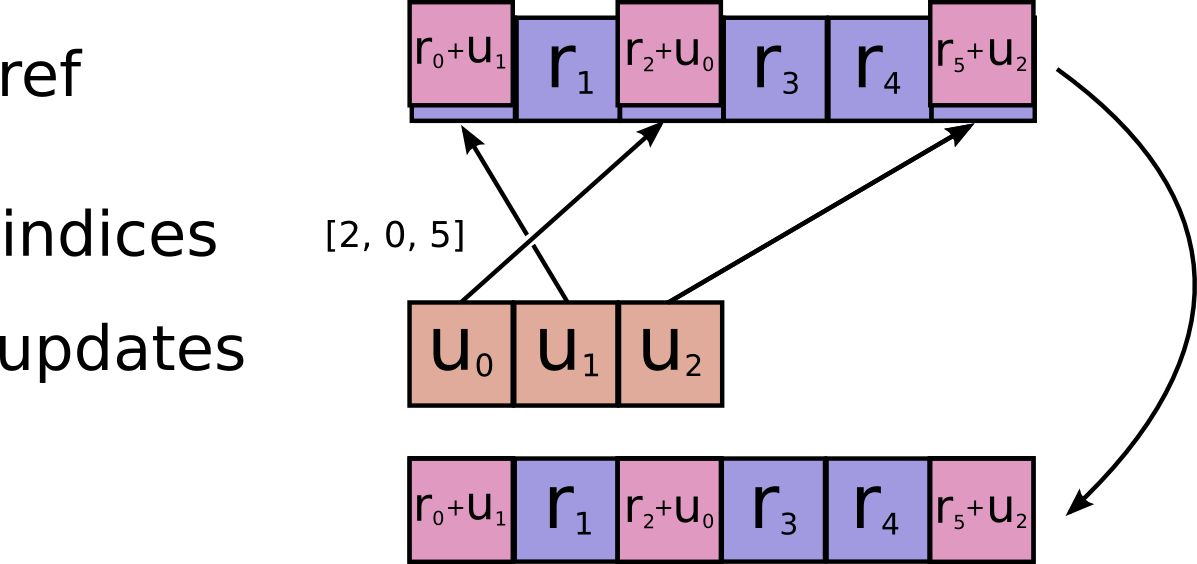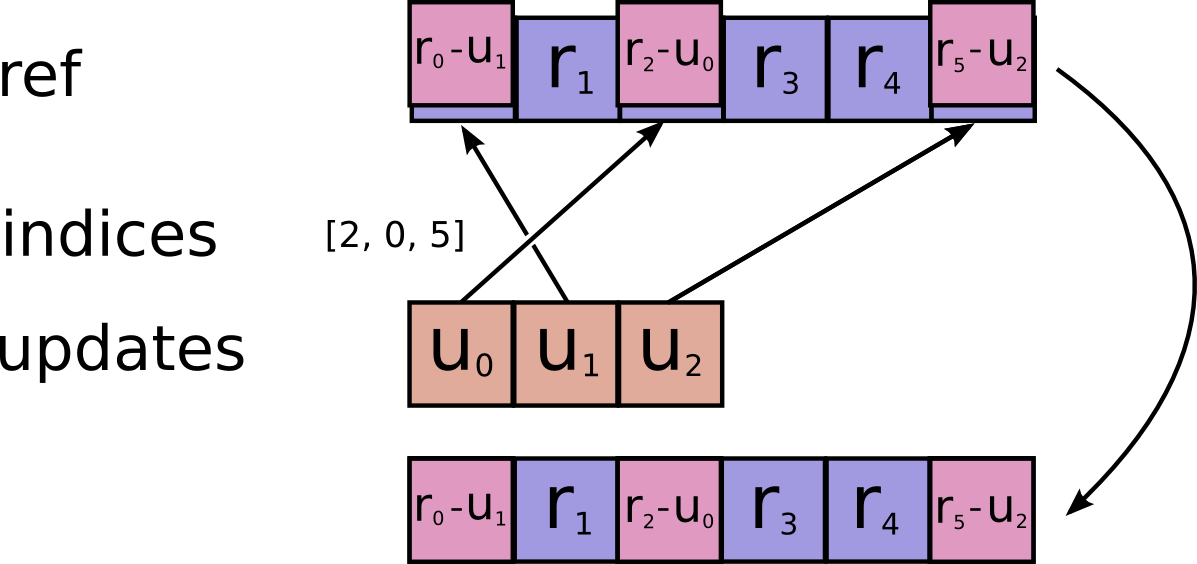"""Python wrappers around TensorFlow ops.
This file is MACHINE GENERATED! Do not edit.
"""
import collections
from tensorflow.python import pywrap_tfe as pywrap_tfe
from tensorflow.python.eager import context as _context
from tensorflow.python.eager import core as _core
from tensorflow.python.eager import execute as _execute
from tensorflow.python.framework import dtypes as _dtypes
from tensorflow.python.framework import op_def_registry as _op_def_registry
from tensorflow.python.framework import ops as _ops
from tensorflow.python.framework import op_def_library as _op_def_library
from tensorflow.python.util.deprecation import deprecated_endpoints
from tensorflow.python.util import dispatch as _dispatch
from tensorflow.python.util.tf_export import tf_export
from typing import TypeVar
def assign(ref, value, validate_shape=True, use_locking=True, name=None):
r"""Update 'ref' by assigning 'value' to it.
This operation outputs "ref" after the assignment is done.
This makes it easier to chain operations that need to use the reset value.
Args:
ref: A mutable `Tensor`.
Should be from a `Variable` node. May be uninitialized.
value: A `Tensor`. Must have the same type as `ref`.
The value to be assigned to the variable.
validate_shape: An optional `bool`. Defaults to `True`.
If true, the operation will validate that the shape
of 'value' matches the shape of the Tensor being assigned to. If false,
'ref' will take on the shape of 'value'.
use_locking: An optional `bool`. Defaults to `True`.
If True, the assignment will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("assign op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if validate_shape is None:
validate_shape = True
validate_shape = _execute.make_bool(validate_shape, "validate_shape")
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"Assign", ref=ref, value=value, validate_shape=validate_shape,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "validate_shape",
_op._get_attr_bool("validate_shape"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"Assign", _inputs_flat, _attrs, _result)
_result, = _result
return _result
Assign = tf_export("raw_ops.Assign")(_ops.to_raw_op(assign))
def assign_eager_fallback(ref, value, validate_shape, use_locking, name, ctx):
raise RuntimeError("assign op does not support eager execution. Arg 'output_ref' is a ref.")
def assign_add(ref, value, use_locking=False, name=None):
r"""Update 'ref' by adding 'value' to it.
This operation outputs "ref" after the update is done.
This makes it easier to chain operations that need to use the reset value.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
Should be from a `Variable` node.
value: A `Tensor`. Must have the same type as `ref`.
The value to be added to the variable.
use_locking: An optional `bool`. Defaults to `False`.
If True, the addition will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("assign_add op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"AssignAdd", ref=ref, value=value, use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"AssignAdd", _inputs_flat, _attrs, _result)
_result, = _result
return _result
AssignAdd = tf_export("raw_ops.AssignAdd")(_ops.to_raw_op(assign_add))
def assign_add_eager_fallback(ref, value, use_locking, name, ctx):
raise RuntimeError("assign_add op does not support eager execution. Arg 'output_ref' is a ref.")
def assign_sub(ref, value, use_locking=False, name=None):
r"""Update 'ref' by subtracting 'value' from it.
This operation outputs "ref" after the update is done.
This makes it easier to chain operations that need to use the reset value.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
Should be from a `Variable` node.
value: A `Tensor`. Must have the same type as `ref`.
The value to be subtracted to the variable.
use_locking: An optional `bool`. Defaults to `False`.
If True, the subtraction will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("assign_sub op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"AssignSub", ref=ref, value=value, use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"AssignSub", _inputs_flat, _attrs, _result)
_result, = _result
return _result
AssignSub = tf_export("raw_ops.AssignSub")(_ops.to_raw_op(assign_sub))
def assign_sub_eager_fallback(ref, value, use_locking, name, ctx):
raise RuntimeError("assign_sub op does not support eager execution. Arg 'output_ref' is a ref.")
def count_up_to(ref, limit, name=None):
r"""Increments 'ref' until it reaches 'limit'.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `int32`, `int64`.
Should be from a scalar `Variable` node.
limit: An `int`.
If incrementing ref would bring it above limit, instead generates an
'OutOfRange' error.
name: A name for the operation (optional).
Returns:
A `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("count_up_to op does not support eager execution. Arg 'ref' is a ref.")
# Add nodes to the TensorFlow graph.
limit = _execute.make_int(limit, "limit")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"CountUpTo", ref=ref, limit=limit, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("limit", _op._get_attr_int("limit"), "T",
_op._get_attr_type("T"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"CountUpTo", _inputs_flat, _attrs, _result)
_result, = _result
return _result
CountUpTo = tf_export("raw_ops.CountUpTo")(_ops.to_raw_op(count_up_to))
def count_up_to_eager_fallback(ref, limit, name, ctx):
raise RuntimeError("count_up_to op does not support eager execution. Arg 'ref' is a ref.")
def destroy_temporary_variable(ref, var_name, name=None):
r"""Destroys the temporary variable and returns its final value.
Sets output to the value of the Tensor pointed to by 'ref', then destroys
the temporary variable called 'var_name'.
All other uses of 'ref' *must* have executed before this op.
This is typically achieved by chaining the ref through each assign op, or by
using control dependencies.
Outputs the final value of the tensor pointed to by 'ref'.
Args:
ref: A mutable `Tensor`. A reference to the temporary variable tensor.
var_name: A `string`.
Name of the temporary variable, usually the name of the matching
'TemporaryVariable' op.
name: A name for the operation (optional).
Returns:
A `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("destroy_temporary_variable op does not support eager execution. Arg 'ref' is a ref.")
# Add nodes to the TensorFlow graph.
var_name = _execute.make_str(var_name, "var_name")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"DestroyTemporaryVariable", ref=ref, var_name=var_name, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "var_name",
_op.get_attr("var_name"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"DestroyTemporaryVariable", _inputs_flat, _attrs, _result)
_result, = _result
return _result
DestroyTemporaryVariable = tf_export("raw_ops.DestroyTemporaryVariable")(_ops.to_raw_op(destroy_temporary_variable))
def destroy_temporary_variable_eager_fallback(ref, var_name, name, ctx):
raise RuntimeError("destroy_temporary_variable op does not support eager execution. Arg 'ref' is a ref.")
def is_variable_initialized(ref, name=None):
r"""Checks whether a tensor has been initialized.
Outputs boolean scalar indicating whether the tensor has been initialized.
Args:
ref: A mutable `Tensor`.
Should be from a `Variable` node. May be uninitialized.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `bool`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("is_variable_initialized op does not support eager execution. Arg 'ref' is a ref.")
# Add nodes to the TensorFlow graph.
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"IsVariableInitialized", ref=ref, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("dtype", _op._get_attr_type("dtype"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"IsVariableInitialized", _inputs_flat, _attrs, _result)
_result, = _result
return _result
IsVariableInitialized = tf_export("raw_ops.IsVariableInitialized")(_ops.to_raw_op(is_variable_initialized))
def is_variable_initialized_eager_fallback(ref, name, ctx):
raise RuntimeError("is_variable_initialized op does not support eager execution. Arg 'ref' is a ref.")
def resource_count_up_to(resource, limit, T, name=None):
r"""Increments variable pointed to by 'resource' until it reaches 'limit'.
Args:
resource: A `Tensor` of type `resource`.
Should be from a scalar `Variable` node.
limit: An `int`.
If incrementing ref would bring it above limit, instead generates an
'OutOfRange' error.
T: A `tf.DType` from: `tf.int32, tf.int64`.
name: A name for the operation (optional).
Returns:
A `Tensor` of type `T`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceCountUpTo", name, resource, "limit", limit, "T", T)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_count_up_to_eager_fallback(
resource, limit=limit, T=T, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
limit = _execute.make_int(limit, "limit")
T = _execute.make_type(T, "T")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceCountUpTo", resource=resource, limit=limit, T=T, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("limit", _op._get_attr_int("limit"), "T",
_op._get_attr_type("T"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ResourceCountUpTo", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ResourceCountUpTo = tf_export("raw_ops.ResourceCountUpTo")(_ops.to_raw_op(resource_count_up_to))
def resource_count_up_to_eager_fallback(resource, limit, T, name, ctx):
limit = _execute.make_int(limit, "limit")
T = _execute.make_type(T, "T")
resource = _ops.convert_to_tensor(resource, _dtypes.resource)
_inputs_flat = [resource]
_attrs = ("limit", limit, "T", T)
_result = _execute.execute(b"ResourceCountUpTo", 1, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
if _execute.must_record_gradient():
_execute.record_gradient(
"ResourceCountUpTo", _inputs_flat, _attrs, _result)
_result, = _result
return _result
def resource_scatter_nd_add(ref, indices, updates, use_locking=True, name=None):
r"""Applies sparse addition to individual values or slices in a Variable.
`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `ref`.
It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to
indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th
dimension of `ref`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]
```
For example, say we want to add 4 scattered elements to a rank-1 tensor to
8 elements. In Python, that addition would look like this:
```python
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8], use_resource=True)
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
add = tf.scatter_nd_add(ref, indices, updates)
with tf.Session() as sess:
print sess.run(add)
```
The resulting update to ref would look like this:
[1, 13, 3, 14, 14, 6, 7, 20]
See `tf.scatter_nd` for more details about how to make updates to
slices.
Args:
ref: A `Tensor` of type `resource`.
A resource handle. Must be from a VarHandleOp.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`.
A Tensor. Must have the same type as ref. A tensor of
values to add to ref.
use_locking: An optional `bool`. Defaults to `True`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterNdAdd", name, ref, indices, updates,
"use_locking", use_locking)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_nd_add_eager_fallback(
ref, indices, updates, use_locking=use_locking, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterNdAdd", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
return _op
ResourceScatterNdAdd = tf_export("raw_ops.ResourceScatterNdAdd")(_ops.to_raw_op(resource_scatter_nd_add))
def resource_scatter_nd_add_eager_fallback(ref, indices, updates, use_locking, name, ctx):
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_attr_T, (updates,) = _execute.args_to_matching_eager([updates], ctx, [])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
ref = _ops.convert_to_tensor(ref, _dtypes.resource)
_inputs_flat = [ref, indices, updates]
_attrs = ("T", _attr_T, "Tindices", _attr_Tindices, "use_locking",
use_locking)
_result = _execute.execute(b"ResourceScatterNdAdd", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_nd_max(ref, indices, updates, use_locking=True, name=None):
r"""TODO: add doc.
Args:
ref: A `Tensor` of type `resource`.
A resource handle. Must be from a VarHandleOp.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`.
A Tensor. Must have the same type as ref. A tensor of
values whose element wise max is taken with ref
use_locking: An optional `bool`. Defaults to `True`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterNdMax", name, ref, indices, updates,
"use_locking", use_locking)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_nd_max_eager_fallback(
ref, indices, updates, use_locking=use_locking, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterNdMax", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
return _op
ResourceScatterNdMax = tf_export("raw_ops.ResourceScatterNdMax")(_ops.to_raw_op(resource_scatter_nd_max))
def resource_scatter_nd_max_eager_fallback(ref, indices, updates, use_locking, name, ctx):
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_attr_T, (updates,) = _execute.args_to_matching_eager([updates], ctx, [])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
ref = _ops.convert_to_tensor(ref, _dtypes.resource)
_inputs_flat = [ref, indices, updates]
_attrs = ("T", _attr_T, "Tindices", _attr_Tindices, "use_locking",
use_locking)
_result = _execute.execute(b"ResourceScatterNdMax", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_nd_min(ref, indices, updates, use_locking=True, name=None):
r"""TODO: add doc.
Args:
ref: A `Tensor` of type `resource`.
A resource handle. Must be from a VarHandleOp.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`.
A Tensor. Must have the same type as ref. A tensor of
values whose element wise min is taken with ref.
use_locking: An optional `bool`. Defaults to `True`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterNdMin", name, ref, indices, updates,
"use_locking", use_locking)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_nd_min_eager_fallback(
ref, indices, updates, use_locking=use_locking, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterNdMin", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
return _op
ResourceScatterNdMin = tf_export("raw_ops.ResourceScatterNdMin")(_ops.to_raw_op(resource_scatter_nd_min))
def resource_scatter_nd_min_eager_fallback(ref, indices, updates, use_locking, name, ctx):
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_attr_T, (updates,) = _execute.args_to_matching_eager([updates], ctx, [])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
ref = _ops.convert_to_tensor(ref, _dtypes.resource)
_inputs_flat = [ref, indices, updates]
_attrs = ("T", _attr_T, "Tindices", _attr_Tindices, "use_locking",
use_locking)
_result = _execute.execute(b"ResourceScatterNdMin", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_nd_sub(ref, indices, updates, use_locking=True, name=None):
r"""Applies sparse subtraction to individual values or slices in a Variable.
`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `ref`.
It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to
indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th
dimension of `ref`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]
```
For example, say we want to subtract 4 scattered elements from a rank-1 tensor
with 8 elements. In Python, that subtraction would look like this:
```python
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8], use_resource=True)
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
sub = tf.scatter_nd_sub(ref, indices, updates)
with tf.Session() as sess:
print sess.run(sub)
```
The resulting update to ref would look like this:
[1, -9, 3, -6, -4, 6, 7, -4]
See `tf.scatter_nd` for more details about how to make updates to
slices.
Args:
ref: A `Tensor` of type `resource`.
A resource handle. Must be from a VarHandleOp.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`.
A Tensor. Must have the same type as ref. A tensor of
values to add to ref.
use_locking: An optional `bool`. Defaults to `True`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterNdSub", name, ref, indices, updates,
"use_locking", use_locking)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_nd_sub_eager_fallback(
ref, indices, updates, use_locking=use_locking, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterNdSub", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
return _op
ResourceScatterNdSub = tf_export("raw_ops.ResourceScatterNdSub")(_ops.to_raw_op(resource_scatter_nd_sub))
def resource_scatter_nd_sub_eager_fallback(ref, indices, updates, use_locking, name, ctx):
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_attr_T, (updates,) = _execute.args_to_matching_eager([updates], ctx, [])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
ref = _ops.convert_to_tensor(ref, _dtypes.resource)
_inputs_flat = [ref, indices, updates]
_attrs = ("T", _attr_T, "Tindices", _attr_Tindices, "use_locking",
use_locking)
_result = _execute.execute(b"ResourceScatterNdSub", 0, inputs=_inputs_flat,
attrs=_attrs, ctx=ctx, name=name)
_result = None
return _result
def resource_scatter_nd_update(ref, indices, updates, use_locking=True, name=None):
r"""Applies sparse `updates` to individual values or slices within a given
variable according to `indices`.
`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `ref`.
It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to
indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th
dimension of `ref`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]].
```
For example, say we want to update 4 scattered elements to a rank-1 tensor to
8 elements. In Python, that update would look like this:
```python
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
indices = tf.constant([[4], [3], [1] ,[7]])
updates = tf.constant([9, 10, 11, 12])
update = tf.scatter_nd_update(ref, indices, updates)
with tf.Session() as sess:
print sess.run(update)
```
The resulting update to ref would look like this:
[1, 11, 3, 10, 9, 6, 7, 12]
See `tf.scatter_nd` for more details about how to make updates to
slices.
Args:
ref: A `Tensor` of type `resource`.
A resource handle. Must be from a VarHandleOp.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`.
A Tensor. Must have the same type as ref. A tensor of updated
values to add to ref.
use_locking: An optional `bool`. Defaults to `True`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
The created Operation.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
try:
_result = pywrap_tfe.TFE_Py_FastPathExecute(
_ctx, "ResourceScatterNdUpdate", name, ref, indices, updates,
"use_locking", use_locking)
return _result
except _core._NotOkStatusException as e:
_ops.raise_from_not_ok_status(e, name)
except _core._FallbackException:
pass
try:
return resource_scatter_nd_update_eager_fallback(
ref, indices, updates, use_locking=use_locking, name=name, ctx=_ctx)
except _core._SymbolicException:
pass # Add nodes to the TensorFlow graph.
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ResourceScatterNdUpdate", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
return _op
ResourceScatterNdUpdate = tf_export("raw_ops.ResourceScatterNdUpdate")(_ops.to_raw_op(resource_scatter_nd_update))
def resource_scatter_nd_update_eager_fallback(ref, indices, updates, use_locking, name, ctx):
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_attr_T, (updates,) = _execute.args_to_matching_eager([updates], ctx, [])
_attr_Tindices, (indices,) = _execute.args_to_matching_eager([indices], ctx, [_dtypes.int32, _dtypes.int64, ])
ref = _ops.convert_to_tensor(ref, _dtypes.resource)
_inputs_flat = [ref, indices, updates]
_attrs = ("T", _attr_T, "Tindices", _attr_Tindices, "use_locking",
use_locking)
_result = _execute.execute(b"ResourceScatterNdUpdate", 0,
inputs=_inputs_flat, attrs=_attrs, ctx=ctx,
name=name)
_result = None
return _result
def scatter_add(ref, indices, updates, use_locking=False, name=None):
r"""Adds sparse updates to a variable reference.
This operation computes
# Scalar indices
ref[indices, ...] += updates[...]
# Vector indices (for each i)
ref[indices[i], ...] += updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] += updates[i, ..., j, ...]
This operation outputs `ref` after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must have the same type as `ref`.
A tensor of updated values to add to `ref`.
use_locking: An optional `bool`. Defaults to `False`.
If True, the addition will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_add op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterAdd", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterAdd", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterAdd = tf_export("raw_ops.ScatterAdd")(_ops.to_raw_op(scatter_add))
def scatter_add_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_add op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_div(ref, indices, updates, use_locking=False, name=None):
r"""Divides a variable reference by sparse updates.
This operation computes
```python
# Scalar indices
ref[indices, ...] /= updates[...]
# Vector indices (for each i)
ref[indices[i], ...] /= updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] /= updates[i, ..., j, ...]
```
This operation outputs `ref` after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions divide.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must have the same type as `ref`.
A tensor of values that `ref` is divided by.
use_locking: An optional `bool`. Defaults to `False`.
If True, the operation will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_div op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterDiv", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterDiv", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterDiv = tf_export("raw_ops.ScatterDiv")(_ops.to_raw_op(scatter_div))
def scatter_div_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_div op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_max(ref, indices, updates, use_locking=False, name=None):
r"""Reduces sparse updates into a variable reference using the `max` operation.
This operation computes
# Scalar indices
ref[indices, ...] = max(ref[indices, ...], updates[...])
# Vector indices (for each i)
ref[indices[i], ...] = max(ref[indices[i], ...], updates[i, ...])
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] = max(ref[indices[i, ..., j], ...], updates[i, ..., j, ...])
This operation outputs `ref` after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions combine.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `half`, `bfloat16`, `float32`, `float64`, `int32`, `int64`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must have the same type as `ref`.
A tensor of updated values to reduce into `ref`.
use_locking: An optional `bool`. Defaults to `False`.
If True, the update will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_max op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterMax", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterMax", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterMax = tf_export("raw_ops.ScatterMax")(_ops.to_raw_op(scatter_max))
def scatter_max_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_max op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_min(ref, indices, updates, use_locking=False, name=None):
r"""Reduces sparse updates into a variable reference using the `min` operation.
This operation computes
# Scalar indices
ref[indices, ...] = min(ref[indices, ...], updates[...])
# Vector indices (for each i)
ref[indices[i], ...] = min(ref[indices[i], ...], updates[i, ...])
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] = min(ref[indices[i, ..., j], ...], updates[i, ..., j, ...])
This operation outputs `ref` after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions combine.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `half`, `bfloat16`, `float32`, `float64`, `int32`, `int64`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must have the same type as `ref`.
A tensor of updated values to reduce into `ref`.
use_locking: An optional `bool`. Defaults to `False`.
If True, the update will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_min op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterMin", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterMin", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterMin = tf_export("raw_ops.ScatterMin")(_ops.to_raw_op(scatter_min))
def scatter_min_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_min op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_mul(ref, indices, updates, use_locking=False, name=None):
r"""Multiplies sparse updates into a variable reference.
This operation computes
```python
# Scalar indices
ref[indices, ...] *= updates[...]
# Vector indices (for each i)
ref[indices[i], ...] *= updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] *= updates[i, ..., j, ...]
```
This operation outputs `ref` after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their contributions multiply.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must have the same type as `ref`.
A tensor of updated values to multiply to `ref`.
use_locking: An optional `bool`. Defaults to `False`.
If True, the operation will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_mul op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterMul", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterMul", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterMul = tf_export("raw_ops.ScatterMul")(_ops.to_raw_op(scatter_mul))
def scatter_mul_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_mul op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_nd_add(ref, indices, updates, use_locking=False, name=None):
r"""Applies sparse addition to individual values or slices in a Variable.
`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `ref`.
It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to
indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th
dimension of `ref`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]
```
For example, say we want to add 4 scattered elements to a rank-1 tensor to
8 elements. In Python, that addition would look like this:
```python
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
add = tf.scatter_nd_add(ref, indices, updates)
with tf.Session() as sess:
print sess.run(add)
```
The resulting update to ref would look like this:
[1, 13, 3, 14, 14, 6, 7, 20]
See `tf.scatter_nd` for more details about how to make updates to
slices.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A mutable Tensor. Should be from a Variable node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`. Must have the same type as `ref`.
A Tensor. Must have the same type as ref. A tensor of updated values
to add to ref.
use_locking: An optional `bool`. Defaults to `False`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_nd_add op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterNdAdd", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterNdAdd", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterNdAdd = tf_export("raw_ops.ScatterNdAdd")(_ops.to_raw_op(scatter_nd_add))
def scatter_nd_add_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_nd_add op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_nd_max(ref, indices, updates, use_locking=False, name=None):
r"""Computes element-wise maximum.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A mutable Tensor. Should be from a Variable node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`. Must have the same type as `ref`.
A Tensor. Must have the same type as ref. A tensor of updated values
to add to ref.
use_locking: An optional `bool`. Defaults to `False`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_nd_max op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterNdMax", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterNdMax", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterNdMax = tf_export("raw_ops.ScatterNdMax")(_ops.to_raw_op(scatter_nd_max))
def scatter_nd_max_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_nd_max op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_nd_min(ref, indices, updates, use_locking=False, name=None):
r"""Computes element-wise minimum.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A mutable Tensor. Should be from a Variable node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`. Must have the same type as `ref`.
A Tensor. Must have the same type as ref. A tensor of updated values
to add to ref.
use_locking: An optional `bool`. Defaults to `False`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_nd_min op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterNdMin", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterNdMin", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterNdMin = tf_export("raw_ops.ScatterNdMin")(_ops.to_raw_op(scatter_nd_min))
def scatter_nd_min_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_nd_min op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_nd_sub(ref, indices, updates, use_locking=False, name=None):
r"""Applies sparse subtraction to individual values or slices in a Variable.
within a given variable according to `indices`.
`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `ref`.
It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to
indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th
dimension of `ref`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]
```
For example, say we want to subtract 4 scattered elements from a rank-1 tensor
with 8 elements. In Python, that subtraction would look like this:
```python
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
sub = tf.scatter_nd_sub(ref, indices, updates)
with tf.Session() as sess:
print sess.run(sub)
```
The resulting update to ref would look like this:
[1, -9, 3, -6, -4, 6, 7, -4]
See `tf.scatter_nd` for more details about how to make updates to
slices.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
A mutable Tensor. Should be from a Variable node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`. Must have the same type as `ref`.
A Tensor. Must have the same type as ref. A tensor of updated values
to subtract from ref.
use_locking: An optional `bool`. Defaults to `False`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_nd_sub op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterNdSub", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterNdSub", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterNdSub = tf_export("raw_ops.ScatterNdSub")(_ops.to_raw_op(scatter_nd_sub))
def scatter_nd_sub_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_nd_sub op does not support eager execution. Arg 'output_ref' is a ref.")
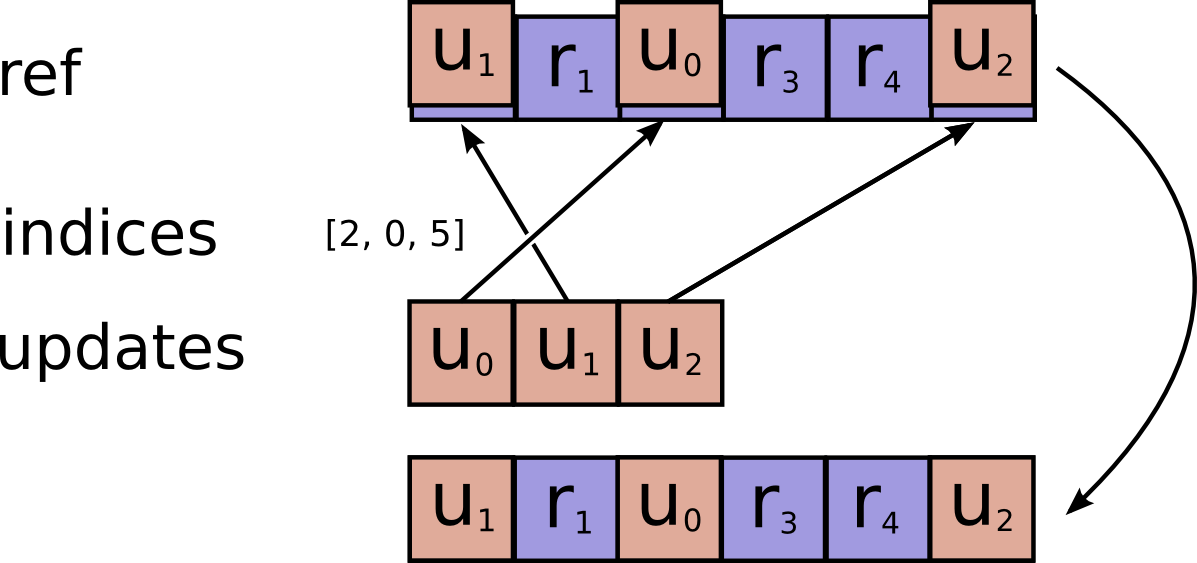
def scatter_nd_update(ref, indices, updates, use_locking=True, name=None):
r"""Applies sparse `updates` to individual values or slices within a given
variable according to `indices`.
`ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into `ref`.
It must be shape \\([d_0, ..., d_{Q-2}, K]\\) where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to
indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th
dimension of `ref`.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
$$[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]].$$
For example, say we want to update 4 scattered elements to a rank-1 tensor to
8 elements. In Python, that update would look like this:
```python
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
indices = tf.constant([[4], [3], [1] ,[7]])
updates = tf.constant([9, 10, 11, 12])
update = tf.scatter_nd_update(ref, indices, updates)
with tf.Session() as sess:
print sess.run(update)
```
The resulting update to ref would look like this:
[1, 11, 3, 10, 9, 6, 7, 12]
See `tf.scatter_nd` for more details about how to make updates to
slices.
See also `tf.scatter_update` and `tf.batch_scatter_update`.
Args:
ref: A mutable `Tensor`.
A mutable Tensor. Should be from a Variable node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A Tensor. Must be one of the following types: int32, int64.
A tensor of indices into ref.
updates: A `Tensor`. Must have the same type as `ref`.
A Tensor. Must have the same type as ref. A tensor of updated
values to add to ref.
use_locking: An optional `bool`. Defaults to `True`.
An optional bool. Defaults to True. If True, the assignment will
be protected by a lock; otherwise the behavior is undefined,
but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_nd_update op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterNdUpdate", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterNdUpdate", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterNdUpdate = tf_export("raw_ops.ScatterNdUpdate")(_ops.to_raw_op(scatter_nd_update))
def scatter_nd_update_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_nd_update op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_sub(ref, indices, updates, use_locking=False, name=None):
r"""Subtracts sparse updates to a variable reference.
```python
# Scalar indices
ref[indices, ...] -= updates[...]
# Vector indices (for each i)
ref[indices[i], ...] -= updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] -= updates[i, ..., j, ...]
```
This operation outputs `ref` after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple `indices` reference
the same location, their (negated) contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
Args:
ref: A mutable `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `complex64`, `int64`, `qint8`, `quint8`, `qint32`, `bfloat16`, `qint16`, `quint16`, `uint16`, `complex128`, `half`, `uint32`, `uint64`.
Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must have the same type as `ref`.
A tensor of updated values to subtract from `ref`.
use_locking: An optional `bool`. Defaults to `False`.
If True, the subtraction will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_sub op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = False
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterSub", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterSub", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterSub = tf_export("raw_ops.ScatterSub")(_ops.to_raw_op(scatter_sub))
def scatter_sub_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_sub op does not support eager execution. Arg 'output_ref' is a ref.")
def scatter_update(ref, indices, updates, use_locking=True, name=None):
r"""Applies sparse updates to a variable reference.
This operation computes
```python
# Scalar indices
ref[indices, ...] = updates[...]
# Vector indices (for each i)
ref[indices[i], ...] = updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] = updates[i, ..., j, ...]
```
This operation outputs `ref` after the update is done.
This makes it easier to chain operations that need to use the reset value.
If values in `ref` is to be updated more than once, because there are
duplicate entries in `indices`, the order at which the updates happen
for each value is undefined.
Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
See also `tf.batch_scatter_update` and `tf.scatter_nd_update`.
Args:
ref: A mutable `Tensor`. Should be from a `Variable` node.
indices: A `Tensor`. Must be one of the following types: `int32`, `int64`.
A tensor of indices into the first dimension of `ref`.
updates: A `Tensor`. Must have the same type as `ref`.
A tensor of updated values to store in `ref`.
use_locking: An optional `bool`. Defaults to `True`.
If True, the assignment will be protected by a lock;
otherwise the behavior is undefined, but may exhibit less contention.
name: A name for the operation (optional).
Returns:
A mutable `Tensor`. Has the same type as `ref`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("scatter_update op does not support eager execution. Arg 'output_ref' is a ref.")
# Add nodes to the TensorFlow graph.
if use_locking is None:
use_locking = True
use_locking = _execute.make_bool(use_locking, "use_locking")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"ScatterUpdate", ref=ref, indices=indices, updates=updates,
use_locking=use_locking, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("T", _op._get_attr_type("T"), "Tindices",
_op._get_attr_type("Tindices"), "use_locking",
_op._get_attr_bool("use_locking"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"ScatterUpdate", _inputs_flat, _attrs, _result)
_result, = _result
return _result
ScatterUpdate = tf_export("raw_ops.ScatterUpdate")(_ops.to_raw_op(scatter_update))
def scatter_update_eager_fallback(ref, indices, updates, use_locking, name, ctx):
raise RuntimeError("scatter_update op does not support eager execution. Arg 'output_ref' is a ref.")
def temporary_variable(shape, dtype, var_name="", name=None):
r"""Returns a tensor that may be mutated, but only persists within a single step.
This is an experimental op for internal use only and it is possible to use this
op in unsafe ways. DO NOT USE unless you fully understand the risks.
It is the caller's responsibility to ensure that 'ref' is eventually passed to a
matching 'DestroyTemporaryVariable' op after all other uses have completed.
Outputs a ref to the tensor state so it may be read or modified.
E.g.
var = state_ops._temporary_variable([1, 2], types.float_)
var_name = var.op.name
var = state_ops.assign(var, [[4.0, 5.0]])
var = state_ops.assign_add(var, [[6.0, 7.0]])
final = state_ops._destroy_temporary_variable(var, var_name=var_name)
Args:
shape: A `tf.TensorShape` or list of `ints`.
The shape of the variable tensor.
dtype: A `tf.DType`. The type of elements in the variable tensor.
var_name: An optional `string`. Defaults to `""`.
Overrides the name used for the temporary variable resource. Default
value is the name of the 'TemporaryVariable' op (which is guaranteed unique).
name: A name for the operation (optional).
Returns:
A mutable `Tensor` of type `dtype`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("temporary_variable op does not support eager execution. Arg 'ref' is a ref.")
# Add nodes to the TensorFlow graph.
shape = _execute.make_shape(shape, "shape")
dtype = _execute.make_type(dtype, "dtype")
if var_name is None:
var_name = ""
var_name = _execute.make_str(var_name, "var_name")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"TemporaryVariable", shape=shape, dtype=dtype, var_name=var_name,
name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("shape", _op.get_attr("shape"), "dtype",
_op._get_attr_type("dtype"), "var_name",
_op.get_attr("var_name"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"TemporaryVariable", _inputs_flat, _attrs, _result)
_result, = _result
return _result
TemporaryVariable = tf_export("raw_ops.TemporaryVariable")(_ops.to_raw_op(temporary_variable))
def temporary_variable_eager_fallback(shape, dtype, var_name, name, ctx):
raise RuntimeError("temporary_variable op does not support eager execution. Arg 'ref' is a ref.")
def variable(shape, dtype, container="", shared_name="", name=None):
r"""Use VariableV2 instead.
Args:
shape: A `tf.TensorShape` or list of `ints`.
dtype: A `tf.DType`.
container: An optional `string`. Defaults to `""`.
shared_name: An optional `string`. Defaults to `""`.
name: A name for the operation (optional).
Returns:
A mutable `Tensor` of type `dtype`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("variable op does not support eager execution. Arg 'ref' is a ref.")
# Add nodes to the TensorFlow graph.
shape = _execute.make_shape(shape, "shape")
dtype = _execute.make_type(dtype, "dtype")
if container is None:
container = ""
container = _execute.make_str(container, "container")
if shared_name is None:
shared_name = ""
shared_name = _execute.make_str(shared_name, "shared_name")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"Variable", shape=shape, dtype=dtype, container=container,
shared_name=shared_name, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("shape", _op.get_attr("shape"), "dtype",
_op._get_attr_type("dtype"), "container",
_op.get_attr("container"), "shared_name",
_op.get_attr("shared_name"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"Variable", _inputs_flat, _attrs, _result)
_result, = _result
return _result
Variable = tf_export("raw_ops.Variable")(_ops.to_raw_op(variable))
def variable_eager_fallback(shape, dtype, container, shared_name, name, ctx):
raise RuntimeError("variable op does not support eager execution. Arg 'ref' is a ref.")
def variable_v2(shape, dtype, container="", shared_name="", name=None):
r"""Holds state in the form of a tensor that persists across steps.
Outputs a ref to the tensor state so it may be read or modified.
TODO(zhifengc/mrry): Adds a pointer to a more detail document
about sharing states in tensorflow.
Args:
shape: A `tf.TensorShape` or list of `ints`.
The shape of the variable tensor.
dtype: A `tf.DType`. The type of elements in the variable tensor.
container: An optional `string`. Defaults to `""`.
If non-empty, this variable is placed in the given container.
Otherwise, a default container is used.
shared_name: An optional `string`. Defaults to `""`.
If non-empty, this variable is named in the given bucket
with this shared_name. Otherwise, the node name is used instead.
name: A name for the operation (optional).
Returns:
A mutable `Tensor` of type `dtype`.
"""
_ctx = _context._context or _context.context()
tld = _ctx._thread_local_data
if tld.is_eager:
raise RuntimeError("variable_v2 op does not support eager execution. Arg 'ref' is a ref.")
# Add nodes to the TensorFlow graph.
shape = _execute.make_shape(shape, "shape")
dtype = _execute.make_type(dtype, "dtype")
if container is None:
container = ""
container = _execute.make_str(container, "container")
if shared_name is None:
shared_name = ""
shared_name = _execute.make_str(shared_name, "shared_name")
_, _, _op, _outputs = _op_def_library._apply_op_helper(
"VariableV2", shape=shape, dtype=dtype, container=container,
shared_name=shared_name, name=name)
_result = _outputs[:]
if _execute.must_record_gradient():
_attrs = ("shape", _op.get_attr("shape"), "dtype",
_op._get_attr_type("dtype"), "container",
_op.get_attr("container"), "shared_name",
_op.get_attr("shared_name"))
_inputs_flat = _op.inputs
_execute.record_gradient(
"VariableV2", _inputs_flat, _attrs, _result)
_result, = _result
return _result
VariableV2 = tf_export("raw_ops.VariableV2")(_ops.to_raw_op(variable_v2))
def variable_v2_eager_fallback(shape, dtype, container, shared_name, name, ctx):
raise RuntimeError("variable_v2 op does not support eager execution. Arg 'ref' is a ref.")