9.6 KiB
Regresja liniowa
Na dzisiejszych zajęciach omówimy problem predykcji informacji i jego rozwiązanie poprzez wykorzystanie regresji liniowej.
Zadaniem regresji liniowej jest po prostu dopasowanie prostej linii do danych. Warto podkreślić, że regresja liniowa przyjmuje założenie, że związek między cechami a zmienną objaśnianą jest mniej więcej liniowy. Regresja liniowa nie jest jedynym rodzajem regresji aczkolwiek jest to najprostsza wersja.
Regresja może nam pomóc w predykcji (przewidzeniu) wartości jakiejś zmiennej objaśnianej (zależnej) na podstawie jakiś cech (zmiennych niezależnych).
Rozgrzewka
Przeanalizuj poniższy wykres:
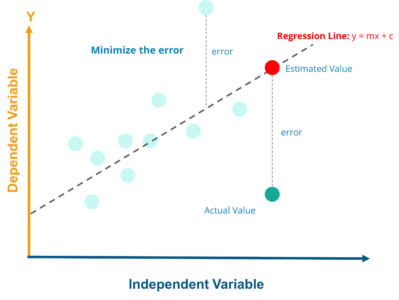
Dlaczego możemy zastosować regresję liniową do przewidywania informacji o danych?
Co musimy znaleźć, aby móc dokonywać predykcji informacji? Co musimy mieć na uwadze, aby to znaleźć?
Przykład
Załóżmy, że mamy uczniów, którzy pracują w kursie e-learningowym i ciekawi nas, czy zakończą pracę w tym kursie z sukcesem, tzn. zdobędą jak najlepszy wynik w końcowym teście zaliczeniowym. Aktualne informacje, które posiadamy, to czas spędzony w tym kursie, liczba rozwiązanych ćwiczeń, liczba elementów, których uczeń jeszcze nie odwiedził. Wiemy też, kiedy uczeń zaczął się uczyć i ile razy wchodził do kursu. Każdy uczeń ma też świadomość, że mają określony termin, do kiedy muszą podejść do końcowego testu zaliczeniowego.
Powiedzmy, że na początek przyjrzymy się jednej z informacji - liczbie rozwiązanych ćwiczeń. Załóżmy, że w kursie jest 20 ćwiczeń do rozwiązania a wynik w końcowym teście zaliczeniowym badamy w procentach. Rok temu mieliśmy innych uczniów, którzy też pracowali z tym kursem e-learningowym i mamy informację o ich wynikach:
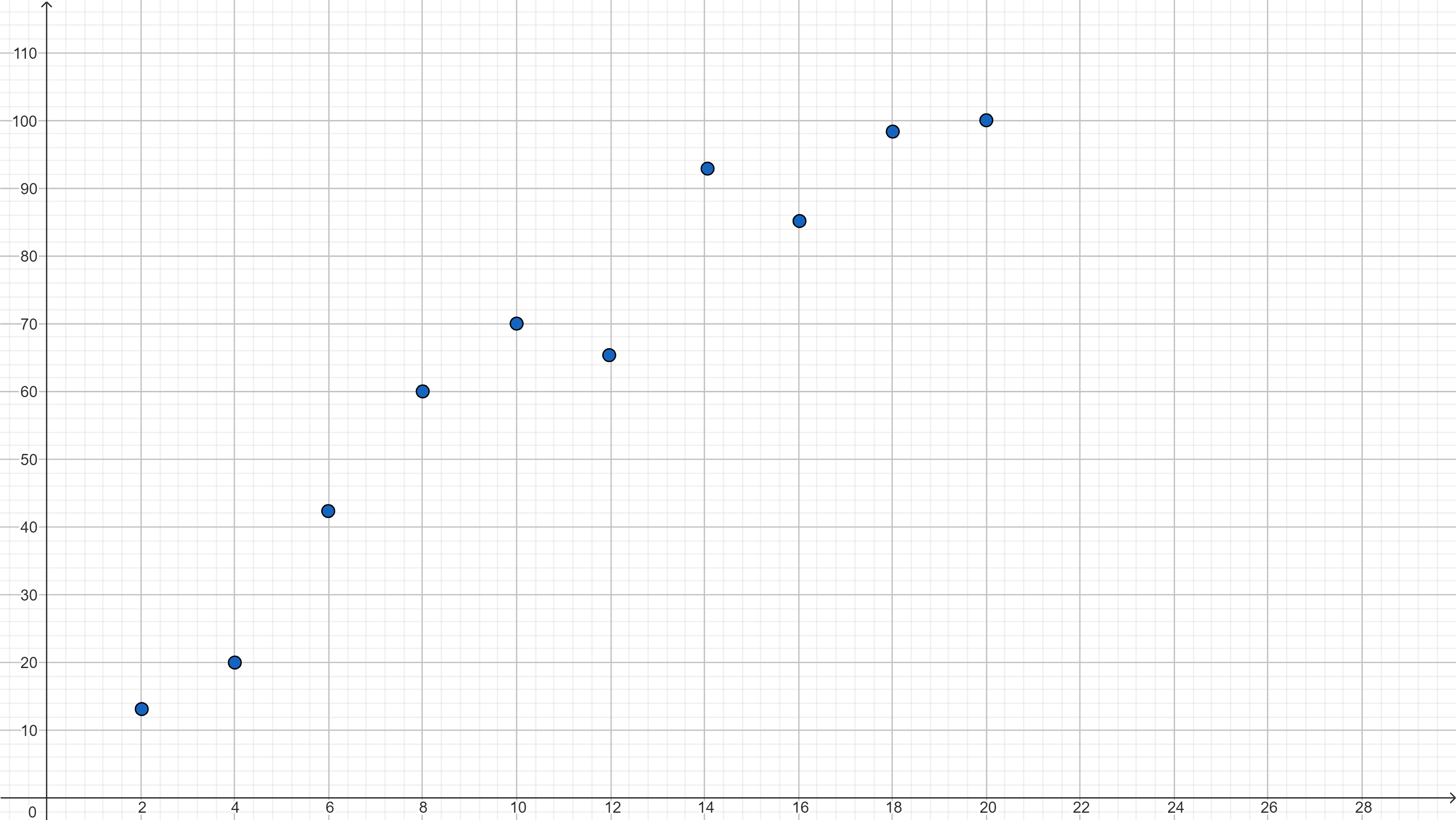
Zauważmy, że mamy tutaj pewien trend. W przybliżeniu możemy stwierdzić, że im większa liczba rozwiązanych ćwiczeń w kursie tym większy wynik w końcowym teście zaliczeniowym. Zatem moglibyśmy spróbować wyznaczyć funkcję, która pokazywałaby ten trend. Najprościej będzie wyznaczyć zależność liniową, czyli pewną funkcję liniową, która nam przybliży trend. Musimy znaleźć taką funkcję, dla której będziemy mieć sytuację, że dla jak największej liczby argumentów będziemy mieć jak najmniejszą różnicę pomiędzy wartością, którą zwróci funkcja a wartością rzeczywistą, którą mamy na powyższym wykresie.
Zatem naszym zadaniem jest wyznaczenie pewnej funkcji liniowej postaci: $f(x)=ax+b$, gdzie:
$x$ - liczba rozwiązanych ćwiczeń w kursie
$f(x)$ - przybliżony wynik osiągnięty w końcowym teście zaliczeniowym
$a$ - współczynnik kierunkowy naszej funkcji regresji liniowej
$b$ - wyraz wolny
Powstaje pytanie jak wyznaczyć wartości $a$ i $b$. Istnieją algorytmy numeryczne, które pozwalają znaleźć przybliżone wartości. Jednym z nich jest tzw. algorytm gradientu prostego. Natomiast nie będziemy go w tym momencie omawiać.
Na zajęciach ze statystyki będziecie Państwo (jeśli jeszcze nie mieliście statystyki) uczyć się jak wyznaczać te szukane wartości wg pewnych wzorów i teraz z nich skorzystamy:
$a=\frac{\sum_{i=1}^{n}\left ( x_{i}-\overline{x} \right )\left ( y_{i}-\overline{y} \right )}{\sum_{i=1}^{n}\left ( x_{i}-\overline{x} \right )^{2}}$
$b=\overline{y}-a\overline{x}$
gdzie:
$n$ - liczba punktów na naszym wykresie
$(x_{i}, y_{i})$ to i-ty punkt na naszym wykresie
$\overline{x}$ to średnia arytmetyczna wszystkich argumentów z naszego wykresu (liczby rozwiązanych ćwiczeń)
$\overline{y}$ to średnia arytmetyczna wszystkich wartości z naszego wykresu (wyników w teście)
Co do zasady te wzory będą (lub były) wyjaśniane na zajęciach ze statystyki, natomiast na ten moment powinna wystarczyć nam informacja, że wynikają one z faktu, że szukamy takiej funkcji, dla której różnice między obliczoną a rzeczywistą wartością są jak najmniejsze. Różnice te mogą być ujemne, dlatego bada się kwadraty różnic, żeby nie było sytuacji, że różnice pewnych wartości się wyzerują i przez to znajdziemy błędną funkcję regresji. Taką metodę nazywa się metodą najmniejszych kwadratów a same różnice nazywa się resztami lub residuami.
Gdybyśmy dla naszych danych wyznaczyli zgodnie z powyższymi wzorami wartość funkcji regresji liniowej otrzymalibyśmy prostą jak na poniższym wykresie:
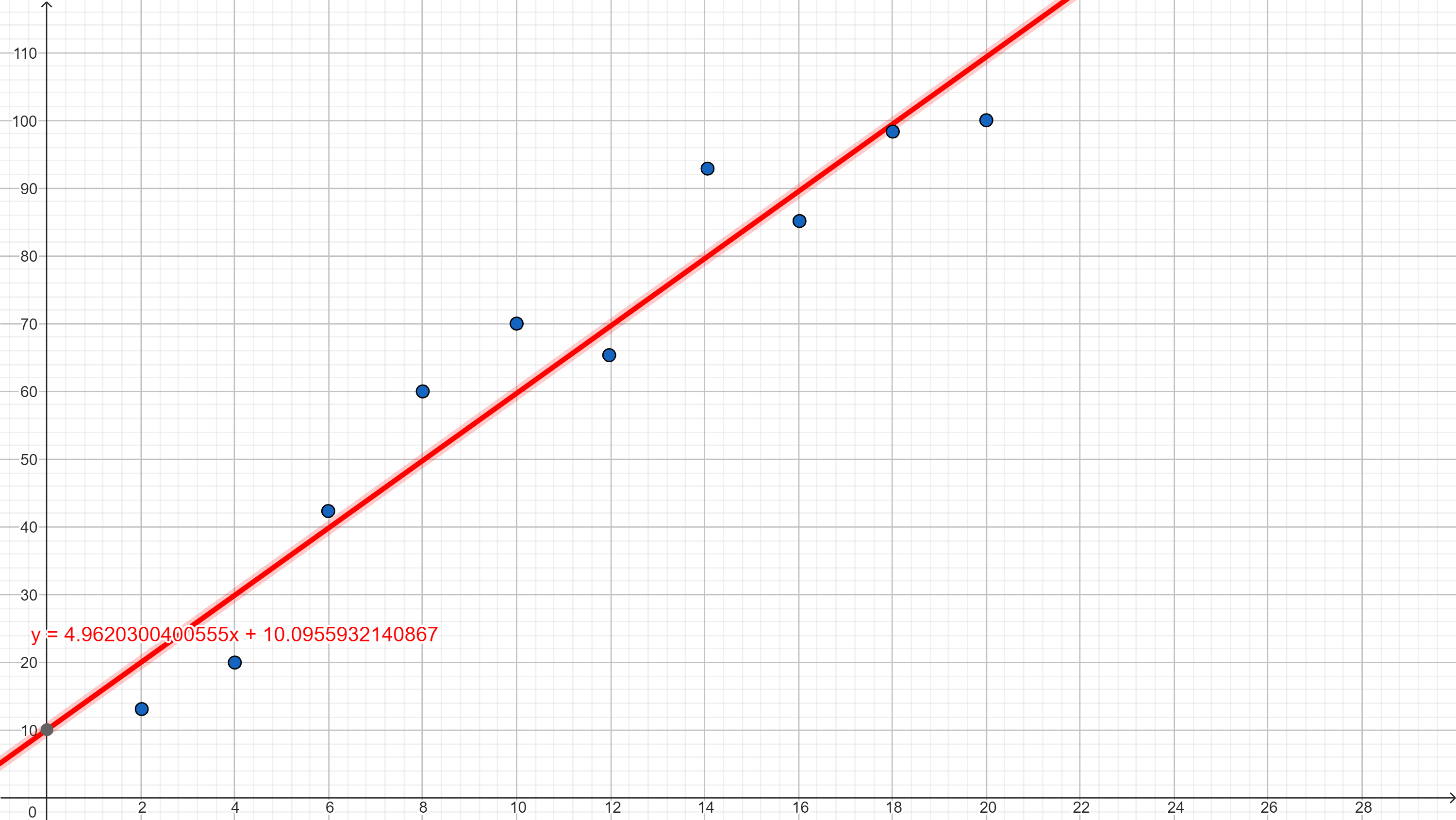
Można to interpretować następująco:
- ponieważ wyraz wolny $b$ w przybliżeniu wynosi 10,1 to można powiedzieć, że jeśli uczeń nie rozwiąże ćwiczeń, to jego wynik na teście końcowym wyniesie właśnie ok. 10%;
- ponieważ współczynnik kierunkowy $a$ jest dodatni to oznacza, że wraz ze wzrostem liczby rozwiązanych ćwiczeń będzie rósł wynik na teście końcowym;
- ponieważ współczynnik kierunkowy $a$ wynosi ok. 4,96, oznacza to, że wraz z każdym kolejnym rozwiązanym ćwiczeniem wynik w teście końcowym wzrasta o ok. 4,96%.
To, czy powyższe wnioski są w naszym problemie sensowne to inna sprawa. Regresja liniowa ma swoje plusy i minusy:
Zalety:
- Prostota – dzięki swojej prostocie wykorzystywana jest w wielu dziedzinach: od matematyki, poprzez ekonomię, aż po geodezję,
- interpretowalność – dzięki prostym wzorom bardzo łatwo wyjaśnić biznesowi lub innym osobom, jak dana cecha wpływa na wynik modelu,
- szybkość – nawet przy dużej liczbie danych dla prostych algorytmów wyniki dostajemy prawie od razu.
Wady:
- Prostota (wcześniej zaleta ;P) – świat nie składa się z prostych liniowych zależności. Gdyby tak było, to pewnie nie byłoby takiego rozwoju uczenia maszynowego.
Oczywiście mamy więcej informacji niż liczba rozwiązanych ćwiczeń, więc można by było spróbować wyznaczyć funkcję wielu zmiennych, w której każdy ze składników byłby jakąś funkcją liniową. To już spróbujemy zrobić korzystając z możliwości języka Python i dostępnych dla niego bibliotek.