7.6 KiB
Sztuczna Inteligencja 2020 - Raport z podprojektu
Autor: Maksymilian Kierski
Raportowany okres: 15.05.2020-26.05.2020
Wybrana metoda uczenia: Splotowe sieci neuronowe (CNN)
Cel podprojektu
Celem podprojektu jest umożliwienie kelnerowi stwierdzenia czy na talerzu znajdującym się na stole jest jeszcze jedzenie, czy już go nie ma. Do tego celu zastosowałem splotowe sieci neuronowe (CNN), oraz biblioteki:
- numpy, cv2 - tworzenie danych wejściowych
- tensorflow keras - tworzenie modelu
- tensorboard - analiza modelów
Uczenie modelu
Dane wejściowe
Dane wejściowe składają się z dwóch rodzajów zdjęć talerzy, full - pełnych, oraz empty - pustych. Na początku, aby nasz model mógł się nauczać potrzebujemy nasze dane wejściowe odpowiednio przetworzyć.
for category in CATEGORIES:
path = os.path.join(DATADIR, category)
class_num = CATEGORIES.index(category)
for img in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path, img),
cv2.IMREAD_GRAYSCALE)
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
training_data.append([new_array, class_num])
except Exception as e:
pass
random.shuffle(training_data)
Tutaj nasze dane wejściowe są odpowiednio przetwarzane. Na początku zdjęcie jest sczytywane, oraz przetwarzane aby każdy pixel był w skali szarości 0 - 255 (ponieważ kolor w tym zadaniu według mnie, nie odgrywa ważnej roli). Następnie skalowany jest do mniejszych rozmiarów i w końcu jako macierz zadeklarowanych wymiarów trafia do tablicy ze swoją etykietą. Na końcu cała tablica jest przetasowywana, aby umożliwić modelowi lepszą naukę.
Teraz dane zostają podzielone na zestaw cech i zestaw etykiet, oraz zostają zapisane do plików za pomocą pickle.
for features, label in training_data:
X.append(features)
y.append(label)
pickle_in = open(relative_path + 'SavedData/X.pickle', 'rb')
X = pickle.load(pickle_in)
pickle_in = open(relative_path + 'SavedData/y.pickle', 'rb')
y = pickle.load(pickle_in)
Tworzenie modelu i proces jego nauki
Wczytywanie danych potrzebnych do nauki modelu
Na początku sczytywane są odpowiednio przygotowane dane (funkcja load_dataset)
pickle_in = open(relative_path + 'SavedData/X.pickle', 'rb')
X = pickle.load(pickle_in)
pickle_in = open(relative_path + 'SavedData/y.pickle', 'rb')
y = pickle.load(pickle_in)
return X, y
Wczytywanie danych i normalizacja X, ponieważ używam kolorów w skali szarości 0 - 255, to do normalizacji (skala 0-1) wystarczy przemnożyć każde pole macierzy przez 255. Inicjalizacja tensorboardu, który przyda się nam do analizy stworzonych przez nas modeli.
X = load_dataset()[0]
y = load_dataset()[1]
X = np.array(X).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
y = np.array(y)
X = X / 255.0
tenserboard = TensorBoard(log_dir='{}/logs/{}'.format(relative_path, NAME))
Tworzenie sekwencyjnego modelu splotowych sieci neuronowych
Tutaj inicjalizuje model jako sekwencyjny, czyli w którym każda warstwa wykonywana jest po kolei.
model = Sequential()
Jako iż tworzę splotową sieć neuronową w której podstawową strukturą jest
graph LR
A((splot)) --> B(suma)
B --> C((splot))
C --> D(suma)
D --> E[w pełni połączona warstwa]
E --> F[wynik]
to jako pierwsze tworzę warstwę splotu i sumy.
model.add(Conv2D(64, (3, 3),input_shape=X.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
Warstwa splotu opiera się na 64 filtrach, które sprawdzają pola o powierzchni 9 pixeli. Jak działa splot? Splot to czynność polegająca na pobieraniu oryginalnych danych i tworzeniu z nich mapy cech z pól o zadeklarowanych wymiarach. Jest ich tak dużo jak pozwala na to nam całość naszych danych. Po czym wykonywana jest funkcja aktywacyjna ReLu. A na końcu na naszej wykonujemy pooling z atrybutem max, czyli z wielkości 2 na 2 z naszej warstwy splotu wybieramy największą wartość.
W tym pod projekcie najbardziej efektywne okazało się zastosowanie dwóch takich warstw.
layer size | conv layer | Dense layer |
64 | 1 | 0 | loss: 0.0443 - accuracy: 0.9942 - val_loss: 0.3614 - val_accuracy: 0.7692
64 | 2 | 0 | loss: 0.0931 - accuracy: 0.9625 - val_loss: 0.4772 - val_accuracy: 0.8462
64 | 3 | 0 | loss: 0.2491 - accuracy: 0.9020 - val_loss: 0.3762 - val_accuracy: 0.7949
64 | 1 | 1 | loss: 0.0531 - accuracy: 0.9971 - val_loss: 0.4176 - val_accuracy: 0.8205
64 | 2 | 1 | loss: 0.0644 - accuracy: 0.9798 - val_loss: 0.5606 - val_accuracy: 0.8462
64 | 3 | 1 | loss: 0.1126 - accuracy: 0.9625 - val_loss: 0.5916 - val_accuracy: 0.8205
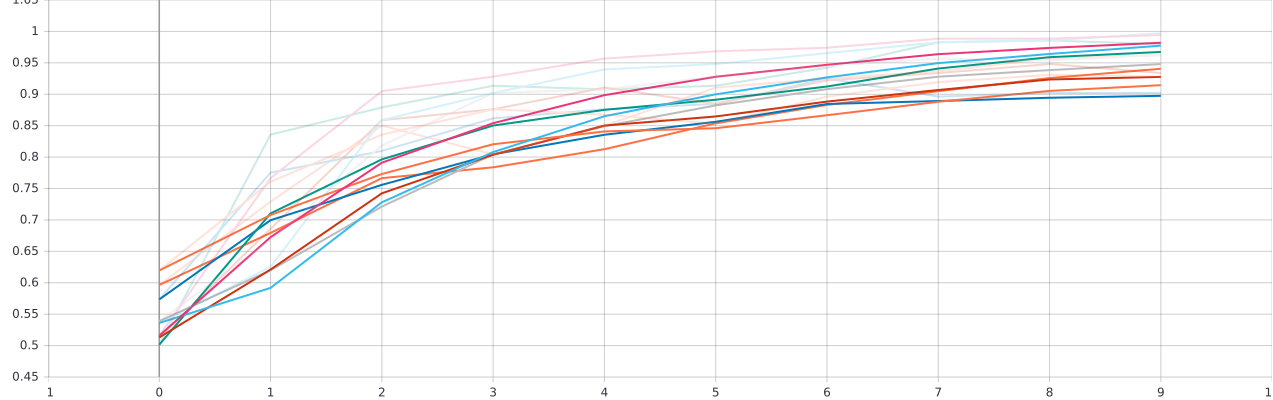
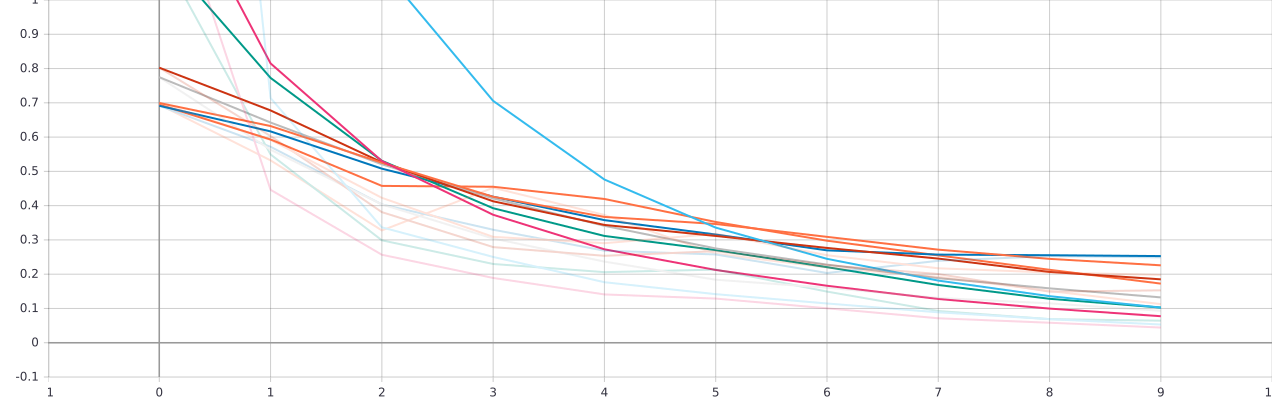
W drugim przypadku nie musimy już zmieniać naszych danych ponieważ pochodzą one z poprzedniej warstwy.
model.add(Conv2D(64, (3, 3),input_shape=X.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
Na koniec spłaszczam naszą trójwymiarową tablice, na macierz stosując funkcje Flatten(), oraz używam warstwę Dense z tylko jednym neuronem, który będzie naszym wynikiem. Funkcja aktywacji jest to oczywiście funkcja sigmoid ponieważ chcemy otrzymać wynik (0-1).
model.add(Flatten())
model.add(Dense(1))
model.add(Activation('sigmoid'))
Następnie zachodzi kompilacja modelu. Używam funkcję straty binary_crosentropy , ponieważ mierzymy się z problemem klasyfikacji binarnej. Problem klasyfikacji binarnej jest wtedy, gdy do rozpatrzenia mamy tylko dwa przypadki, w tym zadaniu talerz z jedzeniem(0) oraz bez jedzenia(1). Optymalizator, który użyłem jest to adam, a za pomocą metrics aktywuje monitorowanie dokładności. Kilka słów o optymalizatorze adam - Adam, jest obecnie zalecany przy większości zadań optymalizacyjnych związanych z uczeniem, ponieważ łączy on zalety Adadelty i RMSprop, a zatem lepiej radzi sobie z większością problemów.
Na sam koniec wywołuję funkcję uczenia, oraz zapisuję model do wykorzystania go w projekcie głównym.
model.fit(X, y, batch_size=32, epochs=10, validation_split=0.1, callbacks=[tenserboard])
model.save(relative_path + 'SavedModels/{}.model'.format(NAME))
Integracja z projektem
Podprojekt wywołujemy naciskając m na klawiaturze, kelner wtedy wybiera losowo stolik i do niego idzie zaimplementowanym wcześniej algorytmem A*. Po dotarciu do wybranego miejsca, możemy wywołać funkcje sprawdzającą talerz use_model_to_predict('img')
def prepare(filepath):
img_array = cv2.imread(filepath, cv2.IMREAD_GRAYSCALE)
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
plt.imshow(img_array, cmap=plt.cm.binary)
plt.show()
return new_array.reshape(-1, IMG_SIZE, IMG_SIZE, 1)
model = tf.keras.models.load_model(relative_path + 'SavedModels/plate-64x2-cnn.model')
prediction = model.predict([prepare(relative_path + 'TestData/' + name + '.jpg')])
return int(prediction[0][0])
Funkcja ta konwertuję zdjęcie zadeklarowane do wylosowanego stolika oraz odpowiednio je konwertuję. Następnie ładuję zadeklarowany przez nas model, który zwraca nam odpowiednią liczbę, która w int() daje 0 lub 1. Odpowiednio 0 to talerz pełny a 1 to pusty. Dzięki czemu funkcją text_speech() możemy wyświetlić odpowiednią informacje na ekranie.