{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Przygotowali\n",
"Wojciech Jarmosz
\n",
"Michał Kubiak
\n",
"Przemysław Owczarczyk"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Temat:\n",
"Klasyfikacja za pomocą naiwnej metody bayesowskiej (rozkłady dyskretne). Implementacja powinna założyć, że cechy są dyskretne/jakościowe. Na wejściu oczekiwany jest zbiór, który zawiera p-cech dyskretnych/jakościowych, wektor etykiet oraz wektor prawdopodobieństw a priori dla klas. Na wyjściu otrzymujemy prognozowane etykiety oraz prawdopodobieństwa a posteriori. Dodatkową wartością odpowiednia wizualizacja."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Wstęp\n",
"Jednym z najbardziej użytecznych zastosowań twierdzenia Bayesa jest tzw. naiwny klasyfikator bayesowski - \n",
"Prosty klasyfikator probabilistyczny. Naiwne klasyfikatory bayesowskie są oparte na założeniu o wzajemnej niezależności predyktorów (zmiennych niezależnych). Często nie mają one żadnego związku z rzeczywistością i właśnie z tego powodu nazywa się je naiwnymi. Klasyfikator ten można wykorzystywać do określania prawdopodobieństwa klas na podstawie szeregu różnych obserwacji."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Pomimo swojego naiwnego charakteru naiwna metoda bayesowska zwykle dobrze się sprawdza w praktyce. Jest to odpowiedni przykład obrazujący, co oznacza popularne w statystyce powiedzenie „wszystkie modele są złe, ale niektóre są użyteczne” (za autora tego powiedzenia uznaje się na ogół statystyka George'a E.P. Boxa)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Założenie naiwnego bayesa\n",
"$P(class | variable1, variable2, variable3) = \\frac{P(variable1, variable2, valriable3|class) * P(class)}{P(variable1, variable2, variable3)}$\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**przy założeniu o niezależności zmiennych losowych $variable1$, $variable2$, $variable3$**:\n",
"\n",
"\n",
"$P(variable1, variable2, variable3|class) = P(variable1|class)* P(variable2|class) * P(variable3|class)$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**ostatecznie:**\n",
"\n",
"\n",
"$P(class | variable1, variable2, variable3) = \\frac{P(variable1|class)* P(variable2|class) * P(variable3|class) * P(class)}{\\sum_k{P(variable1|class_k)* P(variable2|class_k) * P(variable3|class_k) * P(class_k)}}$\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# DataSet\n",
"Według Światowej Organizacji Zdrowia (WHO) udar to druga najczęstsza przyczyna zgonów na świecie, odpowiedzialna za około 11% wszystkich zgonów. Ten zestaw danych jest używany do przewidywania, czy pacjent prawdopodobnie dostanie udaru, na podstawie parametrów wejściowych, takich jak płeć, wiek, różne choroby. \n",
"https://www.kaggle.com/fedesoriano/stroke-prediction-dataset"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Wizualizacja"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"𝑎𝑔𝑒:60−69
\n",
"ℎ𝑦𝑝𝑒𝑟𝑡𝑒𝑛𝑠𝑖𝑜𝑛:𝑛𝑜
\n",
"ℎ𝑒𝑎𝑟𝑡_𝐷𝑖𝑠𝑒𝑎𝑠𝑒𝑦𝑒𝑠
\n",
"𝑏𝑚𝑖:𝑜𝑏𝑒𝑠𝑖𝑡𝑦_1
\n",
"𝑔𝑒𝑛𝑑𝑒𝑟:𝑓𝑒𝑚𝑎𝑙𝑒
\n",
"𝑠𝑚𝑜𝑘𝑖𝑛𝑔𝑠𝑡𝑎𝑡𝑢𝑠:𝑠𝑚𝑜𝑘𝑒𝑠"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"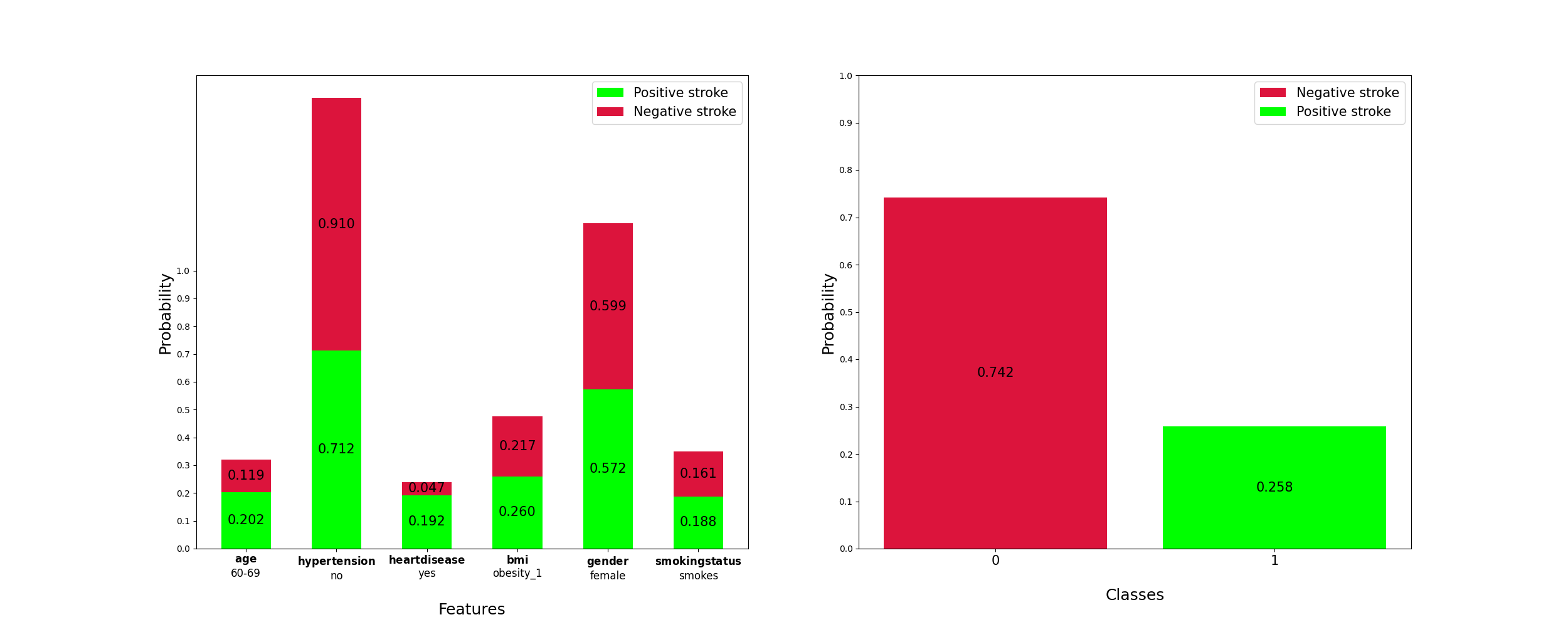"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"𝑎𝑔𝑒:70−79
\n",
"ℎ𝑦𝑝𝑒𝑟𝑡𝑒𝑛𝑠𝑖𝑜𝑛: yes
\n",
"ℎ𝑒𝑎𝑟𝑡_𝐷𝑖𝑠𝑒𝑎𝑠𝑒: 𝑦𝑒𝑠
\n",
"𝑏𝑚𝑖:correct
\n",
"𝑔𝑒𝑛𝑑𝑒𝑟:𝑚𝑎𝑙𝑒
\n",
"𝑠𝑚𝑜𝑘𝑖𝑛𝑔𝑠𝑡𝑎𝑡𝑢𝑠:never_𝑠𝑚𝑜𝑘𝑒d"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"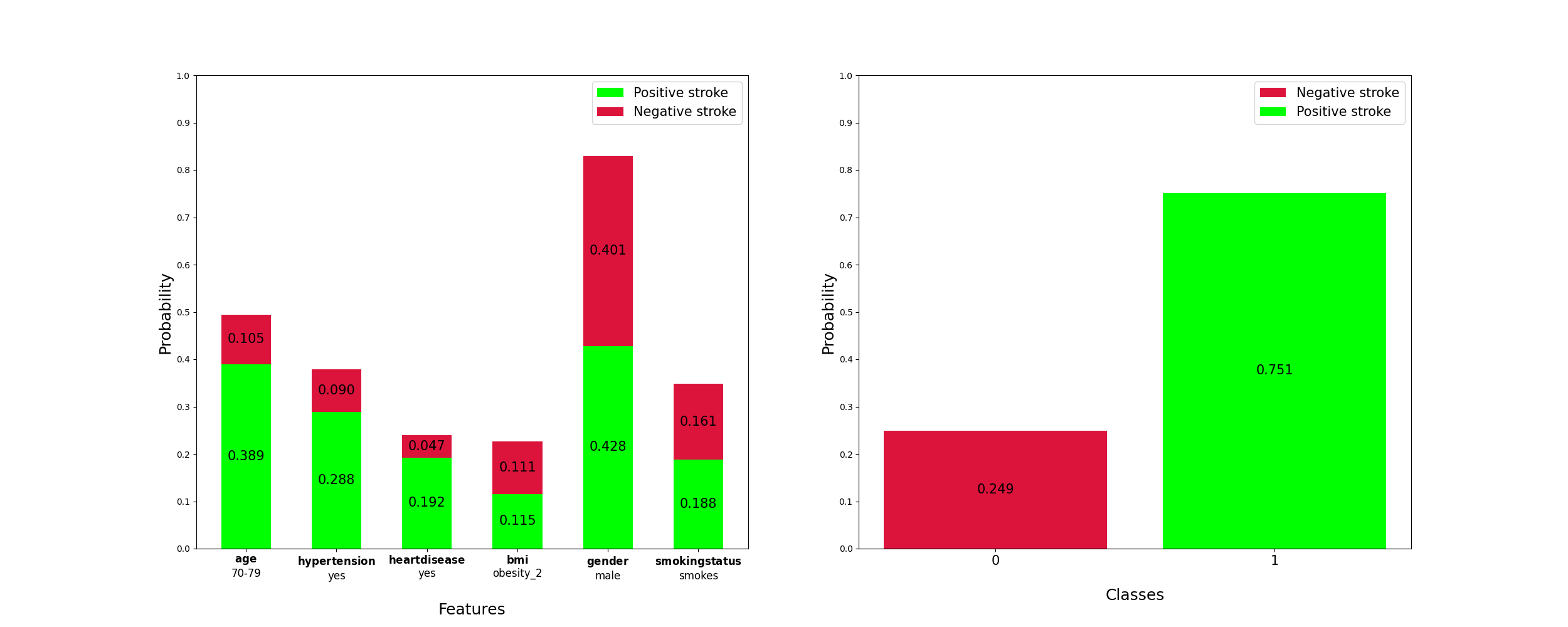"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"𝑎𝑔𝑒:70−79
\n",
"ℎ𝑦𝑝𝑒𝑟𝑡𝑒𝑛𝑠𝑖𝑜𝑛: yes
\n",
"ℎ𝑒𝑎𝑟𝑡_𝐷𝑖𝑠𝑒𝑎𝑠𝑒: 𝑦𝑒𝑠
\n",
"𝑏𝑚𝑖:correct
\n",
"𝑔𝑒𝑛𝑑𝑒𝑟:fe𝑚𝑎𝑙𝑒
\n",
"𝑠𝑚𝑜𝑘𝑖𝑛𝑔𝑠𝑡𝑎𝑡𝑢𝑠:never_𝑠𝑚𝑜𝑘𝑒d"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"𝑎𝑔𝑒:30−39
\n",
"ℎ𝑦𝑝𝑒𝑟𝑡𝑒𝑛𝑠𝑖𝑜𝑛: no
\n",
"ℎ𝑒𝑎𝑟𝑡_𝐷𝑖𝑠𝑒𝑎𝑠𝑒: 𝑦𝑒𝑠
\n",
"𝑏𝑚𝑖: obesity_2
\n",
"avg_glucose_level: 250-270\n",
"𝑔𝑒𝑛𝑑𝑒𝑟:fe𝑚𝑎𝑙𝑒
\n",
"𝑠𝑚𝑜𝑘𝑖𝑛𝑔𝑠𝑡𝑎𝑡𝑢𝑠:smokes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"𝑎𝑔𝑒:0-29
\n",
"ℎ𝑦𝑝𝑒𝑟𝑡𝑒𝑛𝑠𝑖𝑜𝑛: no
\n",
"ℎ𝑒𝑎𝑟𝑡_𝐷𝑖𝑠𝑒𝑎𝑠𝑒: no
\n",
"𝑏𝑚𝑖: correct
\n",
"avg_glucose_level: 130-170\n",
"𝑔𝑒𝑛𝑑𝑒𝑟:𝑚𝑎𝑙𝑒
\n",
"𝑠𝑚𝑜𝑘𝑖𝑛𝑔𝑠𝑡𝑎𝑡𝑢𝑠:never_smoked"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"𝑎𝑔𝑒:80-89
\n",
"ℎ𝑦𝑝𝑒𝑟𝑡𝑒𝑛𝑠𝑖𝑜𝑛: yes
\n",
"ℎ𝑒𝑎𝑟𝑡_𝐷𝑖𝑠𝑒𝑎𝑠𝑒: no
\n",
"𝑏𝑚𝑖: correct
\n",
"avg_glucose_level: 130-170\n",
"𝑔𝑒𝑛𝑑𝑒𝑟:𝑚𝑎𝑙𝑒
\n",
"𝑠𝑚𝑜𝑘𝑖𝑛𝑔𝑠𝑡𝑎𝑡𝑢𝑠:never_smoked"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"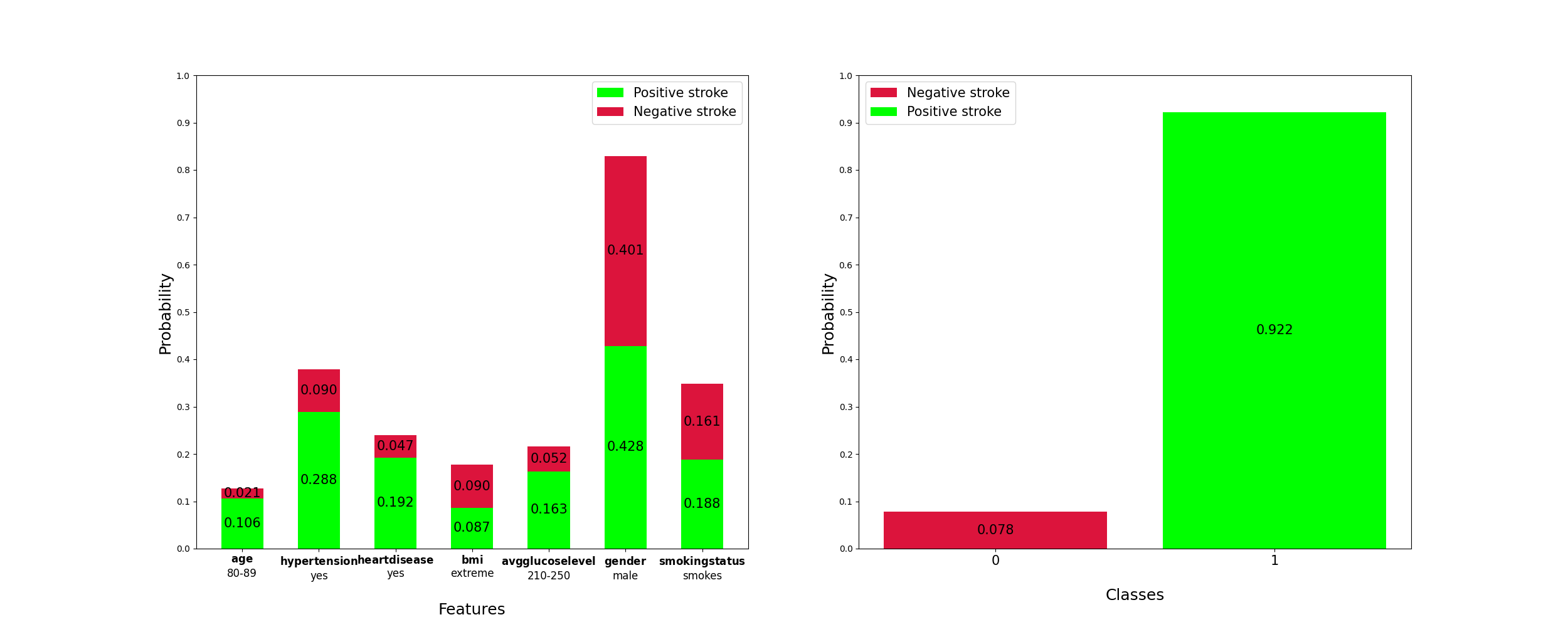"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.5"
}
},
"nbformat": 4,
"nbformat_minor": 4
}