51 KiB
Wyszukiwarka - szybka i sensowna
Roboczy przykład
Zakładamy, że mamy pewną kolekcję dokumentów $D = {d_1, \ldots, d_N}$. ($N$ - liczba dokumentów w kolekcji).
{-# LANGUAGE OverloadedStrings #-}
import Data.Text hiding(map, filter, zip)
import Prelude hiding(words, take)
collectionD :: [Text]
collectionD = ["Ala ma kota.", "Podobno jest kot w butach.", "Ty chyba masz kota!", "But chyba zgubiłem."]
-- Operator (!!) zwraca element listy o podanym indeksie
-- (Przy większych listach będzie nieefektywne, ale nie będziemy komplikować)
collectionD !! 1Podobno jest kot w butach.
Wydobycie tekstu
Przykładowe narzędzia:
- pdftotext
- antiword
- Tesseract OCR
- Apache Tika - uniwersalne narzędzie do wydobywania tekstu z różnych formatów
Normalizacja tekstu
Cokolwiek robimy z tekstem, najpierw musimy go _znormalizować.
Tokenizacja
Po pierwsze musimy podzielić tekst na _tokeny, czyli wyrazapodobne jednostki. Może po prostu podzielić po spacjach?
tokenizeStupidly :: Text -> [Text]
-- words to funkcja z Data.Text, która dzieli po spacjach
tokenizeStupidly = words
tokenizeStupidly $ Prelude.head collectionDAla
ma
kota.
A, trzeba _chociaż odsunąć znaki interpunkcyjne. Najprościej użyć wyrażenia regularnego. Warto użyć unikodowych własności znaków i konstrukcji \p{...}.
{-# LANGUAGE QuasiQuotes #-}
import Text.Regex.PCRE.Heavy
tokenize :: Text -> [Text]
tokenize = map fst . scan [re|[\p{L}0-9]+|\p{P}|]
tokenize $ Prelude.head collectionDAla
ma
kota
.
Cała kolekcja stokenizowana:
map tokenize collectionDAla
ma
kota
.
Podobno
jest
kot
w
butach
.
Ty
chyba
masz
kota
!
But
chyba
zgubiłem
.
Problemy z tokenizacją
Język angielski
tokenize "I use a data-base"I
use
a
data
-
base
tokenize "I use a database"I
use
a
database
tokenize "I use a data base"I
use
a
data
base
tokenize "I don't like Python"I
don
'
t
like
Python
tokenize "+0018 555 555 122"0018
555
555
122
tokenize "+0018555555122"0018555555122
tokenize "Which one is better: C++ or C#?"Which
one
is
better
:
C
or
C
#
?
Inne języki?
tokenize "Rechtsschutzversicherungsgesellschaften wie die HUK-Coburg machen es bereits seit geraumer Zeit vor:"Rechtsschutzversicherungsgesellschaften
wie
die
HUK
-
Coburg
machen
es
bereits
seit
geraumer
Zeit
vor
:
tokenize "今日波兹南是贸易、工业及教育的中心。波兹南是波兰第五大的城市及第四大的工业中心,波兹南亦是大波兰省的行政首府。也舉辦有不少展覽會。是波蘭西部重要的交通中心都市。"今日波兹南是贸易
、
工业及教育的中心
。
波兹南是波兰第五大的城市及第四大的工业中心
,波兹南亦是大波兰省的行政首府
。
也舉辦有不少展覽會
。
是波蘭西部重要的交通中心都市
。
tokenize "l'ordinateur"l
'
ordinateur
Lematyzacja
_Lematyzacja to sprowadzenie do formy podstawowej (lematu), np. "krześle" do "krzesło", "zrobimy" do "zrobić" dla języka polskiego, "chairs" do "chair", "made" do "make" dla języka angielskiego.
Lematyzacja dla języka polskiego jest bardzo trudna, praktycznie nie sposób wykonać ją regułowo, po prostu musimy się postarać o bardzo obszerny _słownik form fleksyjnych.
Na potrzeby tego wykładu stwórzmy sobie mały słownik form fleksyjnych w postaci tablicy asocjacyjnej (haszującej).
import Data.Map as Map hiding(take, map, filter)
mockInflectionDictionary :: Map Text Text
mockInflectionDictionary = Map.fromList [
("kota", "kot"),
("butach", "but"),
("masz", "mieć"),
("ma", "mieć"),
("buta", "but"),
("zgubiłem", "zgubić")]
lemmatizeWord :: Map Text Text -> Text -> Text
lemmatizeWord dict w = findWithDefault w w dict
lemmatizeWord mockInflectionDictionary "butach"
-- a tego nie ma w naszym słowniczku, więc zwracamy to samo
lemmatizeWord mockInflectionDictionary "butami"
lemmatize :: Map Text Text -> [Text] -> [Text]
lemmatize dict = map (lemmatizeWord dict)
lemmatize mockInflectionDictionary $ tokenize $ collectionD !! 0
but
butami
Ala
mieć
kot
.
Pytanie: Nawet w naszym słowniczku mamy problemy z niejednoznacznością lematyzacji. Jakie?
Obszerny słownik form fleksyjnych dla języka polskiego: http://zil.ipipan.waw.pl/PoliMorf?action=AttachFile&do=view&target=PoliMorf-0.6.7.tab.gz
Stemowanie
Stemowanie (rdzeniowanie) obcina wyraz do _rdzenia niekoniecznie będącego sensownym wyrazem, np. "krześle" może być rdzeniowane do "krześl", "krześ" albo "krzes", "zrobimy" do "zrobi".
- stemowanie nie jest tak dobrze określone jak lematyzacja (można robić na wiele sposobów)
- bardziej podatne na metody regułowe (choć dla polskiego i tak trudno)
- dla angielskiego istnieją znane algorytmy stemowania, np. algorytm Portera
- zob. też program Snowball z regułami dla wielu języków
Prosty stemmer "dla ubogich" dla języka polskiego to obcinanie do sześciu znaków.
poorMansStemming :: Text -> Text
poorMansStemming = take 6
poorMansStemming "zrobimy"
poorMansStemming "komputerami"
poorMansStemming "butach"zrobim
komput
butach
_Stop words
Często wyszukiwarki pomijają krótkie, częste i nieniosące znaczenia słowa - _stop words (słowa przestankowe).
isStopWord :: Text -> Bool
isStopWord "w" = True
isStopWord "jest" = True
isStopWord "że" = True
-- przy okazji możemy pozbyć się znaków interpunkcyjnych
isStopWord w = w ≈ [re|^\p{P}+$|]
isStopWord "kot"
isStopWord "!"
False
True
removeStopWords :: [Text] -> [Text]
removeStopWords = filter (not . isStopWord)
removeStopWords $ tokenize $ Prelude.head collectionD Ala
ma
kota
Pytanie: Jakim zapytaniom usuwanie _stop words może szkodzić? Podać przykłady dla języka polskiego i angielskiego.
Normalizacja - różności
W skład normalizacji może też wchodzić:
- poprawianie błędów literowych
- sprowadzanie do małych liter (lower-casing czy raczej case-folding)
- usuwanie znaków diakrytycznych
toLower "ŻDŹBŁO"żdźbło
toCaseFold "ŹDŹBŁO"źdźbło
Pytanie: Kiedy _case-folding da inny wynik niż lower-casing? Jakie to ma praktyczne znaczenie?
Normalizacja jako całościowy proces
Najważniejsza zasada: dokumenty w naszej kolekcji powinny być normalizowane w dokładnie taki sposób, jak zapytania.
Efektem normalizacji jest zamiana dokumentu na ciąg _termów (ang. terms), czyli znormalizowanych wyrazów.
Innymi słowy po normalizacji dokument $d_i$ traktujemy jako ciąg termów $t_i^1,\dots,t_i^{|d_i|}$.
normalize :: Text -> [Text]
normalize = removeStopWords . map toLower . lemmatize mockInflectionDictionary . tokenize
normalize $ collectionD !! 3but
chyba
zgubić
Zbiór wszystkich termów w kolekcji dokumentów nazywamy słownikiem (ang. _vocabulary), nie mylić ze słownikiem jako strukturą danych w Pythonie (dictionary).
$$V = \bigcup_{i=1}^N \{t_i^1,\dots,t_i^{|d_i|}\}$$
(To zbiór, więc liczymy bez powtórzeń!)
import Data.Set as Set hiding(map)
getVocabulary :: [Text] -> Set Text
getVocabulary = Set.unions . map (Set.fromList . normalize)
getVocabulary collectionDfromList ["ala","but","chyba","kot","mie\263","podobno","ty","zgubi\263"]
Jak wyszukiwarka może być szybka?
_Odwrócony indeks (ang. inverted index) pozwala wyszukiwarce szybko szukać w milionach dokumentów. Odwrócoy indeks to prostu... indeks, jaki znamy z książek (mapowanie słów na numery stron/dokumentów).
collectionDNormalized = map normalize collectionD
documentToPostings :: ([Text], Int) -> Set (Text, Int)
documentToPostings (d, ix) = Set.fromList $ map (\t -> (t, ix)) d
documentToPostings (collectionDNormalized !! 2, 2)
fromList [("chyba",2),("kot",2),("mie\263",2),("ty",2)]collectionToPostings :: [[Text]] -> Set (Text, Int)
collectionToPostings coll = Set.unions $ map documentToPostings $ zip coll [0..]
collectionToPostings collectionDNormalizedfromList [("ala",0),("but",1),("but",3),("chyba",2),("chyba",3),("kot",0),("kot",1),("kot",2),("mie\263",0),("mie\263",2),("podobno",1),("ty",2),("zgubi\263",3)]updateInvertedIndex :: (Text, Int) -> Map Text [Int] -> Map Text [Int]
updateInvertedIndex (t, ix) invIndex = insertWith (++) t [ix] invIndex
getInvertedIndex :: [[Text]] -> Map Text [Int]
getInvertedIndex = Prelude.foldr updateInvertedIndex Map.empty . Set.toList . collectionToPostings
getInvertedIndex collectionDNormalizedfromList [("ala",[0]),("but",[1,3]),("chyba",[2,3]),("kot",[0,1,2]),("mie\263",[0,2]),("podobno",[1]),("ty",[2]),("zgubi\263",[3])]Relewantność
Potrafimy szybko przeszukiwać znormalizowane dokumenty, ale które dokumenty są ważne (_relewantne) względem potrzeby informacyjnej użytkownika?
Zapytania boole'owskie
pizzeria Poznań dowóztopizzeria AND Poznań AND dowózczypizzera OR POZNAŃ OR dowóz- `(pizzeria OR pizza OR tratoria) AND Poznań AND dowóz
pizzeria AND Poznań AND dowóz AND NOT golonka
Jak domyślnie interpretować zapytanie?
- jako zapytanie AND -- być może za mało dokumentów
- rozwiązanie pośrednie?
- jako zapytanie OR -- być może za dużo dokumentów
Możemy jakieś miary dopasowania dokumentu do zapytania, żeby móc posortować dokumenty...
Mierzenie dopasowania dokumentu do zapytania
Potrzebujemy jakieś funkcji $\sigma : Q x D \rightarrow \mathbb{R}$.
Musimy jakoś zamienić dokumenty na liczby, tj. dokumenty na wektory liczb, a całą kolekcję na macierz.
Po pierwsze ponumerujmy wszystkie termy ze słownika.
voc = getVocabulary collectionD
vocD :: Map Int Text
vocD = Map.fromList $ zip [0..] $ Set.toList voc
invvocD :: Map Text Int
invvocD = Map.fromList $ zip (Set.toList voc) [0..]
vocD
invvocD
vocD ! 0
invvocD ! "chyba"
fromList [(0,"ala"),(1,"but"),(2,"chyba"),(3,"kot"),(4,"mie\263"),(5,"podobno"),(6,"ty"),(7,"zgubi\263")]
fromList [("ala",0),("but",1),("chyba",2),("kot",3),("mie\263",4),("podobno",5),("ty",6),("zgubi\263",7)]ala
2
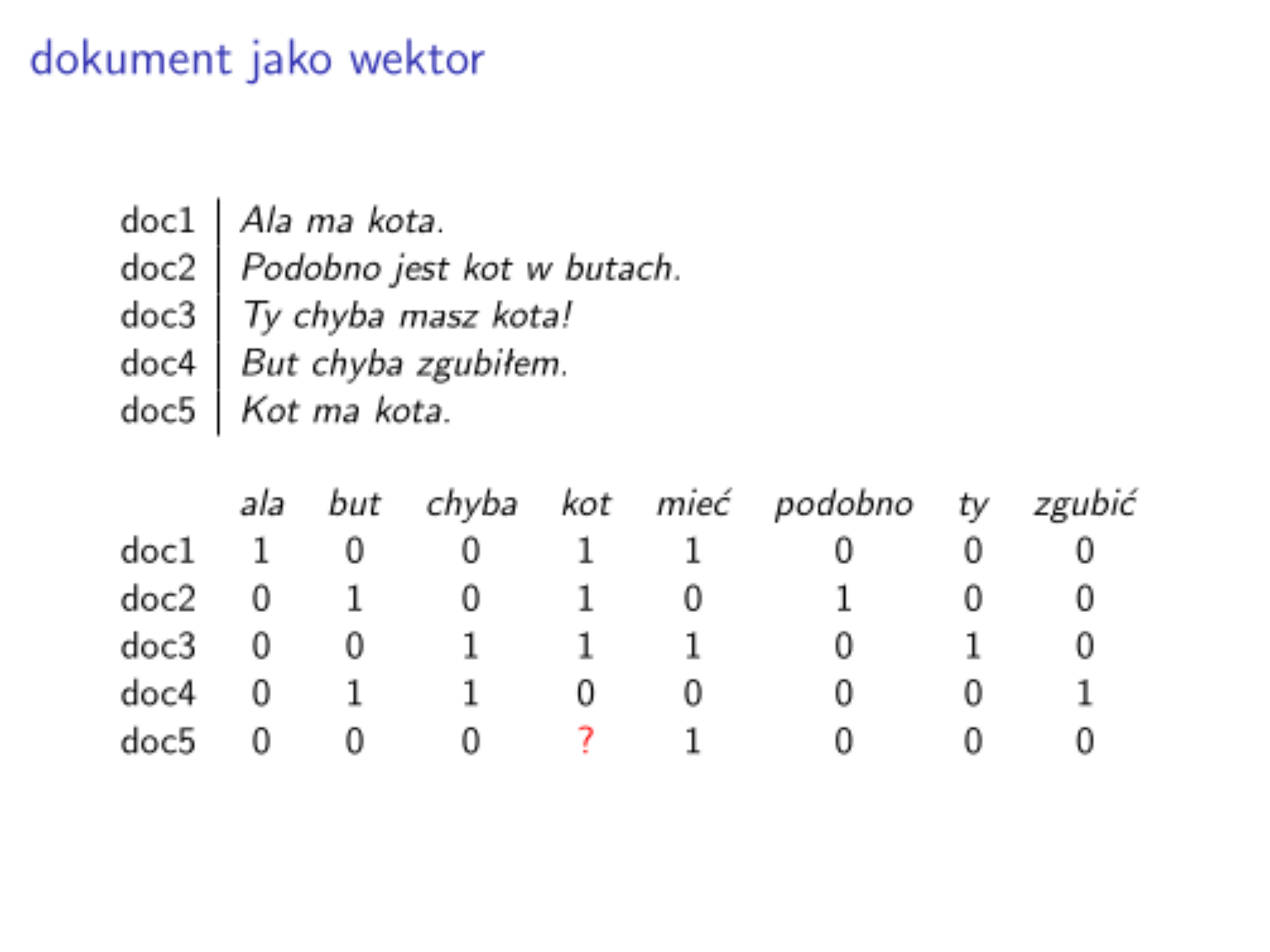
Napiszmy funkcję, która _wektoryzuje znormalizowany dokument.
vectorize :: Int -> Map Int Text -> [Text] -> [Double]
vectorize vecSize v doc = map (\i -> count (v ! i) doc) $ [0..(vecSize-1)]
where count t doc
| t `elem` doc = 1.0
| otherwise = 0.0
vocSize = Set.size voc
(collectionDNormalized !! 2)
vectorize vocSize vocD (collectionDNormalized !! 2)
ty
chyba
mieć
kot
[0.0,0.0,1.0,1.0,1.0,0.0,1.0,0.0]
Jak inaczej uwzględnić częstość wyrazów?
$\tf_{t,d}$
$1+\log(\tf_{t,d})$
$0.5 + \frac{0.5 \times \tf_{t,d}}{max_t(\tf_{t,d})}$
Odwrotna częstość dokumentowa
Czy wszystkie wyrazy są tak samo ważne?
NIE. Wyrazy pojawiające się w wielu dokumentach są mniej ważne.
Aby to uwzględnić, przemnażamy frekwencję wyrazu przez _odwrotną częstość w dokumentachinverse document frequency):
$$\idf_t = \log \frac{N}{\df_t},$$
gdzie:
$\idf_t$ - odwrotna częstość wyrazu $t$ w dokumentach
$N$ - liczba dokumentów w kolekcji
$\df_f$ - w ilu dokumentach wystąpił wyraz $t$?
Dlaczego idf?
term $t$ wystąpił...
- w 1 dokumencie, $\idf_t = \log N/1 = \log N$
- 2 razy w kolekcji, $\idf_t = \log N/2$ lub $\log N$
- 3 razy w kolekcji, $\idf_t = \log N/(N/2) = \log 2$
- we wszystkich dokumentach, $\idf_t = \log N/N = \log 1 = 0$
Co z tego wynika?
Zamiast $\tf_{t,d}$ będziemy w wektorach rozpatrywać wartości:
$$\tfidf_{t,d} = \tf_{t,d} \times \idf_{t}$$
Teraz zdefiniujemy _overlap score measure:
$$\sigma(q,d) = \sum_{t \in q} \tfidf_{t,d}$$