6.5 KiB
Podobieństwo słów
Słabości $n$-gramowych modeli języka
Podstawowa słabość $n$-gramowych modeli języka polega na tym, że każde słowo jest traktowane w izolacji. W, powiedzmy, bigramowym modelu języka każda wartość $P(w_2|w_1)$ jest estymowana osobno, nawet dla — w jakimś sensie podobnych słów. Na przykład:
- $P(\mathit{zaszczekał}|\mathit{pies})$, $P(\mathit{zaszczekał}|\mathit{jamnik})$, $P(\mathit{zaszczekał}|\mathit{wilczur})$ są estymowane osobno,
- $P(\mathit{zaszczekał}|\mathit{pies})$, $P(\mathit{zamerdał}|\mathit{pies})$, $P(\mathit{ugryzł}|\mathit{pies})$ są estymowane osobno,
- dla każdej pary $u$, $v$, gdzie $u$ jest przyimkiem (np. dla), a $v$ — osobową formą czasownika (np. napisał) model musi się uczyć, że $P(v|u)$ powinno mieć bardzo niską wartość.
Podobieństwo słów jako sposób na słabości $n$-gramowych modeli języka?
Intuicyjnie wydaje się, że potrzebujemy jakiegoś sposobu określania podobieństwa słów, tak aby w naturalny sposób, jeśli słowa $u$ i $u'$ oraz $v$ i $v'$ są bardzo podobne, wówczas $P(u|v) \approx P(u'|v')$.
Można wskazać trzy sposoby określania podobieństwa słów: odległość edycyjna Lewensztajna, hierarchie słów i odległość w przestrzeni wielowymiarowej.
Odległość Lewensztejna
Słowo dom ma coś wspólnego z domem, domkiem, domostwem, domownikami, domowym i udomowieniem (?? — tu już można mieć wątpliwości). Więc może oprzeć podobieństwa na powierzchownym podobieństwie?
Możemy zastosować tutaj odległość Lewensztejna, czyli minimalną liczbę operacji edycyjnych, które są potrzebne, aby przekształcić jedno słowo w drugie. Zazwyczaj jako elementarne operacje edycyjne definiuje się:
- usunięcie znaku,
- dodanie znaku,
- zamianu znaku.
Na przykład odległość edycyjna między słowami domkiem i domostwem wynosi 4: zamiana k na o, i na s, dodanie t, dodanie w.
import Levenshtein
Levenshtein.distance('domkiem', 'domostwem')4
Niestety, to nie jest tak, że słowa są podobne wtedy i tylko wtedy, gdy wyglądają podobnie:
- tapet nie ma nic wspólnego z tapetą,
- słowo sowa nie wygląda jak ptak, puszczyk, jastrząb, kura itd.
Powierzchowne podobieństwo słów łączy się zazwyczaj z relacjami fleksyjnymi i słowotwórczymi (choć też nie zawsze, por. np. pary słów będące przykładem supletywizmu: człowiek-ludzie, brać-zwiąć, rok-lata). A co z innymi własnościami wyrazów czy raczej bytów przez nie denotowanych (słowa oznaczające zwierzęta należące do gromady ptaków chcemy traktować jako, w jakiejś mierze przynajmnie, podobne)?
Dodajmy jeszcze, że w miejsce odległości Lewensztejna warto czasami używać podobieństwa Jaro-Winklera, które mniejszą wagę przywiązuje do zmian w końcówkach wyrazów:
import Levenshtein
Levenshtein.jaro_winkler('domu', 'domowy')
Levenshtein.jaro_winkler('domowy', 'maskowy')0.6626984126984127
Klasy i hierarchie słów
Innym sposobem określania podobieństwa między słowami jest zdefiniowanie klas słów. Słowa należące do jednej klasy będą podobne, do różnych klas — niepodobne.
Klasy gramatyczne
Klasy mogą odpowiadać standardowym kategoriom gramatycznym znanym z językoznawstwa, na przykład częściom mowy (rzeczownik, przymiotnik, czasownik itd.). Wiele jest niejednoznacznych jeśli chodzi o kategorię części mowy:
- powieść — rzeczownik czy czasownik?
- komputerowi — rzeczownik czy przymiotnik?
- lecz — spójnik, czasownik (!) czy rzeczownik (!!)?
Oznacza to, że musimy dysponować narzędziem, które pozwala automatycznie, na podstawie kontekstu, tagować tekst częściami mowy (ang. POS tagger). Takie narzędzia pozwalają na osiągnięcie wysokiej dokładności, niestety zawsze wprowadzają jakieś błędy, które mogą propagować się dalej.
Klasy indukowane automatycznie
Zamiast z góry zakładać klasy wyrazów można zastosować metody uczenia nienadzorowanego (podobne do analizy skupień) w celu wyindukowanie automatycznie klas (tagów) z korpusu.
Użycie klas słów w modelu języka
Najprostszy sposób uwzględnienia klas słów w $n$-gramowym modelowaniu języka polega stworzeniu dwóch osobnych modeli:
- tradycyjnego modelu języka $M_W$ operującego na słowach,
- modelu języka $M_T$ wyuczonego na klasach słów (czy to częściach mowy, czy klasach wyindukowanych automatycznie).
Zauważmy, że rząd modelu $M_T$ ($n_T$) może dużo większy niż rząd modelu $M_W$ ($n_W$) — klas będzie dużo mniej niż wyrazów, więc problem rzadkości danych jest dużo mniejszy i można rozpatrywać dłuższe $n$-gramy.
Dwa modele możemy połączyć za pomocą prostej kombinacji liniowej sterowanej hiperparametrem $\lambda$:
$$P(w_i|w_{i-n_T}+1\ldots w_{i-1}) = \lambda P_{M_T}(w_i|w_{i-n_W}+1\ldots w_{i-1}) + (1 - \lambda) P_{M_W}(w_i|w_{i-n_T}+1\ldots w_{i-1}).$$
Hierarchie słów
Zamiast płaskiej klasyfikacji słów można zbudować hierarchię słów czy pojęć. Taka hierarchia może dotyczyć właściwości gramatycznych (na przykład rzeczownik w liczbie pojedynczej w dopełniaczu będzie podklasą rzeczownika) lub własności denotowanych bytów.
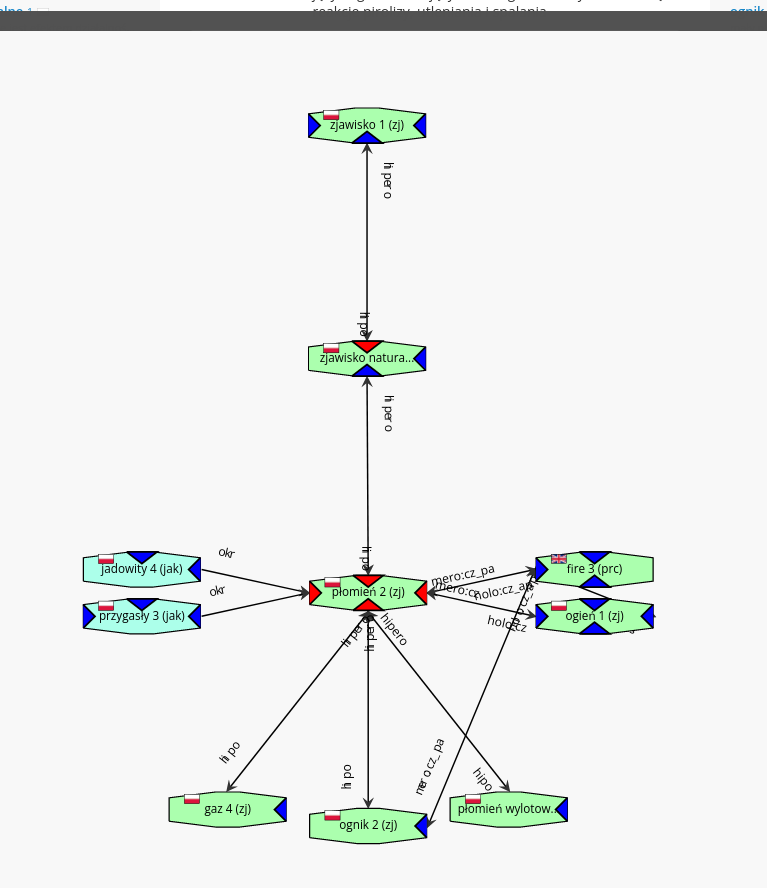
Niekiedy dość łatwo stworzyć hierarchie (taksonomię) pojęć. Na przykład jamnik jest rodzajem psa (słowo jamnik jest hiponimem słowa pies, zaś słowo pies hiperonimem słowa jamnik), pies — ssaka, ssak — zwierzęcia, zwierzę — organizmu żywego, organizm — bytu materialnego.
Analityczny język Johna Wilkinsa
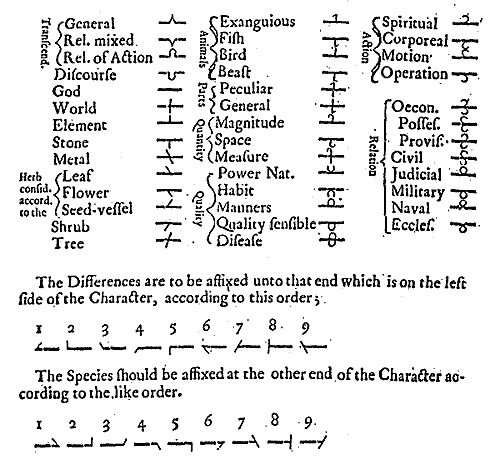
Już od dawna filozofowie myśleli o stworzenie języka uniwersalnego, w którym hierarchia bytów jest ułożona w „naturalny” sposób.
Przykładem jest angielski uczony John Wilkins (1614-1672). W dziele An Essay towards a Real Character and a Philosophical Language zaproponował on rozbudowaną hierarchię bytów.
Słowosieci
Współczesnym odpowiednik hierarchii Wilkinsa są słowosieci (ang. /wordnets). Przykłady:
- dla języka polskiego: Słowosieć,
- dla języka angielskiego: Princeton Wordnet (i Słowosieć!)