14 KiB
- Atencja
Atencja
Sieci LSTM w roku 2017/2018 zostały wyparte przez nową, pod pewnymi względami prostszą, architekturę Transformer. Sieci Transformer oparte są zasadniczo na prostej idei atencji (attention), pierwszy artykuł wprowadzający sieci Transformer nosił nawet tytuł [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
Intuicyjnie, atencja jest rodzajem uwagi, którą sieć może selektywnie kierować na wybrane miejsca (w modelowaniu języka: wybrane wyrazy).
Idea atencji jest jednak wcześniejsza, powstała jako ulepszenie sieci rekurencyjnych. My omówimy ją jednak na jeszcze prostszym przykładzie użycia w modelowaniu języka za pomocą hybrydy modelu bigramowego i modelu worka słów.
Prosty przykład zastosowania atencji
Wróćmy do naszego przykładu z Wykładu 8, w którym łączyliśmy $n$-gramowy model języka z workiem słów. Przyjmijmy bigramowy model języka ($n=2$), wówczas:
$$y = \operatorname{softmax}(C[E(w_{i-1}),A(w_1,\dots,w_{i-2})]),$$
gdzie $A$ była prostą agregacją (np. sumą albo średnią) embeddingów $E(w_1),\dots,E(w_{i-2})$. Aby wyjść z nieuporządkowanego modelu worka słów, próbowaliśmy w prosty sposób uwzględnić pozycję wyrazów czy ich istotność (za pomocą odwrotnej częstości dokumentowej). Oba te sposoby niestety zupełnie nie uwzględniają kontekstu.
Innymi słowy, chcielibyśmy mieć sumę ważoną zanurzeń:
$$A(w_1,\dots,j) = \omega_1 E(w_1) + \dots + \omega_j E(w_j) = \sum_{k=1}^j \omega_k E(w_k),$$
tak by $\omega_k$ w sposób bardziej zasadniczy zależały od lokalnego kontekstu, a nie tylko od pozycji $k$ czy słowa $w_k$. W naszym uproszczonym przypadku jako kontekst możemy rozpatrywać słowo bezpośrednio poprzedzające odgadywane słowa (kontekstem jest $w_{i-1}$).
Wygodnie również przyjąć, że $\sum_{k=1}^j \omega_k = 1$, wówczas mamy do czynienia ze średnią ważoną.
Nieznormalizowane wagi atencji
Będziemy liczyć nieznormalizowane wagi atencji $\hat{\alpha}_{k,j}$. Określają one, jak bardzo słowo $w_j$ „zwraca uwagę” na poszczególne, inne słowa. Innymi słowy, wagi opisują, jak bardzo słowo $w_k$ pasuje do naszego kontekstu, czyli słowa $w_j$.
Najprostszy sposób mierzenia dopasowania to po prostu iloczyn skalarny:
$$\hat{\alpha}_{k,j} = E(w_k)E(w_j),$$
można też alternatywnie złamać symetrię iloczynu skalarnego i wyliczać dopasowanie za pomocą prostej sieci feed-forward:
$$\hat{\alpha}_{k,j} = \vec{v}\operatorname{tanh}(W_{\alpha}[E(w_k),E(w_j)] + \vec{b_{\alpha}}).$$
W drugim przypadku pojawiają się dodatkowe wyuczalne paramatery: macierz $W_{\alpha}$, wektory $\vec{b_{\alpha}}$ i $\vec{v}$.
Normalizacja wag atencji
Jak już wspomniano, dobrze żeby wagi atencji sumowały się do 1. W tym celu możemy po prostu zastosować funkcję softmax:
$$\alpha_{k,j} = \operatorname{softmax}([\hat{\alpha}_{1,j},\dots,\hat{\alpha}_{j-1,j}]).$$
Zauważmy jednak, że otrzymanego z funkcji softmax wektora $[\alpha_{1,j},\dots,\alpha_{j-1,j}]$ tym razem nie interpretujemy jako rozkład prawdopodobieństwa. Jest to raczej rozkład uwagi, atencji słowa $w_j$ względem innych słów.
Użycie wag atencji w prostym neuronowym modelu języka
Teraz jako wagi $\omega$ w naszym modelu języka możemy przyjąć:
$$\omega_k = \alpha_{k,i-1}.$$
Oznacza to, że z naszego worka będziemy „wyjmowali” słowa w sposób selektywny, w zależności od wyrazu, który bezpośrednio poprzedza słowo odgadywane.
Diagram
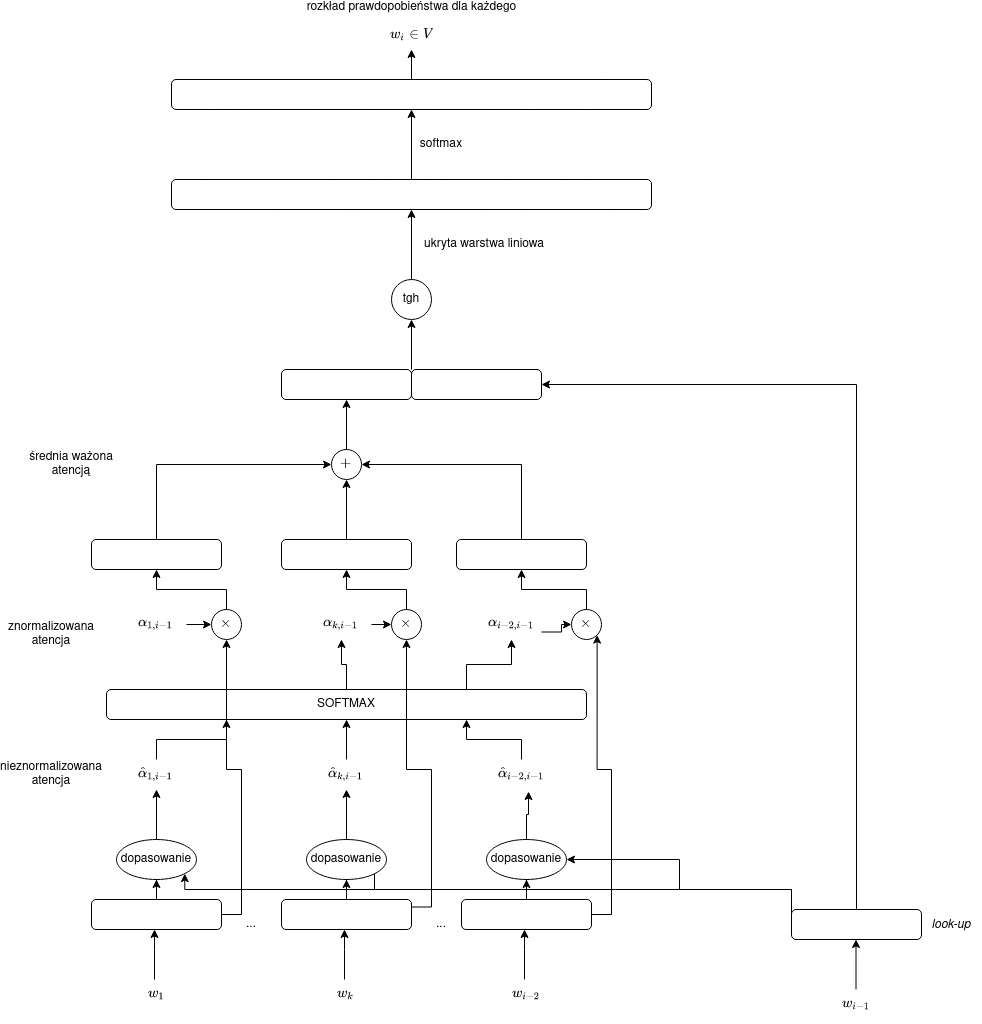
Atencja jako „miękka” baza danych
O atencji można myśleć metaforycznie jako o odpytywaniu „miękkiej”, wektorowej bazy danych. Możemy sobie wyobrazić, że słowa $w_1,\dots,w_{j-1}$ są naszą bazą danych, a słowo $w_j$ (z którego kierujemy „snop” uwagi) jest zapytaniem (query). To zapytanie dopasowujemy do kluczy (keys), w najprostszym ujęciu po prostu słów $w_1,\dots,w_{j-1}$ (a właściwie ich zanurzeń). Jeśli klucz pasuje do zapytania, odpowiednia wartość (value) jest wydobywana z bazy. Nasza baza jest jednak „miękka”, nie — zerojedynkowa, zapytanie pasuje klucza w pewnym stopniu, mniej lub bardziej.
W najprostszym ujęciu wartości są tym samym co klucze, czyli z naszej bazy wydobywamy te same zanurzenia słów, których używamy jako kluczy. Można jednak skomplikować schemat rozróżniając klucze i wartości — mogą one powstawać przez rzutowanie podstawowe zanurzenia różnymi macierzami:
$$\vec{k_i} = W_k E(w_i),$$
$$\vec{v_i} = W_v E(w_i).$$
Również samo zapytanie może powstać przez rzutowanie:
$$\vec{q_i} = W_q E(w_i).$$
Jeśli zanurzenie $E(w_i)$ o rozmiarze $m$ przedstawimy w postaci kolumnowej, wówczas macierze będą $W_k$ i $W_q$ będą miały rozmiar $d_k \times m$, gdzie $d_k$ jest rozmiarem kluczy i zapytań (dlaczego wektory kluczy i zapytań powinny mieć raczej ten sam rozmiar?), zaś macierz $W_v$ — $d_v \times m$, gdzie $d_v$ to rozmiar zanurzenia wektora wartości. Zazwyczaj $d_k = d_v = m$, ale nie jest to obligatoryjne.
Teraz nieznormalizowane wagi atencji przyjmą postać:
$$\hat{\alpha}_{i,j} = \vec{q_i}^T\vec{k_j} = (W_q E(w_i))(W_k E(k_j)).$$
Zauważmy, że ciąg $\hat{\alpha}_{1,j},\dots,\hat{\alpha}_{j-1,j}$ można potraktować jako wektor $\hat{\vec{\alpha}_{*,j}}$ i wyliczać w postaci zwartej:
$$\hat{\vec{\alpha}_{*,j}} = \vec{k_j}^T K$$
gdzie $K$ to macierz kluczy złożona z wektorów $\vec{k_1},\dots,\vec{k_{j-1}}$, tj. macierz o rozmiarze $d_k \times (j-1)$.
Wektor znormalizowanych wag atencji będzie miał wówczas postać:
$$\vec{\alpha}_{*,j} = \operatorname{softmax}(\vec{k_j}^T K).$$
Dokonajmy teraz agregacji wartości — obliczeniamy średnią wektorów wartości (\vec{v_i}) ważoną atencją:
$$A(w_1,\dots,j-1) = \alpha_{1,j} \vec{v_1} + \dots + \alpha_{j-1,j} \vec{v_{j-1}} = \sum_{i=1}^{j-1} \alpha_{i,j} v_i.$$
Jeśli $j-1$ wektorów wartości ułożyłem w macierz $V$ (o rozmiarze $(j-1) \times d_v$), powyższy wzór będziemy mogli zapisać jako iloczyn wektora wag atencji i macierzy $V$:
$$A(w_1,\dots,j-1) = \vec{\alpha}_{*,j}^T V = \operatorname{softmax}(\vec{k_j}^T K)^T V.$$
Sposób patrzenia na atencję przez pryzmat trójki zapytania-klucze-wartości okaże się niezwykle ważny w wypadku modelu Transformer (zob. kolejny wykład).
Atencja jako składnik sieci rekurencyjnej
Atencję wprowadzono pierwotnie jako uzupełnienie sieci rekurencyjnej. Potrzeba ta pojawiła się na początku rozwoju neuronowego tłumaczenia maszynowego (neural machine translation, NMT), czyli tłumaczenia maszynowego (automatycznego) realizowanego za pomocą sieci neuronowych.
Neuronowe tłumaczenie maszynowe jest właściwie rozszerzeniem idei modelowania języka na biteksty (teksty równoległe). Omówmy najpierw podstawy generowania tekstu.
Model języka jako generator
Jak pamiętamy, model języka $M$ wylicza prawdopodobieństwo tekstu $w_1,\dots,w_N$:
$$P_M(w_1,\dots,w_N) = ?.$$
Zazwyczaj jest to równoważne obliczaniu rozkładu prawdopodobieństwa kolejnego słowa:
$$P_M(w_j|w_1,\dots,w_{j-1}) = ?.$$
Załóżmy, że mamy pewien początek (prefiks) tekstu o długości $p$: $w_1,\dots,w_p$. Powiedzmy, że naszym celem jest wygenerowanie dokończenia czy kontynuacji tego tekstu (nie określamy z góry tej długości tej kontynuacji).
Najprostszy sposób wygenerowania pierwszego wyrazu dokończenia polega na wzięciu wyrazu maksymalizującego prawdopodobieństwo według modelu języka:
$$w_{p+1} = \operatorname{argmax}_w P_M(w|w_1,\dots,w_p).$$
Pytanie: Dlaczego \operatorname{argmax}, a nie \operatorname{max}?
Słowo $w_{p+1}$ możemy dołączyć do prefiksu i powtórzyć procedurę:
$$w_{p+2} = \operatorname{argmax}_w P_M(w|w_1,\dots,w_p,w_{p+1}),$$
i tak dalej.
Pytanie: Kiedy zakończymy procedurę generowania?
Omawiana procedura jest najprostszym sposobem, czasami nie daje najlepszego wyniku, na przykład może pojawić się efekt „jąkania” (model generuje w kółko ten sam wyraz), dlatego opracowano bardziej wymyślne sposoby generowania w oparciu o modele języka. Omówimy je później.
Zastosowania generatora opartego na modelu języka
Mogłoby się wydawać, że generator tekstu ma raczej ograniczone zastosowanie (generowanie fake newsów?). Okazuje się jednak, że zaskakująco wiele zadań przetwarzania języka naturalnego można przedstawić jako zadanie generowania tekstu. Przykładem jest tłumaczenie maszynowe.
Tłumaczenie maszynowe jako zadanie generowania tekstu
W tłumaczeniu maszynowym (tłumaczeniu automatycznym, ang. machine translation) na wejściu podawany jest tekst (na ogół pojedyncze zdanie) źródłowy (source sentence) $S = (u_1,\dots,u_|S|)$, celem jest uzyskanie tekstu docelowego (target sentence) $T=(w_1,\dots,w_|T|). Zakładamy, że $S$ jest tekstem w pewnym języku źródłowym (/source language/), zaś $T$ — w innym języku, języku docelowym (target language).
Współczesne tłumaczenie maszynowe jest oparte na metodach statystycznych — system uczy się na podstawie obszernego zbioru odpowiadających sobie zdań w obu językach. Taki zbiór nazywamy korpusem równoległym (parallel corpus). Duży zbiór korpusów równoległych dla wielu języków można znaleźć na stronie projektu [OPUS](https://opus.nlpl.eu/). Zobaczmy na przykład fragment EUROPARL (protokoły Parlamentu Europejskiego):
$ wget 'https://opus.nlpl.eu/download.php?f=Europarl/v8/moses/en-pl.txt.zip' -O en-pl.txt.zip
$ unzip en-pl.txt.zip
$ paste Europarl.en-pl.en Europarl.en-pl.pl | shuf -n 5
The adoption of these amendments by the Committee on the Environment meant that we could place more emphasis on patients' rights to information, rather than make it an option for the pharmaceutical industries to provide that information. Przyjęcie tych poprawek przez Komisję Ochrony Środowiska Naturalnego oznaczało, że mogliśmy położyć większy nacisk na prawo pacjentów do informacji, zamiast uczynić zeń możliwość, z której branża farmaceutyczna może skorzystać w celu dostarczenia informacji.
I hope that the High Representative - who is not here today - will raise this episode with China and also with Nepal, whose own nascent democracy is kept afloat partly by EU taxpayers' money in the form of financial aid. Mam nadzieję, że nieobecna dzisiaj wysoka przedstawiciel poruszy tę kwestię w rozmowach z Chinami, ale również z Nepalem, którego młoda demokracja funkcjonuje częściowo dzięki finansowej pomocy pochodzącej z pieniędzy podatników w UE.
Immunity and privileges of Renato Brunetta (vote) Wniosek o obronę immunitetu parlamentarnego Renata Brunetty (głosowanie)
The 'new Member States' - actually, the name continues to be sort of conditional, making it easier to distinguish between the 'old' Member States and those that acceded to the EU after two enlargement rounds, owing to their particular historical background and perhaps the fact that they are poorer than the old ones."Nowe państwa członkowskie” - ta nazwa nadal ma w pewnym sensie charakter warunkowy i ułatwia rozróżnienie pomiędzy "starszymi” państwami członkowskimi oraz tymi, które przystąpiły do UE po dwóch rundach rozszerzenia, które wyróżnia ich szczególna historia, a zapewne także fakt, że są uboższe, niż starsze państwa członkowskie.
The number of armed attacks also rose by 200% overall. Także liczba ataków zbrojnych wzrosła łącznie o 200 %.Zauważmy, że możemy taki tekst modelować po prostu traktując jako jeden. Innymi słowy, nie modelujemy tekstu angielskiego ani polskiego, tylko angielsko-polską mieszankę, to znaczy uczymy model, który najpierw modeluje prawdopodobieństwo po stronie źródłowej (powiedzmy — angielskiej):
The number of armed attacks also ?
W momencie napotkania specjalnego tokenu końca zdania źródłowego (powiedzmy <eoss>) model
powinien nauczyć się, że musi przerzucić się na modelowanie tekstu w języku docelowym (powiedzmy — polskim):
The number of armed attacks also rose by 200% overall.<eoss>Także liczba ataków ?W czasie uczenia wykorzystujemy korpus równoległy traktując go po prostu jako zwykły ciągły tekst (dodajemy tylko specjalne tokeny końca zdania źródłowego i końca zdania docelowego).
W fazie inferencji (w tłumaczeniu maszynowym tradycyjnie nazywaną
dekodowaniem) zamieniamy nasz model języka w generator i podajemy
tłumaczone zdanie jako prefiks, doklejając tylko token <eoss>.
Neuronowe modele języka jako translatory
Jako że N-gramowego modelu języka ani modelu opartego na worku słów nie da się użyć w omawiany sposób w tłumaczeniu maszynowym (dlaczego?), jako pierwszych użyto w neuronowym tłumaczeniu maszynowym sieci LSTM, przy użyciu omawianego wyżej sposobu.
System tłumaczenia oparte na sieciach LSTM działały zaskakująco
dobrze, zważywszy na to, że cała informacja o zdaniu źródłowym musi
zostać skompresowana do wektora o stałym rozmiarze. (Dlaczego? W
momencie osiągnięcia tokenu <eoss> cały stan sieci to kombinacja
właściwego stanu $\vec{s_i}$ i komórki pamięci $\vec{c_i}$.)
Neuronowe tłumaczenie oparte na sieciach LSTM działa względnie dobrze dla krótkich zdań, dla dłuższych rezultaty są gorsze — po prostu sieć nie jest w stanie skompresować w wektorze o stałej długości znaczenia całego zdania. Na początku rozwoju neuronowego tłumaczenia maszynowego opracowano kilka metod radzenia sobie z tym problemem (np. zaskakująco dobrze działa odwrócenie zdania źródłowego — siec LSTM łatwiej zacząć generować zdanie docelowe, jeśli niedawno „widziała” początek zdania źródłowego, przynajmniej dla pary języków o podobnym szyku).
Najlepsze efekty dodało dodanie atencji do modelu LSTM
Atencja w sieciach rekurencyjnych
Funkcję rekurencyjną można rozbudować o trzeci argument, w którym podany będzie wynik działania atencji $A'$ względem ostatniego wyrazu, tj.:
$$A(w_1,\dots,w_t) = R(A(w_1,\dots,w_{t-1}), A'(w_1,\dots,w_{t-1}), E(w_t)),$$
W czasie tłumaczenia model może kierować swoją uwagę na wyrazy powiązane z aktualnie tłumaczonym fragmentem (zazwyczaj — po prostu odpowiedniki).