27 KiB
Uczenie maszynowe – zastosowania
10. Sieci neuronowe – propagacja wsteczna
%matplotlib inline
import numpy as np
import math10.1. Metoda propagacji wstecznej – wprowadzenie
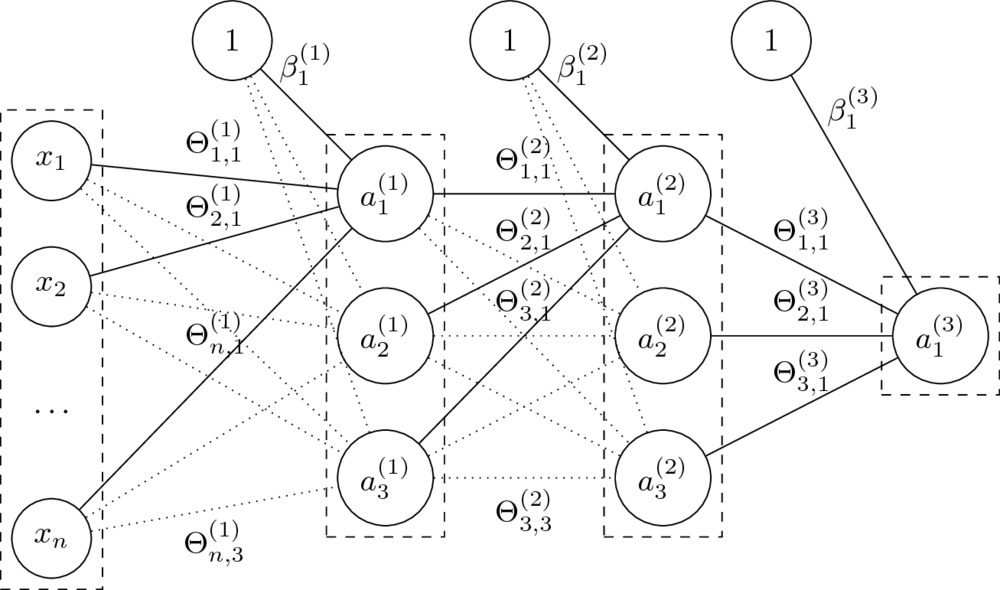
Architektura sieci neuronowych
- Budowa warstwowa, najczęściej sieci jednokierunkowe i gęste.
- Liczbę i rozmiar warstw dobiera się do każdego problemu.
- Rozmiary sieci określane poprzez liczbę neuronów lub parametrów.
_Feedforward
Mając daną $n$-warstwową sieć neuronową oraz jej parametry $\Theta^{(1)}, \ldots, \Theta^{(L)} $ oraz $\beta^{(1)}, \ldots, \beta^{(L)} $, obliczamy:
$$a^{(l)} = g^{(l)}\left( a^{(l-1)} \Theta^{(l)} + \beta^{(l)} \right). $$
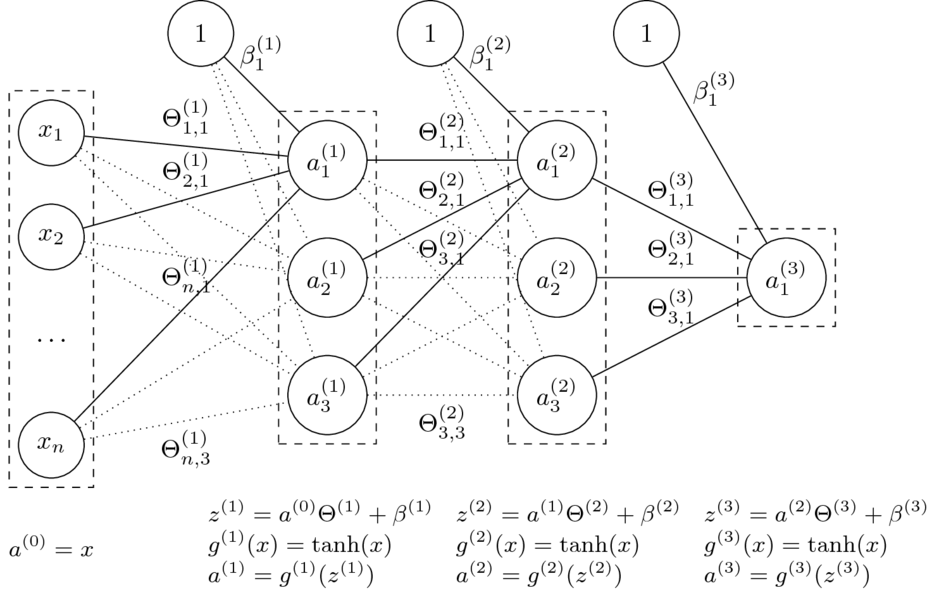
- Funkcje $g^{(l)}$ to funkcje aktywacji.
Dla $i = 0$ przyjmujemy $a^{(0)} = x$ (wektor wierszowy cech) oraz $g^{(0)}(x) = x$ (identyczność).
- Parametry $\Theta$ to wagi na połączeniach miedzy neuronami dwóch warstw.
Rozmiar macierzy $\Theta^{(l)}$, czyli macierzy wag na połączeniach warstw $a^{(l-1)}$ i $a^{(l)}$, to $\dim(a^{(l-1)}) \times \dim(a^{(l)})$.
- Parametry $\beta$ zastępują tutaj dodawanie kolumny z jedynkami do macierzy cech.
Macierz $\beta^{(l)}$ ma rozmiar równy liczbie neuronów w odpowiedniej warstwie, czyli $1 \times \dim(a^{(l)})$.
- Klasyfikacja: dla ostatniej warstwy $L$ (o rozmiarze równym liczbie klas) przyjmuje się $g^{(L)}(x) = \mathop{\mathrm{softmax}}(x)$.
- Regresja: pojedynczy neuron wyjściowy; funkcją aktywacji może wtedy być np. funkcja identycznościowa.
- Pozostałe funkcje aktywacji najcześciej mają postać sigmoidy, np. sigmoidalna, tangens hiperboliczny.
Ale niekoniecznie, np. ReLU, leaky ReLU, maxout.
Jak uczyć sieci neuronowe?
- W poznanych do tej pory algorytmach (regresja liniowa, regresja logistyczna) do uczenia używaliśmy funkcji kosztu, jej gradientu oraz algorytmu gradientu prostego (GD/SGD)
- Dla sieci neuronowych potrzebowalibyśmy również znaleźć gradient funkcji kosztu.
- Co sprowadza się do bardziej ogólnego problemu:
jak obliczyć gradient $\nabla f(x)$ dla danej funkcji $f$ i wektora wejściowego $x$?
Pochodna funkcji
- Pochodna mierzy, jak szybko zmienia się wartość funkcji względem zmiany jej argumentów:
$$ \frac{d f(x)}{d x} = \lim_{h \to 0} \frac{ f(x + h) - f(x) }{ h } $$
Pochodna cząstkowa i gradient
- Pochodna cząstkowa mierzy, jak szybko zmienia się wartość funkcji względem zmiany jej _pojedynczego argumentu.
- Gradient to wektor pochodnych cząstkowych:
$$ \nabla f = \left( \frac{\partial f}{\partial x_1}, \ldots, \frac{\partial f}{\partial x_n} \right) $$
Gradient – przykłady
$$ f(x_1, x_2) = x_1 + x_2 \qquad \to \qquad \frac{\partial f}{\partial x_1} = 1, \quad \frac{\partial f}{\partial x_2} = 1, \quad \nabla f = (1, 1) $$
$$ f(x_1, x_2) = x_1 \cdot x_2 \qquad \to \qquad \frac{\partial f}{\partial x_1} = x_2, \quad \frac{\partial f}{\partial x_2} = x_1, \quad \nabla f = (x_2, x_1) $$
$$ f(x_1, x_2) = \max(x_1 + x_2) \hskip{12em} \\ \to \qquad \frac{\partial f}{\partial x_1} = \mathbb{1}_{x \geq y}, \quad \frac{\partial f}{\partial x_2} = \mathbb{1}{y \geq x}, \quad \nabla f = (\mathbb{1}{x \geq y}, \mathbb{1}{y \geq x}) $$
Własności pochodnych cząstkowych
Jezeli $f(x, y, z) = (x + y) , z$ oraz $x + y = q$, to: $$f = q z, \quad \frac{\partial f}{\partial q} = z, \quad \frac{\partial f}{\partial z} = q, \quad \frac{\partial q}{\partial x} = 1, \quad \frac{\partial q}{\partial y} = 1 $$
Reguła łańcuchowa
$$ \frac{\partial f}{\partial x} = \frac{\partial f}{\partial q} , \frac{\partial q}{\partial x}, \quad \frac{\partial f}{\partial y} = \frac{\partial f}{\partial q} , \frac{\partial q}{\partial y} $$
Propagacja wsteczna – prosty przykład
# Dla ustalonego wejścia
x = -2; y = 5; z = -4# Krok w przód
q = x + y
f = q * z
print(q, f)(3, -12)
# Propagacja wsteczna dla f = q * z
dz = q
dq = z
# Propagacja wsteczna dla q = x + y
dx = 1 * dq # z reguły łańcuchowej
dy = 1 * dq # z reguły łańcuchowej
print([dx, dy, dz])[-4, -4, 3]

- Właśnie tak wygląda obliczanie pochodnych metodą propagacji wstecznej!
- Spróbujmy czegoś bardziej skomplikowanego:
metodą propagacji wstecznej obliczmy pochodną funkcji sigmoidalnej.
Propagacja wsteczna – funkcja sigmoidalna
Funkcja sigmoidalna:
$$f(\theta,x) = \frac{1}{1+e^{-(\theta_0 x_0 + \theta_1 x_1 + \theta_2)}}$$
$$ \begin{array}{lcl} f(x) = \frac{1}{x} \quad & \rightarrow & \quad \frac{df}{dx} = -\frac{1}{x^2} \\ f_c(x) = c + x \quad & \rightarrow & \quad \frac{df}{dx} = 1 \\ f(x) = e^x \quad & \rightarrow & \quad \frac{df}{dx} = e^x \\ f_a(x) = ax \quad & \rightarrow & \quad \frac{df}{dx} = a \\ \end{array} $$

# Losowe wagi i dane
w = [2,-3,-3]
x = [-1, -2]
# Krok w przód
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # funkcja sigmoidalna
# Krok w tył
ddot = (1 - f) * f # pochodna funkcji sigmoidalnej
dx = [w[0] * ddot, w[1] * ddot]
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot]
print(dx)
print(dw)[0.3932238664829637, -0.5898357997244456] [-0.19661193324148185, -0.3932238664829637, 0.19661193324148185]
Obliczanie gradientów – podsumowanie
- Gradient $f$ dla $x$ mówi jak zmieni się całe wyrażenie przy zmianie wartości $x$.
- Gradienty łączymy korzystając z reguły łańcuchowej.
- W kroku wstecz gradienty informują, które części grafu powinny być zwiększone lub zmniejszone (i z jaką siłą), aby zwiększyć wartość na wyjściu.
- W kontekście implementacji chcemy dzielić funkcję $f$ na części, dla których można łatwo obliczyć gradienty.
10.2. Uczenie wielowarstwowych sieci neuronowych metodą propagacji wstecznej
Mając algorytm SGD oraz gradienty wszystkich wag, moglibyśmy trenować każdą sieć.
Niech: $$\Theta = (\Theta^{(1)},\Theta^{(2)},\Theta^{(3)},\beta^{(1)},\beta^{(2)},\beta^{(3)})$$
Funkcja sieci neuronowej z grafiki:
$$\small h_\Theta(x) = \tanh(\tanh(\tanh(x\Theta^{(1)}+\beta^{(1)})\Theta^{(2)} + \beta^{(2)})\Theta^{(3)} + \beta^{(3)})$$
- Funkcja kosztu dla regresji: $$J(\Theta) = \dfrac{1}{2m} \sum_{i=1}^{m} (h_\Theta(x^{(i)})- y^{(i)})^2 $$
- Jak obliczymy gradienty?
$$\nabla_{\Theta^{(l)}} J(\Theta) = ? \quad \nabla_{\beta^{(l)}} J(\Theta) = ?$$
W kierunku propagacji wstecznej
- Pewna (niewielka) zmiana wagi $\Delta z^l_j$ dla $j$-ego neuronu w warstwie $l$ pociąga za sobą (niewielką) zmianę kosztu:
$$\frac{\partial J(\Theta)}{\partial z^{l}_j} \Delta z^{l}_j$$
- Jeżeli $\frac{\partial J(\Theta)}{\partial z^{l}_j}$ jest duża, $\Delta z^l_j$ ze znakiem przeciwnym zredukuje koszt.
- Jeżeli $\frac{\partial J(\Theta)}{\partial z^l_j}$ jest bliska zeru, koszt nie będzie mocno poprawiony.
- Definiujemy błąd $\delta^l_j$ neuronu $j$ w warstwie $l$:
$$\delta^l_j := \dfrac{\partial J(\Theta)}{\partial z^l_j}$$ $$\delta^l := \nabla_{z^l} J(\Theta) \quad \textrm{ (zapis wektorowy)} $$
Podstawowe równania propagacji wstecznej
$$ \begin{array}{rcll} \delta^L & = & \nabla_{a^L}J(\Theta) \odot { \left( g^{L} \right) }^{\prime} \left( z^L \right) & (BP1) \\[2mm] \delta^{l} & = & \left( \left( \Theta^{l+1} \right) ! ^\top , \delta^{l+1} \right) \odot {{ \left( g^{l} \right) }^{\prime}} \left( z^{l} \right) & (BP2)\\[2mm] \nabla_{\beta^l} J(\Theta) & = & \delta^l & (BP3)\\[2mm] \nabla_{\Theta^l} J(\Theta) & = & a^{l-1} \odot \delta^l & (BP4)\\ \end{array} $$
(BP1)
$$ \delta^L_j ; = ; \frac{ \partial J }{ \partial a^L_j } , g' !! \left( z^L_j \right) $$ $$ \delta^L ; = ; \nabla_{a^L}J(\Theta) \odot { \left( g^{L} \right) }^{\prime} \left( z^L \right) $$ Błąd w ostatniej warstwie jest iloczynem szybkości zmiany kosztu względem $j$-tego wyjścia i szybkości zmiany funkcji aktywacji w punkcie $z^L_j$.
(BP2)
$$ \delta^{l} ; = ; \left( \left( \Theta^{l+1} \right) ! ^\top , \delta^{l+1} \right) \odot {{ \left( g^{l} \right) }^{\prime}} \left( z^{l} \right) $$ Aby obliczyć błąd w $l$-tej warstwie, należy przemnożyć błąd z następnej ($(l+1)$-szej) warstwy przez transponowany wektor wag, a uzyskaną macierz pomnożyć po współrzędnych przez szybkość zmiany funkcji aktywacji w punkcie $z^l$.
(BP3)
$$ \nabla_{\beta^l} J(\Theta) ; = ; \delta^l $$ Błąd w $l$-tej warstwie jest równy wartości gradientu funkcji kosztu.
(BP4)
$$ \nabla_{\Theta^l} J(\Theta) ; = ; a^{l-1} \odot \delta^l $$ Gradient funkcji kosztu względem wag $l$-tej warstwy można obliczyć jako iloczyn po współrzędnych $a^{l-1}$ przez $\delta^l$.
Algorytm propagacji wstecznej
Dla jednego przykładu $(x,y)$:
- Wejście: Ustaw aktywacje w warstwie cech $a^{(0)}=x$
- Feedforward: dla $l=1,\dots,L$ oblicz $$z^{(l)} = a^{(l-1)} \Theta^{(l)} + \beta^{(l)} \textrm{ oraz } a^{(l)}=g^{(l)} !! \left( z^{(l)} \right) $$
- Błąd wyjścia $\delta^{(L)}$: oblicz wektor $$\delta^{(L)}= \nabla_{a^{(L)}}J(\Theta) \odot {g^{\prime}}^{(L)} !! \left( z^{(L)} \right) $$
- Propagacja wsteczna błędu: dla $l = L-1,L-2,\dots,1$ oblicz $$\delta^{(l)} = \delta^{(l+1)}(\Theta^{(l+1)})^T \odot {g^{\prime}}^{(l)} !! \left( z^{(l)} \right) $$
- Gradienty:
- $\dfrac{\partial}{\partial \Theta_{ij}^{(l)}} J(\Theta) = a_i^{(l-1)}\delta_j^{(l)} \textrm{ oraz } \dfrac{\partial}{\partial \beta_{j}^{(l)}} J(\Theta) = \delta_j^{(l)}$
W naszym przykładzie:
$$\small J(\Theta) = \frac{1}{2} \left( a^{(L)} - y \right) ^2 $$ $$\small \dfrac{\partial}{\partial a^{(L)}} J(\Theta) = a^{(L)} - y$$
$$\small \tanh^{\prime}(x) = 1 - \tanh^2(x)$$

Algorytm SGD z propagacją wsteczną
Pojedyncza iteracja:
- Dla parametrów $\Theta = (\Theta^{(1)},\ldots,\Theta^{(L)})$ utwórz pomocnicze macierze zerowe $\Delta = (\Delta^{(1)},\ldots,\Delta^{(L)})$ o takich samych wymiarach (dla uproszczenia opuszczono wagi $\beta$).
- Dla $m$ przykładów we wsadzie (_batch), $i = 1,\ldots,m$:
- Wykonaj algortym propagacji wstecznej dla przykładu $(x^{(i)}, y^{(i)})$ i przechowaj gradienty $\nabla_{\Theta}J^{(i)}(\Theta)$ dla tego przykładu;
- $\Delta := \Delta + \dfrac{1}{m}\nabla_{\Theta}J^{(i)}(\Theta)$
- Wykonaj aktualizację wag: $\Theta := \Theta - \alpha \Delta$
Propagacja wsteczna – podsumowanie
- Algorytm pierwszy raz wprowadzony w latach 70. XX w.
- W 1986 David Rumelhart, Geoffrey Hinton i Ronald Williams pokazali, że jest znacznie szybszy od wcześniejszych metod.
- Obecnie najpopularniejszy algorytm uczenia sieci neuronowych.
10.3. Implementacja sieci neuronowych
import pandas
src_cols = ['łod.dł.', 'łod.sz.', 'pł.dł.', 'pł.sz.', 'Gatunek']
trg_cols = ['łod.dł.', 'łod.sz.', 'pł.dł.', 'pł.sz.', 'Iris setosa?']
data = (
pandas.read_csv('iris.csv', usecols=src_cols)
.apply(lambda x: [x[0], x[1], x[2], x[3], 1 if x[4] == 'Iris-setosa' else 0], axis=1))
data.columns = trg_cols
data[:6]| łod.dł. | łod.sz. | pł.dł. | pł.sz. | Iris setosa? | |
|---|---|---|---|---|---|
| 0 | 5.2 | 3.4 | 1.4 | 0.2 | 1.0 |
| 1 | 5.1 | 3.7 | 1.5 | 0.4 | 1.0 |
| 2 | 6.7 | 3.1 | 5.6 | 2.4 | 0.0 |
| 3 | 6.5 | 3.2 | 5.1 | 2.0 | 0.0 |
| 4 | 4.9 | 2.5 | 4.5 | 1.7 | 0.0 |
| 5 | 6.0 | 2.7 | 5.1 | 1.6 | 0.0 |
m, n_plus_1 = data.values.shape
n = n_plus_1 - 1
Xn = data.values[:, 0:n].reshape(m, n)
X = np.matrix(np.concatenate((np.ones((m, 1)), Xn), axis=1)).reshape(m, n_plus_1)
Y = np.matrix(data.values[:, n]).reshape(m, 1)
print(X[:6])
print(Y[:6])[[1. 5.2 3.4 1.4 0.2] [1. 5.1 3.7 1.5 0.4] [1. 6.7 3.1 5.6 2.4] [1. 6.5 3.2 5.1 2. ] [1. 4.9 2.5 4.5 1.7] [1. 6. 2.7 5.1 1.6]] [[1.] [1.] [0.] [0.] [0.] [0.]]
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(3, input_dim=5))
model.add(Dense(3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, Y)/home/pawel/.local/lib/python2.7/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`. from ._conv import register_converters as _register_converters Using TensorFlow backend.
Epoch 1/1 150/150 [==============================] - 0s 2ms/step - loss: 3.6282 - acc: 0.3333
<keras.callbacks.History at 0x7f9bd195e190>
model.predict(np.array([1.0, 3.0, 1.0, 2.0, 4.0]).reshape(-1, 5)).tolist()[0][0]0.05484907701611519
scores = model.evaluate(X, Y)
print()
for i in range(len(scores)):
print('{}:\t{:.4f}'.format(model.metrics_names[i], scores[i]))150/150 [==============================] - 0s 293us/step () loss: 3.4469 acc: 0.3333