Compare commits
No commits in common. "master" and "development" have entirely different histories.
master
...
developmen
1
.gitignore
vendored
@ -1,4 +1,3 @@
|
||||
/.idea/
|
||||
__pycache__
|
||||
/venv/
|
||||
/doc/_build/
|
||||
|
||||
214
DecisionTree.md
@ -1,214 +0,0 @@
|
||||
# DSZI_Survival - Drzewa Decyzyjne
|
||||
### Autor: Michał Czekański
|
||||
|
||||
## Cel zastosowania w projekcie
|
||||
W projekcie DSZI_Survival drzewo decyzyjne użyte jest do podejmowania decyzji przez agenta, rozbitka na bezludnej wyspie,
|
||||
jaką czynność wykonać w danej chwili.
|
||||
|
||||
Czy:
|
||||
* zdobyć pożywienie
|
||||
* udać się do źródła wody
|
||||
* odpocząć przy ognisku
|
||||
|
||||
## Opis drzewa decyzyjnego
|
||||
|
||||
* **Drzewo decyzyjne** to drzewo reprezentujące jakąś funkcję, Boolowską w najprostszym przypadku.
|
||||
* Drzewo decyzyjne jako **argument** przyjmuje obiekt - sytuację opisaną za pomocą zestawu **atrybutów**
|
||||
* **Wierzchołek** drzewa decyzyjnego odpowiada testowi jednego z atrybutów (np. IsMonday)
|
||||
* Każda **gałąź** wychodząca z wierzchołka jest oznaczona możliwą wartością testu z wierzchołka (np. True)
|
||||
* **Liść** zawiera wartość do zwrócenia (**decyzję, wybór**), gdy liść ten zostanie osiągnięty (np. ShopType.Grocery)
|
||||
|
||||
|
||||
## Metoda uczenia - Algorytm ID3
|
||||
|
||||
Metoda użyta do uczenia drzewa decyzyjnego to metoda **indukcyjnego uczenia drzewa decyzyjnego**.
|
||||
|
||||
### Działanie ID3
|
||||
* Definiujemy atrybuty, które będą posiadały przykłady służące do uczenia drzewa (**atrybuty**)
|
||||
|
||||
```python
|
||||
class AttributeDefinition:
|
||||
def __init__(self, id, name: str, values: List):
|
||||
self.id = id
|
||||
self.name = name
|
||||
self.values = values
|
||||
|
||||
class Attribute:
|
||||
def __init__(self, attributeDefinition: AttributeDefinition, value):
|
||||
self.attributeDefinition = attributeDefinition
|
||||
self.value = value
|
||||
```
|
||||
* Tworzymy przykłady z wykorzystaniem atrybutów (**przykłady**)
|
||||
|
||||
```python
|
||||
class DecisionTreeExample:
|
||||
def __init__(self, classification, attributes: List[Attribute]):
|
||||
self.attributes = attributes
|
||||
self.classification = classification
|
||||
```
|
||||
* Ustalamy domyślną wartość do zwrócenia przez drzewo - **klasa domyślna**
|
||||
* Następnie postępujemy indukcyjnie:
|
||||
* Jeżeli liczba przykładów == 0: zwracamy wierzchołek oznaczony klasą domyślną
|
||||
* Jeżeli wszystkie przykłady są tak samo sklasyfikowane: zwracamy wierzchołek oznacz. tą klasą
|
||||
* Jeżeli liczba atrybutów == 0: zwracamy wierzchołek oznacz. klasą, którą posiada większość przykładów
|
||||
* W przeciwnym wypadku **wybieramy atrybut** A (o wyborze atrybutu poniżej) i czynimy go korzeniem drzewa T
|
||||
* **nowa_klasa_domyślna** = wierzchołek oznaczony klasą, która jest przypisana największej liczbie przykładów
|
||||
* Dla każdej wartości W atrybutu A:
|
||||
* nowe_przykłady = przykłady, dla których atrybut A przyjmuje wartość W
|
||||
* Dodajemy do T krawędź oznaczoną przez wartość W, która prowadzi do wierzchołka zwróconego przez wywołanie indukcyjne:
|
||||
*treelearn(nowe_przykłady, atrybuty−A, nowa_klasa_domyślna)*
|
||||
* Zwróć drzewo T
|
||||
```python
|
||||
class DecisionTree(object):
|
||||
def __init__(self, root):
|
||||
self.root = root
|
||||
self.branches = []
|
||||
self.branchesNum = 0
|
||||
```
|
||||
|
||||
### Wybór atrybutu
|
||||
W trakcie uczenia drzewa decyzyjnego chcemy wybrać jak najlepszy atrybut, dzięki któremu możliwie jak najszybciej będziemy mogli sklasyfikować podane przykłady.
|
||||
|
||||
Miarą porównawczą atrybutów będzie **zysk informacji** dla danego atrybutu (**information gain**).
|
||||
|
||||
Atrybut o największym zysku zostanie wybrany.
|
||||
|
||||
**Implementacja**
|
||||
|
||||
```python
|
||||
def chooseAttribute(attributes: List[AttributeDefinition], examples: List[DecisionTreeExample], classifications):
|
||||
bestAttribute = None
|
||||
bestAttributeGain = -1
|
||||
|
||||
for attribute in attributes:
|
||||
attrInformationGain = calculateInformationGain(attribute, classifications, examples)
|
||||
if attrInformationGain > bestAttributeGain:
|
||||
bestAttribute = attribute
|
||||
bestAttributeGain = attrInformationGain
|
||||
|
||||
return bestAttribute
|
||||
```
|
||||
|
||||
|
||||
#### Obliczanie zysku informacji
|
||||
(Wszelkie obliczenia wedle wzorów podanych na zajęciach)
|
||||
* I(C) - Obliczamy zawartość informacji dla zbioru możliwych klasyfikacji
|
||||
|
||||

|
||||
|
||||
* E(A) - Obliczamy ilość informacji potrzebną do zakończenia klasyfikacji po sprawdzeniu atrybutu
|
||||
|
||||
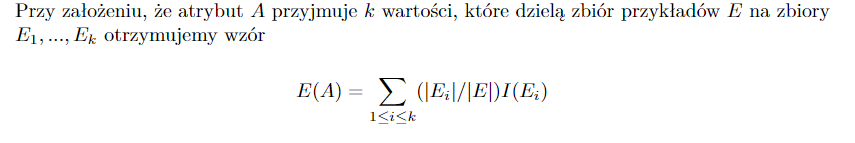
|
||||
|
||||
* **G(A)** - **Przyrost informacji dla atrybutu A** = I(C) - E(A)
|
||||
|
||||
**Implementacja**
|
||||
|
||||
```python
|
||||
def calculateInformationGain(attribute: AttributeDefinition, classifications, examples: List[DecisionTreeExample]):
|
||||
return calculateEntropy(classifications, examples) - calculateRemainder(attribute, examples, classifications)
|
||||
```
|
||||
|
||||
## Opis implementacji
|
||||
### Definicje atrybutów:
|
||||
* Głód: **[0, 1/4); [1/4, 1/2); [1/2, 3/4); [3/4, 1]**
|
||||
* Pragnienie: **[0, 1/4); [1/4, 1/2); [1/2, 3/4); [3/4, 1]**
|
||||
* Energia: **[0, 1/4); [1/4, 1/2); [1/2, 3/4); [3/4, 1]**
|
||||
* Odległość od jedzenia: **[0, 3); [3, 8); [8, 15); [15, max)**
|
||||
* Odległość od źródła wody: **[0, 3); [3, 8); [8, 15); [15, max)**
|
||||
* Odległość od miejsca spoczynku: **[0, 3); [3, 8); [8, 15); [15, max)**
|
||||
* Odległość pomiędzy wodą a jedzeniem: **[0, 3); [3, 8); [8, 15); [15, max)**
|
||||
|
||||
```python
|
||||
class PlayerStatsValue(Enum):
|
||||
ZERO_TO_QUARTER = 0
|
||||
QUARTER_TO_HALF = 1
|
||||
HALF_TO_THREE_QUARTERS = 2
|
||||
THREE_QUARTERS_TO_FULL = 3
|
||||
|
||||
class DistFromObject(Enum):
|
||||
LT_3 = 0
|
||||
GE_3_LT_8 = 1
|
||||
GE_8_LT_15 = 2
|
||||
GE_15 = 3
|
||||
```
|
||||
### Uczenie drzewa
|
||||
|
||||
```python
|
||||
def inductiveDecisionTreeLearning(examples: List[DecisionTreeExample], attributes: List[AttributeDefinition], default,
|
||||
classifications)
|
||||
```
|
||||
|
||||
### Zwracanie decyzji przez drzewo
|
||||
```python
|
||||
def giveAnswer(self, example: DecisionTreeExample):
|
||||
if self.branchesNum == 0:
|
||||
return self.root
|
||||
|
||||
for attr in example.attributes:
|
||||
if attr.attributeDefinition.id == self.root.id:
|
||||
for branch in self.branches:
|
||||
if branch.label == attr.value:
|
||||
return branch.subtree.giveAnswer(example)
|
||||
```
|
||||
|
||||
### Wybór celu dla agenta
|
||||
```python
|
||||
def pickEntity(self, player, map, pickForGa=False):
|
||||
foods = map.getInteractablesByClassifier(Classifiers.FOOD)
|
||||
waters = map.getInteractablesByClassifier(Classifiers.WATER)
|
||||
rests = map.getInteractablesByClassifier(Classifiers.REST)
|
||||
|
||||
playerStats = DTPlayerStats.dtStatsFromPlayerStats(player.statistics)
|
||||
|
||||
# Get waters sorted by distance from player
|
||||
dtWaters: List[DTSurvivalInteractable] = []
|
||||
for water in waters:
|
||||
dtWater = DTSurvivalInteractable.dtInteractableFromInteractable(water, player.x, player.y)
|
||||
dtWaters.append(dtWater)
|
||||
dtWaters.sort(key=lambda x: x.accurateDistanceFromPlayer)
|
||||
nearestDtWater = dtWaters[0]
|
||||
|
||||
# Get foods sorted by distance from player
|
||||
dtFoods: List[DTSurvivalInteractable] = []
|
||||
for food in foods:
|
||||
dtFood = DTSurvivalInteractable.dtInteractableFromInteractable(food, player.x, player.y)
|
||||
dtFoods.append(dtFood)
|
||||
|
||||
dtFoods.sort(key=lambda x: x.accurateDistanceFromPlayer)
|
||||
# If there is no food on map return nearest water.
|
||||
try:
|
||||
nearestDtFood = dtFoods[0]
|
||||
except IndexError:
|
||||
return nearestDtWater.interactable
|
||||
|
||||
# Get rest places sorted by distance from player
|
||||
dtRestPlaces: List[DTSurvivalInteractable] = []
|
||||
for rest in rests:
|
||||
dtRest = DTSurvivalInteractable.dtInteractableFromInteractable(rest, player.x, player.y)
|
||||
dtRestPlaces.append(dtRest)
|
||||
dtRestPlaces.sort(key=lambda x: x.accurateDistanceFromPlayer)
|
||||
nearestDtRest = dtRestPlaces[0]
|
||||
|
||||
currentSituation = SurvivalDTExample(None, playerStats.hungerAmount, playerStats.thirstAmount,
|
||||
playerStats.staminaAmount,
|
||||
nearestDtFood.dtDistanceFromPlayer, nearestDtWater.dtDistanceFromPlayer,
|
||||
nearestDtRest.dtDistanceFromPlayer,
|
||||
nearestDtFood.getDtDistanceFromOtherInteractable(nearestDtWater.interactable))
|
||||
|
||||
treeDecision, choice = self.__pickEntityAfterTreeDecision__(currentSituation,
|
||||
dtFoods,
|
||||
dtRestPlaces,
|
||||
dtWaters)
|
||||
return choice.interactable
|
||||
```
|
||||
|
||||
## Zestaw uczący, zestaw testowy
|
||||
|
||||
### Zestaw uczący
|
||||
|
||||
Zestaw uczący był generowany poprzez tworzenie losowych przykładów i zapytanie użytkownika o klasyfikację, a następnie zapisywany do pliku.
|
||||
|
||||
### Zestaw testowy
|
||||
|
||||
Przy testowaniu drzewa podajemy ile procent wszystkich, wcześniej wygenerowanych przykładów mają być przykłady testowe.
|
||||
@ -1,173 +0,0 @@
|
||||
# Algorythm Genetyczny w projekcie DSZI_Survival
|
||||
**Autor:** Marcin Kostrzewski
|
||||
|
||||
---
|
||||
## Cel
|
||||
Celem algorytmu jest znalezienie czterech optymalnych wartości, według których
|
||||
agent podejmuje decyzję, co zrobić dalej. Te cztery cechy to:
|
||||
* Priorytet (chęć) zaspokajania głodu,
|
||||
* Zaspokajanie pragnienia,
|
||||
* Odpoczynek,
|
||||
* Jak odległość od obiektu wpływa na podjętą decyzję.
|
||||
|
||||
Zestaw tych cech reprezentuje klasa-struktura **[*Affinities*](https://git.wmi.amu.edu.pl/s444409/DSZI_Survival/src/master/src/AI/Affinities.py)**:
|
||||
```python
|
||||
class Affinities:
|
||||
def __init__(self, food, water, rest, walking):
|
||||
"""
|
||||
Create a container of affinities. Affinities describe, what type of entities a player prioritizes.
|
||||
:param food: Food affinity
|
||||
:param water: Freshwater affinity
|
||||
:param rest: Firepit affinity
|
||||
:param walking: How distances determine choices
|
||||
"""
|
||||
self.food = food
|
||||
self.water = water
|
||||
self.rest = rest
|
||||
self.walking = walking
|
||||
```
|
||||
|
||||
Oczywiście agent (gracz) posiada w swojej klasie pole ``self.affinities``.
|
||||
|
||||
## Podejmowanie decyzji
|
||||
|
||||
Gracz podejmuje decyzję o wyborze celu według następującej formuły:
|
||||
```python
|
||||
typeWeight / (distance / walkingAffinity) * affectedStat * multiplier
|
||||
```
|
||||
gdzie:
|
||||
* *typeWeight* - wartość cechy odpowiadającej typowi celu,
|
||||
* *distance* - odległość od celu,
|
||||
* *walkingAffinity* - waga odległości,
|
||||
* *affectedStat* - aktualna wartość odpowiadającej statystyki agenta,
|
||||
* *multiplier* - mnożnik redukujący wpływ obecnych statystyk na wybór.
|
||||
|
||||
Implementacja w **[*GA.py/pickEntity()*](https://git.wmi.amu.edu.pl/s444409/DSZI_Survival/src/master/src/AI/GA.py)** (przykładowo dla jedzenia):
|
||||
```python
|
||||
watersWeights = []
|
||||
thirst = player.statistics.thirst
|
||||
for water in waters:
|
||||
typeWeight = weights[1]
|
||||
distance = abs(player.x - water.x) + abs(player.x - water.y)
|
||||
watersWeights.append(typeWeight / (distance * walkingAffinity) * thirst * 0.01)
|
||||
```
|
||||
|
||||
Dla każdego obiektu, z którym agent może podjąć interakcję wyliczana jest ta wartość
|
||||
i wybierany jest obiekt, dla którego jest największa.
|
||||
|
||||
## Implementacja algorytmu genetycznego
|
||||
|
||||
Za realizację algorytmu odpowiada funkcja *geneticAlgorithm()* w **[*GA.py*](https://git.wmi.amu.edu.pl/s444409/DSZI_Survival/src/master/src/AI/GA.py)** (Skrócona wersja):
|
||||
```python
|
||||
def geneticAlgorithm(map, iter, solutions, mutationAmount=0.05):
|
||||
# Based on 4 weights, that are affinities tied to the player
|
||||
weightsCount = 4
|
||||
|
||||
# Initialize the first population with random values
|
||||
initialPopulation = numpy.random.uniform(low=0.0, high=1.0, size=(solutions, weightsCount))
|
||||
population = initialPopulation
|
||||
|
||||
for i in range(iter):
|
||||
fitness = []
|
||||
for player in population:
|
||||
fitness.append(doSimulation(player, map))
|
||||
|
||||
parents = selectMatingPool(population, fitness, int(solutions / 2))
|
||||
|
||||
offspring = mating(parents, solutions, mutationAmount)
|
||||
|
||||
population = offspring
|
||||
```
|
||||
|
||||
#### Omówienie:
|
||||
|
||||
##### Pierwsza populacja
|
||||
Pierwsza populacja inicjalizowana jest losowymi wartościami. Szukamy
|
||||
czterech najlepszych wag; każdy osobnik z gatunku jest reprezentowany przez
|
||||
listę 4-elementową wag.
|
||||
|
||||
```python
|
||||
initialPopulation = numpy.random.uniform(low=0.0, high=1.0, size=(solutions, weightsCount))
|
||||
```
|
||||
|
||||
Rozpoczyna się pętla, która stworzy tyle generacji, ile sprecyzujemy w parametrze.
|
||||
|
||||
##### Symulacja i *fitness*
|
||||
|
||||
Dla każdego osobnika z populacji uruchamiana jest symulacja. Symulacja dzieje się w tle,
|
||||
żeby zminimializować czas potrzebny do wykonania pełnej symulacji. Jej koniec następuje w momencie,
|
||||
gdy agent umrze.
|
||||
```python
|
||||
fitness.append(doSimulation(player, map))
|
||||
```
|
||||
|
||||
Wartością zwracaną przez funkcję symulacji jest tzw. *fitness*. W tym wypadku,
|
||||
wartością tą jest ilość kroków, jakie pokonał agent przez cykl życia.
|
||||
|
||||
##### Wybór rodziców
|
||||
|
||||
Rodzice dla dzieci przyszłego pokolenia wybierani są na podstawie wartości
|
||||
*fitness*. W tym wypadku wybirana jest połowa populacji z najwyższymi wartościami przeżywalności.
|
||||
```python
|
||||
parents = selectMatingPool(population, fitness, int(solutions / 2))
|
||||
```
|
||||
|
||||
##### Potomstwo, czyli rozmnażanie i mutacje
|
||||
|
||||
Za wyliczanie wartości dla nowego pokolenia odpowiada funkcja ``mating``. Przekazujemy do niej rodziców, ilość potomstwa
|
||||
i siłę mutacji. Z **[*GA.py/mating()*](https://git.wmi.amu.edu.pl/s444409/DSZI_Survival/src/master/src/AI/GA.py)**:
|
||||
```python
|
||||
for i in range(offspringCount):
|
||||
parent1 = i % len(parents)
|
||||
parent2 = (i + 1) % len(parents)
|
||||
offspring.append(crossover(parents[parent1], parents[parent2]))
|
||||
```
|
||||
|
||||
Do stworzenia potomstwa używana jest funkcja ``crossover``, która wylicza wartości, jakie przyjmie nowe potomstwo.
|
||||
Wartośc ta to mediana wartości obu rodziców. Z **[*GA.py/crossover()*](https://git.wmi.amu.edu.pl/s444409/DSZI_Survival/src/master/src/AI/GA.py)**:
|
||||
```python
|
||||
for gene1, gene2 in zip(genes1, genes2):
|
||||
result.append((gene1 + gene2) / 2)
|
||||
```
|
||||
Po zastosowaniu krzyżówki, jeden losowo wybrany gen jest alterowany o niewielką wartość (mutacja). Z **[*GA.py/mutation()*](https://git.wmi.amu.edu.pl/s444409/DSZI_Survival/src/master/src/AI/GA.py)**:
|
||||
```python
|
||||
for player in offspring:
|
||||
randomGeneIdx = random.randrange(0, len(player))
|
||||
player[randomGeneIdx] = player[randomGeneIdx] + random.uniform(-1.0, 1.0) * mutationAmount
|
||||
```
|
||||
|
||||
Nowe potomstwo zastępuje obecną populacje i algorytm wchodzi w kolejną pętle:
|
||||
```python
|
||||
population = offspring
|
||||
```
|
||||
|
||||
## Skuteczność algorytmu
|
||||
|
||||
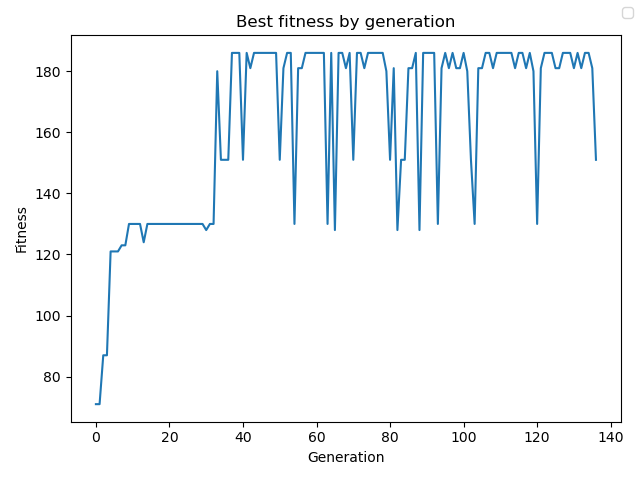
Zastosowanie algorytmu przynosi niezbyt spektakularne, lecz oczekiwane wyniki. Po uruchomieniu symulacji
|
||||
dla 1000 generacji:
|
||||
* Wykres wartości fitness od generacji:
|
||||
|
||||
|
||||
* Najlepsze / najgorsze fitness:
|
||||
```
|
||||
Best Fitness: 186
|
||||
Worst Fitness: 71
|
||||
```
|
||||
|
||||
* Zestaw najlepszych / najgorszych wartości
|
||||
```
|
||||
Best:
|
||||
Affinities: food=0.9659207331357987, water=1.06794833921562, rest=0.4224083038045297, walking=0.26676612275274836
|
||||
Worst:
|
||||
Affinities: food=0.3927852322929111, water=0.6888704071372844, rest=0.625376993269597, walking=0.5415515638814266
|
||||
```
|
||||
### Przykład symulacji dla najlepszego osobnika:
|
||||
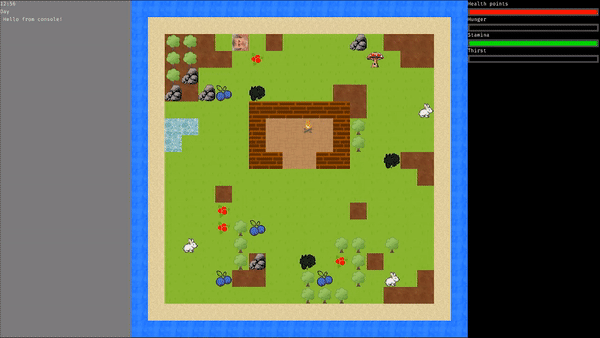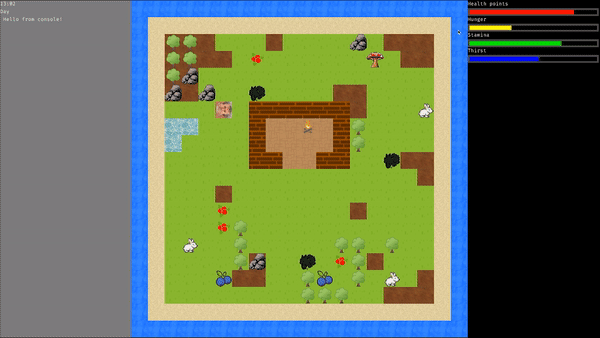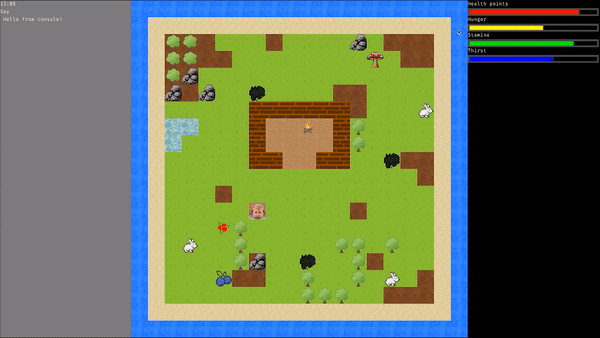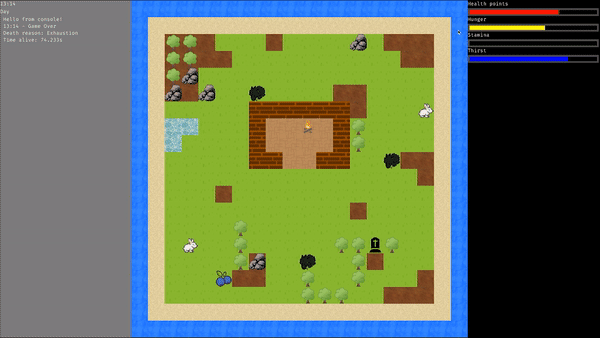
|
||||
|
||||
## Zastosowanie w całości projektu
|
||||
Dzięki wyliczonym przez algorytm wagom, gracz poruszający się w środowisku będzie znał swoje priorytety i będzie w stanie
|
||||
przeżyć jak najdłużej. Obecnie, wybór obiektu jest dość statyczny i niezbyt "mądry", został napisany jedynie
|
||||
na potrzeby tego projektu. W przyszłości algorytm może być trenowany według inteligentnych wyborów obiektów np. poprzez zastosowanie
|
||||
drzewa decyzyjnego. Każdy obiekt ma zdefiniowany swój skutek, czyli gracz z góry wie, czym jest dany obiekt. W przyszłości
|
||||
gracz może nie znać informacji o obiektach, może być do tego używany jakiś inny algorytm, który oceni,
|
||||
czym jest dany obiekt.
|
||||
@ -1,70 +0,0 @@
|
||||
# DSZI_Survival - Sieć Neuronowa
|
||||
### Autor: Jonathan Spaczyński
|
||||
|
||||
## Cel zastosowania w projekcie
|
||||
W projekcie DSZI_Survival sieć neuronowa użyta jest do podejmowania decyzji przez agenta.
|
||||
Decyzja polega na rozpoznawaniu zdjęć owoców (jabłka i gruszki). W przypadku nie rozpoznania owocu przez
|
||||
agenta, dochodzi do zatrucia i agent umiera/przegrywa.
|
||||
|
||||
## Przygotowanie danych
|
||||
|
||||
* **Krok 1** Przechowywane zdjęcia owoców muszą przejść przez proces zamiany zdjęcia (.jpg) na dane, które
|
||||
mogą być wykorzystane przez sieć neuronową.
|
||||
|
||||
```python
|
||||
CATEGORIES = ["Apple", "Pear"]
|
||||
IMG_SIZE = 64
|
||||
|
||||
training_data = []
|
||||
|
||||
|
||||
def create_training_data():
|
||||
for category in CATEGORIES:
|
||||
path = os.path.join(DATADIR, category)
|
||||
class_num = CATEGORIES.index(category)
|
||||
for img in os.listdir(path):
|
||||
try:
|
||||
img_array = cv2.imread(os.path.join(path, img), cv2.IMREAD_GRAYSCALE)
|
||||
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
|
||||
training_data.append([new_array, class_num])
|
||||
except Exception as e:
|
||||
pass
|
||||
```
|
||||
zdjęcia są przechowywane w tablicy training_data wraz z klasyfikacją (class_num) odpowiadającą jakim typem owocu jest zdjęcie
|
||||
|
||||
* **Krok 2** Bardzo ważnym krokiem jest pomieszanie danych. W przeciwnym wypadku nasz model po ciągłym otrzymywanie danych
|
||||
reprezentujących tylko jedną kategorię owoców mógłby się wyuczyć, aby tylko zgadywać tą kategorię.
|
||||
```python
|
||||
random.shuffle(training_data)
|
||||
```
|
||||
* **Krok 3** Ostatnim krokiem jest zaktualizowanie danych w taki sposób żeby były z przedziału
|
||||
od 0 d 255 (reprezentacja koloru danego pixela)
|
||||
```python
|
||||
X = X / 255.0
|
||||
```
|
||||
## Kilka słów na temat danych
|
||||
* **Ilość Danych** Do trenowania modelu wykorzystałem 8568 zdjęć gruszek i jabłek
|
||||
z czego mniej więcej połowa danych była jednym z typów ww. owoców, a druga połowa
|
||||
reprezentowała pozostałą kategorią
|
||||
* **Dane wykorzystane do obliczenia skutecznośći** stanowiły małą i oddzielną część danych wykorzystanych do trenowania.
|
||||
## Model
|
||||
* **Dane wejściowe:** Dane o kształcie 64x64 reprezentujące pixele w zdjęciach owoców
|
||||
* **Warstwa ukryta:** Składająca się z 128 "neuronów" wykorzystującą sigmoid jako funkcję aktywacyjną
|
||||
* **Warstwa wyjściowa:** Składająca się z 2 "neuronów" reprezentujących gruszkę i jabłko
|
||||
* **Stała ucząca:** 0.001
|
||||
|
||||
```python
|
||||
model = tf.keras.Sequential([
|
||||
tf.keras.layers.Flatten(input_shape=(64, 64)),
|
||||
tf.keras.layers.Dense(128, activation=tf.nn.sigmoid),
|
||||
tf.keras.layers.Dense(2, activation=tf.nn.sigmoid)
|
||||
])
|
||||
|
||||
model.compile(tf.keras.optimizers.Adam(lr=0.001),
|
||||
loss="sparse_categorical_crossentropy",
|
||||
metrics=["accuracy"])
|
||||
```
|
||||
## Osiągniecia modelu
|
||||
* **Trafność:** 86.4%
|
||||
* **Strata:** 0.312
|
||||
|
||||
23
README.md
@ -7,24 +7,5 @@ Skład zespołu:
|
||||
- Michał Czekański
|
||||
- Marcin Kostrzewski
|
||||
|
||||
## Wymagania
|
||||
```
|
||||
Python 3.x
|
||||
pygame: 1.9.x
|
||||
```
|
||||
## Uruchomienie
|
||||
Projekt można uruchomić w dwóch trybach, które podajemy jako parametry:
|
||||
* test: Wizualne środowisko agenta, którym możemy sami prouszać
|
||||
* ga: Uruchomienie algorytmu genetycznego w tle. Musimy dodatkowo jako kolejny
|
||||
parametr podać ilość iteracji dla algorytmu. Możemy dodać -t, jeżeli
|
||||
chcemy uruchomić algorytm w wielu wątkach (Nie działa zbyt dobrze)
|
||||
```
|
||||
$ python Run.py {test|ga} [iter] [-t]
|
||||
```
|
||||
## Konfiguracja
|
||||
Plik z konfiguracją znajduje w ```data/config/mainConfig.json```.
|
||||
|
||||
## Sterowanie
|
||||
* Poruszanie się: *WASD*
|
||||
* A*: ***u*** lub click myszką w jednostkę (np; królik)
|
||||
* Interakcja: *SPACJA*
|
||||
Poruszanie się: *WASD*
|
||||
Podnoszenie obiektów: *SPACJA*
|
||||
5
Run.py
@ -1,7 +1,6 @@
|
||||
from pathlib import Path
|
||||
import sys
|
||||
|
||||
from src.game.Game import Game
|
||||
|
||||
# TODO: Paths are still retarded
|
||||
programPath = Path(".").resolve()
|
||||
game = Game(programPath, sys.argv)
|
||||
game = Game(programPath)
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.0 KiB |