10 KiB
Entropia
Entropia ($E$) to miara nieuporządkowania, niepewności, niewiedzy. Im większa entropia, tym mniej wiemy. Pojęcie to pierwotnie wywodzi się z termodynamiki, później znaleziono wiele zaskakujących analogii i zastosowań w innych dyscyplinach nauki.
Entropia w fizyce
W termodynamice entropia jest miarą nieuporządkowania układów fizycznych, na przykład pojemników z gazem. Przykładowo, wyobraźmy sobie dwa pojemniki z gazem, w którym panuje różne temperatury.

Jeśli usuniemy przegrodę między pojemnikami, temperatura się wyrówna, a uporządkowanie się zmniejszy.

Innymi słowy, zwiększy się stopień nieuporządkowania układu, czyli właśnie entropia.
II prawo termodynamiki
Jedno z najbardziej fundamentalnych praw fizyki, II prawo termodynamiki głosi, że w układzie zamkniętym entropia nie spada.
Pytanie: Czy to, że napisałem te materiały do wykładu i uporządkowałem wiedzę odnośnie do statystycznych własności języka, nie jest sprzeczne z II prawem termodynamiki?
Konsekwencją II prawa termodynamiki jest śmierć cieplna Wszechświata (zob. [wizualizacja przyszłości Wszechświata](https://www.youtube.com/watch?v=uD4izuDMUQA)).
Entropia w teorii informacji
Pojęcie entropii zostało „odkryte” na nowo przez Claude'a Shannona, gdy wypracował ogólną teorię informacji.
Teoria informacji zajmuje się między innymi zagadnieniem optymalnego kodowania komunikatów.
Wyobraźmy sobie pewne źródło (generator) losowych komunikatów z zamkniętego zbioru symboli ($\Sigma$; nieprzypadkowo używamy oznaczeń z poprzedniego wykładu). Nadawca $N$ chce przesłać komunikat o wyniku losowania do odbiorcy $O$ używając zer i jedynek (bitów). Teorioinformacyjną entropię można zdefiniować jako średnią liczbę bitów wymaganych do przesłania komunikatu.

Obliczanie entropii — proste przykłady
Załóżmy, że nadawca chce przekazać odbiorcy informację o wyniku rzutu monetą. Entropia wynosi wówczas rzecz jasna 1 — na jedno losowanie wystarczy jeden bit (informację o tym, że wypadł orzeł, możemy zakodować na przykład za pomocą zera, zaś to, że wypadła reszka — za pomocą jedynki).
Rozpatrzmy przypadek, gdy nadawca rzuca ośmiościenną kością. Aby przekazać wynik, potrzebuje wówczas 3 bity (a więc entropia ośmiościennej kości wynosi 3 bity). Przykładowe kodowanie może mieć następującą postać:
| Wynik | Kodowanie |
|---|---|
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 000 |
Obliczenie entropii — trudniejszy przykład
Załóżmy, że $\Sigma = \{A, B, C, D\}$, natomiast poszczególne komunikaty są losowane zgodnie z następującym rozkładem prawdopodobieństwa: $P(A)=1/2$, $P(B)=1/4$, $P(C)=1/8$, $P(D)=1/8$. Ile wynosi entropia w takim przypadku? Można by sądzić, że 2, skoro wystarczą 2 bity do przekazania wyniku losowania przy zastosowaniu następującego kodowania:
| Wynik | Kodowanie |
|---|---|
| A | 00 |
| B | 01 |
| C | 10 |
| D | 11 |
Problem w tym, że w rzeczywistości nie jest to optymalne kodowanie. Możemy sprytnie zmniejszyć średnią liczbę bitów wymaganych do przekazania losowego wyniku przypisując częstszym wynikom krótsze kody, rzadszym zaś — dłuższe. Oto takie optymalne kodowanie:
| Wynik | Kodowanie |
|---|---|
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
Używając takiego kodowanie średnio potrzebujemy:
$$\frac{1}{2}1 + \frac{1}{4}2 + \frac{1}{8}3 + \frac{1}{8}3 = 1,75$$
bita. Innymi słowy, entropia takiego źródła wynosi 1,75 bita.
Kodowanie musi być jednoznaczne!
Można by sądzić, że da się stworzyć jeszcze krótsze kodowanie dla omawianego rozkładu nierównomiernego:
| Wynik | Kodowanie |
|---|---|
| A | 0 |
| B | 1 |
| C | 01 |
| D | 11 |
Niestety, nie jest to właściwe rozwiązanie — kodowanie musi być jednoznaczne nie tylko dla pojedynczego komunikatu, lecz dla całej sekwencji. Na przykład ciąg 0111 nie jest jednoznaczny przy tym kodowaniu (ABBB czy CD?). Podane wcześniej kodowanie spełnia warunek jednoznaczności, ciąg 0111 można odkodować tylko jako AD.
Ogólny wzór na entropię.
Na podstawie poprzedniego przykładu można dojść do intuicyjnego wniosku, że optymalny kod dla wyniku o prawdopodobieństwie $p$ ma długość $-\log_2(p)$, a zatem ogólnie entropia źródła o rozkładzie prawdopodobieństwa $\{p_1,\ldots,p_|\Sigma|\}$ wynosi:
$$E = -\sum_{i=1}^{|\Sigma|} p_i\log_2(p_i)$$.
Zauważmy, że jest to jeden z nielicznych przypadków, gdy w nauce naturalną podstawą logarytmu jest 2 zamiast… podstawy logarytmu naturalnego ($e$).
Teoretycznie można mierzyć entropię używając logarytmu naturalnego ($\ln$), jednostką entropii będzie wówczas nat zamiast bita, niewiele to jednak zmienia i jest mniej poręczne i trudniejsze do interpretacji (przynajmniej w kontekście informatyki) niż operowanie na bitach.
Pytanie Ile wynosi entropia zwykłej sześciennej kostki? Jak wygląda optymalne kodowanie wyników rzutu taką kostką?
Entropia dla próby Bernoulliego
Wiemy już, że entropia dla rzutu monetą wynosi 1 bit. A jaki będzie wynik dla źle wyważonej monety?
import matplotlib.pyplot as plt
from math import log
import numpy as np
def binomial_entropy(p):
return -(p * log(p, 2) + (1-p) * log(1-p, 2))
x = list(np.arange(0.001,1,0.001))
y = [binomial_entropy(x) for x in x]
plt.figure().clear()
plt.xlabel('prawdopodobieństwo wylosowania orła')
plt.ylabel('entropia')
plt.plot(x, y)
fname = f'03_Entropia/binomial-entropy.png'
plt.savefig(fname)
fname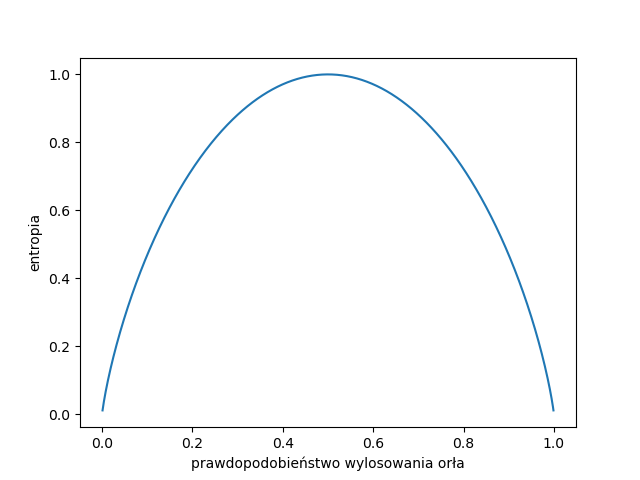
Pytanie Dla oszukańczej monety (np. dla której wypada zawsze orzeł) entropia wynosi 0, czy to wynik zgodny z intuicją?
Entropia a język
Tekst w danym języku możemy traktować jako ciąg symboli (komunikatów) losowanych według jakiegoś rozkładu prawdopodobieństwa. W tym sensie możemy mówić o entropii języka.
Oczywiście, jak zawsze, musimy jasno stwierdzić, czym są symbole języka: literami, wyrazami czy jeszcze jakimiś innymi jednostkami.
Pomiar entropii języka — pierwsze przybliżenie
Załóżmy, że chcemy zmierzyć entropię języka polskiego na przykładzie „Pana Tadeusza” — na poziomie znaków. W pierwszym przybliżeniu można by policzyć liczbę wszystkich znaków…
chars_in_pan_tadeusz = len(set(get_characters(pan_tadeusz)))
chars_in_pan_tadeusz95
… założyć jednostajny rozkład prawdopodobieństwa i w ten sposób policzyć entropię:
from math import log
95 * (1/95) * log(95, 2)6.569855608330948
Mniej rozrzutne kodowanie
Przypomnijmy sobie jednak, że rozkład jednostek języka jest zawsze skrajnie nierównomierny! Jeśli uwzględnić ten nierównomierny rozkład znaków, można opracować o wiele efektywniejszy sposób zakodowania znaków składających się na „Pana Tadeusza” (częste litery, np. „a” i „e” powinny mieć krótkie kody, a rzadkie, np. „ź” — dłuższe).
Policzmy entropię przy takim założeniu:
from collections import Counter
from math import log
def unigram_entropy(t):
counter = Counter(t)
total = counter.total()
return -sum((p := count / total) * log(p, 2) for count in counter.values())
unigram_entropy(get_characters(pan_tadeusz))4.938605272823633
(Jak dowiemy się na kolejnym wykładzie, zastosowaliśmy tutaj unigramowy model języka).
Ile wynosi entropia rękopisu Wojnicza?
unigram_entropy(get_characters(voynich))3.902708104423842
Rzeczywista entropia?
W rzeczywistości entropia jest jeszcze mniejsza, tekst nie jest generowany przecież według rozkładu wielomianowego. Istnieją rzecz jasna pewne zależności między znakami, np. niemożliwe, żeby po „ń” wystąpiły litera „a” czy „e”. Na poziomie wyrazów zależności mogę mieć jeszcze bardziej skrajny charakter, np. po wyrazie „przede” prawie na pewno wystąpi „wszystkim”, co oznacza, że w takiej sytuacji słowo „wszystkim” może zostać zakodowane za pomocą 0 (!) bitów.
Można uwzględnić takie zależności i uzyskać jeszcze lepsze kodowanie, a co za tym idzie lepsze oszacowanie entropii. (Jak wkrótce się dowiemy, oznacza to użycie digramowego, trigramowego, etc. modelu języka).
Rozmiar skompresowanego pliku jako przybliżenie entropii
Celem algorytmów kompresji jest właściwie wyznaczanie efektywnych sposobów kodowania danych. Możemy więc użyć rozmiaru skompresowanego pliku w bitach (po podzieleniu przez oryginalną długość) jako dobrego przybliżenia entropii.
import zlib
def entropy_by_compression(t):
compressed = zlib.compress(t.encode('utf-8'))
return 8 * len(compressed) / len(t)
entropy_by_compression(pan_tadeusz)3.673019884633768
Dla porównania wynik dla rękopisu Wojnicza:
entropy_by_compression(voynich)2.942372881355932
Gra Shannona
Innym sposobem oszacowania entropii tekstu jest użycie… ludzi. Można poprosić rodzimych użytkowników danego języka o przewidywanie kolejnych liter (bądź wyrazów) i w ten sposób oszacować entropię.
Projekt Zaimplementuj aplikację webową, która umożliwi „rozegranie” gry Shannona.