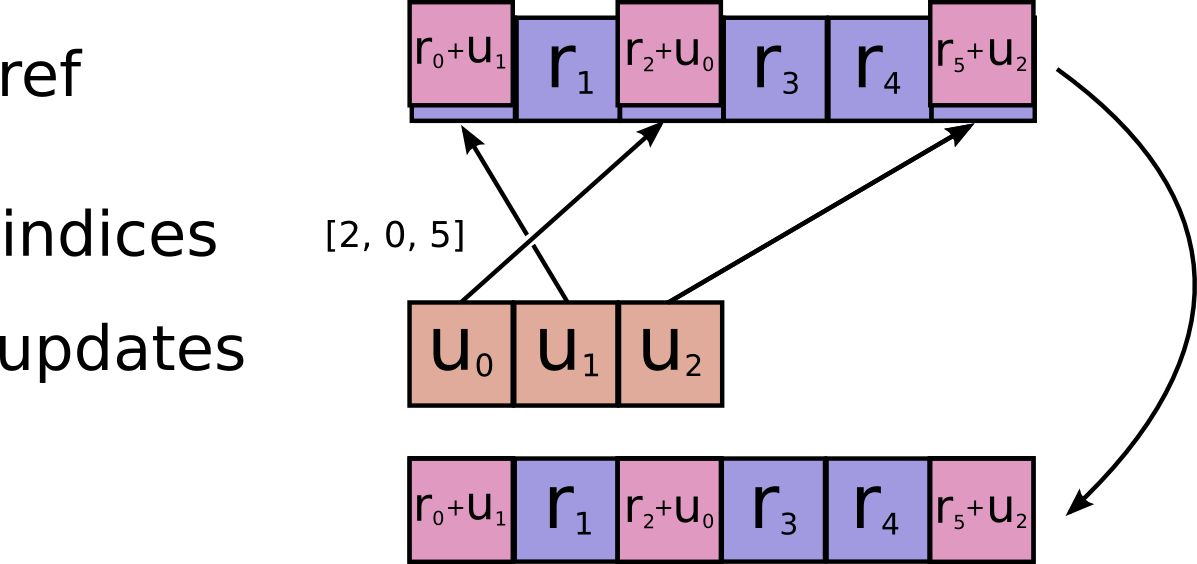"""Python wrappers around TensorFlow ops.
This file is MACHINE GENERATED! Do not edit.
"""
import collections
from tensorflow.python import pywrap_tfe as pywrap_tfe
from tensorflow.python.eager import context as _context
from tensorflow.python.eager import core as _core
from tensorflow.python.eager import execute as _execute
from tensorflow.python.framework import dtypes as _dtypes
from tensorflow.python.framework import op_def_registry as _op_def_registry
from tensorflow.python.framework import ops as _ops
from tensorflow.python.framework import op_def_library as _op_def_library
from tensorflow.python.util.deprecation import deprecated_endpoints
from tensorflow.python.util import dispatch as _dispatch
from tensorflow.python.util.tf_export import tf_export
from typing import TypeVar
def assign_add_variable_op(resource, value, name=None):
r"""Adds a value to the current value of a variable.
Any ReadVariableOp with a control dependency on this op is guaranteed to
see the incremented value or a subsequent newer one.
Args:
resource: A `Tensor` of type `resource`.
handle to the resource in which to store the variable.
value: A `Tensor`. the value by which the variable will be incremented.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "AssignAddVariableOp", name, resource, value)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return assign_add_variable_op_eager_fallback(
resource, value, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"AssignAddVariableOp", resource=resource, value=value, name=name)
return _op
AssignAddVariableOp = tf_export("raw_ops.AssignAddVariableOp")(_ops.to_raw_op(assign_add_variable_op))
def assign_add_variable_op_eager_fallback(resource, value, name, ctx):
_attr_dtype, (value,) = _execute.args_to_matching_eager([value], ctx, [])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, value]
_attrs = ("dtype", _attr_dtype)
_result = _execute.execute(b"AssignAddVariableOp", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def assign_sub_variable_op(resource, value, name=None):
r"""Subtracts a value from the current value of a variable.
Any ReadVariableOp with a control dependency on this op is guaranteed to
see the decremented value or a subsequent newer one.
Args:
resource: A `Tensor` of type `resource`.
handle to the resource in which to store the variable.
value: A `Tensor`. the value by which the variable will be incremented.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "AssignSubVariableOp", name, resource, value)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return assign_sub_variable_op_eager_fallback(
resource, value, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"AssignSubVariableOp", resource=resource, value=value, name=name)
return _op
AssignSubVariableOp = tf_export("raw_ops.AssignSubVariableOp")(_ops.to_raw_op(assign_sub_variable_op))
def assign_sub_variable_op_eager_fallback(resource, value, name, ctx):
_attr_dtype, (value,) = _execute.args_to_matching_eager([value], ctx, [])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, value]
_attrs = ("dtype", _attr_dtype)
_result = _execute.execute(b"AssignSubVariableOp", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def assign_variable_op(resource, value, validate_shape=False, name=None):
r"""Assigns a new value to a variable.
Any ReadVariableOp with a control dependency on this op is guaranteed to return
this value or a subsequent newer value of the variable.
Args:
resource: A `Tensor` of type `resource`.
handle to the resource in which to store the variable.
value: A `Tensor`. the value to set the new tensor to use.
validate_shape: An optional `bool`. Defaults to `False`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "AssignVariableOp", name, resource, value, "validate_shape",
validate_shape)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return assign_variable_op_eager_fallback(
resource, value, validate_shape=validate_shape, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if validate_shape is None:
validate_shape = False
validate_shape = _execute.make_bool(validate_shape, "validate_shape")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"AssignVariableOp", resource=resource, value=value,
validate_shape=validate_shape, name=name)
return _op
AssignVariableOp = tf_export("raw_ops.AssignVariableOp")(_ops.to_raw_op(assign_variable_op))
def assign_variable_op_eager_fallback(resource, value, validate_shape, name, ctx):
if validate_shape is None:
validate_shape = False
validate_shape = _execute.make_bool(validate_shape, "validate_shape")
_attr_dtype, (value,) = _execute.args_to_matching_eager([value], ctx, [])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, value]
_attrs = ("dtype", _attr_dtype, "validate_shape", validate_shape)
_result = _execute.execute(b"AssignVariableOp", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def consume_mutex_lock(mutex_lock, name=None):
r"""This op consumes a lock created by `MutexLock`.
This op exists to consume a tensor created by `MutexLock` (other than
direct control dependencies). It should be the only that consumes the tensor,
and will raise an error if it is not. Its only purpose is to keep the
mutex lock tensor alive until it is consumed by this op.
**NOTE**: This operation must run on the same device as its input. This may
be enforced via the `colocate_with` mechanism.
Args:
mutex_lock: A `Tensor` of type `variant`.
A tensor returned by `MutexLock`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ConsumeMutexLock", name, mutex_lock)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return consume_mutex_lock_eager_fallback(
mutex_lock, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ConsumeMutexLock", mutex_lock=mutex_lock, name=name)
return _op
ConsumeMutexLock = tf_export("raw_ops.ConsumeMutexLock")(_ops.to_raw_op(consume_mutex_lock))
def consume_mutex_lock_eager_fallback(mutex_lock, name, ctx):
mutex_lock = _ops.convert_to_tensor(mutex_lock, _dtypes.variant)
_inputs_flat = [mutex_lock]
_attrs = None
_result = _execute.execute(b"ConsumeMutexLock", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def destroy_resource_op(resource, ignore_lookup_error=True, name=None):
r"""Deletes the resource specified by the handle.
All subsequent operations using the resource will result in a NotFound
error status.
Args:
resource: A `Tensor` of type `resource`.
handle to the resource to delete.
ignore_lookup_error: An optional `bool`. Defaults to `True`.
whether to ignore the error when the resource
doesn't exist.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "DestroyResourceOp", name, resource, "ignore_lookup_error",
ignore_lookup_error)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return destroy_resource_op_eager_fallback(
resource, ignore_lookup_error=ignore_lookup_error, name=name,
ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if ignore_lookup_error is None:
ignore_lookup_error = True
ignore_lookup_error = _execute.make_bool(ignore_lookup_error, "ignore_lookup_error")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"DestroyResourceOp", resource=resource,
ignore_lookup_error=ignore_lookup_error,
name=name)
return _op
DestroyResourceOp = tf_export("raw_ops.DestroyResourceOp")(_ops.to_raw_op(destroy_resource_op))
def destroy_resource_op_eager_fallback(resource, ignore_lookup_error, name, ctx):
if ignore_lookup_error is None:
ignore_lookup_error = True
ignore_lookup_error = _execute.make_bool(ignore_lookup_error, "ignore_lookup_error")
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource]
_attrs = ("ignore_lookup_error", ignore_lookup_error)
_result = _execute.execute(b"DestroyResourceOp", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def disable_copy_on_read(resource, name=None):
r"""Turns off the copy-on-read mode.
Turns off the copy-on-read mode of a resource variable. If the variable is not in copy-on-read mode, this op has no effect.
Args:
resource: A `Tensor` of type `resource`.
The resource handle of the resource variable.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "DisableCopyOnRead", name, resource)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return disable_copy_on_read_eager_fallback(
resource, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"DisableCopyOnRead", resource=resource, name=name)
return _op
DisableCopyOnRead = tf_export("raw_ops.DisableCopyOnRead")(_ops.to_raw_op(disable_copy_on_read))
def disable_copy_on_read_eager_fallback(resource, name, ctx):
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource]
_attrs = None
_result = _execute.execute(b"DisableCopyOnRead", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def mutex_lock(mutex, name=None):
r"""Locks a mutex resource. The output is the lock. So long as the lock tensor
is alive, any other request to use `MutexLock` with this mutex will wait.
This is particularly useful for creating a critical section when used in
conjunction with `MutexLockIdentity`:
```python
mutex = mutex_v2(
shared_name=handle_name, container=container, name=name)
def execute_in_critical_section(fn, *args, **kwargs):
lock = gen_resource_variable_ops.mutex_lock(mutex)
with ops.control_dependencies([lock]):
r = fn(*args, **kwargs)
with ops.control_dependencies(nest.flatten(r)):
with ops.colocate_with(mutex):
ensure_lock_exists = mutex_lock_identity(lock)
# Make sure that if any element of r is accessed, all of
# them are executed together.
r = nest.map_structure(tf.identity, r)
with ops.control_dependencies([ensure_lock_exists]):
return nest.map_structure(tf.identity, r)
```
While `fn` is running in the critical section, no other functions which wish to
use this critical section may run.
Often the use case is that two executions of the same graph, in parallel,
wish to run `fn`; and we wish to ensure that only one of them executes
at a time. This is especially important if `fn` modifies one or more
variables at a time.
It is also useful if two separate functions must share a resource, but we
wish to ensure the usage is exclusive.
Args:
mutex: A `Tensor` of type `resource`. The mutex resource to lock.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `variant`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "MutexLock", name, mutex)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return mutex_lock_eager_fallback(
mutex, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"MutexLock", mutex=mutex, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ()
_inputs_flat = _op.inputs
_execute.record_gradient(
"MutexLock", _inputs_flat, _attrs, _result)
_result, = _result
return _result
MutexLock = tf_export("raw_ops.MutexLock")(_ops.to_raw_op(mutex_lock))
def mutex_lock_eager_fallback(mutex, name, ctx):
mutex = _ops.convert_to_tensor(mutex, _dtypes.resource)
_inputs_flat = [mutex]
_attrs = None
_result = _execute.execute(b"MutexLock", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"MutexLock", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def mutex_v2(container="", shared_name="", name=None):
r"""Creates a Mutex resource that can be locked by `MutexLock`.
Args:
container: An optional `string`. Defaults to `""`.
If non-empty, this variable is placed in the given container.
Otherwise, a default container is used.
shared_name: An optional `string`. Defaults to `""`.
If non-empty, this variable is named in the given bucket
with this shared_name. Otherwise, the node name is used instead.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `resource`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "MutexV2", name, "container", container, "shared_name",
shared_name)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return mutex_v2_eager_fallback(
container=container, shared_name=shared_name, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if container is None:
container = ""
container = _execute.make_str(container, "container")
if shared_name is None:
shared_name = ""
shared_name = _execute.make_str(shared_name, "shared_name")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"MutexV2", container=container, shared_name=shared_name, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("container", _op.get_attr("container"), "shared_name",
_op.get_attr("shared_name"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"MutexV2", _inputs_flat, _attrs, _result)
_result, = _result
return _result
MutexV2 = tf_export("raw_ops.MutexV2")(_ops.to_raw_op(mutex_v2))
def mutex_v2_eager_fallback(container, shared_name, name, ctx):
if container is None:
container = ""
container = _execute.make_str(container, "container")
if shared_name is None:
shared_name = ""
shared_name = _execute.make_str(shared_name, "shared_name")
_inputs_flat = []
_attrs = ("container", container, "shared_name", shared_name)
_result = _execute.execute(b"MutexV2", 1, inputs=_inputs_flat, attrs=_attrs,
ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"MutexV2", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def read_variable_op(resource, dtype, name=None):
r"""Reads the value of a variable.
The tensor returned by this operation is immutable.
The value returned by this operation is guaranteed to be influenced by all the
writes on which this operation depends directly or indirectly, and to not be
influenced by any of the writes which depend directly or indirectly on this
operation.
Args:
resource: A `Tensor` of type `resource`.
handle to the resource in which to store the variable.
dtype: A `tf.DType`. the dtype of the value.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `dtype`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ReadVariableOp", name, resource, "dtype", dtype)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return read_variable_op_eager_fallback(
resource, dtype=dtype, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
dtype = _execute.make_type(dtype, "dtype")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ReadVariableOp", resource=resource, dtype=dtype, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("dtype", _op._get_attr_type("dtype"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ReadVariableOp", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ReadVariableOp = tf_export("raw_ops.ReadVariableOp")(_ops.to_raw_op(read_variable_op))
def read_variable_op_eager_fallback(resource, dtype, name, ctx):
dtype = _execute.make_type(dtype, "dtype")
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource]
_attrs = ("dtype", dtype)
_result = _execute.execute(b"ReadVariableOp", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"ReadVariableOp", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def resource_gather(resource, indices, dtype, batch_dims=0, validate_indices=True, name=None):
r"""Gather slices from the variable pointed to by `resource` according to `indices`.
`indices` must be an integer tensor of any dimension (usually 0-D or 1-D).
Produces an output tensor with shape `indices.shape + params.shape[1:]` where:
```python
# Scalar indices
output[:, ..., :] = params[indices, :, ... :]
# Vector indices
output[i, :, ..., :] = params[indices[i], :, ... :]
# Higher rank indices
output[i, ..., j, :, ... :] = params[indices[i, ..., j], :, ..., :]
```
Args:
resource: A `Tensor` of type `resource`.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
dtype: A `tf.DType`.
batch_dims: An optional `int`. Defaults to `0`.
validate_indices: An optional `bool`. Defaults to `True`.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `dtype`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceGather", name, resource, indices, "batch_dims",
batch_dims, "validate_indices", validate_indices, "dtype", dtype)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_gather_eager_fallback(
resource, indices, batch_dims=batch_dims,
validate_indices=validate_indices, dtype=dtype, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
dtype = _execute.make_type(dtype, "dtype")
if batch_dims is None:
batch_dims = 0
batch_dims = _execute.make_int(batch_dims, "batch_dims")
if validate_indices is None:
validate_indices = True
validate_indices = _execute.make_bool(validate_indices, "validate_indices")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceGather", resource=resource, indices=indices, dtype=dtype,
batch_dims=batch_dims,
validate_indices=validate_indices, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("batch_dims", _op._get_attr_int("batch_dims"),
"validate_indices", _op._get_attr_bool("validate_indices"),
"dtype", _op._get_attr_type("dtype"), "Tindices",
_op._get_attr_type("Tindices"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ResourceGather", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ResourceGather = tf_export("raw_ops.ResourceGather")(_ops.to_raw_op(resource_gather))
def resource_gather_eager_fallback(resource, indices, dtype, batch_dims, validate_indices, name, ctx):
dtype = _execute.make_type(dtype, "dtype")
if batch_dims is None:
batch_dims = 0
batch_dims = _execute.make_int(batch_dims, "batch_dims")
if validate_indices is None:
validate_indices = True
validate_indices = _execute.make_bool(validate_indices, "validate_indices")
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices]
_attrs = ("batch_dims", batch_dims, "validate_indices", validate_indices,
"dtype", dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceGather", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"ResourceGather", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def resource_gather_nd(resource, indices, dtype, name=None):
r"""TODO: add doc.
Args:
resource: A `Tensor` of type `resource`.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
dtype: A `tf.DType`.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `dtype`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceGatherNd", name, resource, indices, "dtype", dtype)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_gather_nd_eager_fallback(
resource, indices, dtype=dtype, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
dtype = _execute.make_type(dtype, "dtype")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceGatherNd", resource=resource, indices=indices, dtype=dtype,
name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("dtype", _op._get_attr_type("dtype"), "Tindices",
_op._get_attr_type("Tindices"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ResourceGatherNd", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ResourceGatherNd = tf_export("raw_ops.ResourceGatherNd")(_ops.to_raw_op(resource_gather_nd))
def resource_gather_nd_eager_fallback(resource, indices, dtype, name, ctx):
dtype = _execute.make_type(dtype, "dtype")
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices]
_attrs = ("dtype", dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceGatherNd", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"ResourceGatherNd", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def resource_scatter_add(resource, indices, updates, name=None):
r"""Adds sparse updates to the variable referenced by `resource`.
This operation computes
# Scalar indices
ref[indices, ...] += updates[...]
# Vector indices (for each i)
ref[indices[i], ...] += updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] += updates[i, ..., j, ...]
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
resource: A `Tensor` of type `resource`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A tensor of updated values to add to `ref`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterAdd", name, resource, indices, updates)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_add_eager_fallback(
resource, indices, updates, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterAdd", resource=resource, indices=indices,
updates=updates, name=name)
return _op
ResourceScatterAdd = tf_export("raw_ops.ResourceScatterAdd")(_ops.to_raw_op(resource_scatter_add))
def resource_scatter_add_eager_fallback(resource, indices, updates, name, ctx):
_attr_dtype, (updates,) = _execute.args_to_matching_eager([updates], ctx, [_dtypes.float32, _dtypes.float64, _dtypes.int32, _dtypes.uint8, _dtypes.int16, _dtypes.int8, _dtypes.complex64, _dtypes.int64, _dtypes.qint8, _dtypes.quint8, _dtypes.qint32, _dtypes.bfloat16, _dtypes.qint16, _dtypes.quint16, _dtypes.uint16, _dtypes.complex128, _dtypes.half, _dtypes.uint32, _dtypes.uint64, ])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices, updates]
_attrs = ("dtype", _attr_dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceScatterAdd", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_div(resource, indices, updates, name=None):
r"""Divides sparse updates into the variable referenced by `resource`.
This operation computes
# Scalar indices
ref[indices, ...] /= updates[...]
# Vector indices (for each i)
ref[indices[i], ...] /= updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] /= updates[i, ..., j, ...]
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions multiply.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
resource: A `Tensor` of type `resource`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A tensor of updated values to add to `ref`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterDiv", name, resource, indices, updates)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_div_eager_fallback(
resource, indices, updates, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterDiv", resource=resource, indices=indices,
updates=updates, name=name)
return _op
ResourceScatterDiv = tf_export("raw_ops.ResourceScatterDiv")(_ops.to_raw_op(resource_scatter_div))
def resource_scatter_div_eager_fallback(resource, indices, updates, name, ctx):
_attr_dtype, (updates,) = _execute.args_to_matching_eager([updates], ctx, [_dtypes.float32, _dtypes.float64, _dtypes.int32, _dtypes.uint8, _dtypes.int16, _dtypes.int8, _dtypes.complex64, _dtypes.int64, _dtypes.qint8, _dtypes.quint8, _dtypes.qint32, _dtypes.bfloat16, _dtypes.qint16, _dtypes.quint16, _dtypes.uint16, _dtypes.complex128, _dtypes.half, _dtypes.uint32, _dtypes.uint64, ])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices, updates]
_attrs = ("dtype", _attr_dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceScatterDiv", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_max(resource, indices, updates, name=None):
r"""Reduces sparse updates into the variable referenced by `resource` using the `max` operation.
This operation computes
# Scalar indices
ref[indices, ...] = max(ref[indices, ...], updates[...])
# Vector indices (for each i)
ref[indices[i], ...] = max(ref[indices[i], ...], updates[i, ...])
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] = max(ref[indices[i, ..., j], ...], updates[i, ..., j, ...])
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions are combined.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
resource: A `Tensor` of type `resource`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A tensor of updated values to add to `ref`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterMax", name, resource, indices, updates)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_max_eager_fallback(
resource, indices, updates, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterMax", resource=resource, indices=indices,
updates=updates, name=name)
return _op
ResourceScatterMax = tf_export("raw_ops.ResourceScatterMax")(_ops.to_raw_op(resource_scatter_max))
def resource_scatter_max_eager_fallback(resource, indices, updates, name, ctx):
_attr_dtype, (updates,) = _execute.args_to_matching_eager([updates], ctx, [_dtypes.float32, _dtypes.float64, _dtypes.int32, _dtypes.uint8, _dtypes.int16, _dtypes.int8, _dtypes.complex64, _dtypes.int64, _dtypes.qint8, _dtypes.quint8, _dtypes.qint32, _dtypes.bfloat16, _dtypes.qint16, _dtypes.quint16, _dtypes.uint16, _dtypes.complex128, _dtypes.half, _dtypes.uint32, _dtypes.uint64, ])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices, updates]
_attrs = ("dtype", _attr_dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceScatterMax", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_min(resource, indices, updates, name=None):
r"""Reduces sparse updates into the variable referenced by `resource` using the `min` operation.
This operation computes
# Scalar indices
ref[indices, ...] = min(ref[indices, ...], updates[...])
# Vector indices (for each i)
ref[indices[i], ...] = min(ref[indices[i], ...], updates[i, ...])
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] = min(ref[indices[i, ..., j], ...], updates[i, ..., j, ...])
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions are combined.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
resource: A `Tensor` of type `resource`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A tensor of updated values to add to `ref`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterMin", name, resource, indices, updates)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_min_eager_fallback(
resource, indices, updates, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterMin", resource=resource, indices=indices,
updates=updates, name=name)
return _op
ResourceScatterMin = tf_export("raw_ops.ResourceScatterMin")(_ops.to_raw_op(resource_scatter_min))
def resource_scatter_min_eager_fallback(resource, indices, updates, name, ctx):
_attr_dtype, (updates,) = _execute.args_to_matching_eager([updates], ctx, [_dtypes.float32, _dtypes.float64, _dtypes.int32, _dtypes.uint8, _dtypes.int16, _dtypes.int8, _dtypes.complex64, _dtypes.int64, _dtypes.qint8, _dtypes.quint8, _dtypes.qint32, _dtypes.bfloat16, _dtypes.qint16, _dtypes.quint16, _dtypes.uint16, _dtypes.complex128, _dtypes.half, _dtypes.uint32, _dtypes.uint64, ])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices, updates]
_attrs = ("dtype", _attr_dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceScatterMin", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_mul(resource, indices, updates, name=None):
r"""Multiplies sparse updates into the variable referenced by `resource`.
This operation computes
# Scalar indices
ref[indices, ...] *= updates[...]
# Vector indices (for each i)
ref[indices[i], ...] *= updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] *= updates[i, ..., j, ...]
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions multiply.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
resource: A `Tensor` of type `resource`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A tensor of updated values to add to `ref`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterMul", name, resource, indices, updates)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_mul_eager_fallback(
resource, indices, updates, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterMul", resource=resource, indices=indices,
updates=updates, name=name)
return _op
ResourceScatterMul = tf_export("raw_ops.ResourceScatterMul")(_ops.to_raw_op(resource_scatter_mul))
def resource_scatter_mul_eager_fallback(resource, indices, updates, name, ctx):
_attr_dtype, (updates,) = _execute.args_to_matching_eager([updates], ctx, [_dtypes.float32, _dtypes.float64, _dtypes.int32, _dtypes.uint8, _dtypes.int16, _dtypes.int8, _dtypes.complex64, _dtypes.int64, _dtypes.qint8, _dtypes.quint8, _dtypes.qint32, _dtypes.bfloat16, _dtypes.qint16, _dtypes.quint16, _dtypes.uint16, _dtypes.complex128, _dtypes.half, _dtypes.uint32, _dtypes.uint64, ])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices, updates]
_attrs = ("dtype", _attr_dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceScatterMul", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_sub(resource, indices, updates, name=None):
r"""Subtracts sparse updates from the variable referenced by `resource`.
This operation computes
# Scalar indices
ref[indices, ...] -= updates[...]
# Vector indices (for each i)
ref[indices[i], ...] -= updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] -= updates[i, ..., j, ...]
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
resource: A `Tensor` of type `resource`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A tensor of updated values to add to `ref`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterSub", name, resource, indices, updates)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_sub_eager_fallback(
resource, indices, updates, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterSub", resource=resource, indices=indices,
updates=updates, name=name)
return _op
ResourceScatterSub = tf_export("raw_ops.ResourceScatterSub")(_ops.to_raw_op(resource_scatter_sub))
def resource_scatter_sub_eager_fallback(resource, indices, updates, name, ctx):
_attr_dtype, (updates,) = _execute.args_to_matching_eager([updates], ctx, [_dtypes.float32, _dtypes.float64, _dtypes.int32, _dtypes.uint8, _dtypes.int16, _dtypes.int8, _dtypes.complex64, _dtypes.int64, _dtypes.qint8, _dtypes.quint8, _dtypes.qint32, _dtypes.bfloat16, _dtypes.qint16, _dtypes.quint16, _dtypes.uint16, _dtypes.complex128, _dtypes.half, _dtypes.uint32, _dtypes.uint64, ])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices, updates]
_attrs = ("dtype", _attr_dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceScatterSub", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_update(resource, indices, updates, name=None):
r"""Assigns sparse updates to the variable referenced by `resource`.
This operation computes
# Scalar indices
ref[indices, ...] = updates[...]
# Vector indices (for each i)
ref[indices[i], ...] = updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] = updates[i, ..., j, ...]
Args:
resource: A `Tensor` of type `resource`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. A tensor of updated values to add to `ref`.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterUpdate", name, resource, indices, updates)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_update_eager_fallback(
resource, indices, updates, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterUpdate", resource=resource, indices=indices,
updates=updates, name=name)
return _op
ResourceScatterUpdate = tf_export("raw_ops.ResourceScatterUpdate")(_ops.to_raw_op(resource_scatter_update))
def resource_scatter_update_eager_fallback(resource, indices, updates, name, ctx):
_attr_dtype, (updates,) = _execute.args_to_matching_eager([updates], ctx, [])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource, indices, updates]
_attrs = ("dtype", _attr_dtype, "Tindices", _attr_Tindices)
_result = _execute.execute(b"ResourceScatterUpdate", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def var_handle_op(dtype, shape, container="", shared_name="", allowed_devices=[], name=None):
r"""Creates a handle to a Variable resource.
Args:
dtype: A `tf.DType`.
the type of this variable. Must agree with the dtypes
of all ops using this variable.
shape: A `tf.TensorShape` or list of `ints`.
The (possibly partially specified) shape of this variable.
container: An optional `string`. Defaults to `""`.
the container this variable is placed in.
shared_name: An optional `string`. Defaults to `""`.
the name by which this variable is referred to.
allowed_devices: An optional list of `strings`. Defaults to `[]`.
DEPRECATED. The allowed devices containing the resource variable. Set when the
output ResourceHandle represents a per-replica/partitioned resource variable.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `resource`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "VarHandleOp", name, "container", container, "shared_name",
shared_name, "dtype", dtype, "shape", shape, "allowed_devices",
allowed_devices)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return var_handle_op_eager_fallback(
container=container, shared_name=shared_name, dtype=dtype,
shape=shape, allowed_devices=allowed_devices, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
dtype = _execute.make_type(dtype, "dtype")
shape = _execute.make_shape(shape, "shape")
if container is None:
container = ""
container = _execute.make_str(container, "container")
if shared_name is None:
shared_name = ""
shared_name = _execute.make_str(shared_name, "shared_name")
if allowed_devices is None:
allowed_devices = []
if not isinstance(allowed_devices, (list, tuple)):
raise TypeError(
"Expected list for 'allowed_devices' argument to "
"'var_handle_op' Op, not %r." % allowed_devices)
allowed_devices = [_execute.make_str(_s, "allowed_devices") for _s in allowed_devices]
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"VarHandleOp", dtype=dtype, shape=shape, container=container,
shared_name=shared_name,
allowed_devices=allowed_devices, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("container", _op.get_attr("container"), "shared_name",
_op.get_attr("shared_name"), "dtype",
_op._get_attr_type("dtype"), "shape", _op.get_attr("shape"),
"allowed_devices", _op.get_attr("allowed_devices"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"VarHandleOp", _inputs_flat, _attrs, _result)
_result, = _result
return _result
VarHandleOp = tf_export("raw_ops.VarHandleOp")(_ops.to_raw_op(var_handle_op))
def var_handle_op_eager_fallback(dtype, shape, container, shared_name, allowed_devices, name, ctx):
dtype = _execute.make_type(dtype, "dtype")
shape = _execute.make_shape(shape, "shape")
if container is None:
container = ""
container = _execute.make_str(container, "container")
if shared_name is None:
shared_name = ""
shared_name = _execute.make_str(shared_name, "shared_name")
if allowed_devices is None:
allowed_devices = []
if not isinstance(allowed_devices, (list, tuple)):
raise TypeError(
"Expected list for 'allowed_devices' argument to "
"'var_handle_op' Op, not %r." % allowed_devices)
allowed_devices = [_execute.make_str(_s, "allowed_devices") for _s in allowed_devices]
_inputs_flat = []
_attrs = ("container", container, "shared_name", shared_name, "dtype",
dtype, "shape", shape, "allowed_devices", allowed_devices)
_result = _execute.execute(b"VarHandleOp", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"VarHandleOp", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def var_is_initialized_op(resource, name=None):
r"""Checks whether a resource handle-based variable has been initialized.
Args:
resource: A `Tensor` of type `resource`. the input resource handle.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `bool`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "VarIsInitializedOp", name, resource)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return var_is_initialized_op_eager_fallback(
resource, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"VarIsInitializedOp", resource=resource, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ()
_inputs_flat = _op.inputs
_execute.record_gradient(
"VarIsInitializedOp", _inputs_flat, _attrs, _result)
_result, = _result
return _result
VarIsInitializedOp = tf_export("raw_ops.VarIsInitializedOp")(_ops.to_raw_op(var_is_initialized_op))
def var_is_initialized_op_eager_fallback(resource, name, ctx):
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource]
_attrs = None
_result = _execute.execute(b"VarIsInitializedOp", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"VarIsInitializedOp", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def variable_shape(input, out_type=_dtypes.int32, name=None):
r"""Returns the shape of the variable pointed to by `resource`.
This operation returns a 1-D integer tensor representing the shape of `input`.
For example:
```
# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]]
shape(t) ==> [2, 2, 3]
```
Args:
input: A `Tensor` of type `resource`.
out_type: An optional `tf.DType` from: `tf.int32, tf.int64`. Defaults to `tf.int32`.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `out_type`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "VariableShape", name, input, "out_type", out_type)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return variable_shape_eager_fallback(
input, out_type=out_type, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if out_type is None:
out_type = _dtypes.int32
out_type = _execute.make_type(out_type, "out_type")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"VariableShape", input=input, out_type=out_type, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("out_type", _op._get_attr_type("out_type"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"VariableShape", _inputs_flat, _attrs, _result)
_result, = _result
return _result
VariableShape = tf_export("raw_ops.VariableShape")(_ops.to_raw_op(variable_shape))
def variable_shape_eager_fallback(input, out_type, name, ctx):
if out_type is None:
out_type = _dtypes.int32
out_type = _execute.make_type(out_type, "out_type")
input = _ops.convert_to_tensor(input, _dtypes.resource)
_inputs_flat = [input]
_attrs = ("out_type", out_type)
_result = _execute.execute(b"VariableShape", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"VariableShape", _inputs_flat, _attrs, _result)
_result, = _result
return _result