| dev-A | ||
| test-A | ||
| train | ||
| .gitignore | ||
| cnlps-report-example.pdf | ||
| config.txt | ||
| diagram_dataset.png | ||
| diagram_usage.png | ||
| in-header.tsv | ||
| out-header.tsv | ||
| README.md | ||
{kind=link}
{kind=link}
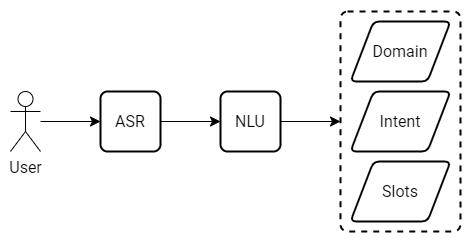
CAICCAIC: Centre for Artificial Intelligence Challenge on Conversational AI Correctness
Develop Natural Language Understanding models that are robust to speech recognition errors.
Task Description
Introduction
Regardless of the near-human accuracy of Automatic Speech Recognition in general-purpose transcription tasks, speech recognition errors can significantly deteriorate the performance of a Natural Language Understanding model that follows the speech-to-text module in a virtual assistant. The problem is even more apparent when an ASR system from an external vendor is used as an integral part of a conversational system without any further adaptation.
The goal of this competition is to develop Natural Language Understanding models that are robust to speech recognition errors.
The approach used to prepare data for the challenge is meant to promote models robust to various types of errors in the input, making it impossible to solve the task by simply learning a shallow mapping from incorrectly recognized words to the correct ones. This reflects real-world scenarios where the NLU system is presented with inputs that exhibit various disturbances due to changes in the ASR model, acoustic conditions, speaker variation, and other causes.
Dates
- Feb 13, 2023: Training data available (English)
- Feb 20, 2023: Training data available (other languages)
- May 17, 2023: Test data available
- May 31, 2023: Deadline for submitting the results
- June 04, 2023: Announcement of the final results, sending invitations for submitting papers
- July 04, 2023: Deadline for submitting invited papers
- July 11, 2023: Author notification
- July 31, 2023: Final paper submission, registration
- Sept 20, 2023: Challenges in Natural Language Processing Symposium
Data
The training set is derived from Leyzer: A Dataset for Multilingual Assistants. It consists of user utterances along with the semantic representation of the commands targeted at a virtual assistant. A fraction of the utterances in the training set is contaminated with speech recognition errors; however, to make the task more challenging, we left the majority of the utterances intact. The erroneous samples were obtained from user utterances using a TTS model followed by an ASR system.
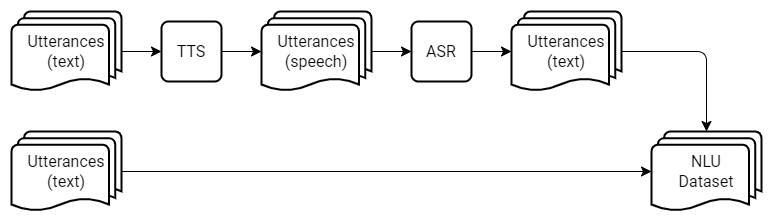
The training data are located in the train directory of the cnlps-caiccaic repository. The train directory contains two files:
-
in.tsv with four columns:
a. sample identifier:
306,b. language code:
en-US,c. data split type:
train,d. utterance:
adjust the temperature to 82 degrees fahrenheit on my reception room thermostat. -
expected.tsv with three columns representing:
a. domain label:
Airconditioner,b. intent label:
SetTemperatureToValueOnDevice,c. annotations for slot values:
{'device_name': 'reception room', 'value': '82 degrees fahrenheit'}.
For experimentation, we provide the validation dataset located in the dev-A directory of the cnlps-caiccaic repository. It was created using the same pipeline as the train dataset.
For the sake of preliminary comparison of results between contestants and self-evaluation we provide test dataset located in test-A directory of cnlps-caiccaic repository.
It contains only input values, while expected values hidden for contestants and are used by gonito platform to evaluate submissions.
The test set prepared for the final evaluation will be released on May 17, 2023, and placed in the test-B directory of the cnlps-caiccaic repository. The goal of the task is to develop NLU models that are robust to speech recognition errors regardless of their type and origin, therefore participants should not assume that the same TTS and ASR models will be used for the preparation of the test data as for the preparation of the training data. Also, the ratio of utterances containing speech recognition errors to intact utterances will vary, with far more erroneous samples found in the test set.
| Locale | split | utterances | mean length | length std | min | 50% | max |
|---|---|---|---|---|---|---|---|
| en-US | test | 3344 | 9.95066 | 4.32209 | 1 | 9 | 33 |
| en-US | train | 13022 | 9.34511 | 3.7176 | 1 | 9 | 33 |
| en-US | valid | 3633 | 9.28103 | 3.79942 | 1 | 9 | 30 |
| es-ES | test | 3520 | 13.2136 | 6.11027 | 1 | 12 | 36 |
| es-ES | train | 15043 | 13.3689 | 6.0222 | 1 | 12 | 39 |
| es-ES | valid | 3546 | 13.1523 | 5.94796 | 1 | 12 | 39 |
| pl-PL | test | 3494 | 8.9273 | 3.05946 | 1 | 9 | 22 |
| pl-PL | train | 12753 | 8.97224 | 3.02764 | 1 | 9 | 26 |
| pl-PL | valid | 3498 | 9.01801 | 3.05389 | 1 | 9 | 23 |
Baseline
We use XLM-RoBERTa Base as a baseline model for intent detection and slot-filling. XLM-RoBERTa is a multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. Each model was trained independently on the entire training set and optimized on the evaluation set. Results of the evaluation of the final epoch checkpoint on the test set are presented in the table below:
| Language | Intent Accuracy (%) | Slot F1 (%) |
|---|---|---|
| en-US | 90.40 | 78.77 |
| es-ES | 97.07 | 96.91 |
| pl-PL | 95.94 | 96.02 |
| all | 95.04 | - |
All models are available at huggingface where all details of model training and how to execute them are described:
Baseline is also submitted to Gonito platform where detailed results can be found: https://gonito.net/view-variant/8893
Submissions
-
The solutions for the task are to be submitted via the Gonito platform challenge available at https://gonito.csi.wmi.amu.edu.pl/challenge/cnlps-caiccaic.
-
For
in.tsvfile located intest-A(ortest-B) directory, the participants are expected to provideout.tsvfile in the same directory. -
Each row of
out.tsvshould contain the predictions for the corresponding row inin.tsv. -
The format of
out.tsvfile is the same as the format oftrain/expected.tsv.
Rules
-
Participants are allowed to use any publicly available data.
-
Participants are allowed to use any publicly available pre-trained models.
-
Manual labeling is forbidden.
-
Max. 5 submissions per day are allowed.
-
Teams may consist of one or more people. There is no restriction on the size of the team. Only one team representative should submit the team's solution to the platform.
-
If it turns out that the solutions submitted by two different teams have the same score, the team that submitted the solution earlier would be ranked higher.
-
To be included in the final ranking, a team should provide a report describing their solution.
-
The report should conform to the requirements specified in the exemplary document provided at https://github.com/kubapok/cnlps-caiccaic/blob/master/cnlps-report-example.pdf.
-
The best scoring submission on
test-Bfor which a report is provided wins.
Special session at FedCSIS 2023:
The authors of selected submissions will be invited to prepare the extended versions of their reports for publication in the conference proceedings and presentation at FedCSIS 2023. The Organizing Committee will make the selection based on the final evaluation results, the quality of submitted reports, and the originality of the presented methods. The papers will be indexed by the IEEE Digital Library and Web of Science (70 points MEiN- info for polish scientists).
Evaluation
To create the final ranking, the submissions will be scored using Exact Match Accuracy (EMA), i.e.
the percentage of utterance-level predictions in which domain, intent, and all the slots are correct.
Besides EMA scores, we will also report the following auxiliary metrics:
-
Domain accuracy:
the percentage of utterances with correct domain prediction.
-
Intent accuracy:
the percentage of utterances with the correct intent prediction.
-
Slot Word Recognition Rate:
Word Recognition Rate calculated on slot annotations which is the percentage of correctly annotated slot values.
Leaderboard with results of all submissions is available at Gonito platform:
- https://gonito.csi.wmi.amu.edu.pl/challenge/cnlps-caiccaic/leaderboard (new interface)
- https://gonito.net/challenge/cnlps-caiccaic (old interface, more functionality)
You can also easily evaluate your results locally using Geval tool and provided config.txt file.
To do so, get geval executable and run it in the challenge directory. You will get all the metrics calculated and printed to stdout.
Organizing Committee
- Marek Kubis, Adam Mickiewicz University, Poland
- Paweł Skórzewski, Adam Mickiewicz University, Poland
- Marcin Sowański, Samsung Research Poland
- Tomasz Ziętkiewicz, Samsung Research Poland
NEWS
For news regarding dataset updates, baseline results and other changes, please join “CNLPS” Discord server: https://discord.gg/VvjHhh7rbF.
It is also the place to ask questions about the challenge and usage of the Gonito platform.