{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Wstęp do zajęć\n",
"\n",
"Niniejsze zajęcia poświęcone są chmurze obliczeniowej w modelu PaaS (Platform as a Service). Podstawowe informacje na temat tego modelu zostały przedstawione na wcześniejszych zajęciach. Do kluczowych cech usług w tym modelu należą:\n",
"* brak konieczności zarządzania systemem operacyjnym i zainstalowanym środowiskiem uruchomieniowym\n",
"* wysoki stopień automatyzacji, znaczna część konfiguracji odbywa się poprzez ustawienia domyślne i konwencję\n",
"* konieczność dopasowania aplikacji do wymagań platformy uruchomieniowej\n",
"* ograniczony dostep do pewnych zasobów np. brak możliwości zapisu plików, ograniczenie komunikacji do protokołu HTTP\n",
"\n",
"Dostępnych jest wiele usług działających w tym modelu PaaS. Do najpopularniejszych należą:\n",
"\n",
"* Google App Engine - historycznie pierwsza taka usługa, która przetrwała do dziś\n",
"* Amazon AWS Elastic Beanstalk - w pewnym sensie jest to nakładka na usługę AWS EC2\n",
"* Microsoft Azure App Service\n",
"* Salesforce Heroku - jeden z pierwszych i wciąż najpopularniejszy dostawca usług tego typu\n",
"* DigitalOcean App Platform\n",
"* Red Hat OpenShift PaaS\n",
"* The Mendix Low-Code Platform\n",
"* Dev Graph Engine Yard\n",
"\n",
"W czasie zajęć poznamy platformę **Heroku**, która bardzo dobrze obrazuje możliwości oferowane przez model PaaS. Co ważne, w odróżnieniu od wielu dostawców, Heroku oferuje tylko usługę w modelu PaaS.\n",
"\n",
"## Na czym polega PaaS\n",
"\n",
"Model chmury obliczeniowej PaaS zakłada przeniesienie na dostawcę usługi odpowiedzialności za praktycznie wszyskie elementy środowiska, w którym działa aplikacja. Dostawca oprócz sprzętu i infrastruktury, dostarcza system operacyjny, bazy danych oraz środowisko uruchomieniowe dla naszej aplikacji. \n",
"\n",
"W modelu tym tworzona aplikacja najczęściej musi być odpowiednio przygotowana aby mogła zostać uruchomiona w ściśle kontrolowanym środowisku. W początkowych etapach rozwoju był to chyba najczęściej podnoszony argument przeciw takiemu rozwiązaniu. Ścisłe związanie tworzonego oprogramowania z dostawcą usługi było postrzegane jako istotne ograniczenie i zagrożenie dla projektów informatycznych. Wraz z globalnym wzrostem wykorzystania usług chmury obliczeniowej wzrosła również akceptacja dla zwiększenia stopnia powiązania oprogramowania z dostawcą usług (ang. vendor lockin).\n",
"\n",
"Z drugiej strony sam stopień powiązania aplikacji z platformą uległ znacznemu zmniejszeniu. Obecnie większość usług działąjących w modelu PaaS (np. Heroku), pozwala uruchomić niemal dowolną aplikację, napisaną w dowolnej technologi, nawet jeśli nie była ona projektowana specjalnie z myślą o wdrożeniu w chmurze.\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Jak działa Platform as a Service\n",
"\n",
"W następującej części omówiona zostanie zasada działania usługi typu PaaS na przykładzie Heroku. Heroku jest bardzo reprezentatywne dla tego typu usług, dzięki czemu wiedzę tę będzie można zastosować do większości dostępnych usług tego typu.\n",
"\n",
"Zasadę działania Heroku można przedstawić z kilku perspektyw:\n",
"1. Perspektywa działania aplikacji\n",
"1. Perspektywa budowania i wdrażania aplikacji\n",
"1. Perspektywa wirtualizacji i infrastruktury"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Perspektywa działania aplikacji\n",
"\n",
"Aplikacja zbudowana z wykorzystaniem rozwiązania typu PaaS może składać się z wielu modułów. Każdy moduł może korzystać z innych usług i działać w inny sposób. Jednak cechą wspólną wszyskich aplikacji wdrażanych w modelu PaaS jest udostępnianie usług w protokole HTTP i to moduł realizujacy tę funkcjonalność jest najczęściej uważany za główny dla danej aplikacji (nie rzadko stanowi też jedyny moduł aplikacji). \n",
"\n",
"> **Heroku**: Przykładowo w Heroku taki moduł nazywany jest `web` i tylko on może przyjmować żądania HTTP pochodzące z zewnątrz.\n",
"\n",
"Usługa PaaS udostępnia nam adres *URL* naszej aplikacji. Ten adres nie prowadzi jednak bezpośrednio do naszego modułu głównego. Zamiast tego każde wysłane żądanie HTTP trafia do tak zwanego *routera*. Jest to centralny punkt usługi, którego zadanie polega na odnalezieniu właściwej aplikacji, do której kierowane jest zapytanie oraz przekazanie danych do odpowiedniej instancji modułu. \n",
"\n",
"> **Heroku**: Heroku posiada jeden centralny *router* w każdym z regionów, a wszystkie one korzystają z jednego punktu startowego (*entry point*): `herokuapp.com`.\n",
"\n",
"*Router* realizuje również proces tak zwanego równoważenia obciążenia (ang. *load-balancing*). Polega on na przekazywaniu żądań równolegle do różnych kopii (instancji) tego samego modułu. W ten sposób aplikacja może obsłużyć dowolnie wiele wiadomości jednocześnie bez obawy o znaczący wzrost czasu odpowiedzi. Aby to było możliwe konieczne jest przestrzeganie kilku zasad już na etapie projektowania aplikacji:\n",
"\n",
"1. Moduł musi być bezstanowy - nie powinien przechowywać żadnych informacji w pamięci czy na dysku. Całość stanu powinna być przechowywana w zewnętrznej usłudze (np. bazie danych).\n",
"1. Komunikacja z modułem musi być bezstanowa - każde żądanie do modułu musi zawierać wszystkie informacje niezbędne do jego realizacji (patrz założenia stylu REST).\n",
"1. Moduł musi być lekki - aby możliwe było szybkie uruchamianie nowych instancji oraz wyłączania tych już niepotrzebnych.\n",
"\n",
"Skalowanie takich bezstanowych modułów może odbywać się automatycznie lub manualnie, w zależności od potrzeb.\n",
"\n",
"> **Uwaga**: Więcej na tamat zasad jakie powinien spełniać projekt zoptymalizowany pod wdrożenie w modelu PaaS przedstawia koncepcja [The Twelve-Factor App](https://12factor.net/pl/).\n",
"\n",
"Gdy moduł główny naszej aplikacji otrzyma już żądanie HTTP, może przystąpić do jego obsługi. Kod naszej aplikacji jest uruchamiany w zależności od środowiska, w którym aplikacja została napisana. Można wyróżnić trzy główne sposoby wykonania tego kodu:\n",
"\n",
"1. Aplikacja samodzielnie uruchamia serwer HTTP nasłuchujący na odpowiednim porcie\n",
"1. Aplikacja jest przygotowana zgodnie z założeniami zewnętrznego serwera HTTP\n",
"1. Aplikacja dostarczana jest w postaci zbudowanego obrazu Docker\n",
"\n",
"Sposób pierwszy jest najpopularniejszy w przypadku języków kompilowanych (np. Go, Rust, Java), podczas gdy drugi jest najpopularniejszy w jezykach skryptowych (Python - uWSGI, Ruby - Unicorn). Sposób trzeci, jest stosunkowo młody, choć większość dostawców oferuje taką usługę, nie zawsze jest ona tak samo wspierana jak pierwsze dwa podejścia. Wybór sposobu uruchamiania aplikacji ma spore znaczenie na wymaganych zasobów. Przykładowo w rozwiązaniu 2. nie ma potrzeby aby proces odpowiedzialny za moduł aplikacji był stale uruchomiony, podczas gdy w pozostałych modelach jest to niezbędne.\n",
"\n",
"> **Heroku**: Potrafi automatycznie wykryć w jaki sposób uruchomić daną aplikację korzystając z bardzo wielu predefiniowanych profili.\n",
"\n",
"> **Heroku**: Obsługuje wszystkie trzy sposoby uruchamiania aplikacji, są one też w pełni wspierane.\n",
"\n",
"> **Heroku**: W ramach darmowego dostępu, wszystkie aplikacje hostowane na Heroku, są automatycznie usypiane jeśli nie są aktywne (nie otrzymują żądań HTTP) przez określony czas.\n",
"\n",
"Gdy odpowiedni proces aplikacji otrzymuje żądanie HTTP, obsługuje je zgodnie ze swoją implementacją. Co ważne może on w tym celu wykorzystywać:\n",
"* inne procesy w ramach tej samej aplikacji - przykładowo procesy robocze do wykonywania zadań w tle,\n",
"* usługi dodatkowe - w tej kategorii najczęściej znajdują się zarządzane bazy danych oraz zasoby dyskowe od dostawcy usługi PaaS,\n",
"* usługi zewnętrzne i zasoby Internetu - każda aplikacja może niemal dowolnie korystać z zasobów dostępnych przez sięć Internet.\n",
"\n",
"Na koniec obsługi żądania, zwracana jest odpowiedź HTTP, która przekazywana jest do *routera* i następnie do przeglądarki użytkownika aplikacji.\n",
"\n",
"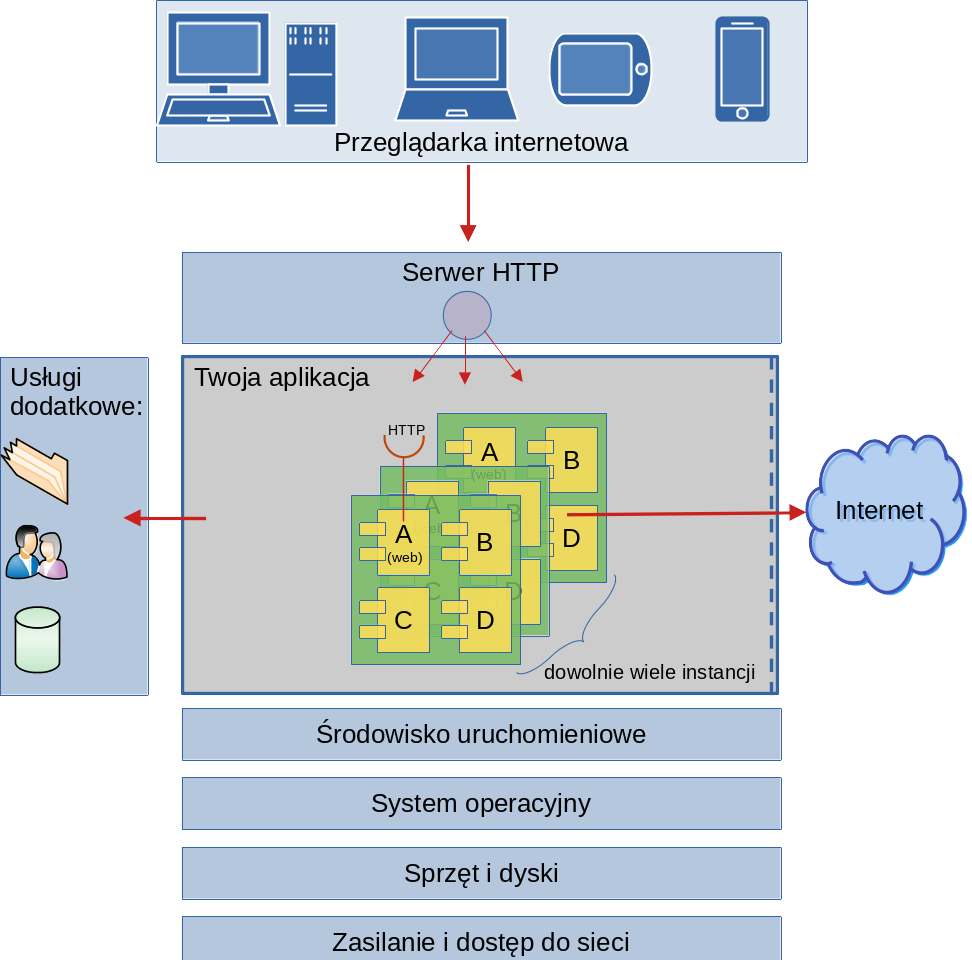\n",
"\n",
"Rysunek 1. Przykładowa architektura usługi typu PaaS. Dostawca zapewnia wszystko z wyjątkiem kodu aplikacji (moduły A, B, C i D)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Perspektywa budowania i wdrażania aplikacji\n",
"\n",
"Proces budowania i wdrażania aplikacji w wielu popularnych usługach typu PaaS oparty jest na repozytorium kodu. Aplikacja budowana jest po każdej zmianie wybranej gałęzi repozytorium.\n",
"\n",
"> **Heroku**: W przypadku Heroku, należy przesłać zmiany na specjalne, tworzone dla każdej aplikacji repozytorium hostowane na serwerach Heroku.\n",
"\n",
"Takie podejście do budowania aplikacji, wspomaga (a tak właściwie wymaga) wdrożenie modelu CI (ang. Continuous Integration, ciągła integracja). Budowanie aplikacji musi być w pełni zautomatyzowane i wykonywane w ściśle kontrolowanym środowisku. Platforma PaaS udostępnia schematy według, których budowane są aplikacje. Często też możliwe jest zdefiniowanie własnych schematów oraz budowanie aplikacji w dowolnym środowisku z wykorzystaniem kontenerów Docker.\n",
"\n",
"> **Heroku**: Heroku obsługuje większość popularnych języków programowania i frameworków: Node.js, Java, Python, PHP, Go i [wiele innych](https://devcenter.heroku.com/articles/buildpacks). Aplikację można też zbudować korzystając z kontenerów.\n",
"\n",
"Przykładowo w środowisku Python, zwyczajowo wszystkie zewnętrzne zależności powinny być opisane w pliku `requirements.txt`. Podczas zautomatyzowanego budowania aplikacji, odpowiedni schemat budowania dla języka Python, zainstaluje wszystkie wymagane zależności i dopiero wtedy przystąpi do budowania właściwej aplikacji.\n",
"\n",
"Zbudowana aplikacja jest łączona z konfiguracją a następnie pakowana i nazywana (np. nazwą, wersją, numerem comita w repozytorium, czy bieżącą datą) tworząc *wydanie* (ang. release). Kolejne wydania aplikacji tworzą rejestr do którego można tylko dodawać nowe elementy. W ten sposób zawsze istnieje możliwość powrotu do wersji wcześniejszej. Tak zdeponowane wydanie może następnie posłużyć do wykonania wdrożenia aplikacji. Jedna zbudowana aplikacja za sprawą różnych konfiguracji (np. testowa, produkcyjna) może prowadzić to wielu wydań. Każde wydanie może zostać uruchomione wielokrotnie czy to w ramach procesu skalowania, czy odtwarzania po awarii jednej z instancji.\n",
"\n",
"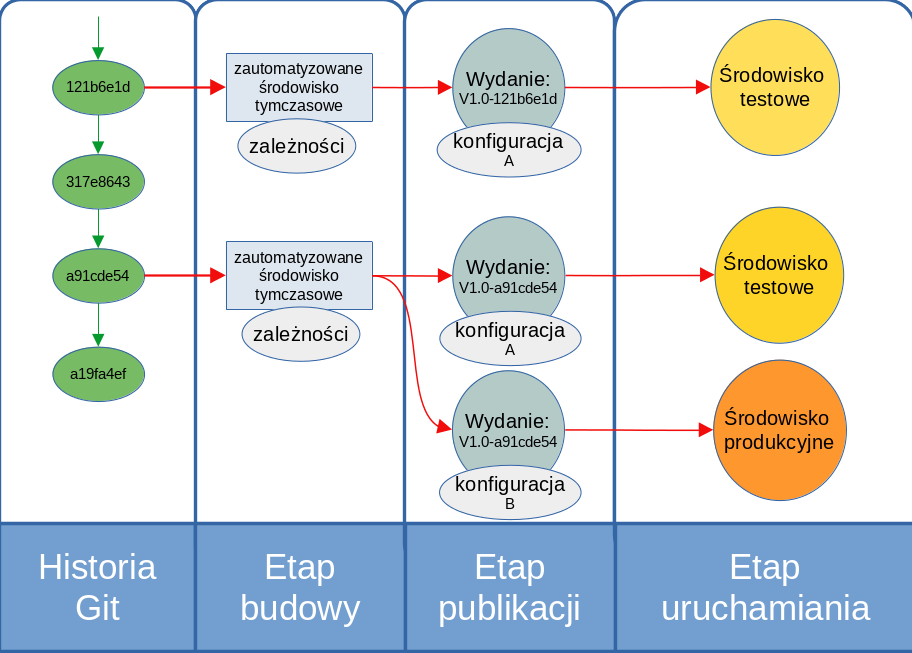\n",
"\n",
"Rysunek 2. Przykładowy schemat procesu budowania aplikacji na potrzeby usługi w modelu Paas."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Perspektywa wirtualizacji i infrastruktury\n",
"\n",
"Korzystając z usług w modelu PaaS, warto też być świadomym jak fizycznie zorganizowana jest infrastrktura, z której korzystamy. Przedstawione tu informacje są bardzo ogólne, gdyż przyjęte rozwiązania techniczne różnią się u poszczególnych dostawców. Można jednak przyjąć, że przedstawiona organizacja jest wspólna dla większości usług.\n",
"\n",
"Przede wszystkim aplikacje uruchamiane w usłudze PaaS korzystają z w pełni zwirtualizowanego środowiska. Najczęściej jest to wirtualizacja kilku poziomowa. Na załączonym schemacie fizyczny serwer (o bardzo dużych zasobach obliczeniowych) jest hostem dla wielu maszyn wirtualnych. Pojedyncza maszyna wirtualna jest natomiast hostem dla bardzo wielu aplikacji wdrożonych w modelu PaaS. Każda z takich aplikacji może pracować we własnym zwirtualizowanym środowisku (np. kontenerze Docker). Całość połączona jest poprzez sieć wirtualną i zabezpieczona odpowiednio skonfigurowaną zaporą sieciową. *Router* jest odpowiedzialny za przesyłanie żądań HTTP do odpowiednich maszyn wirtualnych i dalej do kontenerów i aplikacji.\n",
"\n",
"Przy przydzielaniu zasobów stosuje się bardzo często tak zwany over-provisioning. Polega to na udostępnianiu większej ilości wirtualnych zasobów, niż jest fizycznie dostępne. Przyjmuje się założenie, że jest bardzo mało prawdopodobne aby jednocześnie wszystkie aplikacje potrzebowały 100% zadeklarowanych zasobów. Oczywiście w skrajnym przypadku może to powodować przerwy w działaniu niektórych aplikacji oraz spadki wydajności. Stąd tak ważna jest konfiguracja skalowania i instancji zapasowych. Z drugiej strony takie podejście pozwala drastycznie zmniejszyć koszty usługi. W porównaniu z dedykowanym serwerem redukcja kosztów może sięgać nawet 100x, a w porównaniu z zasobami wirtualnymi ale o dedykowanych zasobach 10x. Niektórzy dostawcy usług oferują wariant usługi w ramach, którego zasoby nie są współdzielone i/lub przydzielane wielokrotnie. Taka usługa jest znacznie droższa od standardowej, ale gwarantuje stabilną wydajność i dostępność nie zależnie od obciążenia zasobów usługodawcy.\n",
"\n",
"> **Heroku**: Jak już zostało to powiedziane wcześniej, Heroku nie utrzymuje swojej własnej dedykowanej infrastruktury. Korzysta natomiast z zasobów AWS, w szczególności z maszyn wirtualnych EC2, które stanowią podstawę mocy obliczeniowej dostępnej dla aplikacji. Jedna maszyna wirtualna nawet najsłabsza, może bez problemu obsłużyć wiele aplikacji. W ten sposób wdrożenie aplikacji na Heroku może nadal być bardziej opłacalne niż bezpośrednio na AWS EC2. Ciekawe opracowanie na ten temat znajduje się [tu](https://christopher.xyz/2019/01/23/heroku-dyno-sizes.html).\n",
"\n",
"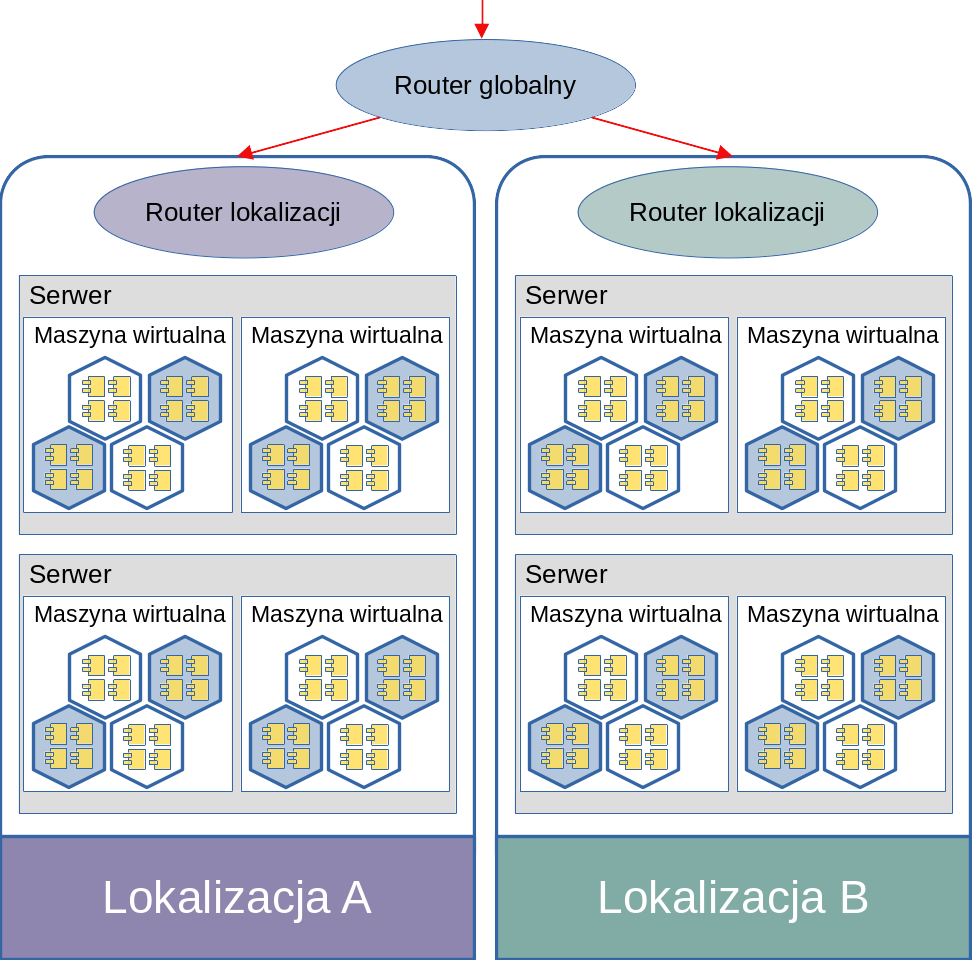\n",
"Rysunek 3."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Zadania do realizacji w czasie zajęć\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Konfiguracja środowiska\n",
"\n",
"1. Zarejestruj się w usłudze Heroku korzystając z formularza pod adresem: .\n",
"\n",
"1. Zainstaluj narzędzie do zarządzania aplikacjami w chmurze Heroku:\n",
"\n",
" ```bash\n",
" cd /dev/shm && wget https://cli-assets.heroku.com/heroku-linux-x64.tar.gz && tar xvf heroku-linux-x64.tar.gz\n",
" ```\n",
" > **Uwaga**: Oczywiście Heroku CLI możesz zainstalować w dowolnej lokalizacji w systemie, jeśli chcesz aby komenda `heroku` była dostępna globalnie w całym systemie zainstaluj ją w `/usr/local/bin`.\n",
"\n",
" > **Uwaga**: Katalog `/dev/shm` to dość specjalne miejsce w każdym współczesnym systemie linuxowym. Jest to dysk zlokalizowany w pamięci operacyjnej, w związku z czym jego zawartość jest czyszczona przy każdym wyłączeniu komputera. Ponadto pamiętaj że umieszczając tam duże pliki ograniczasz ilość pamięci operacyjnej dostępnej dla systemu i innych procesów.\n",
"\n",
"1. Zaloguj się w zainstalowanym narzędziu:\n",
"\n",
" ```bash\n",
" /dev/shm/heroku/bin/heroku login\n",
" ```\n",
"\n",
" Komanda ta może poprosić Cię o otwarcie w przeglądarce internetowej wyświetlonego linku w celu wykonania logowania do serwisu Heroku.\n",
"\n",
" > **Uwaga**: Dane logowania (login i hasło) nie zostaną zapisane na komputerze. Heroku (podobnie jak większość współczesnych serwisów dbających o bezpieczeństwo użytkowników) korzysta z tak zwanych *tokenów* dostępowych. Podając login i hasło, system weryfikuje Twoje uprawnienia, a następnie generuje specjalny token dostępowy, który następnie pozwala na dostęp do zasobów bez podawania/przechowywania hasła. Token może mieć ograniczone uprawnienia, a co najważniejsze można go unieważnić. Więcej informacji znajduje się w [dokumentacji Heroku](https://devcenter.heroku.com/articles/authentication)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"## Przykładowa aplikacja\n",
"\n",
"1. Sklonuj repozytorium Git zawierające przykładowy projekt startowy w Javie (używający frameworka Spring):\n",
"\n",
"\n",
" ```bash\n",
" cd ~\n",
" git clone https://github.com/heroku/java-getting-started.git\n",
" cd java-getting-started\n",
" ```\n",
"\n",
"1. Utwórz nową aplikację na Heroku i wyświetl informacje o niej:\n",
"\n",
" ```bash\n",
" appName=$(/dev/shm/heroku/bin/heroku create --stack heroku-20 --region eu --json | jq -r '.name')\n",
" /dev/shm/heroku/bin/heroku apps:info $appName\n",
" ```\n",
" \n",
"\tNowo utworzoną aplikację zobaczymy także w interfejsie webowym pod adresem: .\n",
"\n",
" > **Uwaga**: Tak naprawdę wystarczyłaby komenda `heroku create` (ewentualnie z własną nazwą tworzonej aplikacji), reszta powyższego polecenia przechwytuje nazwę nowo utworzonego projektu i zapisuję ją w zmiennej powłoki do późniejszego użycia.\n",
"\n",
" > **Uwaga**: Tworząc aplikację nie podaliśmy jej nazwy, Heroku generuje je automatycznie jako zbitki dwóch losowych słów z języka angielskiego.\n",
"\n",
" > **Uwaga**: Parametr `--stack` określa bazowy obraz kontenera na podstawie, którego utworzona zostanie aplikacja. Więcej informacji w [dokumentacji](https://devcenter.heroku.com/articles/stack).\n",
"\n",
"1. Polecenie `heroku create` nie tylko utworzyło aplikacje w infrastrukturze Heroku, ale jednocześnie zarejestrowało dodatkowe repozytorium docelowe (upstream) dla naszej aplikacji. Dzięki temu można bardzo łatwo wysłać kod aplikacji na serwery Heroku korzstając z narzędzia `git`:\n",
"\n",
" ```bash\n",
" git push heroku main\n",
" ```\n",
"\n",
"\tAplikacja powinna być dostępna po podanym na końcu linkiem. Link można też uzyskać w interfejsie webowym, jest on stały dla danej aplikacji.\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Modyfikacja aplikacji\n",
"\n",
"1. Dodamy teraz obsługę nowej ścieżki w naszej przykładowej aplikacji. Zmodyfikuj plik `src/main/java/com/example/Main.java` dodając:\n",
"\n",
" * w nagłówku pliku \n",
" ```java\n",
" import org.springframework.web.bind.annotation.PathVariable;\n",
" ```\n",
" * wewnątrz klasy Main\n",
" ```java\n",
" @RequestMapping(\"/hello/{name}\")\n",
" String hello(@PathVariable(value=\"name\") String name) {\n",
" return \"hello\";\n",
" }\n",
" \n",
" \n",
" ```\n",
"\n",
"1. Dodaj plik `src/main/resources/templates/hello.html` o następującej treści:\n",
"\n",
" ```html\n",
" \n",
" \n",
" \n",
" \n",
" \n",
"
Hello name!
\n",
" \n",
" \n",
" \n",
" ```\n",
"\n",
"1. Utwórz nowy commit i wyślij zmiany do Heroku.\n",
"\n",
" ```bash\n",
" git add src/main/resources/templates/hello.html\n",
" git commit -a -m 'Hello'\n",
" git push heroku main\n",
" ```\n",
"\n",
" Po krótkiej chwili aplikacja powinna zostać podmieniona.\n",
"\n",
" > **Wskazówka**: Kompletne logi z procesu kompilacji i wdrażania aplikacji dostępne są w interfejsie webowym.\n",
"\n",
"1. Aplikację można usunąć za pomocą interfejsu webowego lub z linii poleceń:\n",
"\n",
" ```bash\n",
" /dev/shm/heroku/bin/heroku apps:delete $appName\n",
" ```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Aplikacja od zera w Pythonie\n",
"\n",
"1. W tym zadaniu utworzymy aplikację od zera i uruchomimy ją w chmurze Heroku. Skorzystamy z gotowej przykładowej aplikacji wyświetlającej losowe strony.\n",
"\n",
"1. Stwórz nowy katalog i wewnątrz niego utwórz puste repozytorium `git`:\n",
"\n",
" ```bash\n",
" mkdir newApp\n",
" cd newApp\n",
" git init\n",
" ```\n",
"\n",
"1. Skopiuj do tego katalogu cztery pliki (`layout.jinja2`, `table.jinja2`, `lipsum.jinja2` i `main.py`) dołączone do materiałów do zajęć.\n",
"\n",
"1. Tworzymy nową aplikację na Heroku i wysyłamy naszą aplikację:\n",
"\n",
" ```bash\n",
" appName=$(/dev/shm/heroku/bin/heroku create --stack heroku-20 --region eu --json | jq -r '.name')\n",
" git add .\n",
" git commit -m 'Pierwsza wersja'\n",
" git push heroku master\n",
" ```\n",
"\n",
" Ostatnia linijka się nie powiedzie, bo Heroku nie wie co zrobić z wysyłanym kodem. Możesz też sprawdzić w interfejsie webowym co się stało.\n",
"\n",
"1. Heroku stara się automatycznie wykryć język aplikacji i odpowiednio ją skompilować/zbudować. Pisząc własną aplikację warto poczytać dokładnie jak to robi. Większość języków/frameworków ma pewne konwencje nazywania plików czy wyszczególniania zależności i wystarczy się do nich stosować, by Heroku obsłużyło je poprawnie. \n",
"\n",
" > **Uwaga**: Takie podejście znacząco ułatwia korzystanie z platformy, szczególnie początkującym użytkownikom. W dalszej części zajęć pokazane zostanie jak przejąć pełnie kontroli nad Heroku i podjąć wszystkie decyzje samodzielnie.\n",
"\n",
" Obecność pliku `requirements.txt` jest sygnałem dla Heroku, że mamy do czynienia z aplikację napisaną w Pythonie, a w tym pliku są zależności do zainstalowania przez managera pakietów `pip`. Tworzymy więc w naszym projekcie plik `requirements.txt` o zawartości:\n",
"\n",
" ```python\n",
" pyramid\n",
" pyramid-jinja2\n",
" pyramid-debugtoolbar\n",
" faker\n",
" uwsgi\n",
" ```\n",
"\n",
"\tNastępnie dodajemy go do repozytorium i wysyłamy do Heroku:\n",
"\n",
"\t```bash\n",
"\tgit add requirements.txt\n",
" git commit -m 'requirements.txt'\n",
" git push heroku master\n",
" ```\n",
"\n",
" Teraz powinniśmy widzieć jak ściągane są zależności naszej aplikacji i na końcu zobaczymy link pod jakim nasza aplikacja 'działa'. Odwiedź stronę w przeglądarce, czy strona działa zgodnie z oczekiwaniami?\n",
"\n",
"1. Logi naszej aplikacji można zawsze sprawdzić w interfejsie webowym. Można to też zrobić bezpośrednio z konsoli:\n",
"\n",
" ```bash\n",
" /dev/shm/heroku/bin/heroku logs -a $appName\n",
" ```\n",
"\n",
" Aplikacja co prawda się zbudowała, ale Heroku dalej nie wie jak ją uruchomić.\n",
"\n",
"1. Aby poinstruować Heroku jak zbudowaną aplikację uruchmić musimy utworzyć plik `Procfile` (uwaga na wielką literę) o zawartości:\n",
"\n",
"\t```\n",
" web: uwsgi --http-socket=:$PORT --die-on-term --module=main:app\n",
"\t```\n",
"\n",
" Mówimy w nim, że nasza aplikacja jest aplikacją webową i można ją uruchomić podanym poleceniem (to samo zadziałałoby lokalnie po utworzeniu odpowiedniego środowiska wirtualnego). Tutaj chcemy, by uWSGI nasłuchiwał na porcie o numerze pochodzącym ze zmiennej środowiskowej `PORT` (definiowanej przez Heroku).\n",
"\n",
"\tPo wysłaniu zmian do Heroku wszystko powinno już działać.\n",
"\n",
"1. Aplikację możemy łatwo usunąć:\n",
"\n",
" ```bash\n",
" /dev/shm/heroku/bin/heroku apps:delete $appName\n",
" ```\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Większa kontrola nad Heroku\n",
"\n",
"Heroku bardzo dobrze wykrywa domyślne ustawienia i konfiguracje. Czasem jednak to nie wystarcza. Struktura wdrażanej aplikacji może być zbyt złożona, lub dostosowana pod inną infrastrukturę. W takiej sytuacji pomocą służą pliki konfiguracyjne Heroku:\n",
"\n",
"* [Procfile](https://devcenter.heroku.com/articles/procfile) - samodzielnie sprawdza się dla najprostszych aplikacji, często działa w połączeniu z konfiguracją w `app.json`\n",
"* [app.json](https://devcenter.heroku.com/articles/app-json-schema) - pozwala definiować dodatkowe informacje na temat aplikacji oraz umożliwia zarządzanie dodatkami (np. bazą danych)\n",
"* [heroku.yml](https://devcenter.heroku.com/articles/build-docker-images-heroku-yml) - stworzony z myślą o wdrażaniu przy użyciu narzędzia `Docker`. Nie jest kompatybilny `Procfile`.\n",
"\n",
"\n",
"Przekształcimy teraz poprzednią aplikację tak aby uzyskać pełną kontrolę nad środowiskiem, w którym będzie działać. Wykorzystamy do tego narzędzie `Docker` i konfigurację z wykorzystaniem pliku `heroku.yml`.\n",
"\n",
"1. Dodaj plik `heroku.yml` o następującej treści:\n",
"\n",
" ```yaml\n",
" build:\n",
" docker:\n",
" web: Dockerfile\n",
" run:\n",
" web: uwsgi --http-socket=:$PORT --die-on-term --module=main:app\n",
" ```\n",
" Pierwsza część informuje Heroku w jaki sposób zbudować naszą aplikację, dla uzyskania pełnej elastyczności podajemy tylko nazwę pliku `Dockerfile` naszej aplikacji. W ten sposób możemy zrealizować dowolne operacje, skorzystać z dowolnych narzędzi.\n",
"\n",
" > **Wskazówka**: W sekcji `docker` można umieścić wiele pozycji, co umożliwi zbudowanie wielu obrazów docker.\n",
"\n",
" Druga część pliku odpowiada za określenie jak uruchomić naszą aplikację. Działa podobnie jak Procfile.\n",
"\n",
" > **Wskazówka**: W sekcji `run` można umieścić wiele pozycji, co umożliwi uruchomienie wielu procesów w ramach jednej aplikacji.\n",
"\n",
"1. Utwórz plik `Dockerfile` o następującej treści\n",
"\n",
" ```dockerfile\n",
" FROM python:3\n",
" WORKDIR /usr/src/app\n",
"\n",
" COPY requirements.txt ./\n",
" RUN pip install --no-cache-dir -r requirements.txt\n",
"\n",
" COPY . .\n",
" ```\n",
"\n",
" Bazujemy tu na oficjalnym obrazie Python. Na początek kopiujemy plik `requirements.txt` i instalujemy wszystkie zależności, następnie kopiujemy resztę projektu. Nie podajemy dyrektyw `ENTRYPOINT` ani `CMD`, gdyż zostaną one zastąpione przez konfigurację z sekcji `run` pliku `heroku.yml`.\n",
"\n",
"\n",
"\n",
"1. Usuwamy plik `Procfile`.\n",
"\n",
" ```bash\n",
" rm Procfile\n",
" ```\n",
"\n",
"1. Zmieniamy *stack* naszej aplikacji w Heroku tak aby oparta była ona o kontener:\n",
"\n",
" ```bash\n",
" /dev/shm/heroku/bin/heroku stack:set container\n",
" ```\n",
"\n",
"1. Dodajemy pliki do repozytorium i wysyłamy do Heroku. Nowa wersja strony powinna zostać zbudowana i uruchomiona. Zwróć uwagę na proces budowania, który obecnie pobiera i buduje odpowiednie obrazy dockerowe. Heroku nie korzysta już ze swoich domyślnych ustawień, zamiast tego buduje obraz docker zgodnie z dostarczaoną specyfikacją."
]
}
],
"metadata": {
"interpreter": {
"hash": "98b0a9b7b4eaaa670588a142fd0a9b87eaafe866f1db4228be72b4211d12040f"
},
"kernelspec": {
"display_name": "Python 3.9.5 64-bit ('base': conda)",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.5"
}
},
"nbformat": 4,
"nbformat_minor": 2
}