5.0 KiB

Modelowanie Języka
8. Neuronowe modele językowe [ćwiczenia]
Jakub Pokrywka (2022)

Instalacja pytorch
Zadanie
Proszę wykonać tylko jedno zadanie z dwóch!
Zadanie 1 (proste)
Wzorując się na materiałach z wykładu stworzyć neuronowy, bigramowy model językowy.
Warunki zaliczenia:
- wynik widoczny na platformie zarówno dla dev i dla test
- wynik dla dev i test lepszy (niższy) niż 1024.00 (liczone przy pomocy geval)
- deadline do końca dnia 24.04
- commitując rozwiązanie proszę również umieścić rozwiązanie w pliku /run.py (czyli na szczycie katalogu). Można przekonwertować jupyter do pliku python przez File → Download as → Python. Rozwiązanie nie musi być w pythonie, może być w innym języku.
- zadania wykonujemy samodzielnie
- w nazwie commita podaj nr indeksu
- w tagach podaj neural-network oraz bigram!
- uwaga na specjalne znaki \\n w pliku 'in.tsv' oraz pierwsze kolumny pliku in.tsv (które należy usunąć)
Punktacja:
- podstawa: 60 punktów
- 40 punktów z najlepszy wynik z 2 grup
Zadanie 2 (trudniejsze)
Wzorując się na materiałach z wykładu stworzyć neuronowy, trigramowy model językowy.
Warunki zaliczenia:
- wynik widoczny na platformie zarówno dla dev i dla test
- wynik dla dev i test lepszy (niższy) niż 1024.00 (liczone przy pomocy geval)
- deadline do końca dnia 24.04
- commitując rozwiązanie proszę również umieścić rozwiązanie w pliku /run.py (czyli na szczycie katalogu). Można przekonwertować jupyter do pliku python przez File → Download as → Python. Rozwiązanie nie musi być w pythonie, może być w innym języku.
- zadania wykonujemy samodzielnie
- w nazwie commita podaj nr indeksu
- w tagach podaj neural-network oraz trigram!
- uwaga na specjalne znaki \\n w pliku 'in.tsv' oraz pierwsze kolumny pliku in.tsv (które należy usunąć)
Punktacja:
- podstawa: 120 punktów
- 40 punktów z najlepszy wynik z 2 grup
- 20 punktów za drugi najlepszy wynik z 2 grup
W jaki sposób uzyskać lepszy wynik?
Dla lepszych wyników, można trenować model przez kilka epok.
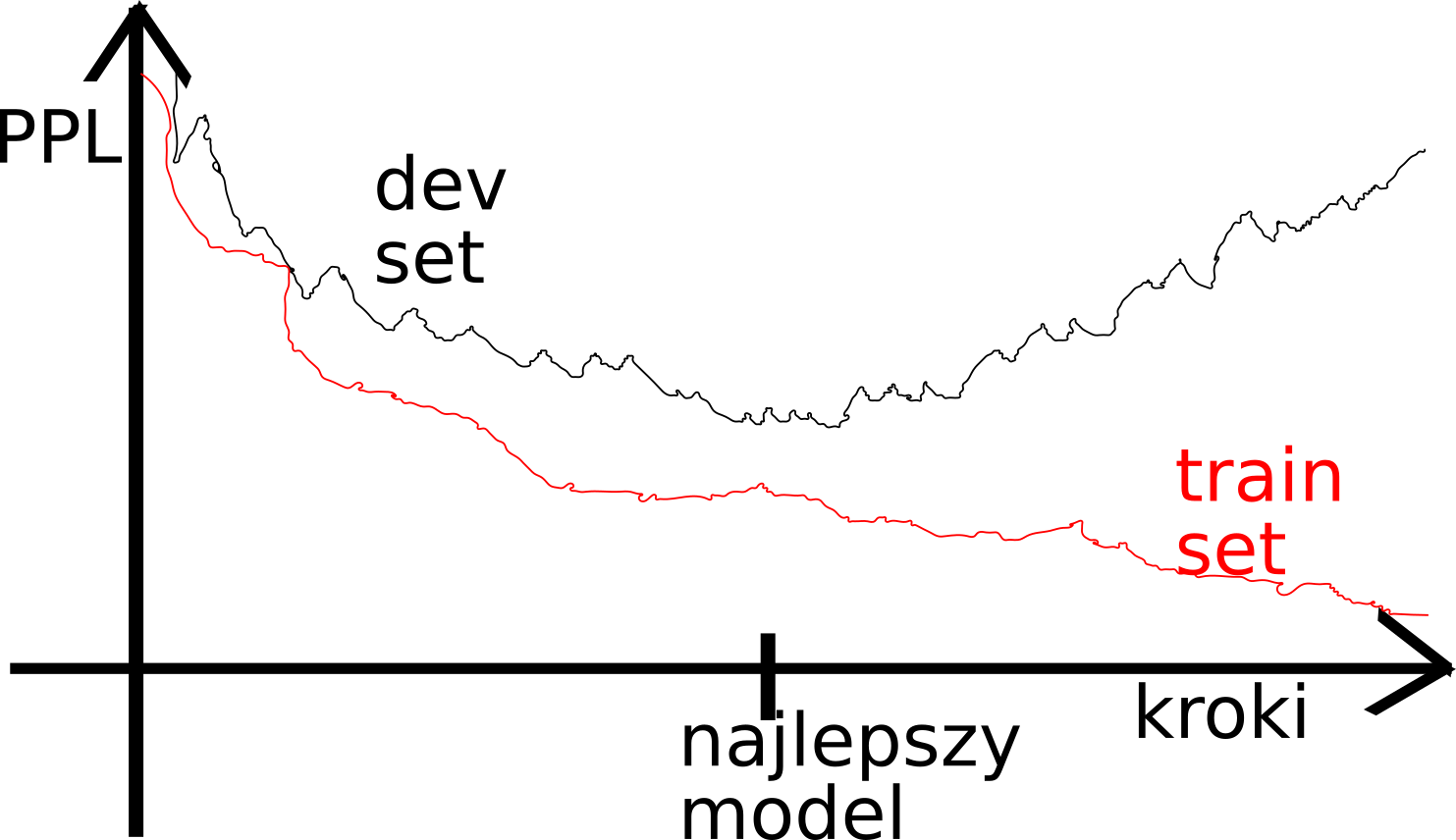
Zgodnie z dobra praktyką w uczeniu maszynowym należy monitorować wynik (tutaj perplexity) na zbiorze deweloperskim w trakcie uczenia.
Kod z wykładu pokazuje jedynie wynik funkcji kosztu na zbiorze trenującym. Dla kompletnego rozwiązania warto zaimplementować monitorowanie kosztu dla zbioru deweloperskiego. Przy każdym sprawdzaniu wyniku, należy sprawdzać czy obecny model jest najlepszy i jeżeli jest najlepszy to zapisywać jego stan najlepiej w postaci binarnej (może byc pickle) do pliku
Po zakończeniu trenowania należy wybrać model który uzyskuje najmniejszy wynik funkcji kosztu dla zbioru deweloperskiego i użyć go do wygenerowania odpowiedzi dla zbioru testowego.