Poprawiono przecinki w pracy oraz rozdzielcznosć niektórych wykreśów.
@ -35,14 +35,14 @@
|
||||
\newlabel{fig:neural_model_multi}{{1.4}{18}}
|
||||
\citation{deep_learning}
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {1.4\relax .\leavevmode@ifvmode \kern .5em }Funkcje aktywacji}{19}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {1.5\relax .\leavevmode@ifvmode \kern .5em }Wielowarstwowe sieci neuronowe}{19}\protected@file@percent }
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.5}{\ignorespaces Funkcja logistyczna\relax }}{19}\protected@file@percent }
|
||||
\newlabel{fig:sigmoid}{{1.5}{19}}
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {1.5\relax .\leavevmode@ifvmode \kern .5em }Wielowarstwowe sieci neuronowe}{20}\protected@file@percent }
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.6}{\ignorespaces Przyk\IeC {\l }ad modelu wielowarstwowej sieci neuronowej\relax }}{20}\protected@file@percent }
|
||||
\newlabel{fig:neural_net_1}{{1.6}{20}}
|
||||
\citation{survay}
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.5}{\ignorespaces Funkcja logistyczna\relax }}{20}\protected@file@percent }
|
||||
\newlabel{fig:sigmoid}{{1.5}{20}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {1.5.1\relax .\leavevmode@ifvmode \kern .5em }Jednokierunkowe sieci neuronowe}{20}\protected@file@percent }
|
||||
\newlabel{section:feedforeward}{{1.5.1}{20}}
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.6}{\ignorespaces Przyk\IeC {\l }ad modelu wielowarstwowej sieci neuronowej\relax }}{21}\protected@file@percent }
|
||||
\newlabel{fig:neural_net_1}{{1.6}{21}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {1.5.1\relax .\leavevmode@ifvmode \kern .5em }Jednokierunkowe sieci neuronowe}{21}\protected@file@percent }
|
||||
\newlabel{section:feedforeward}{{1.5.1}{21}}
|
||||
\newlabel{section:backpropagation}{{1.5.1}{21}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {1.5.2\relax .\leavevmode@ifvmode \kern .5em }Autoenkoder}{21}\protected@file@percent }
|
||||
\newlabel{section:autoencoder}{{1.5.2}{21}}
|
||||
@ -54,13 +54,13 @@
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.8}{\ignorespaces Rekurencyjny neuron (po lewej) odwini\IeC {\k e}ty w czasie (po prawej)\relax }}{23}\protected@file@percent }
|
||||
\newlabel{fig:unrolled-rnn}{{1.8}{23}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {1.5.4\relax .\leavevmode@ifvmode \kern .5em }LSTM}{23}\protected@file@percent }
|
||||
\citation{handson}
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.9}{\ignorespaces Kom\IeC {\'o}rka LSTM\relax }}{24}\protected@file@percent }
|
||||
\newlabel{fig:lstm}{{1.9}{24}}
|
||||
\citation{handson}
|
||||
\citation{seq2seq}
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.10}{\ignorespaces Tangens hiperboliczny\relax }}{25}\protected@file@percent }
|
||||
\newlabel{fig:tanh}{{1.10}{25}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {1.5.5\relax .\leavevmode@ifvmode \kern .5em }Sequence-to-sequence}{26}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {1.5.5\relax .\leavevmode@ifvmode \kern .5em }Sequence-to-sequence}{25}\protected@file@percent }
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {1.11}{\ignorespaces Architektura modelu sequence-to-sequence\relax }}{26}\protected@file@percent }
|
||||
\newlabel{fig:seq2seq}{{1.11}{26}}
|
||||
\citation{tempos}
|
||||
@ -78,53 +78,53 @@
|
||||
\@writefile{lot}{\contentsline {table}{\numberline {2.1}{\ignorespaces D\IeC {\'z}wi\IeC {\k e}ki symboliczne oraz ich cz\IeC {\k e}stotliwo\IeC {\'s}ci\relax }}{29}\protected@file@percent }
|
||||
\newlabel{table:dzwieki}{{2.1}{29}}
|
||||
\newlabel{fig:pieciolinia}{{2.3}{30}}
|
||||
\newlabel{section:skala}{{2.1.3}{31}}
|
||||
\newlabel{section:skala}{{2.1.3}{30}}
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {2.2\relax .\leavevmode@ifvmode \kern .5em }Cyfrowa reprezentacja muzyki symbolicznej}{31}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {2.2.1\relax .\leavevmode@ifvmode \kern .5em }Standard MIDI}{31}\protected@file@percent }
|
||||
\@writefile{lof}{\contentsline {figure}{\numberline {2.4}{\ignorespaces Fragment protoko\IeC {\l }u MIDI\relax }}{31}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {chapter}{Rozdzia\PlPrIeC {\l }\ 3\relax .\leavevmode@ifvmode \kern .5em Projekt}{35}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {chapter}{Rozdzia\PlPrIeC {\l }\ 3\relax .\leavevmode@ifvmode \kern .5em Projekt}{33}\protected@file@percent }
|
||||
\@writefile{lof}{\addvspace {10\p@ }}
|
||||
\@writefile{lot}{\addvspace {10\p@ }}
|
||||
\newlabel{section:project}{{3}{35}}
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.1\relax .\leavevmode@ifvmode \kern .5em }Koncepcja}{35}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.2\relax .\leavevmode@ifvmode \kern .5em }Wst\IeC {\k e}pne przygotowanie danych do treningu}{36}\protected@file@percent }
|
||||
\newlabel{section:midi}{{3.2}{36}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.1\relax .\leavevmode@ifvmode \kern .5em }Muzyczne ,,s\IeC {\l }owo''}{36}\protected@file@percent }
|
||||
\newlabel{section:midi_words}{{3.2.1}{36}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.2\relax .\leavevmode@ifvmode \kern .5em }Konwersja MIDI na sekwencje s\IeC {\l }\IeC {\'o}w muzycznych}{36}\protected@file@percent }
|
||||
\newlabel{section:project}{{3}{33}}
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.1\relax .\leavevmode@ifvmode \kern .5em }Koncepcja}{33}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.2\relax .\leavevmode@ifvmode \kern .5em }Wst\IeC {\k e}pne przygotowanie danych do treningu}{34}\protected@file@percent }
|
||||
\newlabel{section:midi}{{3.2}{34}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.1\relax .\leavevmode@ifvmode \kern .5em }Muzyczne ,,s\IeC {\l }owo''}{34}\protected@file@percent }
|
||||
\newlabel{section:midi_words}{{3.2.1}{34}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.2\relax .\leavevmode@ifvmode \kern .5em }Konwersja MIDI na sekwencje s\IeC {\l }\IeC {\'o}w muzycznych}{34}\protected@file@percent }
|
||||
\citation{survay}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.3\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania danych}{39}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.4\relax .\leavevmode@ifvmode \kern .5em }Podzia\IeC {\l } danych na dane wej\IeC {\'s}ciowe i wyj\IeC {\'s}ciowe}{40}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.5\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania zbioru ucz\IeC {\k a}cego}{42}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.3\relax .\leavevmode@ifvmode \kern .5em }Definicja modelu}{44}\protected@file@percent }
|
||||
\newlabel{section:model}{{3.3}{44}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.3.1\relax .\leavevmode@ifvmode \kern .5em }Model w trybie uczenia}{44}\protected@file@percent }
|
||||
\newlabel{fig:training-model}{{3.1}{46}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.3.2\relax .\leavevmode@ifvmode \kern .5em }Model w trybie wnioskowania}{46}\protected@file@percent }
|
||||
\newlabel{section:inference-model}{{3.3.2}{46}}
|
||||
\newlabel{fig:inference-decoder}{{3.2}{47}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.3\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania danych}{37}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.4\relax .\leavevmode@ifvmode \kern .5em }Podzia\IeC {\l } danych na dane wej\IeC {\'s}ciowe i wyj\IeC {\'s}ciowe}{38}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.2.5\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania zbioru ucz\IeC {\k a}cego}{40}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.3\relax .\leavevmode@ifvmode \kern .5em }Definicja modelu}{42}\protected@file@percent }
|
||||
\newlabel{section:model}{{3.3}{42}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.3.1\relax .\leavevmode@ifvmode \kern .5em }Model w trybie uczenia}{42}\protected@file@percent }
|
||||
\newlabel{fig:training-model}{{3.1}{44}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.3.2\relax .\leavevmode@ifvmode \kern .5em }Model w trybie wnioskowania}{44}\protected@file@percent }
|
||||
\newlabel{section:inference-model}{{3.3.2}{44}}
|
||||
\newlabel{fig:inference-decoder}{{3.2}{45}}
|
||||
\citation{onehot}
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.4\relax .\leavevmode@ifvmode \kern .5em }Transformacja danych dla modelu}{49}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.1\relax .\leavevmode@ifvmode \kern .5em }Enkodowanie one-hot}{49}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.2\relax .\leavevmode@ifvmode \kern .5em }S\IeC {\l }ownik}{49}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.3\relax .\leavevmode@ifvmode \kern .5em }Elementy specjalne}{50}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.4\relax .\leavevmode@ifvmode \kern .5em }Kodowanie sekwencji}{50}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.5\relax .\leavevmode@ifvmode \kern .5em }Ekperyment}{51}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.1\relax .\leavevmode@ifvmode \kern .5em }Oprogramowanie}{52}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.2\relax .\leavevmode@ifvmode \kern .5em }Zbi\IeC {\'o}r danych}{52}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.3\relax .\leavevmode@ifvmode \kern .5em }Wydobycie danych}{52}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.4\relax .\leavevmode@ifvmode \kern .5em }Trenowanie modelu}{53}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.5\relax .\leavevmode@ifvmode \kern .5em }Generowanie muzyki przy pomocy wytrenowanych modeli}{54}\protected@file@percent }
|
||||
\newlabel{fig:losses}{{3.3}{55}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.6\relax .\leavevmode@ifvmode \kern .5em }Wyniki}{56}\protected@file@percent }
|
||||
\newlabel{fig:score1}{{3.4}{57}}
|
||||
\newlabel{fig:score10}{{3.5}{57}}
|
||||
\newlabel{fig:score25}{{3.6}{58}}
|
||||
\newlabel{fig:score50}{{3.7}{59}}
|
||||
\newlabel{fig:score75}{{3.8}{59}}
|
||||
\newlabel{fig:score100}{{3.9}{60}}
|
||||
\newlabel{fig:score150}{{3.10}{60}}
|
||||
\@writefile{toc}{\contentsline {chapter}{Podsumowanie}{61}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.4\relax .\leavevmode@ifvmode \kern .5em }Transformacja danych dla modelu}{47}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.1\relax .\leavevmode@ifvmode \kern .5em }Enkodowanie one-hot}{47}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.2\relax .\leavevmode@ifvmode \kern .5em }S\IeC {\l }ownik}{47}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.3\relax .\leavevmode@ifvmode \kern .5em }Elementy specjalne}{48}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.4.4\relax .\leavevmode@ifvmode \kern .5em }Kodowanie sekwencji}{48}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {section}{\numberline {3.5\relax .\leavevmode@ifvmode \kern .5em }Ekperyment}{49}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.1\relax .\leavevmode@ifvmode \kern .5em }Oprogramowanie}{50}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.2\relax .\leavevmode@ifvmode \kern .5em }Zbi\IeC {\'o}r danych}{50}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.3\relax .\leavevmode@ifvmode \kern .5em }Wydobycie danych}{50}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.4\relax .\leavevmode@ifvmode \kern .5em }Trenowanie modelu}{51}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.5\relax .\leavevmode@ifvmode \kern .5em }Generowanie muzyki przy pomocy wytrenowanych modeli}{52}\protected@file@percent }
|
||||
\newlabel{fig:losses}{{3.3}{53}}
|
||||
\@writefile{toc}{\contentsline {subsection}{\numberline {3.5.6\relax .\leavevmode@ifvmode \kern .5em }Wyniki}{54}\protected@file@percent }
|
||||
\newlabel{fig:score1}{{3.4}{55}}
|
||||
\newlabel{fig:score10}{{3.5}{55}}
|
||||
\newlabel{fig:score25}{{3.6}{56}}
|
||||
\newlabel{fig:score50}{{3.7}{57}}
|
||||
\newlabel{fig:score75}{{3.8}{57}}
|
||||
\newlabel{fig:score100}{{3.9}{58}}
|
||||
\newlabel{fig:score150}{{3.10}{58}}
|
||||
\@writefile{toc}{\contentsline {chapter}{Podsumowanie}{59}\protected@file@percent }
|
||||
\@writefile{lof}{\addvspace {10\p@ }}
|
||||
\@writefile{lot}{\addvspace {10\p@ }}
|
||||
\bibcite{survay}{1}
|
||||
@ -137,6 +137,6 @@
|
||||
\bibcite{statystyka}{8}
|
||||
\bibcite{tempos}{9}
|
||||
\bibcite{deep_learning_2}{10}
|
||||
\@writefile{toc}{\contentsline {chapter}{Bibliografia}{63}\protected@file@percent }
|
||||
\@writefile{toc}{\contentsline {chapter}{Bibliografia}{61}\protected@file@percent }
|
||||
\@writefile{lof}{\addvspace {10\p@ }}
|
||||
\@writefile{lot}{\addvspace {10\p@ }}
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
# Fdb version 3
|
||||
["makeindex document.idx"] 1592398843 "document.idx" "document.ind" "document" 1592408443
|
||||
"document.idx" 1592408434 0 d41d8cd98f00b204e9800998ecf8427e ""
|
||||
["makeindex document.idx"] 1592412677 "document.idx" "document.ind" "document" 1592414473
|
||||
"document.idx" 1592413171 0 d41d8cd98f00b204e9800998ecf8427e ""
|
||||
(generated)
|
||||
"document.ilg"
|
||||
"document.ind"
|
||||
["pdflatex"] 1592408437 "j:/_MAGISTERKA/praca-magisterska/docs/document.tex" "j:/_MAGISTERKA/praca-magisterska/docs/document.pdf" "document" 1592408443
|
||||
"document.ilg"
|
||||
["pdflatex"] 1592414465 "j:/_MAGISTERKA/praca-magisterska/docs/document.tex" "j:/_MAGISTERKA/praca-magisterska/docs/document.pdf" "document" 1592414473
|
||||
"c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plit.enc" 1550343089 1946 62ba825cda1ff16dbaa60d53ac60525a ""
|
||||
"c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plme.enc" 1550343089 3126 59f33ff3e396436ebc36f4e7b444d5c4 ""
|
||||
"c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plmi.enc" 1550343089 2005 f094775651a1386335c158fb632529f1 ""
|
||||
@ -27,9 +27,7 @@
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbsy10.tfm" 1550343089 1300 0059c6d760901a3c6e7efe9457b0072d ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx10.tfm" 1550343089 2120 c2bca6a74408b1687f9d32e4fd3978fc ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx12.tfm" 1550343089 2112 e31d5b368c33d42906fcc26c9ca0a59c ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx5.tfm" 1550343089 2124 14faa80a751bb0ae001f3a68d089d55a ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx6.tfm" 1550343089 2136 fe7e8613da9d5c5d815ae6349be1b039 ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx7.tfm" 1550343089 2128 5133c57fe3206d5e27757aee8392aebc ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx8.tfm" 1550343089 2124 8c7c117cce23f08f5cf96b79bd777a5f ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plcsc10.tfm" 1550343089 2140 d2ca82625bedca0b1948a5da5764d911 ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plex10.tfm" 1550343089 992 93098cecc00cfdb7e881cb8983ca7545 ""
|
||||
@ -57,7 +55,6 @@
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/plti12.tfm" 1550343089 2248 f77d595f67089cf2926494dc25800828 ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/pltt10.tfm" 1550343089 1280 1c9b21667354f78365f19e9802715019 ""
|
||||
"c:/software/latex/texmf-dist/fonts/tfm/public/pl/pltt12.tfm" 1550343089 1284 c8c4a3eceb0e687daf7c6971a24f073f ""
|
||||
"c:/software/latex/texmf-dist/fonts/type1/public/amsfonts/cm/cmex10.pfb" 1550339660 30251 6afa5cb1d0204815a708a080681d4674 ""
|
||||
"c:/software/latex/texmf-dist/fonts/type1/public/amsfonts/symbols/msbm10.pfb" 1550339661 34694 870c211f62cb72718a00e353f14f254d ""
|
||||
"c:/software/latex/texmf-dist/fonts/type1/public/pl/plbsy10.pfb" 1550343089 26818 88ded7cd04bfcc3752273159f2e6a97d ""
|
||||
"c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx10.pfb" 1550343089 27050 0da5f310861fb948b3c5e6a53aad685b ""
|
||||
@ -196,15 +193,15 @@
|
||||
"c:/software/latex/texmf-var/web2c/pdftex/pdflatex.fmt" 1550344823 4224189 05b80a2fc98956d1ad757099b6714631 ""
|
||||
"c:/software/latex/texmf.cnf" 1550344763 715 839ef4b14d931ce86420174d3a223d3e ""
|
||||
"chapter-style.sty" 1560952449 376 87871882de090607c810d89fd5ae18d9 ""
|
||||
"document.aux" 1592408442 12333 d4eb3c9c8f4e0cdcae21f0327f146984 ""
|
||||
"document.ind" 1592398843 0 d41d8cd98f00b204e9800998ecf8427e "makeindex document.idx"
|
||||
"document.tex" 1592408431 94834 4ed947d88f630dfe6232db29d455af86 ""
|
||||
"document.toc" 1592408442 5377 2fb0ecc4457bfa12bfcd8a2246d2a677 ""
|
||||
"images/autoencoder.png" 1590441548 23857 e7e97c4ad164834bf8d9e2a1bef11905 ""
|
||||
"images/gradient_descent_1_long.png" 1590441549 10075 3f2887989844779ae2c10639cdfbca6e ""
|
||||
"images/gradient_descent_2_long.png" 1590441549 8705 4b42e8becdda3fb5896ce89581451166 ""
|
||||
"document.aux" 1592414472 12333 f03945da9a0198c6832f0bcc70eb3e8d ""
|
||||
"document.ind" 1592412677 0 d41d8cd98f00b204e9800998ecf8427e "makeindex document.idx"
|
||||
"document.tex" 1592414464 94830 fd19bc0133206b7afb97ef9148e6dce8 ""
|
||||
"document.toc" 1592414472 5377 99f1fbfeeed311c15641911019d5b141 ""
|
||||
"images/autoencoder.png" 1592409298 45138 b1cb8e1c5a4277b2e72bf3e77e86d26c ""
|
||||
"images/gradient_descent_1_long.png" 1592412262 47914 5c985451026c8d5e28901587bf5ee835 ""
|
||||
"images/gradient_descent_2_long.png" 1592412282 43574 6b02401960a159a520593d4ccef24fff ""
|
||||
"images/inference-decoder-graph.png" 1592382139 39617 5ccfdc4fde77e18a8689e1af6b852a5e ""
|
||||
"images/linear_reg.png" 1590441550 8534 8c3054c64ce0c420cfa4a974101de696 ""
|
||||
"images/linear_reg.png" 1592410888 34049 142ae5d54f2f01f5ab08d1b171e3ca4f ""
|
||||
"images/lstm_cell2.PNG" 1590484840 26867 8c9571a6b2a25863a5fcc2f35a1e4acc ""
|
||||
"images/lstm_cell2.png" 1590484840 26867 8c9571a6b2a25863a5fcc2f35a1e4acc ""
|
||||
"images/naural_model_multi_ver2.png" 1590741836 60625 7690eb63f6502a54c7c5a513c98bf051 ""
|
||||
@ -220,22 +217,22 @@
|
||||
"images/score_25.png" 1592392124 30596 c9588004b87eec1b14753250ee464cc1 ""
|
||||
"images/score_50.png" 1592392124 31659 2815c50633e004d965b99b76172563db ""
|
||||
"images/score_75.png" 1592392124 32253 a0a7c7b44586d06bd6ac717e8ccb1705 ""
|
||||
"images/seq2seq2.PNG" 1590503901 30893 1856fa19ecec2dec6c981cc7e4f930f7 ""
|
||||
"images/seq2seq2.png" 1590503901 30893 1856fa19ecec2dec6c981cc7e4f930f7 ""
|
||||
"images/sigmoid.png" 1590441554 9716 acc4f414b1d7e983d673c0833a10041d ""
|
||||
"images/tanh.png" 1590744728 11044 b335b43319d514b24107cb538c17cd0a ""
|
||||
"images/seq2seq2.PNG" 1592410077 22081 430dae2249558395b5f32ff397f1a417 ""
|
||||
"images/seq2seq2.png" 1592410077 22081 430dae2249558395b5f32ff397f1a417 ""
|
||||
"images/sigmoid.png" 1592410722 43181 0e20faa6b80bbd42b9d26b690ad05e78 ""
|
||||
"images/tanh.png" 1592410760 46526 cb5e8f6c0f4ca3468d7d91f68462ebe5 ""
|
||||
"images/training-model-graph.png" 1592382149 47079 cc27892ae4a91cc8c95eafec2e573739 ""
|
||||
"images/training_losses.png" 1592382149 57293 6eb12c89458f62456bc8b0860f6df331 ""
|
||||
"images/wartosc_nut.jpg" 1590441554 48213 d311c2cedb2ed53dcf5eff20f70eda80 ""
|
||||
"images/waveform_axis.png" 1592213328 15586 415de2db6755bd1d0d64273aaa86d16d ""
|
||||
"j:/_MAGISTERKA/praca-magisterska/docs/document.aux" 1592408442 12333 d4eb3c9c8f4e0cdcae21f0327f146984 ""
|
||||
"j:/_MAGISTERKA/praca-magisterska/docs/document.tex" 1592408431 94834 4ed947d88f630dfe6232db29d455af86 ""
|
||||
"images/waveform_axis.png" 1592410460 56303 20c29ea310c3d0f7bef501c488c7de5a ""
|
||||
"j:/_MAGISTERKA/praca-magisterska/docs/document.aux" 1592414472 12333 f03945da9a0198c6832f0bcc70eb3e8d ""
|
||||
"j:/_MAGISTERKA/praca-magisterska/docs/document.tex" 1592414464 94830 fd19bc0133206b7afb97ef9148e6dce8 ""
|
||||
"pythonhighlight.sty" 1590660734 4822 44a39a68d852c9742af161f7166b2a03 ""
|
||||
(generated)
|
||||
"document.aux"
|
||||
"document.log"
|
||||
"document.pdf"
|
||||
"j:/_MAGISTERKA/praca-magisterska/docs/document.log"
|
||||
"j:/_MAGISTERKA/praca-magisterska/docs/document.pdf"
|
||||
"document.toc"
|
||||
"document.idx"
|
||||
"document.pdf"
|
||||
"document.toc"
|
||||
"j:/_MAGISTERKA/praca-magisterska/docs/document.pdf"
|
||||
"document.aux"
|
||||
|
||||
@ -244,6 +244,12 @@ INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx10.tfm
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/gradient_descent_2_long.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/gradient_descent_2_long.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/gradient_descent_2_long.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx8.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx6.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plmib10.tfm
|
||||
@ -255,12 +261,6 @@ INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbsy10.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/cm/cmex10.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/amsfonts/cmextra/cmex8.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/amsfonts/cmextra/cmex7.tfm
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/sigmoid.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/sigmoid.png
|
||||
INPUT j:/_MAGISTERKA/praca-magisterska/docs/images/sigmoid.png
|
||||
@ -296,8 +296,6 @@ INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plmi5.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plsy10.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plsy7.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plsy5.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx7.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/pl/plbx5.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/amsfonts/symbols/msam10.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/amsfonts/symbols/msam7.tfm
|
||||
INPUT c:/software/latex/texmf-dist/fonts/tfm/public/amsfonts/symbols/msam5.tfm
|
||||
@ -355,7 +353,6 @@ INPUT c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plms.enc
|
||||
INPUT c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plmi.enc
|
||||
INPUT c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plme.enc
|
||||
INPUT c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plsc.enc
|
||||
INPUT c:/software/latex/texmf-dist/fonts/type1/public/amsfonts/cm/cmex10.pfb
|
||||
INPUT c:/software/latex/texmf-dist/fonts/type1/public/amsfonts/symbols/msbm10.pfb
|
||||
INPUT c:/software/latex/texmf-dist/fonts/type1/public/pl/plbsy10.pfb
|
||||
INPUT c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx10.pfb
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
This is pdfTeX, Version 3.14159265-2.6-1.40.19 (TeX Live 2018/W32TeX) (preloaded format=pdflatex 2019.2.16) 17 JUN 2020 17:40
|
||||
This is pdfTeX, Version 3.14159265-2.6-1.40.19 (TeX Live 2018/W32TeX) (preloaded format=pdflatex 2019.2.16) 17 JUN 2020 19:21
|
||||
entering extended mode
|
||||
restricted \write18 enabled.
|
||||
file:line:error style messages enabled.
|
||||
@ -568,93 +568,100 @@ Overfull \vbox (16.08192pt too high) detected at line 198
|
||||
[]
|
||||
|
||||
Rozdzia\PlPrIeC {\l } 1.
|
||||
<images/linear_reg.png, id=50, 433.62pt x 289.08pt>
|
||||
<images/linear_reg.png, id=50, 540.8205pt x 369.17924pt>
|
||||
File: images/linear_reg.png Graphic file (type png)
|
||||
<use images/linear_reg.png>
|
||||
Package pdftex.def Info: images/linear_reg.png used on input line 228.
|
||||
(pdftex.def) Requested size: 398.33858pt x 265.57306pt.
|
||||
(pdftex.def) Requested size: 398.33858pt x 271.91525pt.
|
||||
[13] [14 <j:/_MAGISTERKA/praca-magisterska/docs/images/linear_reg.png>] [15]
|
||||
<images/gradient_descent_1_long.png, id=69, 216.81pt x 289.08pt>
|
||||
<images/gradient_descent_1_long.png, id=69, 216.81pt x 216.81pt>
|
||||
File: images/gradient_descent_1_long.png Graphic file (type png)
|
||||
<use images/gradient_descent_1_long.png>
|
||||
Package pdftex.def Info: images/gradient_descent_1_long.png used on input line 281.
|
||||
(pdftex.def) Requested size: 142.26378pt x 189.69504pt.
|
||||
<images/gradient_descent_2_long.png, id=70, 216.81pt x 289.08pt>
|
||||
(pdftex.def) Requested size: 142.26378pt x 142.27127pt.
|
||||
<images/gradient_descent_2_long.png, id=70, 216.81pt x 216.81pt>
|
||||
File: images/gradient_descent_2_long.png Graphic file (type png)
|
||||
<use images/gradient_descent_2_long.png>
|
||||
Package pdftex.def Info: images/gradient_descent_2_long.png used on input line 283.
|
||||
(pdftex.def) Requested size: 142.26378pt x 189.69504pt.
|
||||
[16 <j:/_MAGISTERKA/praca-magisterska/docs/images/gradient_descent_1_long.png> <j:/_MAGISTERKA/praca-magisterska/docs/images/gradient_descent_2_long.png>]
|
||||
<images/naural_model_one_ver2.png, id=80, 437.83575pt x 451.08525pt>
|
||||
(pdftex.def) Requested size: 142.26378pt x 142.27127pt.
|
||||
<images/naural_model_one_ver2.png, id=71, 437.83575pt x 451.08525pt>
|
||||
File: images/naural_model_one_ver2.png Graphic file (type png)
|
||||
<use images/naural_model_one_ver2.png>
|
||||
Package pdftex.def Info: images/naural_model_one_ver2.png used on input line 315.
|
||||
(pdftex.def) Requested size: 227.62204pt x 234.51062pt.
|
||||
[17 <j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png>]
|
||||
<images/naural_model_multi_ver2.png, id=85, 417.35925pt x 448.67625pt>
|
||||
[16 <j:/_MAGISTERKA/praca-magisterska/docs/images/gradient_descent_1_long.png> <j:/_MAGISTERKA/praca-magisterska/docs/images/gradient_descent_2_long.png>]
|
||||
<images/naural_model_multi_ver2.png, id=78, 417.35925pt x 448.67625pt>
|
||||
File: images/naural_model_multi_ver2.png Graphic file (type png)
|
||||
<use images/naural_model_multi_ver2.png>
|
||||
Package pdftex.def Info: images/naural_model_multi_ver2.png used on input line 341.
|
||||
(pdftex.def) Requested size: 227.62204pt x 244.70514pt.
|
||||
[18 <j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png>]
|
||||
<images/sigmoid.png, id=90, 433.62pt x 289.08pt>
|
||||
[17 <j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_one_ver2.png>] [18 <j:/_MAGISTERKA/praca-magisterska/docs/images/naural_model_multi_ver2.png>]
|
||||
<images/sigmoid.png, id=88, 564.9105pt x 374.5995pt>
|
||||
File: images/sigmoid.png Graphic file (type png)
|
||||
<use images/sigmoid.png>
|
||||
Package pdftex.def Info: images/sigmoid.png used on input line 388.
|
||||
(pdftex.def) Requested size: 398.33858pt x 265.57306pt.
|
||||
[19]
|
||||
<images/neural_net_1_ver2.png, id=95, 678.1335pt x 444.4605pt>
|
||||
(pdftex.def) Requested size: 398.33858pt x 264.14412pt.
|
||||
[19 <j:/_MAGISTERKA/praca-magisterska/docs/images/sigmoid.png>]
|
||||
<images/neural_net_1_ver2.png, id=94, 678.1335pt x 444.4605pt>
|
||||
File: images/neural_net_1_ver2.png Graphic file (type png)
|
||||
<use images/neural_net_1_ver2.png>
|
||||
Package pdftex.def Info: images/neural_net_1_ver2.png used on input line 420.
|
||||
(pdftex.def) Requested size: 227.62204pt x 149.1885pt.
|
||||
[20 <j:/_MAGISTERKA/praca-magisterska/docs/images/sigmoid.png>]
|
||||
<images/autoencoder.png, id=100, 372.64218pt x 353.82187pt>
|
||||
[20 <j:/_MAGISTERKA/praca-magisterska/docs/images/neural_net_1_ver2.png>]
|
||||
<images/autoencoder.png, id=99, 419.76825pt x 397.485pt>
|
||||
File: images/autoencoder.png Graphic file (type png)
|
||||
<use images/autoencoder.png>
|
||||
Package pdftex.def Info: images/autoencoder.png used on input line 448.
|
||||
(pdftex.def) Requested size: 227.62204pt x 216.12256pt.
|
||||
[21 <j:/_MAGISTERKA/praca-magisterska/docs/images/neural_net_1_ver2.png>] [22 <j:/_MAGISTERKA/praca-magisterska/docs/images/autoencoder.png (PNG copy)>]
|
||||
<images/rnn.png, id=109, 680.5425pt x 257.16075pt>
|
||||
(pdftex.def) Requested size: 227.62204pt x 215.53633pt.
|
||||
[21]
|
||||
<images/rnn.png, id=105, 680.5425pt x 257.16075pt>
|
||||
File: images/rnn.png Graphic file (type png)
|
||||
<use images/rnn.png>
|
||||
Package pdftex.def Info: images/rnn.png used on input line 467.
|
||||
(pdftex.def) Requested size: 398.33858pt x 150.52278pt.
|
||||
|
||||
Underfull \vbox (badness 3557) has occurred while \output is active []
|
||||
|
||||
[22 <j:/_MAGISTERKA/praca-magisterska/docs/images/autoencoder.png>]
|
||||
<images/lstm_cell2.png, id=110, 419.76825pt x 295.1025pt>
|
||||
File: images/lstm_cell2.png Graphic file (type png)
|
||||
<use images/lstm_cell2.png>
|
||||
Package pdftex.def Info: images/lstm_cell2.png used on input line 488.
|
||||
(pdftex.def) Requested size: 398.33858pt x 280.04857pt.
|
||||
[23 <j:/_MAGISTERKA/praca-magisterska/docs/images/rnn.PNG>] [24 <j:/_MAGISTERKA/praca-magisterska/docs/images/lstm_cell2.PNG>]
|
||||
<images/tanh.png, id=119, 433.62pt x 289.08pt>
|
||||
<images/tanh.png, id=119, 578.16pt x 367.97475pt>
|
||||
File: images/tanh.png Graphic file (type png)
|
||||
<use images/tanh.png>
|
||||
Package pdftex.def Info: images/tanh.png used on input line 526.
|
||||
(pdftex.def) Requested size: 398.33858pt x 265.57306pt.
|
||||
(pdftex.def) Requested size: 398.33858pt x 253.52666pt.
|
||||
[25 <j:/_MAGISTERKA/praca-magisterska/docs/images/tanh.png>]
|
||||
<images/seq2seq2.png, id=125, 763.05075pt x 242.70676pt>
|
||||
<images/seq2seq2.png, id=125, 596.2275pt x 196.3335pt>
|
||||
File: images/seq2seq2.png Graphic file (type png)
|
||||
<use images/seq2seq2.png>
|
||||
Package pdftex.def Info: images/seq2seq2.png used on input line 543.
|
||||
(pdftex.def) Requested size: 398.33858pt x 126.70078pt.
|
||||
(pdftex.def) Requested size: 398.33858pt x 131.17126pt.
|
||||
[26 <j:/_MAGISTERKA/praca-magisterska/docs/images/seq2seq2.PNG>]
|
||||
Overfull \vbox (16.08192pt too high) detected at line 551
|
||||
[]
|
||||
|
||||
Rozdzia\PlPrIeC {\l } 2.
|
||||
<images/waveform_axis.png, id=130, 433.62pt x 289.08pt>
|
||||
<images/waveform_axis.png, id=130, 707.64375pt x 436.029pt>
|
||||
File: images/waveform_axis.png Graphic file (type png)
|
||||
<use images/waveform_axis.png>
|
||||
Package pdftex.def Info: images/waveform_axis.png used on input line 583.
|
||||
(pdftex.def) Requested size: 398.33858pt x 265.57306pt.
|
||||
(pdftex.def) Requested size: 398.33858pt x 245.44534pt.
|
||||
[27
|
||||
|
||||
] [28 <j:/_MAGISTERKA/praca-magisterska/docs/images/waveform_axis.png>]
|
||||
<images/wartosc_nut.jpg, id=138, 903.375pt x 470.75874pt>
|
||||
]
|
||||
<images/wartosc_nut.jpg, id=134, 903.375pt x 470.75874pt>
|
||||
File: images/wartosc_nut.jpg Graphic file (type jpg)
|
||||
<use images/wartosc_nut.jpg>
|
||||
Package pdftex.def Info: images/wartosc_nut.jpg used on input line 602.
|
||||
(pdftex.def) Requested size: 398.33858pt x 207.57985pt.
|
||||
|
||||
Underfull \vbox (badness 1527) has occurred while \output is active []
|
||||
|
||||
[28 <j:/_MAGISTERKA/praca-magisterska/docs/images/waveform_axis.png>]
|
||||
LaTeX Font Info: External font `plex10' loaded for size
|
||||
(Font) <10> on input line 609.
|
||||
LaTeX Font Info: External font `plex10' loaded for size
|
||||
@ -666,158 +673,140 @@ File: images/nuty_linia.png Graphic file (type png)
|
||||
<use images/nuty_linia.png>
|
||||
Package pdftex.def Info: images/nuty_linia.png used on input line 644.
|
||||
(pdftex.def) Requested size: 398.33858pt x 74.14209pt.
|
||||
|
||||
Underfull \vbox (badness 1142) has occurred while \output is active []
|
||||
|
||||
[29 <j:/_MAGISTERKA/praca-magisterska/docs/images/wartosc_nut.jpg>] [30 <j:/_MAGISTERKA/praca-magisterska/docs/images/nuty_linia.png (PNG copy)>] (c:/software/latex/texmf-dist/tex/latex/listings/lstlang1.sty
|
||||
File: lstlang1.sty 2018/09/02 1.7 listings language file
|
||||
)
|
||||
LaTeX Font Info: Try loading font information for OT4+cmtt on input line 679.
|
||||
LaTeX Font Info: Try loading font information for OT4+cmtt on input line 682.
|
||||
(c:/software/latex/texmf-dist/tex/latex/polski/ot4cmtt.fd
|
||||
File: ot4cmtt.fd 2008/02/24 v1.2.1 Font defs for fonts PL (MW)
|
||||
) [31] [32] [33] [34
|
||||
|
||||
]
|
||||
Overfull \vbox (16.08192pt too high) detected at line 735
|
||||
) [31] [32]
|
||||
Overfull \vbox (16.08192pt too high) detected at line 738
|
||||
[]
|
||||
|
||||
Rozdzia\PlPrIeC {\l } 3.
|
||||
[35] [36]
|
||||
[33
|
||||
|
||||
] [34]
|
||||
|
||||
LaTeX Font Warning: Font shape `OT4/cmtt/bx/n' in size <10> not available
|
||||
(Font) Font shape `OT4/cmtt/m/n' tried instead on input line 777.
|
||||
(Font) Font shape `OT4/cmtt/m/n' tried instead on input line 780.
|
||||
|
||||
[37]
|
||||
[35]
|
||||
Underfull \vbox (badness 7081) has occurred while \output is active []
|
||||
|
||||
[38] [39] [40] [41]
|
||||
[36] [37] [38] [39]
|
||||
Underfull \vbox (badness 2080) has occurred while \output is active []
|
||||
|
||||
[42] [43] [44]
|
||||
<images/training-model-graph.png, id=195, 968.61874pt x 406.51875pt>
|
||||
[40] [41] [42]
|
||||
<images/training-model-graph.png, id=188, 968.61874pt x 406.51875pt>
|
||||
File: images/training-model-graph.png Graphic file (type png)
|
||||
<use images/training-model-graph.png>
|
||||
Package pdftex.def Info: images/training-model-graph.png used on input line 1114.
|
||||
Package pdftex.def Info: images/training-model-graph.png used on input line 1117.
|
||||
(pdftex.def) Requested size: 398.33858pt x 167.1762pt.
|
||||
[45]
|
||||
Overfull \hbox (2.09326pt too wide) in paragraph at lines 1133--1134
|
||||
[43]
|
||||
Overfull \hbox (2.09326pt too wide) in paragraph at lines 1136--1137
|
||||
[][][][][]\OT4/cmr/m/n/12 , za-wie-ra-j¡-ce se-kwen-cje ele-men-tów wyj-±cio-wych, któ-
|
||||
[]
|
||||
|
||||
[46 <j:/_MAGISTERKA/praca-magisterska/docs/images/training-model-graph.png>]
|
||||
<images/inference-decoder-graph.png, id=203, 1179.40625pt x 296.10625pt>
|
||||
[44 <j:/_MAGISTERKA/praca-magisterska/docs/images/training-model-graph.png>]
|
||||
<images/inference-decoder-graph.png, id=197, 1179.40625pt x 296.10625pt>
|
||||
File: images/inference-decoder-graph.png Graphic file (type png)
|
||||
<use images/inference-decoder-graph.png>
|
||||
Package pdftex.def Info: images/inference-decoder-graph.png used on input line 1168.
|
||||
Package pdftex.def Info: images/inference-decoder-graph.png used on input line 1171.
|
||||
(pdftex.def) Requested size: 398.33858pt x 100.0106pt.
|
||||
[47 <j:/_MAGISTERKA/praca-magisterska/docs/images/inference-decoder-graph.png>]
|
||||
Overfull \hbox (11.16063pt too wide) in paragraph at lines 1212--1213
|
||||
[][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][]
|
||||
[]
|
||||
|
||||
|
||||
Overfull \hbox (4.86064pt too wide) in paragraph at lines 1215--1216
|
||||
[][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][]
|
||||
[]
|
||||
|
||||
|
||||
[45 <j:/_MAGISTERKA/praca-magisterska/docs/images/inference-decoder-graph.png>]
|
||||
Underfull \vbox (badness 10000) has occurred while \output is active []
|
||||
|
||||
[48]
|
||||
Overfull \hbox (1.23253pt too wide) in paragraph at lines 1234--1235
|
||||
\OT4/cmr/m/n/12 one-hot (\OT4/cmr/m/it/12 one-hot en-co-ding\OT4/cmr/m/n/12 ) En-ko-do-wa-nie One-Hot jest wy-ko-rzy-sty-wa-ne w ucze-
|
||||
[]
|
||||
|
||||
[49] [50]
|
||||
Overfull \hbox (42.66057pt too wide) in paragraph at lines 1341--1342
|
||||
[46] [47] [48]
|
||||
Overfull \hbox (42.66057pt too wide) in paragraph at lines 1345--1346
|
||||
[][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][]
|
||||
[]
|
||||
|
||||
|
||||
Underfull \vbox (badness 4713) has occurred while \output is active []
|
||||
|
||||
[51] [52] [53]
|
||||
<images/training_losses.png, id=228, 722.7pt x 722.7pt>
|
||||
[49] [50] [51]
|
||||
<images/training_losses.png, id=222, 722.7pt x 722.7pt>
|
||||
File: images/training_losses.png Graphic file (type png)
|
||||
<use images/training_losses.png>
|
||||
Package pdftex.def Info: images/training_losses.png used on input line 1470.
|
||||
Package pdftex.def Info: images/training_losses.png used on input line 1474.
|
||||
(pdftex.def) Requested size: 398.33858pt x 398.33534pt.
|
||||
|
||||
Overfull \hbox (3.0656pt too wide) in paragraph at lines 1477--1478
|
||||
Overfull \hbox (3.0656pt too wide) in paragraph at lines 1481--1482
|
||||
[]\OT4/cmr/m/n/12 Gdy zde-fi-nio-wa-ne mo-de-le zo-sta-n¡ wy-tre-no-wa-ne mo-»e-my wy-ko-rzy-sta¢ skrypt
|
||||
[]
|
||||
|
||||
[54]
|
||||
Overfull \hbox (4.86064pt too wide) in paragraph at lines 1495--1496
|
||||
[52]
|
||||
Overfull \hbox (4.86064pt too wide) in paragraph at lines 1499--1500
|
||||
[][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][][]
|
||||
[]
|
||||
|
||||
[55 <j:/_MAGISTERKA/praca-magisterska/docs/images/training_losses.png>]
|
||||
Overfull \hbox (1.56473pt too wide) in paragraph at lines 1509--1511
|
||||
[53 <j:/_MAGISTERKA/praca-magisterska/docs/images/training_losses.png>]
|
||||
Overfull \hbox (1.56473pt too wide) in paragraph at lines 1513--1515
|
||||
[][][][][][][][]\OT4/cmr/m/n/12 , któ-re wspie-ra-j¡ for-mat se-kwen-cji sªów mu-zycz-nych omó-
|
||||
[]
|
||||
|
||||
|
||||
Overfull \hbox (0.20659pt too wide) in paragraph at lines 1534--1535
|
||||
Overfull \hbox (0.20659pt too wide) in paragraph at lines 1538--1539
|
||||
\OT4/cmr/m/n/12 oraz opo-wiem ja-kie ulep-sze-nia po-ja-wia-ªy si¦ wraz z po-st¦-pem tre-nin-gu. Wszyst-
|
||||
[]
|
||||
|
||||
<images/score_1.png, id=237, 585.68813pt x 241.65282pt>
|
||||
<images/score_1.png, id=230, 585.68813pt x 241.65282pt>
|
||||
File: images/score_1.png Graphic file (type png)
|
||||
<use images/score_1.png>
|
||||
Package pdftex.def Info: images/score_1.png used on input line 1540.
|
||||
Package pdftex.def Info: images/score_1.png used on input line 1544.
|
||||
(pdftex.def) Requested size: 398.33858pt x 164.35861pt.
|
||||
[56]
|
||||
<images/score_10.png, id=241, 575.90157pt x 290.58563pt>
|
||||
[54]
|
||||
<images/score_10.png, id=234, 575.90157pt x 290.58563pt>
|
||||
File: images/score_10.png Graphic file (type png)
|
||||
<use images/score_10.png>
|
||||
Package pdftex.def Info: images/score_10.png used on input line 1549.
|
||||
Package pdftex.def Info: images/score_10.png used on input line 1553.
|
||||
(pdftex.def) Requested size: 398.33858pt x 200.99646pt.
|
||||
[57 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_1.png (PNG copy)> <j:/_MAGISTERKA/praca-magisterska/docs/images/score_10.png (PNG copy)>]
|
||||
<images/score_25.png, id=245, 578.91281pt x 307.1475pt>
|
||||
[55 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_1.png (PNG copy)> <j:/_MAGISTERKA/praca-magisterska/docs/images/score_10.png (PNG copy)>]
|
||||
<images/score_25.png, id=239, 578.91281pt x 307.1475pt>
|
||||
File: images/score_25.png Graphic file (type png)
|
||||
<use images/score_25.png>
|
||||
Package pdftex.def Info: images/score_25.png used on input line 1558.
|
||||
Package pdftex.def Info: images/score_25.png used on input line 1562.
|
||||
(pdftex.def) Requested size: 398.33858pt x 211.34148pt.
|
||||
<images/score_50.png, id=246, 578.16pt x 307.90031pt>
|
||||
<images/score_50.png, id=240, 578.16pt x 307.90031pt>
|
||||
File: images/score_50.png Graphic file (type png)
|
||||
<use images/score_50.png>
|
||||
Package pdftex.def Info: images/score_50.png used on input line 1567.
|
||||
Package pdftex.def Info: images/score_50.png used on input line 1571.
|
||||
(pdftex.def) Requested size: 398.33858pt x 212.13666pt.
|
||||
<images/score_75.png, id=247, 588.69937pt x 310.15875pt>
|
||||
<images/score_75.png, id=241, 588.69937pt x 310.15875pt>
|
||||
File: images/score_75.png Graphic file (type png)
|
||||
<use images/score_75.png>
|
||||
Package pdftex.def Info: images/score_75.png used on input line 1576.
|
||||
Package pdftex.def Info: images/score_75.png used on input line 1580.
|
||||
(pdftex.def) Requested size: 398.33858pt x 209.86871pt.
|
||||
<images/score_100.png, id=248, 574.39594pt x 314.67563pt>
|
||||
<images/score_100.png, id=242, 574.39594pt x 314.67563pt>
|
||||
File: images/score_100.png Graphic file (type png)
|
||||
<use images/score_100.png>
|
||||
Package pdftex.def Info: images/score_100.png used on input line 1585.
|
||||
Package pdftex.def Info: images/score_100.png used on input line 1589.
|
||||
(pdftex.def) Requested size: 398.33858pt x 218.23076pt.
|
||||
[58 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_25.png (PNG copy)>]
|
||||
<images/score_150.png, id=252, 580.41844pt x 300.3722pt>
|
||||
[56 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_25.png (PNG copy)>]
|
||||
<images/score_150.png, id=246, 580.41844pt x 300.3722pt>
|
||||
File: images/score_150.png Graphic file (type png)
|
||||
<use images/score_150.png>
|
||||
Package pdftex.def Info: images/score_150.png used on input line 1592.
|
||||
Package pdftex.def Info: images/score_150.png used on input line 1596.
|
||||
(pdftex.def) Requested size: 398.33858pt x 206.14786pt.
|
||||
[59 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_50.png (PNG copy)> <j:/_MAGISTERKA/praca-magisterska/docs/images/score_75.png (PNG copy)>] [60 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_100.png (PNG copy)> <j:/_MAGISTERKA/praca-magisterska/docs/images/score_150.png (PNG copy)>] [61
|
||||
[57 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_50.png (PNG copy)> <j:/_MAGISTERKA/praca-magisterska/docs/images/score_75.png (PNG copy)>] [58 <j:/_MAGISTERKA/praca-magisterska/docs/images/score_100.png (PNG copy)> <j:/_MAGISTERKA/praca-magisterska/docs/images/score_150.png (PNG copy)>] [59
|
||||
|
||||
] [62
|
||||
] [60
|
||||
|
||||
] (j:/_MAGISTERKA/praca-magisterska/docs/document.ind) [63] (j:/_MAGISTERKA/praca-magisterska/docs/document.aux) )
|
||||
] (j:/_MAGISTERKA/praca-magisterska/docs/document.ind) [61] (j:/_MAGISTERKA/praca-magisterska/docs/document.aux) )
|
||||
Here is how much of TeX's memory you used:
|
||||
16792 strings out of 492616
|
||||
311476 string characters out of 6131816
|
||||
660831 words of memory out of 5000000
|
||||
20343 multiletter control sequences out of 15000+600000
|
||||
27095 words of font info for 80 fonts, out of 8000000 for 9000
|
||||
16788 strings out of 492616
|
||||
311428 string characters out of 6131816
|
||||
660527 words of memory out of 5000000
|
||||
20341 multiletter control sequences out of 15000+600000
|
||||
26080 words of font info for 78 fonts, out of 8000000 for 9000
|
||||
1141 hyphenation exceptions out of 8191
|
||||
55i,12n,50p,1576b,1971s stack positions out of 5000i,500n,10000p,200000b,80000s
|
||||
{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plit.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/pltt.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plrm.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plms.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plmi.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plme.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plsc.enc}<c:/software/latex/texmf-dist/fonts/type1/public/amsfonts/cm/cmex10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/amsfonts/symbols/msbm10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbsy10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plcsc10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plex10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmi12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmi6.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmi8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmib10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr7.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plsltt10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plsy10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plsy8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plti10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plti12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/pltt10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/pltt12.pfb>
|
||||
Output written on j:/_MAGISTERKA/praca-magisterska/docs/document.pdf (63 pages, 1024299 bytes).
|
||||
55i,12n,50p,1575b,1971s stack positions out of 5000i,500n,10000p,200000b,80000s
|
||||
{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plit.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/pltt.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plrm.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plms.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plmi.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plme.enc}{c:/software/latex/texmf-dist/fonts/enc/dvips/pl/plsc.enc}<c:/software/latex/texmf-dist/fonts/type1/public/amsfonts/symbols/msbm10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbsy10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plbx8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plcsc10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plex10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmi12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmi6.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmi8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plmib10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr7.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plr8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plsltt10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plsy10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plsy8.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plti10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/plti12.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/pltt10.pfb><c:/software/latex/texmf-dist/fonts/type1/public/pl/pltt12.pfb>
|
||||
Output written on j:/_MAGISTERKA/praca-magisterska/docs/document.pdf (61 pages, 1199946 bytes).
|
||||
PDF statistics:
|
||||
352 PDF objects out of 1000 (max. 8388607)
|
||||
221 compressed objects within 3 object streams
|
||||
343 PDF objects out of 1000 (max. 8388607)
|
||||
214 compressed objects within 3 object streams
|
||||
0 named destinations out of 1000 (max. 500000)
|
||||
138 words of extra memory for PDF output out of 10000 (max. 10000000)
|
||||
|
||||
|
||||
@ -162,9 +162,9 @@ Jednocześnie przyjmuję do wiadomości, że przypisanie sobie, w pracy dyplomow
|
||||
|
||||
\chapter*{Streszczenie}
|
||||
|
||||
W pracy magisterskiej pod tytułem ,,Generowanie muzyki przy pomocy głębokiego uczenia'' został zaproponowany przykład sieci neuronowej którego celem jest generowanie krótkich multi instrumentalnych klipów muzycznych.
|
||||
W pracy magisterskiej pod tytułem ,,Generowanie muzyki przy pomocy głębokiego uczenia'' został zaproponowany przykład sieci neuronowej, którego celem jest generowanie krótkich multi instrumentalnych klipów muzycznych.
|
||||
|
||||
Główna część pracy została poprzedzona wprowadzeniem do tematu sieci neuronowych oraz teorii muzyki, w celu lepszego zrozumienia omawianego tematu. W rozdziale~\ref{section:nets} przeznaczonym teorii sieci neuronowych autor przedstawia w jaki sposób rozbudować regresję liniową aby otrzymać model sieci neuronowej oraz przedstawia rekurencyjne sieci neuronowe, komórki LSTM oraz model sequence-to-sequence. W rozdziale~\ref{section:music} poświęconym teorii muzyki autor odróżnia dwa pojęcia, muzykę w rozumieniu fizycznego zjawiska, oraz muzykę symboliczną jaką obiekt abstrakcyjny. Następnie zostały opisane podstawowe obiekty muzyczne oraz przedstawiony protokół MIDI. Protokół MIDI jest międzynarodowym standardem komunikacji instrumentów muzycznych a w formie plików przechowuje informacje o muzyce w formie podobnej do zapisu nutowego. Pliki midi zostały wykorzystane jako źródło informacji dla sieci neuronowej.
|
||||
Główna część pracy została poprzedzona wprowadzeniem do tematu sieci neuronowych oraz teorii muzyki, w celu lepszego zrozumienia omawianego tematu. W rozdziale~\ref{section:nets} przeznaczonym teorii sieci neuronowych autor przedstawia w jaki sposób rozbudować regresję liniową, aby otrzymać model sieci neuronowej oraz przedstawia rekurencyjne sieci neuronowe, komórki LSTM oraz model sequence-to-sequence. W rozdziale~\ref{section:music} poświęconym teorii muzyki autor odróżnia dwa pojęcia, muzykę w rozumieniu fizycznego zjawiska oraz muzykę symboliczną jaką obiekt abstrakcyjny. Następnie zostały opisane podstawowe obiekty muzyczne oraz przedstawiony protokół MIDI. Protokół MIDI jest międzynarodowym standardem komunikacji instrumentów muzycznych a w formie plików przechowuje informacje o muzyce w formie podobnej do zapisu nutowego. Pliki midi zostały wykorzystane jako źródło informacji dla sieci neuronowej.
|
||||
|
||||
W rozdziale~\ref{section:project} została przedstawiona część główna pracy. Autor przyrównuje partie muzyczne do języka mówionego a różne instrumenty do różnych języków świata. Dlatego do generowania muzyki została wykorzystana architektura służąca do tłumaczenia maszynowego języków sequence-to-sequence. W pracy zostanie zaproponowane kodowanie muzyki jako sekwencje zdarzeń, nazywanych w pracy ,,muzycznymi słowami'', gdzie każde słowo posiada informacje o wysokości i długości trwania dźwięku, akordu lub pauzy. Następnie zostanie zademonstrowana architektura modelu wraz z jej implementacją w języku Python z wykorzystaniem biblioteki Keras oraz szczegóły opis procesu przygotowania danych dla modelu.
|
||||
|
||||
@ -190,7 +190,7 @@ The rest of this chapter discusses an example of using the proposed model to gen
|
||||
|
||||
W pierwszej części swojej pracy W pierwszej części pracy opiszę w jaki sposób działają sieci neuronowe, jak się uczą oraz podstawowe architektury sieci, które pomogą zrozumieć model który wykorzystałem. Następnie krótko przedstawię podstawowe koncepcje związane z muzyką oraz sposobami jej reprezentacji.
|
||||
|
||||
Następnie przedstawię swój projekt modelu. Omówię jakie idee stały za wyborami, które podjąłem w projektowaniu sieci. Szczegółowo opiszę sposób ekstrakcji danych tak aby mogły być one wykorzystane przez model. Opiszę architekturę którą wybrałem oraz przedstawię i opiszę fragmenty kodu w języku Python. W tym samym rozdziale zademonstruję na przykładowym zbiorze danych proces ich przetworzenia, uczenia modelu oraz generowania muzyki. Na końcu pokażę i omówię wyniki.
|
||||
Następnie przedstawię swój projekt modelu. Omówię jakie idee stały za wyborami, które podjąłem w projektowaniu sieci. Szczegółowo opiszę sposób ekstrakcji danych tak, aby mogły być one wykorzystane przez model. Opiszę architekturę którą wybrałem oraz przedstawię i opiszę fragmenty kodu w języku Python. W tym samym rozdziale zademonstruję na przykładowym zbiorze danych proces ich przetworzenia, uczenia modelu oraz generowania muzyki. Na końcu pokażę i omówię wyniki.
|
||||
|
||||
|
||||
\newpage
|
||||
@ -288,11 +288,11 @@ The rest of this chapter discusses an example of using the proposed model to gen
|
||||
|
||||
Dla funkcji $h(x)$ należy ustalić wartość początkową $\Theta_0$ dla wszystkich parametrów $\theta_1$ ... $\theta_p$.
|
||||
|
||||
\[ \Theta_0 = \mathbf{\boldsymbol{\left[ \theta_1, \theta_2, ... ,\theta_n \right]}}. \]
|
||||
\[ \Theta_0 = \left[ \theta_1, \theta_2, ... ,\theta_n \right]. \]
|
||||
|
||||
Następnie policzyć wszystkie pochodne częściowe $\frac{\partial J_\theta(h)}{\partial \theta_i}$. Otrzymamy w ten sposób gradient $\nabla J_\theta(h)$, gdzie
|
||||
\[
|
||||
\nabla J_\theta(h) = \mathbf{\boldsymbol{\left[ \frac{\partial J_\theta(h)}{\partial \theta_1}, \frac{\partial J_\theta(h)}{\partial \theta_2}, ... , \frac{\partial J_\theta(h)}{\partial \theta_p} \right]}}.
|
||||
\nabla J_\theta(h) = \left[ \frac{\partial J_\theta(h)}{\partial \theta_1}, \frac{\partial J_\theta(h)}{\partial \theta_2}, ... , \frac{\partial J_\theta(h)}{\partial \theta_p} \right].
|
||||
\]
|
||||
|
||||
Następnie obliczyć element $\Theta_{k+1}$ ze wzoru
|
||||
@ -397,14 +397,14 @@ The rest of this chapter discusses an example of using the proposed model to gen
|
||||
|
||||
W ten sposób możemy w łatwy sposób zmienić model regresji liniowej na model regresji logistycznej.
|
||||
\[
|
||||
\sigma(\boldsymbol{b}+\boldsymbol{XW}) = \hat{Y}.
|
||||
\sigma(\boldsymbol{b}+\boldsymbol{XW}) = \boldsymbol{\hat{Y}}.
|
||||
\]
|
||||
|
||||
W dalszych częściach pracy, kiedy będę używał funkcji aktywacji nie wskazując na konkretną funkcję, będę wykorzystywał oznaczenie $AF(x)$.
|
||||
|
||||
\section{Wielowarstwowe sieci neuronowe}
|
||||
|
||||
Model omawiany wcześniej może posłużyć jako podstawowy element do budowania bardziej skomplikowanych modeli. Aby to zrobić, należy potraktować otrzymany wektor $\boldsymbol{\hat{Y}}$ jako wektor wejściowy do następnego podstawowego modelu. Składając ze sobą wiele perceptronów w jeden model, tworzymy warstwy (\textit{ang. layers}) sieci neuronowej.
|
||||
Model omawiany wcześniej może posłużyć jako podstawowy element do budowania bardziej skomplikowanych modeli. Aby to zrobić, należy potraktować otrzymany wektor $\hat{Y}$ jako wektor wejściowy do następnego podstawowego modelu. Składając ze sobą wiele perceptronów w jeden model, tworzymy warstwy (\textit{ang. layers}) sieci neuronowej.
|
||||
|
||||
Wyróżniamy trzy rodzaje warstw:
|
||||
\begin{itemize}
|
||||
@ -481,7 +481,7 @@ The rest of this chapter discusses an example of using the proposed model to gen
|
||||
|
||||
\subsection{LSTM}
|
||||
|
||||
Komórki LSTM (\textit{ang. long-short term memory}) są rozszerzeniem neuronów sieci rekurencyjnych. Pozwalają wykrywać zależności w danych w długim okresie. Posiadają dwa wektory opisujące stan neuronu. Wektor $\boldsymbol{h_{(t)}}$ określa stan krótkookresowy i wektor $\boldsymbol{c_{(t)}}$ określa stan długookresowy.
|
||||
Komórki LSTM (\textit{ang. long-short term memory}) są rozszerzeniem neuronów sieci rekurencyjnych. Pozwalają wykrywać zależności w danych w długim okresie. Posiadają dwa wektory opisujące stan neuronu. Wektor $h_{(t)}$ określa stan krótkookresowy i wektor $c_{(t)}$ określa stan długookresowy.
|
||||
|
||||
\begin{figure}[!htb]
|
||||
\centering
|
||||
@ -490,7 +490,7 @@ The rest of this chapter discusses an example of using the proposed model to gen
|
||||
\label{fig:lstm}
|
||||
\end{figure}
|
||||
|
||||
Główny pomysł na funkcjonowanie komórek LSTM był taki, aby sieć sama mogła się nauczyć jakie informacje są istotne i je przechować, a które informacje można pominąć, zapomnieć. Schemat komórki LSTM przedstawiono na rysunku~\ref{fig:lstm}. Aby to osiągnąć powstała idea bramek (\textit{ang. gates}), oraz kontrolerów bramek (\textit{ang. gate controllers}). W komórce LSTM wyróżniamy trzy bramki. Bramkę zapomnienia (\textit{ang. forget gate}) sterowaną przez $f_{(t)}$, bramkę wejściową(\textit{ang. input gate}) sterowaną przez $i_{(t)}$, oraz bramkę wyjściową (\textit{ang. output gate}), sterowaną przez $o_{(t)}$. Przepływ danych w komórce LSTM zaczyna w miejscu gdzie wektor wejściowy $x_{(t)}$ i poprzedni krótkoterminowy stan $h_{(t-1)}$ trafiają do czterech warstw. Główną warstwą jest ta zwracająca $g_{(t)}$. W podstawowej komórce RNN jest tylko ta warstwa. Pozostałe trzy warstwy po przejściu przez funkcje logistyczne trafiają do bramek. Bramka zapomnienia kontroluje, które informacje z długookresowego stanu $c_{(t-1)}$ powinny zostać wykasowane. Bramka wejściowa kontroluje jakie informacje z $g_{(t)}$ powinny zostać przekazane dalej i dodane do następnego stanu długookresowego $c_{(t)}$. Bramka wyjściowa odpowiada za wybranie odpowiednich elementów z stanu długookresowego i przekazanie ich następnych kroku. Wynik komórki zostaje przekazany do wyjścia komórki $y_{(t)}$ oraz jako następny stan krótkoterminowy $h_{(t)}$.
|
||||
Główny pomysł na funkcjonowanie komórek LSTM był taki, aby sieć sama mogła się nauczyć jakie informacje są istotne i je przechować, a które informacje można pominąć, zapomnieć. Schemat komórki LSTM przedstawiono na rysunku~\ref{fig:lstm}. Aby to osiągnąć powstała idea bramek (\textit{ang. gates}) oraz kontrolerów bramek (\textit{ang. gate controllers}). W komórce LSTM wyróżniamy trzy bramki. Bramkę zapomnienia (\textit{ang. forget gate}) sterowaną przez $f_{(t)}$, bramkę wejściową(\textit{ang. input gate}) sterowaną przez $i_{(t)}$ oraz bramkę wyjściową (\textit{ang. output gate}), sterowaną przez $o_{(t)}$. Przepływ danych w komórce LSTM zaczyna w miejscu, gdzie wektor wejściowy $x_{(t)}$ i poprzedni krótkoterminowy stan $h_{(t-1)}$ trafiają do czterech warstw. Główną warstwą jest ta zwracająca $g_{(t)}$. W podstawowej komórce RNN jest tylko ta warstwa. Pozostałe trzy warstwy po przejściu przez funkcje logistyczne trafiają do bramek. Bramka zapomnienia kontroluje, które informacje z długookresowego stanu $c_{(t-1)}$ powinny zostać wykasowane. Bramka wejściowa kontroluje jakie informacje z $g_{(t)}$ powinny zostać przekazane dalej i dodane do następnego stanu długookresowego $c_{(t)}$. Bramka wyjściowa odpowiada za wybranie odpowiednich elementów z stanu długookresowego i przekazanie ich następnych kroku. Wynik komórki zostaje przekazany do wyjścia komórki $y_{(t)}$ oraz jako następny stan krótkoterminowy $h_{(t)}$.
|
||||
|
||||
Kolejne etapy komórki LSTM obliczane są zgodnie z poniższymi wzorami:
|
||||
\[
|
||||
@ -648,16 +648,19 @@ The rest of this chapter discusses an example of using the proposed model to gen
|
||||
|
||||
\footnotetext{https://amplitudaschool.weebly.com/lekcja-11.html 5 kwietnia 2020 13:24}
|
||||
|
||||
\subsubsection{Interwały}
|
||||
\subsubsection{Interwał}
|
||||
O interwałach mówimy, kiedy porównujemy ze sobą dwie nuty. Interwał jest to odległość między nutami, liczona w półnutach. Półnuta jest to najmniejsza odległość między nutami we współczesnej notacji muzycznej. Oktawa jest podzielona na 12 równych części. Pomiędzy dźwiękami C i D jest odległość
|
||||
dwóch półnut, natomiast między F oraz F\# jest odległość jednej półnuty. Dla ludzkiego ucha w celu rozpoznania melodii istotniejsze są interwały między kolejnymi nutami niż konkretna wysokość dźwięków.
|
||||
|
||||
\subsubsection{Oktawy}
|
||||
\subsubsection{Oktawa}
|
||||
|
||||
Oktawą nazywamy zestaw ośmiu nut od C do H. Podane w Tabeli~\ref{table:dzwieki} częstotliwości nut odpowiadają dźwiękom w oktawie czwartej. Dlatego w indeksie dolnym nuty widnieje liczba 4. Aby utworzyć dźwięk, np. $A_5$ należy pomnożyć częstotliwość dźwięku $A_4$ razy dwa, natomiast aby utworzyć dźwięk $A_3$, należy tę częstotliwość podzielić przez dwa.
|
||||
Oktawą nazywamy zestaw ośmiu nut od C do H. Podane w Tabeli~\ref{table:dzwieki} częstotliwości nut odpowiadają dźwiękom w oktawie czwartej. Dlatego w indeksie dolnym nuty widnieje liczba 4. Aby utworzyć dźwięk, np. $A_5$ należy pomnożyć częstotliwość dźwięku $A_4$ razy dwa natomiast, aby utworzyć dźwięk $A_3$, należy tę częstotliwość podzielić przez dwa.
|
||||
|
||||
\begin{center}
|
||||
$A_5$ = 2 * 440Hz = 880Hz \\
|
||||
$A_3$ = 1/2 * 440Hz = 220Hz
|
||||
\end{center}
|
||||
|
||||
\[ A_5 = 440Hz * 2 = 880Hz \]
|
||||
\[ A_3 = 440Hz / 2 = 220Hz \]
|
||||
|
||||
W ten sposób możemy stworzyć nieskończenie wiele oktaw, jednak w rzeczywistości używa się nut od C0 do C8.
|
||||
|
||||
@ -666,12 +669,12 @@ The rest of this chapter discusses an example of using the proposed model to gen
|
||||
|
||||
\subsubsection{Skala}
|
||||
\label{section:skala}
|
||||
Skala jest to zestaw nut, które dobrze ze sobą brzmią. Skalę opisujemy dwoma parametrami, tonacją, oraz modem. Tonacja jest to pierwsza nuta dla skali. Mod natomiast jest to zestaw interwałów liczony od pierwszej nuty. np. C-Dur, gdzie C jest wartością początkową, a Dur opisuje sekwencję interwałów. Możemy utworzyć inne skale, np G-Dur, używając tych samych interwałów, ale zaczynając od innej nuty.
|
||||
Skala jest to zestaw nut, które dobrze ze sobą brzmią. Skalę opisujemy dwoma parametrami, tonacją oraz modem. Tonacja jest to pierwsza nuta dla skali. Mod natomiast jest to zestaw interwałów liczony od pierwszej nuty. np. C-Dur, gdzie C jest wartością początkową, a Dur opisuje sekwencję interwałów. Możemy utworzyć inne skale, np G-Dur, używając tych samych interwałów, ale zaczynając od innej nuty.
|
||||
|
||||
\section{Cyfrowa reprezentacja muzyki symbolicznej}
|
||||
|
||||
\subsection{Standard MIDI}
|
||||
Standard MIDI (ang. Musical Instrument Digital Interface) został stworzony w 1983 aby umożliwić synchronizację i wymianę informacji między elektronicznymi urządzeniami muzycznymi takimi jak syntezatory, keyboardy czy sekwencery.
|
||||
Standard MIDI (ang. Musical Instrument Digital Interface) został stworzony w 1983, aby umożliwić synchronizację i wymianę informacji między elektronicznymi urządzeniami muzycznymi takimi jak syntezatory, keyboardy czy sekwencery.
|
||||
W późniejszych latach został on zaadaptowany do środowiska komputerowego jako cyfrowa reprezentacja muzyki symbolicznej.
|
||||
|
||||
\begin{figure}[!htb]
|
||||
@ -703,13 +706,13 @@ note_on channel=0 note=60 velocity=0 time=0
|
||||
note\textunderscore on channel 0 note 48 velocity 100 time 0 \\
|
||||
\end{center}
|
||||
|
||||
oznacza aby na kanele 0 zagrać dźwięk nr 48 z głośnością 100 w momencie 0 utworu. Nie informuje nas on jednak o długości trwania dźwięku. Aby zakończyć dźwięk, należy wysłać wiadomość:
|
||||
oznacza, aby na kanele 0 zagrać dźwięk nr 48 z głośnością 100 w momencie 0 utworu. Nie informuje nas on jednak o długości trwania dźwięku. Aby zakończyć dźwięk, należy wysłać wiadomość:
|
||||
|
||||
\begin{center}
|
||||
note\textunderscore off, channel 0, note 48, velocity 100, time 24. \\
|
||||
\end{center}
|
||||
|
||||
Zwróćmy uwagę, że aby ustalić wartość nuty potrzebujemy odebrać dwie wiadomości. Różnica między parametrami \textit{time}, informuje nas o długości nuty. W tym przypadku jest to 24.
|
||||
Zwróćmy uwagę, że aby ustalić wartość nuty potrzebujemy odebrać dwie wiadomości. Różnica między parametrami \textit{time} informuje nas o długości nuty. W tym przypadku jest to 24.
|
||||
Co oznacza ćwierćnutę.
|
||||
|
||||
\subsubsection{Rozdzielczość}
|
||||
@ -730,7 +733,7 @@ note_on channel=0 note=60 velocity=0 time=0
|
||||
Program w kontekście standardu MIDI oznacza instrument który ma zagrać nuty. W standardzie GM (ang. General MIDI), jest 16 grup instrumentów a w każdej z nich znajduje się po 8 instrumentów. Są to pianina, chromatyczne perkusje, organy, gitary, basy, instrumenty smyczkowe, zestawy instrumentów, instrumenty dmuchane blaszane, instrumenty dmuchane drewniane, flety, syntezatory prowadzące, syntezatory uzupełniające, efekty syntetyczne, instrumenty etniczne, perkusjonalia i efekty dźwiękowe.
|
||||
|
||||
\subsubsection{Ścieżka}
|
||||
Ścieżka (\textit{ang. track}) grupuje nuty aby podzielić utwór muzyczny na różne instrumenty lub partie. Protokół MIDI pozwala, aby grać wiele ścieżek dźwiękowych jednocześnie. Wtedy mówimy o muzyce polifonicznej lub multiinstrumentalnej.
|
||||
Ścieżka (\textit{ang. track}) grupuje nuty, aby podzielić utwór muzyczny na różne instrumenty lub partie. Protokół MIDI pozwala, aby grać wiele ścieżek dźwiękowych jednocześnie. Wtedy mówimy o muzyce polifonicznej lub multiinstrumentalnej.
|
||||
|
||||
\chapter{Projekt}
|
||||
\label{section:project}
|
||||
@ -743,7 +746,7 @@ note_on channel=0 note=60 velocity=0 time=0
|
||||
|
||||
Na podstawie tej idei postanowiłem opracować model składający się z wielu sieci neuronowych, każda z nich odpowiadać będzie jednej partii w utworze, muzykowi w zespole. Jedna z tych sieci będzie generatorem. Ta sieć powinna być skonstruowana w taki sposób, aby zainicjować partię muzyczną. Pozostałe będą dopasowywać swoje partie w taki sposób, aby pasowały pod partię wygenerowaną. Te sieci nazywać będę modelami akompaniujący. Dzięki temu jesteśmy wstanie stworzyć model wielu sieci, w którym następna sieć będzie produkować swoje partie na podstawie tego, co wygenerowała poprzednia.
|
||||
|
||||
Kluczowe było zauważenie podobieństwa między językiem naturalnym oraz muzyką. Zarówno zdanie jak i partia muzyczna składa się z sekwencji elementów rozmieszczonych w czasie. Elementy te są zależne od długoterminowego kontekstu, oraz od tego jaki element był ustawiony wcześniej. Dla języka naturalnego są to słowa, dla muzyki są to nuty i akordy. Dodatkowo pomyślałem, że różne instrumenty można porównać do różnych języków świata. Wtedy aby stworzyć melodię, np. basu, tak aby pasowała pod partię gitary, należy ,,przetłumaczy'' język gitary na język basu. Do tłumaczeń języka naturalnego wykorzystuje się modele sequence-to-sequence, dlatego postanowiłem w modelu generowania muzyki wykorzystać właśnie tą architekturę. Dodatkowo modele sequence-to-sequence mają tę cechę, że liczba elementów sekwencji wejściowej może być inna niż liczba elementów sekwencji wyjściowej. Idealnie sprawdzi się w przypadku muzyki, ponieważ o długości trwania ścieżki muzycznej nie świadczy liczba nut tylko suma ich wartości.
|
||||
Kluczowe było zauważenie podobieństwa między językiem naturalnym oraz muzyką. Zarówno zdanie jak i partia muzyczna składa się z sekwencji elementów rozmieszczonych w czasie. Elementy te są zależne od długoterminowego kontekstu oraz od tego jaki element był ustawiony wcześniej. Dla języka naturalnego są to słowa, dla muzyki są to nuty i akordy. Dodatkowo pomyślałem, że różne instrumenty można porównać do różnych języków świata. Wtedy, aby stworzyć melodię, np. basu tak, aby pasowała pod partię gitary, należy ,,przetłumaczy'' język gitary na język basu. Do tłumaczeń języka naturalnego wykorzystuje się modele sequence-to-sequence, dlatego postanowiłem w modelu generowania muzyki wykorzystać właśnie tą architekturę. Dodatkowo modele sequence-to-sequence mają tę cechę, że liczba elementów sekwencji wejściowej może być inna niż liczba elementów sekwencji wyjściowej. Idealnie sprawdzi się w przypadku muzyki, ponieważ o długości trwania ścieżki muzycznej nie świadczy liczba nut tylko suma ich wartości.
|
||||
|
||||
\section{Wstępne przygotowanie danych do treningu}
|
||||
\label{section:midi}
|
||||
@ -765,11 +768,11 @@ note_on channel=0 note=60 velocity=0 time=0
|
||||
((60, 64, 67), 0.5)
|
||||
\end{center}
|
||||
|
||||
W ten sposób jesteśmy w stanie kodować melodię w sekwencji słów muzycznych. Tak skonstruowane dane mają niestety swoje negatywne aspekty. Nie da się w ten sposób zapisać partii, w której zostaje grana nowa nuta gdy poprzednia jeszcze powinna brzmieć. Nasz zapis zakłada, że melodia jest grana element po elemencie i nowy element wymusza zakończenie poprzedniego. Nie przechowujemy również informacji o dynamice melodii (głośności). Rozszerzenie tego zapisu o informacje o głośności nie jest trudne i nie będzie wymagać przebudowy modelu, natomiast wraz ze wzrostem liczby możliwych ,,słów muzycznych'' w słowniku i zwiększa złożoność obliczeniową. Zdecydowałem się na niewykorzystanie tych danych w generowaniu muzyki.
|
||||
W ten sposób jesteśmy w stanie kodować melodię w sekwencji słów muzycznych. Tak skonstruowane dane mają niestety swoje negatywne aspekty. Nie da się w ten sposób zapisać partii, w której zostaje grana nowa nuta, gdy poprzednia jeszcze powinna brzmieć. Nasz zapis zakłada, że melodia jest grana element po elemencie i nowy element wymusza zakończenie poprzedniego. Nie przechowujemy również informacji o dynamice melodii (głośności). Rozszerzenie tego zapisu o informacje o głośności nie jest trudne i nie będzie wymagać przebudowy modelu, natomiast wraz ze wzrostem liczby możliwych ,,słów muzycznych'' w słowniku i zwiększa złożoność obliczeniową. Zdecydowałem się na niewykorzystanie tych danych w generowaniu muzyki.
|
||||
|
||||
\subsection{Konwersja MIDI na sekwencje słów muzycznych}
|
||||
|
||||
Powszechny sposób przechowywania muzyki symbolicznej w formie cyfrowej to pliki *.mid lub *.midi które przechowują informację o potoku wiadomości protokołu MIDI. Aby odczytać wiadomości z plików MIDI wykorzystałem bibliotekę \pyth{pretty_midi}, która zawiera wiele funkcji pozwalających na edycję plików MIDI.
|
||||
Powszechny sposób przechowywania muzyki symbolicznej w formie cyfrowej to pliki *.mid lub *.midi, które przechowują informację o potoku wiadomości protokołu MIDI. Aby odczytać wiadomości z plików MIDI wykorzystałem bibliotekę \pyth{pretty_midi}, która zawiera wiele funkcji pozwalających na edycję plików MIDI.
|
||||
|
||||
Aby otworzyć pliki midi za pomocą biblioteki \pyth{pretty_midi}, należy skorzystać z poniższej składni.
|
||||
|
||||
@ -852,7 +855,7 @@ def parse_pretty_midi_instrument(instrument, resolution,
|
||||
|
||||
\end{python}
|
||||
|
||||
Powyższa funkcja w zamienia wartości absolutne czasu, na wartości względne o ustalonej rozdzielczości przez plik MIDI. Dodatkowo zmniejsza szczegółowość, i zaokrągla czas zagrania nuty po szesnastki. Gdy w tym samym momencie, czyli jeśli kilka nut posiada tą samą wartość start, zostają dodane do jednego słowa muzycznego aby utworzyć akord. Pauzy są kodowane jako $-1$. Dodatkowo jeśli pauza trwa dłużej niż takt wtedy zostaje podzielona na mniejsze części o długości \pyth{max_rest_len}. Funkcja zwraca obiekt \pyth{SingleTrack}, który jest obiektem stworzonym aby poza nutami, przechowywać inne istotne informacje na temat ścieżki, którą będą istotne w następnych częściach przetwarzania danych. Ostatecznie sekwencje słów muzycznych przechowane są w \pyth{notes}.
|
||||
Powyższa funkcja w zamienia wartości absolutne czasu, na wartości względne o ustalonej rozdzielczości przez plik MIDI. Dodatkowo zmniejsza szczegółowość i zaokrągla czas zagrania nuty po szesnastki. Gdy w tym samym momencie, czyli jeśli kilka nut posiada tą samą wartość start, zostają dodane do jednego słowa muzycznego, aby utworzyć akord. Pauzy są kodowane jako $-1$. Dodatkowo jeśli pauza trwa dłużej niż takt wtedy zostaje podzielona na mniejsze części o długości \pyth{max_rest_len}. Funkcja zwraca obiekt \pyth{SingleTrack}, który jest obiektem stworzonym, aby poza nutami, przechowywać inne istotne informacje na temat ścieżki, którą będą istotne w następnych częściach przetwarzania danych. Ostatecznie sekwencje słów muzycznych przechowane są w \pyth{notes}.
|
||||
|
||||
\begin{python}
|
||||
>>> resolution = midi.resolution
|
||||
@ -947,11 +950,11 @@ def get_data_seq2seq_melody(self, instrument_class,
|
||||
\subsubsection{Przygotowanie danych dla akompaniamentu}
|
||||
|
||||
Model akompaniujący natomiast, będzie na podstawie partii instrumentu tworzyć partię na nowy instrument.
|
||||
Niech $G, B$ będą sekcjami muzycznymi różnych instrumentów tej samej długości oraz niech
|
||||
Niech $G$, $B$ będą sekcjami muzycznymi różnych instrumentów tej samej długości oraz niech
|
||||
\[
|
||||
\begin{array}{c}
|
||||
G = \left[g_1, g_2, ..., g_k \right], \\
|
||||
B = \left[b_1, b_2, ..., b_k \right],
|
||||
\boldsymbol{G} = \left[g_1, g_2, ..., g_k \right], \\
|
||||
\boldsymbol{B} = \left[b_1, b_2, ..., b_k \right],
|
||||
\end{array}
|
||||
\]
|
||||
wówczas pary dla zbioru uczącego tworzymy w następujący sposób
|
||||
@ -964,7 +967,7 @@ def get_data_seq2seq_melody(self, instrument_class,
|
||||
\]
|
||||
|
||||
dla $t \in (1, k)$.
|
||||
Istotne jest aby każdy element ze zbioru taktów partii $B$ był rzeczywistą aranżacją tego instrumentu dla taktów partii $G$ oraz aby między elementami $g_t$ oraz $b_t$ była muzyczna relacja.
|
||||
Istotne jest, aby każdy element ze zbioru taktów partii $B$ był rzeczywistą aranżacją tego instrumentu dla taktów partii $G$ oraz, aby między elementami $g_t$ oraz $b_t$ była muzyczna relacja.
|
||||
|
||||
Implementacja przedstawionej techniki w Pythonie.
|
||||
\begin{python}
|
||||
@ -1005,7 +1008,7 @@ def get_data_seq2seq_arrangment(self, x_instrument,
|
||||
Podczas etapu ekstrakcji danych z plików MIDI poza informacjami o muzyce, zapamiętuję również informacje o programie partii muzycznej. Każda ścieżka MIDI przechowuje informacje o instrumencie (brzmieniu) danej partii. Istnieje 128 różnych programów, dla zmniejszenia szczególności na potrzeby modelu wyróżniam 16 instrumentów zgodnie z grupą do jakiej należą w podziale General MIDI. Dla każdej z grup, sprawdzam jaki program został najczęściej wykorzystywany i zapisuję go na przyszłość, aby móc wygenerowanej muzyce przy kompilacji do MIDI zdefiniować brzmienie instrumentu zgodnie z najczęściej wykorzystywanym w zbiorze MIDI, który został wykorzystany do stworzenia zbioru uczącego dla modelu.
|
||||
|
||||
\subsubsection{Melodia}
|
||||
Dodatkowym elementem procesu ekstrakcji danych jest znalezienie ścieżek melodii przewodnich w plikach MIDI. Ścieżki tego typu zamiast być oznaczone nazwą grupy instrumentów do której należą oznaczone są nazwą \pyth{Melody}. Melodia jest kategorią ścieżek z podziału ze względu na rolę partii w utworze, zamiast na instrument. Istnieją też inne role instrumentów, jednak często rola jest w pewnym sensie definiowana przez instrument. Nie jest to zasada, bardziej prawidłowość w muzyce. Uznałem że wydobycie tej informacji na temat ścieżki nada więcej muzycznego sensu danym.
|
||||
Dodatkowym elementem procesu ekstrakcji danych jest znalezienie ścieżek melodii przewodnich w plikach MIDI. Ścieżki tego typu zamiast być oznaczone nazwą grupy instrumentów, do której należą oznaczone są nazwą \pyth{Melody}. Melodia jest kategorią ścieżek z podziału ze względu na rolę partii w utworze, zamiast na instrument. Istnieją też inne role instrumentów, jednak często rola jest w pewnym sensie definiowana przez instrument. Nie jest to zasada, bardziej prawidłowość w muzyce. Uznałem że wydobycie tej informacji na temat ścieżki nada więcej muzycznego sensu danym.
|
||||
Aby sprawdzić czy dana ścieżka jest melodią zastosowałem poniższą funkcję:
|
||||
|
||||
\begin{python}
|
||||
@ -1054,13 +1057,13 @@ Funkcja sprawdza liczbę pojedynczych nut i akordów w ścieżce oraz zagęszcze
|
||||
|
||||
Wszystkie modele sieci neuronowych zastosowane w tej pracy, zostały napisane z wykorzystaniem środowiska Keras. Keras jest to środowisko wyższego poziomu, służące do tworzenia modelu głębokiego uczenia.
|
||||
|
||||
Model sequence-to-sequence, jest to model składający się z dwóch mniejszych sieci neuronowych, enkodera i dekodera. Dodatkowo inaczej definiuje się model aby go uczyć, a inaczej aby dokonać predykcji.
|
||||
Model sequence-to-sequence, jest to model składający się z dwóch mniejszych sieci neuronowych, enkodera i dekodera. Dodatkowo inaczej definiuje się model, aby go uczyć a inaczej, aby dokonać predykcji.
|
||||
|
||||
\subsection{Model w trybie uczenia}
|
||||
|
||||
\subsubsection{Definiowanie warstw enkodera}
|
||||
|
||||
Zadaniem enkodera jest wydobycie z przetwarzanej sekwencji kontekstu, skompresowanej informacji o danych. W tym celu zastosowana została jedna warstwa wejściowa o rozmiarze słownika wejściowego, oraz warstwa LSTM. Definiowane warstwy są atrybutami całej klasy modelu, dlatego w prezentowanym kodzie występuje przedrostek \pyth{self.}.
|
||||
Zadaniem enkodera jest wydobycie z przetwarzanej sekwencji kontekstu, skompresowanej informacji o danych. W tym celu zastosowana została jedna warstwa wejściowa o rozmiarze słownika wejściowego oraz warstwa LSTM. Definiowane warstwy są atrybutami całej klasy modelu, dlatego w prezentowanym kodzie występuje przedrostek \pyth{self.}.
|
||||
|
||||
\begin{python}
|
||||
self.encoder_inputs =
|
||||
@ -1128,12 +1131,12 @@ self.train_model.compile(optimizer='rmsprop',
|
||||
|
||||
Możemy zauważyć, że w procesie uczenia musimy zaprezentować modelowi dwa wektory danych wejściowych oraz jednego wektora danych wyjściowych. W pracy zostały one opisane jako:
|
||||
\begin{itemize}
|
||||
\item \pyth{encoder_input_data}, zawierające sekwencję elementów wejściowych. Te dane będą zasilać encoder aby na ich podstawie został wygenerowany kontekst.
|
||||
\item \pyth{encoder_input_data}, zawierające sekwencję elementów wejściowych. Te dane będą zasilać enkoder, aby na ich podstawie został wygenerowany kontekst.
|
||||
\item \pyth{decoder_input_data}, zawierające sekwencje elementów wyjściowych opóźnione o jeden element w czasie. Te dane będą zasilały dekoder.
|
||||
\item \pyth{decoder_target_data}, zawierające sekwencje elementów wyjściowych, które będą celem.
|
||||
\end{itemize}
|
||||
|
||||
Jest to ciekawe, że musimy dostarczyć do modelu dane, które tak naprawdę chcemy otrzymać. Jednak te dane są przesunięte o jeden element w sekwencji do przodu i pierwszy element tej sekwencji nie zawiera treści. Dekoder uczy się jak na podstawie aktualnego stanu enkodera oraz aktualnego elementu sekwencji wyjściowej jaki powinien być następny element w sekwencji docelowej. Warto też zauważyć, że z definicji modelu nie wynika aby model uczył się przetwarzania całych sekwencji, tylko każdego elementu sekwencji z osobna.
|
||||
Jest to ciekawe, że musimy dostarczyć do modelu dane, które tak naprawdę chcemy otrzymać. Jednak te dane są przesunięte o jeden element w sekwencji do przodu i pierwszy element tej sekwencji nie zawiera treści. Dekoder uczy się jak na podstawie aktualnego stanu enkodera oraz aktualnego elementu sekwencji wyjściowej jaki powinien być następny element w sekwencji docelowej. Warto też zauważyć, że z definicji modelu nie wynika, aby model uczył się przetwarzania całych sekwencji, tylko każdego elementu sekwencji z osobna.
|
||||
|
||||
\subsection{Model w trybie wnioskowania}
|
||||
\label{section:inference-model}
|
||||
@ -1195,7 +1198,9 @@ def predict(self, input_seq=None, mode=None):
|
||||
1
|
||||
|
||||
stop_condition = False
|
||||
decoded_sentence = []
|
||||
decoded_seq = []
|
||||
|
||||
y_vocab_size = self.transformer.y_vocab_size
|
||||
|
||||
while not stop_condition:
|
||||
|
||||
@ -1206,36 +1211,36 @@ def predict(self, input_seq=None, mode=None):
|
||||
np.argmax(output_tokens[0, -1, :])
|
||||
sampled_char =
|
||||
self.transformer.y_reverse_dict[sampled_token_index]
|
||||
decoded_sentence.append(sampled_char)
|
||||
decoded_seq.append(sampled_char)
|
||||
|
||||
if (sampled_char == '<EOS>' or
|
||||
len(decoded_sentence) > self.transformer.y_max_seq_length):
|
||||
len(decoded_seq) > self.transformer.y_max_seq_length):
|
||||
stop_condition = True
|
||||
|
||||
target_seq = np.zeros((1, 1, self.transformer.y_vocab_size))
|
||||
target_seq = np.zeros((1, 1, y_vocab_size))
|
||||
target_seq[0, 0, sampled_token_index] = 1.
|
||||
|
||||
states_value = [h, c]
|
||||
|
||||
return decoded_sentence
|
||||
return decoded_seq
|
||||
|
||||
\end{python}
|
||||
|
||||
Encoder w tym trybie ma za zadanie tylko dostarczyć do dekodera wektory kontekstu dla zainicjowania procesu. Dekoder na podstawie wektorów pamięci $h$ i $c$ przewidzi pierwszy element sekwencji i tym samym zainicjuje proces wnioskowania.
|
||||
Enkoder w tym trybie ma za zadanie tylko dostarczyć do dekodera wektory kontekstu dla zainicjowania procesu. Dekoder na podstawie wektorów pamięci $h$ i $c$ przewidzi pierwszy element sekwencji i tym samym zainicjuje proces wnioskowania.
|
||||
|
||||
W tym miejscu mamy kontrolę twórczą nad dekoderem. Aby zainicjować reakcję wystarczą wektory pamięci, możemy wtedy podać je w dowolny sposób i zobaczyć co wygeneruje dekoder. W mojej pracy próbowałem dwóch sposób na zainicjowanie procesu predykcji z wektorów losowych. Pierwszy polega na wygenerowaniu losowej sekwencji dla enkodera i nazywam tę metodę \pyth{from_seq}. Druga metoda polega na bezpośrednim definiowaniu stanu $h$ i $c$ \pyth{states_value} w sposób losowy tak aby wartości były z przedziału [-1, 1].
|
||||
W tym miejscu mamy kontrolę twórczą nad dekoderem. Aby zainicjować reakcję wystarczą wektory pamięci, możemy wtedy podać je w dowolny sposób i zobaczyć co wygeneruje dekoder. W mojej pracy próbowałem dwóch sposób na zainicjowanie procesu predykcji z wektorów losowych. Pierwszy polega na wygenerowaniu losowej sekwencji dla enkodera i nazywam tę metodę \pyth{from_seq}. Druga metoda polega na bezpośrednim definiowaniu stanu $h$ i $c$ \pyth{states_value} w sposób losowy tak, aby wartości były z przedziału [-1, 1].
|
||||
|
||||
\section{Transformacja danych dla modelu}
|
||||
|
||||
Na podstawie definicji modelu wiemy, że należy przygotować trzy zestawy danych aby móc wytrenować model. Dwa zestawy danych wejściowych i jeden zestaw danych wyjściowych. Musimy również zakodować sekwencje elementów w taki sposób aby można było wykonywać na nich obliczenia.
|
||||
Na podstawie definicji modelu wiemy, że należy przygotować trzy zestawy danych, aby móc wytrenować model. Dwa zestawy danych wejściowych i jeden zestaw danych wyjściowych. Musimy również zakodować sekwencje elementów w taki sposób, aby można było wykonywać na nich obliczenia.
|
||||
|
||||
\subsection{Enkodowanie one-hot}
|
||||
|
||||
Każdy element sekwencji jest osobną kategorią, dlatego dane należy traktować tak jak dane kategoryczne. Wykorzystamy w tym celu enkodowanie one-hot (\textit{one-hot encoding}) Enkodowanie One-Hot jest wykorzystywane w uczeniu maszynowym aby nadać liczbową wartość danych kategorycznych. Polega ona stworzeniu słownika, w którym każde słowo otrzyma swój unikatowy identyfikator, następnie zostanie utworzony wektor o wymiarze słów w słowniku, gdzie na pozycji odpowiadającej indeksowi słowa będzie wartość 1 a na pozostałych będzie wartość zero \cite{onehot}.
|
||||
Każdy element sekwencji jest osobną kategorią, dlatego dane należy traktować tak jak dane kategoryczne. Wykorzystamy w tym celu enkodowanie one-hot (\textit{ang. one-hot encoding}) Enkodowanie One-Hot jest wykorzystywane w uczeniu maszynowym, aby nadać liczbową wartość danych kategorycznych. Polega ona stworzeniu słownika, w którym każde słowo otrzyma swój unikatowy identyfikator, następnie zostanie utworzony wektor o wymiarze słów w słowniku, gdzie na pozycji odpowiadającej indeksowi słowa będzie wartość 1 a na pozostałych będzie wartość zero \cite{onehot}.
|
||||
|
||||
\subsubsection{Przykład działania One-Hot Encoding}
|
||||
\subsubsection{Przykład enkodowania one-hot}
|
||||
|
||||
Weźmy sekwencję liter w słowie MATEMATYKA. Znajdźmy unikatowe elementy tej sekwencji, oraz nadajmy im unikatowy identyfikator. Kolejność nie ma znaczenia.
|
||||
Weźmy sekwencję liter w słowie MATEMATYKA. Znajdźmy unikatowe elementy tej sekwencji oraz nadajmy im unikatowy identyfikator. Kolejność nie ma znaczenia.
|
||||
|
||||
\begin{center}
|
||||
M - 0,
|
||||
@ -1249,7 +1254,6 @@ K - 5.
|
||||
Kodując słowo MATEMATYKA, otrzymalibyśmy macierz
|
||||
|
||||
\[
|
||||
\mathbb{\boldsymbol{
|
||||
\begin{bmatrix}
|
||||
1 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 1 \\
|
||||
0 & 1 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\
|
||||
@ -1257,7 +1261,7 @@ Kodując słowo MATEMATYKA, otrzymalibyśmy macierz
|
||||
0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\
|
||||
0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 \\
|
||||
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 \\
|
||||
\end{bmatrix} }}
|
||||
\end{bmatrix}
|
||||
\]
|
||||
|
||||
\subsection{Słownik}
|
||||
@ -1292,7 +1296,7 @@ self.y_reverse_dict = dict(
|
||||
|
||||
\subsection{Elementy specjalne}
|
||||
|
||||
Dodaje się dwóch elementów specjalnych. Te elementy mają za zadanie oznaczenie początku i końca sekwencji. Token początku sekwencji zazwyczaj oznaczany jest jako \pyth{<SOS>} (\textit{ang. start of sequence}). Można spotkać również inne oznaczenia,np. \pyth{<GO>} lub \pyth{<s>}. Ten element ma na celu wypełnienie przestrzeni pierwszego pustego miejsca w danych wejściowych dla dekodera. Token końca sekwencji oznaczany jako \pyth{<EOS>} (\textit{ang. start of sequence}) lub \pyth{</s>}. Ten element jest wykorzystywany aby wywołać warunek stopu w procesie predykcji opisanym w rozdziale~\ref{section:inference-model}.
|
||||
Dodaje się dwóch elementów specjalnych. Te elementy mają za zadanie oznaczenie początku i końca sekwencji. Token początku sekwencji zazwyczaj oznaczany jest jako \pyth{<SOS>} (\textit{ang. start of sequence}). Można spotkać również inne oznaczenia,np. \pyth{<GO>} lub \pyth{<s>}. Ten element ma na celu wypełnienie przestrzeni pierwszego pustego miejsca w danych wejściowych dla dekodera. Token końca sekwencji oznaczany jako \pyth{<EOS>} (\textit{ang. start of sequence}) lub \pyth{</s>}. Ten element jest wykorzystywany, aby wywołać warunek stopu w procesie predykcji opisanym w rozdziale~\ref{section:inference-model}.
|
||||
|
||||
\begin{python}
|
||||
_y_train = []
|
||||
@ -1343,11 +1347,11 @@ for i, (x_train, y_train) in enumerate(zip(x_train, y_train)):
|
||||
|
||||
W ten sposób otrzymujemy trzy zestawy danych potrzebne do przeprowadzenia procesu uczenia modelu.
|
||||
|
||||
Warto zwrócić uwagę, że przed opisaną transformacją sekwencje były różnej długości a po niej, rozmiar sekwencji został rozszerzony do rozmiaru sekwencji posiadającej najwięcej elementów. Taki zabieg był niezbędny ponieważ rozmiar sieci neuronowej jest stały dla wszystkich prób ze zbioru uczącego. Nie wpływa to jednak na same sekwencję ponieważ podczas predykcję kończymy w momencie wygenerowania tokenu \pyth{<EOS>}.
|
||||
Warto zwrócić uwagę, że przed opisaną transformacją sekwencje były różnej długości a po niej, rozmiar sekwencji został rozszerzony do rozmiaru sekwencji posiadającej najwięcej elementów. Taki zabieg był niezbędny, ponieważ rozmiar sieci neuronowej jest stały dla wszystkich prób ze zbioru uczącego. Nie wpływa to jednak na same sekwencję, ponieważ podczas predykcję kończymy w momencie wygenerowania tokenu \pyth{<EOS>}.
|
||||
|
||||
\section{Ekperyment}
|
||||
|
||||
W tej części pokażę jak wykorzystać oprogramowanie, które stworzyłem aby wygenerować muzykę na przykładzie. Omówię cały proces, następnie zademonstruję wyniki.
|
||||
W tej części pokażę jak wykorzystać oprogramowanie, które stworzyłem, aby wygenerować muzykę na przykładzie. Omówię cały proces, następnie zademonstruję wyniki.
|
||||
|
||||
\subsection{Oprogramowanie}
|
||||
Stworzone przeze mnie oprogramowanie, napisane w języku Python, składa się z 2 bibliotek oraz 3 skryptów.
|
||||
@ -1357,10 +1361,10 @@ Stworzone przeze mnie oprogramowanie, napisane w języku Python, składa się z
|
||||
\item \pyth{model.py} - zawiera definicję modelu sieci neuronowej
|
||||
\item \pyth{extract.py} - służy do wydobycia w plików midi zbioru danych w postaci sekwencji.
|
||||
\item \pyth{train.py} - wykonując ten skrypt wykorzystujemy wygenerowane dane, aby wytrenować zestaw sieci neuronowych.
|
||||
\item \pyth{generate.py} - wykorzystuje wytrenowane modele aby wygenerować ostatecznie plik midi.
|
||||
\item \pyth{generate.py} - wykorzystuje wytrenowane modele, aby wygenerować ostatecznie plik midi.
|
||||
\end{itemize}
|
||||
|
||||
Fragmenty bilbiotek \pyth{midi_procesing.py} i \pyth{model.py} zostały szczegółowo omówione w rozdziałach ~\ref{section:midi} i ~\ref{section:model}. Natomiast skrypty \pyth{extract.py}, \pyth{train.py} i \pyth{generate.py} zostały napisane aby ułatwić proces generowania oraz zapewniają powtarzalność i skalowalność prowadzonych eksperymentów.
|
||||
Fragmenty bilbiotek \pyth{midi_procesing.py} i \pyth{model.py} zostały szczegółowo omówione w rozdziałach ~\ref{section:midi} i ~\ref{section:model}. Natomiast skrypty \pyth{extract.py}, \pyth{train.py} i \pyth{generate.py} zostały napisane, aby ułatwić proces generowania oraz zapewniają powtarzalność i skalowalność prowadzonych eksperymentów.
|
||||
|
||||
\subsection{Zbiór danych}
|
||||
W omawianym przykładzie wykorzystałem zbiór wybranych utworów midi zespołu The Offspring. Został on skompletowany ze źródeł dostępnych na stronie internetowej https://www.midiworld.com/. Składa się z 7 utworów.
|
||||
@ -1434,7 +1438,7 @@ Na podstawie takiego zbioru danych, w następnym kroku zostaną wytrenowane czte
|
||||
|
||||
\subsection{Trenowanie modelu}
|
||||
|
||||
Uzywając skypt \pyth{train.py} możemy w prosty sposób wytrenować wszystkie modele, a wagi zapiszą i będzie można je wykorzystać w celu generowania, lub w celu dalszego uczenia.
|
||||
Uzywając skypt \pyth{train.py} możemy w prosty sposób wytrenować wszystkie modele, a wagi zapiszą i będzie można je wykorzystać w celu generowania lub w celu dalszego uczenia.
|
||||
|
||||
\begin{python}
|
||||
>>> python train.py offspring --e 1
|
||||
@ -1474,7 +1478,7 @@ Na potrzeby badań trenowałem i generowałem klipy muzyczne dla epok 1, 10, 25,
|
||||
|
||||
\subsection{Generowanie muzyki przy pomocy wytrenowanych modeli}
|
||||
|
||||
Gdy zdefiniowane modele zostaną wytrenowane możemy wykorzystać skrypt \pyth{generate.py}, wtedy generująca sieć neuonowa zostanie zasilona losowym wektorem aby wygenerować partię. W tym przykładzie gitary a wygenerowana partia posłuży jako dane wejściowe na pozostałych modeli. Ostatecznie otrzymane sekwencje zostaną skompilowane do pliku MIDI. W tym momencie zostają wykorzystane informacje o programach dla każdego z instrumentów, a tempo utworu domyślnie ustawione jest na 120 BPM. Możemy również zdecydować, czy zasilanie dekodera modelu generującego odbędzie się za pomocą losowej sekwencji elementów ze słownika (\textit{from\textunderscore seq}), czy losowy wektor zasili bezpośrednio stany wewnętrzne dekodera $h$ i $c$ (\textit{from\textunderscore state}).
|
||||
Gdy zdefiniowane modele zostaną wytrenowane możemy wykorzystać skrypt \pyth{generate.py}, wtedy generująca sieć neuonowa zostanie zasilona losowym wektorem, aby wygenerować partię. W tym przykładzie gitary a wygenerowana partia posłuży jako dane wejściowe na pozostałych modeli. Ostatecznie otrzymane sekwencje zostaną skompilowane do pliku MIDI. W tym momencie zostają wykorzystane informacje o programach dla każdego z instrumentów, a tempo utworu domyślnie ustawione jest na 120 BPM. Możemy również zdecydować, czy zasilanie dekodera modelu generującego odbędzie się za pomocą losowej sekwencji elementów ze słownika (\textit{from\textunderscore seq}), czy losowy wektor zasili bezpośrednio stany wewnętrzne dekodera $h$ i $c$ (\textit{from\textunderscore state}).
|
||||
|
||||
\begin{python}
|
||||
>>> python generate.py offspring --i 10 --m from_state
|
||||
@ -1504,7 +1508,7 @@ Przekazywanie wygenerowanych partii to odpowiednich modeli wykonywane jest przy
|
||||
\end{python}
|
||||
|
||||
Słownik \pyth{band} przechowuje dane dotyczące całego zespołu modeli. Zmienna \pyth{instrument} jest nazwą instrumentu, \pyth{model} przechowuje obiekt modelu \\
|
||||
sequence-to-sequence, \pyth{program} jest liczbą naturalną odpowiadającą programowi MIDI z kolekcji GM a \pyth{generator} to nazwa instrumentu na podstawie którego powinna zostać wygenerowana kolejna partia instrumentalna.
|
||||
sequence-to-sequence, \pyth{program} jest liczbą naturalną odpowiadającą programowi MIDI z kolekcji GM a \pyth{generator} to nazwa instrumentu na podstawie, którego powinna zostać wygenerowana kolejna partia instrumentalna.
|
||||
|
||||
Kompilacja do MIDI zachodzi z wykorzystaniem klas biblioteki \\
|
||||
\pyth{midi_processing.py}, które wspierają format sekwencji słów muzycznych omówionych w rozdziale ~\ref{section:midi_words}.
|
||||
@ -1542,7 +1546,7 @@ Utwór przedstawiony na rysunku~\ref{fig:score1} został wygenerowany po pierwsz
|
||||
\label{fig:score1}
|
||||
\end{figure}
|
||||
|
||||
Po dziesięciu epokach treningu melodia dalej wygląda na bardzo powtarzalną, jednak teraz jest bardziej spójna. Na przedstawionej na rysunku~\ref{fig:score10} partyturze widać, że model wygenerował partię gitary. Jednostajnie, co ćwierćnutę gra akord C-G-C (tzw. Power Chord) popularnie stosowany w muzyce rockowej. Perkusja wybija tylko jedną perkusjonalię, hi-hat. Melodia gra dźwięk C ale oktawę wyżej niż poprzednio, podobnie jak bas, tylko bas gra oktawę niżej niż poprzednio. Cały utwór oparty jest na dźwięku C, co pomimo monotonnej i mało ciekawej aranżacji jest muzycznie poprawnie i nie powoduje fałszu ani dysonansu w odbiorze.
|
||||
Po dziesięciu epokach treningu melodia dalej wygląda na bardzo powtarzalną, jednak teraz jest bardziej spójna. Na przedstawionej na rysunku~\ref{fig:score10} partyturze widać, że model wygenerował partię gitary. Jednostajnie, co ćwierćnutę gra akord C-G-C (tzw. Power Chord) popularnie stosowany w muzyce rockowej. Perkusja wybija tylko jedną perkusjonalię, hi-hat. Melodia gra dźwięk C, ale oktawę wyżej niż poprzednio, podobnie jak bas, tylko bas gra oktawę niżej niż poprzednio. Cały utwór oparty jest na dźwięku C, co pomimo monotonnej i mało ciekawej aranżacji jest muzycznie poprawnie i nie powoduje fałszu ani dysonansu w odbiorze.
|
||||
|
||||
\begin{figure}[!htb]
|
||||
\centering
|
||||
@ -1560,7 +1564,7 @@ Piętnaście epok później, na rysunku~\ref{fig:score25} model generujący gita
|
||||
\label{fig:score25}
|
||||
\end{figure}
|
||||
|
||||
Na rysunku~\ref{fig:score50} przedstawiono utwór po pięćdziesięciu epokach. W tym momencie partia gitary zaczyna wykorzystywać dwa akordy. Daje to prostą progresję akordów a to mocno urozmaica utwór. Perkusja stała się bardziej jednolita a melodia ciekawsza. Bas w dalszym ciągu monotonnie wygrywa dźwięk C, nawet w momentach gdzie gitara gra akord B$\flat$. Lepsze w tej sytuacji było by zagranie B$\flat$ również na basie.
|
||||
Na rysunku~\ref{fig:score50} przedstawiono utwór po pięćdziesięciu epokach. W tym momencie partia gitary zaczyna wykorzystywać dwa akordy. Daje to prostą progresję akordów a to mocno urozmaica utwór. Perkusja stała się bardziej jednolita a melodia ciekawsza. Bas w dalszym ciągu monotonnie wygrywa dźwięk C nawet w momentach, gdzie gitara gra akord B$\flat$. Lepsze w tej sytuacji było by zagranie B$\flat$ również na basie.
|
||||
|
||||
\begin{figure}[!htb]
|
||||
\centering
|
||||
@ -1598,7 +1602,7 @@ Na rysunku~\ref{fig:score100} i rysunku~\ref{fig:score150} przedstawiono odpowie
|
||||
|
||||
Celem pracy było zaprezentowanie modelu, który byłby w stanie generować krótkie multiinstrumentalne utwory muzyczne. Sądzę że cel pracy został osiągnięty. Model potrafi uczyć się z plików MIDI oraz reprodukować muzykę podobną do tej, z której się uczył. Ocenienie jakości generowanej muzyki jest trudne i subiektywne, ale sądzę że przy odpowiednio dobranym zbiorze uczącym i konfiguracji można wygenerować ciekawe rezultaty.
|
||||
|
||||
Pomimo, że zaprezentowany przeze mnie model posiada potencjał nie sądzę aby mógł on zastąpić ludzi w produkcji muzyki. Natomiast uważam, że mógłby zainspirować muzyków krótkim utworem, który następnie mógłby zostać rozbudowany przez nich do pełnego utworu.
|
||||
Pomimo, że zaprezentowany przeze mnie model posiada potencjał nie sądzę, aby mógł on zastąpić ludzi w produkcji muzyki. Natomiast uważam, że mógłby zainspirować muzyków krótkim utworem, który następnie mógłby zostać rozbudowany przez nich do pełnego utworu.
|
||||
|
||||
Temat produkcji muzyki przez sztuczną inteligencję jest temat ciekawym jak również mocno złożonym i skomplikowanym. Istnieje wiele kwestii, które nie zostały poruszone w pracy jak generowanie tekstu piosenki, dobranie brzmienia instrumentów czy struktury utworu a z którymi muzycy potrafią sobie świetnie dać radę. Dlatego jest jeszcze miejsce na rozwój tej dziedziny sztucznej inteligencji w przyszłości.
|
||||
|
||||
|
||||
@ -9,12 +9,12 @@
|
||||
\contentsline {subsection}{\numberline {1.2.3\relax .\leavevmode@ifvmode \kern .5em }Metody gradientowe}{15}%
|
||||
\contentsline {section}{\numberline {1.3\relax .\leavevmode@ifvmode \kern .5em }Regresja liniowa jako model sieci neuronowej}{17}%
|
||||
\contentsline {section}{\numberline {1.4\relax .\leavevmode@ifvmode \kern .5em }Funkcje aktywacji}{19}%
|
||||
\contentsline {section}{\numberline {1.5\relax .\leavevmode@ifvmode \kern .5em }Wielowarstwowe sieci neuronowe}{19}%
|
||||
\contentsline {subsection}{\numberline {1.5.1\relax .\leavevmode@ifvmode \kern .5em }Jednokierunkowe sieci neuronowe}{20}%
|
||||
\contentsline {section}{\numberline {1.5\relax .\leavevmode@ifvmode \kern .5em }Wielowarstwowe sieci neuronowe}{20}%
|
||||
\contentsline {subsection}{\numberline {1.5.1\relax .\leavevmode@ifvmode \kern .5em }Jednokierunkowe sieci neuronowe}{21}%
|
||||
\contentsline {subsection}{\numberline {1.5.2\relax .\leavevmode@ifvmode \kern .5em }Autoenkoder}{21}%
|
||||
\contentsline {subsection}{\numberline {1.5.3\relax .\leavevmode@ifvmode \kern .5em }Rekurencyjne sieci neuronowe}{22}%
|
||||
\contentsline {subsection}{\numberline {1.5.4\relax .\leavevmode@ifvmode \kern .5em }LSTM}{23}%
|
||||
\contentsline {subsection}{\numberline {1.5.5\relax .\leavevmode@ifvmode \kern .5em }Sequence-to-sequence}{26}%
|
||||
\contentsline {subsection}{\numberline {1.5.5\relax .\leavevmode@ifvmode \kern .5em }Sequence-to-sequence}{25}%
|
||||
\contentsline {chapter}{Rozdzia\PlPrIeC {\l }\ 2\relax .\leavevmode@ifvmode \kern .5em Wprowadzenie do teorii muzyki}{27}%
|
||||
\contentsline {section}{\numberline {2.1\relax .\leavevmode@ifvmode \kern .5em }Podstawowe koncepcje muzyczne}{27}%
|
||||
\contentsline {subsection}{\numberline {2.1.1\relax .\leavevmode@ifvmode \kern .5em }D\IeC {\'z}wi\IeC {\k e}k muzyczny}{27}%
|
||||
@ -22,28 +22,28 @@
|
||||
\contentsline {subsection}{\numberline {2.1.3\relax .\leavevmode@ifvmode \kern .5em }Zapis nutowy}{27}%
|
||||
\contentsline {section}{\numberline {2.2\relax .\leavevmode@ifvmode \kern .5em }Cyfrowa reprezentacja muzyki symbolicznej}{31}%
|
||||
\contentsline {subsection}{\numberline {2.2.1\relax .\leavevmode@ifvmode \kern .5em }Standard MIDI}{31}%
|
||||
\contentsline {chapter}{Rozdzia\PlPrIeC {\l }\ 3\relax .\leavevmode@ifvmode \kern .5em Projekt}{35}%
|
||||
\contentsline {section}{\numberline {3.1\relax .\leavevmode@ifvmode \kern .5em }Koncepcja}{35}%
|
||||
\contentsline {section}{\numberline {3.2\relax .\leavevmode@ifvmode \kern .5em }Wst\IeC {\k e}pne przygotowanie danych do treningu}{36}%
|
||||
\contentsline {subsection}{\numberline {3.2.1\relax .\leavevmode@ifvmode \kern .5em }Muzyczne ,,s\IeC {\l }owo''}{36}%
|
||||
\contentsline {subsection}{\numberline {3.2.2\relax .\leavevmode@ifvmode \kern .5em }Konwersja MIDI na sekwencje s\IeC {\l }\IeC {\'o}w muzycznych}{36}%
|
||||
\contentsline {subsection}{\numberline {3.2.3\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania danych}{39}%
|
||||
\contentsline {subsection}{\numberline {3.2.4\relax .\leavevmode@ifvmode \kern .5em }Podzia\IeC {\l } danych na dane wej\IeC {\'s}ciowe i wyj\IeC {\'s}ciowe}{40}%
|
||||
\contentsline {subsection}{\numberline {3.2.5\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania zbioru ucz\IeC {\k a}cego}{42}%
|
||||
\contentsline {section}{\numberline {3.3\relax .\leavevmode@ifvmode \kern .5em }Definicja modelu}{44}%
|
||||
\contentsline {subsection}{\numberline {3.3.1\relax .\leavevmode@ifvmode \kern .5em }Model w trybie uczenia}{44}%
|
||||
\contentsline {subsection}{\numberline {3.3.2\relax .\leavevmode@ifvmode \kern .5em }Model w trybie wnioskowania}{46}%
|
||||
\contentsline {section}{\numberline {3.4\relax .\leavevmode@ifvmode \kern .5em }Transformacja danych dla modelu}{49}%
|
||||
\contentsline {subsection}{\numberline {3.4.1\relax .\leavevmode@ifvmode \kern .5em }Enkodowanie one-hot}{49}%
|
||||
\contentsline {subsection}{\numberline {3.4.2\relax .\leavevmode@ifvmode \kern .5em }S\IeC {\l }ownik}{49}%
|
||||
\contentsline {subsection}{\numberline {3.4.3\relax .\leavevmode@ifvmode \kern .5em }Elementy specjalne}{50}%
|
||||
\contentsline {subsection}{\numberline {3.4.4\relax .\leavevmode@ifvmode \kern .5em }Kodowanie sekwencji}{50}%
|
||||
\contentsline {section}{\numberline {3.5\relax .\leavevmode@ifvmode \kern .5em }Ekperyment}{51}%
|
||||
\contentsline {subsection}{\numberline {3.5.1\relax .\leavevmode@ifvmode \kern .5em }Oprogramowanie}{52}%
|
||||
\contentsline {subsection}{\numberline {3.5.2\relax .\leavevmode@ifvmode \kern .5em }Zbi\IeC {\'o}r danych}{52}%
|
||||
\contentsline {subsection}{\numberline {3.5.3\relax .\leavevmode@ifvmode \kern .5em }Wydobycie danych}{52}%
|
||||
\contentsline {subsection}{\numberline {3.5.4\relax .\leavevmode@ifvmode \kern .5em }Trenowanie modelu}{53}%
|
||||
\contentsline {subsection}{\numberline {3.5.5\relax .\leavevmode@ifvmode \kern .5em }Generowanie muzyki przy pomocy wytrenowanych modeli}{54}%
|
||||
\contentsline {subsection}{\numberline {3.5.6\relax .\leavevmode@ifvmode \kern .5em }Wyniki}{56}%
|
||||
\contentsline {chapter}{Podsumowanie}{61}%
|
||||
\contentsline {chapter}{Bibliografia}{63}%
|
||||
\contentsline {chapter}{Rozdzia\PlPrIeC {\l }\ 3\relax .\leavevmode@ifvmode \kern .5em Projekt}{33}%
|
||||
\contentsline {section}{\numberline {3.1\relax .\leavevmode@ifvmode \kern .5em }Koncepcja}{33}%
|
||||
\contentsline {section}{\numberline {3.2\relax .\leavevmode@ifvmode \kern .5em }Wst\IeC {\k e}pne przygotowanie danych do treningu}{34}%
|
||||
\contentsline {subsection}{\numberline {3.2.1\relax .\leavevmode@ifvmode \kern .5em }Muzyczne ,,s\IeC {\l }owo''}{34}%
|
||||
\contentsline {subsection}{\numberline {3.2.2\relax .\leavevmode@ifvmode \kern .5em }Konwersja MIDI na sekwencje s\IeC {\l }\IeC {\'o}w muzycznych}{34}%
|
||||
\contentsline {subsection}{\numberline {3.2.3\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania danych}{37}%
|
||||
\contentsline {subsection}{\numberline {3.2.4\relax .\leavevmode@ifvmode \kern .5em }Podzia\IeC {\l } danych na dane wej\IeC {\'s}ciowe i wyj\IeC {\'s}ciowe}{38}%
|
||||
\contentsline {subsection}{\numberline {3.2.5\relax .\leavevmode@ifvmode \kern .5em }Inne aspekty przygotowania zbioru ucz\IeC {\k a}cego}{40}%
|
||||
\contentsline {section}{\numberline {3.3\relax .\leavevmode@ifvmode \kern .5em }Definicja modelu}{42}%
|
||||
\contentsline {subsection}{\numberline {3.3.1\relax .\leavevmode@ifvmode \kern .5em }Model w trybie uczenia}{42}%
|
||||
\contentsline {subsection}{\numberline {3.3.2\relax .\leavevmode@ifvmode \kern .5em }Model w trybie wnioskowania}{44}%
|
||||
\contentsline {section}{\numberline {3.4\relax .\leavevmode@ifvmode \kern .5em }Transformacja danych dla modelu}{47}%
|
||||
\contentsline {subsection}{\numberline {3.4.1\relax .\leavevmode@ifvmode \kern .5em }Enkodowanie one-hot}{47}%
|
||||
\contentsline {subsection}{\numberline {3.4.2\relax .\leavevmode@ifvmode \kern .5em }S\IeC {\l }ownik}{47}%
|
||||
\contentsline {subsection}{\numberline {3.4.3\relax .\leavevmode@ifvmode \kern .5em }Elementy specjalne}{48}%
|
||||
\contentsline {subsection}{\numberline {3.4.4\relax .\leavevmode@ifvmode \kern .5em }Kodowanie sekwencji}{48}%
|
||||
\contentsline {section}{\numberline {3.5\relax .\leavevmode@ifvmode \kern .5em }Ekperyment}{49}%
|
||||
\contentsline {subsection}{\numberline {3.5.1\relax .\leavevmode@ifvmode \kern .5em }Oprogramowanie}{50}%
|
||||
\contentsline {subsection}{\numberline {3.5.2\relax .\leavevmode@ifvmode \kern .5em }Zbi\IeC {\'o}r danych}{50}%
|
||||
\contentsline {subsection}{\numberline {3.5.3\relax .\leavevmode@ifvmode \kern .5em }Wydobycie danych}{50}%
|
||||
\contentsline {subsection}{\numberline {3.5.4\relax .\leavevmode@ifvmode \kern .5em }Trenowanie modelu}{51}%
|
||||
\contentsline {subsection}{\numberline {3.5.5\relax .\leavevmode@ifvmode \kern .5em }Generowanie muzyki przy pomocy wytrenowanych modeli}{52}%
|
||||
\contentsline {subsection}{\numberline {3.5.6\relax .\leavevmode@ifvmode \kern .5em }Wyniki}{54}%
|
||||
\contentsline {chapter}{Podsumowanie}{59}%
|
||||
\contentsline {chapter}{Bibliografia}{61}%
|
||||
|
||||
{kind=link}
|
Before 
(image error) Size: 23 KiB After 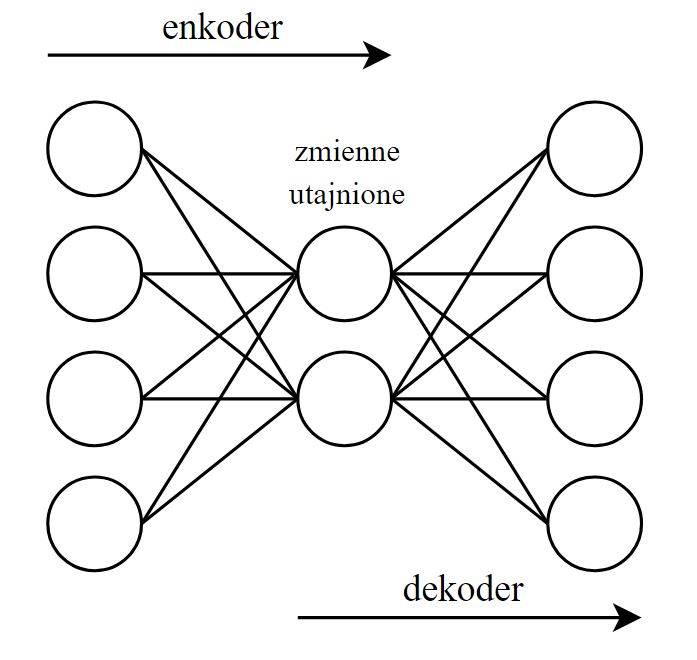
(image error) Size: 44 KiB
|
{kind=link}
|
Before 
(image error) Size: 9.8 KiB After 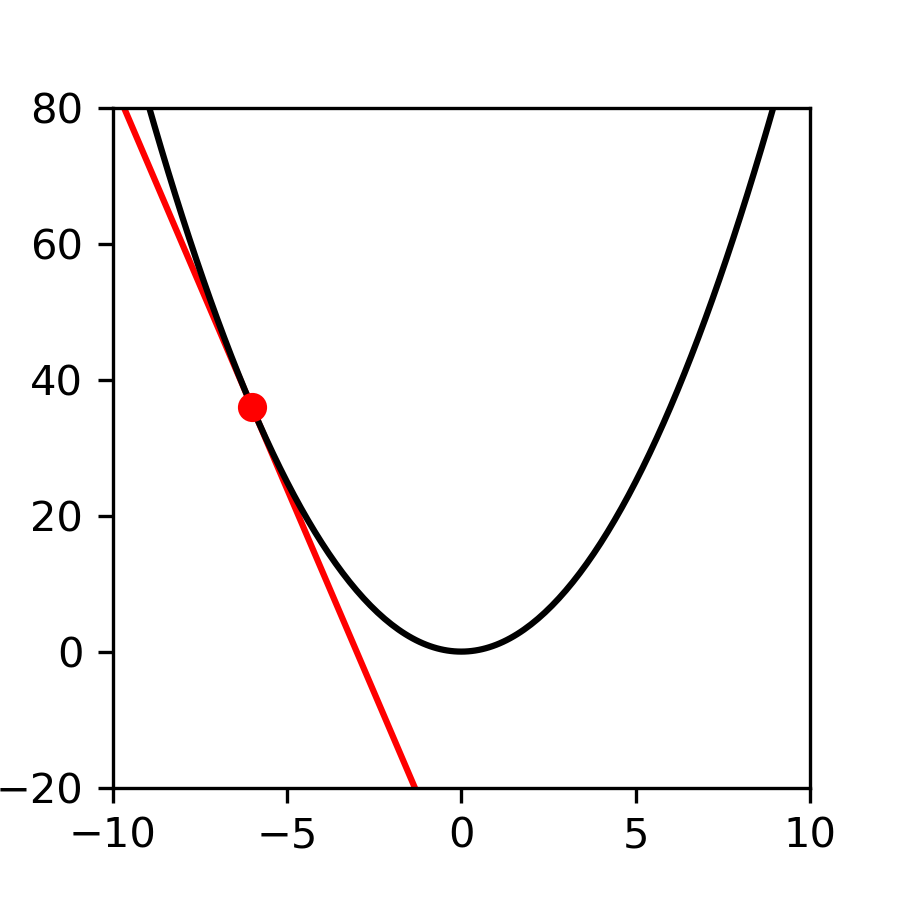
(image error) Size: 47 KiB
|
{kind=link}
|
Before 
(image error) Size: 8.5 KiB After 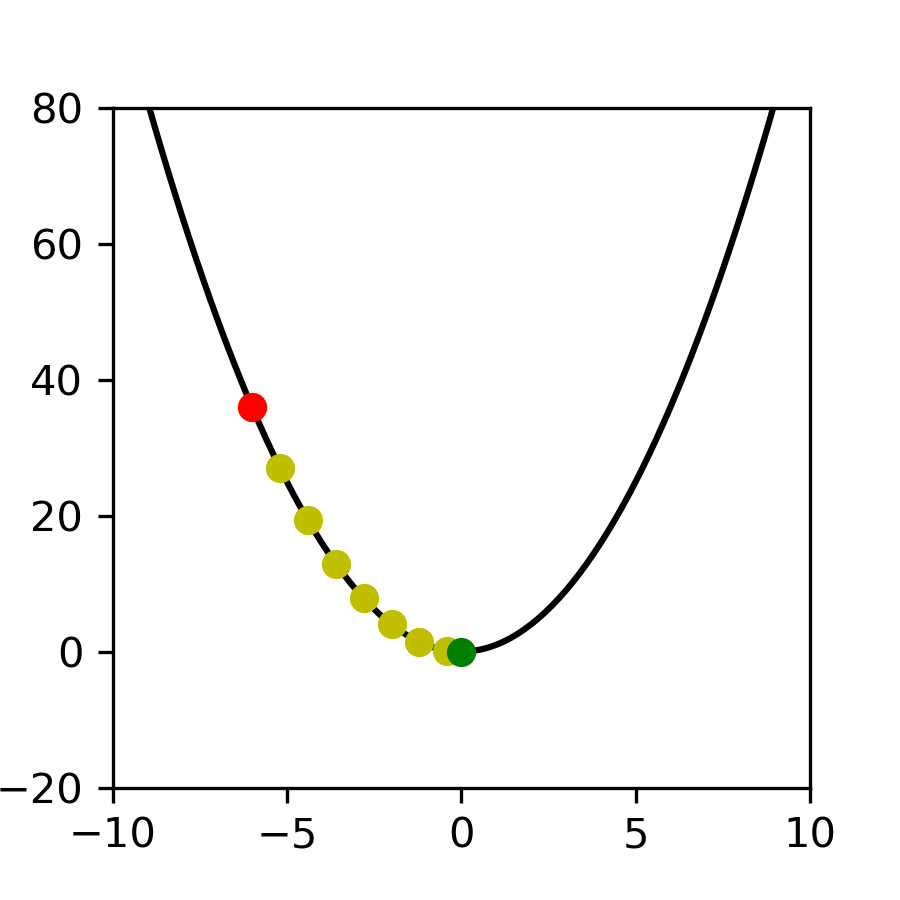
(image error) Size: 43 KiB
|
{kind=link}
|
Before 
(image error) Size: 8.3 KiB After 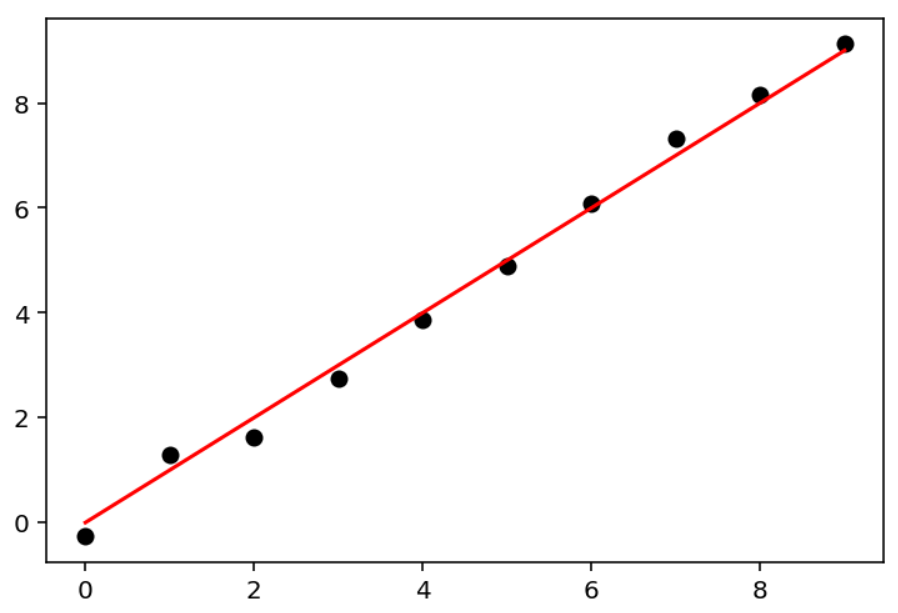
(image error) Size: 33 KiB
|
@ -44,13 +44,15 @@ x = np.arange(-10,10, 0.1)
|
||||
# y = np.arange(0,10)
|
||||
|
||||
tanh = lambda x: (exp(x) - exp(-x))/(exp(x) + exp(-x))
|
||||
sigmoid = lambda x: 1/(1 + exp(-x))
|
||||
|
||||
y_hat = [tanh(yy) for yy in x]
|
||||
# plt.scatter(x, y, c='k')
|
||||
plt.plot(x, y_hat)
|
||||
# plt.show()
|
||||
fig = plt.Figure(figsize=(20,30))
|
||||
plt.show()
|
||||
# plt.labels
|
||||
plt.savefig('tanh.png')
|
||||
# plt.savefig('tanh.png')
|
||||
|
||||
#%%
|
||||
# Gradient descent
|
||||
@ -62,6 +64,8 @@ dx = 2x + c
|
||||
|
||||
|
||||
#%%
|
||||
|
||||
|
||||
func = lambda x: x**2
|
||||
func_dx = lambda x:2*x
|
||||
|
||||
@ -71,14 +75,14 @@ y = func(x)
|
||||
point_x = -6
|
||||
point_y = func(point_x)
|
||||
|
||||
# styczna = lambda x: slope*x + intercept
|
||||
|
||||
|
||||
dx = styczna(x)
|
||||
# dx = styczna(x)
|
||||
|
||||
learning_points_xs = np.arange(point_x, 0, 0.8)
|
||||
learning_points_ys = func(learning_points_xs)
|
||||
|
||||
fig, ax = plt.subplots()
|
||||
fig, ax = plt.subplots(figsize=(3,3))
|
||||
ax.plot(x, y, c='k')
|
||||
|
||||
for px in learning_points_xs[0:1]:
|
||||
@ -86,22 +90,22 @@ for px in learning_points_xs[0:1]:
|
||||
intercept = -px**2
|
||||
styczna = lambda x: slope*x + intercept
|
||||
dx = styczna(x)
|
||||
ax.plot(x, dx, c='r', zorder=1)
|
||||
# ax.plot(x, dx, c='r', zorder=1)
|
||||
|
||||
ax.scatter(x=point_x, y=point_y, c='r', zorder=6) #start
|
||||
# ax.scatter(x=0, y=0, c='g', zorder=6) #min
|
||||
# ax.scatter(x=learning_points_xs, y=learning_points_ys, c='y', zorder=5)
|
||||
ax.scatter(x=0, y=0, c='g', zorder=6) #min
|
||||
ax.scatter(x=learning_points_xs, y=learning_points_ys, c='y', zorder=5)
|
||||
plt.ylim((-20,80))
|
||||
plt.xlim((-20,20))
|
||||
plt.xlim((-10,10))
|
||||
|
||||
# plt.xlabel('x')
|
||||
# plt.ylabel('f(x) = x^2')
|
||||
|
||||
plt.savefig('gradient_descent_1.png')
|
||||
fig.savefig('gradient_descent_2_long.png', dpi=300)
|
||||
|
||||
# https://towardsdatascience.com/understanding-the-mathematics-behind-gradient-descent-dde5dc9be06e?
|
||||
# https://medium.com/code-heroku/gradient-descent-for-machine-learning-3d871fa48b4c
|
||||
|
||||
|
||||
#%% sound wave
|
||||
|
||||
#import the pyplot and wavfile modules
|
||||
@ -109,15 +113,16 @@ import matplotlib.pyplot as plot
|
||||
from scipy.io import wavfile
|
||||
|
||||
# Read the wav file (mono)
|
||||
samplingFrequency, signalData = wavfile.read('foo.wav')
|
||||
samplingFrequency, signalData = wavfile.read(r'docs\images\foo.wav')
|
||||
|
||||
# Plot the signal read from wav file
|
||||
# plot.title('Spectrogram of a wav file with piano music')
|
||||
plot.plot(signalData)
|
||||
plot.xlabel('Próbki')
|
||||
plot.ylabel('Amplituda')
|
||||
plot.savefig('waveform_axis.png')
|
||||
# plot.show()
|
||||
# plot.savefig('waveform_axis.png')
|
||||
fig = plt.Figure(figsize=(2,15))
|
||||
plot.show()
|
||||
|
||||
# print(samplingFrequency)
|
||||
|
||||
|
||||
{kind=link}
|
Before 
(image error) Size: 30 KiB After 
(image error) Size: 22 KiB
|
{kind=link}
|
Before 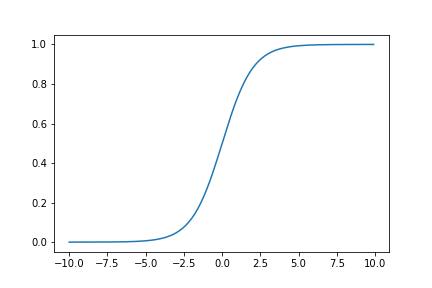
(image error) Size: 9.5 KiB After 
(image error) Size: 42 KiB
|
{kind=link}
|
Before 
(image error) Size: 11 KiB After 
(image error) Size: 45 KiB
|
{kind=link}
|
Before 
(image error) Size: 15 KiB After 
(image error) Size: 55 KiB
|