> button will generate a text file. On the <span class="tabLabels">Upload</span> tab, you can create a new Google Sheet.
|
||||
|
||||
With the <span class="tabLabels">Option Code</span> tab, you can copy JSON of your current custom settings to reuse on another export, or you can paste in existing JSON settings to apply to the current project.
|
||||
|
||||
### SQL exporter {#sql-exporter}
|
||||
|
||||
The SQL exporter creates a SQL statement containing the data you’ve exported, which you can use to overwrite or add to an existing database. Choosing <span class="menuItems">Export</span> → <span class="menuItems">SQL exporter</span> will bring up a window with two tabs: one to define what data to output, and another to modify other aspects of the SQL statement, with options to preview and download the statement.
|
||||
|
||||

|
||||
|
||||
The <span class="tabLabels">Content</span> tab allows you to craft your dataset into an SQL table. From here, you can choose which columns to export, the data type to export for each (or choose "VARCHAR"), and the maximum character length for each field (if applicable based on the data type). You can set a default value for empty cells after unchecking “Allow null” in one or more columns.
|
||||
|
||||
With this output tool, you can choose whether to output only currently visible rows, or all the rows in your dataset, as well as whether to include empty rows. The option to “Trim column names” will remove their whitespace characters.
|
||||
|
||||

|
||||
|
||||
The <span class="tabLabels">Download</span> tab allows you to finalize your complete SQL statement.
|
||||
|
||||
<span class="fieldLabels">Include schema</span> means that you will start your statement with the creation of a table. Without that, you will only have an INSERT statement.
|
||||
|
||||
<span class="fieldLabels">Include content</span> means including the INSERT statement with data from your project. Without that, you will only create empty columns.
|
||||
|
||||
You can include DROP and IF EXISTS if you require them, and set a name for the table to which the statement will refer.
|
||||
|
||||
You can then preview your statement, which will open up a new browser tab/window showing a statement with the first ten rows of your data (if included), or you can save a `.sql` file to your computer.
|
||||
|
||||
### Templating exporter {#templating-exporter}
|
||||
|
||||
If you pick <span class="menuItems">Templating…</span> from the <span class="menuItems">Export</span> dropdown menu, you can “roll your own” exporter. This is useful for formats that we don't support natively yet, or won't support. The Templating exporter generates JSON by default.
|
||||
|
||||

|
||||
|
||||
The Templating Export window allows you to set your own separators, prefix, and suffix to create a complete dataset in the language of your choice. In the <span class="fieldLabels">Row template</span> section, you can choose which columns to generate from each row by calling them with [variables](expressions#variables).
|
||||
|
||||
This can be used to:
|
||||
* output [reconciliation data](expressions#reconciliation), such as `cells["ColumnName"].recon.match.name`
|
||||
* create multiple columns of output from different [member fields](expressions#variables) of a single project column
|
||||
* employ [expressions](expressions) to modify data for output: for example, `cells["ColumnName"].value.toUppercase()`.
|
||||
|
||||
Anything that appears inside doubled curly braces ({{ }}) is treated as a GREL expression; anything outside is generated as straight text. You can use Jython or Clojure by declaring it at the start:
|
||||
```
|
||||
{{jython:return cells["ColumnName"].value}}
|
||||
```
|
||||
|
||||
:::caution
|
||||
Note that some syntax is different in this tool than elsewhere in OpenRefine: a forward slash must be escaped with a backslash, while other characters do not need escaping. You cannot, at this time, include a closing curly brace (}) anywhere in your expression, or it will cause it to malfunction.
|
||||
:::
|
||||
|
||||
You can include [regular expressions](expressions#regular-expressions) as usual (inside forward slashes, with any GREL function that accepts them). For example, you could output a version of your cells with punctuation removed, using an expression such as
|
||||
```
|
||||
{{jsonize(cells["ColumnName"].value.replaceChars("/[.!?$&,/]/",""))}}
|
||||
```
|
||||
|
||||
You could also simply output a plain-text document inserting data from your project into sentences: for example, "In `{{cells["Year"].value}}` we received `{{cells["RequestCount"].value}}` requests."
|
||||
|
||||
You can use the shorthand `${ColumnName}` (no need for quotes) to insert column values directly. You cannot use this inside an expression, because of the closing curly brace.
|
||||
|
||||
If your projects is in records mode, the <span class="fieldLabels">Row separator</span> field will insert a separator between records, rather than individual rows. Rows inside a single record will be directly appended to one another as per the content in the <span class="fieldLabels">Row Template</span> field.
|
||||
|
||||
Once you have created your template, you may wish to save the text you produced in each field, in order to reuse it in the future. Once you click <span class="buttonLabels">Export</span> OpenRefine will output a simple `.txt` file, and your template will be discarded.
|
||||
|
||||
We have recipes on using the Templating exporter to [produce several different formats](https://github.com/OpenRefine/OpenRefine/wiki/Recipes#12-templating-exporter).
|
||||
|
||||
## Export a project {#export-a-project}
|
||||
|
||||
You can share a project in progress with another computer, a colleague, or with someone who wants to check your history. This can be useful for showing that your data cleanup didn’t distort or manipulate the information in any way. Once you have exported a project, another OpenRefine installation can [import it as a new project](starting#import-a-project).
|
||||
|
||||
You can either save it locally or upload it to Google Drive (which requires you to authorize a Google account).
|
||||
|
||||
:::caution
|
||||
OpenRefine project archives contain confidential data from previous steps, which will still be accessible to anyone who has the archive. If you are hoping to keep your original dataset hidden for privacy reasons, such as using OpenRefine to anonymize information, do not share your project archive.
|
||||
:::
|
||||
|
||||
To save your project archive locally: from the <span class="menuItems">Export</span> dropdown, select <span class="menuItems">OpenRefine project archive to file</span>. OpenRefine exports your full project with all of its history. It does not export any current views or applied facets. Existing reconciliation information will be preserved, but the importing computer will need to add the same reconciliation services to keep working with that data.
|
||||
|
||||
OpenRefine exports files in `.tar.gz` format. You can rename the file when you save it; otherwise it will bear the project name.
|
||||
|
||||
To save your project archive to Google Drive: from the <span class="menuItems">Export</span> dropdown, select <span class="menuItems">OpenRefine project archive to Google Drive...</span>. OpenRefine will not share the link with you, only confirm that the file was uploaded.
|
||||
|
||||
## Export operations {#export-operations}
|
||||
|
||||
You can [save and re-apply the history of any project](running#reusing-operations) (all the operations shown in the Undo/Redo tab). This creates JSON that you can save for later reuse on another OpenRefine project.
|
||||
@ -1,208 +0,0 @@
|
||||
---
|
||||
id: expressions
|
||||
title: Expressions
|
||||
sidebar_label: Overview
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
You can use expressions in multiple places in OpenRefine to extend data cleanup and transformation. Expressions are available with the following functions:
|
||||
* <span class="menuItems">Facet</span>:
|
||||
|
||||
* <span class="menuItems">Custom text facet...</span>
|
||||
* <span class="menuItems">Custom numeric facet…</span>
|
||||
* <span class="menuItems">Customized facets</span> (click “change” after they have been created to bring up an expressions window)
|
||||
* <span class="menuItems">Edit cells</span>:
|
||||
|
||||
* <span class="menuItems">Transform…</span>
|
||||
* <span class="menuItems">Split multi-valued cells…</span>
|
||||
* <span class="menuItems">Join multi-valued cells…</span>
|
||||
* <span class="menuItems">Edit column</span>:
|
||||
|
||||
* <span class="menuItems">Split</span>
|
||||
* <span class="menuItems">Join</span>
|
||||
* <span class="menuItems">Add column based on this column</span>
|
||||
* <span class="menuItems">Add column by fetching URLs</span>.
|
||||
|
||||
In the expressions editor window you have the opportunity to select a supported language. The default is [GREL (General Refine Expression Language)](grel); OpenRefine also comes with support for [Clojure](jythonclojure#clojure) and [Jython](jythonclojure#jython). Extensions may offer support for more expressions languages.
|
||||
|
||||
These languages have some syntax differences but support many of the same [variables](#variables). For example, the GREL expression `value.split(" ")[1]` would be written in Jython as `return value.split(" ")[1]`.
|
||||
|
||||
This page is a general reference for available functions, variables, and syntax. For examples that use these expressions for common data tasks, look at the [Recipes section on the wiki](https://github.com/OpenRefine/OpenRefine/wiki/Documentation-For-Users#recipes-and-worked-examples).
|
||||
|
||||
## Expressions {#expressions}
|
||||
|
||||
There are significant differences between OpenRefine's expressions and the spreadsheet formulas you may be used to using for data manipulation. OpenRefine does not store formulas in cells and display output dynamically: OpenRefine’s transformations are one-time operations that can change column contents or generate new columns. These are applied using variables such as `value` or `cell` to perform the same modification to each cell in a column.
|
||||
|
||||
Take the following example:
|
||||
|
||||
|ID|Friend|Age|
|
||||
|---|---|---|
|
||||
|1.|John Smith|28|
|
||||
|2.|Jane Doe|33|
|
||||
|
||||
Were you to apply a transformation to the “friend” column with the expression
|
||||
|
||||
```
|
||||
value.split(" ")[1]
|
||||
```
|
||||
|
||||
OpenRefine would work through each row, splitting the “friend” values based on a space character. The `value` for row 1 is “John Smith” so the output would be “Smith” (as "[1]" selects the second part of the created output); the `value` for row 2 is “Jane Doe” so the output would be “Doe”. Using variables, a single expression yields different results for different rows. The old information would be discarded; you couldn't get "John" and "Jane" back unless you undid the operation in the [History](running#history-undoredo) tab.
|
||||
|
||||
For another example, if you were to create a new column based on your data using the expression `row.starred`, it would generate a column of true and false values based on whether your rows were starred at that moment. If you were to then star more rows and unstar some rows, that data would not dynamically update - you would need to run the operation again to have current true/false values.
|
||||
|
||||
Note that an expression is typically based on one particular column in the data - the column whose drop-down menu is first selected. Many variables are created to stand for things about the cell in that “base column” of the current row on which the expression is evaluated. There are also variables about rows, which you can use to access cells in other columns.
|
||||
|
||||
## The expressions editor {#the-expressions-editor}
|
||||
|
||||
When you select a function that accepts expressions, you will see a window overlay the screen with what we call the expressions editor.
|
||||
|
||||

|
||||
|
||||
The expressions editor offers you a field for entering your formula and shows you a preview of its transformation on your first few rows of cells.
|
||||
|
||||
There is a dropdown menu from which you can choose an expression language. The default at first is GREL; if you begin working with another language, that selection will persist across OpenRefine. Jython and Clojure are also offered with the installation package, and you may be able to add more language support with third-party extensions and customizations.
|
||||
|
||||
There are also tabs for:
|
||||
* <span class="tabLabels">History</span>, which shows you formulas you’ve recently used from across all your projects
|
||||
* <span class="tabLabels">Starred</span>, which shows you formulas from your History that you’ve starred for reuse
|
||||
* <span class="tabLabels">Help</span>, a quick reference to GREL functions.
|
||||
|
||||
Starring formulas you’ve used in the past can be helpful for repetitive tasks you’re performing in batches.
|
||||
|
||||
You can also choose how formula errors are handled: replicate the original cell value, output an error message into the cell, or ouput a blank cell.
|
||||
|
||||
## Regular expressions {#regular-expressions}
|
||||
|
||||
OpenRefine offers several fields that support the use of regular expressions (regex), such as in a <span class="menuItems">Text filter</span> or a <span class="menuItems">Replace…</span> operation. GREL and other expressions can also use regular expression markup to extend their functionality.
|
||||
|
||||
If this is your first time working with regex, you may wish to read [this tutorial specific to the Java syntax that OpenRefine supports](https://docs.oracle.com/javase/tutorial/essential/regex/). We also recommend this [testing and learning tool](https://regexr.com/).
|
||||
|
||||
### GREL-supported regex {#grel-supported-regex}
|
||||
|
||||
To write a regular expression inside a GREL expression, wrap it between a pair of forward slashes (/) much like the way you would in Javascript. For example, in
|
||||
|
||||
```
|
||||
value.replace(/\s+/, " ")
|
||||
```
|
||||
|
||||
the regular expression is `\s+`, and the syntax used in the expression wraps it with forward slashes (`/\s+/`). Though the regular expression syntax in OpenRefine follows that of Java (normally in Java, you would write regex as a string and escape it like "\\s+"), a regular expression within a GREL expression is similar to Javascript.
|
||||
|
||||
Do not use slashes to wrap regular expressions outside of a GREL expression.
|
||||
|
||||
On the [GREL functions](grelfunctions) page, functions that support regex will indicate that with a “p” for “pattern.” The GREL functions that support regex are:
|
||||
* [contains](grelfunctions#containss-sub-or-p)
|
||||
* [replace](grelfunctions#find-and-replace)
|
||||
* [find](grelfunctions#find-and-replace)
|
||||
* [match](grelfunctions#matchs-p)
|
||||
* [partition](grelfunctions#partitions-s-or-p-fragment-b-omitfragment-optional)
|
||||
* [rpartition](grelfunctions#rpartitions-s-or-p-fragment-b-omitfragment-optional)
|
||||
* [split](grelfunctions#splits-s-or-p-sep-b-preservetokens-optional)
|
||||
* [smartSplit](grelfunctions#smartsplits-s-or-p-sep-optional)
|
||||
|
||||
### Jython-supported regex {#jython-supported-regex}
|
||||
|
||||
You can also use [regex with Jython expressions](http://www.jython.org/docs/library/re.html), instead of GREL, for example with a <span class="menuItems">Custom Text Facet</span>:
|
||||
|
||||
```
|
||||
python import re g = re.search(ur"\u2014 (.*),\s*BWV", value) return g.group(1)
|
||||
```
|
||||
|
||||
### Clojure-supported regex {#clojure-supported-regex}
|
||||
|
||||
[Clojure](https://clojure.org/reference/reader) uses the same regex engine as Java, and can be invoked with [re-find](http://clojure.github.io/clojure/clojure.core-api.html#clojure.core/re-find), [re-matches](http://clojure.github.io/clojure/clojure.core-api.html#clojure.core/re-matches), etc. You can use the #"pattern" reader macro as described [in the Clojure documentation](https://clojure.org/reference/other_functions#regex). For example, to get the nth element of a returned sequence, you can use the nth function:
|
||||
|
||||
```
|
||||
clojure (nth (re-find #"\u2014 (.*),\s*BWV" value) 1)
|
||||
```
|
||||
|
||||
## Variables {#variables}
|
||||
|
||||
Most OpenRefine variables have attributes: aspects of the variables that can be called separately. We call these attributes “member fields” because they belong to certain variables. For example, you can query a record to find out how many rows it contains with `row.record.rowCount`: `rowCount` is a member field specific to the `record` variable, which is a member field of `row`. Member fields can be called using a dot separator, or with square brackets (`row["record"]`). The square bracket syntax is also used for variables that can call columns by name, for example, `cells["Postal Code"]`.
|
||||
|
||||
|Variable |Meaning |
|
||||
|-|-|
|
||||
| `value` | The value of the cell in the current column of the current row (can be null) |
|
||||
| `row` | The current row |
|
||||
| `row.record` | One or more rows grouped together to form a record |
|
||||
| `cells` | The cells of the current row, with fields that correspond to the column names (or row.cells) |
|
||||
| `cell` | The cell in the current column of the current row, containing value and other attributes |
|
||||
| `cell.recon` | The cell's reconciliation information returned from a reconciliation service or provider |
|
||||
| `rowIndex` | The index value of the current row (the first row is 0) |
|
||||
| `columnName` | The name of the current cell's column, as a string |
|
||||
|
||||
### Row {#row}
|
||||
|
||||
The `row` variable itself is best used to access its member fields, which you can do using either a dot operator or square brackets: `row.index` or `row["index"]`.
|
||||
|
||||
|Field |Meaning |
|
||||
|-|-|
|
||||
| `row.index` | The index value of the current row (the first row is 0) |
|
||||
| `row.cells` | The cells of the row, returned as an array |
|
||||
| `row.columnNames` | An array of the column names of the project. This will report all columns, even those with null cell values in that particular row. Call a column by number with `row.columnNames[3]` |
|
||||
| `row.starred` | A boolean indicating if the row is starred |
|
||||
| `row.flagged` | A boolean indicating if the row is flagged |
|
||||
| `row.record` | The [record](#record) object containing the current row |
|
||||
|
||||
For array objects such as `row.columnNames` you can preview the array using the expressions window, and output it as a string using `toString(row.columnNames)` or with something like:
|
||||
|
||||
```
|
||||
forEach(row.columnNames,v,v).join("; ")
|
||||
```
|
||||
|
||||
### Cells {#cells}
|
||||
|
||||
The `cells` object is used to call information from the columns in your project. For example, `cells.Foo` returns a [cell](#cell) object representing the cell in the column named “Foo” of the current row. If the column name has spaces, use square brackets, e.g., `cells["Postal Code"]`. To get the corresponding column's value inside the `cells` variable, use `.value` at the end, for example, `cells["Postal Code"].value`. There is no `cells.value` - it can only be used with member fields.
|
||||
|
||||
### Cell {#cell}
|
||||
|
||||
A `cell` object contains all the data of a cell and is stored as a single object.
|
||||
|
||||
You can use `cell` on its own in the expressions editor to copy all the contents of a column to another column, including reconciliation information. Although the preview in the expressions editor will only show a small representation (“[object Cell]”), it will actually copy all the cell's data. Try this with <span class="menuItems">Edit Column</span> → <span class="menuItems">Add Column based on this column ...</span>.
|
||||
|
||||
|Field |Meaning |Member fields |
|
||||
|-|-|-|
|
||||
| `cell` | An object containing the entire contents of the cell | .value, .recon, .errorMessage |
|
||||
| `cell.value` | The value in the cell, which can be a string, a number, a boolean, null, or an error | |
|
||||
| `cell.recon` | An object encapsulating reconciliation results for that cell | See the [reconciliation](expressions#reconciliation) section |
|
||||
| `cell.errorMessage` | Returns the message of an *EvalError* instead of the error object itself (use value to return the error object) | .value |
|
||||
|
||||
### Reconciliation {#reconciliation}
|
||||
|
||||
Several of the fields here provide the data used in [reconciliation facets](reconciling#reconciliation-facets). You must type `cell.recon`; `recon` on its own will not work.
|
||||
|
||||
|Field|Meaning |Member fields |
|
||||
|-|-|-|
|
||||
| `cell.recon.judgment` | A string: either “matched”, "new”, "none” | |
|
||||
| `cell.recon.judgmentAction` | A string: either "single” or “similar” (or “unknown”) | |
|
||||
| `cell.recon.judgmentHistory` | A number, the epoch timestamp (in milliseconds) of your judgment | |
|
||||
| `cell.recon.matched` | A boolean, true if judgment is “matched” | |
|
||||
| `cell.recon.match` | The recon candidate that has been matched against this cell (or null) | .id, .name, .type |
|
||||
| `cell.recon.best` | The highest scoring recon candidate from the reconciliation service (or null) | .id, .name, .type, .score |
|
||||
| `cell.recon.features` | An array of reconciliation features to help you assess the accuracy of your matches | .typeMatch, .nameMatch, .nameLevenshtein, .nameWordDistance |
|
||||
| `cell.recon.features.typeMatch` | A boolean, true if your chosen type is “matched” and false if not (or “(no type)” if unreconciled) | |
|
||||
| `cell.recon.features.nameMatch` | A boolean, true if the cell and candidate strings are identical and false if not (or “(unreconciled)”) | |
|
||||
| `cell.recon.features.nameLevenshtein` | A number representing the [Levenshtein distance](https://en.wikipedia.org/wiki/Levenshtein_distance): larger if the difference is greater between value and candidate | |
|
||||
| `cell.recon.features.nameWordDistance` | A number based on the [word similarity](reconciling#reconciliation-facets) | |
|
||||
| `cell.recon.candidates` | An array of the top 3 candidates (default) | .id, .name, .type, .score |
|
||||
|
||||
The `cell.recon.candidates` and `cell.recon.best` objects have a few deeper fields: `id`, `name`, `type`, and `score`. `type` is an array of type identifiers for a list of candidates, or a single string for the best candidate.
|
||||
|
||||
Arrays such as `cell.recon.candidates` and `cell.recon.candidates.type` can be joined into lists and stored as strings with something like:
|
||||
```
|
||||
forEach(cell.recon.candidates,v,v.name).join("; ")
|
||||
```
|
||||
|
||||
### Record {#record}
|
||||
|
||||
A `row.record` object encapsulates one or more rows that are grouped together, when your project is in records mode. You must call it as `row.record`; `record` will not return values.
|
||||
|
||||
|Field|Meaning |
|
||||
|-|-|
|
||||
| `row.record.index` | The index of the current record (starting at 0) |
|
||||
| `row.record.cells` | An array of the [cells](#cells) in the given column of the record |
|
||||
| `row.record.fromRowIndex` | The row index of the first row in the record |
|
||||
| `row.record.toRowIndex` | The row index of the last row in the record + 1 (i.e. the next record) |
|
||||
| `row.record.rowCount` | A count of the number of rows in the record |
|
||||
|
||||
For example, you can facet by number of rows in each record by creating a <span class="menuItems">Custom Numeric Facet</span> (or a <span class="menuItems">Custom Text Facet</span>) and entering `row.record.rowCount`.
|
||||
@ -1,329 +0,0 @@
|
||||
---
|
||||
id: facets
|
||||
title: Exploring facets
|
||||
sidebar_label: Facets
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
Facets are one of OpenRefine’s strongest features - that’s where the diamond logo comes from!
|
||||
|
||||
Faceting allows you to look for patterns and trends. Facets are essentially aspects or angles of data variance in a given column. For example, if you had survey data where respondents indicated one of five responses from “Strongly agree” to “Strongly disagree,” those five responses make up a text facet, showing how many people selected each option.
|
||||
|
||||
Faceted browsing gives you a big-picture look at your data (do they agree or disagree?) and also allows you to filter down to a specific subset to explore it more (what do people who disagree say in other responses?).
|
||||
|
||||
Typically, you create a facet on a particular column. That facet selection appears on the left, in the <span class="tabLabels">Facet/Filter</span> tab, and you can click on a displayed facet to view all the records that match. You can also “exclude” the facet, to view every record that does _not_ match, and you can select more than one facet by clicking “include.”
|
||||
|
||||
|
||||
### An example {#an-example}
|
||||
|
||||
You can learn about facets and filtering with the following example. You can copy the following table and paste it using the <span class="menuItems">Clipboard</span> method of starting a project if you would like to try it yourself.
|
||||
|
||||
We collected a list of the [10 most populous cities from Wikidata](https://w.wiki/3Em), using an example query of theirs. We removed the GPS coordinates and added the country.
|
||||
|
||||
| cityLabel | population | countryLabel |
|
||||
|-|-|-|
|
||||
| Shanghai | 23390000 | People's Republic of China |
|
||||
| Beijing | 21710000 | People's Republic of China |
|
||||
| Lagos | 21324000 | Nigeria |
|
||||
| Dhaka | 16800000 | Bangladesh |
|
||||
| Mumbai | 15414288 | India |
|
||||
| Istanbul | 14657434 | Turkey |
|
||||
| Tokyo | 13942856 | Japan |
|
||||
| Tianjin | 13245000 | People's Republic of China |
|
||||
| Guangzhou | 13080500 | People's Republic of China |
|
||||
| São Paulo | 12106920 | Brazil |
|
||||
|
||||
If we want to see which countries have the most populous cities, we can create a text facet on the “countryLabel” column and OpenRefine will generate a list of all the different strings used in these cells.
|
||||
|
||||
We will see in the sidebar that the countries identified are displayed, along with the number of matches (the “count”). We can sort this list alphabetically or by the count. If you sort by count at the top of the facet window, you’ll learn which countries hold the most populous cities.
|
||||
|
||||
|Facet|Count|
|
||||
|---|---|
|
||||
|People's Republic of China|4|
|
||||
|Bangladesh|1|
|
||||
|Brazil|1|
|
||||
|India|1|
|
||||
|Japan|1|
|
||||
|Nigeria|1|
|
||||
|Turkey|1|
|
||||
|
||||
If we want to learn more about a particular country, we can click on its appearance in the facet sidebar. This narrows our dataset down temporarily to only rows matching that facet.
|
||||
|
||||
You’ll see the “10 rows” indicator change to “4 matching rows (10 total)” if you click on “People’s Republic of China”. In the data grid, you’ll see fewer rows: only the ones matching your current filter. Each row will maintain its original numbering, though - in this case, rows #1, 2, and 8.
|
||||
|
||||
If you want to go back to the original dataset, click <span class="buttonLabels">Reset All</span> or the small “exclude” text next to the facet. If you want to view the most populous cities in both China and India, click “include” next to each facet. Now you’ll see 5 rows - #1, 2, 5, 8, 9.
|
||||
|
||||
We can also explore our data using the population information. In this case, because population is a number, we can create a numeric facet. This will give us the ability to explore by range rather than by exact matching values.
|
||||
|
||||
With the numeric facet, we are given a scale from the smallest to the largest value in the column. We can drag the range minimum and maximum to narrow the results. In this case, if we narrow down to only cities with more than 20 million in population, we get 3 matching rows out of the original 10.
|
||||
|
||||
When you look back at the text facet display of country names, you should see a smaller list with a reduced count: OpenRefine is now displaying the facets of the 3 matching rows, not the total dataset of 10 rows.
|
||||
|
||||
We can combine these facets - say, by narrowing to only the Chinese cities with populations greater than 20 million - simply by clicking in both. You should see 2 matching rows for both these criteria.
|
||||
|
||||
### Things to know about facets {#things-to-know-about-facets}
|
||||
|
||||
When you have facets applied, you will see “matching rows” in the [project grid header](running#project-grid-header). If you click <span class="menuItems">Export</span> and copy your data out of OpenRefine while facets are active, many of the exporting options will only export the matching rows, not all the rows in your project.
|
||||
|
||||
OpenRefine has several default facets, which you’ll learn about below. The most powerful facets are the ones designed by you - custom facets, written using [expressions](expressions) to transform the data behind the scenes and help you narrow down to precisely what you’re looking for.
|
||||
|
||||
Facets are not saved in the project along with the data. But you can save a link to the current state of the application. Find the <span class="menuItems">[Permalink](running#the-project-bar)</span> next to the project’s name.
|
||||
|
||||
You can modify any facet expression by clicking the “change” button to the right of the column name in the facet sidebar.
|
||||
|
||||
Facet boxes that appear in the sidebar can be resized and rearranged. You can drag and drop the title bar of each box to reorder them, and drag on the bottom bar of text facet boxes.
|
||||
|
||||
## Text facet {#text-facet}
|
||||
|
||||
A text facet can be generated on any column with the “text” data type. Select the column dropdown and go to <span class="menuItems">Facet</span> → <span class="menuItems">Text facet</span>. The created facet will be sorted alphabetically, and can be sorted by count.
|
||||
|
||||
A text facet is very simple: it takes the total contents of the cells of the column in question and matches them up. It does no guessing about typos or near-matches.
|
||||
|
||||
You can edit any entry that appears in the facet display, by hovering over the facet and clicking the “edit” button that appears. You can then type in a new value manually. This will mass-edit every identical cell in the column. This is a great way to fix typos, whitespace, and other issues that may be affecting the way facets appear. You can also automate the cleanup of facets by using [clustering](transforming#cluster-and-edit): a “Cluster” button is displayed within the facet window. It may be most efficient to cluster cells to one value, and then mass-edit that value to your desired string within the clustering operation window.
|
||||
|
||||
Each text facet shows up to 2,000 choices by default. You can [increase this limit on the Preferences screen](running#preferences) if you need to, which may slow down your browser. If your applied facet has more choices than the current limit, you'll be offered the option to increase the limit, which will permanently edit that preference for you.
|
||||
|
||||
The choices and counts displayed in each facet can be copied as tab-separated values. To do so, click on the "X choices" link near the top left corner of the facet. This can be useful to generate small summary tables of your data.
|
||||
|
||||

|
||||
|
||||
## Numeric facet {#numeric-facet}
|
||||
|
||||

|
||||
|
||||
Whereas a text facet groups unique text values into groups, a numeric facet sorts numbers by their range - smallest to biggest. This displays visually as a histogram, and allows you to set a custom facet within that range. You can drag the minimum and maximum range markers to set a range. OpenRefine snaps to some basic equal-sized divisions - 19 in the example set above.
|
||||
|
||||
You will be offered the option to include blank, non-numeric, and error values in your numeric visualization; these will appear in the visual range as “0” values.
|
||||
|
||||
:::info Numbers as text
|
||||
You can create a text facet on numeric data, which will treat each entry as a string. This can be useful if you wish, for example, to manually include facets instead of selecting a range, or sort by count, or copy that count.
|
||||
:::
|
||||
|
||||
:::info Faceting customization
|
||||
As mentioned in the overview, facets can be modified or customized by GREL [expressions](expressions) in many ways. For example, to facet by clusters of [row](expressions#variables) numbers with `row.index/100` or better visualizing numbers greater than 1000 with `max(row.index, 1000)`.
|
||||
:::
|
||||
|
||||
## Timeline facet {#timeline-facet}
|
||||
|
||||

|
||||
|
||||
Much like a numeric facet, a timeline facet will display as a small histogram with the values sorted: in this case, chronologically. A timeline facet only works on cells formatted as the [“date” data type](exploring#dates).
|
||||
|
||||
The facet appears with a count of blank cells and those with errors, which can help you analyze whether your date cells are correctly converted.
|
||||
|
||||
## Scatterplot facet {#scatterplot-facet}
|
||||
|
||||
A scatterplot is a visual representation of two related sets of numeric data.
|
||||
|
||||
You have the option to generate linear scatterplots (where the X and Y axes show continuous increases) or logarithmic scatterplots (where the X and Y axes show exponential or scaled increases). You can also rotate the plot by 45 degrees in either direction, and you can choose the size of the dot indicating a datapoint. You can make these choices in both the preview and in the facet display.
|
||||
|
||||
A scatterplot facet can be generated on any column. You require two or more number columns to generate scatterplots. Selecting <span class="menuItems">Facet</span> → <span class="menuItems">Scatterplot facet</span> will create a preview of data plotted from every number-formatted column in your dataset, comparing every column against every other column. Each scatterplot will show in its own square, allowing you to choose which data comparison you would like to analyze further. You can control which columns are on the X and Y axes by rearranging the columns in your dataset.
|
||||
|
||||

|
||||
|
||||
When you click on your desired square, that two-column comparison will appear in the facets sidebar. From here, you can drag your mouse to draw a rectangle inside the scatterplot, which will narrow down to just the rows matching the points plotted inside that rectangle (as shown by the rectangle inside the square in the image above). This rectangle can be resized by dragging any of the four edges. To draw a new rectangle, simply click and drag your mouse again. To add more scatterplots to the facet sidebar, re-run this process and select a different square.
|
||||
|
||||
If you have multiple facets applied, plotted points in your scatterplot displays will be greyed out if they are not part of the current matching data subset. If the rectangle you have drawn within a scatterplot display only includes grey dots, you will see no matching rows.
|
||||
|
||||
If you would like to export a scatterplot, OpenRefine will open a new tab with a generated PNG file that you can save.
|
||||
|
||||
## Custom text facet {#custom-text-facet}
|
||||
|
||||
You may want to explore your textual data with modifications that aren't permanent. Creating custom text facets will load your column into memory, transform the data temporarily, and store those transformations inside the facet.
|
||||
|
||||
You can also use custom text facets to analyze numerical data, such as by analyzing a number as a string, or by creating a test that will return “true” and “false” as values.
|
||||
|
||||
Clicking on <span class="menuItems">Facet</span> → <span class="menuItems">Custom text facet…</span> will bring up an [expressions](expressions) window where you can enter in a GREL, Jython, or Clojure expression to modify how the facet works.
|
||||
|
||||
A custom text facet operates just like a [text facet](#text-facet) by default. Unlike a text facet, however, you cannot click “edit” on the facets that appear in the sidebar and change the matching cells in your dataset - because what they display is modified, not the original entries.
|
||||
|
||||
For example, you may wish to analyze only the first word in a text field - perhaps the first name in a column of “[First Name] [Last Name]” entries. In this case, you can tell OpenRefine to facet only on the information that comes before the first space:
|
||||
|
||||
```
|
||||
value.split(" ")[0]
|
||||
```
|
||||
|
||||
In this case, `split()` is creating an array of text strings based on every space in the cells ["Firstname", "Lastname"]. Because arrays number their entries starting with 0, we want the first value, so we ask for `[0]`. (Assuming the first name is one word, not something like “Mary Anne.”) We can do the same splitting and ask for the last name with
|
||||
|
||||
```
|
||||
value.split(" ")[1]
|
||||
```
|
||||
|
||||
You may want to create a facet that references several columns. For example, let’s say you have two columns, “First Name” and “Last Name”, and you want out how many people have the same initial letter for both names (e.g., Marilyn Monroe, Steven Segal). To do so, create a custom text facet on either column and enter the expression
|
||||
|
||||
```
|
||||
cells["First Name"].value[0] == cells["Last Name"].value[0]
|
||||
```
|
||||
|
||||
That expression will look for the first letter (the character at index 0) of each entry and compare them. Then it will facet your rows into “true” and “false.”
|
||||
|
||||
You can learn more about text-modification functions on the [Expressions page](expressions).
|
||||
|
||||
## Custom numeric facet {#custom-numeric-facet}
|
||||
|
||||
You may want to explore your numerical data with modifications that aren't permanent. You can also use custom numeric facets to analyze textual data, such as by getting the length of text strings (with `value.length()`), or by analyzing it as though it were formatted as numbers (with `toNumber(value)`).
|
||||
|
||||
If you would like to build your own version of a numeric facet, you can use the <span class="menuItems">Custom Numeric Facet</span> option. Clicking on <span class="menuItems">Facet</span> → <span class="menuItems">Custom Numeric Facet…</span> will bring up an [expressions](expressions) window where you can enter in a GREL, Jython, or Clojure expression to modify how the facet works. A custom numeric facet operates just like a [numeric facet](#numeric-facet) by default.
|
||||
|
||||
For example, you may wish to create a numeric facet that rounds your value to the nearest integer, enter
|
||||
|
||||
```
|
||||
round(value)
|
||||
```
|
||||
|
||||
If you have two columns of numbers and for each row you wish to create a numeric facet only on the larger of the two, enter
|
||||
|
||||
```
|
||||
max(cells["Column1"].value, cells["Column2"].value)
|
||||
```
|
||||
|
||||
If the numeric values in a column are drawn from a power law distribution, then it's better to group them by their logs:
|
||||
|
||||
```
|
||||
value.log()
|
||||
```
|
||||
|
||||
If the values are periodic you could take the modulus by the period to understand if there's a pattern:
|
||||
|
||||
```
|
||||
mod(value, 7)
|
||||
```
|
||||
|
||||
You can learn more about numeric-modification functions on the [Expressions page](expressions).
|
||||
|
||||
## Customized facets {#customized-facets}
|
||||
|
||||
Customized facets have been added to expand the number of default facets users can apply with a single click. They represent some common and useful functions you shouldn’t have to work out using an [expression](expressions).
|
||||
|
||||
All facets that display in the <span class="tabLabels">Facet/Filter</span> tab can be edited by clicking on the “change” button to the right of the column title. This brings up the expressions window that will allow you to modify and preview the expression being used.
|
||||
|
||||
### Word facet {#word-facet}
|
||||
|
||||
A <span class="menuItems">Word facet</span> is a simple version of a text facet: it splits up the content of the cells based on spaces, and outputs each character string as a facet:
|
||||
|
||||
```
|
||||
value.split(" ")
|
||||
```
|
||||
|
||||
This can be useful for exploring the language used in a corpus, looking for common first and last names or titles, or seeing what’s in multi-valued cells you don’t wish to split up.
|
||||
|
||||
Word facet is case-sensitive and only splits by spaces, not by line breaks or other natural divisions.
|
||||
|
||||
### Duplicates facet {#duplicates-facet}
|
||||
|
||||
A <span class="menuItems">Duplicates facet</span> will return only rows that have non-unique values in the column you’ve selected. It will create a facet of “true” and “false” values - true being cells that are not unique, and “false” being cells that are. The actual expression being used is
|
||||
|
||||
```
|
||||
facetCount(value, 'value', '[Column]') > 1
|
||||
```
|
||||
|
||||
Duplicates facets are case-sensitive and you may wish to filter out things like leading and trailing whitespace or other hard-to-see issues. You can modify the facet expression, for example, with:
|
||||
|
||||
```
|
||||
facetCount(trim(toLowercase(value)), 'trim(toLowercase(value))', 'cityLabel') > 1
|
||||
```
|
||||
|
||||
### Numeric log facet {#numeric-log-facet}
|
||||
|
||||
Logarithmic scales reduce wide-ranging quantities to more compact and manageable ranges. A log transformation can be used to make highly skewed distributions less skewed. If your numerical data is unevenly distributed (say, lots of values in one range, and then a long tail extending off into different magnitudes), a <span class="menuItems">Numeric log facet</span> can represent that range better than a simple numeric facet. It will break these values down into more navigable segments than the buckets of a numeric facet. This facet can make patterns in your data more visible. OpenRefine uses a base-10 log, the “common logarithm.”
|
||||
|
||||
For example, we can look at [this data about the body weight of various mammals](http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_Brain2BodyWeight):
|
||||
|
||||
|Species|BodyWeight (kg)|
|
||||
|---|---|
|
||||
| Newborn_Human | 3.2 |
|
||||
| Adult_Human | 73 |
|
||||
| Pithecanthropus_Man | 70 |
|
||||
| Squirrel | 0.8 |
|
||||
| Hamster | 0.15 |
|
||||
| Chimpanzee | 50 |
|
||||
| Rabbit | 1.4 |
|
||||
| Dog_(Beagle) | 10 |
|
||||
| Cat | 4.5 |
|
||||
| Rat | 0.4 |
|
||||
| Sperm_Whale | 35000 |
|
||||
| Turtle | 3 |
|
||||
| Alligator | 270 |
|
||||
|
||||
Most values will be clustered in the 0-100 range, but 35,000 is many magnitudes above that. A numeric facet will create 36 equal buckets of 1,000 each - containing almost all the cells in the first bucket. A numeric log facet will instead display the data more evenly across the visual range.
|
||||
|
||||

|
||||
|
||||
A 1-bounded numeric log facet can be used if you'd like to exclude all the values below 1 (including zero and negative numbers).
|
||||
|
||||
### Text-length facet {#text-length-facet}
|
||||
|
||||
The <span class="menuItems">Text-length facet</span> returns a numerical value for each cell and plots it on a numeric facet chart. The expression used is
|
||||
|
||||
```
|
||||
value.length()
|
||||
```
|
||||
|
||||
This can be useful to, for example, look for values that did not successfully split on an earlier split operation, or to validate that data is a certain expected length (such as whether a date in YYYY/MM/DD is eight to ten characters).
|
||||
|
||||
You can also employ a <span class="menuItems">Log of text-length facet</span> that allows you to navigate more easily a wide range of string lengths. This can be useful in the case of web-scraping, where lots of textual data is loaded into single cells and needs to be parsed out.
|
||||
|
||||
|
||||
### Unicode character-code facet {#unicode-character-code-facet}
|
||||
|
||||

|
||||
|
||||
The Unicode facet identifies and returns [Unicode decimal values](https://en.wikipedia.org/wiki/List_of_Unicode_characters). It generates a list of the Unicode numerical values of each character used in each text cell, which allows you to narrow down and search for special characters, punctuation, and other data formatting issues.
|
||||
|
||||
This facet creates a numerical chart, which offers you the ability to narrow down to a range of numbers. For example, lowercase characters are numbers 97-122, uppercase characters are numbers 65-90, and numerical digits are numbers 48-57.
|
||||
|
||||
### Facet by error {#facet-by-error}
|
||||
|
||||
An error is a data type created by OpenRefine in the process of transforming data. For example, say you had converted a column to the number data type. If one cell had text characters in it, OpenRefine could either output the original text string unchanged or output an error. If you allow errors to be created, you can facet by them later to search for them and fix them.
|
||||
|
||||

|
||||
|
||||
To store errors in cells, ensure that you have <span class="fieldLabels">store error</span> selected for the “On error” option in the expressions window.
|
||||
|
||||
### Facet by null, empty, or blank {#facet-by-null-empty-or-blank}
|
||||
|
||||
Any column can be faceted for [null and/or empty cells](#cell-data-types). These can help you find cells where you want to manually enter content.
|
||||
|
||||
“Blank” means both null values and empty values. All three facets will generate “true” and “false” facets, “true” being blank.
|
||||
|
||||
An empty cell is a cell that is set to contain a string, but doesn’t have any characters in it (a zero-length string). This can be left over from an operation that removed characters, or from manually editing a cell and deleting its contents.
|
||||
|
||||
### Facet by star or flag {#facet-by-star-or-flag}
|
||||
|
||||
Stars and flags offer you the opportunity to mark specific rows for yourself for later focus. Stars and flags persist through closing and opening your project, and thus can provide a different function than using a permalink to persist your facets. Stars and flags can be used in any way you want, although they are designed to help you flag errors and star rows of particular importance.
|
||||
|
||||
You can manually star or flag rows simply by clicking on the icons to the left of each row.
|
||||
|
||||
You can also apply stars or flags to all matching rows by using the <span class="menuItems">All</span> dropdown menu (on the first column) and selecting <span class="menuItems">Edit rows</span> → <span class="menuItems">Star rows</span> or <span class="menuItems">Flag rows</span>. This will create “true” and “false” facets in the <span class="tabLabels">Facet/Filter</span>. These operations will modify all matching rows in your current subset. You can unstar or unflag them as well.
|
||||
|
||||
You may wish to create a custom subset of your data through a series of separate faceting activities (rather than successively narrowing down with multiple facets applied). For example, you may wish to:
|
||||
* apply a facet
|
||||
* star all the matching rows
|
||||
* remove that facet
|
||||
* apply another, unrelated facet
|
||||
* star all the new matching rows (which will not modify already-starred rows)
|
||||
* remove that facet
|
||||
* and then work with all of the cumulative starred rows.
|
||||
|
||||
You can also create a text facet on any column with the expression `row.starred` or `row.flagged`.
|
||||
|
||||
## Text filter {#text-filter}
|
||||
|
||||
Filters allow you to narrow down your data based on whether a given column includes a text string.
|
||||
|
||||
When you choose <span class="menuItems">Text filter</span> a box appears in the <span class="tabLabels">Facet/Filter</span> tab that allows you to enter in text. Matching rows will narrow dynamically with every character you enter. You can set the search to be case-sensitive or not, and you can use this box to enter in a regular expression.
|
||||
|
||||
For example, you can enter in “side” as a text filter, and it will return all cells in that column containing “side,” “sideways,” “offside,” etc.
|
||||
|
||||
The text filter field supports [regular expressions](expressions#regular-expressions). For example, you can employ a regular expression to view all properly-formatted emails:
|
||||
|
||||
```
|
||||
([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9\-\.]+)\.([a-zA-Z0-9\-]{2,15})
|
||||
```
|
||||
|
||||
You can press “invert” on this facet to then see blank cells or invalid email addresses.
|
||||
|
||||
This filter works differently than facets because it is always active as long as it appears in the sidebar. If you “reset” it, you will delete all the text or expression you have entered.
|
||||
|
||||
You can apply multiple text filters in succession, which will successively narrow your data subset. This can be useful if you apply multiple inverted filters, such as to filter out all rows that respond “yes” or “maybe” and only look at the remaining responses.
|
||||
@ -1,154 +0,0 @@
|
||||
---
|
||||
id: grel
|
||||
title: General Refine Expression Language
|
||||
sidebar_label: General Refine Expression Language
|
||||
---
|
||||
|
||||
## Basics {#basics}
|
||||
|
||||
GREL (General Refine Expression Language) is designed to resemble Javascript. Formulas use variables and depend on data types to do things like string manipulation or mathematical calculations:
|
||||
|
||||
|Example|Output|
|
||||
|---|---|
|
||||
| `value + " (approved)"` | Concatenate two strings; whatever is in the cell gets converted to a string first |
|
||||
| `value + 2.239` | Add 2.239 to the existing value (if a number); append text "2.239" to the end of the string otherwise |
|
||||
| `value.trim().length()` | Trim leading and trailing whitespace of the cell value and then output the length of the result |
|
||||
| `value.substring(7, 10)` | Output the substring of the value from character index 7, 8, and 9 (excluding character index 10) |
|
||||
| `value.substring(13)` | Output the substring from index 13 to the end of the string |
|
||||
|
||||
Note that the operator for string concatenation is `+` (not “&” as is used in Excel).
|
||||
|
||||
Evaluating conditions uses symbols such as <, >, *, /, etc. To check whether two objects are equal, use two equal signs (`value=="true"`).
|
||||
|
||||
See the [GREL functions page for a thorough reference](grelfunctions) on each function and its inputs and outputs. Read on below for more about the general nature of GREL expressions.
|
||||
|
||||
## Syntax {#syntax}
|
||||
|
||||
In GREL, functions can use either of these two forms:
|
||||
* functionName(arg0, arg1, ...)
|
||||
* arg0.functionName(arg1, ...)
|
||||
|
||||
The second form is a shorthand to make expressions easier to read. It simply pulls the first argument out and appends it to the front of the function, with a dot:
|
||||
|
||||
|Dot notation |Full notation |
|
||||
|-|-|
|
||||
| `value.trim().length()` | `length(trim(value))` |
|
||||
| `value.substring(7, 10)` | `substring(value, 7, 10)` |
|
||||
|
||||
So, in the dot shorthand, the functions occur from left to right in the order of calling, rather than in the reverse order with parentheses. This allows you to string together multiple functions in a readable order.
|
||||
|
||||
The dot notation can also be used to access the member fields of [variables](expressions#variables). For referring to column names that contain spaces (anything not a continuous string), use square brackets instead of dot notation:
|
||||
|
||||
|Example |Description |
|
||||
|-|-|
|
||||
| `FirstName.cells` | Access the cell in the column named “FirstName” of the current row |
|
||||
| `cells["First Name"]` | Access the cell in the column called “First Name” of the current row |
|
||||
|
||||
Square brackets can also be used to get substrings and sub-arrays, and single items from arrays:
|
||||
|
||||
|Example |Description |
|
||||
|-|-|
|
||||
| `value[1,3]` | A substring of value, starting from character 1 up to but excluding character 3 |
|
||||
| `"internationalization"[1,-2]` | Will return “nternationalizati” (negative indexes are counted from the end) |
|
||||
| `row.columnNames[5]` | Will return the name of the fifth column |
|
||||
|
||||
Any function that outputs an array can use square brackets to select only one part of the array to output as a string (remember that the index of the items in an array starts with 0).
|
||||
|
||||
For example, [partition()](grelfunctions#partitions-s-or-p-fragment-b-omitfragment-optional) would normally output an array of three items: the part before your chosen fragment, the fragment you've identified, and the part after. Selecting only the third part with `"internationalization".partition("nation")[2]` will output “alization” (and so will [-1], indicating the final item in the array).
|
||||
|
||||
## Controls {#controls}
|
||||
|
||||
GREL offers controls to support branching and looping (that is, “if” and “for” functions), but unlike functions, their arguments don't all get evaluated before they get run. A control can decide which part of the code to execute and can affect the environment bindings. Functions, on the other hand, can't do either. Each control decides which of their arguments to evaluate to `value`, and how.
|
||||
|
||||
Please note that the GREL control names are case-sensitive: for example, the isError() control can't be called with iserror().
|
||||
|
||||
#### if(e, eTrue, eFalse) {#ife-etrue-efalse}
|
||||
|
||||
Expression e is evaluated to a value. If that value is true, then expression eTrue is evaluated and the result is the value of the whole if() expression. Otherwise, expression eFalse is evaluated and that result is the value.
|
||||
|
||||
Examples:
|
||||
|
||||
| Example expression | Result |
|
||||
| ------------------------------------------------------------------------ | ------------ |
|
||||
| `if("internationalization".length() > 10, "big string", "small string")` | “big string” |
|
||||
| `if(mod(37, 2) == 0, "even", "odd")` | “odd” |
|
||||
|
||||
Nested if (switch case) example:
|
||||
|
||||
if(value == 'Place', 'http://www.example.com/Location',
|
||||
|
||||
if(value == 'Person', 'http://www.example.com/Agent',
|
||||
|
||||
if(value == 'Book', 'http://www.example.com/Publication',
|
||||
|
||||
null)))
|
||||
|
||||
#### with(e1, variable v, e2) {#withe1-variable-v-e2}
|
||||
|
||||
Evaluates expression e1 and binds its value to variable v. Then evaluates expression e2 and returns that result.
|
||||
|
||||
| Example expression | Result |
|
||||
| ------------------------------------------------------------------------------------ | ---------- |
|
||||
| `with("european union".split(" "), a, a.length())` | 2 |
|
||||
| `with("european union".split(" "), a, forEach(a, v, v.length()))` | [ 8, 5 ] |
|
||||
| `with("european union".split(" "), a, forEach(a, v, v.length()).sum() / a.length())` | 6.5 |
|
||||
|
||||
#### filter(e1, v, e test) {#filtere1-v-e-test}
|
||||
|
||||
Evaluates expression e1 to an array. Then for each array element, binds its value to variable v, evaluates expression test - which should return a boolean. If the boolean is true, pushes v onto the result array.
|
||||
|
||||
| Expression | Result |
|
||||
| ---------------------------------------------- | ------------- |
|
||||
| `filter([ 3, 4, 8, 7, 9 ], v, mod(v, 2) == 1)` | [ 3, 7, 9 ] |
|
||||
|
||||
#### forEach(e1, v, e2) {#foreache1-v-e2}
|
||||
|
||||
Evaluates expression e1 to an array. Then for each array element, binds its value to variable v, evaluates expression e2, and pushes the result onto the result array. When e1 is a JSON object, `forEach` iterates over its keys.
|
||||
|
||||
| Expression | Result |
|
||||
| ------------------------------------------ | ------------------- |
|
||||
| `forEach([ 3, 4, 8, 7, 9 ], v, mod(v, 2))` | [ 1, 0, 0, 1, 1 ] |
|
||||
|
||||
#### forEachIndex(e1, i, v, e2) {#foreachindexe1-i-v-e2}
|
||||
|
||||
Evaluates expression e1 to an array. Then for each array element, binds its index to variable i and its value to variable v, evaluates expression e2, and pushes the result onto the result array.
|
||||
|
||||
| Expression | Result |
|
||||
| ------------------------------------------------------------------------------- | --------------------------- |
|
||||
| `forEachIndex([ "anne", "ben", "cindy" ], i, v, (i + 1) + ". " + v).join(", ")` | 1. anne, 2. ben, 3. cindy |
|
||||
|
||||
#### forRange(n from, n to, n step, v, e) {#forrangen-from-n-to-n-step-v-e}
|
||||
|
||||
Iterates over the variable v starting at from, incrementing by the value of step each time while less than to. At each iteration, evaluates expression e, and pushes the result onto the result array.
|
||||
|
||||
#### forNonBlank(e, v, eNonBlank, eBlank) {#fornonblanke-v-enonblank-eblank}
|
||||
|
||||
Evaluates expression e. If it is non-blank, forNonBlank() binds its value to variable v, evaluates expression eNonBlank and returns the result. Otherwise (if e evaluates to blank), forNonBlank() evaluates expression eBlank and returns that result instead.
|
||||
|
||||
Unlike other GREL functions beginning with “for,” forNonBlank() is not iterative. forNonBlank() essentially offers a shorter syntax to achieving the same outcome by using the isNonBlank() function within an “if” statement.
|
||||
|
||||
#### isBlank(e), isNonBlank(e), isNull(e), isNotNull(e), isNumeric(e), isError(e) {#isblanke-isnonblanke-isnulle-isnotnulle-isnumerice-iserrore}
|
||||
|
||||
Evaluates the expression e, and returns a boolean based on the named evaluation.
|
||||
|
||||
Examples:
|
||||
|
||||
| Expression | Result |
|
||||
| ------------------- | ------- |
|
||||
| `isBlank("abc")` | false |
|
||||
| `isNonBlank("abc")` | true |
|
||||
| `isNull("abc")` | false |
|
||||
| `isNotNull("abc")` | true |
|
||||
| `isNumeric(2)` | true |
|
||||
| `isError(1)` | false |
|
||||
| `isError("abc")` | false |
|
||||
| `isError(1 / 0)` | true |
|
||||
|
||||
Remember that these are controls and not functions: you can’t use dot notation (for example, the format `e.isX()` will not work).
|
||||
|
||||
## Constants {#constants}
|
||||
|Name |Meaning |
|
||||
|-|-|
|
||||
| true | The boolean constant true |
|
||||
| false | The boolean constant false |
|
||||
| PI | From [Java's Math.PI](https://docs.oracle.com/javase/8/docs/api/java/lang/Math.html#PI), the value of pi (that is, 3.1415...) |
|
||||
@ -1,535 +0,0 @@
|
||||
---
|
||||
id: grelfunctions
|
||||
title: GREL functions
|
||||
sidebar_label: GREL functions
|
||||
---
|
||||
|
||||
## Reading this reference {#reading-this-reference}
|
||||
|
||||
For the reference below, the function is given in full-length notation and the in-text examples are written in dot notation. Shorthands are used to indicate the kind of [data type](exploring#data-types) used in each function: s for string, b for boolean, n for number, d for date, a for array, p for a regex pattern, and o for object (meaning any data type), as well as “null” and “error” data types.
|
||||
|
||||
If a function can take more than one kind of data as input or can output more than one kind of data, that is indicated with more than one letter (as with “s or a”) or with o for object, meaning it can take any type of data (string, boolean, date, number, etc.).
|
||||
|
||||
We also use shorthands for substring (“sub”) and separator string (“sep”).
|
||||
Optional arguments will say “(optional)”.
|
||||
|
||||
In places where OpenRefine will accept a string (s) or a regex pattern (p), you can supply a string by putting it in quotes. If you wish to use any [regex](expressions#regular-expressions) notation, wrap the pattern in forward slashes.
|
||||
|
||||
## Boolean functions {#boolean-functions}
|
||||
|
||||
###### and(b1, b2, ...) {#andb1-b2-}
|
||||
|
||||
Uses the logical operator AND on two or more booleans to output a boolean. Evaluates multiple statements into booleans, then returns true if all of the statements are true. For example, `(1 < 3).and(1 < 0)` returns false because one condition is true and one is false.
|
||||
|
||||
###### or(b1, b2, ...) {#orb1-b2-}
|
||||
|
||||
Uses the logical operator OR on two or more booleans to output a boolean. For example, `(1 < 3).or(1 > 7)` returns true because at least one of the conditions (the first one) is true.
|
||||
|
||||
###### not(b) {#notb}
|
||||
|
||||
Uses the logical operator NOT on a boolean to output a boolean. For example, `not(1 > 7)` returns true because 1 > 7 itself is false.
|
||||
|
||||
###### xor(b1, b2, ...) {#xorb1-b2-}
|
||||
|
||||
Uses the logical operator XOR (exclusive-or) on two or more booleans to output a boolean. Evaluates multiple statements, then returns true if only one of them is true. For example, `(1 < 3).xor(1 < 7)` returns false because more than one of the conditions is true.
|
||||
|
||||
## String functions {#string-functions}
|
||||
|
||||
###### length(s) {#lengths}
|
||||
|
||||
Returns the length of string s as a number.
|
||||
|
||||
###### toString(o, string format (optional)) {#tostringo-string-format-optional}
|
||||
|
||||
Takes any value type (string, number, date, boolean, error, null) and gives a string version of that value.
|
||||
|
||||
You can use toString() to convert numbers to strings with rounding, using an [optional string format](https://docs.oracle.com/javase/8/docs/api/java/util/Formatter.html). For example, if you applied the expression `value.toString("%.0f")` to a column:
|
||||
|
||||
|Input|Output|
|
||||
|-|-|
|
||||
|3.2|3|
|
||||
|0.8|1|
|
||||
|0.15|0|
|
||||
|100.0|100|
|
||||
|
||||
You can also convert dates to strings, using date parsing syntax built into OpenRefine (see [the toDate() function for details](#todateo-b-monthfirst-s-format1-s-format2-)). For example, `value.toString("MMM-dd-yyyy")` would convert the date value [2024-10-15T00:00:00Z] to “Oct-15-2024”.
|
||||
|
||||
Note: In OpenRefine, using toString() on a null cell outputs the string “null”.
|
||||
|
||||
### Testing string characteristics {#testing-string-characteristics}
|
||||
|
||||
###### startsWith(s, sub) {#startswiths-sub}
|
||||
|
||||
Returns a boolean indicating whether s starts with sub. For example, `"food".startsWith("foo")` returns true, whereas `"food".startsWith("bar")` returns false.
|
||||
|
||||
###### endsWith(s, sub) {#endswiths-sub}
|
||||
|
||||
Returns a boolean indicating whether s ends with sub. For example, `"food".endsWith("ood")` returns true, whereas `"food".endsWith("odd")` returns false.
|
||||
|
||||
###### contains(s, sub or p) {#containss-sub-or-p}
|
||||
|
||||
Returns a boolean indicating whether s contains sub, which is either a substring or a regex pattern. For example, `"food".contains("oo")` returns true whereas `"food".contains("ee")` returns false.
|
||||
|
||||
You can search for a regular expression by wrapping it in forward slashes rather than quotes: `"rose is a rose".contains(/\s+/)` returns true. startsWith() and endsWith() can only take strings, while contains() can take a regex pattern, so you can use contains() to look for beginning and ending string patterns.
|
||||
|
||||
### Basic string modification {#basic-string-modification}
|
||||
|
||||
#### Case conversion {#case-conversion}
|
||||
|
||||
###### toLowercase(s) {#tolowercases}
|
||||
|
||||
Returns string s converted to all lowercase characters.
|
||||
|
||||
###### toUppercase(s) {#touppercases}
|
||||
|
||||
Returns string s converted to all uppercase characters.
|
||||
|
||||
###### toTitlecase(s) {#totitlecases}
|
||||
|
||||
Returns string s converted into titlecase: a capital letter starting each word, and the rest of the letters lowercase. For example, `"Once upon a midnight DREARY".toTitlecase()` returns the string “Once Upon A Midnight Dreary”.
|
||||
|
||||
#### Trimming {#trimming}
|
||||
|
||||
###### trim(s) {#trims}
|
||||
|
||||
Returns a copy of the string s with leading and trailing whitespace removed. For example, `" island ".trim()` returns the string “island”. Identical to strip().
|
||||
|
||||
###### strip(s) {#strips}
|
||||
|
||||
Returns a copy of the string s with leading and trailing whitespace removed. For example, `" island ".strip()` returns the string “island”. Identical to trim().
|
||||
|
||||
###### chomp(s, sep) {#chomps-sep}
|
||||
|
||||
Returns a copy of string s with the string sep removed from the end if s ends with sep; otherwise, just returns s. For example, `"barely".chomp("ly")` and `"bare".chomp("ly")` both return the string “bare”.
|
||||
|
||||
#### Substring {#substring}
|
||||
|
||||
###### substring(s, n from, n to (optional)) {#substrings-n-from-n-to-optional}
|
||||
|
||||
Returns the substring of s starting from character index from, and up to (excluding) character index to. If the to argument is omitted, substring will output to the end of s. For example, `"profound".substring(3)` returns the string “found”, and `"profound".substring(2, 4)` returns the string “of”.
|
||||
|
||||
Remember that character indices start from zero. A negative character index counts from the end of the string. For example, `"profound".substring(0, -1)` returns the string “profoun”.
|
||||
|
||||
###### slice(s, n from, n to (optional)) {#slices-n-from-n-to-optional}
|
||||
|
||||
Identical to substring() in relation to strings. Also works with arrays; see [Array functions section](#slicea-n-from-n-to-optional).
|
||||
|
||||
###### get(s, n from, n to (optional)) {#gets-n-from-n-to-optional}
|
||||
|
||||
Identical to substring() in relation to strings. Also works with named fields. Also works with arrays; see [Array functions section](#geta-n-from-n-to-optional).
|
||||
|
||||
#### Find and replace {#find-and-replace}
|
||||
|
||||
###### indexOf(s, sub) {#indexofs-sub}
|
||||
|
||||
Returns the first character index of sub as it first occurs in s; or, returns -1 if s does not contain sub. For example, `"internationalization".indexOf("nation")` returns 5, whereas `"internationalization".indexOf("world")` returns -1.
|
||||
|
||||
###### lastIndexOf(s, sub) {#lastindexofs-sub}
|
||||
|
||||
Returns the first character index of sub as it last occurs in s; or, returns -1 if s does not contain sub. For example, `"parallel".lastIndexOf("a")` returns 3 (pointing at the second “a”).
|
||||
|
||||
###### replace(s, s or p find, s replace) {#replaces-s-or-p-find-s-replace}
|
||||
|
||||
Returns the string obtained by replacing the find string with the replace string in the inputted string. For example, `"The cow jumps over the moon and moos".replace("oo", "ee")` returns the string “The cow jumps over the meen and mees”. Find can be a regex pattern. For example, `"The cow jumps over the moon and moos".replace(/\s+/, "_")` will return “The_cow_jumps_over_the_moon_and_moos”.
|
||||
|
||||
You cannot find or replace nulls with this, as null is not a string. You can instead:
|
||||
|
||||
1. Facet by null and then bulk-edit them to a string, or
|
||||
2. Transform the column with an expression such as `if(value==null,"new",value)`.
|
||||
|
||||
###### replaceChars(s, s find, s replace) {#replacecharss-s-find-s-replace}
|
||||
|
||||
Returns the string obtained by replacing a character in s, identified by find, with the corresponding character identified in replace. For example, `"Téxt thát was optícálly recógnízéd".replaceChars("áéíóú", "aeiou")` returns the string “Text that was optically recognized”. You cannot use this to replace a single character with more than one character.
|
||||
|
||||
###### find(s, sub or p) {#finds-sub-or-p}
|
||||
|
||||
Outputs an array of all consecutive substrings inside string s that match the substring or [regex](expressions#grel-supported-regex) pattern p. For example, `"abeadsabmoloei".find(/[aeio]+/)` would result in the array [ "a", "ea", "a", "o", "oei" ].
|
||||
|
||||
You can supply a substring instead of p, by putting it in quotes, and OpenRefine will compile it into a regex pattern. Anytime you supply quotes, OpenRefine interprets the contents as a string, not regex. If you wish to use any regex notation, wrap the pattern in forward slashes.
|
||||
|
||||
###### match(s, p) {#matchs-p}
|
||||
|
||||
Attempts to match the string s in its entirety against the [regex](expressions#grel-supported-regex) pattern p and, if the pattern is found, outputs an array of all [capturing groups](https://www.regular-expressions.info/brackets.html) (found in order). For example, `"230.22398, 12.3480".match(/.*(\d\d\d\d)/)` returns an array of 1 substring: [ "3480" ]. It does not find 2239 as the first sequence with four digits, because the regex indicates the four digits must come at the end of the string.
|
||||
|
||||
You will need to convert the array to a string to store it in a cell, with a function such as toString(). An empty array [] is returned when there is no match to the desired substrings. A null is output when the entire regex does not match.
|
||||
|
||||
Remember to enclose your regex in forward slashes, and to escape characters and use parentheses as needed. Parentheses denote a desired substring (capturing group); for example, “.*(\d\d\d\d)” would return an array containing a single value, while “(.*)(\d\d\d\d)” would return two. So, if you are looking for a desired substring anywhere within a string, use the syntax `value.match(/.*(desired-substring-regex).*/)`.
|
||||
|
||||
For example, if `value` is “hello 123456 goodbye”, the following would occur:
|
||||
|
||||
|Expression|Result|
|
||||
|-|-|
|
||||
|`value.match(/\d{6}/)` |null (does not match the full string)|
|
||||
|`value.match(/.*\d{6}.*/)` |[ ] (no indicated substring)|
|
||||
|`value.match(/.*(\d{6}).*/)` |[ "123456" ] (array with one value)|
|
||||
|`value.match(/(.*)(\d{6})(.*)/)` |[ "hello ", "123456", " goodbye" ] (array with three values)|
|
||||
|
||||
### String parsing and splitting {#string-parsing-and-splitting}
|
||||
|
||||
###### toNumber(s) {#tonumbers}
|
||||
|
||||
Returns a string converted to a number. Will attempt to convert other formats into a string, then into a number. If the value is already a number, it will return the number.
|
||||
|
||||
###### split(s, s or p sep, b preserveTokens (optional)) {#splits-s-or-p-sep-b-preservetokens-optional}
|
||||
|
||||
Returns the array of strings obtained by splitting s by sep. The separator can be either a string or a regex pattern. For example, `"fire, water, earth, air".split(",")` returns an array of 4 strings: [ "fire", " water", " earth", " air" ]. Note that the space characters are retained but the separator is removed. If you include “true” for the preserveTokens boolean, empty segments are preserved.
|
||||
|
||||
###### splitByLengths(s, n1, n2, ...) {#splitbylengthss-n1-n2-}
|
||||
|
||||
Returns the array of strings obtained by splitting s into substrings with the given lengths. For example, `"internationalization".splitByLengths(5, 6, 3)` returns an array of 3 strings: [ "inter", "nation", "ali" ]. Excess characters are discarded.
|
||||
|
||||
###### smartSplit(s, s or p sep (optional)) {#smartsplits-s-or-p-sep-optional}
|
||||
|
||||
Returns the array of strings obtained by splitting s by sep, or by guessing either tab or comma separation if there is no sep given. Handles quotes properly and understands cancelled characters. The separator can be either a string or a regex pattern. For example, `value.smartSplit("\n")` will split at a carriage return or a new-line character.
|
||||
|
||||
Note: [`value.escape('javascript')`](#escapes-s-mode) is useful for previewing unprintable characters prior to using smartSplit().
|
||||
|
||||
###### splitByCharType(s) {#splitbychartypes}
|
||||
|
||||
Returns an array of strings obtained by splitting s into groups of consecutive characters each time the characters change [Unicode categories](https://en.wikipedia.org/wiki/Unicode_character_property#General_Category). For example, `"HenryCTaylor".splitByCharType()` will result in an array of [ "H", "enry", "CT", "aylor" ]. It is useful for separating letters and numbers: `"BE1A3E".splitByCharType()` will result in [ "BE", "1", "A", "3", "E" ].
|
||||
|
||||
###### partition(s, s or p fragment, b omitFragment (optional)) {#partitions-s-or-p-fragment-b-omitfragment-optional}
|
||||
|
||||
Returns an array of strings [ a, fragment, z ] where a is the substring within s before the first occurrence of fragment, and z is the substring after fragment. Fragment can be a string or a regex. For example, `"internationalization".partition("nation")` returns 3 strings: [ "inter", "nation", "alization" ]. If s does not contain fragment, it returns an array of [ s, "", "" ] (the original unpartitioned string, and two empty strings).
|
||||
|
||||
If the omitFragment boolean is true, for example with `"internationalization".partition("nation", true)`, the fragment is not returned. The output is [ "inter", "alization" ].
|
||||
|
||||
You can use regex for your fragment. The expresion `"abcdefgh".partition(/c.e/)` will output [“abc”, "cde", defgh” ].
|
||||
|
||||
###### rpartition(s, s or p fragment, b omitFragment (optional)) {#rpartitions-s-or-p-fragment-b-omitfragment-optional}
|
||||
|
||||
Returns an array of strings [ a, fragment, z ] where a is the substring within s before the last occurrence of fragment, and z is the substring after the last instance of fragment. (Rpartition means “reverse partition.”) For example, `"parallel".rpartition("a")` returns 3 strings: [ "par", "a", "llel" ]. Otherwise works identically to partition() above.
|
||||
|
||||
### Encoding and hashing {#encoding-and-hashing}
|
||||
|
||||
###### diff(s1, s2, s timeUnit (optional)) {#diffs1-s2-s-timeunit-optional}
|
||||
|
||||
Takes two strings and compares them, returning a string. Returns the remainder of s2 starting with the first character where they differ. For example, `"cacti".diff("cactus")` returns "us". Also works with dates; see [Date functions](#diffd1-d2-s-timeunit).
|
||||
|
||||
###### escape(s, s mode) {#escapes-s-mode}
|
||||
|
||||
Escapes s in the given escaping mode. The mode can be one of: "html", "xml", "csv", "url", "javascript". Note that quotes are required around your mode. See the [recipes](https://github.com/OpenRefine/OpenRefine/wiki/Recipes#question-marks--showing-in-your-data) for examples of escaping and unescaping.
|
||||
|
||||
###### unescape(s, s mode) {#unescapes-s-mode}
|
||||
|
||||
Unescapes s in the given escaping mode. The mode can be one of: "html", "xml", "csv", "url", "javascript". Note that quotes are required around your mode. See the [recipes](https://github.com/OpenRefine/OpenRefine/wiki/Recipes#atampampt----att) for examples of escaping and unescaping.
|
||||
|
||||
###### md5(o) {#md5o}
|
||||
|
||||
Returns the [MD5 hash](https://en.wikipedia.org/wiki/MD5) of an object. If fed something other than a string (array, number, date, etc.), md5() will convert it to a string and deliver the hash of the string. For example, `"internationalization".md5()` will return 2c55a1626e31b4e373ceedaa9adc12a3.
|
||||
|
||||
###### sha1(o) {#sha1o}
|
||||
|
||||
Returns the [SHA-1 hash](https://en.wikipedia.org/wiki/SHA-1) of an object. If fed something other than a string (array, number, date, etc.), sha1() will convert it to a string and deliver the hash of the string. For example, `"internationalization".sha1()` will return cd05286ee0ff8a830dbdc0c24f1cb68b83b0ef36.
|
||||
|
||||
###### phonetic(s, s encoding) {#phonetics-s-encoding}
|
||||
|
||||
Returns a phonetic encoding of a string, based on an available phonetic algorithm. See the [section on phonetic clustering](cellediting#clustering-methods) for more information. Can be one of the following supported phonetic methods: [metaphone, doublemetaphone, metaphone3](https://www.wikipedia.org/wiki/Metaphone), [soundex](https://en.wikipedia.org/wiki/Soundex), [cologne](https://en.wikipedia.org/wiki/Cologne_phonetics). Quotes are required around your encoding method. For example, `"Ruth Prawer Jhabvala".phonetic("metaphone")` outputs the string “R0PRWRJHBFL”.
|
||||
|
||||
###### reinterpret(s, s encoderTarget, s encoderSource) {#reinterprets-s-encodertarget-s-encodersource}
|
||||
|
||||
Returns s reinterpreted through the given character encoders. You must supply one of the [supported encodings](http://java.sun.com/j2se/1.5.0/docs/guide/intl/encoding.doc.html) for each of the original source and the target output. Note that quotes are required around your character encoder.
|
||||
|
||||
When an OpenRefine project is started, data is imported and interpreted. A specific character encoding is identified or manually selected at that time (such as UTF-8). You can reinterpret a column into another specificed encoding using this function. This function may not fix your data; it may be better to use this in conjunction with new projects to test the interpretation, and pre-format your data as needed.
|
||||
|
||||
###### fingerprint(s) {#fingerprints}
|
||||
|
||||
Returns the fingerprint of s, a string that is the first step in [fingerprint clustering methods](cellediting#clustering-methods): it will trim whitespaces, convert all characters to lowercase, remove punctuation, sort words alphabetically, etc. For example, `"Ruth Prawer Jhabvala".fingerprint()` outputs the string “jhabvala prawer ruth”.
|
||||
|
||||
###### ngram(s, n) {#ngrams-n}
|
||||
|
||||
Returns an array of the word n-grams of s. That is, it lists all the possible consecutive combinations of n words in the string. For example, `"Ruth Prawer Jhabvala".ngram(2)` would output the array [ "Ruth Prawer", "Prawer Jhabvala" ]. A word n-gram of 1 simply lists all the words in original order; an n-gram larger than the number of words in the string will only return the original string inside an array (e.g. `"Ruth Prawer Jhabvala".ngram(4)` would simply return ["Ruth Prawer Jhabvala"]).
|
||||
|
||||
###### ngramFingerprint(s, n) {#ngramfingerprints-n}
|
||||
|
||||
Returns the [n-gram fingerprint](cellediting#clustering-methods) of s. For example, `"banana".ngram(2)` would output “anbana”, after first generating the 2-grams “ba an na an na”, removing duplicates, and sorting them alphabetically.
|
||||
|
||||
###### unicode(s) {#unicodes}
|
||||
|
||||
Returns an array of strings describing each character of s in their full unicode notation. For example, `"Bernice Rubens".unicode()` outputs [ 66, 101, 114, 110, 105, 99, 101, 32, 82, 117, 98, 101, 110, 115 ].
|
||||
|
||||
###### unicodeType(s) {#unicodetypes}
|
||||
|
||||
Returns an array of strings describing each character of s by their unicode type. For example, `"Bernice Rubens".unicodeType()` outputs [ "uppercase letter", "lowercase letter", "lowercase letter", "lowercase letter", "lowercase letter", "lowercase letter", "lowercase letter", "space separator", "uppercase letter", "lowercase letter", "lowercase letter", "lowercase letter", "lowercase letter", "lowercase letter" ].
|
||||
|
||||
## Format-based functions (JSON, HTML, XML) {#format-based-functions-json-html-xml}
|
||||
|
||||
###### jsonize(o) {#jsonizeo}
|
||||
|
||||
Quotes a value as a JSON literal value.
|
||||
|
||||
###### parseJson(s) {#parsejsons}
|
||||
|
||||
Parses a string as JSON. get() can then be used with parseJson(): for example, `parseJson(" { 'a' : 1 } ").get("a")` returns 1.
|
||||
|
||||
For example, from the following JSON array in `value`, we want to get all instances of “keywords” having the same object string name of “text”, and combine them, using the forEach() function to iterate over the array.
|
||||
|
||||
{
|
||||
"status":"OK",
|
||||
"url":"",
|
||||
"language":"english",
|
||||
"keywords":[
|
||||
{
|
||||
"text":"York en route",
|
||||
"relevance":"0.974363"
|
||||
},
|
||||
{
|
||||
"text":"Anthony Eden",
|
||||
"relevance":"0.814394"
|
||||
},
|
||||
{
|
||||
"text":"President Eisenhower",
|
||||
"relevance":"0.700189"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
The GREL expression `forEach(value.parseJson().keywords,v,v.text).join(":::")` will output “York en route:::Anthony Eden:::President Eisenhower”.
|
||||
|
||||
### Jsoup XML and HTML parsing {#jsoup-xml-and-html-parsing}
|
||||
|
||||
###### parseHtml(s) {#parsehtmls}
|
||||
Given a cell full of HTML-formatted text, parseHtml() simplifies HTML tags (such as by removing “ /” at the end of self-closing tags), closes any unclosed tags, and inserts linebreaks and indents for cleaner code. You cannot pass parseHtml() a URL, but you can pre-fetch HTML with the <span class="menuItems">[Add column by fetching URLs](columnediting#add-column-by-fetching-urls)</span> menu option.
|
||||
|
||||
A cell cannot store the output of parseHtml() unless you convert it with toString(): for example, `value.parseHtml().toString()`.
|
||||
|
||||
When parseHtml() simplifies HTML, it can sometimes introduce errors. When closing tags, it makes its best guesses based on line breaks, indentation, and the presence of other tags. You may need to manually check the results.
|
||||
|
||||
You can then extract or [select()](#selects-element) which portions of the HTML document you need for further splitting, partitioning, etc. An example of extracting all table rows from a div using parseHtml().select() together is described more in depth at [StrippingHTML](https://github.com/OpenRefine/OpenRefine/wiki/StrippingHTML).
|
||||
|
||||
###### parseXml(s) {#parsexmls}
|
||||
Given a cell full of XML-formatted text, parseXml() returns a full XML document and adds any missing closing tags. You can then extract or [select()](#selects-element) which portions of the XML document you need for further splitting, partitioning, etc. Functions the same way as parseHtml() is described above.
|
||||
|
||||
###### select(s, element) {#selects-element}
|
||||
Returns an array of all the desired elements from an HTML or XML document, if the element exists. Elements are identified using the [Jsoup selector syntax](https://jsoup.org/apidocs/org/jsoup/select/Selector.html). For example, `value.parseHtml().select("img.portrait")[0]` would return the entirety of the first “img” tag with the “portrait” class found in the parsed HTML inside `value`. Returns an empty array if no matching element is found. Use with toString() to capture the results in a cell. A tutorial of select() is shown in [StrippingHTML](https://github.com/OpenRefine/OpenRefine/wiki/StrippingHTML).
|
||||
|
||||
You can use select() more than once:
|
||||
|
||||
```
|
||||
value.parseHtml().select("div#content")[0].select("tr").toString()
|
||||
```
|
||||
|
||||
###### htmlAttr(s, element) {#htmlattrs-element}
|
||||
Returns a string from an attribute on an HTML element. Use it in conjunction with parseHtml() as in the following example: `value.parseHtml().select("a.email")[0].htmlAttr("href")` would retrieve the email address attached to a link with the “email” class.
|
||||
|
||||
###### xmlAttr(s, element) {#xmlattrs-element}
|
||||
Returns a string from an attribute on an XML element. Functions the same way htmlAttr() is described above. Use it in conjunction with parseXml().
|
||||
|
||||
###### htmlText(element) {#htmltextelement}
|
||||
Returns a string of the text from within an HTML element (including all child elements), removing HTML tags and line breaks inside the string. Use it in conjunction with parseHtml() and select() to provide an element, as in the following example: `value.parseHtml().select("div.footer")[0].htmlText()`.
|
||||
|
||||
###### xmlText(element) {#xmltextelement}
|
||||
Returns a string of the text from within an XML element (including all child elements). Functions the same way htmlText() is described above. Use it in conjunction with parseXml() and select() to provide an element.
|
||||
|
||||
###### wholeText(element) {#wholetextelement}
|
||||
|
||||
Selects the (unencoded) text of an element and its children, including any new lines and spaces, and returns a string of unencoded, un-normalized text. Use it in conjunction with parseHtml() and select() to provide an element as in the following example: `value.parseHtml().select("div.footer")[0].wholeText()`.
|
||||
|
||||
###### innerHtml(element) {#innerhtmlelement}
|
||||
Returns the [inner HTML](https://developer.mozilla.org/en-US/docs/Web/API/Element/innerHTML) of an HTML element. This will include text and children elements within the element selected. Use it in conjunction with parseHtml() and select() to provide an element.
|
||||
|
||||
###### innerXml(element) {#innerxmlelement}
|
||||
Returns the inner XML elements of an XML element. Does not return the text directly inside your chosen XML element - only the contents of its children. To select the direct text, use ownText(). To select both, use xmlText(). Use it in conjunction with parseXml() and select() to provide an element.
|
||||
|
||||
###### ownText(element) {#owntextelement}
|
||||
Returns the text directly inside the selected XML or HTML element only, ignoring text inside children elements (for this, use innerXml()). Use it in conjunction with a parser and select() to provide an element.
|
||||
|
||||
## Array functions {#array-functions}
|
||||
|
||||
###### length(a) {#lengtha}
|
||||
Returns the size of an array, meaning the number of objects inside it. Arrays can be empty, in which case length() will return 0.
|
||||
|
||||
###### slice(a, n from, n to (optional)) {#slicea-n-from-n-to-optional}
|
||||
Returns a sub-array of a given array, from the first index provided and up to and excluding the optional last index provided. Remember that array objects are indexed starting at 0. If the to value is omitted, it is understood to be the end of the array. For example, `[0, 1, 2, 3, 4].slice(1, 3)` returns [ 1, 2 ], and `[ 0, 1, 2, 3, 4].slice(2)` returns [ 2, 3, 4 ]. Also works with strings; see [String functions](#slices-n-from-n-to-optional).
|
||||
|
||||
###### get(a, n from, n to (optional)) {#geta-n-from-n-to-optional}
|
||||
Returns a sub-array of a given array, from the first index provided and up to and excluding the optional last index provided. Remember that array objects are indexed starting at 0.
|
||||
|
||||
If the to value is omitted, only one array item is returned, as a string, instead of a sub-array. To return a sub-array from one index to the end, you can set the to argument to a very high number such as `value.get(2,999)` or you can use something like `with(value,a,a.get(1,a.length()))` to count the length of each array.
|
||||
|
||||
Also works with strings; see [String functions](#gets-n-from-n-to-optional).
|
||||
|
||||
###### inArray(a, s) {#inarraya-s}
|
||||
Returns true if the array contains the desired string, and false otherwise. Will not convert data types; for example, `[ 1, 2, 3, 4 ].inArray("3")` will return false.
|
||||
|
||||
###### reverse(a) {#reversea}
|
||||
Reverses the array. For example, `[ 0, 1, 2, 3].reverse()` returns the array [ 3, 2, 1, 0 ].
|
||||
|
||||
###### sort(a) {#sorta}
|
||||
Sorts the array in ascending order. Sorting is case-sensitive, uppercase first and lowercase second. For example, `[ "al", "Joe", "Bob", "jim" ].sort()` returns the array [ "Bob", "Joe", "al", "jim" ].
|
||||
|
||||
###### sum(a) {#suma}
|
||||
Return the sum of the numbers in the array. For example, `[ 2, 1, 0, 3 ].sum()` returns 6.
|
||||
|
||||
###### join(a, sep) {#joina-sep}
|
||||
Joins the items in the array with sep, and returns it all as a string. For example, `[ "and", "or", "not" ].join("/")` returns the string “and/or/not”.
|
||||
|
||||
###### uniques(a) {#uniquesa}
|
||||
Returns the array with duplicates removed. Case-sensitive. For example, `[ "al", "Joe", "Bob", "Joe", "Al", "Bob" ].uniques()` returns the array [ "Joe", "al", "Al", "Bob" ].
|
||||
|
||||
As of OpenRefine 3.4.1, uniques() reorders the array items it returns; in 3.4 beta 644 and onwards, it preserves the original order (in this case, [ "al", "Joe", "Bob", "Al" ]).
|
||||
|
||||
## Date functions {#date-functions}
|
||||
|
||||
###### now() {#now}
|
||||
|
||||
Returns the current time according to your system clock, in the [ISO 8601 extended format](exploring#data-types) (converted to UTC). For example, 10:53am (and 00 seconds) on November 26th 2020 in EST returns [date 2020-11-26T15:53:00Z].
|
||||
|
||||
###### toDate(o, b monthFirst, s format1, s format2, ...) {#todateo-b-monthfirst-s-format1-s-format2-}
|
||||
|
||||
Returns the inputted object converted to a date object. Without arguments, it returns the ISO 8601 extended format. With arguments, you can control the output format:
|
||||
* monthFirst: set false if the date is formatted with the day before the month.
|
||||
* formatN: attempt to parse the date using an ordered list of possible formats. Supply formats based on the [SimpleDateFormat](https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html) syntax (and see the table below for a handy reference).
|
||||
|
||||
For example, you can parse a column containing dates in different formats, such as cells with “Nov-09” and “11/09”, using `value.toDate('MM/yy','MMM-yy').toString('yyyy-MM')` and both will output “2009-11”. For another example, “1/4/2012 13:30:00” can be parsed into a date using `value.toDate('d/M/y H:m:s')`.
|
||||
|
||||
| Letter | Date or Time Component | Presentation | Examples |
|
||||
|-|-|-|-|
|
||||
| G | Era designator | Text | AD |
|
||||
| y | Year | Year | 1996; 96 |
|
||||
| Y | [Week year](https://en.wikipedia.org/wiki/ISO_week_date#First_week) | Year | 2009; 09 |
|
||||
| M | Month in year | Month | July; Jul; 07 |
|
||||
| w | Week in year | Number | 27 |
|
||||
| W | Week in month | Number | 2 |
|
||||
| D | Day in year | Number | 189 |
|
||||
| d | Day in month | Number | 10 |
|
||||
| F | Day of week in month | Number | 2 |
|
||||
| E | Day name in week | Text | Tuesday; Tue |
|
||||
| u | Day number of week (1 = Monday, ..., 7 = Sunday) | Number | 1 |
|
||||
| a | AM/PM marker | Text | PM |
|
||||
| H | Hour in day (0-23) | Number | 0 |
|
||||
| k | Hour in day (1-24) | Number | 24 |
|
||||
| K | Hour in AM/PM (0-11) | Number | 0 |
|
||||
| h | Hour in AM/PM (1-12) | Number | 12 |
|
||||
| m | Minute in hour | Number | 30 |
|
||||
| s | Second in minute | Number | 55 |
|
||||
| S | Millisecond | Number | 978 |
|
||||
| n | Nanosecond | Number | 789000 |
|
||||
| z | Time zone | General time zone | Pacific Standard Time; PST; GMT-08:00 |
|
||||
| Z | Time zone | RFC 822 time zone | \-0800 |
|
||||
| X | Time zone | ISO 8601 time zone | \-08; -0800; -08:00 |
|
||||
|
||||
###### diff(d1, d2, s timeUnit) {#diffd1-d2-s-timeunit}
|
||||
|
||||
Given two dates, returns a number indicating the difference in a given time unit (see the table below). For example, `diff(("Nov-11".toDate('MMM-yy')), ("Nov-09".toDate('MMM-yy')), "weeks")` will return 104, for 104 weeks, or two years. The later date should go first. If the output is negative, invert d1 and d2.
|
||||
|
||||
Also works with strings; see [diff() in string functions](#diffsd1-sd2-s-timeunit-optional).
|
||||
|
||||
###### inc(d, n, s timeUnit) {#incd-n-s-timeunit}
|
||||
|
||||
Returns a date changed by the given amount in the given unit of time (see the table below). The default unit is “hour”. A positive value increases the date, and a negative value moves it back in time. For example, if you want to move a date backwards by two months, use `value.inc(-2,"month")`.
|
||||
|
||||
###### datePart(d, s timeUnit) {#datepartd-s-timeunit}
|
||||
|
||||
Returns part of a date. The data type returned depends on the unit (see the table below).
|
||||
|
||||
OpenRefine supports the following values for timeUnit:
|
||||
|
||||
| Unit | Date part returned | Returned data type | Example using [date 2014-03-14T05:30:04.000789000Z] as value |
|
||||
|-|-|-|-|
|
||||
| years | Year | Number | value.datePart("years") → 2014 |
|
||||
| year | Year | Number | value.datePart("year") → 2014 |
|
||||
| months | Month | Number | value.datePart("months") → 2 |
|
||||
| month | Month | Number | value.datePart("month") → 2 |
|
||||
| weeks | Week of the month | Number | value.datePart("weeks") → 3 |
|
||||
| week | Week of the month | Number | value.datePart("week") → 3 |
|
||||
| w | Week of the month | Number | value.datePart("w") → 3 |
|
||||
| weekday | Day of the week | String | value.datePart("weekday") → Friday |
|
||||
| hours | Hour | Number | value.datePart("hours") → 5 |
|
||||
| hour | Hour | Number | value.datePart("hour") → 5 |
|
||||
| h | Hour | Number | value.datePart("h") → 5 |
|
||||
| minutes | Minute | Number | value.datePart("minutes") → 30 |
|
||||
| minute | Minute | Number | value.datePart("minute") → 30 |
|
||||
| min | Minute | Number | value.datePart("min") → 30 |
|
||||
| seconds | Seconds | Number | value.datePart("seconds") → 04 |
|
||||
| sec | Seconds | Number | value.datePart("sec") → 04 |
|
||||
| s | Seconds | Number | value.datePart("s") → 04 |
|
||||
| milliseconds | Millseconds | Number | value.datePart("milliseconds") → 789 |
|
||||
| ms | Millseconds | Number | value.datePart("ms") → 789 |
|
||||
| S | Millseconds | Number | value.datePart("S") → 789 |
|
||||
| n | Nanoseconds | Number | value.datePart("n") → 789000 |
|
||||
| nano | Nanoseconds | Number | value.datePart("n") → 789000 |
|
||||
| nanos | Nanoseconds | Number | value.datePart("n") → 789000 |
|
||||
| time | Milliseconds between input and the [Unix Epoch](https://en.wikipedia.org/wiki/Unix_time) | Number | value.datePart("time") → 1394775004000 |
|
||||
|
||||
## Math functions {#math-functions}
|
||||
|
||||
For integer division and precision, you can use simple evaluations such as `1 / 2`, which is equivalent to `floor(1/2)` - that is, it returns only whole number results. If either operand is a floating point number, they both get promoted to floating point and a floating point result is returned. You can use `1 / 2.0` or `1.0 / 2` or `1.0 * x / y` (if you're working with variables of unknown contents).
|
||||
|
||||
:::caution
|
||||
Some of these math functions don't recognize integers when supplied as the first argument in dot notation (e.g., `5.cos()` simply returns 5 instead of the expected result). To ensure operations are successful, always wrap the first argument in brackets, such as `(value).cos()`.
|
||||
:::
|
||||
|
||||
|Function|Use|Example|
|
||||
|-|-|-|
|
||||
|`abs(n)`|Returns the absolute value of a number.|`abs(-6)` returns 6.|
|
||||
|`acos(n)`|Returns the arc cosine of an angle, in the range 0 through [PI](https://docs.oracle.com/javase/8/docs/api/java/lang/Math.html#PI).|`acos(0.345)` returns 1.218557541697832.|
|
||||
|`asin(n)`|Returns the arc sine of an angle in the range of -PI/2 through PI/2.|`asin(0.345)` returns 0.35223878509706474.|
|
||||
|`atan(n)`|Returns the arc tangent of an angle in the range of -PI/2 through PI/2.|`atan(0.345)` returns 0.3322135507465967.|
|
||||
|`atan2(n1, n2)`|Converts rectangular coordinates (n1, n2) to polar (r, theta). Returns number theta.|`atan2(0.345,0.6)` returns 0.5218342798144103.|
|
||||
|`ceil(n)`|Returns the ceiling of a number.|`3.7.ceil()` returns 4 and `-3.7.ceil()` returns -3.|
|
||||
|`combin(n1, n2)`|Returns the number of combinations for n2 elements as divided into n1.|`combin(20,2)` returns 190.|
|
||||
|`cos(n)`|Returns the trigonometric cosine of a value.|`cos(5)` returns 0.28366218546322625.|
|
||||
|`cosh(n)`|Returns the hyperbolic cosine of a value.|`cosh(5)` returns 74.20994852478785.|
|
||||
|`degrees(n)`|Converts an angle from radians to degrees.|`degrees(5)` returns 286.4788975654116.|
|
||||
|`even(n)`|Rounds the number up to the nearest even integer.|`even(5)` returns 6.|
|
||||
|`exp(n)`|Returns [e](https://en.wikipedia.org/wiki/E_(mathematical_constant)) raised to the power of n.|`exp(5)` returns 148.4131591025766.|
|
||||
|`fact(n)`|Returns the factorial of a number, starting from 1.|`fact(5)` returns 120.|
|
||||
|`factn(n1, n2)`|Returns the factorial of n1, starting from n2.|`factn(10,3)` returns 280.|
|
||||
|`floor(n)`|Returns the floor of a number.|`3.7.floor()` returns 3 and `-3.7.floor()` returns -4.|
|
||||
|`gcd(n1, n2)`|Returns the greatest common denominator of two numbers.|`gcd(95,135)` returns 5.|
|
||||
|`lcm(n1, n2)`|Returns the least common multiple of two numbers.|`lcm(95,135)` returns 2565.|
|
||||
|`ln(n)`|Returns the natural logarithm of n.|`ln(5)` returns 1.6094379124341003.|
|
||||
|`log(n)`|Returns the base 10 logarithm of n.|`log(5)` returns 0.6989700043360189.|
|
||||
|`max(n1, n2)`|Returns the larger of two numbers.|`max(3,10)` returns 10.|
|
||||
|`min(n1, n2)`|Returns the smaller of two numbers.|`min(3,10)` returns 3.|
|
||||
|`mod(n1, n2)`|Returns n1 modulus n2. Note: `value.mod(9)` will work, whereas `74.mod(9)` will not work.|`mod(74, 9)` returns 2. |
|
||||
|`multinomial(n1, n2 …(optional))`|Calculates the multinomial of one number or a series of numbers.|`multinomial(2,3)` returns 10.|
|
||||
|`odd(n)`|Rounds the number up to the nearest odd integer.|`odd(10)` returns 11.|
|
||||
|`pow(n1, n2)`|Returns n1 raised to the power of n2. Note: value.pow(3)` will work, whereas `2.pow(3)` will not work.|`pow(2, 3)` returns 8 (2 cubed) and `pow(3, 2)` returns 9 (3 squared). The square root of any numeric value can be called with `value.pow(0.5)`.|
|
||||
|`quotient(n1, n2)`|Returns the integer portion of a division (truncated, not rounded), when supplied with a numerator and denominator.|`quotient(9,2)` returns 4.|
|
||||
|`radians(n)`|Converts an angle in degrees to radians.|`radians(10)` returns 0.17453292519943295.|
|
||||
|`randomNumber(n lowerBound, n upperBound)`|Returns a random integer in the interval between the lower and upper bounds (inclusively). Will output a different random number in each cell in a column.|
|
||||
|`round(n)`|Rounds a number to the nearest integer.|`3.7.round()` returns 4 and `-3.7.round()` returns -4.|
|
||||
|`sin(n)`|Returns the trigonometric sine of an angle.|`sin(10)` returns -0.5440211108893698.|
|
||||
|`sinh(n)`|Returns the hyperbolic sine of an angle.|`sinh(10)` returns 11013.232874703393.|
|
||||
|`sum(a)`|Sums the numbers in an array. Ignores non-number items. Returns 0 if the array does not contain numbers.|`sum([ 10, 2, three ])` returns 12.|
|
||||
|`tan(n)`|Returns the trigonometric tangent of an angle.|`tan(10)` returns 0.6483608274590866.|
|
||||
|`tanh(n)`|Returns the hyperbolic tangent of a value.|`tanh(10)` returns 0.9999999958776927.|
|
||||
|
||||
## Other functions {#other-functions}
|
||||
|
||||
###### type(o) {#typeo}
|
||||
Returns a string with the data type of o, such as undefined, string, number, boolean, etc. For example, a [Transform](cellediting#transform) operation using `value.type()` will convert all cells in a column to strings of their data types.
|
||||
|
||||
###### facetCount(choiceValue, s facetExpression, s columnName) {#facetcountchoicevalue-s-facetexpression-s-columnname}
|
||||
Returns the facet count corresponding to the given choice value, by looking for the facetExpression in the choiceValue in columnName. For example, to create facet counts for the following table, we could generate a new column based on “Gift” and enter in `value.facetCount("value", "Gift")`. This would add the column we've named “Count”:
|
||||
|
||||
| Gift | Recipient | Price | Count |
|
||||
|-|-|-|-|
|
||||
| lamp | Mary | 20 | 1 |
|
||||
| clock | John | 57 | 2 |
|
||||
| watch | Amit | 80 | 1 |
|
||||
| clock | Claire | 62 | 2 |
|
||||
|
||||
The facet expression, wrapped in quotes, can be useful to manipulate the inputted values before counting. For example, you could do a textual cleanup using fingerprint(): `(value.fingerprint()).facetCount(value.fingerprint(),"Gift")`.
|
||||
|
||||
###### hasField(o, s name) {#hasfieldo-s-name}
|
||||
Returns a boolean indicating whether o has a member field called [name](expressions#variables). For example, `cell.recon.hasField("match")` will return false if a reconciliation match hasn’t been selected yet, or true if it has. You cannot chain your desired fields: for example, `cell.hasField("recon.match")` will return false even if the above expression returns true).
|
||||
|
||||
###### coalesce(o1, o2, o3, ...) {#coalesceo1-o2-o3-}
|
||||
Returns the first non-null from a series of objects. For example, `coalesce(value, "")` would return an empty string “” if `value` was null, but otherwise return `value`.
|
||||
|
||||
###### cross(cell, s projectName (optional), s columnName (optional)) {#crosscell-s-projectname-optional-s-columnname-optional}
|
||||
Returns an array of zero or more rows in the project projectName for which the cells in their column columnName have the same content as the cell in your chosen column. For example, if two projects contained matching names, and you wanted to pull addresses for people by their names from a project called “People” you would apply the following expression to your column of names:
|
||||
```
|
||||
cell.cross("People","Name").cells["Address"].value[0]
|
||||
```
|
||||
|
||||
This would match your current column to the “Name” column in “People” and, using those matches, pull the respective “Address” value into your current project.
|
||||
|
||||
You may need to do some data preparation with cross(), such as using trim() on your key columns or deduplicating values.
|
||||
|
||||
The first argument will be interpreted as `cell.value` if set to `cell`. If you omit projectName and columnName, they will default to the current project and index column (number 0).
|
||||
|
||||
Recipes and more examples for using cross() can be found [on our wiki](https://github.com/OpenRefine/OpenRefine/wiki/Recipes#combining-datasets).
|
||||
@ -1,425 +0,0 @@
|
||||
---
|
||||
id: installing
|
||||
title: Installing OpenRefine
|
||||
sidebar_label: Installing
|
||||
---
|
||||
|
||||
## System requirements {#system-requirements}
|
||||
|
||||
OpenRefine does not require internet access to run its basic functions. Once you download and install it, it runs as a small web server on your own computer, and you access that local web server by using your browser. It only requires an internet connection to import data from the web, reconcile data using a web service, or export data to the web.
|
||||
|
||||
OpenRefine requires three things on your computer in order to function:
|
||||
|
||||
#### Compatible operating system {#compatible-operating-system}
|
||||
|
||||
OpenRefine is designed to work with **Windows**, **Mac**, and **Linux** operating systems. [Our team releases packages for each](https://openrefine.org/download.html).
|
||||
|
||||
#### Java {#java}
|
||||
|
||||
[Java](https://java.com/en/download/) must be installed and configured on your computer to run OpenRefine. The Mac version of OpenRefine includes Java; new in OpenRefine 3.4, there is also a Windows package with Java included.
|
||||
|
||||
If you install and start OpenRefine on a Windows computer without Java, it will automatically open up a browser window to the [Java downloads page](https://java.com/en/download/), and you can simply follow the instructions there.
|
||||
|
||||
We recommend you [download](https://java.com/en/download/) and install Java before proceeding with the OpenRefine installation. Please note that OpenRefine works with Java 8 to Java 15 but not Java 16 or later versions.
|
||||
|
||||
#### Compatible browser {#compatible-browser}
|
||||
|
||||
OpenRefine works best on browsers based on Webkit, such as:
|
||||
|
||||
* Google Chrome
|
||||
* Chromium
|
||||
* Opera
|
||||
* Microsoft Edge
|
||||
|
||||
We are aware of some minor rendering and performance issues on other browsers such as Firefox. We don't support Internet Explorer. If you are having issues running OpenRefine, see the [section on Running](running.md#troubleshooting).
|
||||
|
||||
### Release versions {#release-versions}
|
||||
|
||||
OpenRefine always has a [latest stable release](https://github.com/OpenRefine/OpenRefine/releases/latest), as well as some more recent developments available in beta, release candidate, or [snapshot releases](https://github.com/OpenRefine/OpenRefine-snapshot-releases/releases). If you are installing for the first time, we recommend [the latest stable release](https://github.com/OpenRefine/OpenRefine/releases/latest).
|
||||
|
||||
If you wish to use an extension that is only compatible with an earlier version of OpenRefine, and do not require the latest features, you may find that [an older stable version is best for you](https://github.com/OpenRefine/OpenRefine/releases) in our list of releases. Look at later releases to see which security vulnerabilities are being fixed, in order to assess your own risk tolerance for using earlier versions. Look for “final release” versions instead of “beta” or “release candidate” versions.
|
||||
|
||||
#### Unstable versions {#unstable-versions}
|
||||
|
||||
If you need a recently developed function, and are willing to risk some untested code, you can look at [the most recent items in the list](https://github.com/OpenRefine/OpenRefine/releases) and see what changes appeal to you.
|
||||
|
||||
“Beta” and “release candidate” versions may both have unreported bugs and are most suitable for people who are willing to help us troubleshoot these versions by [creating bug reports](https://github.com/OpenRefine/OpenRefine/issues).
|
||||
|
||||
For the absolute latest development updates, see the [snapshot releases](https://github.com/OpenRefine/OpenRefine-snapshot-releases/releases). These are created with every commit.
|
||||
|
||||
#### What’s changed {#whats-changed}
|
||||
|
||||
Our [latest version is OpenRefine 3.4.1](https://github.com/OpenRefine/OpenRefine/releases/tag/3.4.1), released September 24th 2020. The major changes in this version are listed on the [3.4.1 release page](https://github.com/OpenRefine/OpenRefine/releases/tag/3.4.1) with the downloadable packages.
|
||||
|
||||
You can find information about all OpenRefine versions on the [Releases page on Github](https://github.com/OpenRefine/OpenRefine/releases).
|
||||
|
||||
:::info Other distributions
|
||||
OpenRefine may also work in other environments, such as [Chromebooks](https://gist.github.com/organisciak/3e12e5138e44a2fed75240f4a4985b4f) where Linux terminals are available. Look at our list of [Other Distributions on the Downloads page](https://openrefine.org/download.html) for other ways of running OpenRefine, and refer to our contributor community to see new environments in development.
|
||||
:::
|
||||
|
||||
## Installing or upgrading {#installing-or-upgrading}
|
||||
### Back up your data {#back-up-your-data}
|
||||
|
||||
If you are upgrading from an older version of OpenRefine and have projects already on your computer, you should create backups of those projects before you install a new version.
|
||||
|
||||
First, [locate your workspace directory](#where-is-data-stored). Then copy everything you find there and paste it into a folder elsewhere on your computer.
|
||||
|
||||
For extra security you can [export your existing OpenRefine projects](exporting#export-a-project).
|
||||
|
||||
:::caution
|
||||
Take note of the [extensions](#installing-extensions) you have currently installed. They may not be compatible with the upgraded version of OpenRefine. Installations can be installed in two places, so be sure to check both your workspace directory and the existing installation directory.
|
||||
:::
|
||||
|
||||
### Install or upgrade OpenRefine {#install-or-upgrade-openrefine}
|
||||
|
||||
If you are upgrading an existing OpenRefine installation, you can delete the old program files and install the new files into the same space. Do not overwrite the files as some obsolete files may be left over unnecessarily.
|
||||
|
||||
:::caution
|
||||
If you have extensions installed, do not delete the `webapp\extensions` folder where you installed them. You may wish to install extensions into the workspace directory instead of the program directory. There is no guarantee that extensions will be forward-compatible with new versions of OpenRefine, and we do not maintain extensions.
|
||||
:::
|
||||
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
<Tabs
|
||||
groupId="operating-systems"
|
||||
defaultValue="win"
|
||||
values={[
|
||||
{label: 'Windows', value: 'win'},
|
||||
{label: 'Mac', value: 'mac'},
|
||||
{label: 'Mac via Homebrew', value: 'mac-hb'},
|
||||
{label: 'Linux', value: 'linux'}
|
||||
]
|
||||
}>
|
||||
|
||||
<TabItem value="win">
|
||||
|
||||
Once you have downloaded the `.zip` file, extract it into a folder where you wish to store program files (such as `D:\Program Files\OpenRefine`).
|
||||
|
||||
You can right-click on `openrefine.exe` or `refine.bat` and pin one of those programs to your Start Menu or create shortcuts for easier access.
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="mac">
|
||||
|
||||
Once you have downloaded the `.dmg` file, open it and drag the OpenRefine icon onto the Applications folder icon (just like you would normally install Mac applications).
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="mac-hb">
|
||||
|
||||
The quick version:
|
||||
|
||||
1. Install [Homebrew](http://brew.sh)
|
||||
2. In Terminal enter ` brew cask install openrefine`
|
||||
1. Then find OpenRefine in your Applications folder.
|
||||
|
||||
The long version:
|
||||
|
||||
[Homebrew](http://brew.sh) is a popular command-line package manager for Mac. Installing Homebrew is accomplished by pasting the installation command on the Homebrew website into a Terminal window. Once Homebrew is installed, applications like OpenRefine can be installed via a simple command. You can [install Homebrew from their website](http://brew.sh).
|
||||
|
||||
###### Install {#install}
|
||||
|
||||
Install OpenRefine with this command:
|
||||
|
||||
```
|
||||
brew cask install openrefine
|
||||
```
|
||||
|
||||
You should see output like this:
|
||||
|
||||
```
|
||||
==> Downloading https://github.com/OpenRefine/OpenRefine/releases/download/2.7/openrefine-mac-2.7.dmg
|
||||
########################### 100.0%
|
||||
==> Verifying checksum for Cask openrefine
|
||||
==> Installing Cask openrefine
|
||||
==> Moving App 'OpenRefine.app' to '/Applications/OpenRefine.app'.
|
||||
🍺 openrefine was successfully installed!
|
||||
```
|
||||
|
||||
Behind the scenes, this command causes Homebrew to download the OpenRefine installer, verify the file’s authenticity (using a SHA-256 checksum), mount the disk image, copy the `OpenRefine.app` application bundle into the Applications folder, unmount the disk image, and save a copy of the installer and metadata about the installation for future use.
|
||||
|
||||
If an existing `OpenRefine.app` is found in the Applications folder, Homebrew will not overwrite it, so installing via Homebrew requires either deleting or renaming previously installed copies.
|
||||
|
||||
###### Uninstall {#uninstall}
|
||||
|
||||
To uninstall OpenRefine, paste this command into the Terminal:
|
||||
|
||||
```
|
||||
brew cask uninstall openrefine
|
||||
```
|
||||
|
||||
You should see output like this:
|
||||
|
||||
```
|
||||
==> Removing App '/Applications/OpenRefine.app'.
|
||||
```
|
||||
|
||||
###### Update {#update}
|
||||
|
||||
To update to the latest version of OpenRefine, paste this command into the Terminal:
|
||||
|
||||
```
|
||||
brew cask reinstall openrefine
|
||||
```
|
||||
|
||||
You should see output like this:
|
||||
|
||||
```
|
||||
==> Downloading https://github.com/OpenRefine/OpenRefine/releases/download/2.7/openrefine-mac-2.7.dmg
|
||||
########################### 100.0%
|
||||
==> Verifying checksum for Cask openrefine
|
||||
==> Removing App '/Applications/OpenRefine.app'.
|
||||
==> Moving App 'OpenRefine.app' to '/Applications/OpenRefine.app'.
|
||||
🍺 openrefine was successfully installed!
|
||||
```
|
||||
|
||||
If you had previously installed the `openrefine-dev` cask (containing a release candidate) and you want to move to the stable release, you need to first uninstall the old cask and then install the new one:
|
||||
|
||||
```
|
||||
brew cask uninstall openrefine-dev
|
||||
brew cask install openrefine
|
||||
```
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="linux">
|
||||
|
||||
Once you have downloaded the `.tar.gz` file, open a shell, navigate to the folder containing the download, and type:
|
||||
|
||||
```
|
||||
tar xzf openrefine-linux-3.4.tar.gz
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
---
|
||||
|
||||
|
||||
### Set where data is stored {#set-where-data-is-stored}
|
||||
|
||||
OpenRefine stores data in two places: program files in the program directory, wherever it is you’ve installed it; and project files in what we call the “workspace directory.” You can access this folder easily from OpenRefine by going to the [home screen](running#the-home-screen) (at [http://127.0.0.1:3333/](http://127.0.0.1:3333/)) and clicking <span class="buttonLabels">Browse workspace directory</span>.
|
||||
|
||||
By default this is:
|
||||
|
||||
<Tabs
|
||||
groupId="operating-systems"
|
||||
defaultValue="win"
|
||||
values={[
|
||||
{label: 'Windows', value: 'win'},
|
||||
{label: 'Mac', value: 'mac'},
|
||||
{label: 'Linux', value: 'linux'}
|
||||
]
|
||||
}>
|
||||
|
||||
<TabItem value="win">
|
||||
|
||||
Depending on your version of Windows, the data is in one of these directories:
|
||||
* `%appdata%\OpenRefine`
|
||||
* `%localappdata%\OpenRefine`
|
||||
* `C:\Documents and Settings\(user id)\Local Settings\Application Data\OpenRefine`
|
||||
* `C:\Users\(user id)\AppData\Roaming\OpenRefine`
|
||||
* `C:\Users\(user id)\AppData\Local\OpenRefine`
|
||||
* `C:\Users\(user id)\OpenRefine`
|
||||
|
||||
For older Google Refine releases, replace `OpenRefine` with `Google\Refine`.
|
||||
|
||||
You can change this by adding this line to the file `openrefine.l4j.ini` and specifying your desired drive and folder path:
|
||||
|
||||
```
|
||||
-Drefine.data_dir=D:\MyDesiredFolder
|
||||
```
|
||||
|
||||
If your folder path has spaces, use neutral quotation marks around it:
|
||||
|
||||
```
|
||||
-Drefine.data_dir="D:\My Desired Folder"
|
||||
```
|
||||
|
||||
If the folder does not exist, OpenRefine will create it.
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="mac">
|
||||
|
||||
```
|
||||
~/Library/Application Support/OpenRefine/
|
||||
```
|
||||
|
||||
For older versions, as Google Refine:
|
||||
|
||||
```
|
||||
~/Library/Application Support/Google/Refine/
|
||||
```
|
||||
|
||||
Logging is to `/var/log/daemon.log` - grep for `com.google.refine.Refine`.
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="linux">
|
||||
|
||||
```
|
||||
~/.local/share/openrefine/
|
||||
```
|
||||
|
||||
You can change this when you run OpenRefine from the terminal, by pointing to the workspace directory through the `-d` parameter:
|
||||
|
||||
```
|
||||
./refine -p 3333 -i 0.0.0.0 -m 6000M -d /My/Desired/Folder
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
---
|
||||
|
||||
|
||||
### Logs {#logs}
|
||||
|
||||
OpenRefine does not currently output an error log, but because the OpenRefine console window is always open (on Linux and Windows) while OpenRefine runs in your browser, you can copy information from the console if an error occurs.
|
||||
|
||||
Using a Mac, you can [run OpenRefine using the terminal](running#starting-and-exiting) in order to capture errors.
|
||||
|
||||
---
|
||||
|
||||
## Increasing memory allocation {#increasing-memory-allocation}
|
||||
|
||||
OpenRefine relies on having computer memory available to it to work effectively. If you are planning to work with large datasets, you may wish to set up OpenRefine to handle it at the outset. By “large” we generally mean one of the following indicators:
|
||||
* more than one million total cells
|
||||
* an input file size of more than 50 megabytes (MB)
|
||||
* more than 50 [rows per record in records mode](running#records-mode)
|
||||
|
||||
By default OpenRefine is set to operate with 1 gigabyte (GB) of memory (1024MB). If you feel that OpenRefine is running slowly, or you are getting “out of memory” errors (for example, `java.lang.OutOfMemoryError`), you can try allocating more memory.
|
||||
|
||||
A good practice is to start with no more than 50% of whatever memory is left over after the estimated usage of your operating system, to leave memory for your browser to run.
|
||||
|
||||
All of the settings below use a four-digit number to specify the megabytes (MB) used (actually [mebibytes](https://en.wikipedia.org/wiki/Mebibyte)). The default is usually 1024MB, but the new value doesn't need to be a multiple of 1024.
|
||||
|
||||
:::info Dealing with large datasets
|
||||
If your project is big enough to need more than the default amount of memory, consider turning off <span class="fieldLabels">Parse cell text into numbers, dates, ...</span> on import. It's convenient, but less efficient than explicitly converting any columns that you need as a data type other than the default “string” type.
|
||||
:::
|
||||
|
||||
<Tabs
|
||||
groupId="operating-systems"
|
||||
defaultValue="win"
|
||||
values={[
|
||||
{label: 'Windows', value: 'win'},
|
||||
{label: 'Mac', value: 'mac'},
|
||||
{label: 'Linux', value: 'linux'}
|
||||
]
|
||||
}>
|
||||
|
||||
<TabItem value="win">
|
||||
|
||||
#### Using openrefine.exe {#using-openrefineexe}
|
||||
|
||||
If you run `openrefine.exe`, you will need to edit the `openrefine.l4j.ini` file found in the program directory and edit the line
|
||||
|
||||
```
|
||||
# max memory memory heap size
|
||||
-Xmx1024M
|
||||
```
|
||||
|
||||
The line “-Xmx1024M” defines the amount of memory available in megabytes. Change the number “1024” - for example, edit the line to “-Xmx2048M” to make 2048MB [2GB] of memory available.
|
||||
|
||||
:::caution openrefine.exe not running?
|
||||
Once you increase the memory allocation, you may find that you cannot run `openrefine.exe`. In this case, your computer needs a 64-bit version of [Java](https://www.java.com/en/download/help/index_installing.xml) (this is different from [Java JDK](#install-or-upgrade-java). Look for the “Windows Offline (64-bit)” download on the Downloads page and install that. Your system must also be set to use the 64-bit version of Java by [changing the Java configuration](https://www.java.com/en/download/help/update_runtime_settings.xml).
|
||||
:::
|
||||
|
||||
#### Using refine.bat {#using-refinebat}
|
||||
|
||||
On Windows, OpenRefine can also be run by using the file `refine.bat` in the program directory. If you start OpenRefine using `refine.bat`, the memory available to OpenRefine can be specified either through command line options, or through the `refine.ini` file.
|
||||
|
||||
To set the maximum amount of memory on the command line when using `refine.bat`, `cd` to the program directory, then type
|
||||
|
||||
```refine.bat /m 2048m```
|
||||
|
||||
where “2048” is the maximum amount of MB that you want OpenRefine to use.
|
||||
|
||||
To change the default that `refine.bat` uses, edit the `refine.ini` line that reads
|
||||
|
||||
```REFINE_MEMORY=1024M```
|
||||
|
||||
Note that this file is only read if you use `refine.bat`, not `openrefine.exe`.
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="mac">
|
||||
|
||||
If you have downloaded the `.dmg` package and you start OpenRefine by double-clicking on it:
|
||||
|
||||
* close OpenRefine
|
||||
* control-click on the OpenRefine icon (opens the contextual menu)
|
||||
* click on "show package content” (a finder window opens)
|
||||
* open the “Contents” folder
|
||||
* open the `Info.plist` file with any text editor (like Mac's default TextEdit)
|
||||
* Change “-Xmx1024M” into, for example, “-Xmx2048M” or “-Xmx8G”
|
||||
* save the file
|
||||
* restart OpenRefine.
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="linux">
|
||||
|
||||
If you have downloaded the `.tar.gz` package and you start OpenRefine from the command line, add the “-m xxxxM” parameter like this:
|
||||
`./refine -m 2048m`
|
||||
|
||||
#### Setting a default {#setting-a-default}
|
||||
|
||||
If you don't want to set this option on the command line each time, you can also set it in the `refine.ini` file. Edit the line
|
||||
|
||||
```
|
||||
REFINE_MEMORY=1024M
|
||||
```
|
||||
|
||||
Make sure it is not commented out (that is, that the line doesn't start with a “#” character), and change “1024” to a higher value. Save the file, and when you next start OpenRefine it will use this value.
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
---
|
||||
|
||||
|
||||
## Installing extensions {#installing-extensions}
|
||||
|
||||
Extensions have been created by our contributor community to add functionality or provide convenient shortcuts for common uses of OpenRefine. [We list extensions we know about on our downloads page](https://openrefine.org/download.html).
|
||||
|
||||
:::info Contributing extensions
|
||||
If you’d like to create or modify an extension, [see our developer documentation here](https://github.com/OpenRefine/OpenRefine/wiki/Documentation-For-Developers). If you’re having a problem, [use our downloads page](https://openrefine.org/download.html) to go to the extension’s page and report the issue there.
|
||||
:::
|
||||
|
||||
### Two ways to install extensions {#two-ways-to-install-extensions}
|
||||
|
||||
You can [install extensions in one of two places](#set-where-data-is-stored):
|
||||
|
||||
* Into your OpenRefine program folder, so they will only be available to that version/installation of OpenRefine (meaning the extension will not run if you upgrade OpenRefine), or
|
||||
* Into your workspace, where your projects are stored, so they will be available no matter which version of OpenRefine you’re using.
|
||||
|
||||
We provide these options because you may wish to reinstall a given extension manually each time you upgrade OpenRefine, in order to be sure it works properly.
|
||||
|
||||
### Find the right place to install {#find-the-right-place-to-install}
|
||||
|
||||
If you want to install the extension into the program folder, go to your program directory and then go to `webapp\extensions` (or create it if not does not exist).
|
||||
|
||||
If you want to install the extension into your workspace, you can:
|
||||
* launch OpenRefine and click <span class="menuItems">Open Project</span> in the sidebar
|
||||
* At the bottom of the screen, click <span class="menuItems">Browse workspace directory</span>
|
||||
* A file-explorer or finder window will open in your workspace
|
||||
* Create a new folder called “extensions” inside the workspace if it does not exist.
|
||||
|
||||
You can also [find your workspace on each operating system using these instructions](#set-where-data-is-stored).
|
||||
|
||||
### Install the extension {#install-the-extension}
|
||||
|
||||
Some extensions have their own instructions: make sure you read the documentation before you begin installing.
|
||||
|
||||
Some extensions may have multiple versions, to match OpenRefine versions, so be sure to choose the right release for your installation. If you have questions about compatibility or want to request or voice your support for an update, [use our downloads page](https://openrefine.org/download.html) to go to the extension’s page and report the issue there.
|
||||
|
||||
Generally, the installation process will be:
|
||||
|
||||
* Download the extension (usually as a zip file from GitHub)
|
||||
* Extract the zip contents into the “extensions” directory, making sure all the contents go into one folder with the name of the extension
|
||||
* Start (or restart) OpenRefine.
|
||||
|
||||
To confirm that installation was a success, follow the instructions provided by the extension. Each extension will appear in its own way inside the OpenRefine interface. Make sure you read its documentation to know where the functionality will appear, such as under specific dropdown menus.
|
||||
@ -1,76 +0,0 @@
|
||||
---
|
||||
id: jythonclojure
|
||||
title: Jython & Clojure
|
||||
sidebar_label: Jython & Clojure
|
||||
---
|
||||
|
||||
## Jython {#jython}
|
||||
|
||||
Jython 2.7.2 comes bundled with the default installation of OpenRefine 3.4.1. You can add libraries and code by following [this tutorial](https://github.com/OpenRefine/OpenRefine/wiki/Extending-Jython-with-pypi-modules). A large number of Python files (`.py` or `.pyc`) are compatible.
|
||||
|
||||
Python code that depends on C bindings will not work in OpenRefine, which uses Java / Jython only. Since Jython is essentially Java, you can also import Java libraries and utilize those.
|
||||
|
||||
You will need to restart OpenRefine, so that new Jython or Python libraries are initialized during startup.
|
||||
|
||||
OpenRefine now has [most of the Jsoup.org library built into GREL functions](grelfunctions#jsoup-xml-and-html-parsing-functions) for parsing and working with HTML and XML elements.
|
||||
|
||||
### Syntax {#syntax}
|
||||
|
||||
Expressions in Jython must have a `return` statement:
|
||||
|
||||
```
|
||||
return value[1:-1]
|
||||
```
|
||||
|
||||
```
|
||||
return rowIndex%2
|
||||
```
|
||||
|
||||
Fields have to be accessed using the bracket operator rather than dot notation:
|
||||
|
||||
```
|
||||
return cells["col1"]["value"]
|
||||
```
|
||||
|
||||
For example, to access the [edit distance](reconciling#reconciliation-facets) between a reconciled value and an original cell value using [recon variables](#reconciliation):
|
||||
|
||||
```
|
||||
return cell["recon"]["features"]["nameLevenshtein"]
|
||||
```
|
||||
|
||||
To return the lower case of `value` (if the value is not null):
|
||||
|
||||
```
|
||||
if value is not None:
|
||||
return value.lower()
|
||||
else:
|
||||
return None
|
||||
```
|
||||
|
||||
### Tutorials {#tutorials}
|
||||
- [Extending Jython with pypi modules](https://github.com/OpenRefine/OpenRefine/wiki/Extending-Jython-with-pypi-modules)
|
||||
- [Working with phone numbers using Java libraries inside Python](https://github.com/OpenRefine/OpenRefine/wiki/Jython#tutorial---working-with-phone-numbers-using-java-libraries-inside-python)
|
||||
|
||||
Full documentation on the Jython language can be found on its official site: [http://www.jython.org](http://www.jython.org).
|
||||
|
||||
## Clojure {#clojure}
|
||||
|
||||
Clojure 1.10.1 comes bundled with the default installation of OpenRefine 3.4.1. At this time, not all [variables](expressions#variables) can be used with Clojure expressions: only `value`, `row`, `rowIndex`, `cell`, and `cells` are available.
|
||||
|
||||
For example, functions can take the form
|
||||
```
|
||||
(.. value (toUpperCase) )
|
||||
```
|
||||
|
||||
Or can look like
|
||||
```
|
||||
(-> value (str/split #" ") last )
|
||||
```
|
||||
|
||||
which functions like `value.split(" ")` in GREL.
|
||||
|
||||
For help with syntax, see the [Clojure website's guide to syntax](https://clojure.org/guides/learn/syntax).
|
||||
|
||||
User-contributed Clojure recipes can be found on our wiki at [https://github.com/OpenRefine/OpenRefine/wiki/Recipes#11-clojure](https://github.com/OpenRefine/OpenRefine/wiki/Recipes#11-clojure).
|
||||
|
||||
Full documentation on the Clojure language can be found on its official site: [https://clojure.org/](https://clojure.org/).
|
||||
@ -1,242 +0,0 @@
|
||||
---
|
||||
id: reconciling
|
||||
title: Reconciling
|
||||
sidebar_label: Reconciling
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
Reconciliation is the process of matching your dataset with that of an external source. Datasets for comparison might be produced by libraries, archives, museums, academic organizations, scientific institutions, non-profits, or interest groups. You can also reconcile against user-edited data on [Wikidata or other Wikibase instances](wikibase/reconciling), or reconcile against [a local dataset that you yourself supply](https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources#local-services).
|
||||
|
||||
To reconcile your OpenRefine project against an external dataset, that dataset must offer a web service that conforms to the [Reconciliation Service API standards](https://reconciliation-api.github.io/specs/0.1/).
|
||||
|
||||
You may wish to reconcile in order to:
|
||||
* fix spelling or variations in proper names
|
||||
* clean up manually-entered subject headings against authorities such as the [Library of Congress Subject Headings](https://id.loc.gov/authorities/subjects.html) (LCSH)
|
||||
* link your data to an existing dataset
|
||||
* add to an editable platform such as [Wikidata](https://www.wikidata.org)
|
||||
* or see whether entities in your project appear in some specific list, such as the [Panama Papers](https://aleph.occrp.org/datasets/734).
|
||||
|
||||
Reconciliation is semi-automated: OpenRefine matches your cell values to the reconciliation information as best it can, but human judgment is required to review and approve the results. Reconciling happens by default through string searching, so typos, whitespace, and extraneous characters will have an effect on the results. You may wish to [clean and cluster](cellediting) your data before reconciliaton.
|
||||
|
||||
:::info Working iteratively
|
||||
We recommend planning your reconciliation operations as iterative: reconcile multiple times with different settings, and with different subgroups of your data.
|
||||
:::
|
||||
|
||||
## Sources {#sources}
|
||||
|
||||
Start with [this current list of reconcilable authorities](https://reconciliation-api.github.io/testbench/), which includes instructions for adding new services via Wikidata editing if you have one to add.
|
||||
|
||||
OpenRefine maintains a [further list of sources on the wiki](https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources), which can be edited by anyone. This list includes ways that you can reconcile against a [local dataset](https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources#local-services).
|
||||
|
||||
Other services may exist that are not yet listed in these two places: for example, the [310 datasets hosted by the Organized Crime and Corruption Reporting Project (OCCRP)](https://aleph.occrp.org/datasets/) each have their own reconciliation URL, or you can reconcile against their entire database with the URL [shared on the reconciliation API list](https://reconciliation-api.github.io/testbench/). For another example, you can reconcile against the entire Virtual International Authority File (VIAF) dataset, or [only the contributions from certain institutions](http://refine.codefork.com/). Search online to see if the authority you wish to reconcile against has an available service, or whether you can download a copy to reconcile against locally.
|
||||
|
||||
OpenRefine includes Wikidata reconciliation in the installation package - see the [Wikibase](wikibase/reconciling) page for more information particular to that service. Extensions can add reconciliation services, and can also add enhanced reconciliation capacities. Check the list of extensions on the [Downloads page](https://openrefine.org/download.html) for more information.
|
||||
|
||||
Each source will have its own documentation on how it provides reconciliation. The table on [the reconciliation API list](https://reconciliation-api.github.io/testbench/) indicates whether your chosen service supports the features described below. Refer to the service's documentation if you have questions about its behaviors and which OpenRefine features it supports.
|
||||
|
||||
In addition to the reconciliation services mentioned above, you may also choose to build your own service. You can either start from scratch using the [API specification](https://reconciliation-api.github.io/specs/latest/) or use one of the frameworks mentioned in the [Reconciliation census](https://reconciliation-api.github.io/census/services/).
|
||||
|
||||
Of particular note is [reconcile-csv](http://okfnlabs.org/reconcile-csv/) which allows you to build a reconciliation service from a simple CSV file. Thus if you wanted to reconcile one OpenRefine project against another, you'd simply need to export the target project as a CSV, point `reconcile-csv` at it and you're good to go. A somewhat newer port of this project written in Python can be found at [csv-reconcile](https://github.com/gitonthescene/csv-reconcile) which is more configurable and defaults to parsing tab separated files for convenience.
|
||||
|
||||
Similiarly, you may choose to export some SPARQL output to a TSV to limit the scope of values you're reconciling against and/or for better peformance.
|
||||
|
||||
## Getting started {#getting-started}
|
||||
|
||||
Choose a column to reconcile and use its dropdown menu to select <span class="menuItems">Reconcile</span> → <span class="menuItems">Start reconciling</span>. If you want to reconcile only some cells in that column, first use filters and facets to isolate them.
|
||||
|
||||
In the reconciliation window, you will see Wikidata offered as a default service. To add another service, click <span class="buttonLabels">Add Standard Service...</span> and paste in the URL of a [service](#sources). You should see the name of the service appear in the list of <span class="buttonLabels">Services</span> if the URL is correct.
|
||||
|
||||

|
||||
|
||||
Once you select a service, your selected column may be sampled in order to suggest [“types” (categories)](#reconciling-by-type) to reconcile against. Other services will suggest their available types without sampling, and some services have no types.
|
||||
|
||||
For example, if you had a list of artists represented in a gallery collection, you could reconcile their names against the Getty Research Institute’s [Union List of Artist Names (ULAN)](https://www.getty.edu/research/tools/vocabularies/ulan/). The same [Getty reconciliation URL](https://services.getty.edu/vocab/reconcile/) will offer you ULAN, AAT (Art and Architecture Thesaurus), and TGN (Thesaurus of Geographic Names).
|
||||
|
||||

|
||||
|
||||
Refer to the [documentation specific to the reconciliation service](https://reconciliation-api.github.io/testbench/) to learn whether types are offered, which types are offered, and which one is most appropriate for your column. You may wish to facet your data and reconcile batches against different types if available.
|
||||
|
||||
Reconciliation can be a time-consuming process, especially with large datasets. We suggest starting with a small test batch. There is no throttle (delay between requests) to set for the reconciliation process. The amount of time will vary for each service, and vary based on the options you select during the process.
|
||||
|
||||
When the process is done, you will see the reconciliation data in the cells.
|
||||
If the cell was successfully matched, it displays text as a single dark blue link. In this case, the reconciliation is confident that the match is correct, and you should not have to check it manually.
|
||||
If there is no clear match, one or more candidates are displayed, together with their reconciliation score, with the text in light blue links. You will need to select the correct one.
|
||||
|
||||
For each matching decision you make, you have two options: match this cell only (one checkmark), or also use the same identifier for all other cells containing the same original string (two checkmarks).
|
||||
|
||||
For services that offer the [“preview entities” feature](https://reconciliation-api.github.io/testbench/), you can hover your mouse over the suggestions to see more information about the candidates or matches. Each participating service (and each type) will deliver different structured data that may help you compare the candidates.
|
||||
|
||||
For example, the Getty ULAN shows an artist’s discipline, nationality, and birth and death years:
|
||||
|
||||

|
||||
|
||||
Hovering over the suggestion will also offer the two matching options as buttons.
|
||||
|
||||
For matched values (those appearing as dark blue links), the underlying cell value has not been altered - the cell is storing both the original string and the matched entity link at the same time. If you were to copy your column to a new column at this point using `value`, for example, the reconcilation data would not transfer - only the original strings. You can learn more about how OpenRefine stores different pieces of information in each cell in [the Variables section specific to reconciliation data](expressions#reconciliation).
|
||||
|
||||
For each cell, you can manually “Create new item,” which will take the cell’s original value and apply it, as though it is a match. This will not become a dark blue link, because at this time there is nothing to link to: it is a draft entity stored only in your project. You can use this feature to prepare these entries for eventual upload to an editable service such as [Wikibase](wikibase/overview), but most services do not yet support this feature.
|
||||
|
||||
### Reconciliation facets {#reconciliation-facets}
|
||||
|
||||
Under <span class="menuItems">Reconcile</span> → <span class="menuItems">Facets</span> there are a number of reconciliation-specific faceting options. OpenRefine automatically creates two facets when you reconcile some cells.
|
||||
|
||||
One is a numeric facet for “best candidate's score,” the range of reconciliation scores of only the best candidate of each cell. Higher scores mean better matches, although each service calculates scores differently and has a different range. You can facet for higher scores using the numeric facet, and then approve them all in bulk, by using <span class="menuItems">Reconcile</span> → <span class="menuItems">[Actions](#reconciliation-actions)</span> → <span class="menuItems">Match each cell to its best candidate</span>.
|
||||
|
||||
There is also a “judgment” facet created, which lets you filter for the cells that haven't been matched (pick “none” in the facet). As you process each cell, its judgment changes from “none” to “matched” and it disappears from the view.
|
||||
|
||||
You can add other facets by selecting <span class="menuItems">Reconcile</span> → <span class="menuItems">Facets</span> on your reconciled column. You can facet by:
|
||||
|
||||
* your judgments (“matched,” or “none” for unreconciled cells, or “new” for entities you've created)
|
||||
* the action you’ve performed on that cell (chosen a “single” match, or set a “mass” match, or no action, which appears as “unknown”)
|
||||
* the timestamps on the edits you’ve made so far (these appear as millisecond counts since an arbitrary point: they can be sorted alphabetically to move forward and back in time).
|
||||
|
||||
You can facet only the best candidates for each cell, based on:
|
||||
* the score (calculated based on each service's own methods)
|
||||
* the edit distance (using the [Levenshtein distance](cellediting#nearest-neighbor), a number based on how many single-character edits would be required to get your original value to the candidate value, with a larger value being a greater difference)
|
||||
* the word similarity.
|
||||
|
||||
Word similarity is calculated as a percentage based on how many words (excluding [stop words](https://en.wikipedia.org/wiki/Stop_word)) in the original value match words in the candidate. For example, the value “Maria Luisa Zuloaga de Tovar” matched to the candidate “Palacios, Luisa Zuloaga de” results in a word similarity value of 0.6, or 60%, or 3 out of 5 words. Cells that are not yet matched to one candidate will show as 0.0).
|
||||
|
||||
You can also look at each best candidate’s:
|
||||
* type (the ones you have selected in successive reconciliation attempts, or other types returned by the service based on the cell values)
|
||||
* type match (“true” if you selected a type and it succeeded, “false” if you reconciled against no particular type, and “(no type)” if it didn’t reconcile)
|
||||
* name match (“true” if you’ve matched, “false” if you haven’t yet chosen from the candidates, or “(unreconciled)” if it didn’t reconcile).
|
||||
|
||||
These facets are useful for doing successive reconciliation attempts, against different types, and with different supplementary information. The information represented by these facets are held in the cells themselves and can be called using the [reconciliation variables](expressions#reconciliation) available in expressions.
|
||||
|
||||
### Reconciliation actions {#reconciliation-actions}
|
||||
|
||||
You can use the <span class="menuItems">Reconcile</span> → <span class="menuItems">Actions</span> menu options to perform bulk changes (which will apply only to your currently viewed set of rows or records):
|
||||
* <span class="menuItems">Match each cell to its best candidate</span> (by highest score)
|
||||
* <span class="menuItems">Create a new item for each cell</span> (discard any suggested matches)
|
||||
* <span class="menuItems">Create one new item for similar cells</span> (a new entity will be created for each unique string)
|
||||
* <span class="menuItems">Match all filtered cells to...</span> (a specific item from the chosen service, via a search box; only works with services that support the “suggest entities” property)
|
||||
* <span class="menuItems">Discard all reconciliation judgments</span> (reverts back to multiple candidates per cell, including cells that may have been auto-matched in the original reconciliation process)
|
||||
* <span class="menuItems">Clear reconciliation data</span>, reverting all cells back to their original values.
|
||||
|
||||
The other options available under <span class="menuItems">Reconcile</span> are:
|
||||
* <span class="menuItems">Copy reconciliation data...</span> (to an existing column: if the original values in your reconciliation column are identical to those in your chosen column, the matched and new cells will copy over; unmatched values will not change)
|
||||
* [<span class="menuItems">Use values as identifiers</span>](#reconciling-with-unique-identifiers) (if you are reconciling with unique identifiers instead of by doing string searches)
|
||||
* [<span class="menuItems">Add entity identifiers column</span>](#add-entity-identifiers-column).
|
||||
|
||||
## Reconciling with unique identifiers {#reconciling-with-unique-identifiers}
|
||||
|
||||
Reconciliation services use unique identifiers for their entities. For example, the 14th Dalai Lama has the VIAF ID [38242123](https://viaf.org/viaf/38242123/) and the Wikidata ID [Q17293](https://www.wikidata.org/wiki/Q37349). You can supply these identifiers directly to your chosen reconciliation service in order to pull more data, but these strings will not be “reconciled” against the external dataset.
|
||||
|
||||
Select the column with unique identifiers and apply the operation <span class="menuItems">Reconcile</span> → <span class="menuItems">Use values as identifiers</span>. This will bring up the list of reconciliation services you have already added (to add a new service, open the <span class="menuItems">Start reconciling...</span> window first). If you use this operation on a column of IDs, you will not have access to the usual reconciliation settings.
|
||||
|
||||
Matching identifiers does not validate them. All cells will appear as dark blue “confirmed” matches. You should check before this operation that the identifiers in the column exist on the target service.
|
||||
|
||||
You may get false positives, which you will need to hover over or click on to identify:
|
||||
|
||||

|
||||
|
||||
## Reconciling by type {#reconciling-by-type}
|
||||
|
||||
Reconciliation services, once added to OpenRefine, may suggest types from their databases. These types will usually be whatever the service specializes in: people, events, places, buildings, tools, plants, animals, organizations, etc.
|
||||
|
||||
Reconciling against a type may be faster and more accurate, but may result in fewer matches. Some services have hierarchical types (such as “mammal” as a subtype of “animal”). When you reconcile against a more specific type, unmatched values may fall back to the broader type; other services will not do this, so you may need to perform successive reconciliation attempts against different types. Refer to the documentation specific to the reconciliation service to learn more.
|
||||
|
||||
When you select a service from the list, OpenRefine will load some or all available types. Some services will sample the first ten rows of your column to suggest types (check the [“Suggest types” column](https://reconciliation-api.github.io/testbench/)). You will see a service’s types in the reconciliation window:
|
||||
|
||||

|
||||
|
||||
In this example, “Person” and “Corporate Name” are potential types offered by the reconciliation API for VIAF. You can also use the <span class="fieldLabels">Reconcile against type:</span> field to enter in another type that the service offers. When you start typing, this field may search and suggest existing types. For VIAF, you could enter “/book/book” if your column contained publications. You may need to enter the service's own strings precisely instead of attempting to search for a match.
|
||||
|
||||
Types are structured to fit their content: the Wikidata “human” type, for example, can include fields for birth and death dates, nationality, etc. The VIAF “person” type can include nationality and gender. You can use this to [include more properties](#reconciling-with-additional-columns) and find better matches.
|
||||
|
||||
If your column doesn’t fit one specific type offered, you can <span class="fieldLabels">Reconcile against no particular type</span>. This may take longer.
|
||||
|
||||
We recommend working in batches and reconciling against different types, moving from specific to broad. You can create a facet for <span class="menuItems">Best candidate’s types</span> facet to see which types are being represented. Some candidates may return more than one type, depending on the service. Types may appear in facets by their unique IDs, rather than by their semantic labels (for example, Q5 for “human” in Wikidata).
|
||||
|
||||
## Reconciling with additional columns {#reconciling-with-additional-columns}
|
||||
|
||||
Some of your cells may be ambiguous, in the sense that a string can point to more than one entity: there are dozens of places called “Paris” and many characters, people, and pieces of culture, too. Selecting non-geographic or more localized types can help narrow that down, but if your chosen service doesn't provide a useful type, you can include more properties that make it clear whether you're looking for Paris, France.
|
||||
|
||||

|
||||
|
||||
Including supplementary information can be useful, depending on the service (such as including birthdate information about each person you are trying to reconcile). You can re-reconcile unmatched cells with additional properties, in the right side of the <span class="menuItems">Start reconciling</span> window, under “Also use relevant details from other columns.” The column names in your project will appear in the reconciliation window, with an <span class="fieldLabels">Include?</span> checkbox next to each one.
|
||||
|
||||
Fill in the <span class="fieldLabels">As Property</span> field with the type of information you are including. When you start typing, potential fields may pop up (depending on the [“suggest properties” feature](https://reconciliation-api.github.io/testbench/)), such as “birthDate” in the case of ULAN or “Geburtsdatum” in the case of Integrated Authority File (GND). Use the documentation for your chosen service to identify the fields in their terms.
|
||||
|
||||
Some services will not be able to search for the exact name of your desired <span class="fieldLabels">As Property</span> entry, but you can still manually supply the field name. Refer to the service to choose the most appropriate field, and make sure you enter it correctly.
|
||||
|
||||

|
||||
|
||||
## Fetching more data {#fetching-more-data}
|
||||
|
||||
One reason to reconcile to some external service is that it allows you to pull data from that service into your OpenRefine project. There are three ways to do this:
|
||||
|
||||
* Add identifiers for your values
|
||||
* Add columns from reconciled values
|
||||
* Add column by fetching URLs.
|
||||
|
||||
### Add entity identifiers column {#add-entity-identifiers-column}
|
||||
|
||||
Once you have selected matches for your cells, you can retrieve the unique identifiers for those cells and create a new column for these, with <span class="menuItems">Reconcile</span> → <span class="menuItems">Add entity identifiers column</span>. You will be asked to supply a column name. New items and other unmatched cells will generate null values in this column.
|
||||
|
||||
### Add columns from reconciled values {#add-columns-from-reconciled-values}
|
||||
|
||||
If the reconciliation service supports [data extension](https://reconciliation-api.github.io/testbench/), then you can augment your reconciled data with new columns using <span class="menuItems">Edit column</span> → <span class="menuItems">Add columns from reconciled values...</span>.
|
||||
|
||||
For example, if you have a column of chemical elements identified by name, you can fetch categorical information about them such as their atomic number and their element symbol:
|
||||
|
||||

|
||||
|
||||
Once you have chosen reconciliation matches for your cells, selecting <span class="menuItems">Add column from reconciled values...</span> will bring up a window to choose which related information you’d like to import into new columns. You can manually enter desired properties, or select from a list of suggestions.
|
||||
|
||||
The quality of the suggested properties will depend on how you have reconciled your data beforehand: reconciling against a specific type will provide you with the associated properties of that type. For example, GND suggests elements about the “people” type after you've reconciled with it, such as their parents, native languages, children, etc.
|
||||
|
||||

|
||||
|
||||
If you have left any values unreconciled in your column, you will see “<not reconciled>” in the preview. These will generate blank cells if you continue with the column addition process.
|
||||
|
||||
This process may pull more than one property per row in your data (such as multiple occupations), so you may need to switch into records mode after you've added columns.
|
||||
|
||||
### Add columns by fetching URLs {#add-columns-by-fetching-urls}
|
||||
|
||||
If the reconciliation service cannot extend data, look for a generic web API for that data source, or a structured URL that points to their dataset entities via unique IDs (such as “https://viaf.org/viaf/000000”). You can use the <span class="menuItems">Edit column</span> → <span class="menuItems">[Add column by fetching URLs](columnediting#add-column-by-fetching-urls)</span> operation to call this API or URL with the IDs obtained from the reconciliation process. This will require using [expressions](expressions).
|
||||
|
||||
You may not want to pull the entire HTML content of the pages at the ends of these URLs, so look to see whether the service offers a metadata endpoint, such as JSON-formatted data. You can either use a column of IDs, or you can pull the ID from each matched cell during the fetching process.
|
||||
|
||||
For example, if you have reconciled artists to the Getty's ULAN, and [have their unique ULAN IDs as a column](#add-entity-identifiers-column), you can generate a new column of JSON-formatted data by using <span class="menuItems">Add column by fetching URLs</span> and entering the GREL expression `"http://vocab.getty.edu/" + value + ".json"`. For this service, the unique IDs are formatted “ulan/000000” and so the generated URLs look like “http://vocab.getty.edu/ulan/000000.json”.
|
||||
|
||||
Alternatively, you can insert the ID directly from the matched column's reconciliation variables, using a GREL expression like `“http://vocab.getty.edu/” + cell.recon.match.id + “.json”` instead.
|
||||
|
||||
Remember to set an appropriate throttle and to refer to the service documentation to ensure your compliance with their terms. See [the section about this operation](columnediting#add-column-by-fetching-urls) to learn more about the fetching process.
|
||||
|
||||
## Keep all the suggestions made {#keep-all-the-suggestions-made}
|
||||
|
||||
To generate a list of each suggestion made, rather than only the best candidate, you can use a [GREL expression](expressions#GREL). Go to <span class="menuItems">Edit column</span> → <span class="menuItems">Add column based on this column</span>. To create a list of all the possible matches, use something like
|
||||
|
||||
```
|
||||
forEach(cell.recon.candidates,c,c.name).join(", ")
|
||||
```
|
||||
|
||||
To get the unique identifiers of these matches instead, use
|
||||
|
||||
```
|
||||
forEach(cell.recon.candidates,c,c.id).join(", ")
|
||||
```
|
||||
|
||||
This information is stored as a string, without any attached reconciliation information.
|
||||
|
||||
## Writing reconciliation expressions {#writing-reconciliation-expressions}
|
||||
|
||||
OpenRefine supplies a number of variables related specifically to reconciled values. These can be used in GREL and Jython expressions. For example, some of the reconciliation variables are:
|
||||
|
||||
* `cell.recon.match.id` or `cell.recon.match.name` for matched values
|
||||
* `cell.recon.best.name` or `cell.recon.best.id` for best-candidate values
|
||||
* `cell.recon.candidates` for all listed candidates of each cell
|
||||
* `cell.recon.judgment` (the values used in the “judgment” facet)
|
||||
* `cell.recon.judgmentHistory` (the values used in the “judgment action timestamp” facet)
|
||||
* `cell.recon.matched` (a “true” or “false” value)
|
||||
|
||||
You can find out more in the [reconciliaton variables](expressions#reconciliaton-variables) section.
|
||||
|
||||
## Exporting reconciled data {#exporting-reconciled-data}
|
||||
|
||||
Once you have data that is reconciled to existing entities online, you may wish to export that data to a user-editable service such as Wikidata. See the section on [uploading your edits to Wikidata or other Wikibase instances](wikibase/uploading) for more information, or the section on [exporting](exporting) to see other formats OpenRefine can produce.
|
||||
|
||||
You can share reconciled data in progress through a [project export or import](exporting#export-a-project), with some preparation. The importing user needs to have the appropriate reconciliation services installed on their OpenRefine instance (by going to <span class="menuItems">Start reconciling</span> and clicking on <span class="buttonLabels">Add Standard Service...</span>) in advance of opening the project, in order to use candidate and match links. Otherwise, the links will be broken and the user will need to add the reconciliation service and re-reconcile the columns in question. [Wikidata](wikibase/reconciling) reconciliation data can be shared more easily as the service comes bundled with OpenRefine.
|
||||
@ -1,509 +0,0 @@
|
||||
---
|
||||
id: running
|
||||
title: Running OpenRefine
|
||||
sidebar_label: Running
|
||||
---
|
||||
|
||||
## Starting and exiting {#starting-and-exiting}
|
||||
|
||||
OpenRefine does not require internet access to run its basic functions. Once you download and install it, it runs as a small web server on your own computer, and you access that local web server by using your browser.
|
||||
|
||||
You will see a command line window open when you run OpenRefine. Ignore that window while you work on datasets in your browser.
|
||||
|
||||
No matter how you start OpenRefine, it will load its interface in your computer’s default browser. If you would like to use another browser instead, start OpenRefine and then point your chosen browser at the home screen: [http://127.0.0.1:3333/](http://127.0.0.1:3333/).
|
||||
|
||||
OpenRefine works best on browsers based on Webkit, such as:
|
||||
* Google Chrome
|
||||
* Chromium
|
||||
* Opera
|
||||
* Microsoft Edge
|
||||
|
||||
We are aware of some minor rendering and performance issues on other browsers such as Firefox. We don't support Internet Explorer.
|
||||
|
||||
You can view and work on multiple projects at the same time by simply having multiple tabs or browser windows open. From the <span class="menuItems">Open Project</span> screen, you can right-click on project names and open them in new tabs or windows.
|
||||
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
<Tabs
|
||||
groupId="operating-systems"
|
||||
defaultValue="win"
|
||||
values={[
|
||||
{label: 'Windows', value: 'win'},
|
||||
{label: 'Mac', value: 'mac'},
|
||||
{label: 'Linux', value: 'linux'}
|
||||
]
|
||||
}>
|
||||
|
||||
<TabItem value="win">
|
||||
|
||||
#### With openrefine.exe {#with-openrefineexe}
|
||||
You can run OpenRefine by double-clicking `openrefine.exe` or calling it from the command line.
|
||||
|
||||
If you want to [modify the way `openrefine.exe` opens](#starting-with-modifications), you can edit the `openrefine.l4j.ini` file.
|
||||
|
||||
#### With refine.bat {#with-refinebat}
|
||||
On Windows, OpenRefine can also be run by using the file `refine.bat` in the program directory. If you start OpenRefine using `refine.bat`, you can do so by opening the file itself, or by calling it from the command line.
|
||||
|
||||
If you call `refine.bat` from the command line, you can [start OpenRefine with modifications](#starting-with-modifications).
|
||||
If you want to modify the way `refine.bat` opens through double-clicking or using a shortcut, you can edit the `refine.ini` file.
|
||||
|
||||
#### Exiting {#exiting}
|
||||
|
||||
To exit OpenRefine, close all the browser tabs or windows, then navigate to the command line window. To close this window and ensure OpenRefine exits properly, hold down `Control` and press `C` on your keyboard. This will save any last changes to your projects.
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="mac">
|
||||
|
||||
You can find OpenRefine in your Applications folder, or you can open it using Terminal.
|
||||
|
||||
To run OpenRefine using Terminal:
|
||||
* Find the OpenRefine application / icon in Finder
|
||||
* Control-click on the icon and select “Show Package Contents” from the context menu
|
||||
* This should open a new Finder menu: navigate into the “MacOS” folder
|
||||
* Control-click on “JavaAppLauncher”
|
||||
* Choose “Open With” from the menu, and select “Terminal.”
|
||||
|
||||
To exit, close all your OpenRefine browser tabs, go back to the terminal window and press `Command` and `Q` to close it down.
|
||||
|
||||
:::caution Problems starting?
|
||||
If you are using an older version of OpenRefine or are on an older version of MacOS, [check our Wiki for solutions to problems with MacOS](https://github.com/OpenRefine/OpenRefine/wiki/Installation-Instructions#macos).
|
||||
:::
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="linux">
|
||||
|
||||
Use a terminal to launch OpenRefine. First, navigate to the installation folder. Then call the program:
|
||||
|
||||
```
|
||||
cd openrefine-3.4.1
|
||||
./refine
|
||||
```
|
||||
|
||||
This will start OpenRefine and open your browser to the home screen.
|
||||
|
||||
To exit, close all the browser tabs, and then press `control` and `C` in the terminal window.
|
||||
|
||||
:::caution Did you get a JAVA_HOME error?
|
||||
“Error: Could not find the ‘java’ executable at ‘’, are you sure your JAVA_HOME environment variable is pointing to a proper java installation?”
|
||||
|
||||
If you see this error, you need to [install and configure a JDK package](installing#linux), including setting up `JAVA_HOME`.
|
||||
:::
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
---
|
||||
|
||||
### Troubleshooting {#troubleshooting}
|
||||
|
||||
If you are having problems connecting to OpenRefine with your browser, [check our Wiki for information about browser settings and operating-system issues](https://github.com/OpenRefine/OpenRefine/wiki/FAQ#i-am-having-trouble-connecting-to-openrefine-with-my-browser).
|
||||
|
||||
### Starting with modifications {#starting-with-modifications}
|
||||
|
||||
When you run OpenRefine from a command line, you can change a number of default settings.
|
||||
|
||||
<Tabs
|
||||
groupId="operating-systems"
|
||||
defaultValue="win"
|
||||
values={[
|
||||
{label: 'Windows', value: 'win'},
|
||||
{label: 'Mac', value: 'mac'},
|
||||
{label: 'Linux', value: 'linux'}
|
||||
]
|
||||
}>
|
||||
|
||||
<TabItem value="win">
|
||||
|
||||
On Windows, use a slash:
|
||||
|
||||
```
|
||||
C:>refine /i 127.0.0.2 /p 3334
|
||||
```
|
||||
|
||||
Get a list of all the commands with `refine /?`.
|
||||
|
||||
|Command|Use|Syntax example|
|
||||
|---|---|---|
|
||||
|/w|Path to the webapp|refine /w /path/to/openrefine|
|
||||
|/m|Memory maximum heap|refine /m 6000M|
|
||||
|/p|Port|refine /p 3334|
|
||||
|/i|Interface (IP address, or IP and port)|refine /i 127.0.0.2:3334|
|
||||
|/H|HTTP host to expect on incoming requests|refine /H openrefine.internal|
|
||||
|/d|Enable debugging (on port 8000)|refine /d|
|
||||
|/x|Enable JMX monitoring for Jconsole and JvisualVM|refine /x|
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="mac">
|
||||
|
||||
You cannot start the Mac version with modifications using Terminal, but you can modify the way the application starts with [settings within files](#modifications-set-within-files).
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="linux">
|
||||
|
||||
To see the full list of command-line options, run `./refine -h`.
|
||||
|
||||
|Command|Use|Syntax example|
|
||||
|---|---|---|
|
||||
|-w|Path to the webapp|./refine -w /path/to/openrefine|
|
||||
|-d|Path to the workspace|./refine -d /where/you/want/the/workspace|
|
||||
|-m|Memory maximum heap|./refine -m 6000M|
|
||||
|-p|Port|./refine -p 3334|
|
||||
|-i|Interface (IP address, or IP and port)|./refine -i 127.0.0.2:3334|
|
||||
|-H|HTTP host to expect on incoming requests|./refine -H openrefine.internal|
|
||||
|-k|Add a Google API key|./refine -k YOUR_API_KEY|
|
||||
|-v|Verbosity (from low to high: error,warn,info,debug,trace)|./refine -v info|
|
||||
|-x|Additional Java configuration parameters (see Java documentation)||
|
||||
|--debug|Enable debugging (on port 8000)|./refine --debug|
|
||||
|--jmx|Enable JMX monitoring for Jconsole and JvisualVM|./refine --jmx|
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
---
|
||||
|
||||
#### Modifications set within files {#modifications-set-within-files}
|
||||
|
||||
On Windows, you can modify the way `openrefine.exe` runs by editing `openrefine.l4j.ini`; you can modify the way `refine.bat` runs by editing `refine.ini`.
|
||||
|
||||
You can modify the Mac application by editing `info.plist`.
|
||||
|
||||
On Linux, you can edit `refine.ini`.
|
||||
|
||||
Some settings, such as changing memory allocations, are already set inside these files, and all you have to do is change the values. Some lines need to be un-commented to work.
|
||||
|
||||
For example, inside `refine.ini`, you should see:
|
||||
```
|
||||
no_proxy="localhost,127.0.0.1"
|
||||
#REFINE_PORT=3334
|
||||
#REFINE_HOST=127.0.0.1
|
||||
#REFINE_WEBAPP=main\webapp
|
||||
|
||||
# Memory and max form size allocations
|
||||
#REFINE_MAX_FORM_CONTENT_SIZE=1048576
|
||||
REFINE_MEMORY=1400M
|
||||
|
||||
# Set initial java heap space (default: 256M) for better performance with large datasets
|
||||
REFINE_MIN_MEMORY=1400M
|
||||
...
|
||||
```
|
||||
|
||||
##### JVM preferences {#jvm-preferences}
|
||||
|
||||
Further modifications can be performed by using JVM preferences. These JVM preferences are different options and have different syntax than the key/value descriptions used on the command line.
|
||||
|
||||
Some of the most common keys (with their defaults) are:
|
||||
* The project [autosave](starting#autosaving) frequency: `-Drefine.autosave` (5 [minutes])
|
||||
* The workspace director: `-Drefine.data_dir` (/)
|
||||
* Development mode: `-Drefine.development` (false)
|
||||
* Headless mode: `-Drefine.headless` (false)
|
||||
* IP: `-Drefine.host` (127.0.0.1)
|
||||
* Port: `-Drefine.port` (3333)
|
||||
* The application folder: `-Drefine.webapp` (main/webapp)
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
<Tabs
|
||||
groupId="operating-systems"
|
||||
defaultValue="win"
|
||||
values={[
|
||||
{label: 'Windows', value: 'win'},
|
||||
{label: 'Mac', value: 'mac'},
|
||||
{label: 'Linux', value: 'linux'}
|
||||
]
|
||||
}>
|
||||
|
||||
<TabItem value="win">
|
||||
|
||||
Locate the `refine.l4j.ini` file, and insert lines in this way:
|
||||
|
||||
```
|
||||
-Drefine.port=3334
|
||||
-Drefine.host=127.0.0.2
|
||||
-Drefine.webapp=broker/core
|
||||
```
|
||||
|
||||
In `refine.ini`, use a similar syntax, but set multiple parameters within a single line starting with `JAVA_OPTIONS=`:
|
||||
|
||||
```
|
||||
JAVA_OPTIONS=-Drefine.data_dir=C:\Users\user\Documents\OpenRefine\ -Drefine.port=3334
|
||||
|
||||
```
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="mac">
|
||||
|
||||
Locate the `info.plist`, and find the `array` element that follows the line
|
||||
|
||||
```
|
||||
<key>JVMOptions</key>
|
||||
```
|
||||
|
||||
Typically this looks something like:
|
||||
|
||||
```
|
||||
<key>JVMOptions</key>
|
||||
<array>
|
||||
<string>-Xms256M</string>
|
||||
<string>-Xmx1024M</string>
|
||||
<string>-Drefine.version=2.6-beta.1</string>
|
||||
<string>-Drefine.webapp=$APP_ROOT/Contents/Resource/webapp</string>
|
||||
</array>
|
||||
```
|
||||
|
||||
Add in values such as:
|
||||
|
||||
```
|
||||
<key>JVMOptions</key>
|
||||
<array>
|
||||
<string>-Xms256M</string>
|
||||
<string>-Xmx1024M</string>
|
||||
<string>-Drefine.version=2.6-beta.1</string>
|
||||
<string>-Drefine.webapp=$APP_ROOT/Contents/Resource/webapp</string>
|
||||
<string>-Drefine.autosave=2</string>
|
||||
<string>-Drefine.port=3334</string>
|
||||
</array>
|
||||
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="linux">
|
||||
|
||||
Locate the `refine.ini` file, and add `JAVA_OPTIONS=` before the `-Drefine.preference` declaration. You can un-comment and edit the existing suggested lines, or add lines:
|
||||
|
||||
```
|
||||
JAVA_OPTIONS=-Drefine.autosave=2
|
||||
JAVA_OPTIONS=-Drefine.port=3334
|
||||
JAVA_OPTIONS=-Drefine.data_dir=usr/lib/OpenRefineWorkspace
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
|
||||
---
|
||||
|
||||
Refer to the [official Java documentation](https://docs.oracle.com/javase/8/docs/technotes/tools/windows/java.html) for more preferences that can be set.
|
||||
|
||||
## The home screen {#the-home-screen}
|
||||
|
||||
When you first launch OpenRefine, you will see a screen with a menu on the left hand side that includes <span class="menuItems">Create Project</span>, <span class="menuItems">Open Project</span>, <span class="menuItems">Import Project</span>, and <span class="menuItems">Language Settings</span>. This is called the “home screen,” where you can manage your projects and general settings.
|
||||
|
||||
In the lower left-hand corner of the screen, you'll see <span class="menuItems">Preferences</span>, <span class="menuItems">Help</span>, and <span class="menuItems">About</span>.
|
||||
|
||||
### Language settings {#language-settings}
|
||||
|
||||
From the home screen, look in the options to the left for <span class="menuItems">Language Settings</span>. You can set your preferred interface language here. This language setting will persist until you change it again in the future. Languages are translated as a community effort; some languages are partially complete and default back to English where unfinished. Currently OpenRefine supports the following languages for 75% or more of the interface:
|
||||
|
||||
* Cebuano
|
||||
* German
|
||||
* English (UK)
|
||||
* English (US)
|
||||
* Spanish
|
||||
* Filipino
|
||||
* French
|
||||
* Hebrew
|
||||
* Magyar
|
||||
* Italian
|
||||
* Japanese (日本語)
|
||||
* Portuguese (Brazil)
|
||||
* Tagalog
|
||||
* Chinese (简体中文)
|
||||
|
||||
To leave the Language Settings screen, click on the diamond “OpenRefine” logo.
|
||||
|
||||
:::info Help us Translate OpenRefine
|
||||
We use Weblate to provide translations for the interface. You can check [our profile on Weblate](https://hosted.weblate.org/projects/openrefine/translations/) to see which languages are in the process of being supported. See [our technical reference if you are interested in contributing translation work](https://docs.openrefine.org/technical-reference/translating) to make OpenRefine accessible to people in other languages.
|
||||
:::
|
||||
|
||||
### Preferences {#preferences}
|
||||
|
||||
In the bottom left corner of the screen, look for <span class="menuItems">Preferences</span>. At this time you can set preferences using a key/value pair: that is, selecting one of the keys below and setting a value for it.
|
||||
|
||||
|Setting|Key|Value syntax|Default|Example|Version|
|
||||
|---|---|---|---|---|---|
|
||||
|Interface language|userLang|[ISO 639-1](https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes) two-digit code|en|fr|—|
|
||||
|Maximum facets|ui.browsing.listFacet.limit|Number|2000|5000|—|
|
||||
|Timeout for Google Drive import|googleReadTimeOut|Number (microseconds)|180000|500000|—|
|
||||
|Timeout for Google Drive authorization|googleConnectTimeOut|Number (microseconds)|180000|500000|—|
|
||||
|Maximum lag for Wikibase edit retries|wikibase.upload.maxLag|Number (seconds)|5|10|—|
|
||||
|Display of the reconciliation preview on hover|cell-ui.previewMatchedCells|Boolean|true|false|v3.2|
|
||||
|Values for the choice of the number of rows to display|ui.browsing.pageSize|Array of number (JSON)|[ 5, 10, 25, 50 ]|[ 100,500,1000 ]|v3.4|
|
||||
|Width of the panel for facets/history|ui.browsing.facetsHistoryPanelWidth|Number (pixel)|300|500|v3.5|
|
||||
|
||||
To leave the Preferences screen, click on the diamond “OpenRefine” logo.
|
||||
|
||||
If the preference you’re looking for isn’t here, look at the options you can set from the [command line or in an `.ini` file](#starting-with-modifications).
|
||||
|
||||
## The project screen {#the-project-screen}
|
||||
|
||||
The project screen (or work screen) is where you will spend most of your time once you have [begun to work on a project](starting). This is a quick walkthrough of the parts of the interface you should familiarize yourself with.
|
||||
|
||||

|
||||
|
||||
### The project bar {#the-project-bar}
|
||||
|
||||
The project bar runs across the very top of the project screen. It contains the the OpenRefine logo, the project title, and the project control buttons on the right side.
|
||||
|
||||
At any time you can close your current project and go back to the home screen by clicking on the OpenRefine logo. If you’d like to open another project in a new browser tab or window, you can right-click on the logo and use “Open in a new tab.” You will lose [your current facets and view settings](#facetfilter) if you close your project (but data transformations will be saved in the [History](#history-undoredo) of the project).
|
||||
|
||||
:::caution
|
||||
Don’t click the “back” button on your browser - it will likely close your current project and you will lose your facets and view settings.
|
||||
:::
|
||||
|
||||
You can rename a project at any time by clicking inside the project title, which will turn into a text field. Project names don’t have to be unique, as OpenRefine organizes them based on a unique identifier behind the scenes.
|
||||
|
||||
The <span class="menuItems">Permalink</span> allows you to return to a project at a specific view state - that is, with [facets and filters](facets) applied. The <span class="menuItems">Permalink</span> can help you pick up where you left off if you have to close your project while working with facets and filters. It puts view-specific information directly into the URL: clicking on it will load this current-view URL in the existing tab. You can right-click and copy the <span class="menuItems">Permalink</span> URL to copy the current view state to your clipboard, without refreshing the tab you’re using.
|
||||
|
||||
The <span class="menuItems">Open…</span> button will open up a new browser tab showing the <span class="menuItems">Create Project</span> screen. From here you can change settings, start a new project, or open an existing project.
|
||||
|
||||
<span class="menuItems">Export</span> is a dropdown menu that allows you to pick a format for exporting a dataset. Many of the export options will only export rows and records that are currently visible - the currently selected facets and filters, not the total data in the project.
|
||||
|
||||
<span class="menuItems">Help</span> will open up a new browser tab and bring you to this user manual on the web.
|
||||
|
||||
### The grid header {#the-grid-header}
|
||||
|
||||
The grid header sits below the project bar and above the project grid (where the data of your project is displayed). The grid header will tell you the total number of rows or records in your project, and indicate whether you are in [rows or records mode](exploring#rows-vs-records).
|
||||
|
||||
It will also tell you if you’re currently looking at a select number of rows via facets or filtering, rather than the entire dataset, by displaying either, for example, “180 rows” or “67 matching rows (180 total).”
|
||||
|
||||
Directly below the row number, you have the ability to switch between [row mode and records mode](exploring#rows-vs-records). OpenRefine stores projects persistently in one of the two modes, and displays your data as records by default if you are.
|
||||
|
||||
To the right of the rows/records selection is the array of options for how many rows/records to view on screen at one time. At the far right of the screen you can navigate through your entire dataset one page at a time.
|
||||
|
||||
### Extensions {#extensions}
|
||||
|
||||
The <span class="menuItems">Extensions</span> dropdown offers you options for extending your data - most commonly by uploading your edited statements to Wikidata, or by importing or exporting schema. You can learn more about these functions on the [Wikibase section](wikibase/overview). Other extensions may also add functions to this dropdown menu.
|
||||
|
||||
### The grid {#the-grid}
|
||||
|
||||
The area of the project screen that displays your dataset is called the “grid” (or the “data grid,” or the “project grid”). The grid presents data in a tabular format, which may look like a normal spreadsheet program to you.
|
||||
|
||||
Columns widths are automatically set based on their contents; some column headers may be cut off, but can be viewed by mousing over the headers.
|
||||
|
||||
In each column header you will see a small arrow. Clicking on this arrow brings up a dropdown menu containing column-specific data exploration and transformation options. You will learn about each of these options in the [Exploring data](exploring) and [Transforming data](transforming) sections.
|
||||
|
||||
The first column in every project will always be <span class="menuItems">All</span>, which contains options to flag, star, and do non-column-specific operations. The <span class="menuItems">All</span> column is also where rows/records are numbered. Numbering shows the permanent order of rows and records; a temporary sorting or facet may reorder the rows or show a limited set, but numbering will show you the original identifiers unless you make a permanent change.
|
||||
|
||||
The project grid may display with both vertical and horizontal scrolling, depending on the number and width of columns, and the number of rows/records displayed. You can control the display of the project grid by using [Sort and View options](exploring#sort-and-view).
|
||||
|
||||
Mousing over individual cells will allow you to [edit cells individually](cellediting#edit-one-cell-at-a-time).
|
||||
|
||||
### Facet/Filter {#facetfilter}
|
||||
|
||||
The <span class="tabLabels">Facet/Filter</span> tab is one of the main ways of exploring your data: displaying the patterns and trends in your data, and helping you narrow your focus and modify that data. [Facets](facets) and [filters](facets#text-filter) are explained more in [Exploring data](exploring).
|
||||
|
||||

|
||||
|
||||
In the tab, you will see three buttons: <span class="menuItems">Refresh</span>, <span class="menuItems">Reset all</span>, and <span class="menuItems">Remove all</span>.
|
||||
|
||||
Refreshing your facets will ensure you are looking at the latest information about each facet, for example if you have changed the counts or eliminated some options.
|
||||
|
||||
Resetting your facets will remove any inclusion or exclusion you may have set - the facet options will stay in the sidebar, but your view settings will be undone.
|
||||
|
||||
Removing your facets will clear out the sidebar entirely. If you have written custom facets using [expressions](expressions), these will be lost.
|
||||
|
||||
You can preserve your facets and filters for future use by copying a <span class="menuItems">[Permalink](#the-project-bar)</span>.
|
||||
|
||||
### History (Undo/Redo) {#history-undoredo}
|
||||
|
||||
In OpenRefine, any activity that changes the data can be undone. Changes are tracked from the very beginning, when a project is first created. The change history of each project is saved with the project's data, so quitting OpenRefine does not erase the steps you've taken. When you restart OpenRefine, you can view and undo changes that you made before you quit OpenRefine. OpenRefine [autosaves](starting#autosaving) your actions every five minutes by default, and when you close OpenRefine properly (using Ctrl + C). You can [change this interval](running#jvm-preferences).
|
||||
|
||||
Project history gets saved when you export a project archive, and restored when you import that archive to a new installation of OpenRefine.
|
||||
|
||||
 tab with 13 steps.")
|
||||
|
||||
When you click on the <span class="tabLabels">Undo / Redo</span> tab in the sidebar of any project, that project’s history is shown as a list of changes in order, with the first “change” being the action of creating the project itself. (That first change, indexed as step zero, cannot be undone.) Here is a sample history with 3 changes:
|
||||
|
||||
```
|
||||
0. Create project
|
||||
1. Remove 7 rows
|
||||
2. Create new column Last Name based on column Name with grel:value.split(" ")
|
||||
3. Split 230 cell(s) in column Address into several columns by separator
|
||||
```
|
||||
|
||||
The current state of the project is highlighted with a dark blue background. If you move back and forth on the timeline you will see the current state become highlighted, while the actions that came after that state will be grayed out.
|
||||
|
||||
To revert your data back to an earlier state, simply click on the last action in the timeline you want to keep. In the example above, if we keep the removal of 7 rows but revert everything we did after that, then click on “Remove 7 rows.” The last 2 changes will be undone, in order to bring the project back to state #1.
|
||||
|
||||
In this example, changes #2 and #3 will now be grayed out. You can redo a change by clicking on it in the history - everything up to and including it will be redone.
|
||||
|
||||
If you have moved back one or more states, and then you perform a new operation on your data, the later actions (everything that’s greyed out) will be erased and cannot be re-applied.
|
||||
|
||||
The Undo/Redo tab will indicate which step you’re on, and if you’re about to risk erasing work - by saying something like “4/5" or “1/7” at the end.
|
||||
|
||||
#### Reusing operations {#reusing-operations}
|
||||
|
||||
Operations that you perform in OpenRefine can be reused. For example, a formula you wrote inside one project can be copied and applied to another project later.
|
||||
|
||||
To reuse one or more operations, first extract it from the project where it was first applied. Click to the <span class="tabLabels">Undo/Redo</span> tab and click <span class="menuItems">Extract…</span>. This brings up a box that lists all operations up to the current state (it does not show undone operations). Select the operation or operations you want to extract using the checkboxes on the left, and they will be encoded as JSON on the right. Copy that JSON to the clipboard.
|
||||
|
||||
Move to the second project, go to the <span class="tabLabels">Undo/Redo</span> tab, click <span class="menuItems">Apply…</span> and paste in that JSON.
|
||||
|
||||
Not all operations can be extracted. Edits to a single cell, for example, can’t be replicated.
|
||||
|
||||
## Advanced OpenRefine uses {#advanced-openrefine-uses}
|
||||
|
||||
### Running OpenRefine's Linux version on a Mac {#running-openrefines-linux-version-on-a-mac}
|
||||
|
||||
You can run OpenRefine from the command line in Mac by using the Linux installation package. We do not promise support for this method. Follow the instructions in the Linux section.
|
||||
|
||||
### Running as a server {#running-as-a-server}
|
||||
|
||||
:::caution
|
||||
Please note that if your machine has an external IP (is exposed to the Internet), you should not do this, or should protect it behind a proxy or firewall, such as nginx. Proceed at your own risk.
|
||||
:::
|
||||
|
||||
By default (and for security reasons), OpenRefine only listens to TCP requests coming from localhost (127.0.0.1) on port 3333. If you want to share your OpenRefine instance with colleagues and respond to TCP requests to any IP address of the machine, start it from the command line like this:
|
||||
```
|
||||
./refine -i 0.0.0.0
|
||||
```
|
||||
|
||||
or set this option in `refine.ini`:
|
||||
```
|
||||
REFINE_HOST=0.0.0.0
|
||||
```
|
||||
|
||||
or set this JVM option:
|
||||
```
|
||||
-Drefine.host=0.0.0.0
|
||||
```
|
||||
|
||||
On Mac, you can add a specific entry to the `Info.plist` file located within the app bundle (`/Applications/OpenRefine.app/Contents/Info.plist`):
|
||||
```
|
||||
<key>JVMOptions</key>
|
||||
|
||||
<array>
|
||||
<string>-Drefine.host=0.0.0.0</string>
|
||||
…
|
||||
</array>
|
||||
```
|
||||
|
||||
:::caution
|
||||
OpenRefine has no built-in security or version control for multi-user scenarios. OpenRefine has a single data model that is not shared, so there is a risk of data operations being overwritten by other users. Care must be taken by users.
|
||||
:::
|
||||
|
||||
### Automating OpenRefine {#automating-openrefine}
|
||||
|
||||
Some users may wish to employ OpenRefine for batch processing as part of a larger automated pipeline. Not all OpenRefine features can work without human supervision and advancement (such as clustering), but many data transformation tasks can be automated.
|
||||
|
||||
:::caution
|
||||
The following are all third-party extensions and code; the OpenRefine team does not maintain them and cannot guarantee that any of them work.
|
||||
:::
|
||||
|
||||
Some examples:
|
||||
|
||||
* This project allows OpenRefine to be run from the command line using [operations saved in a JSON file](#reusing-operations): [OpenRefine batch processing](https://github.com/opencultureconsulting/openrefine-batch)
|
||||
* A Python project for applying a JSON file of operations to a data file, outputting the new file, and deleting the temporary project, written by David Huynh and Max Ogden: [Python client library for Google Refine](https://github.com/maxogden/refine-python)
|
||||
* And the same in Ruby: [Refine-Ruby](https://github.com/maxogden/refine-ruby)
|
||||
* Another Python client library, by Paul Makepeace: [OpenRefine Python Client Library](https://github.com/PaulMakepeace/refine-client-py)
|
||||
|
||||
To look for other instances, search our Google Groups [for users](https://groups.google.com/g/openrefine) and [for developers](https://groups.google.com/g/openrefine-dev), where [these projects were originally posted](https://groups.google.com/g/openrefine/c/GfS1bfCBJow/m/qWYOZo3PKe4J).
|
||||
@ -1,35 +0,0 @@
|
||||
---
|
||||
id: sortview
|
||||
title: Sort and view
|
||||
sidebar_label: Sort and view
|
||||
---
|
||||
|
||||
## Sort {#sort}
|
||||
|
||||
You can temporarily sort your rows by one column. You can sort based on [data type](exploring#data-types):
|
||||
* text alphabetically or reverse
|
||||
* numbers by largest or smallest
|
||||
* dates by earliest or latest
|
||||
* boolean values by false first or true first.
|
||||
|
||||
You can also choose where to place errors and blank cells in the sorting. Text can be case-sensitive or not: if so, cells that start with lowercase characters will appear ahead of those that start with uppercase characters.
|
||||
|
||||

|
||||
|
||||
After you apply a sorting method, you can make it permanent, remove it, reverse it, or apply a subsequent sorting. When it is applied, you’ll find <span class="menuItems">Sort</span> in the project grid header to the right of the rows-display setting, which will show all current sorting settings.
|
||||
|
||||
If you have multiple sorting methods applied, they will work in the order you applied them (represented in order in the <span class="menuItems">Sort</span> menu). For example, you can sort an “authors” column alphabetically, and then sort their books by publication date, for those authors that have more than one book. If you apply those in a different order - sort all the publication dates in the dataset first, and then alphabetically by author - your dataset will look different.
|
||||
|
||||

|
||||
|
||||
When the sorting method you've applied is temporary, you will see that the rows retain their original numbering. When you make that sorting method permanent, by selecting <span class="menuItems">Reorder rows permanently</span>, the row numbers will change and the <span class="menuItems">Sort</span> menu in the project grid header will disappear. This will apply all current sorting methods.
|
||||
|
||||
## View {#view}
|
||||
|
||||
You can control what data you view in the grid. On each column, you will see a <span class="menuItems">View</span> menu option. From there, you can “collapse” (hide) that specific column, all other columns, all columns to the left, and all columns to the right. Using the <span class="menuItems">View</span> option that appears in the <span class="menuItems">All</span> column’s dropdown menu, you can collapse all columns, and expand all the columns that you previously collapsed.
|
||||
|
||||
### Show/hide “null” {#showhide-null}
|
||||
|
||||
You can find, under <span class="menuItems">All</span> → <span class="menuItems">View</span>, the option to show and hide [“null” values](exploring#data-types). A small grey “null” will appear in each applicable cell. Remember that a null cell is not the same thing as an empty cell.
|
||||
|
||||

|
||||
@ -1,194 +0,0 @@
|
||||
---
|
||||
id: starting
|
||||
title: Starting a project
|
||||
sidebar_label: Starting a project
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
An OpenRefine project is started by importing in some existing data - OpenRefine doesn’t allow you to create a dataset from nothing.
|
||||
|
||||
No matter where your data comes from, OpenRefine won’t modify your original data source. It copies all the information from your input, creates its own project file, and stores it in your [workspace directory](installing#set-where-data-is-stored).
|
||||
|
||||
The data and all of your edits are [automatically saved](#autosaving) inside the project file. When you’re finished modifying the data, you can [export it back out](exporting) into the file format of your choice.
|
||||
|
||||
You can also receive and open other people’s projects, or send them yours, by [exporting a project archive](exporting#export-a-project) and [importing it](#import-a-project).
|
||||
|
||||
## Create a project by importing data {#create-a-project-by-importing-data}
|
||||
|
||||
When you start OpenRefine, you’ll be taken to the <span class="menuItems">Create Project</span> screen. You’ll see on the left side of the screen that your options are to:
|
||||
|
||||
* import data from one or more files on your computer
|
||||
* import data from one or more links on the web
|
||||
* import data by pasting in text from your clipboard
|
||||
* import data from a database (using SQL), and
|
||||
* import one or more Sheets from Google Drive.
|
||||
|
||||
From these sources, you can load any of the following file formats:
|
||||
|
||||
* comma-separated values (CSV) or text-separated values (TSV)
|
||||
* Text files
|
||||
* Fixed-width columns
|
||||
* JSON
|
||||
* XML
|
||||
* OpenDocument spreadsheet (ODS)
|
||||
* Excel spreadsheet (XLS or XLSX)
|
||||
* PC-Axis (PX)
|
||||
* MARC
|
||||
* RDF data (JSON-LD, N3, N-Triples, Turtle, RDF/XML)
|
||||
* Wikitext
|
||||
|
||||
More formats can be imported by [adding extensions to provide that functionality](https://openrefine.org/download.html).
|
||||
|
||||
If you supply two or more files for one project, the files’ rows will be loaded in the order that you specify, and OpenRefine will create a column at the beginning of the dataset with the source URL or file name in it to help you identify where each row came from. If the files have columns with identical names, the data will load in those columns; if not, the successive files will append all of their new columns to the end of the dataset:
|
||||
|
||||
|File|Fruit|Quantity|Berry|Berry source|
|
||||
|---|---|---|---|---|
|
||||
|fruits.csv|Orange|4|
|
||||
|fruits.csv|Apple|6|
|
||||
|berries.csv||9|Mulberry|Greece|
|
||||
|berries.csv||2|Blueberry|Canada|
|
||||
|
||||
You cannot combine two datasets into one project by appending data within rows. You can, however, combine two projects later using functions such as [cross()](grelfunctions/#crosscell-s-projectname-s-columnname), or [fetch further data](columnediting) using other methods.
|
||||
|
||||
For whichever method you choose to start your project, when you click <span class="menuItems">Next >></span> you will be given a preview and a chance to configure the way OpenRefine interprets the data you input.
|
||||
|
||||
### Get data from this computer {#get-data-from-this-computer}
|
||||
|
||||
Click on <span class="menuItems">Browse…</span> and select a file (or several) on your hard drive. All files will be shown, not just compatible ones.
|
||||
|
||||
If you import an archive file (something with the extension `.zip`, `.tar.gz`, `.tgz`, `.tar.bz2`, `.gz`, or `.bz2`), OpenRefine detects the files inside it, shows you a preview screen, and allows you to select which ones to load. This does not work with `.rar` files. When importing multiple archives you can store the name of the archive each file was extracted from by ticking the `Store archive file` option upon import.
|
||||
|
||||
### Web addresses (URLs) {#web-addresses-urls}
|
||||
|
||||
Type or paste the URL to a data file into the field provided. You can add as many fields as you want. OpenRefine will download the file and preview the project for you.
|
||||
|
||||
If you supply two or more file URLs, OpenRefine will identify each one and ask you to choose which (or all) to load.
|
||||
|
||||
Do not use this form to load a Google Sheet by its link; use [the Google Data form instead](#google-data).
|
||||
|
||||
### Clipboard {#clipboard}
|
||||
|
||||
You can copy and paste in data from anywhere. OpenRefine will recognize comma-separated, tab-separated, or table-formatted information copied from sources such as word-processing documents, spreadsheets, and tables in PDFs. You can also just paste in a list of items that you want to turn into rows. OpenRefine recognizes each new text line as a row.
|
||||
|
||||
This can be useful if you want to pre-select a specific number of rows from your source data, or paste together rows from different places, rather than delete unwanted rows later in the project interace.
|
||||
|
||||
This can also be useful if you would like to paste in a list of URLs, which you can use later to [fetch more data](columnediting).
|
||||
|
||||
### Database (SQL) {#database-sql}
|
||||
|
||||
If you are an administrator or have SQL access to a database of information, you may want to pull the latest dataset directly from there. This could include an online catalogue, a content management system, or a digital repository or collection management system. You can also load a database (`.db`) file saved locally. You will need to use an [SQL query](https://www.w3schools.com/sql/) to import your intended data.
|
||||
|
||||
There are some publicly-accessible databases you can query, such as [one provided by Rfam](https://docs.rfam.org/en/latest/database.html). The instructions provided by Rfam can help you understand how to connect to and query from other databases.
|
||||
|
||||
OpenRefine can connect to PostgreSQL, MySQL, MariaDB, and SQLite database systems. It will automatically populate the <span class="fieldLabels">Port</span> field based on which of these you choose, but you can manually edit this if needed.
|
||||
|
||||
If you have a `.db` file, you can supply the path to the file on your computer in the <span class="fieldLabels">Database</span> field at the bottom of the form. You can leave the rest of the fields blank.
|
||||
|
||||
To import data directly from a database, you will need the database type (such as MySQL), database name, the hostname (either an IP address or the domain that hosts the database), and the port on the host. You will need an account authorized for access, and you may need to add OpenRefine's IP address or host to the "allowable hosts" for that account. You can find that information by pressing <span class="buttonLabels">Test</span> and getting the IP address from the error message that results.
|
||||
|
||||
You can either connect just once to gather data, or save the connection to use it again later. If you press <span class="buttonLabels">Connect</span> without saving, OpenRefine will forget all the information you just entered. If you’d like to save the connection, name your connection in a way you will recognize later. Click <span class="buttonLabels">Save</span> and it will appear in the <span class="menuItems">Saved Connections</span> list on the left. From now on, you can click on the <span class="buttonLabels">...</span> ellipsis to the right of the connection you’ve saved, and click <span class="buttonLabels">Connect</span>.
|
||||
|
||||
If your connection is successful, you will see a Query Editor where you can run your SQL query. OpenRefine will give you an error if you write a statement that tries to modify the source database in any way.
|
||||
|
||||
### Google data {#google-data}
|
||||
|
||||
You have two ways to load in data from Google Sheets:
|
||||
* providing a link to an accessible Google Sheet (that is, one with link-sharing turned on), and
|
||||
* selecting a Google Sheet in your Google Drive.
|
||||
|
||||
#### Google Sheet by URL {#google-sheet-by-url}
|
||||
|
||||
You can import data from any Google Sheet that has link-sharing turned on. Paste in a URL that looks something like
|
||||
|
||||
```
|
||||
https://docs.google.com/spreadsheets/………/edit?usp=sharing
|
||||
```
|
||||
|
||||
This will only work with Sheets, not with any other Google Drive file that might have an available link, including `.xls` and other valid files that are hosted in Google Drive. These links will not work when attempting to start a project [by URL](#web-addresses-urls) either, so you need to download those files to your computer.
|
||||
|
||||
#### Google Sheet from Drive {#google-sheet-from-drive}
|
||||
|
||||
You can authorize OpenRefine to access your Google Drive data and import data from any Google Sheet it finds there. This will include Sheets that belong to you and Sheets that are shared with you, as well as Sheets that are in your trash.
|
||||
|
||||
When you select a Google option (either here, or [when exporting project data to Google Drive or Google Sheets](exporting), you will see a pop-up window that asks you to select a Google account to authorize with. You may see an error message when you authorize: if so, try your import or export operation again and it should succeed.
|
||||
|
||||
OpenRefine will not show spreadsheets that are in your email inbox or stored in any other Google property - only in Drive. It also won’t show all compatible file formats, only Sheets files.
|
||||
|
||||
OpenRefine will generate a list of all Sheets it finds, with the most recently modified Sheets at the top. If a file you’ve just added isn’t showing in this list, you can close and restart OpenRefine, or simply navigate to an existing project, open it, then head back to the <span class="menuItems">Create Project</span> window and check again.
|
||||
|
||||
When you click <span class="buttonLabels">Preview</span> the Sheet will open in a new browser tab. When you click the Sheet title, OpenRefine will begin to process the data.
|
||||
|
||||
|
||||
## Project preview {#project-preview}
|
||||
|
||||
Once OpenRefine is ready to import the data, you will see a screen with <span class="menuItems">Configure Parsing Options</span> at the top. You’ll see a preview of the first 100 rows and all identified columns.
|
||||
|
||||
At the bottom of the screen you will find options for telling OpenRefine how to process what it has found. You can tell it which row(s) to parse as column headers, as well as to ignore any number of rows at the top. You can also select a specific range of rows to work with, by discarding some rows at the top (excluding the header) and limiting the total number of rows it loads.
|
||||
|
||||
OpenRefine tries to guess how to parse your data based on the file extension. For example, `.xml` files are going to be parsed as though they are formatted in XML. An unknown file extension (or your clipboard copy-paste) is assumed to be either tab-separated or comma-separated. OpenRefine looks for a tab character, and if one is found, it assumes you have imported tab-separated data.
|
||||
|
||||
If OpenRefine isn’t certain what format you imported, it will provide a list of possibilities under <span class="menuItems">Parse data as</span> and some settings. You can specify a custom separator now, or split columns later while [transforming your data](transforming).
|
||||
|
||||
If you imported a spreadsheet with multiple worksheets, they will be listed along with the number of rows they contain. You can only select data from one worksheet.
|
||||
|
||||
Note that OpenRefine does not preserve any formatting, such as cell or text colour, that my have been in the original data file. Hyperlinked text will be input as plain text, but OpenRefine will recognize links and make them clickable inside the project interface.
|
||||
|
||||
:::info Encoding issues?
|
||||
Look for character encoding issues at this stage. You may want to manually select an encoding, such as UTF-8, UTF-16, or ASCII, if OpenRefine does not display some characters correctly in the preview. Once your project is created, you can specify another encoding for specific columns using the [reinterpret() function](grelfunctions#reinterprets-s-encoder).
|
||||
:::
|
||||
|
||||
You should create a project name at this stage. You can also supply tags to keep your projects organized. When you’re happy with the preview, click <span class="buttonLabels">Create Project</span>.
|
||||
|
||||
|
||||
## Import a project {#import-a-project}
|
||||
|
||||
Because OpenRefine only runs locally on your computer, you can’t have a project accessible to more than one person at the same time.
|
||||
|
||||
The best way to collaborate with another person is to export and import projects that save all your changes, so that you can pick up where someone else left off. You can also [export projects](exporting#export-a-project) and import them to other computers, such as for working on the same project from the office and from home.
|
||||
|
||||
An exported project will include all of the [history](running#history-undoredo), so you can see (and undo) all the changes from the previous user. It is essentially a point-in-time snapshot of their work. OpenRefine only exports projects as `.tar.gz` files at this time.
|
||||
:::caution
|
||||
If you wish to hide the original state of your data and your history of edits (for example, if you are using OpenRefine to anonymize information), export your cleaned dataset only and do not share your project archive.
|
||||
:::
|
||||
|
||||
Once someone has sent you a project archive file from their computer, you can save it anywhere. OpenRefine will import it like a new project and save its information to your workspace directory.
|
||||
|
||||
In the left-hand menu of the home screen, click <span class="buttonLabels">Import Project</span>. Click <span class="buttonLabels">Browse…</span> and navigate to wherever you saved the file you were sent (for example, your Downloads folder).
|
||||
|
||||
You can rename the project if you’d like - we recommend adding your name, a date, or a version number, if you’re planning to continue collaborating with another person (or working from multiple computers).
|
||||
|
||||
Then, click <span class="buttonLabels">Import Project</span>. Your project should appear with a step count beside <span class="tabLabels">Undo/Redo</span> if steps were saved by the exporter.
|
||||
|
||||
OpenRefine will store the project in its own workspace directory, so you can now delete the original file that was sent to you.
|
||||
|
||||
|
||||
## Project management {#project-management}
|
||||
|
||||
You can access all of your created projects by clicking on <span class="menuItems">Open Project</span>. Your project list can be organized by modification date, title, row count, and other metadata you can supply (such as subject, descripton, tags, or creator). To edit the fields you see here, click <span class="menuItems">About</span> to the left of each project. There you can edit a number of available fields. You can also see the project ID that corresponds to the name of the folder in your work directory.
|
||||
|
||||
### Naming projects {#naming-projects}
|
||||
|
||||
You may have multiple projects from the same dataset, or multiple versions from sharing a project with another person. OpenRefine automatically generates a project name from the imported file, or “clipboard” when you use <span class="menuItems">Clipboard</span> importing. Project names don’t have to be unique, and OpenRefine will create many projects with the same name unless you intervene.
|
||||
|
||||
You can edit a project's name when you create it or import it, and you can rename a project later by opening it and clicking on the project name at the top of the screen.
|
||||
|
||||
### Autosaving {#autosaving}
|
||||
|
||||
OpenRefine [saves all of your actions](running#history-undoredo) (everything you can see in the <span class="tabLabels">Undo/Redo</span> panel). That includes flagging and starring rows.
|
||||
|
||||
It doesn’t, however, save your facets, filters, or any kind of view you may have in place while you work. This includes the number of rows showing, and any sorting or column collapsing you may have done. A good rule of thumb is: if it’s not showing in <span class="tabLabels">Undo/Redo</span>, you will lose it when you leave the project workspace.
|
||||
|
||||
Autosaving happens by default every five minutes. You can [change this preference by following these directions](running#jvm-preferences).
|
||||
|
||||
You can only save and share facets and filters, not any other type of view. To save current facets and filters, click <span class="menuItems">Permalink</span>. The project will reload with a different URL, which you can then copy and save elsewhere. This permalink will save both the facets and filters you’ve set, and the settings for each one (such as sorting by count rather than by name).
|
||||
|
||||
### Deleting projects {#deleting-projects}
|
||||
|
||||
You can delete projects, which will erase the project files from the workspace directory on your computer. This is immediate and cannot be undone.
|
||||
|
||||
Go to <span class="menuItems">Open Project</span> and find the project you want to delete. Click on the <span class="menuItems">X</span> to the left of the project name. There will be a confirmation dialog.
|
||||
|
||||
### Project files {#project-files}
|
||||
|
||||
You can find all of your raw project files in your work directory. They will be named according to the unique “Project ID” that OpenRefine has assigned them, which you can find on the <span class="menuItems">Open Project</span> screen, under the “About” link for each project.
|
||||
@ -1,34 +0,0 @@
|
||||
---
|
||||
id: transforming
|
||||
title: Transforming data
|
||||
sidebar_label: Overview
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
OpenRefine gives you powerful ways to clean, correct, codify, and extend your data. Without ever needing to type inside a single cell, you can automatically fix typos, convert things to the right format, and add structured categories from trusted sources.
|
||||
|
||||
This section of ways to improve data are organized by their appearance in the menu options in OpenRefine. You can:
|
||||
|
||||
* change the order of [rows](#edit-rows) or [columns](columnediting#rename-remove-and-move)
|
||||
* edit [cell contents](cellediting) within a particular column
|
||||
* [transform](transposing) rows into columns, and columns into rows
|
||||
* [split or join columns](columnediting#split-or-join)
|
||||
* [add new columns](columnediting) based on existing data, with fetching new information, or through [reconciliation](reconciling)
|
||||
* convert your rows of data into [multi-row records](exploring#rows-vs-records).
|
||||
|
||||
## Edit rows {#edit-rows}
|
||||
|
||||
Moving rows around is a permanent change to your data.
|
||||
|
||||
You can [sort your data](sortview#sort) based on the values in one column, but that change is a temporary view setting. With that setting applied, you can make that new order permanent.
|
||||
|
||||

|
||||
|
||||
In the project grid header, the word “Sort” will appear when a sort operation is applied. Click on it to show the dropdown menu, and select <span class="menuItems">Reorder rows permanently</span>. You will see the numbering of the rows change under the <span class="menuItems">All</span> column.
|
||||
|
||||
:::info Reordering all rows
|
||||
Reordering rows permanently will affect all rows in the dataset, not just those currently viewed through [facets and filters](facets).
|
||||
:::
|
||||
|
||||
You can undo this action using the [<span class="fieldLabels">History</span> tab](running#history-undoredo).
|
||||
@ -1,234 +0,0 @@
|
||||
---
|
||||
id: transposing
|
||||
title: Transposing
|
||||
sidebar_label: Transposing
|
||||
---
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
These functions were created to solve common problems with reshaping your data: pivoting cells from a row into a column, or pivoting cells from a column into a row. You can also transpose from a repeated set of values into multiple columns.
|
||||
|
||||
## Transpose cells across columns into rows {#transpose-cells-across-columns-into-rows}
|
||||
|
||||
Imagine personal data with addresses in this format:
|
||||
|
||||
|Name|Street|City|State/Province|Country|Postal code|
|
||||
|---|---|---|---|---|---|
|
||||
|Jacques Cousteau|23, quai de Conti|Paris||France|75270|
|
||||
|Emmy Noether|010 N Merion Avenue|Bryn Mawr|Pennsylvania|USA|19010|
|
||||
|
||||
You can transpose the address information from this format into multiple rows. Go to the “Street” column and select <span class="menuItems">Transpose</span> → <span class="menuItems">Transpose cells across columns into rows</span>. From there you can select all of the five columns, starting with “Street” and ending with “Postal code,” that correspond to address information. Once you begin, you should put your project into [records mode](exploring#rows-vs-records) to associate the subsequent rows with “Name” as the key column.
|
||||
|
||||

|
||||
|
||||
### One column {#one-column}
|
||||
|
||||
You can transpose the multiple address columns into a series of rows:
|
||||
|
||||
|Name|Address|
|
||||
|---|---|
|
||||
|Jacques Cousteau|23, quai de Conti|
|
||||
| |Paris|
|
||||
| |France|
|
||||
| |75270|
|
||||
|Emmy Noether|010 N Merion Avenue|
|
||||
||Bryn Mawr|
|
||||
||Pennsylvania|
|
||||
||USA|
|
||||
||19010|
|
||||
|
||||
You can choose one column and include the column-name information in each cell by prepending it to the value, with or without a separator:
|
||||
|
||||
|Name|Address|
|
||||
|---|---|
|
||||
|Jacques Cousteau|Street: 23, quai de Conti|
|
||||
| |City: Paris|
|
||||
| |Country: France|
|
||||
| |Postal code: 75270|
|
||||
|Emmy Noether|Street: 010 N Merion Avenue|
|
||||
||City: Bryn Mawr|
|
||||
||State/Province: Pennsylvania|
|
||||
||Country: USA|
|
||||
||Postal code: 19010|
|
||||
|
||||
### Two columns {#two-columns}
|
||||
|
||||
You can retain the column names as separate cell values, by selecting <span class="fieldLabels">Two new columns</span> and naming the key and value columns.
|
||||
|
||||
|Name|Address part|Address|
|
||||
|---|---|---|
|
||||
|Jacques Cousteau|Street|23, quai de Conti|
|
||||
| |City|Paris|
|
||||
| |Country|France|
|
||||
| |Postal code|75270|
|
||||
|Emmy Noether|Street|010 N Merion Avenue|
|
||||
||City|Bryn Mawr|
|
||||
||State/Province|Pennsylvania|
|
||||
||Country|USA|
|
||||
||Postal code|19010|
|
||||
|
||||
## Transpose cells in rows into columns {#transpose-cells-in-rows-into-columns}
|
||||
|
||||
Imagine employee data in this format:
|
||||
|
||||
|Column|
|
||||
|---|
|
||||
|Employee: Karen Chiu|
|
||||
|Job title: Senior analyst|
|
||||
|Office: New York|
|
||||
|Employee: Joe Khoury|
|
||||
|Job title: Junior analyst|
|
||||
|Office: Beirut|
|
||||
|Employee: Samantha Martinez|
|
||||
|Job title: CTO|
|
||||
|Office: Tokyo|
|
||||
|
||||
The goal is to sort out all of the information contained in one column into separate columns, but keep it organized by the person it represents:
|
||||
|
||||
|Name |Job title |Office|
|
||||
|---|---|---|
|
||||
|Karen Chiu |Senior analyst |New York|
|
||||
|Joe Khoury |Junior analyst |Beirut|
|
||||
|Samantha Martinez |CTO |Tokyo|
|
||||
|
||||
By selecting <span class="menuItems">Transpose</span> → <span class="menuItems">Transpose cells in rows into columns...</span> a window will appear that simply asks how many rows to transpose. In this case, each employee record has three rows, so input “3” (do not subtract one for the original column). The original column will disappear and be replaced with three columns, with the name of the original column plus a number appended.
|
||||
|
||||
|Column 1 |Column 2 |Column 3|
|
||||
|---|---|---|
|
||||
|Employee: Karen Chiu |Job title: Senior analyst |Office: New York|
|
||||
|Employee: Joe Khoury |Job title: Junior analyst |Office: Beirut|
|
||||
|Employee: Samantha Martinez |Job title: CTO |Office: Tokyo|
|
||||
|
||||
From here you can use <span class="menuItems">Cell editing</span> → <span class="menuItems">Replace</span> to remove “Employee: ”, “Job title: ”, and “Office: ” if you wish, or use [expressions](expressions) with <span class="menuItems">Edit cells</span> → <span class="menuItems">Transform...</span> to clean out the extraneous characters:
|
||||
|
||||
```
|
||||
value.replace("Employee: ", "")
|
||||
```
|
||||
|
||||
If your dataset doesn't have a predictable number of cells per intended row, such that you cannot specify easily how many columns to create, try <span class="menuItems">Columnize by key/value columns</span>.
|
||||
|
||||
## Columnize by key/value columns {#columnize-by-keyvalue-columns}
|
||||
|
||||
This operation can be used to reshape a dataset that contains key and value columns: the repeating strings in the key column become new column names, and the contents of the value column are moved to new columns. This operation can be found at <span class="menuItems">Transpose</span> → <span class="menuItems">Columnize by key/value columns</span>.
|
||||
|
||||

|
||||
|
||||
Consider the following example, with flowers, their colours, and their International Union for Conservation of Nature (IUCN) identifiers:
|
||||
|
||||
|Field |Data |
|
||||
|--------|----------------------|
|
||||
|Name |Galanthus nivalis |
|
||||
|Color |White |
|
||||
|IUCN ID |162168 |
|
||||
|Name |Narcissus cyclamineus |
|
||||
|Color |Yellow |
|
||||
|IUCN ID |161899 |
|
||||
|
||||
In this format, each flower species is described by multiple attributes on consecutive rows. The “Field” column contains the keys and the “Data” column contains the values. In the <span class="menuItems">Columnize by key/value columns</span> window you can select each of these from the available columns. It transforms the table as follows:
|
||||
|
||||
| Name | Color | IUCN ID |
|
||||
|-----------------------|----------|---------|
|
||||
| Galanthus nivalis | White | 162168 |
|
||||
| Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
### Entries with multiple values in the same column {#entries-with-multiple-values-in-the-same-column}
|
||||
|
||||
If a new row would have multiple values for a given key, then these values will be grouped on consecutive rows, to form a [record structure](exploring#rows-vs-records).
|
||||
|
||||
For instance, flowers can have multiple colors:
|
||||
|
||||
| Field | Data |
|
||||
|-------------|-----------------------|
|
||||
| Name | Galanthus nivalis |
|
||||
| _Color_ | _White_ |
|
||||
| _Color_ | _Green_ |
|
||||
| IUCN ID | 162168 |
|
||||
| Name | Narcissus cyclamineus |
|
||||
| Color | Yellow |
|
||||
| IUCN ID | 161899 |
|
||||
|
||||
This table is transformed by the Columnize operation to:
|
||||
|
||||
| Name | Color | IUCN ID |
|
||||
|-----------------------|----------|---------|
|
||||
| Galanthus nivalis | White | 162168 |
|
||||
| | Green | |
|
||||
| Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
The first key encountered by the operation serves as the record key, so the “Green” value is attached to the “Galanthus nivalis” name. See the [Row order](#row-order) section for more details about the influence of row order on the results of the operation.
|
||||
|
||||
### Notes column {#notes-column}
|
||||
|
||||
In addition to the key and value columns, you can optionally add a column for notes. This can be used to store extra metadata associated to a key/value pair.
|
||||
|
||||
Consider the following example:
|
||||
|
||||
| Field | Data | Source |
|
||||
|---------|---------------------|-----------------------|
|
||||
| Name | Galanthus nivalis | IUCN |
|
||||
| Color | White | Contributed by Martha |
|
||||
| IUCN ID | 162168 | |
|
||||
| Name | Narcissus cyclamineus | Legacy |
|
||||
| Color | Yellow | 2009 survey |
|
||||
| IUCN ID | 161899 | |
|
||||
|
||||
If the “Source” column is selected as the notes column, this table is transformed to:
|
||||
|
||||
| Name | Color | IUCN ID | Source: Name | Source: Color |
|
||||
|-----------------------|----------|---------|---------------|-----------------------|
|
||||
| Galanthus nivalis | White | 162168 | IUCN | Contributed by Martha |
|
||||
| Narcissus cyclamineus | Yellow | 161899 | Legacy | 2009 survey |
|
||||
|
||||
Notes columns can therefore be used to preserve provenance or other context about a particular key/value pair.
|
||||
|
||||
### Row order {#row-order}
|
||||
|
||||
The order in which the key/value pairs appear matters. The Columnize operation will use the first key it encounters as the delimiter for entries: every time it encounters this key again, it will produce a new row, and add the following key/value pairs to that row.
|
||||
|
||||
Consider for instance the following table:
|
||||
|
||||
| Field | Data |
|
||||
|----------|-----------------------|
|
||||
| _Name_ | Galanthus nivalis |
|
||||
| Color | White |
|
||||
| IUCN ID | 162168 |
|
||||
| _Name_ | Crinum variabile |
|
||||
| _Name_ | Narcissus cyclamineus |
|
||||
| Color | Yellow |
|
||||
| IUCN ID | 161899 |
|
||||
|
||||
The occurrences of the “Name” value in the “Field” column define the boundaries of the entries. Because there is no other row between the “Crinum variabile” and the “Narcissus cyclamineus” rows, the “Color” and “IUCN ID” columns for the “Crinum variabile” entry will be empty:
|
||||
|
||||
| Name | Color | IUCN ID |
|
||||
|-----------------------|----------|---------|
|
||||
| Galanthus nivalis | White | 162168 |
|
||||
| Crinum variabile | | |
|
||||
| Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
This sensitivity to order is removed if there are extra columns: in that case, the first extra column will serve as the key for the new rows.
|
||||
|
||||
### Extra columns {#extra-columns}
|
||||
|
||||
If your dataset contains extra columns, that are not being used as the key, value, or notes columns, they can be preserved by the operation. For this to work, they must have the same value in all old rows corresponding to a new row.
|
||||
|
||||
In the following example, the “Field” and “Data” columns are used as key and value columns respectively, and the “Wikidata ID” column is not selected:
|
||||
|
||||
| Field | Data | Wikidata ID |
|
||||
|---------|-----------------------|-------------|
|
||||
| Name | Galanthus nivalis | Q109995 |
|
||||
| Color | White | Q109995 |
|
||||
| IUCN ID | 162168 | Q109995 |
|
||||
| Name | Narcissus cyclamineus | Q1727024 |
|
||||
| Color | Yellow | Q1727024 |
|
||||
| IUCN ID | 161899 | Q1727024 |
|
||||
|
||||
This will be transformed to:
|
||||
|
||||
| Wikidata ID | Name | Color | IUCN ID |
|
||||
|-------------|-----------------------|----------|---------|
|
||||
| Q109995 | Galanthus nivalis | White | 162168 |
|
||||
| Q1727024 | Narcissus cyclamineus | Yellow | 161899 |
|
||||
|
||||
This actually changes the operation: OpenRefine no longer looks for the first key (“Name”) but simply pivots all information based on the first extra column's values. Every old row with the same value gets transposed into one new row. If you have more than one extra column, they are pivoted as well but not used as the new key.
|
||||
|
||||
You can use <span class="menuItems">[Fill down](cellediting#fill-down-and-blank-down)</span> to put identical values in the extra columns if you need to.
|
||||
@ -1,31 +0,0 @@
|
||||
---
|
||||
id: troubleshooting
|
||||
title: Troubleshooting
|
||||
sidebar_label: Troubleshooting
|
||||
---
|
||||
|
||||
## Frequently asked questions {#frequently-asked-questions}
|
||||
|
||||
We collect and share FAQs and responses on Github at [https://github.com/OpenRefine/OpenRefine/wiki/FAQ](https://github.com/OpenRefine/OpenRefine/wiki/FAQ).
|
||||
|
||||
If you don’t find your problem and solution there, continue on to the resources in the Community section below to see more conversations and look for solutions.
|
||||
|
||||
## Community {#community}
|
||||
|
||||
### If you’re having a problem: {#if-youre-having-a-problem}
|
||||
* Search the [User forum](https://groups.google.com/g/openrefine) to see if the problem is already reported
|
||||
* Search [Github issues](https://github.com/OpenRefine/OpenRefine/issues) to see if the problem is already reported
|
||||
* Read [Stack Overflow](https://stackoverflow.com/questions/tagged/openrefine) to see if others had a similar problem
|
||||
* Check [Twitter](https://twitter.com/search?f=tweets&vertical=default&q=OpenRefine%20OR%20%22Open%20Refine%22%20OR%20%23OpenRefine&src=typd) to see if others are discussing the problem
|
||||
* Report an issue:
|
||||
* First as a new thread (conversation) in the [User forum](https://groups.google.com/g/openrefine).
|
||||
* Then, if you wish, you can create a Github issue.
|
||||
|
||||
### If you want to contribute: {#if-you-want-to-contribute}
|
||||
* [Help us translate the tool into more languages](https://docs.openrefine.org/technical-reference/translating), using Weblate
|
||||
* [We have a guide to contributing](technical-reference/contributing) in the [Technical Reference](technical-reference/technical-reference-index) section
|
||||
* Contribute your feature requests in the [User forum](https://groups.google.com/g/openrefine) or as [Github issues](https://github.com/OpenRefine/OpenRefine/issues/new/choose)
|
||||
* Join the User Forum and/or the [Developer Forum](https://groups.google.com/g/openrefine-dev)
|
||||
* Share your successes and use cases with us, in the User forum
|
||||
* Add your [blog posts, guides, tips, tricks, tutorials to our list](https://github.com/OpenRefine/OpenRefine/wiki/External-Resources)
|
||||
* Keep an eye out for and respond to our biennial user survey.
|
||||
@ -1,72 +0,0 @@
|
||||
Sometimes your data is not as simple as a normal table, or the sort of
|
||||
statements that you want to do varies on each row. This document
|
||||
explains how to work around these cases.
|
||||
|
||||
## Hierarchical data {#hierarchical-data}
|
||||
|
||||
Sometimes your source provides data in a structured format, such as XML,
|
||||
JSON or RDF. OpenRefine can import these files and will convert them to
|
||||
tables. These tables will reflect some of the hierarchy in the file by
|
||||
means of null cells, using the [records mode](/manual/exploring#rows-vs-records).
|
||||
|
||||
The Wikibase extension always works in rows mode, so if we want to add
|
||||
statements which reference both the artist and the song, we need to fill
|
||||
the null cells with the corresponding artist. You can do this with the
|
||||
**Fill down** operation (in the **Edit cells** menu for this column).
|
||||
This function will copy not just cell values but also reconciliation
|
||||
results.
|
||||
|
||||
## Conditional additions {#conditional-additions}
|
||||
|
||||
Sometimes you want to add a statement only in some conditions.
|
||||
|
||||
The workflow to achieve this looks like this:
|
||||
- Use facets to select the rows where you do not want to add any
|
||||
information;
|
||||
- Blank out the cells in the column that contain the information you
|
||||
want to add. If you do not want to lose this information, you can
|
||||
create a copy of the column beforehand;
|
||||
- Remove your facets to see all rows again;
|
||||
- Create a schema using the column you partially blanked out as
|
||||
statement value.
|
||||
|
||||
## Varying properties {#varying-properties}
|
||||
|
||||
Sometimes you wish you could use column variables for properties in your
|
||||
schema. It is currently not possible, first because we do not have a
|
||||
reconciliation service for properties yet, but also because allowing
|
||||
varying properties in a statement would mean that these properties could
|
||||
potentially have different datatypes, which would break the structure of
|
||||
the schema.
|
||||
|
||||
If you only want to use a few properties, there is a way to go around
|
||||
this problem. For instance, say you have a first column of altitudes and a
|
||||
second column that indicates whether you should add it as
|
||||
[operating altitude (P2254)](https://www.wikidata.org/wiki/Property:P2254) or as
|
||||
[elevation above sea level (P2044)](https://www.wikidata.org/wiki/Property:P2044).
|
||||
|
||||
Create a text facet on the first column. Filter to keep only the
|
||||
*altitude* values. Add a new column based on the second column, by
|
||||
keeping the default expression (`value`) which just copies the existing
|
||||
values. Then, select the *maximum operating altitude* value in the facet
|
||||
and do the same. Reset the facet, you should have obtained two new columns
|
||||
which partition the original column. You can now create a schema which adds
|
||||
two statements, with values taken from those columns. Since blank values are
|
||||
ignored, exactly one statement will be added for each item, with the desired property.
|
||||
|
||||
## Adapting to existing data on Wikibase {#adapting-to-existing-data-on-wikibase}
|
||||
|
||||
Sometimes you want to create statements only if there are no such
|
||||
statements on the item yet. Here is one way to achieve this:
|
||||
|
||||
- first, retrieve the existing values from Wikidata first, using the
|
||||
**Edit columns** → **Add columns from reconciled values** action;
|
||||
- second, create a *facet by null* on the newly created column that
|
||||
contains the information you want to control against;
|
||||
- select the non-null rows (value **false**);
|
||||
- clear the contents of the column where your source values are
|
||||
(**Edit cells** → **Common transformations** → **To null**).
|
||||
|
||||
You can now construct your schema as usual - null values will be ignored
|
||||
when generating the statements.
|
||||
|
||||
@ -1,149 +0,0 @@
|
||||
---
|
||||
id: configuration
|
||||
title: Connecting OpenRefine to a Wikibase instance
|
||||
sidebar_label: Connecting to Wikibase
|
||||
---
|
||||
|
||||
This page explains how to connect OpenRefine to any Wikibase instance. If you just want to work with [Wikidata](https://www.wikidata.org/), you can ignore this page as Wikidata is configured out of the box in OpenRefine.
|
||||
|
||||
## For Wikibase end users {#for-wikibase-end-users}
|
||||
|
||||
All you need to configure OpenRefine to work with a Wikibase instance is a *manifest* for that instance, which provides some metadata and links required for the integration to work.
|
||||
|
||||
We offer some off-the-shelf manifests for some public Wikibase instances in the [wikibase-manifests](https://github.com/OpenRefine/wikibase-manifests) repository. But the administrators of your Wikibase instance should provide one that is potentially more
|
||||
up to date, so it makes sense to request it to them first.
|
||||
|
||||
## For Wikibase administrators {#for-wikibase-administrators}
|
||||
|
||||
To let your users contribute to your Wikibase instance with OpenRefine, you will need to write a manifest as described above. There is currently no canonical location where this manifest should be hosted - just make sure can be found easily by your users. This section explains the format of the manifest.
|
||||
|
||||
### Requirements {#requirements}
|
||||
|
||||
To work with OpenRefine, your Wikibase instance needs an associated reconciliation service. For instance you can use [a Python wrapper](https://github.com/wetneb/openrefine-wikibase) for this. Also, in addition to Wikibase, the [UniversalLanguageSelector extension](https://www.mediawiki.org/wiki/Special:MyLanguage/Extension:UniversalLanguageSelector) should be installed.
|
||||
|
||||
|
||||
### The format of the manifest {#the-format-of-the-manifest}
|
||||
|
||||
Here is the manifest of Wikidata:
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "1.0",
|
||||
"mediawiki": {
|
||||
"name": "Wikidata",
|
||||
"root": "https://www.wikidata.org/wiki/",
|
||||
"main_page": "https://www.wikidata.org/wiki/Wikidata:Main_Page",
|
||||
"api": "https://www.wikidata.org/w/api.php"
|
||||
},
|
||||
"wikibase": {
|
||||
"site_iri": "http://www.wikidata.org/entity/",
|
||||
"maxlag": 5,
|
||||
"properties": {
|
||||
"instance_of": "P31",
|
||||
"subclass_of": "P279"
|
||||
},
|
||||
"constraints": {
|
||||
"property_constraint_pid": "P2302",
|
||||
"exception_to_constraint_pid": "P2303",
|
||||
"constraint_status_pid": "P2316",
|
||||
"mandatory_constraint_qid": "Q21502408",
|
||||
"suggestion_constraint_qid": "Q62026391",
|
||||
"distinct_values_constraint_qid": "Q21502410",
|
||||
// ...
|
||||
}
|
||||
},
|
||||
"oauth": {
|
||||
"registration_page": "https://meta.wikimedia.org/wiki/Special:OAuthConsumerRegistration/propose"
|
||||
},
|
||||
"reconciliation": {
|
||||
"endpoint": "https://wikidata.reconci.link/${lang}/api"
|
||||
},
|
||||
"editgroups": {
|
||||
"url_schema": "([[:toollabs:editgroups/b/OR/${batch_id}|details]])"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
In general, there are several parts of the manifest: version, mediawiki, wikibase, oauth, reconciliation and editgroups.
|
||||
|
||||
#### version {#version}
|
||||
|
||||
The version should in the format "1.x". The minor version should be increased when you update the manifest in a backward-compatible manner. The major version should be "1" if the manifest is in the format specified by [wikibase-manifest-schema-v1.json](https://github.com/afkbrb/wikibase-manifest/blob/master/wikibase-manifest-schema-v1.json).
|
||||
|
||||
#### mediawiki {#mediawiki}
|
||||
|
||||
This part contains some basic information of the Wikibase.
|
||||
|
||||
##### name {#name}
|
||||
|
||||
The name of the Wikibase, should be unique for different Wikibase instances.
|
||||
|
||||
##### root {#root}
|
||||
|
||||
The root of the Wikibase. Typically in the form "https://foo.bar/wiki/". The trailing slash cannot be omitted.
|
||||
|
||||
##### main_page {#main_page}
|
||||
|
||||
The main page of the Wikibase. Typically in the form "https://foo.bar/wiki/Main_Page".
|
||||
|
||||
##### api {#api}
|
||||
|
||||
The MediaWiki API endpoint of the Wikibase. Typically in the form "https://foo.bar/w/api.php".
|
||||
|
||||
#### wikibase {#wikibase}
|
||||
|
||||
This part contains configurations of the Wikibase extension.
|
||||
|
||||
##### site_iri {#site_iri}
|
||||
|
||||
The IRI of the Wikibase, in the form 'http://foo.bar/entity/'. This should match the IRI prefixes used in RDF serialization. Be careful about using "http" or "https", because any variation will break comparisons at various places. The trailing slash cannot be omitted.
|
||||
|
||||
##### maxlag {#maxlag}
|
||||
|
||||
Maxlag is a parameter that controls how aggressive a mass-editing tool should be when uploading edits to a Wikibase instance. See https://www.mediawiki.org/wiki/Manual:Maxlag_parameter for more details. The value should be adapted according to the actual traffic of the Wikibase.
|
||||
|
||||
##### properties {#properties}
|
||||
|
||||
Some special properties of the Wikibase.
|
||||
|
||||
###### instance_of {#instance_of}
|
||||
|
||||
The ID of the property "instance of".
|
||||
|
||||
###### subclass_of {#subclass_of}
|
||||
|
||||
The ID of the property "subclass of".
|
||||
|
||||
##### constraints {#constraints}
|
||||
|
||||
Not required. Should be configured if the Wikibase has the [WikibaseQualityConstraints extension](https://www.mediawiki.org/wiki/Extension:WikibaseQualityConstraints) installed. Configurations of constraints consists of IDs of constraints related properties and items. For Wikidata, these IDs are retrieved from [extension.json](https://github.com/wikimedia/mediawiki-extensions-WikibaseQualityConstraints/blob/master/extension.json). To configure this for another Wikibase instance, you should contact an admin of the Wikibase instance to get the content of `extension.json`.
|
||||
|
||||
#### oauth {#oauth}
|
||||
|
||||
Not required. Should be configured if the Wikibase has the [OAuth extension](https://www.mediawiki.org/wiki/Extension:OAuth) installed.
|
||||
|
||||
##### registration_page {#registration_page}
|
||||
|
||||
The page to register an OAuth consumer of the Wikibase. Typically in the form "https://foo.bar/wiki/Special:OAuthConsumerRegistration/propose".
|
||||
|
||||
#### reconciliation {#reconciliation}
|
||||
|
||||
The Wikibase instance must have at least a reconciliation service endpoint linked to it. If there is no reconciliation service for the Wikibase, you can run one with [openrefine-wikibase](https://github.com/wetneb/openrefine-wikibase).
|
||||
|
||||
##### endpoint {#endpoint}
|
||||
|
||||
The default reconciliation service endpoint of the Wikibase instance. The endpoint must contain the "${lang}" variable such as "https://wikidata.reconci.link/${lang}/api", since the reconciliation service is expected to work for different languages.
|
||||
|
||||
#### editgroups {#editgroups}
|
||||
|
||||
Not required. Should be configured if the Wikibase instance has [EditGroups](https://github.com/Wikidata/editgroups) service(s).
|
||||
|
||||
##### url_schema {#url_schema}
|
||||
|
||||
The URL schema used in edits summary. This is used for EditGroups to extract the batch id from a batch of edits and for linking to the EditGroups page of the batch. The URL schema must contains the variable '${batch_id}', such as '([[:toollabs:editgroups/b/OR/${batch_id}|details]])' for Wikidata.
|
||||
|
||||
#### Check the format of the manifest {#check-the-format-of-the-manifest}
|
||||
|
||||
As mentioned above, the manifest should be in the format specified by [wikibase-manifest-schema-v1.json](https://github.com/afkbrb/wikibase-manifest/blob/master/wikibase-manifest-schema-v1.json). You can check the format by adding the manifest directly to OpenRefine, and OpenRefine will complain if there is anything wrong with the format.
|
||||
|
||||
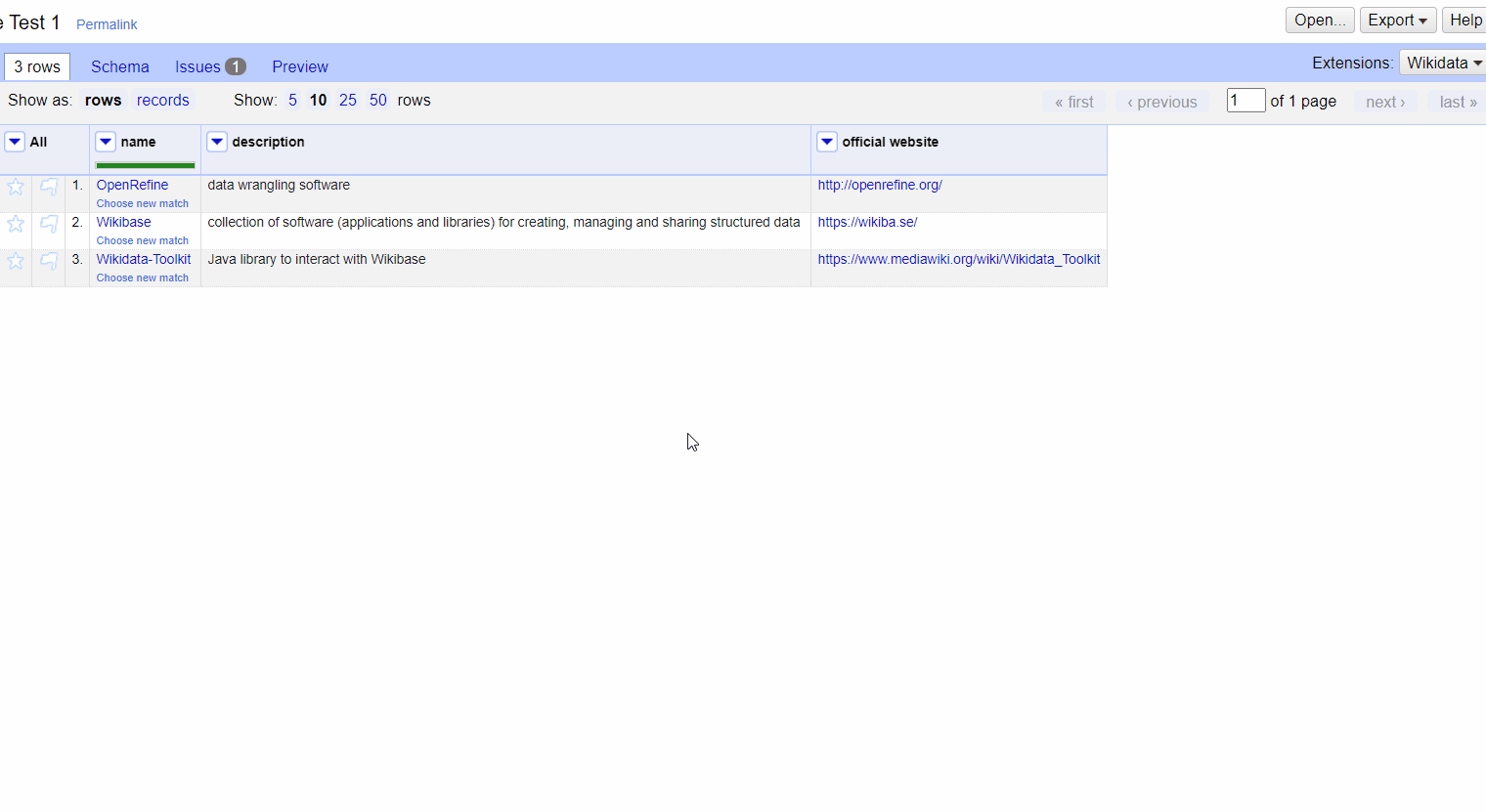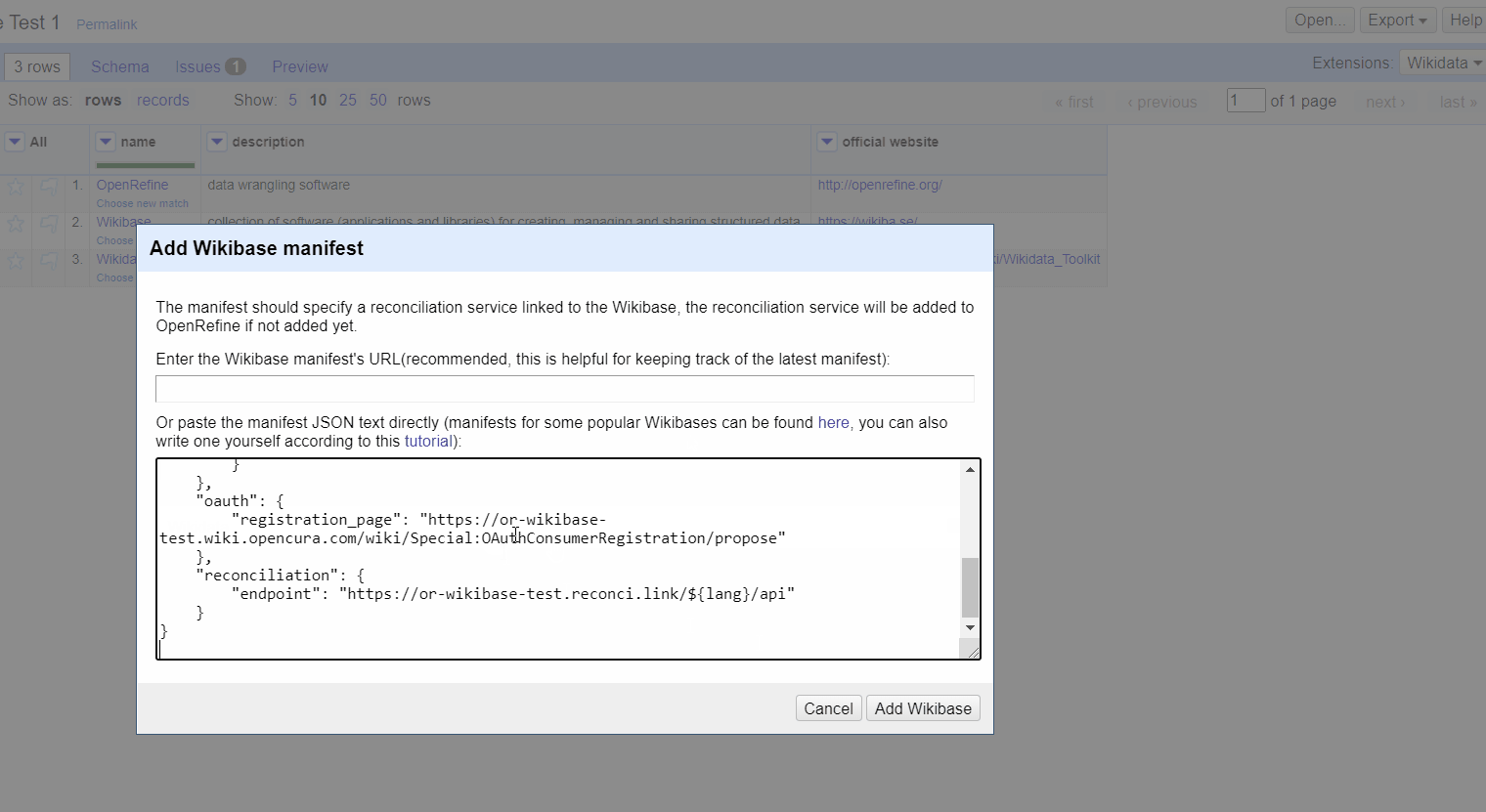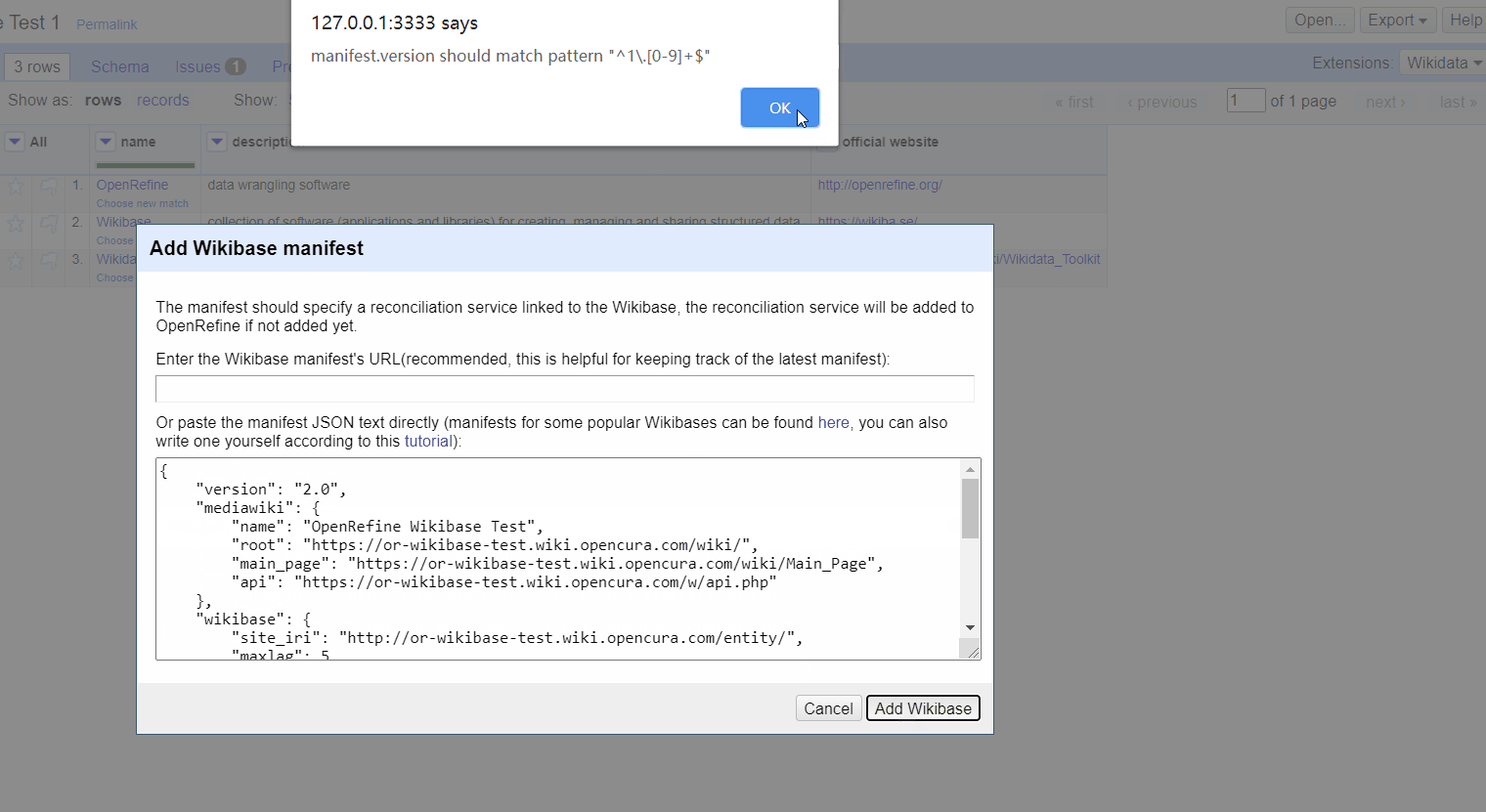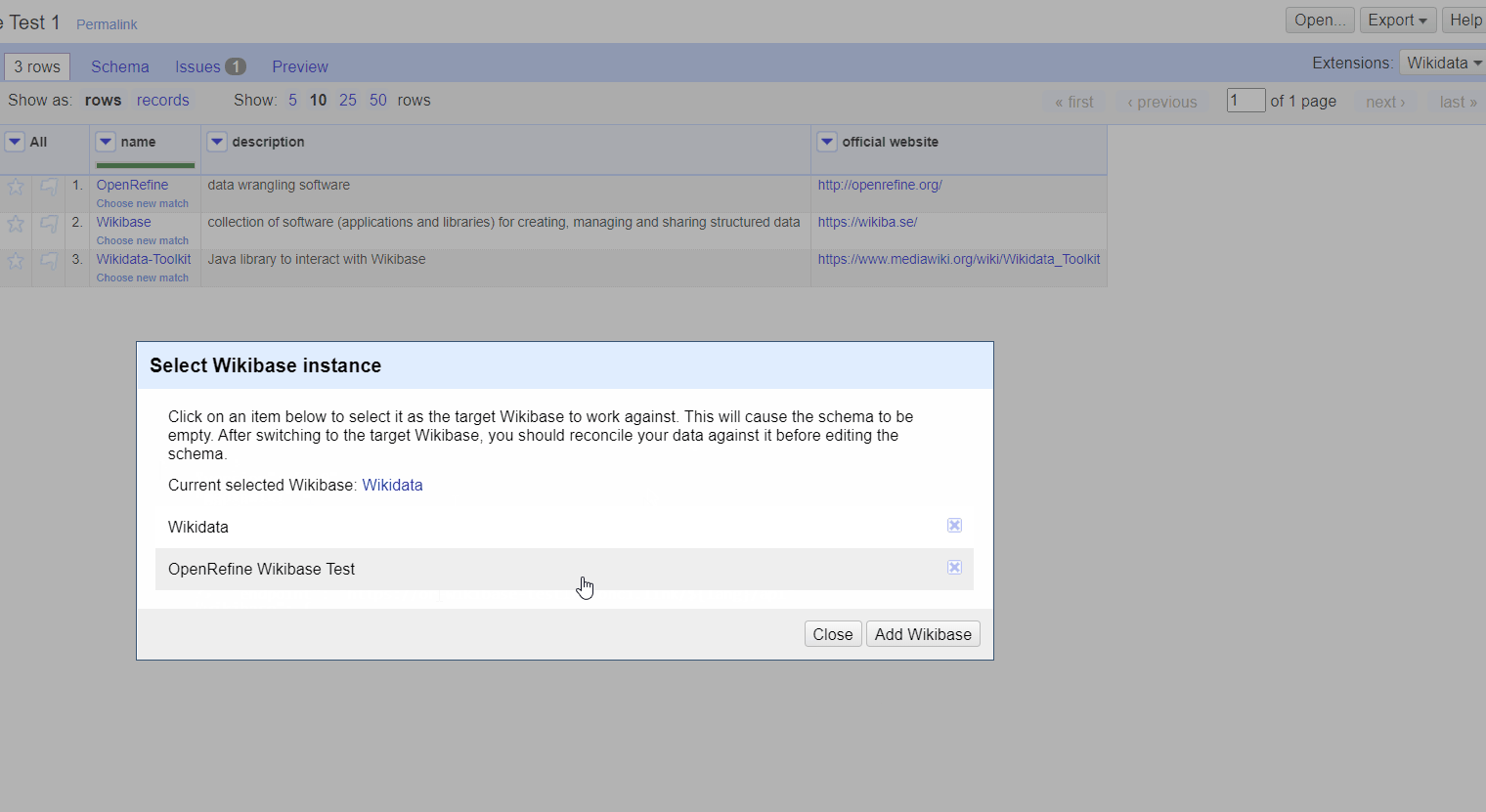
|
||||
@ -1,104 +0,0 @@
|
||||
---
|
||||
id: new-entities
|
||||
title: Creating new items
|
||||
sidebar_label: New items
|
||||
---
|
||||
|
||||
OpenRefine can create new items. This page explains how they are
|
||||
generated.
|
||||
|
||||
## Words of caution {#words-of-caution}
|
||||
|
||||
- The fact that OpenRefine does not propose any item when reconciling
|
||||
a cell does not mean that the item is not present in the Wikibase instance:
|
||||
it can be missed for all sorts of reasons. Please make
|
||||
sure that you are not creating any duplicates!
|
||||
|
||||
- Make sure that the items that you want to create are admissible in
|
||||
the Wikibase instance. For Wikidata, see the [notability guidelines](https://www.wikidata.org/wiki/Wikidata:Notability);
|
||||
|
||||
- Deleting items generally requires special rights: if you want to revert an
|
||||
edit group that includes new items in Wikidata, you will need to ask an
|
||||
administrator to do it.
|
||||
|
||||
## Workflow overview {#workflow-overview}
|
||||
|
||||
Here is how you would typically create new items with OpenRefine:
|
||||
|
||||
- Reconcile a column;
|
||||
- Mark some of its cells as new items. This will not create items yet.
|
||||
If you need to mark many rows as new items, use the **Reconcile** →
|
||||
**Actions** → **Create a new item for each cell** operation.
|
||||
- Create a Wikibase schema as usual, using the column where your new
|
||||
items are marked;
|
||||
- Perform the edits: the new items will be created on Wikidata at this
|
||||
point;
|
||||
- The cells that you had marked as new items will now be reconciled to
|
||||
the newly-created items.
|
||||
|
||||
It is often useful (but not mandatory) to treat new items in isolation
|
||||
and use a dedicated schema for them. This helps you add many statements
|
||||
on the new items (including labels and descriptions) without risking to
|
||||
clutter existing items with redundant edits. Use a facet on the judgment
|
||||
status of the reconciled column to isolate new items and perform their
|
||||
edits separately. As always in OpenRefine, only the rows covered by your
|
||||
facets will be considered when uploading the edits to Wikidata: if a
|
||||
cell is reconciled to a new item but is excluded by the facet, no new
|
||||
item will be created for it.[^1]
|
||||
|
||||
Note that even if you know that all items in your column are new, you
|
||||
will still need to make a first reconciliation pass by selecting the
|
||||
Wikidata reconciliation service, and then setting all reconciliation
|
||||
statuses to \"new\". If you skip the first part, OpenRefine will not
|
||||
know that this column is reconciled against your Wikibase instance (it could be
|
||||
reconciled to other services) so it will not let you use it in place of
|
||||
an item in a Wikibase schema.
|
||||
|
||||
You can also perform the edits with QuickStatements - in this case, your
|
||||
OpenRefine project will not be updated with the newly created Qids.
|
||||
|
||||
## Adding labels to new items {#adding-labels-to-new-items}
|
||||
|
||||
The text that is in a cell reconciled to \"new\" is not automatically
|
||||
used as label for the newly-created item. This is because OpenRefine has
|
||||
no way to guess in which language this label should be. When adding new
|
||||
items, you need to explicitly add a label in the schema. This label can
|
||||
use the reconciled column as source, but if you have other cells matched
|
||||
to existing items, be careful not to override the labels of these items
|
||||
(if it is not your intention).
|
||||
|
||||
OpenRefine will refuse to perform edits where new items are created
|
||||
without any labels (as this is considered a critical issue). Other
|
||||
issues will be raised if insufficient basic information is added on the
|
||||
items (but these other warnings will not prevent you from performing the
|
||||
edits).
|
||||
|
||||
## Marking multiple cells as identical items {#marking-multiple-cells-as-identical-items}
|
||||
|
||||
If you mark individual cells as new items, one new item per cell will be
|
||||
created. Sometimes multiple rows refer to the same item. OpenRefine
|
||||
makes it possible to mark all the corresponding cells as the *same* new
|
||||
item. Two conditions have to be met:
|
||||
- the reconciled cells must be in the same column (it is not possible
|
||||
to mark two cells in different colums as the same new item);
|
||||
- the cells must contain the same initial text value.
|
||||
|
||||
If these two conditions are met, then isolate these cells with facets
|
||||
and go to **Reconcile** → **Actions** → **Create one item for similar
|
||||
cells**. This will mark the cells as new and referring to the same item.
|
||||
|
||||
## Retrieving the Qids of the newly-created items {#retrieving-the-qids-of-the-newly-created-items}
|
||||
|
||||
Once you have performed your edits with OpenRefine, any new cells
|
||||
covered by the facet will be updated with their new Qids. You can
|
||||
retrieve these Qids with the **Edit column** → **Add column based on
|
||||
this column** action and using the `cell.recon.match.id` expression.
|
||||
Note that you will no longer be able to isolate new items with a
|
||||
judgment facet at this stage (because the judgment will be updated to
|
||||
**matched**) so it can be worth marking these rows (for instance with a
|
||||
star or flag) before performing the edits.
|
||||
|
||||
[^1]: The only exception to this rule is when marking multiple cells as
|
||||
identical items: in this case, if one of such cells are included in
|
||||
the facet, then all the others will be updated with the newly
|
||||
created Qid once the edits are made.
|
||||
@ -1,134 +0,0 @@
|
||||
---
|
||||
id: overview
|
||||
title: Overview of Wikibase support
|
||||
sidebar_label: Overview
|
||||
---
|
||||
|
||||
[Wikibase](https://wikiba.se/) is a platform for collaborative knowledge base editing. Its flagship instance [Wikidata](https://www.wikidata.org/) offers structured data about the world and can be edited by anyone. OpenRefine provides powerful ways to both pull data from Wikibase and add data to it.
|
||||
|
||||
OpenRefine's Wikibase integration is provided by an extension which is available by default in OpenRefine. In this page, we present the functionalities for Wikidata, but [any Wikibase instance can be connected to OpenRefine](./configuration) to obtain a similar integration.
|
||||
|
||||
## Editing Wikidata with OpenRefine {#editing-wikidata-with-openrefine}
|
||||
|
||||
As a user-maintained data source, Wikidata can be edited by anyone. OpenRefine makes it simple to upload information in bulk. You simply need to get your information into the correct format, and ensure that it is new (not redundant to information already on Wikidata) and does not conflict with existing Wikidata information.
|
||||
|
||||
You do not need a Wikidata account to reconcile your local OpenRefine project to Wikidata, but to upload your cleaned dataset to Wikidata, you will need an [autoconfirmed](https://www.wikidata.org/wiki/Wikidata:Autoconfirmed_users) account, and you must [authorize OpenRefine with that account](#manage-wikidata-account).
|
||||
|
||||
Wikidata is built by creating entities (such as people, organizations, or places, identified with unique numbers starting with Q), defining properties (unique numbers starting with P), and using properties to define relationships between entities (a Q has a property P, with a value of another Q).
|
||||
|
||||
For example, you may wish to create entities for local authors and the books they've set in your community. Each writer will be an entity with the occupation [author (Q482980)](https://www.wikidata.org/wiki/Q482980), each book will be an entity with the property “instance of” ([P31](https://www.wikidata.org/wiki/Property:P31)) linking it to a class such as [literary work (Q7725634)](https://www.wikidata.org/wiki/Q7725634), and books will be related to authors through a property [author (P50)](https://www.wikidata.org/wiki/Property:P50). Books can have places where they are set, with the property [narrative location (P840)](https://www.wikidata.org/wiki/Property:P840).
|
||||
|
||||
To do this with OpenRefine, you'll need a column of publication titles that you have reconciled (and create new items where needed); each publication will have one or more locations in a “setting” column, which is also reconciled to municipalities or regions where they exist (and create new items where needed). Then you can add those new relationships, and create new entities for authors, books, and places where needed. You do not need columns for properties; those are defined later, in the creation of your [schema](#edit-wikidata-schema).
|
||||
|
||||
There is a list of [tutorials and walkthroughs on Wikidata](https://www.wikidata.org/wiki/Wikidata:Tools/OpenRefine/Editing) that will allow you to see the full process. You can save your schemas and drafts in OpenRefine, and your progress stays in draft until you are ready to upload it to Wikidata.
|
||||
|
||||
Batches of edits to Wikidata that are created with OpenRefine can be undone. You can test out the uploading process by reconciling to several “sandbox” entities created specifically for drafting edits and learning about Wikidata:
|
||||
* https://www.wikidata.org/wiki/Q4115189
|
||||
* https://www.wikidata.org/wiki/Q13406268
|
||||
* https://www.wikidata.org/wiki/Q15397819
|
||||
* https://www.wikidata.org/wiki/Q64768399
|
||||
|
||||
If you upload edits that are redundant (that is, all the statements you want to make have already been made), nothing will happen. If you upload edits that conflict with existing information (such as a different birthdate than one already in Wikidata), it will be added as a second statement. OpenRefine produces no warnings as to whether your data replicates or conflicts with existing Wikidata elements.
|
||||
|
||||
You can use OpenRefine's reconciliation preview to look at the target Wikidata elements and see what information they already have, and whether the elements' histories have had similar edits reverted in the past.
|
||||
|
||||
### Wikidata schema {#wikidata-schema}
|
||||
|
||||
A [schema](https://en.wikipedia.org/wiki/Database_schema) is a plan for how to structure information in a database. In OpenRefine, the schema operates as a template for how Wikidata edits should be applied: how to translate your tabular data into statements. With a schema, you can:
|
||||
* preview the Wikidata edits and inspect them manually;
|
||||
* analyze and fix any issues highlighted by OpenRefine;
|
||||
* upload your changes to Wikidata by logging in with your own account;
|
||||
* export the changes to the QuickStatements v1 format.
|
||||
|
||||
For example, if your dataset has columns for authors, publication titles, and publication years, your schema can be conceptualized as: [publication title] has the author [author], and was published in [publication year]. To establish these facts, you need to establish one or more columns as “items,” for which you will make “statements” that relate them to other columns.
|
||||
|
||||
You can export any schema you create, and import an existing schema for use with a new dataset. This can help you work in batches on a large amount of data while minimizing redundant labor.
|
||||
|
||||
Once you select <span class="menuItems">Edit Wikidata schema</span> under the <span class="menuItems">Extensions</span> dropdown menu, your project interface will change. You’ll see new tabs added to the right of “X rows/records" in the grid header: “Schema,” “Issues,” and “Preview.” You can now switch between the tabular grid format of your dataset and the screens that allow you to prepare data for uploading.
|
||||
|
||||
OpenRefine presents you with an easy visual way to map out the relationships in your dataset. Each of the columns of your project will appear at the top of the sceren, and you can simply drag and drop them into the appropriate slots. To get start, select one column as an item.
|
||||
|
||||

|
||||
|
||||
You may wish to refer to [this Wikidata tutorial on how OpenRefine handles Wikidata schema](https://www.wikidata.org/wiki/Wikidata:Tools/OpenRefine/Editing/Tutorials/Basic_editing). For details about how each data type is handled in the Wikibase schema, see [Schema alignment](./schema-alignment).
|
||||
|
||||
#### Editing terms with your schema {#editing-terms-with-your-schema}
|
||||
|
||||
With OpenRefine, you can edit the terms (labels, aliases, descriptions, or sitelinks) of Wikidata entities as well as establish relationships between entities. For example, you may wish to upload pseudonyms, pen names, maiden names, or married names for authors.
|
||||
|
||||

|
||||
|
||||
You can do so by putting the preferred names in one column of your dataset and alternative names in another column. In the schema interface, add an item for the preferred values, then click “Add term” on the right-hand side of the screen. Select “Alias” from the dropdown, enter in “English” in the language field, and drop your alternative names column into the space. For this example, you should also consider adding those alternative names to the authors' entries using the property [pseudonym (P742)](https://www.wikidata.org/wiki/Property:P742). The "description" and "label" terms can only contain one value, so there is an option to override existing values if needed. Aliases can be potentially infinite.
|
||||
|
||||

|
||||
|
||||
Terms must always have an associated language. You can select the term's language by typing in the “lang” field, which will auto-complete for you. You cannot edit multiple languages at once, unless you supply a suitable column instead. For example, suppose you had translated publication titles, with data in the following format:
|
||||
|
||||
|English title|Translated title|Translation language|
|
||||
|---|---|---|
|
||||
|Possession|Besessen|German|
|
||||
||Обладать|Russian|
|
||||
|Disgrace|Disgrâce|French|
|
||||
||Vergogna|Italian|
|
||||
|Wolf Hall|En la corte del lobo|Spanish|
|
||||
||ウルフ・ホール|Japanese|
|
||||
|
||||
You could upload the “Translated titles” to “Label” with the language specified by “Translation language.” You may wish to fetch the two-letter language code and use that instead for better language matches.
|
||||
|
||||

|
||||
|
||||
### Manage Wikidata account {#manage-wikidata-account}
|
||||
|
||||
To edit Wikidata directly from OpenRefine, you must log in with a Wikidata account. OpenRefine can only upload edits with Wikidata user accounts that are “[autoconfirmed](https://www.wikidata.org/wiki/Wikidata:Autoconfirmed_users)” - at this time, that means accounts that have more than 50 edits and have existed for longer than four days.
|
||||
|
||||
Use the <span class="menuItems">Extensions</span> menu to select <span class="menuItems">Manage Wikidata account</span> and you will be presented with the following window:
|
||||
|
||||

|
||||
|
||||
For security reasons, you should not use your main account authorization with OpenRefine. Wikidata allows you to set special passwords to access your account through software. You can find [this setting for your account here](https://www.wikidata.org/wiki/Special:BotPasswords) once logged in. Creating bot access will prompt you for a unique name. You should then enable the following required settings:
|
||||
* High-volume editing
|
||||
* Edit existing pages
|
||||
* Create, edit, and move pages
|
||||
|
||||
It will then generate a username (in the form of “yourwikidatausername@yourbotname”) and password for you to use with OpenRefine.
|
||||
|
||||
If your account or your bot is not properly authorized, OpenRefine will not display a warning or error when you try to upload your edits.
|
||||
|
||||
You can store your unencrypted username and password in OpenRefine, saved locally to your computer and available for future use. For security reasons, you may wish to leave this box unchecked. You can also save your OpenRefine-specific bot password in your browser or with a password management tool.
|
||||
|
||||
### Import and export schema {#import-and-export-schema}
|
||||
|
||||
You can save time on repetitive processes by defining a schema on one project, then exporting it and importing for use on new datasets in the future. Or you and your colleagues can share a schema with each other to coordinate your work.
|
||||
|
||||
You can export a schema from a project using <span class="menuItems">Export</span> → <span class="menuItems">Wikidata schema</span>, or by using <span class="menuItems">Extensions</span> → <span class="menuItems">Export schema</span>. OpenRefine will generate a JSON file for you to save and share. You may experience issues with pop-up windows in your browser: consider allowing pop-ups from the OpenRefine URL (`127.0.0.1`) from now on.
|
||||
|
||||
You can import a schema using <span class="menuItems">Extensions</span> → <span class="menuItems">Import schema</span>. You can upload a JSON file, or paste JSON statements directly into a field in the window. An imported schema will look for columns with the same names, and you will see an error message if your project doesn't contain matching columns.
|
||||
|
||||
### Upload edits to Wikidata {#upload-edits-to-wikidata}
|
||||
|
||||
There are two menu options in OpenRefine for applying your edits to Wikidata, and the details of the differences between the two can be found in the [Uploading page](./uploading). Under <span class="menuItems">Export</span> you will see <span class="menuItems">Wikidata edits...</span> and under <span class="menuItems">Extensions</span> you will see <span class="menuItems">Upload edits to Wikidata</span>. Both will bring up the same window for you to [log in with a Wikidata account](#manage-wikidata-account).
|
||||
|
||||
Once you are authorized, you will see a window with any outstanding issues. You can ignore these issues, but we recommend you resolve them.
|
||||
|
||||
If you are ready to upload your edits, you can provide an “Edit summary” - a short message describing the batch of edits you are making. It can be helpful to leave notes for yourself, such as “batch 1: authors A-G” or other indicators of your workflow progress. OpenRefine will show the progress of the upload as it is happening, but does not show a confirmaton window.
|
||||
|
||||
If your edits have been successful, you will see them listed on [your Wikidata user contributions page](https://www.wikidata.org/wiki/Special:Contributions/), and on the [Edit groups page](https://editgroups.toolforge.org/). All edits can be undone from this second interface.
|
||||
|
||||
### QuickStatements export {#quickstatements-export}
|
||||
|
||||
Your OpenRefine data can be exported in a format recognized by [QuickStatements](https://www.wikidata.org/wiki/Help:QuickStatements), a tool that creates Wikidata edits using text commands. OpenRefine generates “version 1” QuickStatements commands.
|
||||
|
||||
There are advantages to using QuickStatements rather than uploading your edits directly to Wikidata, including the way QuickStatements resolves duplicates and redundancies. You can learn more on QuickStatements' [Help page](https://www.wikidata.org/wiki/Help:QuickStatements), and on OpenRefine's [Uploading page](https://www.wikidata.org/wiki/Wikidata:Tools/OpenRefine/Editing/Uploading).
|
||||
|
||||
In order to use QuickStatements, you must authorize it with a Wikidata account that is [autoconfirmed](https://www.wikidata.org/wiki/Wikidata:Autoconfirmed_users) (it may appear as “MediaWiki” when you authorize).
|
||||
|
||||
Follow the [steps listed on this page](https://www.wikidata.org/wiki/Help:QuickStatements#Running_QuickStatements).
|
||||
To prepare your OpenRefine data into QuickStatements, select <span class="menuItems">Export</span> → <span class="menuItems">QuickStatements file</span>, or <span class="menuItems">Extensions</span> → <span class="menuItems">Export to QuickStatements</span>. Exporting your schema from OpenRefine will generate a text file called `statements.txt` by default. Paste the contents of the text file into a new QuickStatements batch using version 1. You can find [version 1 of the tool (no longer maintained) here](https://wikidata-todo.toolforge.org/quick_statements.php). The text commands will be processed into Wikidata edits and previewed for you to review before submitting.
|
||||
|
||||
### Issue detection {#issue-detection}
|
||||
|
||||
This section is an overview of the [Quality assurance page](./quality-assurance).
|
||||
|
||||
OpenRefine will analyze your schema and make suggestions. It does not check for conflicts in your proposed edits, or tell you about redundancies.
|
||||
|
||||
One of the most common suggestions is to attach [a reference to your edits](https://www.wikidata.org/wiki/Help:Sources) - a citation for where the information can be found. This can be a book or newspaper citation, a URL to an online page, a reference to a physical source in an archival or special collection, or another source. If the source is itself an item on Wikidata, use the relationship [stated in (P248)](https://www.wikidata.org/wiki/Property:P248); otherwise, use [reference URL (P854)](https://www.wikidata.org/wiki/Property:P854) to identify an external source.
|
||||
@ -1,48 +0,0 @@
|
||||
---
|
||||
id: quality-assurance
|
||||
title: Quality assurance for Wikibase uploads
|
||||
sidebar_label: Quality assurance
|
||||
---
|
||||
|
||||
This page explains how the Wikidata extension of OpenRefine analyzes edits before they are uploaded to the Wikibase
|
||||
instance. Most of these checks rely on the use of the [Wikibase Quality Constraints](https://gerrit.wikimedia.org/g/mediawiki/extensions/WikibaseQualityConstraints) extension and the configuration of the property and item identifiers in the [Wikibase manifest](./configuration).
|
||||
|
||||
## Overview {#overview}
|
||||
|
||||
Changes are scrutinized before they are uploaded, but also before the current content of the corresponding items is retrieved and merged with the updates. This means that some constraint violations cannot be predicted by the software (for instance, adding a new statement that conflicts with an existing statement on the item). However, this makes it possible to run the checks quickly, even for relatively large batches of edits. Issues are therefore refreshed in real time while the user builds the schema.
|
||||
|
||||
As a consequence, not all constraint violations can be detected: the ones that are supported are listed in the [Constraint violations](#constraint-violations) section. Conversely, not all issues reported will be flagged as constraint violations on the Wikibase site: see [Generic issues](#generic-issues) for these.
|
||||
|
||||
## Reconciliation {#reconciliation}
|
||||
|
||||
You should always assess the quality of your reconciliation results first. OpenRefine has various tools for quality assurance of reconciliation results. For instance:
|
||||
|
||||
* you can analyze the string similarity between your original names and those of the reconciled items (for instance with <span class="menuItems">Reconcile</span> → <span class="menuItems">Facets</span> → <span class="menuItems">Best candidate's name edit distance</span>);
|
||||
* you can compare the values in your table with those on the items (via a text facet defined by a custom expression);
|
||||
* you can facet by type on the reconciled items (add a new column with the types and use a text facet ordered by counts to get a sense of the distribution of types in your reconciled items).
|
||||
|
||||
## Constraint violations {#constraint-violations}
|
||||
|
||||
Constraints are retrieved as defined on the properties, using [ (P2302)](https://www.wikidata.org/wiki/Property:P2302).
|
||||
|
||||
The following constraints are supported:
|
||||
* [format constraint (Q21502404)](https://www.wikidata.org/wiki/Q21502404), checked on all values
|
||||
* [inverse constraint (Q21510855)](https://www.wikidata.org/wiki/Q21510855): OpenRefine assumes that the inverses of the candidate statements are not in Wikidata yet. If you know that the inverse statements are already in Wikidata, you can safely ignore this issue.
|
||||
* [used for values only constraint (Q21528958)](https://www.wikidata.org/wiki/Q21528958), [used as qualifier constraint (Q21510863)](https://www.wikidata.org/wiki/Q21510863) and [used as reference constraint (Q21528959)](https://www.wikidata.org/wiki/Q21528959)
|
||||
* [allowed qualifiers constraint (Q21510851)](https://www.wikidata.org/wiki/Q21510851)
|
||||
* [required qualifier constraint (Q21510856)](https://www.wikidata.org/wiki/Q21510856)
|
||||
* [single-value constraint (Q19474404)](https://www.wikidata.org/wiki/Q19474404): this will only trigger if you are adding more than one statement with the property on the same item, but will not detect any existing statement with this property.
|
||||
* [distinct values constraint (Q21502410)](https://www.wikidata.org/wiki/Q21502410): similarly, this only checks for conflicts inside your edit batch.
|
||||
|
||||
A comparison of the supported constraints with respect to other implementations is available [here](https://www.wikidata.org/wiki/Wikidata:WikiProject_property_constraints/reports/implementations).
|
||||
|
||||
## Generic issues {#generic-issues}
|
||||
|
||||
OpenRefine also detects issues that are not flagged (yet) by constraint violations on Wikidata:
|
||||
* Statements without references. This does not rely on [citation needed constraint (Q54554025)](https://www.wikidata.org/wiki/Q54554025): all statements are expected to have references. (The idea is that when importing a dataset, every statement you add
|
||||
* should link to this dataset - it does not hurt to do it even for generic properties such as [instance of (P31)](https://www.wikidata.org/wiki/Property:P31).)
|
||||
* Spurious whitespace and non-printable characters in strings (including labels, descriptions and aliases);
|
||||
* Self-referential statements (statements which mention the item they belong to);
|
||||
* New items created without any label;
|
||||
* New items created without any description;
|
||||
* New items created without any [instance of (P31)](https://www.wikidata.org/wiki/Property:P31) or [subclass of (P279)](https://www.wikidata.org/wiki/Property:P279) statement.
|
||||
@ -1,45 +0,0 @@
|
||||
---
|
||||
id: reconciling
|
||||
title: Reconciling with Wikibase
|
||||
sidebar_label: Reconciling with Wikibase
|
||||
---
|
||||
|
||||
The Wikidata [reconciliation service](reconciling) for OpenRefine [supports](https://reconciliation-api.github.io/testbench/):
|
||||
* A large number of potential types to reconcile against
|
||||
* Previewing and viewing entities
|
||||
* Suggesting entities, types, and properties
|
||||
* Augmenting your project with more information pulled from Wikidata.
|
||||
|
||||
You can find documentation and further resources on the reconciliation API [here](https://wikidata.reconci.link/).
|
||||
|
||||
For the most part, Wikidata reconciliation behaves the same way other reconciliation services do, but there are a few processes and features specific to Wikidata.
|
||||
|
||||
## Language settings {#language-settings}
|
||||
|
||||
You can install a version of the Wikidata reconciliation service that uses your language. First, you need the language code: this is the [two-letter code found on this list](https://en.wikipedia.org/wiki/List_of_Wikipedias), or in the domain name of the desired Wikipedia/Wikidata (for instance, “fr” if your Wikipedia is https://fr.wikipedia.org/wiki/).
|
||||
|
||||
Then, open the reconciliation window (under <span class="menuItems">Reconcile</span> → <span class="menuItems">Start reconciling...</span>) and click <span class="menuItems">Add Standard Service</span>. The URL to enter is `https://wikidata.reconci.link/fr/api`, where “fr” is your desired language code.
|
||||
|
||||
When reconciling using this interface, items and properties will be displayed in your chosen language if the label is available. The matching score of the reconciliation is not influenced by your choice of language for the service: items are matched by considering all labels and returning the best possible match. The language of your dataset is also irrelevant to your choice of language for the reconciliation service; it simply determines which language labels to return based on the entity chosen.
|
||||
|
||||
## Restricting matches by type {#restricting-matches-by-type}
|
||||
|
||||
In Wikidata, types are items themselves. For instance, the [university of Ljubljana (Q1377)](https://www.wikidata.org/wiki/Q1377) has the type [public university (Q875538)](https://www.wikidata.org/wiki/Q875538), using the [instance of (P31)](https://www.wikidata.org/wiki/Property:P31) property. Types can be subclasses of other types, using the [subclass of (P279)](https://www.wikidata.org/wiki/Property:P279) property. For instance, [public university (Q875538)](https://www.wikidata.org/wiki/Q875538) is a subclass of [university (Q3918)](https://www.wikidata.org/wiki/Q3918). You can visualize these structures with the [Wikidata Graph Builder](https://angryloki.github.io/wikidata-graph-builder/).
|
||||
|
||||
When you select or enter a type for reconciliation, OpenRefine will include that type and all of its subtypes. For instance, if you select [university (Q3918)](https://www.wikidata.org/wiki/Q3918), then [university of Ljubljana (Q1377)](https://www.wikidata.org/wiki/Q1377) will be a possible match, though that item isn't directly linked to Q3918 - because it is directly linked to Q875538, the subclass of Q3918.
|
||||
|
||||
Some items and types may not yet be set as an instance or subclass of anything (because Wikidata is crowdsourced). If you restrict reconciliation to a type, items without the chosen type will not appear in the results, except as a fallback, and will have a lower score.
|
||||
|
||||
## Reconciling via unique identifiers {#reconciling-via-unique-identifiers}
|
||||
|
||||
You can supply a column of unique identifiers (in the form "Q###" for entities) directly to Wikidata in order to pull more data, but [these strings will not be “reconciled” against the external dataset](reconciling#reconciling-with-unique-identifiers). Apply the operation <span class="menuItems">Reconcile</span> → <span class="menuItems">Use values as identifiers</span> on your column of QIDs. All cells will appear as dark blue “confirmed” matches. Some of the “matches” may be errors, which you will need to hover over or click on to identify. You cannot use this to reconcile properties (in the form "P###").
|
||||
|
||||
If the identifier you submit is assigned to multiple Wikidata items (because Wikidata is crowdsourced), all of the items are returned as candidates, with none automatically matched.
|
||||
|
||||
## Property paths, special properties, and subfields {#property-paths-special-properties-and-subfields}
|
||||
|
||||
Wikidata's hierarchical property structure can be called by using property paths (using |, /, and . symbols). Labels, aliases, descriptions, and sitelinks can also be accessed. You can also match values against subfields, such as latitude and longitude subfields of a geographical coordinate.
|
||||
|
||||
For information on how to do this, read the [documentation and further resources here](https://wikidata.reconci.link/#documentation).
|
||||
|
||||
|
||||
@ -1,253 +0,0 @@
|
||||
---
|
||||
id: schema-alignment
|
||||
title: Schema alignment
|
||||
sidebar_label: Schema alignment
|
||||
---
|
||||
|
||||
A Wikibase schema is a template of Wikidata edits that is applied
|
||||
to each row in the project. This page describes how each part of this
|
||||
template works, and how it generates edits depending on the contents of
|
||||
the table cells.
|
||||
|
||||
## Items {#items}
|
||||
|
||||
An item in the schema represents a set of changes on a particular
|
||||
Wikidata item, generated by a single row. This item can contain changes
|
||||
in [terms](#terms) (labels, descriptions and aliases) or
|
||||
[statements](#statements).
|
||||
|
||||
It is possible to make edits on different items for each row of your
|
||||
table: just add multiple items in your schema. Each item has a subject,
|
||||
which can be either entered manually (when the item on which the edits
|
||||
should be made is the same for all rows), or any reconciled column can
|
||||
be dropped in this field. In this case, the edits will depend on the
|
||||
reconciliation status of each cell:
|
||||
|
||||
- If the cell is matched to an item, edits will be made on that item;
|
||||
- If the cell is marked as corresponding to a new item, a new item
|
||||
will be created for it. See [New items](./new-entities) for more
|
||||
details about how this works;
|
||||
- If the cell has reconciliation candidates but has not been matched
|
||||
to any of them, the edit will be skipped (even if there is only one
|
||||
candidate with a high reconciliation score);
|
||||
- If the cell is not reconciled or blank, the edit will be skipped.
|
||||
|
||||
Do not worry about the ordering of items in the schema or the order of
|
||||
your rows, as OpenRefine will rearrange your edits to optimize their
|
||||
upload. If your project makes edits on the same item across multiple
|
||||
rows, these edits will be merged together and performed in one edit. See
|
||||
[Uploading your changes](./uploading) about that.
|
||||
|
||||
## Terms {#terms}
|
||||
|
||||
**Terms** are the language-specific strings that you find at the top of
|
||||
Wikidata items: labels, descriptions and aliases. OpenRefine lets you
|
||||
edit these terms via the Wikidata schema.
|
||||
|
||||
### Languages {#languages}
|
||||
|
||||
Each term belongs to a particular language. Wikidata supports [hundreds
|
||||
of languages](https://www.wikidata.org/wiki/Help:Wikimedia_language_codes/lists/all), which
|
||||
are designated by language codes. For each term that you want to add to
|
||||
an item, you will need to specify the language for this term. There are
|
||||
two cases:
|
||||
|
||||
- Either the language is constant across your dataset: you know that
|
||||
all the names in a given column are spelled in the same language. In
|
||||
this case, type the name of the language in the input and select the
|
||||
language in the drop-down suggestion dialog. This will place the
|
||||
appropriate language code in the input.
|
||||
- Or the language varies across your dataset. In this case, you need
|
||||
to provide a column of Wikimedia language codes that indicates the
|
||||
language for each term that you want to add. Just drag and drop this
|
||||
column to the language field. If there are any invalid language
|
||||
codes in this column, the corresponding terms will be ignored.
|
||||
OpenRefine will translate any deprecated language codes to their
|
||||
preferred values silently.
|
||||
|
||||
### Labels {#labels}
|
||||
|
||||
This is because Wikidata items can have at most one label per language,
|
||||
so you need to choose whether to override any existing label (default
|
||||
behaviour before 3.2) or only insert your label if there is no such
|
||||
label in the given language (default behaviour starting from 3.2). When
|
||||
the content of the cell providing the label is blank, nothing will be
|
||||
changed (so, it is not possible to remove labels).
|
||||
|
||||
### Descriptions {#descriptions}
|
||||
|
||||
Descriptions work like labels: there is at most one description per
|
||||
language, and OpenRefine can override existing descriptions or leave
|
||||
them unchanged. It is not possible to remove descriptions either.
|
||||
|
||||
### Aliases {#aliases}
|
||||
|
||||
Aliases are added to the list of existing aliases in the given language.
|
||||
When adding an alias in a language where no label has been added yet,
|
||||
the alias is automatically promoted to a label for this language. It is
|
||||
not possible to remove aliases or to override any existing aliases.
|
||||
|
||||
## Statements {#statements}
|
||||
|
||||
You can add statements in the schema: this will generate new statements
|
||||
on the corresponding items. These statements will be merged with any
|
||||
existing statements on the actual Wikidata items and [this merging process depends on the upload medium](./uploading#Merging-strategies-for-statements).
|
||||
It is forecast to give more control over the merging strategy in the
|
||||
near future.
|
||||
|
||||
### Main values {#main-values}
|
||||
|
||||
Statements must have main values: \"novalue\" or \"somevalue\"
|
||||
statements are not supported yet. The main value of a statement is a
|
||||
data value whose type depends on the property used for the statement. If
|
||||
the main value cannot be evaluated (for instance because one of the
|
||||
cells it depends on is empty), then the entire statement will be
|
||||
skipped.
|
||||
|
||||
See the [data values](#data-values) section for more details
|
||||
about how to specify each type of data value and when they are skipped.
|
||||
|
||||
### Qualifiers {#qualifiers}
|
||||
|
||||
Qualifiers can be added on each statement. When their values are
|
||||
skipped, only the qualifier will be discarded: the rest of the statement
|
||||
will still be added.
|
||||
|
||||
### References {#references}
|
||||
|
||||
References can (and should) be added to back each statement. If values
|
||||
inside the reference are skipped, the corresponding part of the
|
||||
reference will be discarded but the reference will still be added
|
||||
(unless the reference becomes empty).
|
||||
|
||||
### Ranks {#ranks}
|
||||
|
||||
All statements ranks are set to **Normal**. It is currently not possible
|
||||
to set a different rank.
|
||||
|
||||
## Data values {#data-values}
|
||||
|
||||
Data values are the data that you can find as target of a statement (or
|
||||
qualifier, or part of a reference). Each property dictates a particular
|
||||
type of data value. In each case, OpenRefine uses a particular process
|
||||
to translate cell contents to a data value of the appropriate type. This
|
||||
section explains the process for all data types.
|
||||
|
||||
### Items {#items-1}
|
||||
|
||||
Items are evaluated in the same way as the subjects of items in the
|
||||
schema. They can be input directly using the auto-suggest service
|
||||
provided, or any column reconciled against Wikidata can be used. Refer to
|
||||
[the first Items section](#items) to see how they are
|
||||
evaluated.
|
||||
|
||||
### Strings and external identifiers {#strings-and-external-identifiers}
|
||||
|
||||
Bare strings and external identifiers can be input directly as constants
|
||||
(if they do not change across rows) or using any column. If a reconciled
|
||||
column is used for a string value, it is the value of the cell that is
|
||||
going to be used, not the name of the reconciled item (which is what
|
||||
OpenRefine displays). Values are skipped when the column is blank or
|
||||
null.
|
||||
|
||||
### Monolingual texts {#monolingual-texts}
|
||||
|
||||
Monolingual texts consist of two parts:
|
||||
|
||||
- the language: see [Languages](#languages) for their
|
||||
structure;
|
||||
- the value of the text: see [the section above](#strings-and-external-identifiers).
|
||||
|
||||
A monolingual text is skipped when any of its parts is skipped (that is,
|
||||
if the language or the text are invalid).
|
||||
|
||||
### Dates {#dates}
|
||||
|
||||
Dates are parsed from cell contents (or from any constant provided in
|
||||
the schema) and the precision of the date is inferred from its format.
|
||||
Here are the valid formats:
|
||||
|
||||
- `YYYYM`, such as `2001M` (millenium precision)
|
||||
- `YYYYC`, such as `1901C` (century precision)
|
||||
- `YYYYD`, such as `1981D` (decade precision)
|
||||
- `YYYY`, such as `1984` (year precision)
|
||||
- `YYYY-MM`, such as `2019-03` (month precision)
|
||||
- `YYYY-MM-DD`, such as `1897-08-14` (day precision)
|
||||
|
||||
Any value that does not match any of these formats will be ignored. All
|
||||
dates are represented in UTC, Gregorian calendar.
|
||||
|
||||
In OpenRefine 3.3, the following new formats have been introduced:
|
||||
|
||||
- `TODAY` returns today's date with day precision. This will be
|
||||
evaluated when performing the edits (or exporting to
|
||||
QuickStatements);
|
||||
- `YYYY-MM-DD_QID` can be used to specify a date in a particular
|
||||
calendar (such as the [proleptic Julian calendar (Q1985786)](https://www.wikidata.org/wiki/Q1985786).
|
||||
|
||||
In OpenRefine 3.5, the following new format has been introduced:
|
||||
|
||||
- `-234` represents the year 234 [BCE](https://en.wikipedia.org/wiki/Common_Era)
|
||||
|
||||
### Quantities {#quantities}
|
||||
|
||||
Quantities consist of two parts: the amount and the unit.
|
||||
|
||||
- the amount is mandatory and must be a string, such as `18,229.1020`.
|
||||
The precision that is displayed will be respected (the same number
|
||||
of trailing zeros will be shown in Wikidata). By default, no upper
|
||||
and lower bounds will be set. To define these, one needs to use the
|
||||
engineering notation, such as `3.45E+3`, which will be interpreted
|
||||
as `3,450±5`. As usual, the amount can be provided as a constant or
|
||||
as a column variable. In the latter case, the values in the column
|
||||
must be strings.
|
||||
- the unit is optional. It is an item, so it can be provided either
|
||||
with the auto-suggest dialog or as a reconciled column. It is
|
||||
important to note that if a reconciled column is used, any
|
||||
unreconciled cells will discard the entire quantity value. So a
|
||||
template for a quantity value is either always unit-less, or always
|
||||
has a unit.
|
||||
|
||||
### Globe coordinates {#globe-coordinates}
|
||||
|
||||
Geographic coordinates are specified as strings with the following
|
||||
formats, where all components are floating point numbers in degrees:
|
||||
|
||||
- `latitude,longitude` for a default precision of ten micro degrees
|
||||
(for instance:
|
||||
[`49.265278,4.028611`](https://tools.wmflabs.org/geohack/geohack.php?params=49.265277777778_N_4.0286111111111_E_globe:earth&language=en)
|
||||
can be used indicate the position of Reims, France.
|
||||
|
||||
|
||||
- `latitude,longitude,precision` when specifying an explicit precision
|
||||
(for instance: `49.265278,4.028611,0.1` can be used indicate the
|
||||
position of Reims within a tenth of a degree).
|
||||
|
||||
All globe coordinates are on Earth ([Q2](https://www.wikidata.org/wiki/Q2)).
|
||||
|
||||
If your coordinates are in a different format, such as
|
||||
`49° 15′ 55″ N, 4° 1′ 43″ E`, you will need to convert them to decimal
|
||||
format first.
|
||||
|
||||
### Media on Commons {#media-on-commons}
|
||||
|
||||
Media on Wikimedia Commons is treated like strings, whose values must
|
||||
exactly match filenames on Commons. These values are not checked during
|
||||
schema evaluations: if they are wrong, uploading the statements will
|
||||
fail.
|
||||
|
||||
Tabular data and Geoshapes must be prefixed with the `Data:` namespace.
|
||||
This is indicated by the placeholder in the field that appears when
|
||||
constructing the schema.
|
||||
|
||||
### Properties {#properties}
|
||||
|
||||
Properties are always constants: there is currently no way to reconcile
|
||||
a column against properties. They have to be selected with the
|
||||
auto-suggest dialog.
|
||||
|
||||
### Other data types {#other-data-types}
|
||||
|
||||
URLs, mathematical expressions and other textual datatypes are supported
|
||||
and treated as strings. At the time of writing, all datatypes supported
|
||||
by Wikidata are supported by OpenRefine.
|
||||
@ -1,48 +0,0 @@
|
||||
---
|
||||
id: uploading
|
||||
title: Uploading edits to Wikibase
|
||||
sidebar_label: Uploading edits
|
||||
---
|
||||
|
||||
This page explains how to upload your edits to the target Wikibase. It assumes you already have a created a Wikibase schema in your OpenRefine project.
|
||||
|
||||
## Uploading with OpenRefine {#uploading-with-openrefine}
|
||||
|
||||
* Click <span class="menuItems">Wikidata</span> → <span class="menuItems">Upload edits to Wikidata</span>.
|
||||
* Log in with your personal account or your bot account depending on which account you want to use to make the edits. It is a good practice to use a [bot password](https://www.mediawiki.org/wiki/Manual:Bot_passwords).
|
||||
* Supply a meaningful edit summary. This is especially important because OpenRefine condenses all your changes on the same item as one edit: if you are making multiple changes, the edit summary generated by Wikibase will not indicate clearly what sort of change you made. If you are making atomic changes, such as adding a single alias or statement, the automatic edit summaries will be more meaningful. If supported by your Wikibase instance, OpenRefine will append a link to the [EditGroups](https://editgroups.toolforge.org/) tool, which lets you track and analyze your edit batch after upload.
|
||||
* Click <span class="buttonLabels">Perform edits</span> and wait for the operation to complete. You can watch your edits being made by checking your wiki contributions or the EditGroups tool.
|
||||
|
||||
Because performing edits in OpenRefine counts as an operation, you can extract this operation and reapply it to other projects. If you do so, you should also include the operation that saves the schema (only the last one is required), and make sure that the column names in the schema match those of the OpenRefine project where you are applying the operation.
|
||||
|
||||
## Uploading with QuickStatements {#uploading-with-quickstatements}
|
||||
|
||||
This requires that the Wikibase site has an associated [QuickStatements](https://meta.wikimedia.org/wiki/QuickStatements) tool.
|
||||
|
||||
* Click <span class="menuItems">Wikibase</span> → <span class="menuItems">Export to QuickStatements</span> and copy the contents of the file;
|
||||
* Go to QuickStatements (for Wikidata it can be found at https://quickstatements.toolforge.org/) and login to authorize the tool to use your account;
|
||||
* Click <span class="buttonLabels">Version 1 format</span>;
|
||||
* Paste the generated changes in the text area;
|
||||
* Perform the edits with <span class="buttonLabels">Run</span> or <span class="buttonLabels">Run in background</span>.
|
||||
|
||||
## Notable differences between the two methods {#notable-differences-between-the-two-methods}
|
||||
|
||||
### Merging strategy for statements {#merging-strategy-for-statements}
|
||||
|
||||
OpenRefine checks for existing statements which match not only the property and the target value, but also the qualifiers. On the other hand, QuickStatements ignores qualifiers when matching statements.
|
||||
Both merging strategies can be useful depending on the properties. It is forecast to let the user configure the matching method in OpenRefine.
|
||||
|
||||
If references are provided, both tools merge references in matching statements.
|
||||
|
||||
### New item creation {#new-item-creation}
|
||||
|
||||
OpenRefine supports creating new items with arbitrary relations between them.
|
||||
|
||||
QuickStatements supports creating new items with the <code>CREATE</code> instruction, and subsequent instructions can use the <code>LAST</code> placeholder to use the Qid of the last created item. When generating QuickStatements instructions, OpenRefine reorders your edits so that this syntax can be used. In rare cases, such as when a statement links two newly-created items, it is impossible to use QuickStatements to perform the edit. In this case, no QuickStatements script will be generated.
|
||||
|
||||
### Speed and number of edits {#speed-and-number-of-edits}
|
||||
|
||||
OpenRefine generally performs one edit per item touched by an edit batch and at most two in general (in the case where new items contain links between them). This was chosen to minimize server load, speed up the upload and keep item histories compact. The downside is that the edit summaries can be less meaningful - it is therefore important that users supply informative summaries when uploading their batches. OpenRefine asymptotically edits at the rate of 60 edits per minute (so, usually 60 items per minute). The first edits are made more quickly, which is convenient for small batches.
|
||||
|
||||
QuickStatements performs incremental edits (for instance, when adding a statement with a qualifier and a reference, it will make three edits). That generally means lower speed, but more explicit item histories.
|
||||
|
||||
@ -1,283 +0,0 @@
|
||||
---
|
||||
id: architecture
|
||||
title: Architecture
|
||||
sidebar_label: Architecture
|
||||
---
|
||||
|
||||
OpenRefine is a web application, but is designed to be run locally on your own machine. The server-side maintains states of the data (undo/redo history, long-running processes, etc.) while the client-side maintains states of the user interface (facets and their selections, view pagination, etc.). The client-side makes GET and POST ajax calls to cause changes to the data and to fetch data and data-related states from the server-side.
|
||||
|
||||
This architecture provides a good separation of concerns (data vs. UI); allows the use of familiar web technologies (HTML, CSS, Javascript) to implement user interface features; and enables the server side to be called by third-party software through standard GET and POST operations.
|
||||
|
||||
## Technology stack {#technology-stack}
|
||||
|
||||
The server-side part of OpenRefine is implemented in Java as one single servlet which is executed by the [Jetty](http://jetty.codehaus.org/jetty/) web server + servlet container. The use of Java strikes a balance between performance and portability across operating systems (there is very little OS-specific code and has mostly to do with starting the application).
|
||||
|
||||
OpenRefine has no database. It uses its own in-memory data-store that is built up-front to be optimized for the operations required by faceted browsing and infinite undo.
|
||||
|
||||
The client-side part of OpenRefine is implemented in HTML, CSS and Javascript and uses the following libraries:
|
||||
* [jQuery](http://jquery.com/)
|
||||
* [jQueryUI](http:jqueryui.com/)
|
||||
* [Recurser jquery-i18n](https://github.com/recurser/jquery-i18n)
|
||||
|
||||
The functional extensibility of OpenRefine is provided by a fork of the [SIMILE Butterfly](https://github.com/OpenRefine/simile-butterfly) modular web application framework.
|
||||
|
||||
Several projects provide the functionality to read and write custom format files (POI, opencsv, JENA, marc4j).
|
||||
|
||||
String clustering is provided by the [SIMILE Vicino](http://code.google.com/p/simile-vicino/) project.
|
||||
|
||||
OAuth functionality is provided by the [Signpost](https://github.com/mttkay/signpost) project.
|
||||
|
||||
## Server-side architecture {#server-side-architecture}
|
||||
|
||||
OpenRefine's server-side is written entirely in Java (`main/src/`) and its entry point is the Java servlet `com.google.refine.RefineServlet`. By default, the servlet is hosted in the lightweight Jetty web server instantiated by `server/src/com.google.refine.Refine`. Note that the server class itself is under `server/src/`, not `main/src/`; this separation leaves the possibility of hosting `RefineServlet` in a different servlet container.
|
||||
|
||||
The web server configuration is in `main/webapp/WEB-INF/web.xml`; that's where `RefineServlet` is hooked up. `RefineServlet` itself is simple: it just reacts to requests from the client-side by routing them to the right `Command` class in the packages `com.google.refine.commands.**`.
|
||||
|
||||
As mentioned before, the server-side maintains states of the data, and the primary class involved is `com.google.refine.ProjectManager`.
|
||||
|
||||
### Projects {#projects}
|
||||
|
||||
In OpenRefine there's the concept of a workspace similar to that in Eclipse. When you run OpenRefine it manages projects within a single workspace, and the workspace is embodied in a file directory with sub-directories. The default workspace directories are listed in the [FAQs](https://github.com/OpenRefine/OpenRefine/wiki/FAQ-Where-Is-Data-Stored). You can get OpenRefine to use a different directory by specifying a -d parameter at the command line.
|
||||
|
||||
The class `ProjectManager` is what manages the workspace. It keeps in memory the metadata of every project (in the class `ProjectMetadata`). This metadata includes the project's name and last modified date, and any other information necessary to present and let the user interact with the project as a whole. Only when the user decides to look at the project's data would `ProjectManager` load the project's actual data. The separation of project metadata and data is to minimize the amount of stuff loaded into memory.
|
||||
|
||||
A project's _actual_ data includes the columns, rows, cells, reconciliation records, and history entries.
|
||||
|
||||
A project is loaded into memory when it needs to be displayed or modified, and it remains in memory until 1 hour after the last time it gets modified. Periodically the project manager tries to save modified projects, and it saves as many modified projects as possible within 30 seconds.
|
||||
|
||||
### Data Model {#data-model}
|
||||
|
||||
A project's data consists of
|
||||
|
||||
- _raw data_: a list of rows, each row consisting of a list of cells
|
||||
- _models_ on top of that raw data that give high-level presentation or interpretation of that data. This design lets the same raw data be viewed in different ways by different models, and let the models be changed without costly changes to the raw data.
|
||||
|
||||
#### Column Model {#column-model}
|
||||
|
||||
Cells in rows are not named and can only be addressed by their list position indices. So, a _column model_ is needed to give a name to each list position. The column model also stores other metadata for each column, including the type that cells in the column have been reconciled to and the overall reconciliation statistics of those cells.
|
||||
|
||||
Each column also acts as a cache for data computed from the raw data related to that column.
|
||||
|
||||
Columns in the column model can be removed and re-ordered without changing the raw data--the cells in the rows. This makes column removal and ordering operations really quick.
|
||||
|
||||
##### Column Groups {#column-groups}
|
||||
|
||||
Consider the following data:
|
||||
|
||||

|
||||
|
||||
Although the data is in a grid, we humans can understand that it is a tree. First of all, all rows contain data ultimately linked to the movie Austin Powers, although only one row contains the text "Austin Powers" in the "movie title" column. We also know that "USA" and "Germany" are not related to Elizabeth Hurley and Mike Myers respectively (say, as their nationality), but rather, "USA" and "Germany" are related to the movie (where it was released). We know that Mike Myers played both the character "Austin Powers" and the character "Dr. Evil"; and for the latter he received 2 awards. We humans can understand how to interpret the grid as a tree based on its visual layout as well as some knowledge we have about the movie domain but is not encoded in the table.
|
||||
|
||||
OpenRefine can capture our knowledge of this transformation from grid to tree using _column groups_, also stored in the column model. Each column group illustrated as a blue bracket above specifies which columns are grouped together, as well as which of those columns is the key column in that group (blue triangle). One column group can span over columns grouped by another column group, and in this way, column groups form a hierarchy determined by which column group envelopes another. This hierarchy of column groups allows the 2-dimensional (grid-shaped) table of rows and cells to be interpreted as a list of hierarchical (tree-shaped) data records.
|
||||
|
||||
Blank cells play a very important role. The blank cell in a key column of a row (e.g., cell "character" on row 4) makes that row (row 4) _depend_ on the first preceding row with that column filled in (row 3). This means that "Best Comedy Perf" on row 4 applies to "Dr. Evil" on row 3. Row 3 is said to be a _context row_ for row 4. Similarly, since rows 2 - 6 all have blank cells in the first column, they all depend on row 1, and all their data ultimately applies to the movie Austin Powers. Row 1 depends on no other row and is said to be a _record row_. Rows 1 - 6 together form one _record_.
|
||||
|
||||
Currently (as of 12th December 2017) only the XML and JSON importers create column groups, and while the data table view does display column groups but it doesn't support modifying them.
|
||||
|
||||
### Changes, History, Processes, and Operations {#changes-history-processes-and-operations}
|
||||
|
||||
All changes to the project's data are tracked (N.B. this does not include changes to a project's metadata - such as the project name.)
|
||||
|
||||
Changes are stored as `com.google.refine.history.Change` objects. `com.google.refine.history.Change` is an interface, and implementing classes are in `com.google.refine.model.changes.**`. Each change object stores enough data to modify the project's data when its `apply()` method is called, and enough data to revert its effect when its `revert()` method is called. It's only supposed to _store_ data, not to actually _compute_ the change. In this way, it's like a .diff patch file for a code base.
|
||||
|
||||
Some change objects can be huge, as huge as the project itself. So change objects are not kept in memory except when they are to be applied or reverted. However, since we still need to show the user some information about changes (as displayed in the History panel in the UI), we keep metadata of changes separate from the change objects. For each change object there is one corresponding `com.google.refine.history.HistoryEntry` for storing its metadata, such as the change's human-friendly description and timestamp.
|
||||
|
||||
Each project has a `com.google.refine.history.History` object that contains an ordered list of all `HistoryEntry` objects storing metadata for all changes that have been done since after the project was created. Actually, there are 2 ordered lists: one for done changes that can be reverted (undone), an done for undone changes that can be re-applied (redone). Changes must be done or redone in their exact orders in these lists because each change makes certain assumptions about the state of the project before and after it is applied. As changes cannot be undone/redone out of order, when one change fails to revert, it blocks the whole history from being reverted to any state preceding that change (as happened in [Issue #2](https://github.com/OpenRefine/OpenRefine/issues/2)).
|
||||
|
||||
As mentioned before, a change contains only the diff and does not actually compute that diff. The computation is performed by a `com.google.refine.process.Process` object--every change object is created by a process object. A process can be immediate, producing its change object synchronously within a very short period of time (e.g., starring one row); or a process can be long-running, producing its change object after a long time and a lot of computation, including network calls (e.g., reconciling a column).
|
||||
|
||||
As the user interacts with the UI on the client-side, their interactions trigger ajax calls to the server-side. Some calls are meant to modify the project. Those are handled by commands that instantiates processes. Processes are queued in a first-in-first-out basis. The first-in process gets run and until it is done all the other processes are stuck in the queue.
|
||||
|
||||
A process can effect a change in one thing in the project (e.g., edit one particular cell, star one particular row), or a process can effect changes in _potentially_ many things in the project (e.g., edit zero or more cells sharing the same content, starring all rows filtered by some facets). The latter kind of process is generalizable: it is meaningful to apply them on another similar project. Such a process is associated with an _abstract operation_ `com.google.refine.model.AbstractOperation` that encodes the information necessary to create another instance of that process, but potentially for a different project. When you click "extract" in the History panel, these abstract operations are called to serialize their information to JSON; and when you click "apply" in the History panel, the JSON you paste in is used to re-construct these abstract operations, which in turn create processes, which get run sequentially in a queue to generate change object and history entry pairs.
|
||||
|
||||
In summary,
|
||||
|
||||
- change objects store diffs
|
||||
- history entries store metadata of change objects
|
||||
- processes compute diffs and create change object and history entry pairs
|
||||
- some processes are long-running and some are immediate; processes are run sequentially in a queue
|
||||
- generalizable processes can be re-constructed from abstract operations
|
||||
|
||||
## Client-side architecture {#client-side-architecture}
|
||||
The client-side part of OpenRefine is implemented in HTML, CSS and Javascript and uses the following Javascript libraries:
|
||||
* [jQuery](http://jquery.com/)
|
||||
* [jQueryUI](http:jqueryui.com/)
|
||||
* [Recurser jquery-i18n](https://github.com/recurser/jquery-i18n)
|
||||
|
||||
### Importing architecture {#importing-architecture}
|
||||
|
||||
OpenRefine has a sophisticated architecture for accommodating a diverse and extensible set of importable file formats and work flows. The formats range from simple CSV, TSV to fixed-width fields to line-based records to hierarchical XML and JSON. The work flows allow the user to preview and tweak many different import settings before creating the project. In some cases, such as XML and JSON, the user also has to select which elements in the data file to import. Additionally, a data file can also be an archive file (e.g., .zip) that contains many files inside; the user can select which of those files to import. Finally, extensions to OpenRefine can inject functionalities into any part of this architecture.
|
||||
|
||||
### The Index Page and Action Areas {#the-index-page-and-action-areas}
|
||||
|
||||
The opening screen of OpenRefine is implemented by the file refine/main/webapp/modules/core/index.vt and will be referred to here as the index page. Its default implementation contains 3 finger tabs labeled Create Project, Open Project, and Import Project. Each tab selects an "action area". The 3 default action areas are for, obviously, creating a new project, opening an existing project, and importing a project .tar file.
|
||||
|
||||
Extensions can add more action areas in Javascript. For example, this is how the Create Project action area is added (refine/main/webapp/modules/core/scripts/index/create-project-ui.js):
|
||||
|
||||
```javascript
|
||||
Refine.actionAreas.push({
|
||||
id: "create-project",
|
||||
label: "Create Project",
|
||||
uiClass: Refine.CreateProjectUI
|
||||
});
|
||||
```
|
||||
|
||||
The UI class is a constructor function that takes one argument, a jQuery-wrapped HTML element where the tab body of the action area should be rendered.
|
||||
|
||||
If your extension requires a very unique importing work flow, or a very novel feature that should be exposed on the index page, then add a new action area. Otherwise, try to use the existing work flows as much as possible.
|
||||
|
||||
### The Create Project Action Area {#the-create-project-action-area}
|
||||
|
||||
The Create Project action area is itself extensible. Initially, it embeds a set of finger tabs corresponding to a variety of "source selection UIs": you can select a source of data by specifying a file on your computer, or you can specify the URL to a publicly accessible data file or data feed, or you can paste in from the clipboard a chunk of data.
|
||||
|
||||
There are actually 3 points of extension in the Create Project action area, and the first is invisible.
|
||||
|
||||
#### Importing Controllers {#importing-controllers}
|
||||
|
||||
The Create Project action area manages a list of "importing controllers". Each controller follows a particular work flow (in UI terms, think "wizard"). Refine comes with a "default importing controller" (refine/main/webapp/modules/core/scripts/index/default-importing-controller/controller.js) and its work flow assumes that the data can be retrieved and cached in whole before getting processed in order to generate a preview for the user to inspect. (If the data cannot be retrieved and cached in whole before previewing, then another importing controller is needed.)
|
||||
|
||||
An importing controller is just programming logic, but it can manifest itself visually by registering one or more data source UIs and one or more custom panels in the Create Project action area. The default importing controller registers 3 such custom panels, which act like pages of a wizard.
|
||||
|
||||
An extension can register any number of importing controller. Each controller has a client-side part and a server-side part. Its client-side part is just a constructor function that takes an object representing the Create Project action area (usually named `createProjectUI`). The controller (client-side) is expected to use that object to register data source UIs and/or create custom panels. The controller is not expected to have any particular interface method. The default importing controller's client-side code looks like this (refine/main/webapp/modules/core/scripts/index/default-importing-controller/controller.js):
|
||||
|
||||
```javascript
|
||||
Refine.DefaultImportingController = function(createProjectUI) {
|
||||
this._createProjectUI = createProjectUI; // save a reference to the create project action area
|
||||
|
||||
this._progressPanel = createProjectUI.addCustomPanel(); // create a custom panel
|
||||
this._progressPanel.html('...'); // render the custom panel
|
||||
... do other stuff ...
|
||||
};
|
||||
Refine.CreateProjectUI.controllers.push(Refine.DefaultImportingController); // register the controller
|
||||
```
|
||||
|
||||
We will cover the server-side code below.
|
||||
|
||||
#### Data Source Selection UIs {#data-source-selection-uis}
|
||||
|
||||
Data source selection UIs are another point of extensibility in the Create Project action area. As mentioned previously, by default there are 3 data source UIs. Those are added by the default importing controller.
|
||||
|
||||
Extensions can also add their own data source UIs. A data source selection UI object can be registered like so
|
||||
|
||||
```javascript
|
||||
createProjectUI.addSourceSelectionUI({
|
||||
label: "This Computer",
|
||||
id: "local-computer-source",
|
||||
ui: theDataSourceSelectionUIObject
|
||||
});
|
||||
```
|
||||
|
||||
`theDataSourceSelectionUIObject` is an object that has the following member methods:
|
||||
|
||||
- `attachUI(bodyDiv)`
|
||||
- `focus()`
|
||||
|
||||
If you want to install a data source selection UI that is managed by the default importing controller, then register its UI class with the default importing controller, like so (refine/main/webapp/modules/core/scripts/index/default-importing-sources/sources.js):
|
||||
|
||||
```javascript
|
||||
Refine.DefaultImportingController.sources.push({
|
||||
"label": "This Computer",
|
||||
"id": "upload",
|
||||
"uiClass": ThisComputerImportingSourceUI
|
||||
});
|
||||
```
|
||||
|
||||
The default importing controller will assume that the `uiClass` field is a constructor function and call it with one argument--the controller object itself. That constructor function should save the controller object for later use. More specifically, for data source UIs that use the default importing controller, they can call the controller to kickstart the process that retrieves and caches the data to import:
|
||||
|
||||
```javascript
|
||||
controller.startImportJob(form, "... status message ...");
|
||||
```
|
||||
|
||||
The argument `form` is a jQuery-wrapped FORM element that will get submitted to the server side at the command /command/core/create-importing-job. That command and the default importing controller will take care of uploading or downloading the data, caching it, updating the client side's progress display, and then showing the next importing step when the data is fully cached.
|
||||
|
||||
See refine/main/webapp/modules/core/scripts/index/default-importing-sources/sources.js for examples of such source selection UIs. While we write about source selection UIs managed by the default importing controller here, chances are your own extension will not be adding such a new source selection UI. Your extension probably adds with a new importing controller as well as a new source selection UI that work together.
|
||||
|
||||
#### File Selection Panel {#file-selection-panel}
|
||||
Documentation not currently available
|
||||
|
||||
#### Parsing UI Panel {#parsing-ui-panel}
|
||||
Documentation not currently available
|
||||
|
||||
### Server-side Components {#server-side-components}
|
||||
|
||||
#### ImportingController {#importingcontroller}
|
||||
Documentation not currently available
|
||||
|
||||
#### UrlRewriter {#urlrewriter}
|
||||
Documentation not currently available
|
||||
|
||||
#### FormatGuesser {#formatguesser}
|
||||
Documentation not currently available
|
||||
|
||||
#### ImportingParser {#importingparser}
|
||||
Documentation not currently available
|
||||
|
||||
|
||||
## Faceted browsing architecture {#faceted-browsing-architecture}
|
||||
|
||||
Faceted browsing support is core to OpenRefine as it is the primary and only mechanism for filtering to a subset of rows on which to do something _en masse_ (ie in bulk). Without faceted browsing or an equivalent querying/browsing mechanism, you can only change one thing at a time (one cell or row) or else change everything all at once; both kinds of editing are practically useless when dealing with large data sets.
|
||||
|
||||
In OpenRefine, different components of the code need to know which rows to process from the faceted browsing state (how the facets are constrained). For example, when the user applies some facet selections and then exports the data, the exporter serializes only the matching rows, not all rows in the project. Thus, faceted browsing isn't only hooked up to the data view for displaying data to the user, but it is also hooked up to almost all other parts of the system.
|
||||
|
||||
### Engine Configuration {#engine-configuration}
|
||||
|
||||
As OpenRefine is a web app, there might be several browser windows opened on the same project, each in a different faceted browsing state. It is best to maintain the faceted browsing state in each browser window while keeping the server side completely stateless with regard to faceted browsing. Whenever the client-side needs something done by the server, it transfers the entire faceted browsing state over to the server-side. The faceted browsing state behaves much like the `WHERE` clause in a SQL query, telling the server-side how to select the rows to process.
|
||||
|
||||
In fact, it is best to think of the faceted browsing state as just a database query much like a SQL query. It can be passed around the whole system, to any component needing to know which rows to process. It is serialized into JSON to pass between the client-side and the server side, or to save in an abstract operation's specification. The job of the faceted browsing subsystem on the client-side is to let the user interactively modify this "faceted browsing query", and the job of the faceted browsing subsystem on the server side is to resolve that query.
|
||||
|
||||
In the code, the faceted browsing state, or faceted browsing query, is actually called the *engine configuration* or *engine config* for short. It consists mostly of an array facet configurations. For each facet, it stores the name of the column on which the facet is based (or an empty string if there is no base column). Each type of facet has different configuration. Text search facets have queries and flags for case-sensitivity mode and regular expression mode. Text facets (aka list facets) and numeric range facets have expressions. Each list facet also has an array of selected choices, an invert flag, and flags for whether blank and error cells are selected. Each numeric range facet has, among other things, a "from" and a "to" values. If you trace the AJAX calls, you'd see the engine configs being shuttled, e.g.,
|
||||
|
||||
```json
|
||||
{
|
||||
"facets" : [
|
||||
{
|
||||
"type": "text",
|
||||
"name": "Shrt_Desc",
|
||||
"columnName": "Shrt_Desc",
|
||||
"mode": "text",
|
||||
"caseSensitive": false,
|
||||
"query": "cheese"
|
||||
},
|
||||
{
|
||||
"type": "list",
|
||||
"name": "Shrt_Desc",
|
||||
"columnName": "Shrt_Desc",
|
||||
"expression": "grel:value.toLowercase().split(\",\")",
|
||||
"omitBlank": false,
|
||||
"omitError": false,
|
||||
"selection": [],
|
||||
"selectBlank":false,
|
||||
"selectError":false,
|
||||
"invert":false
|
||||
},
|
||||
{
|
||||
"type": "range",
|
||||
"name": "Water",
|
||||
"expression": "value",
|
||||
"columnName": "Water",
|
||||
"selectNumeric": true,
|
||||
"selectNonNumeric": true,
|
||||
"selectBlank": true,
|
||||
"selectError": true,
|
||||
"from": 0,
|
||||
"to": 53
|
||||
}
|
||||
],
|
||||
"includeDependent": false
|
||||
}
|
||||
```
|
||||
|
||||
### Server-Side Subsystem {#server-side-subsystem}
|
||||
|
||||
From an engine configuration like the one above, the server-side faceted browsing subsystem is capable of producing:
|
||||
|
||||
- an iteration over the rows matching the facets' constraints
|
||||
- information on how to render the facets (e.g., choice and count pairs for a list facet, histogram for a numeric range facet)
|
||||
|
||||
When the engine config JSON arrives in an HTTP request on the server-side, a `com.google.refine.browsing.Engine` object is constructed and initialized with that JSON. It in turns constructs zero or more `com.google.refine.browsing.facets.Facet` objects. Then for each facet, the engine calls its `getRowFilter()` method, which returns `null` if the facet isn't constrained in anyway, or a `com.google.refine.browsing.filters.RowFilter` object. Then, to when iterating over a project's rows, the engine calls on all row filters' `filterRow()` method. If and only if all row filters return `true` the row is considered to match the facets' constraints. How each row filter works depends on the corresponding type of facet.
|
||||
|
||||
To produce information on how to render a particular facet in the UI, the engine follows the same procedure described in the previous except it skips over the facet in question. In other words, it produces an iteration over all rows constrained by the other facets. Then it feeds that iteration to the facet in question by calling the facet's `computeChoices()` method. This gives the method a chance to compute the rendering information for its UI counterpart on the client-side. When all facets have been given a chance to compute their rendering information, the engine calls all facets to serialize their information as JSON and returns the JSON to the client-side. Only one HTTP call is needed to compute all facets.
|
||||
|
||||
### Client-side subsystem {#client-side-subsystem}
|
||||
|
||||
On the client-side there is also an engine object (implemented in Javascript rather than Java) and zero or more facet objects (also in Javascript, obviously). The engine is responsible for distributing the rendering information computed on the server-side to the right facets, and when the user interacts with a facet, the facet tells the engine to update the whole UI. To do so, the engine gathers the configuration of each facet and composes the whole engine config as a single JSON object. Two separate AJAX calls are made with that engine config, one to retrieve the rows to render, and one to re-compute the rendering information for the facets because changing one facet does affect all the other facets.
|
||||
@ -1,276 +0,0 @@
|
||||
---
|
||||
id: build-test-run
|
||||
title: How to build, test and run
|
||||
sidebar_label: How to build, test and run
|
||||
---
|
||||
|
||||
import useBaseUrl from '@docusaurus/useBaseUrl';
|
||||
|
||||
|
||||
You will need:
|
||||
* [OpenRefine source code](https://github.com/OpenRefine/OpenRefine)
|
||||
* [Java JDK](http://java.sun.com/javase/downloads/index.jsp) (Get [OpenJDK from here](https://jdk.java.net/15/).)
|
||||
* [Apache Maven](https://maven.apache.org) (OPTIONAL)
|
||||
* A Unix/Linux shell environment OR the Windows command line
|
||||
|
||||
From the top level directory in the OpenRefine application you can build, test and run OpenRefine using the `./refine` shell script (if you are working in a \*nix shell), or using the `refine.bat` script from the Windows command line. Note that the `refine.bat` on Windows only supports a subset of the functionality, supported by the `refine` shell script. The example commands below are using the `./refine` shell script, and you will need to use `refine.bat` if you are working from the Windows command line.
|
||||
|
||||
### Get OpenRefine source code
|
||||
|
||||
With Git installed, use the `git clone` command to download the [project's repo](https://github.com/OpenRefine/OpenRefine) to a directory of your choice.
|
||||
|
||||
### Set up JDK {#set-up-jdk}
|
||||
|
||||
You must [install JDK](https://jdk.java.net/15/) and set the JAVA_HOME environment variable (please ensure it points to the JDK, and not the JRE).
|
||||
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
<Tabs
|
||||
groupId="operating-systems"
|
||||
defaultValue="win"
|
||||
values={[
|
||||
{label: 'Windows', value: 'win'},
|
||||
{label: 'Mac', value: 'mac'},
|
||||
{label: 'Linux', value: 'linux'}
|
||||
]
|
||||
}>
|
||||
|
||||
<TabItem value="win">
|
||||
|
||||
1. On Windows 10, click the Start Menu button, type `env`, and look at the search results. Click <span class="buttonLabels">Edit the system environment variables</span>. (If you are using an earlier version of Windows, use the “Search” or “Search programs and files” box in the Start Menu.)
|
||||
|
||||

|
||||
|
||||
2. Click <span class="buttonLabels">Environment Variables…</span> at the bottom of the <span class="tabLabels">Advanced</span> window.
|
||||
3. In the <span class="tabLabels">Environment Variables</span> window that appears, click <span class="buttonLabels">New…</span> and create a variable with the key `JAVA_HOME`. You can set the variable for only your user account, as in the screenshot below, or set it as a system variable - it will work either way.
|
||||
|
||||

|
||||
|
||||
4. Set the `Value` to the folder where you installed JDK, in the format `D:\Programs\OpenJDK`. You can locate this folder with the <span class="buttonLabels">Browse directory...</span> button.
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="mac">
|
||||
|
||||
First, find where Java is on your computer with this command:
|
||||
|
||||
```
|
||||
which java
|
||||
```
|
||||
|
||||
Check the environment variable `JAVA_HOME` with:
|
||||
|
||||
```
|
||||
$JAVA_HOME/bin/java --version
|
||||
```
|
||||
|
||||
To set the environment variable for the current Java version of your MacOS:
|
||||
|
||||
```
|
||||
export JAVA_HOME="$(/usr/libexec/java_home)"
|
||||
```
|
||||
|
||||
Or, for Java 13.x:
|
||||
|
||||
```
|
||||
export JAVA_HOME="$(/usr/libexec/java_home -v 13)"
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
|
||||
<TabItem value="linux">
|
||||
|
||||
##### With the terminal {#with-the-terminal}
|
||||
|
||||
Enter the following:
|
||||
|
||||
```
|
||||
sudo apt install default-jre
|
||||
```
|
||||
|
||||
This probably won’t install the latest JDK package available on the Java website, but it is faster and more straightforward. (At the time of writing, it installs OpenJDK 11.0.7.)
|
||||
|
||||
##### Manually {#manually}
|
||||
|
||||
First, [extract the JDK package](https://openjdk.java.net/install/) to the new directory `usr/lib/jvm`:
|
||||
|
||||
```
|
||||
sudo mkdir -p /usr/lib/jvm
|
||||
sudo tar -x -C /usr/lib/jvm -f /tmp/openjdk-14.0.1_linux-x64_bin.tar.gz
|
||||
```
|
||||
|
||||
Then, navigate to this folder and confirm the final path (in this case, `usr/lib/jvm/jdk-14.0.1`). Open a terminal and type
|
||||
|
||||
```
|
||||
sudo gedit /etc/profile
|
||||
```
|
||||
|
||||
In the text window that opens, insert the following lines at the end of the `profile` file, using the path above:
|
||||
|
||||
```
|
||||
JAVA_HOME=/usr/lib/jvm/jdk-14.0.1
|
||||
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
|
||||
export JAVA_HOME
|
||||
export PATH
|
||||
```
|
||||
|
||||
Note: OpenRefine on Linux currently supports jdk versions 8 to 15. Reference: [Issue 4106](https://github.com/OpenRefine/OpenRefine/issues/4106).
|
||||
|
||||
Save and close the file. When you are back in the terminal, type
|
||||
|
||||
```
|
||||
source /etc/environment
|
||||
```
|
||||
|
||||
Exit the terminal and restart your system. You can then check that `JAVA_HOME` is set properly by opening another terminal and typing
|
||||
```
|
||||
echo $JAVA_HOME
|
||||
```
|
||||
|
||||
It should show the path you set above.
|
||||
|
||||
</TabItem>
|
||||
|
||||
</Tabs>
|
||||
|
||||
---
|
||||
|
||||
|
||||
|
||||
### Maven (Optional) {#maven-optional}
|
||||
OpenRefine's build script will download Maven for you and use it, if not found already locally installed.
|
||||
|
||||
If you will be using your Maven installation instead of OpenRefine's build script download installation, then set the `MVN_HOME` environment variable. You may need to reboot your machine after setting these environment variables. If you receive a message `Could not find the main class: com.google.refine.Refine. Program will exit.` it is likely `JAVA_HOME` is not set correctly.
|
||||
|
||||
Ensure that you set your `MAVEN_HOME` environment variable, for example:
|
||||
|
||||
```shell
|
||||
MAVEN_HOME=E:\Downloads\apache-maven-3.5.4-bin\apache-maven-3.5.4\
|
||||
```
|
||||
|
||||
NOTE: You can use Maven commands directly, but running some goals in isolation might fail (try adding the `compile test-compile` goals in your invocation if that is the case).
|
||||
|
||||
### Building {#building}
|
||||
|
||||
To see what functions are supported by OpenRefine's build system, type
|
||||
```shell
|
||||
./refine -h
|
||||
```
|
||||
|
||||
To build the OpenRefine application from source type:
|
||||
```shell
|
||||
./refine clean
|
||||
./refine build
|
||||
```
|
||||
|
||||
### Testing {#testing}
|
||||
Since OpenRefine is composed of two parts, a server and a in-browser UI, the testing system reflects that:
|
||||
|
||||
* on the server side, it's powered by [TestNG](http://testng.org/) and the unit tests are written in Java;
|
||||
* on the client side, we use [Cypress](https://www.cypress.io/) and the tests are written in Javascript
|
||||
|
||||
To run all tests, use:
|
||||
```shell
|
||||
./refine test
|
||||
```
|
||||
**this option is not available when using refine.bat**
|
||||
|
||||
|
||||
If you want to run only the server side portion of the tests, use:
|
||||
```shell
|
||||
./refine server_test
|
||||
```
|
||||
|
||||
If you are running the UI tests for the first time, [you must go through the installation process.](functional-tests)
|
||||
If you want to run only the client side portion of the tests, use:
|
||||
```shell
|
||||
./refine ui_test chrome
|
||||
```
|
||||
|
||||
## Running {#running}
|
||||
To run OpenRefine from the command line (assuming you have been able to build from the source code successfully)
|
||||
```shell
|
||||
./refine
|
||||
```
|
||||
By default, OpenRefine will use [refine.ini](https://github.com/OpenRefine/OpenRefine/blob/master/refine.ini) for configuration. You can copy it and rename it to `refine-dev.ini`, which will be used for configuration instead. `refine-dev.ini` won't be tracked by Git, so feel free to put your custom configurations into it.
|
||||
|
||||
## Building Distributions (Kits) {#building-distributions-kits}
|
||||
|
||||
The Refine build system uses Apache Ant to automate the creation of the installation packages for the different operating systems. The packages are currently optimized to run on Mac OS X which is the only platform capable of creating the packages for all three OS that we support.
|
||||
|
||||
To build the distributions type
|
||||
|
||||
```shell
|
||||
./refine dist <version>
|
||||
```
|
||||
where 'version' is the release version.
|
||||
|
||||
## Building, Testing and Running OpenRefine from Eclipse {#building-testing-and-running-openrefine-from-eclipse}
|
||||
OpenRefine' source comes with Maven configuration files which are recognized by [Eclipse](http://www.eclipse.org/) if the Eclipse Maven plugin (m2e) is installed.
|
||||
|
||||
At the command line, go to a directory **not** under your Eclipse workspace directory and check out the source:
|
||||
|
||||
```shell
|
||||
git clone https://github.com/OpenRefine/OpenRefine.git
|
||||
```
|
||||
|
||||
In Eclipse, invoke the `Import...` command and select `Existing Maven Projects`.
|
||||
|
||||

|
||||
|
||||
Choose the root directory of your clone of the repository. You get to choose which modules of the project will be imported. You can safely leave out the `packaging` module which is only used to generate the Linux, Windows and MacOS distributions.
|
||||
|
||||
<img alt="Screenshot of Select maven projects to import" src={useBaseUrl('img/eclipse-import-maven-project-2.png')} />
|
||||
|
||||
To run and debug OpenRefine from Eclipse, you will need to add an execution configuration on the `server` sub-project.
|
||||
Right click on the `server` subproject, click `Run as...` and `Run configurations...` and create a new `Maven Build` run configuration. Rename the run configuration `OpenRefine`. Enter the root directory of the project as `Base directory` and use `exec:java` as a Maven goal.
|
||||
|
||||

|
||||
|
||||
This will add a run configuration that you can then use to run OpenRefine from Eclipse.
|
||||
|
||||
## Testing in Eclipse {#testing-in-eclipse}
|
||||
|
||||
You can run the server tests directly from Eclipse. To do that you need to have the TestNG launcher plugin installed, as well as the TestNG M2E plugin (for integration with Maven). If you don't have it, you can get it by [installing new software](https://help.eclipse.org/2020-03/index.jsp?topic=/org.eclipse.platform.doc.user/tasks/tasks-129.htm) from this update URL http://dl.bintray.com/testng-team/testng-eclipse-release/
|
||||
|
||||
Once the TestNG launching plugin is installed in your Eclipse, right click on the source folder "main/tests/server/src", select `Run As` -> `TestNG Test`. This should open a new tab with the TestNG launcher running the OpenRefine tests.
|
||||
|
||||
### Test coverage in Eclipse {#test-coverage-in-eclipse}
|
||||
|
||||
It is possible to analyze test coverage in Eclipse with the `EclEmma Java Code Coverage` plugin. It will add a `Coverage as…` menu similar to the `Run as…` and `Debug as…` menus which will then display the covered and missed lines in the source editor.
|
||||
|
||||
### Debug with Eclipse {#debug-with-eclipse}
|
||||
Here's an example of putting configuration in Eclipse for debugging, like putting values for the Google Data extension. Other type of configurations that can be set are memory, Wikidata login information and more.
|
||||
|
||||

|
||||
|
||||
## Building, Testing and Running OpenRefine from IntelliJ idea {#building-testing-and-running-openrefine-from-intellij-idea}
|
||||
|
||||
At the command line, go to a directory you want to save the OpenRefine project and execute the following command to clone the repository:
|
||||
|
||||
```shell
|
||||
git clone https://github.com/OpenRefine/OpenRefine.git
|
||||
```
|
||||
|
||||
Then, open the IntelliJ idea and go to `file -> open` and select the location of the cloned repository.
|
||||
|
||||

|
||||
|
||||
It will prompt you to add as a maven project as the source code contains a pom.xml file in it. Allow `auto-import` so that it can add it as a maven project.
|
||||
If it doesn't prompt something like this then you can go on the right side of the IDE and click on maven then, click on `reimport all the maven projects` that will add all the dependencies and jar files required for the project.
|
||||
|
||||

|
||||
|
||||
After this, you will be able to properly build, test, and run the OpenRefine project from the terminal.
|
||||
But if you will go to any of the test folders and open some file it will show you some import errors because the project isn't yet set up at the module level.
|
||||
|
||||
For removing those errors, and enjoying the features of the IDE like ctrl + click, etc you need to set up the project at the module level too. Open the different modules like `extensions/wikidata`, `main` as a project in the IDE. Then, right-click on the project folder and open the module settings.
|
||||
|
||||

|
||||
|
||||
In the module settings, add the source folder and test source folders of that module.
|
||||
|
||||

|
||||
|
||||
Then, do the same thing for the main OpenRefine project and now you are good to go.
|
||||
@ -1,68 +0,0 @@
|
||||
---
|
||||
id: contributing
|
||||
title: Contributing
|
||||
sidebar_label: Contributing
|
||||
---
|
||||
|
||||
Please read the general [guidelines on contributing to OpenRefine](https://github.com/OpenRefine/OpenRefine/blob/master/CONTRIBUTING.md) first, then review the information on [reporting and tracking issues](#reporting-and-tracking-issues), and on making your [first pull request](#your-first-pull-request) below)
|
||||
|
||||
## Reporting and tracking issues {#reporting-and-tracking-issues}
|
||||
|
||||
If you need to file a bug or request a feature, [create an Issue in the OpenRefine Github repository](https://github.com/OpenRefine/OpenRefine/issues). Github issues should be used for reporting specific bugs and requesting specific features. If you just don't know how to do something using OpenRefine, or want to discuss some ideas, please:
|
||||
|
||||
- [Try the user manual](/)
|
||||
- [post to our OpenRefine mailing list](http://groups.google.com/group/openrefine/)
|
||||
|
||||
## Contributing to the documentation {#contributing-to-the-documentation}
|
||||
|
||||
We use [Docusaurus](https://docusaurus.io/) for our docs. For small documentation changes, you should be able to edit the Markdown files directly and submit them as a pull request. A preview of the docs will be generated automatically. But it is also
|
||||
possible to preview your changes locally. Assuming you have [Node.js](https://nodejs.org/en/download/) installed (which includes npm), you can install Docusaurus with:
|
||||
|
||||
You will need to install [Yarn](https://yarnpkg.com/getting-started/install) before you can build the site.
|
||||
```sh
|
||||
npm install -g yarn
|
||||
```
|
||||
|
||||
Once you have installed yarn, navigate to docs directory & set-up the dependencies.
|
||||
|
||||
```sh
|
||||
cd docs
|
||||
yarn
|
||||
```
|
||||
|
||||
Once this is done, generate the docs with:
|
||||
|
||||
```sh
|
||||
yarn build
|
||||
```
|
||||
|
||||
You can also spin a local web server to serve the docs for you, with auto-refresh when you edit the source files, with:
|
||||
```sh
|
||||
yarn start
|
||||
```
|
||||
|
||||
## Your first code pull request {#your-first-code-pull-request}
|
||||
|
||||
This describes the overall steps to your first code contribution in OpenRefine. If you have trouble with any of these steps feel free to reach out on the [developer mailing list](https://groups.google.com/forum/#!forum/openrefine-dev) or the [Gitter channel](https://gitter.im/OpenRefine/OpenRefine).
|
||||
|
||||
- Install OpenRefine, learn to use it by following some tutorials or watching [some videos](http://openrefine.org/). That will ensure you understand the user workflows and get familiar with the terminology used in the tool.
|
||||
|
||||
- Fork the GitHub repository, clone it on your machine and set up your IDE to work on it. We have [instructions for this](https://github.com/OpenRefine/OpenRefine/wiki/Building-OpenRefine-From-Source).
|
||||
|
||||
- Browse through the list of issues to find an issue that you find interesting. You should pick one where you understand what the problem is as a user, you can see why fixing it would be an improvement to the tool. It is also a good idea to pick an issue that matches your technical skills: some require work on the backend (in Java) or in the frontend (Javascript), often both. We try to maintain a list of [good first issues](https://github.com/OpenRefine/OpenRefine/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) which should be easier than others and should not require any difficult design decision.
|
||||
|
||||
- Reproduce the issue locally, by following the steps described in the issue. You might need to locate a particular dialog, use a specific importer on a sample file, or follow any other user workflow. If you have followed all the steps described in the issue and cannot observe the issue mentioned, write a comment on the issue explaining that you are not able to reproduce it (perhaps it was fixed by another change).
|
||||
|
||||
- Locate the code that is relevant for the issue you want to solve. Text search across files is often useful for that. For instance, if the issue you want to solve is about a dialog entitled "Columnize by key/values", you can search for "Columnize" in the entire source code. For more details about this technique, see [this comment](https://github.com/OpenRefine/OpenRefine/issues/3137#issuecomment-691649962).
|
||||
|
||||
- Study how the current code works. You might want to use a debugger to put breakpoints at the relevant locations (for inspecting the backend, use your IDE's debugger, for the frontend, use your browser's developer tools).
|
||||
|
||||
- Create a git branch for your fix. The name of your branch should contain the issue number, and a few words to describe the topic of the fix, for instance "issue-1234-columnize-layout".
|
||||
|
||||
- Make changes to the code to fix the issue. If you are changing backend code, it would be great if you could also write a test in Java to demonstrate the fix. You can imitate existing tests for that. We currently do not have frontend tests.
|
||||
|
||||
- commit your changes, using a message that contains one of the special words "closes" and "fixes" which are detected by Github, followed by the issue number, e.g. "closes #1234" or "fixes #1234", this will link the commit to the issue you are working on.
|
||||
|
||||
- push your branch to your fork and create a pull request for it, explaining the approach you have used, any design decisions you have made.
|
||||
|
||||
Thank you!
|
||||
@ -1,29 +0,0 @@
|
||||
---
|
||||
id: development-roadmap
|
||||
title: Development roadmap
|
||||
sidebar_label: Development roadmap
|
||||
---
|
||||
|
||||
Please be aware that the OpenRefine roadmap is subject to change at any time, so please check back regularly, and monitor [milestones](https://github.com/OpenRefine/OpenRefine/milestones), [projects](https://github.com/OpenRefine/OpenRefine/projects) and [issues](https://github.com/OpenRefine/OpenRefine/issues) in Github to keep up to date with current plans.
|
||||
|
||||
If there are features you would like to see that are not currently listed here or in current [milestones](https://github.com/OpenRefine/OpenRefine/milestones), [projects](https://github.com/OpenRefine/OpenRefine/projects) and [issues](https://github.com/OpenRefine/OpenRefine/issues), please add them to the [issue tracker](https://github.com/OpenRefine/OpenRefine/issues).
|
||||
|
||||
|
||||
## Planned releases {#planned-releases}
|
||||
|
||||
### 4.0 {#40}
|
||||
[New backend storage option to allow using much bigger datasets at the expense of real-time feedback.](https://github.com/OpenRefine/OpenRefine/milestone/7)
|
||||
|
||||
New UI (possibly Vue or React based)
|
||||
|
||||
## Work in progress {#work-in-progress}
|
||||
Alongside the planned releases there are often smaller pieces of work in progress. Check for [recently updated issues](https://github.com/OpenRefine/OpenRefine/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc) and [pull requests](https://github.com/OpenRefine/OpenRefine/pulls?q=is%3Apr+is%3Aopen+sort%3Aupdated-desc) to see what is currently in the works.
|
||||
|
||||
## On the back burner {#on-the-back-burner}
|
||||
Some aspects of OpenRefine have previously been targeted for release, but have not made it into a release and have not been worked on recently. If you would like to see features in these areas, please create an issue the describes what development you would like to see:
|
||||
|
||||
- Streamlining traditional features
|
||||
- Views: map, timeline, protovis (D3.js) charts
|
||||
- Better machinery to guess and re-encode cell values (useful for fixing encoding issues)
|
||||
- Collaborative editing support (see documentation on the '[broker protocol](https://github.com/OpenRefine/OpenRefine/wiki/Broker-Protocol)' to see where this work was going)
|
||||
- Column groups
|
||||
@ -1,241 +0,0 @@
|
||||
---
|
||||
id: functional-tests
|
||||
title: Functional tests
|
||||
sidebar_label: Functional tests
|
||||
---
|
||||
|
||||
import useBaseUrl from '@docusaurus/useBaseUrl';
|
||||
|
||||
## Introduction {#introduction}
|
||||
|
||||
OpenRefine interface is tested with the [Cypress framework](https://www.cypress.io/).
|
||||
With Cypress, tests are performing assertions using a real browser, the same way a real user would use the software.
|
||||
|
||||
Cypress tests can be ran
|
||||
|
||||
- using the Cypress test runner (development mode)
|
||||
- using a command line (CI/CD mode)
|
||||
|
||||
If you are writing tests, the Cypress test runner is good enough, and the command-line is mainly used by the CI/CD platform (Github actions)
|
||||
|
||||
## Cypress brief overview {#cypress-brief-overview}
|
||||
|
||||
Cypress operates insides a browser, it's internally using NodeJS.
|
||||
That's a key difference with tools such as Selenium.
|
||||
|
||||
**From the Cypress documentation:**
|
||||
|
||||
> But what this also means is that your test code **is being evaluated inside the browser**. Test code is not evaluated in Node, or any other server side language. The **only** language we will ever support is the language of the web: JavaScript.
|
||||
|
||||
Good starting points with Cypress are the [Getting started guide](https://docs.cypress.io/guides/getting-started/writing-your-first-test.html#Write-your-first-test), and the [Trade-offs](https://docs.cypress.io/guides/references/trade-offs.html#Permanent-trade-offs-1)
|
||||
|
||||
The general workflow of a Cypress test is to
|
||||
|
||||
- Start a browser (yarn run cypress open)
|
||||
- Visit a URL
|
||||
- Trigger user actions
|
||||
- Assert that the DOM contains expected texts and elements using selectors
|
||||
|
||||
## Getting started {#getting-started}
|
||||
|
||||
If this is the first time you use Cypress, it is recommended for you to get familiar with the tool.
|
||||
|
||||
- [Cypress overview](https://docs.cypress.io/guides/overview/why-cypress.html)
|
||||
- [Cypress examples of tests and syntax](https://example.cypress.io/)
|
||||
|
||||
### 1. Install Cypress {#1-install-cypress}
|
||||
|
||||
You will need:
|
||||
|
||||
- [Node.js 10 or 12 and above](https://nodejs.org)
|
||||
- [Yarn or NPM](https://yarnpkg.com/)
|
||||
- A Unix/Linux shell environment or the Windows command line
|
||||
|
||||
To install Cypress and dependencies, run :
|
||||
|
||||
```shell
|
||||
cd ./main/tests/cypress
|
||||
yarn install
|
||||
```
|
||||
|
||||
### 2. Start the test runner {#2-start-the-test-runner}
|
||||
|
||||
The test runner assumes that OpenRefine is up and running on the local machine, the tests themselves do not launch OpenRefine, nor restarts it.
|
||||
|
||||
Start OpenRefine with
|
||||
|
||||
```shell
|
||||
./refine
|
||||
```
|
||||
|
||||
Then start Cypress
|
||||
|
||||
```shell
|
||||
yarn --cwd ./main/tests/cypress run cypress open
|
||||
```
|
||||
|
||||
### 3. Run the existing tests {#3-run-the-existing-tests}
|
||||
|
||||
Once the test runner is up, you can choose to run one or several tests by selecting them from the interface.
|
||||
Click on one of them and the test will start.
|
||||
|
||||
### 4. Add your first test {#4-add-your-first-test}
|
||||
|
||||
- Add a `test.spec.js` into the `main/tests/cypress/cypress/integration` folder.
|
||||
- The test is instantly available in the list
|
||||
- Click on the test
|
||||
- Start to add some code
|
||||
|
||||
## Tests technical documentation {#tests-technical-documentation}
|
||||
|
||||
### A typical test {#a-typical-test}
|
||||
|
||||
A typical OpenRefine test starts with the following code
|
||||
|
||||
```javascript
|
||||
it('Ensure cells are blanked down', function () {
|
||||
cy.loadAndVisitProject('food.mini');
|
||||
cy.get('.viewpanel-sorting a').contains('Sort').click();
|
||||
cy.get('.viewpanel').should('to.contain', 'Something');
|
||||
});
|
||||
```
|
||||
|
||||
The first noticeable thing about a test is the description (`Ensure cells are blanked down`), which describes what the test is doing.
|
||||
Lines usually starts with `cy.something...`, which is the main way to interact with the Cypress framework.
|
||||
|
||||
A few examples:
|
||||
|
||||
- `cy.get('a.my-class')` will retrieve the `<a class="my-class" />` element
|
||||
- `cy.click()` will click on the element
|
||||
- eventually, `cy.should()` will perform an assertion, for example that the element contains an expected text with `cy.should('to.contains', 'my text')`
|
||||
|
||||
On top of that, OpenRefine contributors have added some functions for common OpenRefine interactions.
|
||||
For example
|
||||
|
||||
- `cy.loadAndVisitProject` will create a fresh project in OpenRefine
|
||||
- `cy.assertCellEquals` will ensure that a cell contains a given value
|
||||
|
||||
See below on the dedicated section 'Testing utilities'
|
||||
|
||||
### Testing guidelines {#testing-guidelines}
|
||||
|
||||
- `cy.wait` should be used in the last resort scenario. It's considered a bad practice, though sometimes there is no other choice
|
||||
- Tests should remain isolated from each other. It's best to try one feature at the time
|
||||
- A test should always start with a fresh project
|
||||
- The name of the files should mirror the OpenRefine UI organization
|
||||
|
||||
### Testing utilities {#testing-utilities}
|
||||
|
||||
OpenRefine contributors have added some utility methods on the top of the Cypress framework.
|
||||
Those methods perform some common actions or assertions on OpenRefine, to avoid code duplication.
|
||||
|
||||
Utilities can be found in `cypress/support/commands.js`.
|
||||
|
||||
The most important utility method is `loadAndVisitProject`.
|
||||
This method will create a fresh OpenRefine project based on a dataset given as a parameter.
|
||||
The fixture parameter can be
|
||||
|
||||
- An arbitrary array, the first row is for the column names, other rows are for the values
|
||||
Use an arbitrary array **only** if the test requires some specific grid values
|
||||
**Example:**
|
||||
|
||||
```javascript
|
||||
const fixture = [
|
||||
['Column A', 'Column B', 'Column C'],
|
||||
['0A', '0B', '0C'],
|
||||
['1A', '1B', '1C'],
|
||||
['2A', '2B', '2C'],
|
||||
];
|
||||
cy.loadAndVisitProject(fixture);
|
||||
```
|
||||
|
||||
- A referenced dataset: `food.small` or `food.mini`
|
||||
Most of the time, tests does not require any specific grid values
|
||||
Use food.mini as much as possible, it loads 2 rows and very few columns in the grid
|
||||
Use food.small if the test requires a few hundred rows in the grid
|
||||
|
||||
Those datasets live in `cypress/fixtures`
|
||||
|
||||
### Browsers {#browsers}
|
||||
|
||||
In terms of browsers, Cypress is using what is installed on your operating system.
|
||||
See the [Cypress documentation](https://docs.cypress.io/guides/guides/launching-browsers.html#Browsers) for a list of supported browsers
|
||||
|
||||
### Folder organization {#folder-organization}
|
||||
|
||||
Tests are located in `main/tests/cypress/cypress` folder.
|
||||
The test should not use any file outside the cypress folder.
|
||||
|
||||
- `/fixtures` contains CSVs and OpenRefine project files used by the tests
|
||||
- `/integration` contains the tests
|
||||
- `/plugins` contains custom plugins for the OR project
|
||||
- `/screenshots` and `/videos` contains the recording of the tests, Git ignored
|
||||
- `/support` is a custom library of assertion and common user actions, to avoid code duplication in the tests themselves
|
||||
|
||||
### Configuration {#configuration}
|
||||
|
||||
Cypress execution can be configured with environment variables, they can be declared at the OS level, or when running the test
|
||||
|
||||
Available variables are
|
||||
|
||||
- OPENREFINE_URL, determine on which scheme://url:port to access OpenRefine, default to http://localhost:333
|
||||
- DISABLE_PROJECT_CLEANUP, If set to 1, projects will not be deleted after each run. Default to 0 to keep the OpenRefine instance clean
|
||||
|
||||
|
||||
Cypress contains [exaustive documentation](https://docs.cypress.io/guides/guides/environment-variables.html#Setting) about configuration, but here are two simple ways to configure the execution of the tests:
|
||||
|
||||
#### Overriding with a cypress.env.json file {#overriding-with-a-cypressenvjson-file}
|
||||
|
||||
This file is ignored by Git, and you can use it to configure Cypress locally
|
||||
|
||||
#### Command-line {#command-line}
|
||||
|
||||
You can pass variables at the command-line level
|
||||
|
||||
```shell
|
||||
yarn --cwd ./main/tests/cypress run cypress open --env OPENREFINE_URL="http://localhost:1234"
|
||||
```
|
||||
|
||||
### Visual testing {#visual-testing}
|
||||
|
||||
Tests generally ensure application behavior by making assertions against the DOM, to ensure specific texts or css attributes are present in the document body.
|
||||
Visual testing, on the contrary, is a way to test applications by comparing images.
|
||||
A reference screenshot is taken the first time the test runs, and subsequent runs will compare a new screenshot against the reference, at the pixel level.
|
||||
|
||||
Here is an [introduction to visual testing by Cypress](https://docs.cypress.io/plugins/directory#visual-testing).
|
||||
|
||||
In some cases, we are using visual testing.
|
||||
We are using [Cypress Image Snapshot](https://github.com/jaredpalmer/cypress-image-snapshot)
|
||||
|
||||
Identified cases are so far:
|
||||
|
||||
- testing images created by OpenRefine backend (scatterplots for example)
|
||||
|
||||
Reference screenshots (Called snapshots), are stored in /cypress/snapshots.
|
||||
And a snapshot can be taken for the whole page, or just a single part of the page.
|
||||
|
||||
#### When a visual test fails {#when-a-visual-test-fails}
|
||||
|
||||
First, Cypress will display the following error message:
|
||||
|
||||

|
||||
|
||||
Then, a diff image will be created in /cypress/snapshots, this directory is ignored by Git.
|
||||
The diff images shows the reference image on the left, the image that was taken during the test run on the right, and the diff in the middle.
|
||||
|
||||

|
||||
|
||||
## CI/CD {#cicd}
|
||||
|
||||
In CI/CD, tests are run headless, with the following command-line
|
||||
|
||||
```shell
|
||||
./refine ui_test chrome
|
||||
```
|
||||
|
||||
Results are displayed in the standard output
|
||||
|
||||
## Resources {#resources}
|
||||
|
||||
[Cypress command line options](https://docs.cypress.io/guides/guides/command-line.html#Installation)
|
||||
[Lots of good Cypress examples](https://example.cypress.io/)
|
||||
@ -1,5 +0,0 @@
|
||||
---
|
||||
id: homebrew-cask-process
|
||||
title: Maintaining OpenRefine's Homebrew cask
|
||||
sidebar_label: Maintaining OpenRefine's Homebrew cask
|
||||
---
|
||||
@ -1,89 +0,0 @@
|
||||
---
|
||||
id: maintainer-guidelines
|
||||
title: Guidelines for maintaining OpenRefine
|
||||
sidebar_label: Maintainer guidelines
|
||||
---
|
||||
|
||||
This page describes our practices to review issues and pull requests in the OpenRefine project.
|
||||
|
||||
## Reviewing issues {#reviewing-issues}
|
||||
|
||||
When people create new issues, they automatically get assigned [the "to be reviewed" tag](https://github.com/OpenRefine/OpenRefine/issues?q=is%3Aissue+is%3Aopen+label%3A%22to+be+reviewed%22).
|
||||
|
||||
Ideally, for each of these issues, someone familiar with OpenRefine (not necessarily a developer!) should read the issue and try to determine if there is a genuine bug to fix, or if the enhancement request is legitimate. In those cases, we can remove the "to be reviewed" tag and leave the issue open. In the others, the issue should be politely closed.
|
||||
|
||||
### Bugs {#bugs}
|
||||
|
||||
For a bug, we should first check if it is a real unexpected behaviour or if just comes from a misunderstanding of the intended behaviour of the tool (which could suggest an improvement to the documentation). Then, if it sounds like a genuine problem, we need to check if it can be reproduced independently on the master branch. If the issue does not give enough details about the bug to reproduce it on master, mark it as "not reproducible" and ask the reporter for more information. After some time without any information from the reporter, we can close the issue.
|
||||
|
||||
### Enhancement requests {#enhancement-requests}
|
||||
|
||||
For an enhancement, we need to make a judgment call of whether the proposed functionality is in the scope of the project. There is no universal rule for this of course, so just use your own intuition: do you think this would improve the tool? Would it be consistent with the spirit of the project? Trust your own opinion - if people disagree, they can have a discussion on the issue.
|
||||
|
||||
### Tagging good first issues {#tagging-good-first-issues}
|
||||
|
||||
Adding [the "good first issue" tag](https://github.com/OpenRefine/OpenRefine/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) is something that requires a bit more familiarity with the development process. This tag is used by GitHub to showcase issues in some project lists and we point interested potential contributors to it. It is therefore important that tackling these issues gives them a nice onboarding experience, with as few hurdles as possible.
|
||||
|
||||
Develepers should add the "good first issue" tag when they are confident that they can provide a good pull request for the issue with at most a few hours of work. Also, solving the issue should not require any difficult design decision. The issue should be uncontentious: it should be clear that the proposed solution should be accepted by the team.
|
||||
|
||||
## Reviewing pull requests {#reviewing-pull-requests}
|
||||
|
||||
### Process {#process}
|
||||
|
||||
1. A committer reviews the PR to check for the requirements below and tests it. Each PR should be linked to one or more corresponding issues and the reviewer should check that those are correctly addressed by the PR. The reviewer should be someone else than the PR author. For PRs with an important impact or contentious issues, it is important to leave enough time for other contributors to give their opinion.
|
||||
|
||||
2. The reviewer merges the pull request by squashing its commits into one (except for Weblate PRs which should be merged without squashing).
|
||||
|
||||
3. The reviewer adds the linked issues to the milestone for the next release (such as [the 3.5 milestone](https://github.com/OpenRefine/OpenRefine/milestone/17))
|
||||
|
||||
4. If the change is worth noting for users or developers, the reviewer adds an entry in the changelog for the next release (such as [Changes for 3.5](https://github.com/OpenRefine/OpenRefine/wiki/Changes-for-3.5))
|
||||
|
||||
### Requirements {#requirements}
|
||||
|
||||
#### Code style {#code-style}
|
||||
|
||||
Currently, only our code style for integration tests (using Cypress) is codified and enforced by the CI.
|
||||
For the rest, we rely on imitating the surrounding code. [We should decide on a code style and check it in the CI for other areas of the tool](https://github.com/OpenRefine/OpenRefine/issues/2338).
|
||||
|
||||
#### Testing {#testing}
|
||||
|
||||
We currently rely have two sorts of tests:
|
||||
* Backend tests, in Java, written with the TestNG framework. Their granularity varies, but generally speaking they are unit tests which test components in isolation.
|
||||
* UI tests, in Javascript, written with the Cypress framework. They are integration tests which test both the frontend and the backend at the same time.
|
||||
|
||||
Changes to the backend should generally come with the accompanying TestNG tests.
|
||||
Functional changes to the UI should ideally come with corresponding Cypress tests as well.
|
||||
|
||||
Those tests should be supplied in the same PR as the one that touches the product code.
|
||||
|
||||
#### Documentation {#documentation}
|
||||
|
||||
Changes to user-facing functionality should be reflected in the docs. Those documentation changes should happen in the same PR as the one that touches the product code.
|
||||
|
||||
#### UI style {#ui-style}
|
||||
|
||||
We do not have formally defined UI style guidelines. Contributors are invited to imitate the existing style.
|
||||
|
||||
#### Licensing and dependencies {#licensing-and-dependencies}
|
||||
|
||||
Dependencies can only be added if they are released under a license that is compatible with our BSD Clause-3 license.
|
||||
One should pay attention to the size of the dependencies since they inflate the size of the release bundles.
|
||||
|
||||
#### Continuous integration {#continuous-integration}
|
||||
|
||||
The various check statuses reported by our continuous integration suite should be green.
|
||||
|
||||
### Special pull requests {#special-pull-requests}
|
||||
|
||||
#### Weblate PRs {#weblate-prs}
|
||||
|
||||
Weblate PRs should not be squashed as it prevents Weblate from recognizing that the corresponding changes have been made in master. They should be merged without squashing.
|
||||
|
||||
Reviewing Weblate PRs only amonuts to a quick visual sanity check as maintainers are not expected to master the languages involved. If corrections need to be made, they should be done in Weblate itself.
|
||||
|
||||
#### Dependabot PRs {#dependabot-prs}
|
||||
|
||||
When reviewing a Dependabot PR it is generally useful to pay attention to:
|
||||
* the type of version change: most libraries follow the "semver" versioning convention, which indicates the nature of the change.
|
||||
* the library's changelog, especially if the version change is more significant than a patch release
|
||||
|
||||
@ -1,169 +0,0 @@
|
||||
---
|
||||
id: migrating-older-extensions
|
||||
title: Migrating older Extensions
|
||||
sidebar_label: Migrating older Extensions
|
||||
---
|
||||
|
||||
## Migrating from Ant to Maven {#migrating-from-ant-to-maven}
|
||||
|
||||
### Why are we doing this change? {#why-are-we-doing-this-change}
|
||||
|
||||
Ant is a fairly old (antique?) build system that does not incorporate any dependency management.
|
||||
By migrating to Maven we are making it easier for developers to extend OpenRefine with new libraries, and stop having to ship dozens of .jar files in the repository. Using the Maven repository also encourages developers to add dependencies to released versions of libraries instead of custom snapshots that are hard to update.
|
||||
|
||||
### When was this change made? {#when-was-this-change-made}
|
||||
|
||||
The migration was done between 3.0 and 3.1-beta with this commit:
|
||||
https://github.com/OpenRefine/OpenRefine/commit/47323a9e750a3bc9d43af606006b5eb20ca397b8
|
||||
|
||||
### How to migrate an extension {#how-to-migrate-an-extension}
|
||||
|
||||
You will need to write a `pom.xml` in the root folder of your extension to configure the compilation process with Maven. Sample `pom.xml` files for extensions can be found in the extensions that are shipped with OpenRefine (`gdata`, `database`, `jython`, `pc-axis` and `wikidata`). A sample extension (`sample`) is also provided, with a minimal build file.
|
||||
|
||||
For any library that your extension depends on, you should try to find a matching artifact in the Maven Central repository. If you can find such an artifact, delete the `.jar` file from your extension and add the dependency in your `pom.xml` file. If you cannot find such an artifact, it is still possible to incorporate your own `.jar` file using `maven-install-plugin` that you can configure in your `pom.xml` file as follows:
|
||||
|
||||
|
||||
<plugin>
|
||||
<groupId>org.apache.maven.plugins</groupId>
|
||||
<artifactId>maven-install-plugin</artifactId>
|
||||
<version>2.5.2</version>
|
||||
<executions>
|
||||
<execution>
|
||||
<id>install-wdtk-datamodel</id>
|
||||
<phase>process-resources</phase>
|
||||
<configuration>
|
||||
<file>${basedir}/lib/my-proprietary-library.jar</file>
|
||||
<repositoryLayout>default</repositoryLayout>
|
||||
<groupId>com.my.company</groupId>
|
||||
<artifactId>my-library</artifactId>
|
||||
<version>0.5.3-SNAPSHOT</version>
|
||||
<packaging>jar</packaging>
|
||||
<generatePom>true</generatePom>
|
||||
</configuration>
|
||||
<goals>
|
||||
<goal>install-file</goal>
|
||||
</goals>
|
||||
</execution>
|
||||
<!-- if you need to add more than one jar, add more execution blocks here -->
|
||||
</executions>
|
||||
</plugin>
|
||||
|
||||
And add the dependency to the `<dependencies>` section as usual:
|
||||
|
||||
<dependency>
|
||||
<groupId>com.my.company</groupId>
|
||||
<artifactId>my-library</artifactId>
|
||||
<version>0.5.3-SNAPSHOT</version>
|
||||
</dependency>
|
||||
|
||||
## Migrating to Wikimedia's i18n jQuery plugin {#migrating-to-wikimedias-i18n-jquery-plugin}
|
||||
|
||||
### Why are we doing this change? {#why-are-we-doing-this-change-1}
|
||||
|
||||
This adds various important localization features, such as the ability to handle plurals or interpolation. This also restores the language fallback (displaying strings in English if they are not available in the target language) which did not work with the previous set up.
|
||||
|
||||
### When was the migration made? {#when-was-the-migration-made}
|
||||
|
||||
The migration was made between 3.1-beta and 3.1, with this commit: https://github.com/OpenRefine/OpenRefine/commit/22322bd0272e99869ab8381b1f28696cc7a26721
|
||||
|
||||
### How to migrate an extension {#how-to-migrate-an-extension-1}
|
||||
|
||||
You will need to update your translation files, merging nested objets in one global object, concatenating keys. You can do this by running the following Python script on all your JSON translation files:
|
||||
|
||||
import json
|
||||
import sys
|
||||
|
||||
with open(sys.argv[1], 'r') as f:
|
||||
j = json.loads(f.read())
|
||||
|
||||
result = {}
|
||||
def translate(obj, path):
|
||||
res = {}
|
||||
if type(obj) == str:
|
||||
result['/'.join(path)] = obj
|
||||
else:
|
||||
for k, v in obj.items():
|
||||
new_path = path + [k]
|
||||
translate(v, new_path)
|
||||
|
||||
translate(j, [])
|
||||
|
||||
with open(sys.argv[1], 'w') as f:
|
||||
f.write(json.dumps(result, ensure_ascii=False, indent=4))
|
||||
|
||||
Then your javascript files which retrieve the translated strings should be updated: `$.i18n._('core-dialogs')['cancel']` becomes `$.i18n('core-dialogs/cancel')`. You can do this with the following `sed` script:
|
||||
|
||||
sed -i "s/\$\.i18n._(['\"]\([A-Za-z0-9/_\\-]*\)['\"])\[['\"]\([A-Za-z0-9\-\_]*\)[\"']\]/$.i18n('\1\/\2')/g" my_javascript_file.js
|
||||
|
||||
You can then chase down the places where you are concatenating translated strings, and replace that with more flexible patterns using [the plugin's features](https://github.com/wikimedia/jquery.i18n#jqueryi18n-plugin).
|
||||
|
||||
## Migrating from org.json to Jackson {#migrating-from-orgjson-to-jackson}
|
||||
|
||||
### Why are we doing this change? {#why-are-we-doing-this-change-2}
|
||||
|
||||
The org.json (or json-java) library has multiple drawbacks.
|
||||
* First, it has limited functionality - all the serialization and deserialization has to be done explicitly - an important proportion of OpenRefine's code was dedicated to implementing these;
|
||||
* Second, its implementation is not optimized for speed - multiple projects have reported speedups when migrating to more modern JSON libraries;
|
||||
* Third, and this was the decisive factor to initiate the migration: [its license](https://json.org/license) is the MIT license with an additional condition which makes it non-free. Getting rid of this dependency was required by the Software Freedom Conservancy as a prerequisite to become a fiscal sponsor for the project.
|
||||
|
||||
### When was the migration made? {#when-was-the-migration-made-1}
|
||||
|
||||
This change was made between 3.1 and 3.2-beta, with this commit: https://github.com/OpenRefine/OpenRefine/commit/5639f1b2f17303b03026629d763dcb6fef98550b
|
||||
|
||||
### How to migrate an extension or fork {#how-to-migrate-an-extension-or-fork}
|
||||
|
||||
You will need to use the Jackson library to serialize the classes that implement interfaces or extend classes exposed by OpenRefine.
|
||||
The interface `Jsonizable` was deleted. Any class that used to implement this now needs to be serializable by Jackson, producing the same format as the previous serialization code. This applies to any operation, facet, overlay model or GREL function. If you are new to Jackson, have a look at [this tutorial](https://www.baeldung.com/jackson) to learn how to annotate your class for serialization. Once this is done, you can remove the `void write(JSONWriter writer, Properties options)` method from your class. Note that it is important that you do this migration for all classes implementing the `Jsonizable` interface that are exposed to OpenRefine's core.
|
||||
|
||||
We encourage you to migrate out of org.json completely, but this is only required for the classes that interact with OpenRefine's core.
|
||||
|
||||
#### General notes about migrating {#general-notes-about-migrating}
|
||||
|
||||
OpenRefine's ObjectMapper is available at `ParsingUtilities.mapper`. It is configured to only serialize the fields and getters that have been explicitly marked with `@JsonProperty` (to avoid accidental JSON format changes due to refactoring). On deserialization it will ignore any field in the JSON payload that does not correspond to a field in the Java class. It has serializers and deserializers for `OffsetDateTime` and `LocalDateTime`.
|
||||
|
||||
Useful snippets to use in tests:
|
||||
* deserialize an instance: `MyClass instance = ParsingUtilities.mapper.readValue(jsonString, MyClass.class);` (replaces calls to `Jsonizable.write`);
|
||||
* serialize an instance: `String json = ParsingUtilities.mapper.writeValueAsString(myInstance);` (replaces calls to static methods such as `load`, `loadStreaming` or `reconstruct`);
|
||||
* the equivalent of `JSONObject` is `ObjectNode`, the equivalent of `JSONArray` is `ArrayNode`;
|
||||
* create an empty JSON object: `ParsingUtilities.mapper.createObjectNode()` (replaces `new JSONObject()`);
|
||||
* create an empty JSON array: `ParsingUtilities.mapper.createArrayNode()` (replaces `new JSONArray()`).
|
||||
|
||||
Before undertaking the migration, we recommend that you write some tests which serialize and deserialize your objects. This will help you make sure that the JSON format is preserved during the migration. One way to do this is to collect some sample JSON representations of your objects, and check in your tests that deserializing these JSON payloads and serializing them back to JSON preserves the JSON payload. Some utilities are available to help you with that in [`TestUtils`](https://github.com/OpenRefine/OpenRefine/blob/master/main/tests/server/src/com/google/refine/tests/util/TestUtils.java) (we had [some to test org.json serialization](https://github.com/OpenRefine/OpenRefine/blob/3.1/main/tests/server/src/com/google/refine/tests/util/TestUtils.java) before we got rid of the dependency, feel free to copy them).
|
||||
|
||||
#### For functions {#for-functions}
|
||||
|
||||
Before the migration, you had to explicitly define JSON serialization of functions with a `write` method. You should now override the getters returning the various documentation fields.
|
||||
|
||||
Example: `Cos` function [before](https://github.com/OpenRefine/OpenRefine/blob/3.1/main/src/com/google/refine/expr/functions/math/Cos.java) and [after](https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/expr/functions/math/Cos.java).
|
||||
|
||||
#### For operations {#for-operations}
|
||||
|
||||
Before the JSON migration we refactored engine-dependent operations so that the engine configuration is represented by an `EngineConfig` object instead of a `JSONObject`. Therefore the constructor for your operation should be updated to use this new class. Your constructor should also be annotated to be used during deserialization.
|
||||
|
||||
Note that you do not need to explicitly serialize the operation type, this is already done for you by `AbstractOperation`.
|
||||
|
||||
Example: `ColumnRemovalOperation` [before](https://github.com/OpenRefine/OpenRefine/blob/3.1/main/src/com/google/refine/operations/column/ColumnRemovalOperation.java) and [after](https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/operations/column/ColumnRemovalOperation.java).
|
||||
|
||||
#### For changes {#for-changes}
|
||||
|
||||
Changes are serialized in plain text but often relies on JSON serialization for parts of the data. Just use the methods above with `ParsingUtilities.mapper` to maintain this behaviour.
|
||||
|
||||
Example: `ReconChange` [before](https://github.com/OpenRefine/OpenRefine/blob/3.1/main/src/com/google/refine/model/changes/ReconChange.java) and [after](https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/operations/column/ColumnRemovalOperation.java).
|
||||
|
||||
#### For importers {#for-importers}
|
||||
|
||||
The importing options have been migrated from `JSONObject` to `ObjectNode`. Your compiler should help you propagate this change. Utility functions in `JSONUtilities` have been migrated to Jackson so you should have minimal changes if you used them.
|
||||
|
||||
Example: `TabularImportingParserBase` [before](https://github.com/OpenRefine/OpenRefine/blob/3.1/main/src/com/google/refine/importers/TabularImportingParserBase.java) and [after](https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/importers/TabularImportingParserBase.java).
|
||||
|
||||
#### For overlay models {#for-overlay-models}
|
||||
|
||||
Migrate serialization and deserialization as for other objects.
|
||||
|
||||
Example: `WikibaseSchema` [before](https://github.com/OpenRefine/OpenRefine/blob/3.1/extensions/wikidata/src/org/openrefine/wikidata/schema/WikibaseSchema.java#L203) and [after](https://github.com/OpenRefine/OpenRefine/blob/master/extensions/wikidata/src/org/openrefine/wikidata/schema/WikibaseSchema.java#L60)
|
||||
|
||||
#### For preference values {#for-preference-values}
|
||||
|
||||
Any class that is stored in OpenRefine's preference now needs to implement the `com.google.refine.preferences.PreferenceValue` interface. The static `load` method and the `write` method used previously for deserialization should be deleted and regular Jackson serialization and deserialization should be implemented instead. Note that you do not need to explicitly serialize the class name, this is already done for you by the interface.
|
||||
|
||||
Example: `TopList` [before](https://github.com/OpenRefine/OpenRefine/blob/3.1/main/src/com/google/refine/preference/TopList.java) and [after](https://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/preference/TopList.java)
|
||||
@ -1,285 +0,0 @@
|
||||
---
|
||||
id: openrefine-api
|
||||
title: OpenRefine API
|
||||
sidebar_label: OpenRefine API
|
||||
---
|
||||
|
||||
This is a generic API reference for interacting with OpenRefine's HTTP API.
|
||||
|
||||
**NOTE:** This protocol is subject to change without warning at any time (and has in the past) and is not versioned. Use at your own risk!
|
||||
|
||||
For OpenRefine 3.3 and later, all POST requests need to include a CSRF token as described here: https://github.com/OpenRefine/OpenRefine/wiki/Changes-for-3.3#csrf-protection-changes
|
||||
|
||||
## Create project: {#create-project}
|
||||
|
||||
> **Command:** _POST /command/core/create-project-from-upload_
|
||||
|
||||
When uploading files you will need to send the data as `multipart/form-data`. This is different to all other API calls which use a mixture of query string and POST parameters.
|
||||
|
||||
multipart form-data:
|
||||
|
||||
'project-file' : file contents
|
||||
'project-name' : project name
|
||||
'format' : format of data in project-file (e.g. 'text/line-based/*sv') [optional]
|
||||
'options' : json object containing options relevant to the file format [optional - however, some importers may have required options, such as `recordPath` for the JSON & XML importers].
|
||||
|
||||
The formats supported will depend on the version of OpenRefine you are using and any Extensions you have installed. The common formats include:
|
||||
|
||||
* 'text/line-based': Line-based text files
|
||||
* 'text/line-based/*sv': CSV / TSV / separator-based files [separator to be used in specified in the json submitted to the options parameter]
|
||||
* 'text/line-based/fixed-width': Fixed-width field text files
|
||||
* 'binary/text/xml/xls/xlsx': Excel files
|
||||
* 'text/json': JSON files
|
||||
* 'text/xml': XML files
|
||||
|
||||
If the format is omitted OpenRefine will try to guess the format based on the file extension and MIME type.
|
||||
The values which can be specified in the JSON object submitted to the 'options' parameter will vary depending on the format being imported. If not specified the options will either be guessed at by OpenRefine (e.g. separator being used in a separated values file) or a default value used. The import options for each file format are not currently documented, but can be seen in the OpenRefine GUI interface when importing a file of the relevant format.
|
||||
|
||||
If the project creation is successful, you will be redirected to a URL of the form:
|
||||
|
||||
http://127.0.0.1:3333/project?project=<project id>
|
||||
|
||||
From the project parameter you can extract the project id for use in future API calls. The content of the response is the HTML for the OpenRefine interface for viewing the project.
|
||||
|
||||
### Get project models: {#get-project-models}
|
||||
|
||||
> **Command:** _GET /command/core/get-models?_
|
||||
|
||||
'project' : project id
|
||||
|
||||
Recovers the models for the specific project. This includes columns, records, overlay models, scripting. In the columnModel a list of the columns is displayed, key index and name, and column groupings.
|
||||
|
||||
### Response: {#response}
|
||||
**On success:**
|
||||
```JSON
|
||||
{
|
||||
"columnModel":{
|
||||
"columns":[
|
||||
{
|
||||
"cellIndex":0,
|
||||
"originalName":"email",
|
||||
"name":"email"
|
||||
},
|
||||
{
|
||||
"cellIndex":1,
|
||||
"originalName":"name",
|
||||
"name":"name"
|
||||
},
|
||||
{
|
||||
"cellIndex":2,
|
||||
"originalName":"state",
|
||||
"name":"state"
|
||||
},
|
||||
{
|
||||
"cellIndex":3,
|
||||
"originalName":"gender",
|
||||
"name":"gender"
|
||||
},
|
||||
{
|
||||
"cellIndex":4,
|
||||
"originalName":"purchase",
|
||||
"name":"purchase"
|
||||
}
|
||||
],
|
||||
"keyCellIndex":0,
|
||||
"keyColumnName":"email",
|
||||
"columnGroups":[
|
||||
|
||||
]
|
||||
},
|
||||
"recordModel":{
|
||||
"hasRecords":false
|
||||
},
|
||||
"overlayModels":{
|
||||
|
||||
},
|
||||
"scripting":{
|
||||
"grel":{
|
||||
"name":"General Refine Expression Language (GREL)",
|
||||
"defaultExpression":"value"
|
||||
},
|
||||
"jython":{
|
||||
"name":"Python / Jython",
|
||||
"defaultExpression":"return value"
|
||||
},
|
||||
"clojure":{
|
||||
"name":"Clojure",
|
||||
"defaultExpression":"value"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Apply operations {#apply-operations}
|
||||
|
||||
> **Command:** _POST /command/core/apply-operations?_
|
||||
|
||||
In the parameter
|
||||
|
||||
'project' : project id
|
||||
|
||||
In the form data
|
||||
|
||||
'operations' : Valid JSON **Array** of OpenRefine operations
|
||||
|
||||
Example of a Valid JSON **Array**
|
||||
```JSON
|
||||
'[
|
||||
{
|
||||
"op":"core/column-addition",
|
||||
"description":"Create column zip type at index 15 based on column Zip Code 2 using expression grel:value.type()",
|
||||
"engineConfig":{
|
||||
"mode":"row-based",
|
||||
"facets":[]
|
||||
},
|
||||
"newColumnName":"zip type",
|
||||
"columnInsertIndex":15,
|
||||
"baseColumnName":"Zip Code 2",
|
||||
"expression":"grel:value.type()",
|
||||
"onError":"set-to-blank"
|
||||
},
|
||||
{
|
||||
"op":"core/column-addition",
|
||||
"description":"Create column testing at index 15 based on column Zip Code 2 using expression grel:value.toString()0,5]",
|
||||
"engineConfig":{
|
||||
"mode":"row-based",
|
||||
"facets":[]
|
||||
},
|
||||
"newColumnName":"testing",
|
||||
"columnInsertIndex":15,
|
||||
"baseColumnName":"Zip Code 2",
|
||||
"expression":"grel:value.toString()[0,5]",
|
||||
"onError":"set-to-blank"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
On success returns JSON response
|
||||
`{ "code" : "ok" }`
|
||||
|
||||
## Export rows {#export-rows}
|
||||
|
||||
> **Command:** _POST /command/core/export-rows_
|
||||
|
||||
In the parameter
|
||||
|
||||
'project' : project id
|
||||
'format' : format... (e.g 'tsv', 'csv')
|
||||
|
||||
In the form data
|
||||
|
||||
'engine' : JSON string... (e.g. '{"facets":[],"mode":"row-based"}')
|
||||
|
||||
Returns exported row data in the specified format. The formats supported will depend on the version of OpenRefine you are using and any Extensions you have installed. The common formats include:
|
||||
|
||||
* csv
|
||||
* tsv
|
||||
* xls
|
||||
* xlsx
|
||||
* ods
|
||||
* html
|
||||
|
||||
## Delete project {#delete-project}
|
||||
|
||||
> **Command:** _POST /command/core/delete-project_
|
||||
|
||||
'project' : project id...
|
||||
|
||||
Returns JSON response
|
||||
|
||||
## Check status of async processes {#check-status-of-async-processes}
|
||||
|
||||
> **Command:** _GET /command/core/get-processes_
|
||||
|
||||
'project' : project id...
|
||||
|
||||
Returns JSON response
|
||||
|
||||
## Get all projects metadata: {#get-all-projects-metadata}
|
||||
|
||||
> **Command:** _GET /command/core/get-all-project-metadata_
|
||||
|
||||
Recovers the meta data for all projects. This includes the project's id, name, time of creation and last time of modification.
|
||||
|
||||
### Response: {#response-1}
|
||||
```json
|
||||
{
|
||||
"projects":{
|
||||
"[project_id]":{
|
||||
"name":"[project_name]",
|
||||
"created":"[project_creation_time]",
|
||||
"modified":"[project_modification_time]"
|
||||
},
|
||||
...[More projects]...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Expression Preview {#expression-preview}
|
||||
> **Command:** _POST /command/core/preview-expression_
|
||||
|
||||
Pass some expression (GREL or otherwise) to the server where it will be executed on selected columns and the result returned.
|
||||
|
||||
### Parameters: {#parameters}
|
||||
* **cellIndex**: _[column]_
|
||||
The cell/column you wish to execute the expression on.
|
||||
* **rowIndices**: _[rows]_
|
||||
The rows to execute the expression on as JSON array. Example: `[0,1]`
|
||||
* **expression**: _[language]_:_[expression]_
|
||||
The expression to execute. The language can either be grel, jython or clojure. Example: grel:value.toLowercase()
|
||||
* **project**: _[project_id]_
|
||||
The project id to execute the expression on.
|
||||
* **repeat**: _[repeat]_
|
||||
A boolean value (true/false) indicating whether or not this command should be repeated multiple times. A repeated command will be executed until the result of the current iteration equals the result of the previous iteration.
|
||||
* **repeatCount**: _[repeatCount]_
|
||||
The maximum amount of times a command will be repeated.
|
||||
|
||||
### Response: {#response-2}
|
||||
**On success:**
|
||||
```json
|
||||
{
|
||||
"code": "ok",
|
||||
"results" : [result_array]
|
||||
}
|
||||
```
|
||||
|
||||
The result array will hold up to ten results, depending on how many rows there are in the project that was specified by the [project_id] parameter. Each result is the string that would be put in the cell if the GREL command was executed on that cell. Note that any expression that would return an array or JSon object will be jsonized, although the output can differ slightly from the jsonize() function.
|
||||
|
||||
**On error:**
|
||||
```JSON
|
||||
{
|
||||
"code": "error",
|
||||
"type": "[error_type]",
|
||||
"message": "[error message]"
|
||||
}
|
||||
```
|
||||
|
||||
## Third-party software libraries {#third-party-software-libraries}
|
||||
Libraries using the [OpenRefine API](openrefine-api):
|
||||
|
||||
### Python {#python}
|
||||
* [refine-client-py](https://github.com/PaulMakepeace/refine-client-py/)
|
||||
* Or this fork of the above with an extended CLI [openrefine-client](https://github.com/felixlohmeier/openrefine-client)
|
||||
* [refine-python](https://github.com/maxogden/refine-python)
|
||||
|
||||
### Ruby {#ruby}
|
||||
* [refine-ruby](https://github.com/distillytics/refine-ruby)
|
||||
* The above is a maintained fork of [google-refine](https://github.com/maxogden/refine-ruby)
|
||||
* [google_refine](https://github.com/chengguangnan/google_refine)
|
||||
|
||||
### NodeJS {#nodejs}
|
||||
* [node-openrefine](https://github.com/pm5/node-openrefine)
|
||||
|
||||
### R {#r}
|
||||
* [rrefine](https://cran.r-project.org/web/packages/rrefine/index.html)
|
||||
|
||||
### PHP {#php}
|
||||
* [openrefine-php-client](https://github.com/keboola/openrefine-php-client)
|
||||
|
||||
### Java {#java}
|
||||
* [refine-java](https://github.com/dtap-gmbh/refine-java)
|
||||
|
||||
### Bash {#bash}
|
||||
* [bash-refine.sh](https://gist.github.com/felixlohmeier/d76bd27fbc4b8ab6d683822cdf61f81d) (templates for shell scripts)
|
||||
@ -1,24 +0,0 @@
|
||||
---
|
||||
id: reconciliation-api
|
||||
title: Reconciliation API
|
||||
sidebar_label: Reconciliation API
|
||||
---
|
||||
|
||||
_This is a technical description of the mechanisms behind the reconciliation system in OpenRefine. For usage instructions, see [Reconciliation](/manual/reconciling)._
|
||||
|
||||
A reconciliation service is a web service that, given some text which is a name or label for something, and optionally some additional details, returns a ranked list of potential entities matching the criteria. The candidate text does not have to match each entity's official name perfectly, and that's the whole point of reconciliation--to get from ambiguous text name to precisely identified entities. For instance, given the text "apple", a reconciliation service probably should return the fruit apple, the Apple Inc. company, and New York city (also known as the Big Apple).
|
||||
|
||||
Entities are identified by strong identifiers in some particular identifier space. In the same identifier space, identifiers follow the same syntax. For example, given the string "apple", a reconciliation service might return entities identified by the strings " [Q89](https://www.wikidata.org/wiki/Q89)", "[Q312](https://www.wikidata.org/wiki/Q312)", and "[Q60](https://www.wikidata.org/wiki/Q60)", in the Wikidata ID space. Each reconciliation service can only reconcile to one single identifier space, but several reconciliation services can reconcile to the same identifier space.
|
||||
|
||||
OpenRefine can connect to any reconciliation service which follows the [reconciliation API v0.1](https://reconciliation-api.github.io/specs/0.1/). This was formerly a specification edited by the OpenRefine project, which has now transitioned to its own
|
||||
[W3C Entity Reconciliation Community Group](https://www.w3.org/community/reconciliation/).
|
||||
|
||||
Informally, the main function of any reconciliation service is to find good candidates in the underlying database, given the following data:
|
||||
|
||||
* A string, which is normally the name or title of the entity, in some language.
|
||||
* Optionally, a type which can be used to narrow down the search to entities of this type. OpenRefine does not define a particular set of acceptable types: this choice is left to the reconciliation service (see the suggest API for that).
|
||||
* Optionally, a list of properties and their values, which can be used to refine the search. For instance, when reconciling a database of books, the author name or the publication date are useful bits of information that can be transferred to the reconciliation service. This information will be sent to the reconciliation service if the user binds columns to properties. Again, the notion of property is not predefined in OpenRefine: its definition depends on the reconciliation service.
|
||||
|
||||
See [the specifications of the protocol](https://reconciliation-api.github.io/specs/0.1) for more details about the protocol. You can suggest changes on its [issues tracker](https://github.com/reconciliation-api/specs/issues) or on the [group mailing
|
||||
list](https://lists.w3.org/Archives/Public/public-reconciliation/).
|
||||
|
||||
@ -1,7 +0,0 @@
|
||||
---
|
||||
id: technical-reference-index
|
||||
title: OpenRefine technical reference
|
||||
sidebar_label: Technical Reference Index
|
||||
---
|
||||
|
||||
Technical reference index
|
||||
@ -1,19 +0,0 @@
|
||||
---
|
||||
id: translating-docs
|
||||
title: Translate OpenRefine's documentation
|
||||
sidebar_label: Translate OpenRefine's documentation
|
||||
---
|
||||
|
||||
Our user manual can be translated using [Crowdin](https://crowdin.com/project/openrefine).
|
||||
|
||||
## Getting access to Crowdin
|
||||
|
||||
You need to request access to Crowdin on [our developers mailing list](https://groups.google.com/forum/#!forum/openrefine-dev). You will then be granted translator access on the platform.
|
||||
|
||||
## Publication of translations
|
||||
|
||||
Only the user manual for the current development version is being translated. When we publish a new stable version, we take a snapshot of this and publish it on the website.
|
||||
|
||||
In the meantime the pages you translate will be visible under https://docs.openrefine.org/next/ after a few days.
|
||||
|
||||
|
||||
@ -1,105 +0,0 @@
|
||||
---
|
||||
id: translating-ui
|
||||
title: Translate OpenRefine's interface
|
||||
sidebar_label: Translate OpenRefine's interface
|
||||
---
|
||||
|
||||
Currently supported languages include English, Spanish, Chinese, French, Hebrew, Italian and Japanese.
|
||||
|
||||

|
||||
|
||||
You can help translate OpenRefine into your language by visiting [Weblate](https://hosted.weblate.org/engage/openrefine/?utm_source=widget) which provides a web based UI to edit and add translations and sends automatic pull requests back to our project.
|
||||
|
||||
Click to help translate --> [Weblate](https://hosted.weblate.org/engage/openrefine/?utm_source=widget)
|
||||
|
||||
## Manual translation process {#manual-translation-process}
|
||||
|
||||
Localized strings are entered in a .json file, one per language. They are located in the folder `main/webapp/modules/core/langs/` in a file named `translation-xx`.json, where xx is the language code (i.e. fr for French).
|
||||
|
||||
### Simple case of localized string {#simple-case-of-localized-string}
|
||||
This is an example of a simple string, with the start of the JSON file. This example is for French.
|
||||
```
|
||||
{
|
||||
"name": "Français",
|
||||
"core-index/help": "Aide",
|
||||
(… more lines)
|
||||
}
|
||||
```
|
||||
|
||||
So the key `core-index/help` will render as `"Aide"` in French.
|
||||
|
||||
### Localization with a parameterized value {#localization-with-a-parameterized-value}
|
||||
In this example, the name of the column (represented by `$1` in this example), will be substituted with the string of the name of the column.
|
||||
|
||||
`"core-facets/edit-facet-title": "Cliquez ici pour éditer le nom de la facette\nColonne : $1",`
|
||||
|
||||
### Localization with a singular/plural value {#localization-with-a-singularplural-value}
|
||||
In this example, one of the parameter will have a different string depending if the value is 1 or another value.
|
||||
In this example, the string for page, the second parameter, `$2`, will have an « s » or not depending on the value of `$2`.
|
||||
|
||||
`"core-views/goto-page": "$1 de $2 {{plural:$2|page|pages}}"`
|
||||
|
||||
## Front-end development {#front-end-development}
|
||||
|
||||
The OpenRefine front end has been localized using the [Wikidata jquery.i18n library](https://github.com/OpenRefine/OpenRefine/pull/1285. The localized text is stored in a JSON dictionary on the server and retrieved with a new OpenRefine command.
|
||||
|
||||
### Adding a new string {#adding-a-new-string}
|
||||
|
||||
There should be no hard-coded language strings in the HTML or JSON used for the front end. If you need a new string, first check the existing strings to make sure there isn't an equivalent string, **in an equivalent context**, that you can reuse. Context is important because it can affect how the same literal English text is translated. This cuts down on the amount of text which needs to be translated.
|
||||
|
||||
Strings should be entire sentences or phrases and should include substitution variables for any parameters. Do not concatenate strings in either Java or Javascript (or implicitly by laying them out in a specific order). So, instead of `"You have " + count + " row(s)"` (or worse `count != 1 ? " rows" : " row"`), internationalize everything together so that it can be translated taking into account word ordering and plurals for different languages, ie `"You have $1 {{plural $1: row|rows}}"`, passing the parameter(s) into the `$.i18n` call.
|
||||
|
||||
If there's no string you can reuse, allocate an available key in the appropriate translation dictionary and add the default string, e.g.
|
||||
|
||||
```json
|
||||
...,
|
||||
"section/newkey": "new default string for this key",
|
||||
...
|
||||
```
|
||||
|
||||
and then set the text (or HTML) of your HTML element using i18n helper method. So given an HTML fragment like:
|
||||
```html
|
||||
<label id="new-element-id">[untranslated text would have appeared here before]</label>
|
||||
```
|
||||
we could set its text using:
|
||||
```
|
||||
$('#new-html-element-id').text($.i18n('section/newkey']));
|
||||
```
|
||||
or, if you need to embed HTML tags:
|
||||
```
|
||||
$('#new-html-element-id').html($.i18n('section/newkey']);
|
||||
```
|
||||
|
||||
### Adding a new language {#adding-a-new-language}
|
||||
|
||||
The language dictionaries are stored in the `langs` subdirectory for the module e.g.
|
||||
|
||||
* https://github.com/OpenRefine/OpenRefine/tree/master/main/webapp/modules/core/langs for the main interface
|
||||
* https://github.com/OpenRefine/OpenRefine/tree/master/extensions/gdata/module/langs for google spreadsheet connection
|
||||
* https://github.com/OpenRefine/OpenRefine/tree/master/extensions/database/module/langs for database via JDBC
|
||||
* https://github.com/OpenRefine/OpenRefine/tree/master/extensions/wikidata/module/langs for Wikidata
|
||||
|
||||
To add support for a new language, the easiest way is to do it directly in Weblate. To do it manually, copy `translation-en.json` to `translation-<locale>.json` and have your translator translate all the value strings (ie right hand side).
|
||||
|
||||
#### Main interface {#main-interface}
|
||||
The translation is best done [with Weblate](https://hosted.weblate.org/engage/openrefine/?utm_source=widget). Files are periodically merged by the developer team.
|
||||
|
||||
Run the latest (hopefully cloned from github) version and check whether translated words fit to the layout. Not all items can be translated word by word, especially into non-Ìndo-European languages.
|
||||
|
||||
If you see any text which remains in English even when you have checked all items, please create bug report in the issue tracker so that the developers can fix it.
|
||||
|
||||
#### Extensions {#extensions}
|
||||
|
||||
Extensions can be translated via Weblate just like the core software.
|
||||
|
||||
The new extension for Wikidata contains lots of domain-specific concepts, with which you may not be familiar. The Wikidata may not have reconciliation service for your language. I recommend checking the glossary(https://www.wikidata.org/wiki/Wikidata:Glossary) to be consistent.
|
||||
|
||||
By default, the system tries to load the language file corresponding to the currently in-use browser language. To override this setting a new menu item ("Language Settings") has been added at the index page.
|
||||
To support a new language file, the developer should add a corresponding entry to the dropdown menu in this file: `/OpenRefine/main/webapp/modules/core/scripts/index/lang-settings-ui.html`. The entry should look like:
|
||||
```javascript
|
||||
<option value="<locale>">[Language Label]</option>
|
||||
```
|
||||
|
||||
## Server-side localisation {#server--backend-coding}
|
||||
|
||||
Currently no back end functions are translated, so things like error messages, undo history, etc may appear in English form. Rather than sending raw error text to the front end, it's better to send an error code which is translated into text on the front end. This allows for multiple languages to be supported.
|
||||
@ -1,51 +0,0 @@
|
||||
---
|
||||
id: version-release-process
|
||||
title: How to do an OpenRefine version release
|
||||
sidebar_label: How to do an OpenRefine version release
|
||||
---
|
||||
|
||||
When releasing a new version of Refine, the following steps should be followed:
|
||||
|
||||
1. Make sure the `master` branch is stable and nothing has broken since the previous version. We need developers to stabilize the trunk and some volunteers to try out `master` for a few days.
|
||||
2. Change the version number in [RefineServlet.java](http://github.com/OpenRefine/OpenRefine/blob/master/main/src/com/google/refine/RefineServlet.java#L62) and in the POM files using `mvn versions:set -DnewVersion=2.6-beta -DgenerateBackupPoms=false`. Commit the changes.
|
||||
3. Compose the list of changes in the code and on the wiki. If the issues have been updated with the appropriate milestone, the Github issue tracker should be able to provide a good starting point for this.
|
||||
4. Set up build machine. This needs to be Mac OS X or Linux.
|
||||
5. Download Windows and Mac JREs to bundle them in the Windows and Mac packages from [AdoptOpenJDK](https://adoptopenjdk.net/). You only need the JREs, not the JDKs. Use the lowest version of Java supported (Java 8 currently). Configure the location of these JREs in the `settings.xml` file at the root of the repository. It is important to download recent versions of the JREs as this impacts which HTTPS certificates are accepted by the tool.
|
||||
6. Insert the production Google credentials in https://github.com/OpenRefine/OpenRefine/blob/bc540a880eceb88e54f85ca43eb54769de3bfa4f/extensions/gdata/src/com/google/refine/extension/gdata/GoogleAPIExtension.java#L36-L39 without committing the changes.
|
||||
7. [Build the release candidate kits using the shell script (not just Maven)](https://github.com/OpenRefine/OpenRefine/wiki/Building-OpenRefine-From-Source). This must be done on Mac OS X or Linux to be able to build all 3 kits. On Linux you will need to install the `genisoimage` program first.
|
||||
```shell
|
||||
./refine dist 2.6-beta.2
|
||||
```
|
||||
To build the Windows version with embedded JRE, use `mvn package -s settings.xml -P embedded-jre -DskipTests=true`.
|
||||
|
||||
8. On a Mac machine, compress the Mac `.dmg` (`genisoimage` does not compress it by default) with the following command on a mac machine: `hdiutil convert openrefine-uncompressed.dmg -format UDZO -imagekey zlib-level=9 -o openrefine-3.1-mac.dmg`. If running OS X in a VM, it's probably quicker and more reliable to transfer the kits to the host machine first and then to Github. Finder -> Go -> Connect -> smb://10.0.2.2/. You can then sign the generated DMG file with `codesign -s "Apple Distribution: Code for Science and Society, Inc." openrefine-3.1-mac.dmg`. This requires that you have installed the appropriate certificate on your Mac, see below.
|
||||
|
||||
9. Tag the release candidate in git and push the tag to Github. For example:
|
||||
```shell
|
||||
git tag -a -m "Second beta" 2.6-beta.2
|
||||
git push origin --tags
|
||||
```
|
||||
10. Upload the kits to Github releases [https://github.com/OpenRefine/OpenRefine/releases/](https://github.com/OpenRefine/OpenRefine/releases/) Mention the SHA sums of all uploaded artifacts.
|
||||
11. Announce the beta/release candidate for testing
|
||||
12. Repeat build/release candidate/testing cycle, if necessary.
|
||||
13. Tag the release in git. Build the distributions and upload them.
|
||||
14. [Update the OpenRefine Homebrew cask](https://github.com/OpenRefine/OpenRefine/wiki/Maintaining-OpenRefine's-Homebrew-Cask) or coordinate an update via the [developer list](https://groups.google.com/forum/#!forum/openrefine-dev)
|
||||
15. Verify that the correct versions are shown in the widget at [http://openrefine.org/download](http://openrefine.org/download)
|
||||
16. Announce on the [OpenRefine mailing list](https://groups.google.com/forum/#!forum/openrefine).
|
||||
17. Update the version in master to the next version number with `-SNAPSHOT` (such as `4.3-SNAPSHOT`)
|
||||
```shell
|
||||
mvn versions:set -DnewVersion=4.3-SNAPSHOT
|
||||
```
|
||||
18. If releasing a new major or minor version, create a snapshot of the docs, following [Docusaurus' versioning procedure](https://docusaurus.io/docs/versioning).
|
||||
|
||||
Apple code signing
|
||||
==================
|
||||
|
||||
We have code signing certificates for our iOS distributions. To use them, follow these steps:
|
||||
* Request advisory.committee@openrefine.org to be added to the Apple team: you need to provide the email address that corresponds to your AppleID account;
|
||||
* Create a certificate signing request from your Mac: https://help.apple.com/developer-account/#/devbfa00fef7
|
||||
* Go to https://developer.apple.com/account/resources/certificates/add and select "Apple Distribution" as certificate type
|
||||
* Upload the certificate signing request in the form
|
||||
* Download the generated certificate
|
||||
* Import this certificate in the "Keychain Access" app on your mac
|
||||
* You can now sign code on behalf of the team using the `codesign` utility, such as `codesign -s "Apple Distribution: Code for Science and Society, Inc." openrefine-3.1-mac.dmg`.
|
||||
@ -1,326 +0,0 @@
|
||||
---
|
||||
id: writing-extensions
|
||||
title: Writing Extensions
|
||||
sidebar_label: Writing Extensions
|
||||
---
|
||||
|
||||
## Introduction {#introduction}
|
||||
|
||||
This is a very brief overview of the structure of OpenRefine extensions. For more detailed documentation and step-by-step guides please see the following external documentation/tutorials:
|
||||
|
||||
* Giuliano Tortoreto has [written documentation detailling how to build extension for OpenRefine](https://github.com/giTorto/OpenRefineExtensionDoc/raw/master/main.pdf)
|
||||
* Owen Stephens has written [a guide to developing an extension which adds new GREL functions to OpenRefine](http://www.meanboyfriend.com/overdue_ideas/2017/05/writing-an-extension-to-add-new-grel-functions-to-openrefine/).
|
||||
|
||||
OpenRefine makes use of a modified version of the [Butterfly framework](https://github.com/OpenRefine/simile-butterfly/tree/openrefine) to provide an extension architecture. OpenRefine extensions are Butterfly modules. You don't really need to know about Butterfly itself, but you might encounter "butterfly" here and there in the code base.
|
||||
|
||||
Extensions that come with the code base are located under [the extensions subdirectory](https://github.com/OpenRefine/OpenRefine/tree/master/extensions), but when you develop your own extension, you can put its code anywhere as long as you point Butterfly to it. That is done by any one of the following methods
|
||||
|
||||
* refer to your extension's directory in [the butterfly.properties file](https://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/WEB-INF/butterfly.properties) through a `butterfly.modules.path` setting.
|
||||
* specify the butterfly.modules.path property on the command line when you run OpenRefine. This overrides the values in the property file, so you need to include the default values first e.g. `-Dbutterfly.modules.path=modules,../../extensions,/path/to/your/extension`
|
||||
|
||||
Please note that you should bundle any dependencies yourself, so you are insulated from OpenRefine packaging changes over time.
|
||||
|
||||
### Directory Layout {#directory-layout}
|
||||
|
||||
A OpenRefine extension sits in a file directory that contains the following files and sub-directories:
|
||||
|
||||
```
|
||||
pom.xml
|
||||
src/
|
||||
com/foo/bar/... *.java source files
|
||||
module/
|
||||
*.html, *.vt files
|
||||
scripts/... *.js files
|
||||
styles/... *.css and *.less files
|
||||
images/... image files
|
||||
MOD-INF/
|
||||
lib/*.jar files
|
||||
classes/... java class files
|
||||
module.properties
|
||||
controller.js
|
||||
```
|
||||
|
||||
The file named module.properties (see [example](https://github.com/OpenRefine/OpenRefine/blob/master/extensions/sample/module/MOD-INF/module.properties)) contains the extension's metadata. Of importance is the name field, which gives the extension a name that's used in many other places to refer to it. This can be different from the extension's directory name.
|
||||
|
||||
```
|
||||
name = my-extension-name
|
||||
```
|
||||
|
||||
Your extension's client-side resources (.html, .js, .css files) stored in the module/ subdirectory will be accessible from http://127.0.0.1:3333/extension/my-extension-name/ when OpenRefine is running.
|
||||
|
||||
Also of importance is the dependency
|
||||
|
||||
```
|
||||
requires = core
|
||||
```
|
||||
|
||||
which makes sure that the core module of OpenRefine is loaded before the extension attempts to hook into it.
|
||||
|
||||
The file named controller.js is responsible for registering the extension's hooks into OpenRefine. Look at the sample-extension extension's [controller.js](https://github.com/OpenRefine/OpenRefine/blob/master/extensions/sample/module/MOD-INF/controller.js) file for an example. It should have a function called init() that does the hook registrations.
|
||||
|
||||
The `pom.xml` file is an [Apache Maven](http://maven.apache.org/) build file. You can make a copy of the sample extension's `pom.xml` file to get started. The important point here is that the Java classes should be built into the `module/MOD-INF/classes` sub-directory.
|
||||
|
||||
Note that your extension's Java code would need to reference some libraries used in OpenRefine and OpenRefine's Java classes themselves. These dependencies are reflected in the Maven configuration for the extension.
|
||||
|
||||
## Sample extension {#sample-extension}
|
||||
|
||||
The sample extension is included in the code base so that you can copy it and get started on writing your own extension. After you copy it, make sure you change its name inside its `module/MOD-INF/controller.js` file.
|
||||
|
||||
### Basic Structure {#basic-structure}
|
||||
|
||||
The sample extension's code is in `refine/extensions/sample/`. In that directory, Java source code is contained under the `src` sub-directory, and webapp code is under the `module` sub-directory. Here is the full directory layout:
|
||||
|
||||
```
|
||||
refine/extensions/sample/
|
||||
build.xml (ant build script)
|
||||
src/
|
||||
com/google/refine/sampleExtension/
|
||||
... Java source code ...
|
||||
module/
|
||||
MOD-INF/
|
||||
module.properties (module settings)
|
||||
controller.js (module init and routing logic in Javascript)
|
||||
classes/
|
||||
... compiled Java classes ...
|
||||
lib/
|
||||
... Java jars ...
|
||||
... velocity templates (.vt) ...
|
||||
... LESS css files ...
|
||||
... client-side files (.html, .css, .js, image files) ...
|
||||
```
|
||||
|
||||
The sub-directory `MOD-INF` contains the Butterfly module's metadata and is what Butterfly looks for when it scans directories for modules. `MOD-INF` serves similar functions as `WEB-INF` in other web frameworks.
|
||||
|
||||
Java code is built into the sub-directory `classes` inside `MOD-INF`, and supporting external Java jars are in the `lib` sub-directory. Those will be automatically loaded by Butterfly. (The build.xml script is wired to compile into the `classes` sub-directory.)
|
||||
|
||||
Client-side code is in the inner `module` sub-directory. They can be plain old .html, .css, .js, and image files, or they can be [LESS](http://lesscss.org/) files that get processed into CSS. There are also Velocity .vt files, but they need to be routed inside `MOD-INF/controller.js`.
|
||||
|
||||
`MOD-INF/controller.js` lets you configure the extension's initialization and URL routing in Javascript rather than in Java. For example, when the requested URL path is either `/` or an empty string, we process and return `MOD-INF/index.vt` ( [see http://127.0.0.1:3333/extension/sample/](http://127.0.0.1:3333/extension/sample/) if OpenRefine is running).
|
||||
|
||||
The `init()` function in `controller.js` allows the extension to register various client-side handlers for augmenting pages served by Refine's core. These handlers are feature-specific. For example, [this is where the jython extension adds its parser](https://github.com/OpenRefine/OpenRefine/blob/master/extensions/jython/module/MOD-INF/controller.js#L46). As for the sample extension, it adds its script `project-injection.js` and style `project-injection.less` into the `/project` page. If you [view the source of the /project page](http://127.0.0.1:3333/project), you will see references to those two files.
|
||||
|
||||
### Wiring Up the Extension {#wiring-up-the-extension}
|
||||
|
||||
The Extensions are loaded by the Butterfly framework. Butterfly refers to these as 'modules'. [The location of modules is set in the `main/webapp/butterfly.properties` file](https://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/WEB-INF/butterfly.properties#L27). Butterfly simply descends into each of those paths and looks for any `MOD-INF` directories.
|
||||
|
||||
For more information, see [Extension Points](https://github.com/OpenRefine/OpenRefine/wiki/Extension-Points).
|
||||
|
||||
## Extension points {#extension-points}
|
||||
|
||||
### Client-side: Javascript and CSS {#client-side-javascript-and-css}
|
||||
|
||||
The UI in OpenRefine for working with a project is coded in [the /main/webapp/modules/core/project.vt file](http://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/modules/core/project.vt). The file is quite small, and that's because almost all of its content is to be expanded dynamically through the Velocity variables $scriptInjection and $styleInjection. So that your own Javascript and CSS files get loaded, you need to register them with the ClientSideResourceManager, which is done in the /module/MOD-INF/controller.js file. See [the controller.js file in this sample extension code](http://github.com/OpenRefine/OpenRefine/blob/master/extensions/sample/module/MOD-INF/controller.js) for an example.
|
||||
|
||||
In the registration call, the variable `module` is already available to your code by default, and it refers to your own extension.
|
||||
|
||||
```
|
||||
ClientSideResourceManager.addPaths(
|
||||
"project/scripts",
|
||||
module,
|
||||
[
|
||||
"scripts/foo.js",
|
||||
"scripts/subdir/bar.js"
|
||||
]
|
||||
);
|
||||
```
|
||||
|
||||
You can specify one or more files for registration, and their paths are relative to the `module` subdirectory of your extension. They are included in the order listed.
|
||||
|
||||
Javascript Bundling: Note that `project.vt` belongs to the core module and is thus under the control of the core module's [controller.js file](http://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/modules/core/MOD-INF/controller.js). The Javascript files to be included in `project.vt` are by default bundled together for performance. When debugging, you can prevent this bundling behavior by setting `bundle` to `false` near the top of that `controller.js` file. (If you have commit access to this code base, be sure not to check that change in.)
|
||||
|
||||
### Client-side: Images {#client-side-images}
|
||||
|
||||
We recommend that you always refer to images through your CSS files rather than in your Javascript code. URLs to images will thus be relative to your CSS files, e.g.,
|
||||
|
||||
```
|
||||
.foo {
|
||||
background: url(../images/x.png);
|
||||
}
|
||||
```
|
||||
|
||||
If you really really absolutely need to refer to your images in your Javascript code, then look up your extension's URL path in the global Javascript variable `ModuleWirings`:
|
||||
|
||||
```
|
||||
ModuleWirings["my-extension"] + "images/x.png"
|
||||
```
|
||||
|
||||
### Client-side: HTML Templates {#client-side-html-templates}
|
||||
|
||||
Beside Javascript, CSS, and images, your extension might also include HTML templates that get loaded on the fly by your Javascript code and injected into the page's DOM. For example, here is [the Cluster edit dialog template](http://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/modules/core/scripts/dialogs/clustering-dialog.html), which gets loaded by code in [the equivalent javascript file 'clustering-dialog.js'](http://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/modules/core/scripts/dialogs/clustering-dialog.js):
|
||||
|
||||
```
|
||||
var dialog = $(DOM.loadHTML("core", "scripts/dialogs/clustering-dialog.html"));
|
||||
```
|
||||
|
||||
`DOM.loadHTML` returns the content of the file as a string, and `$(...)` turns it into a DOM fragment. Where `"core"` is, you would want your extension's name. The path of the HTML file is relative to your extension's `module` subdirectory.
|
||||
|
||||
### Client-side: Project UI Extension Points {#client-side-project-ui-extension-points}
|
||||
|
||||
Getting your extension's Javascript code included in `project.vt` doesn't accomplish much by itself unless your code also registers hooks into the UI. For example, you can surely implement an exporter in Javascript, but unless you add a corresponding menu command in the UI, your user can't use your exporter.
|
||||
|
||||
#### Main Menu {#main-menu}
|
||||
|
||||
The main menu can be extended by calling any one of the methods `MenuBar.appendTo`, `MenuBar.insertBefore`, and `MenuBar.insertAfter`. Each method takes 2 arguments: an array of strings that identify a particular existing menu item or submenu, and one new single menu item or submenu or an array of menu items and submenus. For example, to insert 2 menu items and a menu separator before the menu item Project > Export Filtered Rows > Templating..., write this Javascript code wherever that would execute when your Javascript files get loaded:
|
||||
|
||||
```
|
||||
MenuBar.insertBefore(
|
||||
["core/project", "core/export", "core/export-templating"],
|
||||
[
|
||||
{
|
||||
"label":"Menu item 1",
|
||||
"click": function() { ... }
|
||||
},
|
||||
{
|
||||
"label":"Menu item 2",
|
||||
"click": function() { ... }
|
||||
},
|
||||
{} // separator
|
||||
]
|
||||
);
|
||||
```
|
||||
|
||||
The array `["core/project", "core/export", "core/export-templating"]` pinpoints the reference menu item.
|
||||
|
||||
See the beginning of [/main/webapp/modules/core/scripts/project/menu-bar.js](http://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/modules/core/scripts/project/menu-bar.js) for IDs of menu items and submenus.
|
||||
|
||||
#### Column Header Menu {#column-header-menu}
|
||||
|
||||
The drop-down menu of each column can also be extended, but the mechanism is slightly different compared to the main menu. Because the drop-down menu for a particular column is constructed on the fly when the user actually clicks the drop-down menu button, extending the column header menu can't really be done once at start-up time, but must be done every time a column header menu gets created. So, registration in this case involves providing a function that gets called each such time:
|
||||
|
||||
```
|
||||
DataTableColumnHeaderUI.extendMenu(function(column, columnHeaderUI, menu) { ... do stuff to menu ... });
|
||||
```
|
||||
|
||||
That function takes in the column object (which contains the column's name), the column header UI object (generally not so useful), and the menu to extend. In the previous code line where it says "do stuff to menu", you can write something like this:
|
||||
|
||||
```
|
||||
MenuSystem.appendTo(menu, ["core/facet"], [
|
||||
{
|
||||
id: "core/text-facet",
|
||||
label: "My Facet on " + column.name,
|
||||
click: function() {
|
||||
... use column.name and do something ...
|
||||
}
|
||||
},
|
||||
]);
|
||||
```
|
||||
|
||||
In addition to `MenuSystem.appendTo`, you can also call `MenuSystem.insertBefore` and `MenuSystem.insertAfter` which the same 3 arguments. To see what IDs you can use, see the function `DataTableColumnHeaderUI.prototype._createMenuForColumnHeader` in [/main/webapp/modules/core/scripts/views/data-table/column-header-ui.js](http://github.com/OpenRefine/OpenRefine/blob/master/main/webapp/modules/core/scripts/views/data-table/column-header-ui.js).
|
||||
|
||||
### Server-side: Ajax Commands {#server-side-ajax-commands}
|
||||
|
||||
The client-side of OpenRefine gets things done by calling AJAX commands on the server-side. These commands must be registered with the OpenRefine servlet, so that the servlet knows how to route AJAX calls from the client-side. This can be done inside the `init` function in your extension's `controller.js` file, e.g.,
|
||||
|
||||
```
|
||||
function init() {
|
||||
var RefineServlet = Packages.com.google.refine.RefineServlet;
|
||||
RefineServlet.registerCommand(module, "my-command", new Packages.com.foo.bar.MyCommand());
|
||||
}
|
||||
```
|
||||
|
||||
Your command will then be accessible at [http://127.0.0.1:3333/command/my-extension/my-command](http://127.0.0.1:3333/command/my-extension/my-command).
|
||||
|
||||
### Server-side: Operations {#server-side-operations}
|
||||
|
||||
Most commands change the project's data. Most of them do so by creating abstract operations. See the Changes, History, Processes, and Operations section of the [Server Side Architecture](https://github.com/OpenRefine/OpenRefine/wiki/Server-Side-Architecture) document.
|
||||
|
||||
You can register an operation **class** in the `init` function as follows:
|
||||
|
||||
```
|
||||
Packages.com.google.refine.operations.OperationRegistry.registerOperation(
|
||||
module,
|
||||
"operation-name",
|
||||
Packages.com.foo.bar.MyOperation
|
||||
);
|
||||
```
|
||||
|
||||
Do not call `new` to construct an operation instance. You must register the class itself. The class should have a static function for reconstructing an operation instance from a JSON blob:
|
||||
|
||||
```
|
||||
static public AbstractOperation reconstruct(Project project, JSONObject obj) throws Exception {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
### Server-side: GREL {#server-side-grel}
|
||||
|
||||
GREL can be extended with new functions. This is also done in the `init` function in `controller.js`, e.g.,
|
||||
|
||||
```
|
||||
Packages.com.google.refine.grel.ControlFunctionRegistry.registerFunction(
|
||||
"functionName", new Packages.com.foo.bar.TheFunctionClass());
|
||||
```
|
||||
|
||||
You might also want to provide new variables (beyond just `value`, `cells`, `row`, etc.) available to expressions. This is done by registering a binder that implements the interface `com.google.refine.expr.Binder`:
|
||||
|
||||
```
|
||||
Packages.com.google.refine.expr.ExpressionUtils.registerBinder(
|
||||
new Packages.com.foo.bar.MyBinder());
|
||||
```
|
||||
|
||||
### Server-side: Importers {#server-side-importers}
|
||||
|
||||
You can register an importer as follows:
|
||||
|
||||
```
|
||||
Packages.com.google.refine.importers.ImporterRegistry.registerImporter(
|
||||
"importer-name", new Packages.com.foo.bar.MyImporter());
|
||||
```
|
||||
|
||||
The string `"importer-name"` isn't important at all. It's not really related to file extension or mime-type. Just use something unique. Your importer will be explicitly called to test if it can import something.
|
||||
|
||||
### Server-side: Exporters {#server-side-exporters}
|
||||
|
||||
You can register an exporter as follows:
|
||||
|
||||
```
|
||||
Packages.com.google.refine.exporters.ExporterRegistry.registerExporter(
|
||||
"exporter-name", new Packages.com.foo.bar.MyExporter());
|
||||
```
|
||||
|
||||
The string `"exporter-name"` isn't important at all. It's only used by the client-side to tell the server-side which exporter to use. Just use something unique and, of course, relevant.
|
||||
|
||||
### Server-side: Overlay Models {#server-side-overlay-models}
|
||||
|
||||
Overlay models are objects attached onto a core Project object to store and manage additional data for that project. For example, the schema alignment skeleton is managed by the Protograph overlay model. An overlay model implements the interface `com.google.refine.model.OverlayModel` and can be registered like so:
|
||||
|
||||
```
|
||||
Packages.com.google.refine.model.Project.registerOverlayModel(
|
||||
"model-name",
|
||||
Packages.com.foo.bar.MyOverlayModel);
|
||||
```
|
||||
|
||||
Note that you register the **class** , not an instance. The class should implement the following static method for reconstructing an overlay model instance from a JSON blob:
|
||||
|
||||
```
|
||||
static public OverlayModel reconstruct(JSONObject o) throws JSONException {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
When the project gets saved, the overlay model instance's `write` method will be called:
|
||||
|
||||
```
|
||||
public void write(JSONWriter writer, Properties options) throws JSONException {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
### Server-side: Scripting Languages {#server-side-scripting-languages}
|
||||
|
||||
A scripting language (such as Jython) can be registered as follows:
|
||||
|
||||
```
|
||||
Packages.com.google.refine.expr.MetaParser.registerLanguageParser(
|
||||
"jython",
|
||||
"Jython",
|
||||
Packages.com.google.refine.jython.JythonEvaluable.createParser(),
|
||||
"return value"
|
||||
);
|
||||
```
|
||||
|
||||
The first string is the prefix that gets prepended to each expression so that we know which language the expression is in. This should be short, unique, and identifying. The second string is a user-friendly name of the language. The third is an object that implements the interface `com.google.refine.expr.LanguageSpecificParser`. The final string is the default expression in that language that would return the cell's value.
|
||||
|
||||
In 2018 we are making important changes to OpenRefine to modernize it, for the benefit of users and contributors. This page describes the changes that impact developers of extensions or forks and is intended to minimize the effort required on their end to follow the transition. The instructions are written specifically with extension maintainers in mind, but fork maintainers should also find it useful.
|
||||
|
||||
This document describes the migrations in the order they are committed to the master branch. This means that it should be possible to perform each migration in turn, with the ability to run the software between each stage by checking out the appropriate git commit.
|
||||
@ -1,129 +0,0 @@
|
||||
module.exports = {
|
||||
onBrokenLinks: 'throw',
|
||||
onBrokenMarkdownLinks: 'throw',
|
||||
title: 'OpenRefine',
|
||||
tagline: 'A power tool for working with messy data.',
|
||||
url: 'https://docs.openrefine.org/',
|
||||
baseUrl: '/',
|
||||
favicon: 'img/openrefine_logo.png',
|
||||
organizationName: 'OpenRefine', // Usually your GitHub org/user name.
|
||||
projectName: 'OpenRefine', // Usually your repo name.
|
||||
i18n: {
|
||||
defaultLocale: 'en',
|
||||
locales: ['en', 'jp', 'fr'],
|
||||
},
|
||||
themeConfig: {
|
||||
navbar: {
|
||||
title: 'OpenRefine Documentation',
|
||||
logo: {
|
||||
alt: 'OpenRefine diamond logo',
|
||||
src: 'img/openrefine_logo.png',
|
||||
},
|
||||
items: [
|
||||
{
|
||||
to: '/',
|
||||
activeBasePath: 'docs',
|
||||
label: 'User Manual',
|
||||
position: 'left',
|
||||
},
|
||||
{
|
||||
to: 'technical-reference/technical-reference-index',
|
||||
label: 'Technical Reference',
|
||||
position: 'left'
|
||||
},
|
||||
{
|
||||
type: 'localeDropdown',
|
||||
position: 'right',
|
||||
},
|
||||
{
|
||||
href: 'https://github.com/OpenRefine/OpenRefine/edit/master/docs',
|
||||
'aria-label': 'GitHub',
|
||||
className: 'header-github-link',
|
||||
position: 'right',
|
||||
},
|
||||
],
|
||||
},
|
||||
algolia: {
|
||||
apiKey: '591fc612419d2e5b6bee6822cc17064f',
|
||||
indexName: 'openrefine',
|
||||
contextualSearch: true,
|
||||
},
|
||||
footer: {
|
||||
logo: {
|
||||
alt: 'OpenRefine diamond logo',
|
||||
src: 'img/openrefine_logo.png',
|
||||
href: 'https://docs.openrefine.org',
|
||||
},
|
||||
style: 'dark',
|
||||
links: [
|
||||
{
|
||||
title: 'Community',
|
||||
items: [
|
||||
{
|
||||
label: 'Mailing List',
|
||||
href: 'http://groups.google.com/group/openrefine/'
|
||||
},
|
||||
{
|
||||
label: 'Gitter Chat',
|
||||
href: 'https://gitter.im/OpenRefine/OpenRefine',
|
||||
},
|
||||
{
|
||||
label: 'Twitter',
|
||||
href: 'https://twitter.com/openrefine',
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'More',
|
||||
items: [
|
||||
{
|
||||
label: 'Official Website',
|
||||
href: 'https://openrefine.org',
|
||||
},
|
||||
{
|
||||
label: 'GitHub',
|
||||
href: 'https://github.com/OpenRefine/OpenRefine',
|
||||
},
|
||||
],
|
||||
},
|
||||
],
|
||||
copyright: `Copyright © ${new Date().getFullYear()} OpenRefine contributors`,
|
||||
},
|
||||
},
|
||||
themes: [],
|
||||
plugins: [],
|
||||
presets: [
|
||||
[
|
||||
'@docusaurus/preset-classic',
|
||||
{
|
||||
docs: {
|
||||
// Docs folder path relative to website dir. Equivalent to `customDocsPath`.
|
||||
// path: 'docs',
|
||||
// Sidebars file relative to website dir.
|
||||
sidebarPath: require.resolve('./sidebars.js'),
|
||||
// Equivalent to `editUrl` but should point to `website` dir instead of `website/docs`.
|
||||
editUrl: 'https://github.com/OpenRefine/OpenRefine/edit/master/docs',
|
||||
// Equivalent to `docsUrl`.
|
||||
routeBasePath: '/',
|
||||
// Remark and Rehype plugins passed to MDX. Replaces `markdownOptions` and `markdownPlugins`.
|
||||
remarkPlugins: [],
|
||||
rehypePlugins: [],
|
||||
// Equivalent to `enableUpdateBy`.
|
||||
showLastUpdateAuthor: true,
|
||||
// Equivalent to `enableUpdateTime`.
|
||||
showLastUpdateTime: true,
|
||||
},
|
||||
theme: {
|
||||
customCss: require.resolve('./src/css/custom.css'),
|
||||
},
|
||||
},
|
||||
],
|
||||
],
|
||||
scripts: [
|
||||
{
|
||||
src: '/js/fix-location.js',
|
||||
async: false,
|
||||
defer: false,
|
||||
},
|
||||
],
|
||||
};
|
||||
@ -1,9 +0,0 @@
|
||||
|
||||
# Note: this file's config overrides the Netlify UI admin config
|
||||
|
||||
[context.production]
|
||||
command = "yarn netlify:build:production"
|
||||
|
||||
[context.deploy-preview]
|
||||
command = "yarn netlify:build:deployPreview"
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user