18 KiB
- Wygładzanie w n-gramowych modelach języka
Wygładzanie w n-gramowych modelach języka
Dlaczego wygładzanie?
Wyobraźmy sobie urnę, w której znajdują się kule w $m$ kolorach (ściślej: w co najwyżej $m$ kolorach, może w ogóle nie być kul w danym kolorze). Nie wiemy, ile jest ogółem kul w urnie i w jakiej liczbie występuje każdy z kolorów.
Losujemy ze zwracaniem (to istotne!) $T$ kul, załóżmy, że wylosowaliśmy w poszczególnych kolorach $\{k_1,\dots,k_m\}$ kul (tzn. pierwszą kolor wylosowaliśmy $k_1$ razy, drugi kolor — $k_2$ razy itd.). Rzecz jasna, $\sum_{i=1}^m k_i = T$.
Jak powinniśmy racjonalnie szacować prawdopodobieństwa wylosowania kuli w $i$-tym kolorze ($p_i$)?
Wydawałoby się, że wystarczy liczbę wylosowanych kul w danym kolorze podzielić przez liczbę wszystkich prób:
$$p_i = \frac{k_i}{T}.$$
Wygładzanie — przykład
Rozpatrzmy przykład z 3 kolorami (wiemy, że w urnie mogą być kule żółte, zielone i czerwone, tj. $m=3$) i 4 losowaniami ($T=4$):
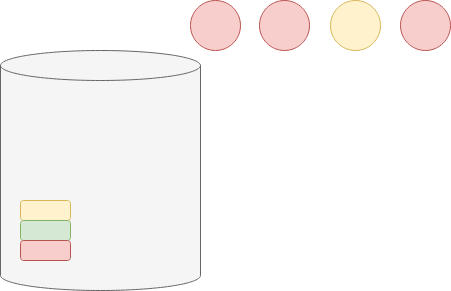
Gdybyśmy w prosty sposób oszacowali prawdopodobieństwa, doszlibyśmy do wniosku, że prawdopodobieństwo wylosowania kuli czerwonej wynosi 3/4, żółtej — 1/4, a zielonej — 0. Wartości te są jednak dość problematyczne:
- Za bardzo przywiązujemy się do naszej skromnej próby, potrzebowalibyśmy większej liczby losowań, żeby być bardziej pewnym naszych estymacji.
- W szczególności stwierdzenie, że prawdopodobieństwo wylosowania kuli zielonej wynosi 0, jest bardzo mocnym stwierdzeniem (twierdzimy, że NIEMOŻLIWE jest wylosowanie kuli zielonej), dopiero większa liczba prób bez wylosowania zielonej kuli mogłaby sugerować prawdopodobieństwo bliskie zeru.
- Zauważmy, że niemożliwe jest wylosowanie ułamka kuli, jeśli w rzeczywistości 10% kul jest żółtych, to nie oznacza się wylosujemy $4\frac{1}{10} = \frac{2}{5}$ kuli. Prawdopodobnie wylosujemy jedną kulę żółtą albo żadną. Wylosowanie dwóch kul żółtych byłoby możliwe, ale mniej prawdopodobne. Jeszcze mniej prawdopodobne byłoby wylosowanie 3 lub 4 kul żółtych.
Idea wygładzania
Wygładzanie (ang. smoothing) polega na tym, że „uszczknąć” nieco masy prawdopodobieństwa zdarzeniom wskazywanym przez eksperyment czy zbiór uczący i rozdzielić ją między mniej prawdopodobne zdarzenia.
Wygładzanie +1
Najprostszy sposób wygładzania to wygładzania +1, nazywane też wygładzaniem Laplace'a, zdefiniowane za pomocą następującego wzoru:
$$p_i = \frac{k_i+1}{T+m}.$$
W naszym przykładzie z urną prawdopodobieństwo wylosowania kuli czerwonej określimy na $\frac{3+1}{4+3} = \frac{4}{7}$, kuli żółtej — $\frac{1+1}{4+3}=2/7$, zielonej — $\frac{0+1}{4+3}=1/7$. Tym samym, kula zielona uzyskała niezerowe prawdopodobieństwo, żółta — nieco zyskała, zaś czerwona — straciła.
Własności wygładzania +1
Zauważmy, że większa liczba prób $m$, tym bardziej ufamy naszemu eksperymentowi (czy zbiorowi uczącemu) i tym bardziej zbliżamy się do niewygładzonej wartości:
$$\lim_{m \rightarrow \infty} \frac{k_i +1}{T + m} = \frac{k_i}{T}.$$
Inna dobra, zdroworozsądkowo, własność to to, że prawdopodobieństwo nigdy nie będzie zerowe:
$$\frac{k_i + 1}{T + m} > 0.$$
Wygładzanie w unigramowym modelu języku
Analogia do urny
Unigramowy model języka, abstrakcyjnie, dokładnie realizuje scenariusz losowania kul z urny: $m$ to liczba wszystkich wyrazów (czyli rozmiar słownika $|V|$), $k_i$ to ile razy w zbiorze uczącym pojawił się $i$-ty wyraz słownika, $T$ — długość zbioru uczącego.
A zatem przy użyciu wygładzania +1 w następujący sposób estymować będziemy prawdopodobieństwo słowa $w$:
$$P(w) = \frac{\# w + 1}{|C| + |V|}.$$
Wygładzanie $+\alpha$
W modelowaniu języka wygładzanie $+1$ daje zazwyczaj niepoprawne wyniki, dlatego częściej zamiast wartości 1 używa się współczynnika $0 < \alpha < 1$:
$$P(w) = \frac{\# w + \alpha}{|C| + \alpha|V|}.$$
W innych praktycznych zastosowaniach statystyki przyjmuje się $\alpha = \frac{1}{2}$, ale w przypadku n-gramowych modeli języka i to będzie zbyt duża wartość.
W jaki sposób ustalić wartość $\alpha$? Można $\alpha$ potraktować $\alpha$ jako hiperparametr i dostroić ją na odłożonym zbiorze.
Jak wybrać wygładzanie?
Jak ocenić, który sposób wygładzania jest lepszy? Jak wybrać $\alpha$ w czasie dostrajania?
Najprościej można sprawdzić estymowane prawdopodobieństwa na zbiorze strojącym (developerskim). Dla celów poglądowych bardziej czytelny będzie podział zbioru uczącego na dwie równe części — będziemy porównywać częstości estymowane na jednej połówce korpusu z rzeczywistymi, empirycznymi częstościami z drugiej połówki.
Wyniki będziemy przedstawiać w postaci tabeli, gdzie w poszczególnych wierszach będziemy opisywać częstości estymowane dla wszystkich wyrazów, które pojawiły się określoną liczbę razy w pierwszej połówce korpusu.
Ostatecznie możemy też po prostu policzyć perplexity na zbiorze testowym
Przykład
Użyjemy polskiej części z korpusu równoległego Open Subtitles:
wget -O en-pl.txt.zip 'https://opus.nlpl.eu/download.php?f=OpenSubtitles/v2018/moses/en-pl.txt.zip'
unzip en-pl.txt.zipUsuńmy duplikaty (zachowując kolejność):
nl OpenSubtitles.en-pl.pl | sort -k 2 -u | sort -k 1 | cut -f 2- > opensubtitles.pl.txtKorpus zawiera ponad 28 mln słów, zdania są krótkie, jest to język potoczny, czasami wulgarny.
$ wc opensubtitles.pl.txt
28154303 178866171 1206735898 opensubtitles.pl.txt
$ head -n 10 opensubtitles.pl.txt
Lubisz curry, prawda?
Nałożę ci więcej.
Hey!
Smakuje ci?
Hey, brzydalu.
Spójrz na nią.
- Wariatka.
- Zadałam ci pytanie!
No, tak lepiej!
- Wygląda dobrze!Podzielimy korpus na dwie części:
head -n 14077151 < opensubtitles.pl.txt > opensubtitlesA.pl.txt
tail -n 14077151 < opensubtitles.pl.txt > opensubtitlesB.pl.txtTokenizacja
Stwórzmy generator, który będzie wczytywał słowa z pliku, dodatkowo:
- ciągi znaków interpunkcyjnych będziemy traktować jak tokeny,
- sprowadzimy wszystkie litery do małych,
- dodamy specjalne tokeny na początek i koniec zdania (
<s>i</s>).
from itertools import islice
import regex as re
import sys
def get_words_from_file(file_name):
with open(file_name, 'r') as fh:
for line in fh:
line = line.rstrip()
yield '<s>'
for m in re.finditer(r'[\p{L}0-9\*]+|\p{P}+', line):
yield m.group(0).lower()
yield '</s>'
list(islice(get_words_from_file('opensubtitlesA.pl.txt'), 0, 100))['<s>', 'lubisz', 'curry', ',', 'prawda', '?', '</s>', '<s>', 'nałożę', 'ci', 'więcej', '.', '</s>', '<s>', 'hey', '!', '</s>', '<s>', 'smakuje', 'ci', '?', '</s>', '<s>', 'hey', ',', 'brzydalu', '.', '</s>', '<s>', 'spójrz', 'na', 'nią', '.', '</s>', '<s>', '-', 'wariatka', '.', '</s>', '<s>', '-', 'zadałam', 'ci', 'pytanie', '!', '</s>', '<s>', 'no', ',', 'tak', 'lepiej', '!', '</s>', '<s>', '-', 'wygląda', 'dobrze', '!', '</s>', '<s>', '-', 'tak', 'lepiej', '!', '</s>', '<s>', 'pasuje', 'jej', '.', '</s>', '<s>', '-', 'hey', '.', '</s>', '<s>', '-', 'co', 'do', '…?', '</s>', '<s>', 'co', 'do', 'cholery', 'robisz', '?', '</s>', '<s>', 'zejdź', 'mi', 'z', 'oczu', ',', 'zdziro', '.', '</s>', '<s>', 'przestań', 'dokuczać']
Empiryczne wyniki
Zobaczmy, ile razy, średnio w drugiej połówce korpusu występują wyrazy, które w pierwszej wystąpiły określoną liczbę razy.
from collections import Counter
counterA = Counter(get_words_from_file('opensubtitlesA.pl.txt'))counterA['taki']48113
max_r = 10
buckets = {}
for token in counterA:
buckets.setdefault(counterA[token], 0)
buckets[counterA[token]] += 1
bucket_counts = {}
counterB = Counter(get_words_from_file('opensubtitlesB.pl.txt'))
for token in counterB:
bucket_id = counterA[token] if token in counterA else 0
if bucket_id <= max_r:
bucket_counts.setdefault(bucket_id, 0)
bucket_counts[bucket_id] += counterB[token]
if bucket_id == 0:
buckets.setdefault(0, 0)
buckets[0] += 1
nb_of_types = [buckets[ix] for ix in range(0, max_r+1)]
empirical_counts = [bucket_counts[ix] / buckets[ix] for ix in range(0, max_r)]Policzmy teraz jakiej liczby wystąpień byśmy oczekiwali, gdyby użyć wygładzania +1 bądź +0.01. (Uwaga: zwracamy liczbę wystąpień, a nie względną częstość, stąd przemnażamy przez rozmiar całego korpusu).
def plus_alpha_smoothing(alpha, m, t, k):
return t*(k + alpha)/(t + alpha * m)
def plus_one_smoothing(m, t, k):
return plus_alpha_smoothing(1.0, m, t, k)
vocabulary_size = len(counterA)
corpus_size = counterA.total()
plus_one_counts = [plus_one_smoothing(vocabulary_size, corpus_size, ix) for ix in range(0, max_r)]
plus_alpha_counts = [plus_alpha_smoothing(0.01, vocabulary_size, corpus_size, ix) for ix in range(0, max_r)]
data = list(zip(nb_of_types, empirical_counts, plus_one_counts, plus_alpha_counts))
vocabulary_size926594
import pandas as pd
pd.DataFrame(data, columns=["liczba tokenów", "średnia częstość w części B", "estymacje +1", "estymacje +0.01"])liczba tokenów średnia częstość w części B estymacje +1 estymacje +0.01 0 388334 1.900495 0.993586 0.009999 1 403870 0.592770 1.987172 1.009935 2 117529 1.565809 2.980759 2.009870 3 62800 2.514268 3.974345 3.009806 4 40856 3.504944 4.967931 4.009741 5 29443 4.454098 5.961517 5.009677 6 22709 5.232023 6.955103 6.009612 7 18255 6.157929 7.948689 7.009548 8 15076 7.308039 8.942276 8.009483 9 12859 8.045649 9.935862 9.009418
Wygładzanie Gooda-Turinga
Inna metoda — wygładzanie Gooda-Turinga — polega na zliczaniu, ile $n$-gramów (na razie rozpatrujemy model unigramowy, więc po prostu pojedynczych wyrazów) wystąpiło zadaną liczbę razy. Niech $N_r$ oznacza właśnie, ile $n$-gramów wystąpiło dokładnie $r$ razy; na przykład $N_1$ oznacza liczbę hapax legomena.
W metodzie Gooda-Turinga używamy następującej estymacji:
$$p(w) = \frac{\# w + 1}{|C|}\frac{N_{r+1}}{N_r}.$$
Przykład
good_turing_counts = [(ix+1)*nb_of_types[ix+1]/nb_of_types[ix] for ix in range(0, max_r)]
data2 = list(zip(nb_of_types, empirical_counts, plus_one_counts, good_turing_counts))
pd.DataFrame(data2, columns=["liczba tokenów", "średnia częstość w części B", "estymacje +1", "Good-Turing"])liczba tokenów średnia częstość w części B estymacje +1 Good-Turing 0 388334 1.900495 0.993586 1.040007 1 403870 0.592770 1.987172 0.582014 2 117529 1.565809 2.980759 1.603009 3 62800 2.514268 3.974345 2.602293 4 40856 3.504944 4.967931 3.603265 5 29443 4.454098 5.961517 4.627721 6 22709 5.232023 6.955103 5.627064 7 18255 6.157929 7.948689 6.606847 8 15076 7.308039 8.942276 7.676506 9 12859 8.045649 9.935862 8.557431
Wygładzanie metodą Gooda-Turinga, mimo prostoty, daje wyniki zaskakująco zbliżone do rzeczywistych.
Wygładzanie dla $n$-gramów
Rzadkość danych
W wypadku bigramów, trigramów, tetragramów itd. jeszcze dotkliwy staje się problem rzadkości danych (data sparsity). Przestrzeń możliwych zdarzeń jest jeszcze większa ($|V|^2$ dla bigramów), więc estymacje stają się jeszcze mniej pewne.
Back-off
Dla $n$-gramów, gdzie $n>1$, nie jesteśmy ograniczeni do wygładzania $+1$, $+k$ czy Gooda-Turinga. W przypadku rzadkich $n$-gramów, w szczególności, gdy $n$-gram w ogóle się nie pojawił w korpusie, możemy „zejść” na poziom krótszych $n$-gramów. Na tym polega back-off.
Otóż jeśli $\# w_{i-n+1}\ldots w_{i-1} > 0$, wówczas estymujemy prawdopodobieństwa w tradycyjny sposób:
$$P_B(w_i|w_{i-n+1}\ldots w_{i-1}) = d_n(w_{i-n+1}\ldots w_{i-1}\ldots w_{i-1}) P(w_i|w_{i-n+1}\ldots w_{i-1})$$
W przeciwnym razie rozpatrujemy rekurencyjnie krótszy $n$-gram:
$$P_B(w_i|w_{i-n+1}\ldots w_{i-1}) = \delta_n(w_{i-n+1}\ldots w_{i-1}\ldots w_{i-1}) P_B(w_i|w_{i-n+2}\ldots w_{i-1}).$$
Technicznie, aby $P_B$ stanowiło rozkład prawdopodobieństwa, trzeba dobrać współczynniki $d$ i $\delta$.
Interpolacja
Alternatywą do metody back-off jest interpolacja — zawsze z pewnym współczynnikiem uwzględniamy prawdopodobieństwa dla krótszych $n$-gramów:
$$P_I(w_i|w_{i-n+1}\ldots w_{i-1}) = \lambda P(w_i|w_{i-n+1}\dots w_{i-1}) + (1-\lambda) P_I(w_i|w_{i-n+2}\dots w_{i-1}).$$
Na przykład, dla trigramów:
$$P_I(w_i|w_{i-2}w_{i-1}) = \lambda P_(w_i|w_{i-2}w_{i-1}) + (1-\lambda)(\lambda P(w_i|w_{i-1}) + (1-\lambda)P_I(w_i)).$$
Uwzględnianie różnorodności
Różnorodność kontynuacji
Zauważmy, że słowa mogą bardzo różnić się co do różnorodności kontynuacji. Na przykład po słowie szop spodziewamy się raczej tylko słowa pracz, każde inne, niewidziane w zbiorze uczącym, będzie zaskakujące. Dla porównania słowo seledynowy ma bardzo dużo możliwych kontynuacji i powinniśmy przeznaczyć znaczniejszą część masy prawdopodobieństwa na kontynuacje niewidziane w zbiorze uczącym.
Różnorodność kontynuacji bierze pod uwagę metoda wygładzania Wittena-Bella, będącą wersją interpolacji.
Wprowadźmy oznaczenie na liczbę możliwych kontynuacji $n-1$-gramu $w_1\ldots w_{n-1}$:
$$N_{1+}(w_1\ldots w_{n-1}\dot\bullet) = |\{w_n : \# w_1\ldots w_{n-1}w_n > 0\}|.$$
Teraz zastosujemy interpolację z następującą wartością parametru $1-\lambda$, sterującego wagą, jaką przypisujemy do krótszych $n$-gramów:
$$1 - \lambda = \frac{N_{1+}(w_1\ldots w_{n-1}\dot\bullet)}{N_{1+}(w_1\ldots w_{n-1}\dot\bullet) + \# w_1\ldots w_{n-1}}.$$
Wygładzanie Knesera-Neya
Zamiast brać pod uwagę różnorodność kontynuacji, możemy rozpatrywać różnorodność historii — w momencie liczenia prawdopodobieństwa dla unigramów dla interpolacji (nie ma to zastosowania dla modeli unigramowych). Na przykład dla wyrazu Jork spodziewamy się tylko bigramu Nowy Jork, a zatem przy interpolacji czy back-off prawdopodobieństwo unigramowe powinno być niskie.
Wprowadźmy oznaczenia na liczbę możliwych historii:
$$N_{1+}(\bullet w) = |\{w_j : \# w_jw > 0\}|$$.
W metodzie Knesera-Neya w następujący sposób estymujemy prawdopodobieństwo unigramu:
$$P(w) = \frac{N_{1+}(\bullet w)}{\sum_{w_j} N_{1+}(\bullet w_j)}.$$
def ngrams(iter, size):
ngram = []
for item in iter:
ngram.append(item)
if len(ngram) == size:
yield tuple(ngram)
ngram = ngram[1:]
list(ngrams("kotek", 3))[('k', 'o', 't'), ('o', 't', 'e'), ('t', 'e', 'k')]
histories = { }
for prev_token, token in ngrams(get_words_from_file('opensubtitlesA.pl.txt'), 2):
histories.setdefault(token, set())
histories[token].add(prev_token) len(histories['jork'])
len(histories['zielony'])
histories['jork']Narzędzia $n$-gramowego modelowania języka
Istnieje kilka narzędzie do modelowania, ze starszych warto wspomnieć pakiety SRILM i IRSTLM. Jest to oprogramowanie bogate w opcje, można wybierać różne opcje wygładzania.
Szczytowym osiągnięciem w zakresie $n$-gramowego modelowania języka jest wspomniany już KenLM. Ma on mniej opcji niż SRILM czy ISRLM, jest za to precyzyjnie zoptymalizowany zarówno jeśli chodzi jakość, jak i szybkość działania. KenLM implementuje nieco zmodyfikowane wygładzanie Knesera-Neya połączone z przycinaniem słownika n-gramów (wszystkie hapax legomena dla $n \geq 3$ są domyślnie usuwane).
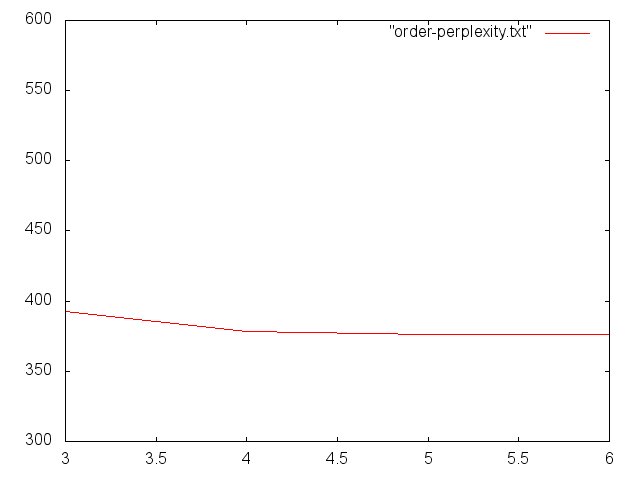
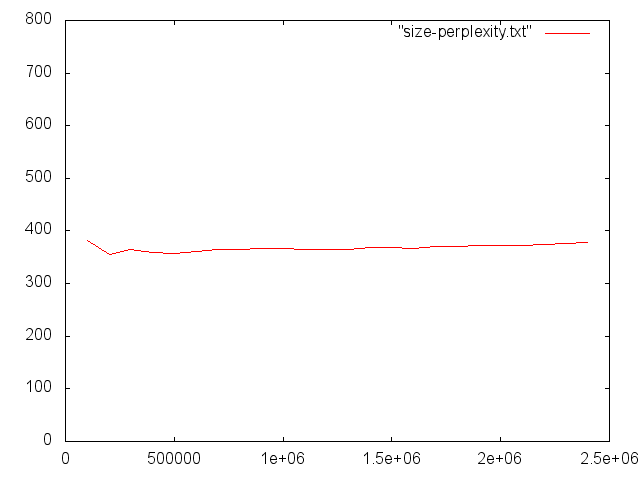
Przykładowe wyniki dla KenLM i korpusu Open Subtitles
Zmiana perplexity przy zwiększaniu zbioru testowego
Zmiana perplexity przy zwiększaniu zbioru uczącego
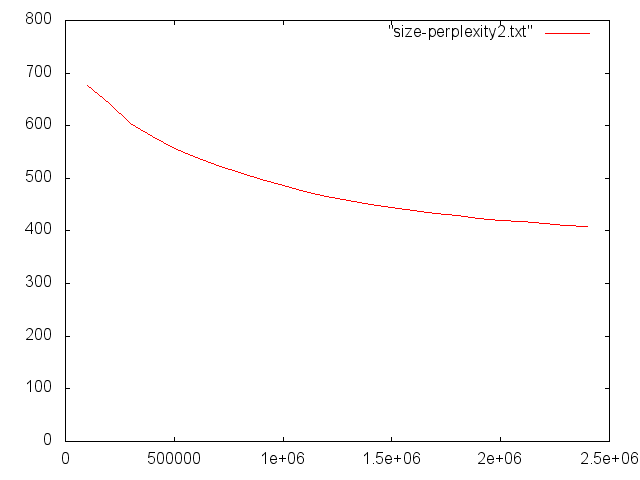
Zmiana perplexity przy zwiększaniu rządu modelu