15 KiB

Ekstrakcja informacji
2. Wyszukiwarki roboty [ćwiczenia]
Jakub Pokrywka (2021)

Wyszukiwarki roboty
Zadanie
Opracować w języku Haskell wyspecjalizowanego robota pobierającego dane z konkretnego serwisu.
Punkty: 80 (domyślnie - niektóre zadanie są trudniejsze, wówczas ich ilość podana jest przy zadaniu)
Ogólne zasady:
- pobieramy informacje (metadane) o plikach PDF, DjVU, JPG itp, ale nie same pliki,
- nie pobierajmy całego serwisu, tylko tyle, ile trzeba, by pobrać metadane o interesujących nas zasobach,
- interesują nas tylko teksty polskie, jeśli nie jest to trudne, należy odfiltrować publikacje obcojęzyczne,
- staramy się ustalać datę z możliwie dużą dokładnością.
Instrukcja
0. Haskell Stack
Pobrać Haskell Stack
curl -sSL https://get.haskellstack.org/ | sh -s - -d ~/bin
Problemy z fizycznymi komputerami wydziałowymi
Na fizycznych komputerach wydziałowych są błędnie ustawione prawa dostępu na dyskach sieciowych, Haskell Stack musi działać na fizycznym dysku:
rm -rf /mnt/poligon/.stack
mkdir /mnt/poligon/.stack
mv ~/.stack ~/.stack-bak # gdyby już był... proszę się nie przejmować błędem
ln -s /mnt/poligon/.stack ~/.stack
1. Repozytorium z przykładowym rozwiązeniem
Zrobienie forka repozytorium https://git.wmi.amu.edu.pl/filipg/twilight-library.git
Sklonowanie sforkowanego repozytorium na komputer
2. Sprawdzenie czy przykładowy robot działa
W katalogu projektu należy odpalić:
stack install # może trwać długo za pierwszym razem
stack exec almanachmuszyny
Jeżeli instalacja nie powiedzie się, być może należy zainstalować paczki libpcre3 libpcre3-dev , np. na ubuntu:
sudo apt install libpcre3 libpcre3-dev
Metoda opracowania robota z przykładu:
Znalezienie wyszystkich stron z rocznikami:
W przeglądarce należy znaleźć wszystkie linki do stron z rocznikami. Najłatwiej zrobić to przez podejrzenie źródła strony. Na przykład można kliknąć prawym przyciskiem myszy na link i wybrac "Inspect Element" (działa na chrome).
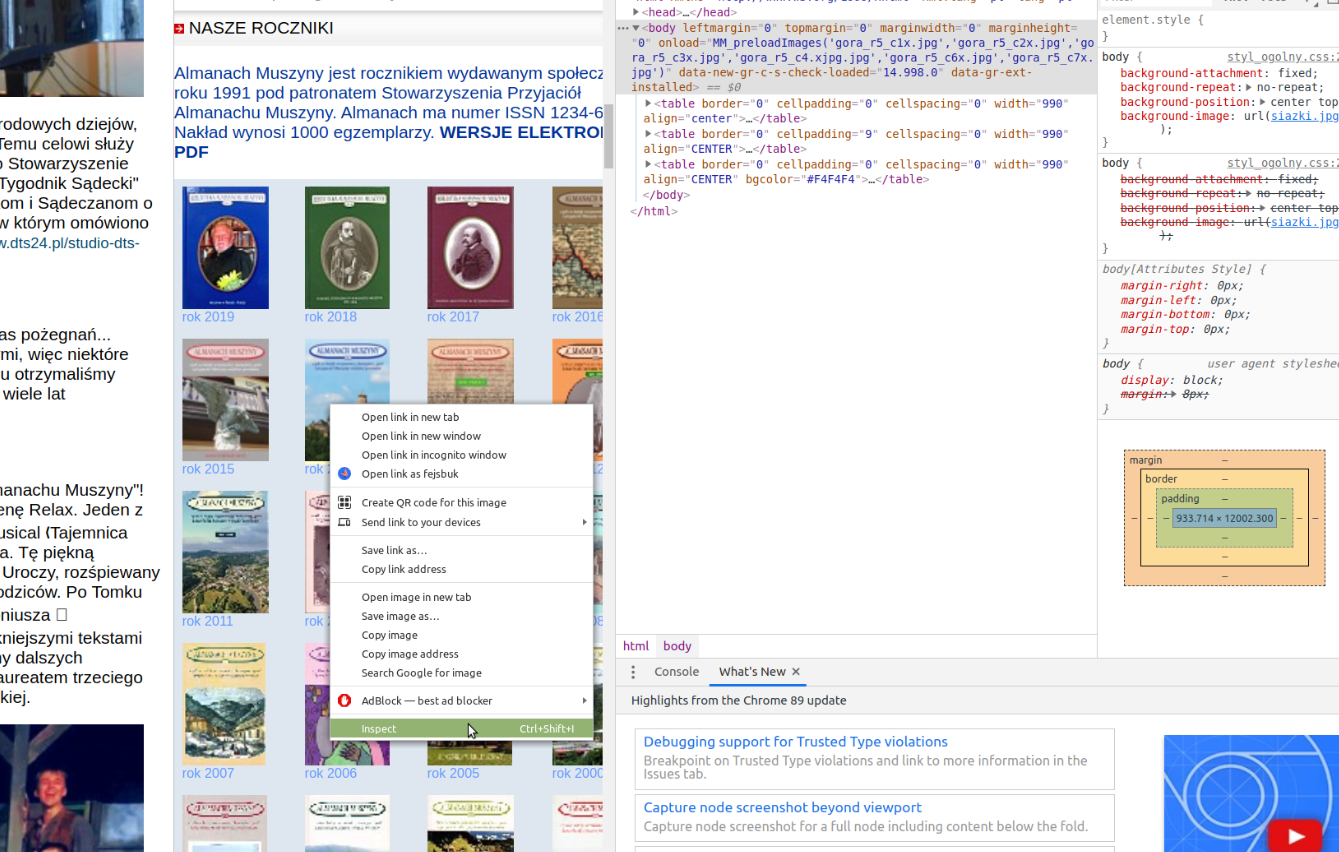
Łatwo zauważyć, że wszystkie linki mają klasę "roczniki". Dlatego należy odwołać sie w robocie do tej klasy poprzez xpath w pliku app/almanachmuszyny.hs :
extractRecords = extractLinksWithText "//a[@class='roczniki']" -- pary adres-tytuł
Następna linijka kodu służy oczyszczeniu stringa z tytułem rocznika:
>>> second (arr $ replace "\r\n " " ")
Następnie, łatwo zauważyć, że robiąc prostą manipulację linkiem z :
http://www.almanachmuszyny.pl/index.php?p=spisy/95s
na
http://www.almanachmuszyny.pl/index.php?p=spisy/95tr
dostajemy stronę spis-treści ze wszystkimi pdf-ami. Dlatego robimy podmianę linku:
>>> first (arr ((++"tr") . init)) -- modyfikujemy pierwszy element pary, czyli adres URL
Nastęnie ze wszystkich podanych stron ze spisem treści wybieramy wszystkie pdfy korzystając z polecenia:
>>> first (extractLinksWithText "//li/a[contains(@href,'.pdf')]")
3. Opracowanie swojego robota
Opracuj swojego robota wzorując się na pliku almanachmuszyny.hs. (Ale dodaj swój plik, nie zmieniaj almanachmuszyny.hs!) Twój robot powinien działać na serwisie wybranym z listy na którą należy się zapisać (na dole tej strony).
Dopisz specyfikację swojego robota do shadow-library.cabal.
Pracuj nad swoim robotem, uruchamiaj go w następujący sposób:
stack build
stack exec mojrobot
mojrobot to przykładowa nazwa- dla swojego projektu użyj innej, znaczącej nazwy
Jeśli publikacja (np. pojedynczy numer gazety) składa się z wielu plików, powinien zostać wygenerowany jeden rekord, w finalUrl powinny znaleźć się URL do poszczególnych stron (np. plików JPR) oddzielone //.
Dla twojego robota przydatne mogą być funkcje zdefiniowane w ShadowLibrary/Core.hs
Problemy z https
W przypadku problemów z https:
Trzeba użyć modułu opartego na bibliotece curl. Paczka Ubuntu została zainstalowana na komputerach wydziałowych. Na swoim komputerze możemy zainstalować paczkę libcurl4-openssl-dev, a następnie można sobie ściągnąć wersję twilight-library opartą na libcurl:
git fetch git://gonito.net/twilight-library withcurl
git merge FETCH_HEAD
4. Zgłoszenie zadań
Po opracowaniu robota oddaj zadanie korzystając z panelu MS TEAMS assigments umieszczając jako rozwiązanie link do twojego repozytorium.
Lista serwisów do wyboru
Na serwis należy zapisywać się korzystając z linka do google doc podanego na ćwiczeniach
Lista serwisów do wyboru (na każdy serwis 1 osoba):
- Teksty Drugie
- Archiwum Inspektora Pracy
- Medycyna Weterynaryjna — również historyczne zasoby od 1945 roku, 120 punktów
- Polskie Towarzystwo Botaniczne — wszystkie dostępne zdigitalizowane publikacje!, 130 punktow
- Wieści Pepowa — nie pominąć strony nr 2 z wynikami, 110 punktów
- Czasopismo Kosmos
- Czasopismo Wszechświat
- Czasopisma polonijne we Francji — najlepiej w postaci PDF-ów, jak np. https://argonnaute.parisnanterre.fr/medias/customer_3/periodique/immi_pol_lotmz1_pdf/BDIC_GFP_2929_1945_039.pdf, 220 punktów
- Muzeum Sztuki — czasopisma, 220 punktów, publikacje, teksty, czasopisma, wycinki
- Wiadomości Urzędu Patentowego
- Czas, czasopismo polonijne, 140 punktów S.G.
- Stenogramy Okrągłego Stołu, 110 punktów
- Nasze Popowice
- Czasopisma entomologiczne
- Wiadomości matematyczne, 120 punktow
- Alkoholizm i Narkomania
- Czasopismo Etyka, O.K.
- Skup makulatury, 250 punktów
- Hermes i https://chomikuj.pl/hermes50-2, 250 punktów
- E-dziennik Województwa Mazowieckiego 150 punktów
- Czasopismo Węgiel Brunatny
- Gazeta GUM
- Nowiny Andrychowskie
- Kawęczyniak
- Zbór Chrześcijański w Bielawia
- Gazeta Rytwiańska
- Nasze Popowice
- Echo Chełmka
- Głos Świdnika 100 punktów
- Aneks 90 punktów
- Teatr Lalel
- Biuletyn Bezpieczna Chemia
- Głos Maszynisty
- Kultura Paryska, całe archiwum z książkami i innymi czasopismami, 180 punktów
- Gazeta Fabryczna - Kraśnik 120 punktów
- Artykuły o Jujutsu
- Wycinki o Taekwon-Do
- Materiały o kolejnictwie 180 punktów
- Centralny Instytut Ochrony Pracy, znaleźć wszystkie publikacje typu http://archiwum.ciop.pl/44938, wymaga trochę sprytu 130 punktów
- Biblioteka Sejmowa - Zasoby Cyfrowe, 200 punktów
- Elektronika Praktyczna, te numery, które dostępne w otwarty sposób, np. rok 1993
- Litewska Akademia Nauk, tylko materiały w jęz. polskim, takie jak np. https://elibrary.mab.lt/handle/1/840, 170 punktów
- Litewska Biblioteka Cyfrowa, wyłuskać tylko materiały w jęz. polskim, 190 punktów
- Czasopisma Geologiczne, 120 punktów
- Czasopisma PTTK, 120 punktów
- Czasopisma Polskiego Towarzystwa Dendrologicznego, 100 punktów
- Kilka przedwojennych książek
- Historia polskiej informatyki - wyjątkowo bez datowania
- Zeszyty Formacyjne Katolickiego Stowarzyszenia „Civitas Christania”, tylko niektóre pliki można zdatować
- Józef Piłsudski Institute of America - 220 punktów
- Prasa podziemna — Częstochowa, również ulotki i inne materiały skanowane - 180 punktów
- Tajemnica Atari, plik ZIP z DjVu
- Gorzowskie Wiadomości Samorządowe
- Gazeta Rodnia - Bieruń
- Parafia Śrem
- BIP Gdynia do roku 1990!, 120 punktów
- BIP Żyrardów do roku 1990!, 120 punktów
- Biuletyn Polarny
- Otwarte czasopisma Wydawnictwa UAM, 140 punktów
- Wycinki o kolei gondolowej — zob. "Napisali o Szyndzielni" na tej stronie
- Instytut Radioelektroniki PW
- Zagadnienia Ekonomiki Rolnej, 100 punktów
- Rozkazy Komendanta Chorągwi Wielkopolskiej ZHP, 130 punktów
- Sulimczyk - pismo harcerskie
- Archiwum Harcerskie, 170 punktów
- Cyfrowe Archiwa Tarnowskie, 100 punktów
- Instytut Techniki Górniczej - wycinki