5.4 KiB
Raport przygotowała: Natalia Plitta
Raportowany okres: 11 maja - 25 maja 2020
Niniejszy raport poświęcony jest przekazaniu informacji na temat stanu mini-projektu indywidualnego w ramach projektu grupowego realizowanego na przedmiot Sztuczna Inteligencja w roku akademickim 2019/2020.
Tematem realizowanego projektu indywidualnego jest stworzenie sztucznej inteligencji, która na podstawie podanych parametrów poleca jedno z siedmiu dań. Wykorzystane zostały poniższe biblioteki:
- scikit - learn
- joblib
- IPython
- pandas
- pydotplus
- StringIO
Realizacja projektu
col_names = ['age', 'sex', 'fat', 'fiber', 'spicy', 'number']
model_tree = pd.read_csv("Nowy.csv", header=None, names=col_names)
model_tree.head()
feature_cols = ['age', 'sex', 'fat', 'fiber', 'spicy']
X = model_tree[feature_cols]
y = model_tree.number
Na początku dane są pobierane z pliku "Nowy.csv" gdzie zostały przygotowane 121 wiersze o kolumnach z kolejno podanymi nazwami. Następnie model zostal podzielony na cechy i etykietę ['number'], która oznacza polecane danie.
Dane:
Aby utworzyć model utworzyłam 121 wierszy z 6 kolejnych liczb oznaczających:
- wiek klienta (7 - 80);
- zawartość tłuszczu w daniu (0 - 16);
- zawartość błonnika w daniu (0 - 16);
- płeć osoby zamawiającej (0 - kobieta lub 1 - mężczyzna);
- ostrość dania (0 - 5);
- polecane danie o danym numerze:
- zupa z soczewicy
- frytki pieczone
- makaron z sosem brokułowym
- pikantne skrzydełka zasmażane
- ostre zasmażane tofu
- hiszpańska zapiekanka ziemniaczana
- pieczone warzywa
Poszczególne liczby są oddzielone przecinkami, a wiersze znakiem nowej linii, plik z rozszerzeniem .csv.
Proces uczenia:
Następnie następuje podział danych na zestaw treningowy i testowy. Zestaw treningowy to 70% danych, testowy 30%. X to zestaw cech, Y zestaw wyników - tutaj etykieta "number".
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
random_state=1)
Drzewa decyzyjne:
Do stworzenia modelu drzew została wykorzystana funkcja DecisionTreeClassifier. Pierwsze drzewo przyjmuje jako kryterium indeks Gini (domyślny), drugie drzewo entropię.
clf = DecisionTreeClassifier()
clf = DecisionTreeClassifier(criterion="entropy")
Do modelu drzewa zostały wczytane dane, dzięki funkcji fit.
clf = clf.fit(X_train, y_train)
Generowane przewidywania są agregowane w zmiennej y_pred, dzięki funckji predict.
y_pred = clf.predict(X_test)
Następnie wyświetlana jest akuratność dla modelu danych o wybranym kryterium, dzięki funkcji accuracy_score.
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
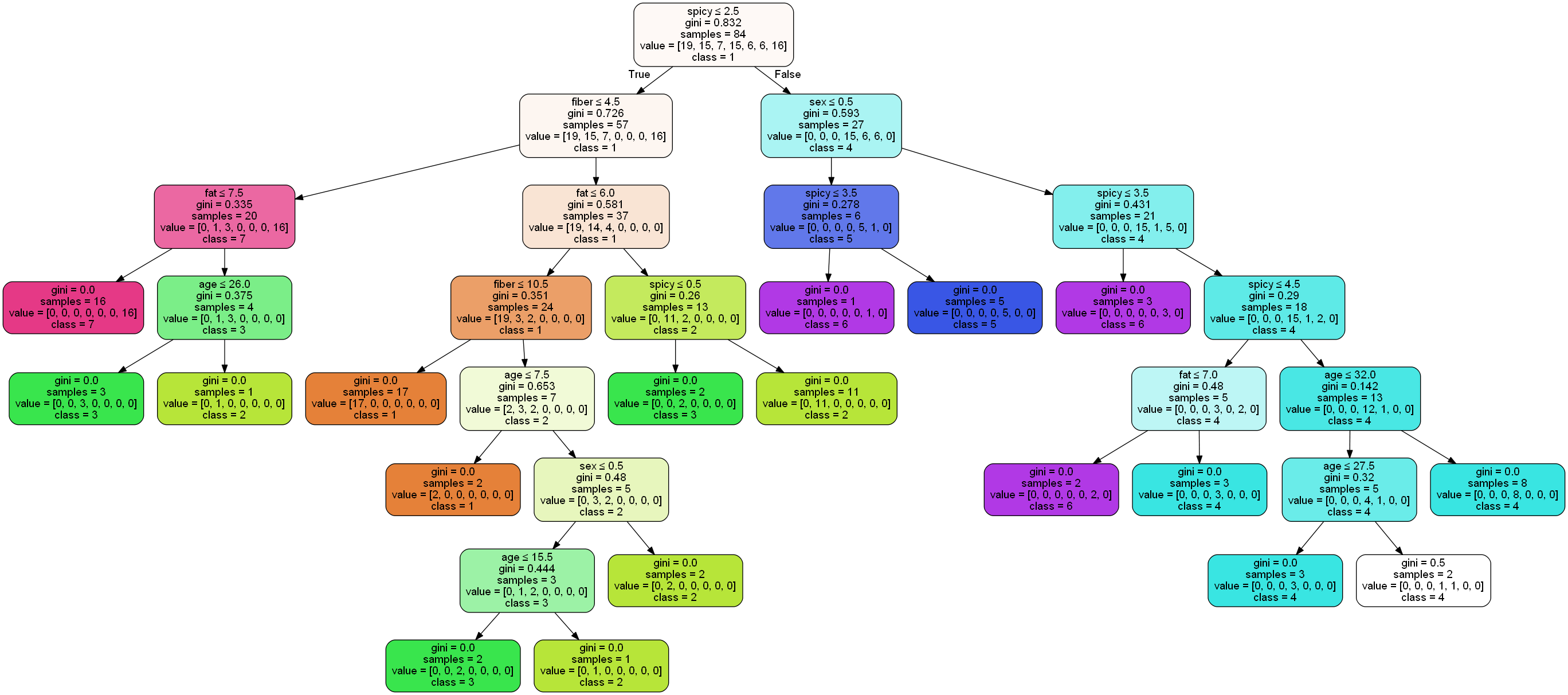
Drzewo decyzyjne ma swoją reprezentację graficzną, która utworzona została dzięki bibliotece IPython, graphviz, StringIO.
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True, feature_names=feature_cols,
class_names=['1', '2', '3', '4', '5', '6', '7'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('polecanie_1.png')
Image(graph.create_png())
Na końcu model (z większym wskaźnikiem trafności) zostaje zapisany do pliku z rozszerzeniem sav.
file_name = 'final_model.sav'
joblib.dump(clf, file_name)
Integracja z projektem
Po uruchomieniu programu i wybraniu na ekranie głównym opcji Ciężkostrawność dań, uruchomiona zostaje funkcja Evaluate(), która ładuje z pliku model drzewa. Zainicjowany zostaje również przykładowy stan restauracji (dodanie kilku klientów, przypisanie im stołów i talerzy). Wywoływany jest też przykładowy ruch kelnera, który podchodzi do kilku stolików i pomaga w ocenie strawności dania, przy pomocy funkcji predictDigest():
def predictDigest(dish, client, model):
data = []
data.append(client.age)
data.append(dish.fatContent)
data.append(dish.fiberContent)
data.append(client.sex)
data.append(dish.spicy)
prediction = model.predict([data])
if prediction == 1:
messagebox.showinfo("opinia", "Z tym może być ciężko. " + str(data))
return prediction
else:
messagebox.showinfo("opinia", "Z tym nie będzie tak źle! " + str(data))
return prediction
Funkcja jako parametry przyjmuje obiekty danie, klient i załadowany model. Parametry potrzebne modelowi do wyznaczenia wyniku pobierane są z odpowiednich obiektów i jako tablica przekazywane do funkcji predict(). Następnie, w zależności od otrzymanego wyniku wyświetlany jest odpowiedni komunikat i dane jakie podlegały ocenie.
Pola fatContent, fiberContent, spicy klasy Dish w momencie tworzenia instancji klasy są ustawiane na losowo wygenerowaną liczbę z odpowiednich przedziałów:
self.fatContent = random.randint(0, 16)
self.fiberContent = random.randint(0, 16)
self.spicy = random.randint(0, 1)
Po zakończeniu trasy wyświetlany jest stosowny komunikat, a aplikacja zostaje wyłączona.