forked from AITech/aitech-ium
12 KiB
12 KiB

Inżynieria uczenia maszynowego
6. Jenkins, część 2. [laboratoria]
Tomasz Ziętkiewicz (2022)

Plan na dziś
- Multibranch pipeline
- Pluginy
- Zadania
Multibranch pipeline
- Multibranch Pipeline to rodzaj projektu na Jenkinsie, który automatycznie obsługuje wiele gałęzi (branch) w repozytorium
- W dominującym dziś sposobie utrzymywania i rozwoju kodu możemy wyróżnić:
- gałąź główną (master branch) - tutaj znajduje się aktualna, gotowa do wydania (opulbikowania/wdrożenia) wersja kodu
- gałęzie typu develop/feature/release/hotfix itp. (tutaj przystępne wyjaśnienie czym się różnią), na których rozwijamy nasz kod/wprowadzamy nowe funkcjonalności/przygotowujemy wersje gotowe do włączenia do gałęzi master, naprawiamy błędy.
- Gałęzi może być sporo i każdą z nich musimy przetestować, najlepiej automatycznie, przed zmergowaniem jej do gałęzi master
- Świetnie nadaje się do tego własnie Multibranch pipeline
- Nawet, jeśli pracujemy tylko na dwóch gałęziach jednocześnie (master i jedna dodatkowa) to i tak warto go zastosować
- Projekt typu Multibranch pipeline automatycznie stworzy pod-projekty (joby) dla każdego (chyba, że ustawimy filtry) brancha znalezionego w podanym przez nas repozytorium
Multibranch pipeline cd.
- Żeby utworzyć projektu typu Multibranch, wybierz ten rodzaj przy tworzeniu projektu

- Przy konfiguracji musimy jedynie podać namiary na repozytorium, w którym Jenkins ma szukać naszych branchy.
- Robimy to w polu "Branch Sources". Możemy tutaj wybrać "git" albo "gitea"
Multibranch pipeline cd.
- Wybranie "gitea" ułatwi nam wybór repozytorium i doda informację o statusie builda w interfejsie Gitea oraz link z Jenkinsa do odpowiedniego brancha w Gitea
Multibranch pipeline cd.
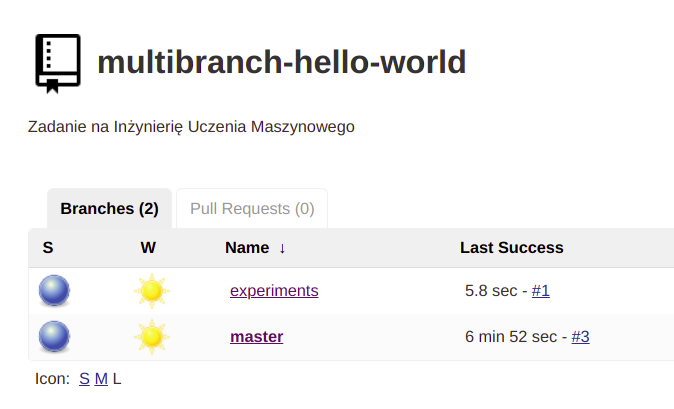
- Po zapisaniu konfiguracji Jenkins utworzy joby dla każdej gałązi znalezionej w repozytorium.
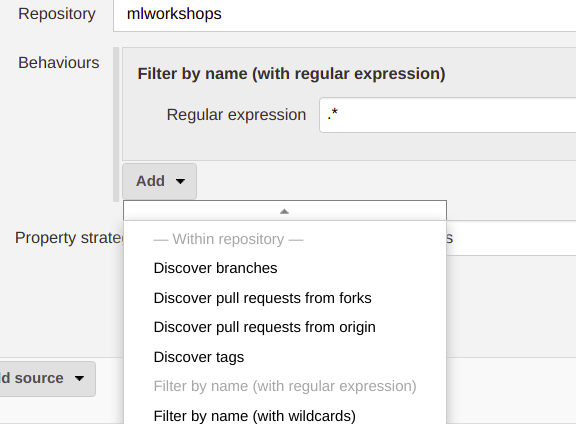
- Żeby ograniczyć branche, dla których mają powstać projekty, możesz użyć "Behaviours" -> "Add" -> "Filter by name":
- Zwróć uwagę:
- Konfigurować można tylko główny projekt
- Jeśli chcesz, żeby konfiguracja projektu Jenkinsowego dla danego brancha była inna niż dla pozostałych, musisz po prostu wprowadzić zmiany w Jenkinsfile na danym branchu.
- Z założenia jednak, konfiguracja powinna być wspólna
- W przypadku kopiowania artefaktów z projektu typu multibranch musisz w nazwie projektu źródłowego, z którego kopiujesz artefaky, zawrzeć również nazwę brancha, w fomracie:
nazwa-projektu/nazwa-brancha, np.:copyArtifacts filter: '*', projectName: 'multibranch-hello-world/experiments/'
Pluginy
- Wszsytkie pluginy można przeglądać tutaj: https://plugins.jenkins.io/
- Instalacja przez administratora (poprzez prosty graficzny interfejs w konfiguracji Jenkinsa)
- Po zainstalowaniu pojawiąją się nowe kroki (steps) dostępnę w pipeline albo nowe opcje konfiguracji
- Git parameter plugin: https://plugins.jenkins.io/git-parameter/
- Email extension plugin: https://plugins.jenkins.io/email-ext/
Git parameter plugin
- https://plugins.jenkins.io/git-parameter/
- Dodaje parametr umożliwiający wybranie m.in. brancha z repozytorium
gitParameter branchFilter: 'origin/(.*)', defaultValue: 'master', name: 'BRANCH', type: 'PT_BRANCH'
Email extension plugin
- https://plugins.jenkins.io/email-ext/
- Umożliwia wysłanie emaila, np. z powiadomieniem o zakończonym buildzie
emailext body: 'Test Message', subject: 'Test Subject', to: 'test@example.com' - Microsoft Teams ma swój własny plugin do powiadomień (https://plugins.jenkins.io/Office-365-Connector/), ale jest on zablokowany od strony Teams przez administratorów
- Na szczęście, kanały Teams mają swój adres email. Adres stworzonego przeze mnie kanału "IUM powiadomienia z Jenkins" na naszej grupie zajęciowej: e19191c5.uam.onmicrosoft.com@emea.teams.ms
- Wysłanie na niego wiadomości email spowoduje pojawienie się jej na tym kanale
Zadanie 1 [5 pkt] (termin: 2 V 2022)
- Stwórz na Jenkins projekt typu Multibranch pipeline o nazwie s123456-training Projekt ten powinien przeprowadzać trenowanie modelu korzystając z kodu przygotowanego na poprzednich zajęciach. Trenowanie powinno odbywać się wewnątrz kontenera docker. [1 pkt]
- Projekt powinien odpalać się automatycznie po zakończonym budowaniu projektu s123456-create-dataset i kopiować z niego zbiór danych [1 pkt]
- Po zakończeniu trenowania powstały model powinien zostać zarchiwizowany [1 pkt]
- Trenowanie modelu potrafi zająć bardzo dużo czasu. Sprawdzanie co 10 minut, czy już się zakończyło, to zły pomysł. Dodaj powiadomienie (wysyłane przez email na Teamsowy kanał "Powiadomienia z Jenkins") o zakończonym jobie zawierające rezultat (Status builda - successfull, failed, aborted itd) [1 pkt]
- Dodaj parametr umożliwiający przekazanie do skryptu trenującego parametrów trenowania. Najprościej zrobić to dodając parametr typu String i doklejać jego wartość do wywołania skryptu trenującego. [1 pkt]
Zadanie 2 [15 pkt] (termin: 2 V 2022)
- Stwórz na Jenkins projekt typu Multibranch pipeline o nazwie s123456-evaluation. Projekt ten będzie przeprowadzał ewaluację modelu stworzonego w s123456-training na danych ze zbioru trenującego [1 pkt]
- Ewaluacja polega na:
- wczytaniu wytrenowanego wcześniej modelu
- dokonaniu predykcji na zbiorze testowym za pomocą wczytanego modelu i zapisanie wyników tej predykcji do pliku
- wyliczeniu zbiorczych metryk (1-3 metryki) na zbiorze testującym (np. Accuracy, Micro-avg precission/recall, F1, RMSE - patrz [wykład 4. "Metody ewaluacji"])(https://git.wmi.amu.edu.pl/AITech/aitech-uma/src/branch/master/wyk/04_Metody_ewaluacji.ipynb) z przedmiotu Uczenie Maszynowe),
- zapisaniu metryk do pliku
- zarchiwizowaniu go [6 pkt]
- W celu śledzenia zmian wartości metryk, zapisuj wartości kumulatywnie w jednym pliku. Żeby to osiągnąć można:
- zapisywać metryki w ścieżce zewnątrznej w stosunku do Jenkinsa (w innym przypadku mogą zostać nadpisane np. podczas checkout repozytorium) - tej opcji nie wykorzystamy - dopisywać metrykę do końca pliku skopiowanego z artefaktów poprzedniego builda (należy uczynić kopiowanie tego artefaktu opcjonalnym, żeby pierwszt build na danym branchu nie "wywalił się" przy próbie skopiowania artefaktów z nieistniejącego joba) [2 pkt] - Mając skumulowane wartości metryk z wszystkich dotychczasowych buildów, stwórz wykres: na osi X numer builda, na osi Y wartość metryk(i). [2 pkt]
Możesz w tym celu użyć:
- pluginu plot
- Matplotlib - biblioteka pythonowa - w tym przypadku archiwizuj wygenerowany obrazek z wykresem
- Gnuplot - w tym przypadku archiwizuj wygenerowany obrazek z wykresem
- Projekt powinien odpalać się automatycznie po zakończonym trenowaniu (s123456-training) i kopiować model z artefaktów. Zauważ, że żeby odpalony projekt (s123456-evaluation) skopiował artefakty z odpowiedniego brancha (tego, który go odpalił), projekt s123456-evaluation musi być wywołany przez s123456-training z odpowiednią wartością parametru branch (patrz punkt 7.) [1 pkt]
- Dane testujące powinny być skopiowane z projektu s123456-create-dataset [1pkt]
- Dodaj parametry umożliwiające wybór:
- gałęzi (branch) projektu s123456-training z której ma być skopiowany model. Można by tutaj użyć prostego parametru typu String, ale użyj łatwiejszego (w użytkowaniu) parametru typu "Git parameter" (patrz wyżej)[1 pkt]
- numeru builda projektu s123456-training ("Build selector for Copy artifact", patrz zajęcia 3.) [1pkt]