23 KiB

Inżynieria uczenia maszynowego
3. System ciągłej integracji na przykładzie Jenkins [laboratoria]
Tomasz Ziętkiewicz (2023)

Ciągła integracja
- Jest to praktyka rozwoju projektów informatycznych polegająca na częstym włączaniu nowych zmian do głównej gałęzi (branch)
- Dzięki jej stosowaniu nie dochodzi do konfliktów przy łączeniu (mergowaniu) gałęzi rozwojowej (feature branch) z główną (master)
- Żeby stosować tę technikę, zmiany muszą być za każdym razem przetestowane, we wspólnym środowisku, tak, żeby działały u innych deweloperów
- Stąd narodziła się potrzeba stosowania systemów automatycznej ciągłej integracji
Systemy ciągłej integracji
- Umożliwiają utomatyczne :
- budowanie
- testowanie
- wydawanie oprogramowania, oraz automatyczne (lub ręczne) wykonywanie dowolnych "zadań"
- Zapewniają:
- wspólne środowisko do testowania zmian, replikowania błędów
- łatwość monitorowania zmian zachodzących w oprogramowaniu
- środowisko do integracji ze sobą części składowych (np. modułów, modeli) w jedną całość
- środowisko, w którym można stworzyć prosty graficzny interfejs służący do uruchamiania zadań z poziomu przeglądarki
Systemy ciągłej integracji
- Jenkins

- Bamboo

- Circle CI

- Team City

- Gitlab CI

Jenkins
- https://www.jenkins.io/
- System ciągłej integracji napisany w języku Java
- Pierwszy release: 2011
- Licencja Open Source (MIT)
- Dużo pluginów
- Aktywny rozwój, wspierany przez The Continuous Delivery Foundation i firmę Cloud Bees
- Działa jako aplikacja webowa z graficznym interfejsem
- Posiada też REST i CLI API
Terminologia
- Job, aka. Pipleine (Projekt) - podstawowa jednostka organizacji pracy wykonywanej przez Jenkinsa.
- Posiada swoją konfigurację, która określa jakie polecenia będą wykonywane w jego ramach.
- Jeden pipeline może być wykonany wiele razy, za każdym razem tworząc nowe _Zadanie (Build).
Przykładowy pipeline: https://tzietkiewicz.vm.wmi.amu.edu.pl:8081/job/hello-world/
- Build (Zadanie) - instancja uruchomionego projektu. Może być w trakcie wykonywania, albo zakończona z jednym z rezultatów:
- Successful

- Unstable

- Aborted

- Failed
 Np: https://tzietkiewicz.vm.wmi.amu.edu.pl:8081/job/hello-world/2/
Np: https://tzietkiewicz.vm.wmi.amu.edu.pl:8081/job/hello-world/2/ - Śledzenie wyników działania buildu jak i debugowanie ewentualnych problemów ułatwiają:
- Wyjście z konsoli (Console Output) - tutaj widać logi wypisywane zarówno przez polecenia/funkcje Jenkinsowe jak i standardowe wyjście / wyjście błędów wykonywanych poleceń systemowych
- Workspace - to katalog roboczy, w którym uruchamiane są polecenia. Tutaj zostaje sklonowane repozytorium (jeśli je klonujemy), tu wywoływane będę polecenia systemowe. Można je przeglądać z poziomu przeglądarki, np. tutaj
- Każdy uruchomiony build można zatrzymać (abort) co powoduje zaprzestanie jego wykonywania
- Build zakończony można usunąć (np. jeśli przez przypadek wypisaliśmy na konsolę nasze hasło)
- Successful
Terminologia c.d.
- Step (Krok?) - każdy pipeline to sekwencja kroków do wykonania.
- W przypadku projektów typu Pipeline, kroki definiuje się w pliku "Jenkinsfile"
- Przykładowe kroki:
- wykonanie polecenia w konsoli (sh)
- sklonowanie repozytorium git (checkout)
- archiwizacja artefaktów (archiveArtifacts)
- kopiowanie artefaktów z innego zadania (copyArtifacts)
- uruchomienie innego zadania (build)
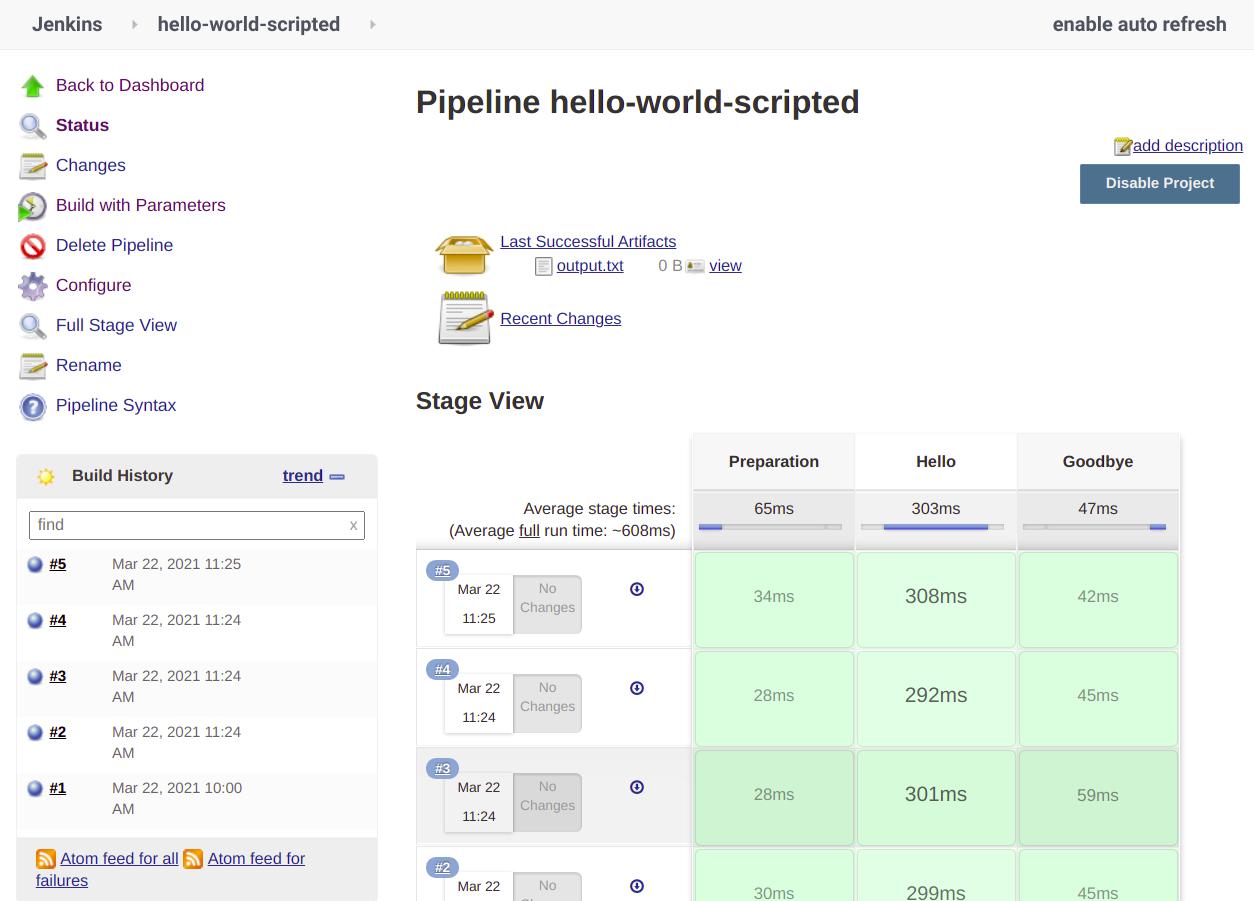
- Stage (Etap?) - Pozwala grupować kroki (steps). Na głównej stronie każdego pipeline możemy zobaczyć wizualizację poszczególnych etapów wraz z czasami ich wykonywania
- Artifact (artefakt) - plik zapisany przez zadanie do późniejszego wykorzytania (przez inne zadania, albo przez użytkownika). Jeśli jednym z kroków zdefiniowanych w projekcie będzie archiwizacja artefaktów, to każde pomyślnie zakończone zadanie będzie miało zapisane swoje artefakty
Dokumentacja
- https://www.jenkins.io/doc/book/pipeline/
- "Pipeline syntax" na stronie każdego projektu, np: https://tzietkiewicz.vm.wmi.amu.edu.pl:8081/job/hello-world/pipeline-syntax/
- Znaki zapytania
 (W konfiguracji joba oraz w "Pipeline Syntax")
(W konfiguracji joba oraz w "Pipeline Syntax")
Zadania [15 pkt]
Na dzisiejszych zajęciach przygotujemy dwa połączone ze sobą zadania:
- Zadanie "s123456-create-dataset":
- pobiera i wybrany na poprzednich zajęciach zbiór danych
- dokonuje "data preprocessing"
- zapisuje wynik jako artefakt
- Zadanie "s123456-dataset-stats":
- obliczy statystyki dla tego zbioru
- zapisze je jako artefakty
Polecenia
1. Zaloguj się
- zaloguj się na https://tzietkiewicz.vm.wmi.amu.edu.pl:8081 za pomocą konta wydziałowego (jak w laboratoriach WMI)
2. Utwórz nowy projekt (Job) [1pkt]
Istnieje kilka rodzajów projektów w Jenkinsie.
Po kliknięciu "Nowy projekt" zobaczymy listę dostępnych rodzajów projektów. Nas interesuje projekt typu "Pipeline".
Jako nazwę wpisz "s123456-create-dataset" (w miejsce 123456 proszę wstawić swój numer indeksu)
3. Definicja Pipeline [2pkt]
Projekty typu Pipeline definiuje się w pliku Jenkinsfile za pomocą skryptu napisanego w jednym z dwóch dostępnych DSL (Domain Specific Language):
- Scripted pipeline (podzbiór języka Groovy)
- Declarative pipeline
Pierwszy z nich daje większe możliwości, drugi jest łatwiejszy, lepiej udokumentowany, ale ma mniejszą siłę ekpresji.
Fragmenty kodu można również generować przy pomocy kreatora, dostępnego pod linkiem Pipeline syntax na stronie każdego projektu. Jest to bardzo przydatna funkcjonalność, nie tylko dla początkujących użytkowników
Jenkinsfile może być wprowadzony bezpośrednio z poziomu przeglądarki, albo pobrany z repozytorium.
Zacznijmy od pierwszej opcji. Jako przykładowego pipeline użyj przykładu Hello World podanego na https://jenkins.io/doc/book/pipeline/getting-started/
Zapisz projekt i spróbuj go uruchomić (przycisk "Uruchom"/"Run" na głównej stronie projektu).
Przykładowy declarative Pipeline (https://tzietkiewicz.vm.wmi.amu.edu.pl:8081/job/hello-world/):
pipeline {
agent any
//Definijuemy parametry, które będzie można podać podczas wywoływania zadania
parameters {
string (
defaultValue: 'Hello World!',
description: 'Tekst, którym chcesz przywitać świat',
name: 'INPUT_TEXT',
trim: false
)
}
stages {
stage('Hello') {
steps {
//Wypisz wartość parametru w konsoli (To nie jest polecenie bash, tylko groovy!)
echo "INPUT_TEXT: ${INPUT_TEXT}"
//Wywołaj w konsoli komendę "figlet", która generuje ASCI-art
sh "figlet \"${INPUT_TEXT}\" | tee output.txt"
}
}
stage('Goodbye!') {
steps {
echo 'Goodbye!'
//Zarchiwizuj wynik
archiveArtifacts 'output.txt'
}
}
}
}
Przykładowy scripted Pipeline (https://tzietkiewicz.vm.wmi.amu.edu.pl:8081/job/hello-world-scripted/):
node {
stage('Preparation') {
properties([
parameters([
string(
defaultValue: 'Hello World!',
description: 'Tekst do wyświetlenie',
name: 'INPUT_TEXT',
trim: false
)
])
])
}
stage('Hello') {
//Wypisz wartość parametru w konsoli (To nie jest polecenie bash, tylko groovy!)
echo "INPUT_TEXT: ${INPUT_TEXT}"
//Wywołaj w konsoli komendę "figlet", która generuje ASCI-art
sh "figlet \"${INPUT_TEXT}\" | tee output.txt"
}
stage('Goodbye') {
echo 'Goodbye!'
//Zarchiwizuj wynik
archiveArtifacts 'output.txt'
}
}
4. Repozytorium [2 pkt]
Jeśli jeszcze tego nie zrobiłaś/zrobiłeś, stwórz nowe _publiczne repozytorium ium_s123456 na wydziałowym serwerze (https://laboratoria.wmi.amu.edu.pl/uslugi/pozostale-uslugi/git/) W przypadku problemów z utworzeniem repozytorium zdalnie, może być to również dodwolne inne, publicznie dostępne repozytorium, np. na GitHub.
Sklonuj repozytorium lokalnie zgodnie ze wskazówkami wyświetlonymi po jego utworzeniu.
Utwórz plik "Jenkinsfile" (zawartość taka sama jak w punkcie 3.) i dodaj go do repozytorium.
W ustawieniach (konfiguracji) projektu przełącz "Pipeline definition" na "Pipeline script from SCM" i podaj ścieżkę do nowo utworzonego repozytorim.
Projekt powinien się uruchamiać za każdym razem, kiedy pojawią się nowe zmiany w repozytorium: "Konfiguracja" -> "Build Triggers" -> "Poll SCM"
W razie problemów z klonowaniem/pushowaniem repozytorium, użyj protokołu ssh zamiast https (przy kopiowaniu ścieżki do repozytorium). Będzie to wymagało skopiowania zawartości pliku ~/.ssh/id_rsa.pub i wklejenia go w ustawieniach wydziałowego gita w zakładce SSH Keys
5. Zapisanie zbioru danych [4 pkt]
Edytuj zawartość Jenkinsfile tak, żeby realizował on następujące zadania:
- Sklonowanie repozytorium git (krok "checkout: Check out from version control")
- Wywołanie skryptu shella (krok "sh: Shell Script").
- Skrypt powinien pobrać zbiór danych i zapisać wyniki jako artefakty
- Proszę też zasymulować przetwarzanie pliku, np. podział na podzbiory (shuf + head/tail), przycięcie do określonej długości (head/tail) lub usunięcie niektórych kolumn (cut).
- Domyślnie tutaj będzie skrypt, który napisali Państwo jako zadanie 1., ale ze względu na brakujące zależności, zapewne nie będzie on działać (rozwiążemy to na następnych zajęciach, korzystając z Dockera). Dlatego proszę w tym celu stworzyć prosty skrypt bash (*.sh).
- Skrypt powinien być zapisany w repozytorium. Unikamy wpisywania treści skryptów bezpośrednio w Jenkinsfile!
- Skrypt powinien zapisywać wyniki swojego działania do pliku
- Plik powstały w kroku 2. należy zarchiwizować (krok "archiveArtifacts"), tak, żeby mógł być wykorzystany przez kolejne projekty.
6. Hasło do Kaggle
Jeśli pobierasz swój zbiór z Kaggle, to możesz mieć problem z uwierzytelnieniem.
Żeby kaggle CLI mogło połączyć się z Kaggle API, musi mieć podaną nazwę użytkownika i token.
Kiedy używamy CLI lokalnie, korzysta ono z ściągniętego przez nas wcześniej pliku ~/.kaggle/kaggle.json, zawierającego nazwę użytkownika i hasło
Zadania na Jenkinsie są wywoływane w systemie przez specjalnego użytkownika (jenkins). Użytkownik ten nie ma w swoim katalogu domowym pliku kaggle.json, więc wywołania kaggle CLI się nie powiodą.
Na szczęście, Kaggle CLI umożliwia podanie danych uwierzytelniających w postaci zmiennych środowiskowych link:
export KAGGLE_USERNAME=datadinosaur export KAGGLE_KEY=xxxxxxxxxxxxxxJenkins natomiast umożliwia utworzenie parametru typu password, którego wartość nie jest nigdzie zapisywana (wartości pozostałych parametrów są zapisywane w zakładce "Parameters" każdego build-a, np. tutaj
konstukcja
withEnvw Jenkinsfile, pozwala wywołać wszystkie otoczone nią polecenia z wyeksportowanymi wartościami zmiennych systemowych. Pozwala to np. przekazać wartości parametrów zadania Jenkinsowego do shella (poleceń wywoływanych zsh).Zwróć jednak uwagę na to, w jaki sposób odwołujesz się do zmiennej z hasłem: https://www.jenkins.io/doc/book/pipeline/jenkinsfile/#string-interpolation !
ten sam rezultat co przy wykorzystaniu
withEnvmożna by osiągnąć wywołując:sh "KAGGLE_USERNAME=${params.KAGGLE_USERNAME} KAGGLE_KEY=${params.KAGGLE_KEY} kaggle datasets list, ale ten pierwszy wydahe się bardziej eleganckiPoniżej przykładowy projekt, który pokazuje jak wywołać Kaggle CLI używając hasła podanego w parametrach zadania:
https://tzietkiewicz.vm.wmi.amu.edu.pl:8081/job/kaggle-CLI-example/
node { stage('Preparation') { properties([ parameters([ string( defaultValue: 'tomaszzitkiewicz', description: 'Kaggle username', name: 'KAGGLE_USERNAME', trim: false ), password( defaultValue: '', description: 'Kaggle token taken from kaggle.json file, as described in https://github.com/Kaggle/kaggle-api#api-credentials', name: 'KAGGLE_KEY' ) ]) ]) } stage('Build') { // Run the maven build withEnv(["KAGGLE_USERNAME=${params.KAGGLE_USERNAME}", "KAGGLE_KEY=${params.KAGGLE_KEY}" ]) { sh 'echo KAGGLE_USERNAME: $KAGGLE_USERNAME' sh 'kaggle datasets list' } } }
7. Parametry zadania [1 pkt]
- Dodaj do projektu
s123456-create-datasetparametr teksotwyCUTOFF, który umożliwi zdefiniowanie wielkości odcięcia zbioru danych (czyli obetnie liczbę przykładów doCUTOFFpierwszych/losowych przykładów). - Wykorzystaj parametr w wywołaniu skryptu tworzącego zbiór
- generowanie kodu definiującego parametry poprzez "Pipeline syntax -> Snippet Generator":
- wybierzz listy pozycji "Properties: Set job properties"
- zaznacz "This project is parameterized"
- Kliknij na "Add parameter" i wybierz rodzaj parametru
6. Statystki [5 pkt]
Stwórz projekt (job) s123456-dataset-stats, który zrealizuje następujące kroki:
- Sklonuje repozytorium git
- Skopiuje zarchiwizowane pliki ze zbiorem danych z artefaktów projektu s123456-create-dataset
- użyj kroku "copyArtifacts"
- możesz wygenerować potrzebny kod za pomocą generatorów w "Pipeline Syntax")
- dodaj paremetr typu "Build selector for Copy artifact", w którym będziesz mógł ustalić z którego builda zadania s123456-create-dataset chcesz skopiować artefakt. Wartość tego parametru będziesz musiał przekazać jako parametr
which build-> "Specified by a build parameter" - przykładowy kod copyArtifact:
copyArtifacts fingerprintArtifacts: true, projectName: 'MY_PROJECT', selector: buildParameter('BUILD_SELECTOR') - przykładowy kod definicji parametru:
properties([parameters([ buildSelector( defaultSelector: lastSuccessful(), description: 'Which build to use for copying artifacts', name: 'BUILD_SELECTOR') ])])
- Wywoła skrypt shella (krok "sh: Shell Script").
- Domyślnie tutaj znajdzie się wywołanie naszego skryptu liczącego statystyki.
- Ze względu na brakujące zależności, na razie wystarczy, że ten skrypt będzie "liczył" ilość linii w wejściowym pliku (polecenie "wc -l").
- Skrypt powinien być zapisany w repozytorium. Unikamy wpisywania treści skryptów bezpośrednio w Jenkinsfile!
- Skrypt powinien zapisywać wyniki swojego działania do pliku
- Plik powstały w kroku 3. należy archiwizować (krok "archiveArtifacts")