61 KiB
Lista zagadnień egzaminacyjnych
Zagadnienia matematyczne:
1. Podstawowe pojęcia matematyczne: definicja, twierdzenie, warunek konieczny i dostateczny, funkcje (definicje, przykłady, podstawowe własności).
definicja -
twierdzenie -
warunek konieczny -
warunek dostateczny -
funkcje - \
2. Szeregi liczbowe: definicja, przykłady, zbieżność, szereg potęgowy i jego suma.
Szereg liczbowy -
3. Funkcje elementarne (funkcja trygonometryczna, wielomian, funkcja wymierna, funkcje wykładnicza, funkcje potęgowa, funkcja logarytmiczna)
Funkcja trygonometryczna - funkcje matematyczne, wyrażające między innymi stosunki między długościami boków trójkąta prostokątnego względem miar jego kątów wewnętrznych
Funkcja wilomianowa - funkcja, której wzorem jest wielomian, W zasadzie analogicznie do definicji wielomianu jako sumy algebraicznej, funkcję jednej zmiennej możemy nazywać funkcją wielomianową, jeżeli: f(x)=anx^n+an−1x^n−1+...+a1x+a0
Funkcja wymierna - to taka funkcja, która jest ilorazem dwóch wielomianów 2x-3/3x+1
Funkcja wykładnicza -
Funkcja potęgowa -
Funkcja logarytmiczna - \
4. Liczby zespolone.
Liczby zespolone - liczby zespolone są rozszerzeniem liczb rzeczywistych ℝ. Zbiór liczb zespolonych oznaczamy symbolem ℂ. W zbiorze liczb zespolonych można wyciągać pierwiastki z liczb ujemnych. Pierwiastek (parzystego stopnia) z liczby ujemnej jest tzw. liczbą urojoną i zapisujemy go za pomocą jednostki urojonej i. Liczbę i definiujemy tak: i^2=−1
5. Podstawowe pojęcia geometrii analitycznej: równania prostej, okręgu, odległość punktu od prostej.
prosta - pojęcie pierwotne, szczególny przypadek nieograniczonej z obydwu ston krywej o nieskończonym promieniu krzywizny w kazdym punkcie
okrąg - nieskończony zbriór punktów równo oddalonych od jednego zwanym środkiem
odleglość punktu od prostej - \
6. Algorytm eliminacji Gaussa.
Algorytm eliminacji Gaussa - metoda eliminacji Gaussa służy do rozwiązywania układów równań pierwszego stopnia, polega na sprowadzeniu macierzy powstałej z równań do postaci macierzy trójkątnej, czyli o uzyskanie zera pod przekątną (przyjęło się, że pod przekątną jednak można też nad przekątną) macierzy
7. Przestrzenie liniowe, wektory, liniowa niezależność wektorów, baza i wymiar przestrzeni liniowej, macierze, wyznacznik i wektory własne macierzy.
8. Tautologie rachunku zdań, kwantyfikatory, prawa dla kwantyfikatorów; definicje i przykłady.
Tautologie rachunku zdań - wyrazenie zbudowane ze zdan prostych i spójników, które jest zawsze prawdziwe
kwantyfikatory - dla kazdego (A bez poprzecznej kreski), istaniej takie (V)
prawa dla kwantyfikatorów - prawo de Morgana ~Vx p(x) <-> Ax ~p(x); ~Ax p(x) <-> Vx ~p(x)
9. Podstawowe pojęcia teorii mnogości: pojęcie zbioru, aksjomat ekstensjonalności, aksjomaty istnienia zbiorów, stosunek należenia elementu do zbioru.
zbiór - należy do pojęć pierwotnych aksjomatycznej teorii mnogości i nie podaje się jego definicji
aksjomat ekstensjonalności - dwa zbiory mają te same elementy, to są równe. Ponieważ dwa równe zbiory mają te same elementy, to możemy sformułować ten aksjomat tak:
dwa zbiory są równe wtedy i tylko wtedy, gdy mają te same elementy
aksjomaty istnienia zbiorów -
stosunek należenia elementu do zbioru -
10. Relacja równoważności, klasy abstrakcji.
Relacja równowazności - Relację ~ na zbiorze A będziemy nazywać relację równoważności, jeśli ma następujące 3 właściwości:
- zwrotna, czyli dla każdego a\in A, a~ a,
- symetryczna, czyli dla każdych a,b nalezy do A, jeśli a~ b, to b~ a,
- przechodnia, czyli dla każdych a,b,c nalezy do A, jeśli a~ b oraz b~ c, to a~ c.
Klasa abstrakcji - zbiór wszystkich elementów, które są w relacji z danym elementem a nalezy do A, nazywamy klasą abstrakcji a i oznaczamy [a]~.
Czyli [a]~={b nalezy do A: a~ b}. Rodzinę wszystkich klas abstrakcji, oznaczamy A/~ i nazywamy zbiorem ilorazowym.
11. Relacje porządkujące i liniowo porządkujące, zbiory dobrze uporządkowane.
relacja porzadkująca - Relację binarną ρ określoną w zbiorze X nazywamy relacją po- rządkującą (lub relacją częściowego porządku), jeśli jest zwrotna, słabo antysymetryczna i przechodnia. Zbiór X z określoną w nim relacją porządkującą nazywamy zbiorem częściowo uporządko- wanym.
relacja liniwo porządkująca -
zbiór dobrze uporządkowany - zbiór skończony X jest w uporządkowany, gdy jego elementy możemy ułożyć w szereg od 'najmniejszego' do 'największego'
Przykładem relacji liniowego porządku jest relacja „mniejszy lub równy” (≤) określona na zbiorze nieujemnych liczb całkowitych.
12. Funkcje, funkcje różnowartościowe, funkcja ze zbioru X na zbiór Y, iniekcja, suriekcja, bijekcja.
funkcja róznowartościowa - Funkcję f(x) nazywamy różnowartościową w zbiorze A, będącym podzbiorem dziedziny funkcji f(x), jeżeli dla każdych x1,x2 nalezy do A prawdziwa jest implikacja: (x1 nie rowne x2) => f(x1) nie równe f(x2).
iniekcja - funkcja jest injekcją, jeśli różnym elementom dziedziny funkcja przyporządkowuje różne elementy przeciwdziedziny
suriekcja - f:X→Y jest suriekcją, (czyli funkcją „na”) wtedy i tylko wtedy, gdy jej zbiór wartości jest równy zbiorowi końcowemu \
13. Granica funkcji; ciągłość funkcji; własności funkcji ciągłej.
granica funkcji - wartości do jakiej dąży funkcja f(x), wraz z tym jak x dąży do liczby x0.
Szukana wartość jest granicą funkcji f(x) w punkcie x0
ciągłość funkcji - Mówimy, że funkcja f(x) jest ciągła w punkcie x0, jeżeli:
lim{x dązy do x0} f(x)=f(x0)
Zatem funkcja f(x) jest ciągła w punkcie x0 jeżeli:
- ma w punkcie x0 granicę równą g,
- posiada w punkcie x0 wartość f(x0),
- granica g równa jest wartości funkcji f(x0).
14. Pochodna funkcji jednej zmiennej rzeczywistej, jej własności oraz podstawowe zastosowania. Zastosowanie pochodnych do badania funkcji (wyznaczenie ekstremów lokalnych, badania przedziałów monotoniczności, badanie wypukłości/wklęsłości funkcji)
15. Całka Riemanna i jej własności. Zastosowanie całek Riemanna w geometrii np. do wyznaczania pól powierzchni.
16. Podstawowe pojęcia kombinatoryki: permutacje, wariacje, kombinacje. Prawa i metody przeliczania. Schematy wyboru.
permutacje - to dowolny n-wyrazowy ciąg utworzony ze wszystkich elementów tego zbior
Pn = n!
Na ile sposobów można ustawić 5 osób w kolejce?
Pierwszą osobę mozna ustawić w 5 miejscach, drugą w 4 miejscach , trzecią w 3 miejscach ...
Rozwiązanie:
Obliczmy liczbę permutacji zbioru 5-elementowego:
P5=5!=5⋅4⋅3⋅2⋅1=120
Czyli pięć osób można ustawić w kolejce na 120 sposobów.
wariacja z powtórzeniami - pozwala na utworzenie ciągu z elementów tego zbioru, z tym, że dopuszcza powtarzanie elementów
Wzór: Wnk = n^k
Ile słów pięcioliterowych (nawet tych bezsensownych) można utworzyć z liter {A,B,C}?
Rozwiązanie:
Przykładami taki słów są: AAAAA, AABCA, CBCBB. Na każde z 5 miejsc możemy wybrać jedną z 3 liter, zatem wszystkich możliwości mamy: 3^5=243
wariancja bez powtórzeń - pozwala na utworzenie ciągu z elementów tego zbioru, z tym, że nie dopuszcza powtarzania elementów.
Wzór: Vnk = n!/(n-k)!
Ile istnieje czterocyfrowych PIN-kodów składających się z różnych cyfr?
Rozwiązanie:
Mamy do dyspozycji 10 cyfr: {0,1,2,3,4,5,6,7,8,9}.
Przykładowymi kodami o różnych cyfrach są: 1234, 0189, 9734. Wszystkich takich wariacji bez powtórzeń jest: 10!/6! = 7⋅8⋅9⋅10 = 5040
kombinacje - pozwala policzyć na ile sposobów można wybrać k elementów z n-elementowego zbioru
Wzór: Cnk = n!/k!(n-k)!
Na ile sposobów można wybrać 2 osoby w klasie 30 osobowej? (30 po 2)
17. Metody dowodzenia twierdzeń (dowód wprost, dowód nie wprost, dowód przez zaprzeczenie), zasada szufladkowa, zasada indukcji matematycznej.
18. Podstawowe pojęcia teorii grafów: grafy skierowane i nieskierowane, grafy proste; grafy ważone; reprezentacje komputerowe grafów; izomorfizm grafów; podgrafy; przeliczanie grafów prostych.
19. Eksperyment losowy, przestrzeń probabilistyczna, zdarzenie losowe, prawdopodobieństwo klasyczne.
20. Zmienna losowa -definicja, rozkład prawdopodobieństwa, przykłady. Wartość oczekiwana, wariancja i kowariancja. Niezależność zmiennych losowych.
21. Prawdopodobieństwo warunkowe, niezależność zdarzeń. Wzór łańcuchowy. Wzór Bayesa.
22. Elementy teorii grup, pierścieni. Ciała skończone.
Zagadnienia informatyczne:
1. Podstawowe informacje o prawie autorskim w informatyce (licencje: open source, closed source, shareware, SaaS, licencje: GPL, MIT, CreativeCommons).
open source - właściciel praw autorskich przyznaje użytkownikom prawa do badania, zmiany i rozpowszechniania oprogramowania (kodu) w ramach licencji wolnego oprogramowania. Zazwyczaj rozwijane przez szeroką społeczność programistów
closed sourse - zamknięte, zastrzeżone oprogramowanie, które nie jest rozpowszechniane publicznie. Pierwotni autorzy mają prawo do kopiowania, modyfikowania, aktualizowania i edytowania kodu źródłowego. W modelu oprogramowania zamkniętego uprawnienia użytkownika końcowego w odniesieniu do aplikacji są ograniczone — użytkownikom nie wolno jest modyfikować, udostępniać, kopiować ani wtórnie publikować kodu źródłowego
shareware - umożliwia wypróbowanie pełnej wersji programu komputerowego (lub jego wybranych funkcji) przez użytkownika przed zakupem. Jest on udostępniany za darmo lub za niedużą opłatą. Jest to rozwiązanie, które proponowane jest jedynie na wcześniej ustaloną liczbę uruchomień lub na pewien okres (czyli tzw. trial, który może trwać od 7 do 90 dni). Po jego upłynięciu użytkownik powinien się zarejestrować i ponieść ewentualne koszty. Jeśli tego nie zrobi, musi usunąć testowane oprogramowanie. Dalsze korzystanie z niego jest nielegalne i w przypadku wykrycia, karalne
SaaS - model udostępniania oprogramowania w chmurze, w którym dostawca chmury rozwija i utrzymuje aplikacje chmurowe, zapewnia ich automatyczne aktualizacje i udostępnia oprogramowanie swoim klientom za pośrednictwem Internetu na zasadzie „pay-as-you-go”, czyli w zależności od wykorzystania zasobów
GPL - Celem licencji GNU GPL jest przekazanie użytkownikom czterech podstawowych wolności:
- wolność uruchamiania programu w dowolnym celu (wolność 0)
- wolność analizowania, jak program działa i dostosowywania go do swoich potrzeb (wolność 1)
- wolność rozpowszechniania niezmodyfikowanej kopii programu (wolność 2)
- wolność udoskonalania programu i publicznego rozpowszechniania własnych ulepszeń, dzięki czemu może z nich skorzystać cała społeczność (wolność 3)\
MIT - opiera się na jednym wymaganiu: we wszystkich rozpowszechnianych wersjach należy zachować warunki licencyjne i informacje o autorze. Powstała MIT - amerykaniskiej uczelni
Creative Commons - Korzystając z utworów na licencjach Creative Commons, licencjobiorca jest zobowiązany do uzyskania zgody na wszelkie czynności związane z korzystaniem z utworu, które prawo zastrzega wyłącznie na rzecz licencjodawcy lub licencja wyraźnie na to nie zezwala. Każda licencja Creative Commons działa na całym świecie i trwa tak długo, jak obowiązujące tam prawo autorskie.
Podstawowe warunki:
- Wolno kopiować, rozprowadzać, przedstawiać i wykonywać objęty prawem autorskim utwór oraz opracowane na jego podstawie utwory zależne pod warunkiem, że zostanie przywołane nazwisko autora pierwowzoru.
- Użycie niekomercyjne. Wolno kopiować, rozprowadzać, przedstawiać i wykonywać objęty prawem autorskim utwór oraz opracowane na jego podstawie utwory zależne jedynie do celów niekomercyjnych.
- Na Tych Samych Warunkach Na tych samych warunkach. Wolno rozprowadzać utwory zależne jedynie na licencji identycznej do tej, na jakiej udostępniono utwór oryginalny.
- Bez utworów zależnych. Wolno kopiować, rozprowadzać, przedstawiać i wykonywać utwór jedynie w jego oryginalnej postaci – tworzenie utworów zależnych nie jest dozwolone
2. Typy danych XML i JSON.
XML to:
- uniwersalny język znaczników przeznaczony do reprezentowania różnych danych w strukturalizowany sposób
- standard, opisany w rekomendacji W3C, oparty o standard SGML.
- to sposób zapisywania danych wraz z ich strukturą w dokumentach tekstowych
- metajęzyk, czyli klasa języków zwanych zastosowaniami XML. Są nimi np. XML Schema, WSDL, XSLT, XHTML, SVG
- jest oparty o model dokumentu jako drzewa, którego węzłami są elementy a liśćmi - pola tekstowe
Zasadniczo XML służy do przechowywania lub przesyłania danych tekstowych wraz z ich strukturą. Konkretne zastosowania XML mogą służyć bardziej specyficznym celom
Czy mnie jest:
- językiem programowani
- sposobem prezentacji
- sposobem tworzenia stron WWW
JSON to otwarty format zapisu struktur danych. Jego przeznaczeniem jest najczęściej wymiana danych pomiędzy aplikacjami; dwukropek oddziela klucz od wartości\
{
"title" : "This Is What You Came For"
}
Wartościami w JSONie mogą być:
- ciąg znaków,
- liczba (można pominąć cudzysłów),
- obiekt JSON (zagnieżdżony),
- tablica,
- wartość prawda/fałsz (zapis małymi literami true albo false)
- null
3. Język maszynowy oraz języki wyższego rzędu. Kompilacja, interpretacja i konsolidacja programu.
Język maszynowy - zestaw rozkazów procesora, w którym zapis programu wyrażony jest w postaci liczb binarnych
Jezyki wyszego poziomu - typ języka programowania, którego składnia i słowa kluczowe mają w jak największym stopniu ułatwić rozumienie kodu programu przez człowieka. Wysoki poziom Kod źródłowy zawiera łatwe do odczytania składnia który jest później konwertowany na język niskiego poziomu, który może być rozpoznawany i obsługiwany przez określony CPU. Program napisany w takim języku musi być przekompilowany
Przykłady: C++, C#, Java, JavaScript
Kompilacja - zmiana kodu z języka wysoko poziomowego na nisko poziomowy, by był zrozumiały dla procesora
Iterpretacja - Przekształcanie (translacja) instrukcji programu na bieżąco do kodu maszynowego lub innej formy pośredniej i natychmiastowe ich wykonywanie
Konsolidacja - proces polagający na łączeniu skomplikowanych modułów kodu
4. Pojęcie funkcji; przekazywanie parametrów i zwracanie wyniku. Czas życia i zakres ważności nazwy.
Funkcja - blok kodu, można przekazać do niej zmienne - parametry i zwrócić jakiś wynik działania funkcji
Czas zycia - ?
5. Zarządzanie pamięcią. Wskaźniki, referencje i dereferencje. Dynamiczna alokacja pamięci, sterta.
Wskaźnik - odwołanie do miejsca w pamięci gdzie jest zmienna.
Referencja - wartość, która posiada informację gdzie w pamięci jest inna wartość.
Dereferencja - zmiana wskaźnika/referencji na faktyczną wartość np zmiennej.
Dynamiczna alokacja pamięci - dynamiczny przydział pamięci w zależności od wymagania
Sterta - naczej kopiec lub stóg to obszar pamięci implementujący strukturę danych o tej samej nazwie. Jej części są udostępniane na wyłączność uruchomianym programom (procesom). Przechowywane są tam dynamicznie tworzone struktury danych. W przeciwieństwie do stosu nie jest uporządkowana ani czyszczona między wywołaniami funkcji
6. Techniki algorytmiczne: dziel i zwyciężaj, programowanie dynamiczne, rekurencja, metoda z powrotami na przykładzie np. algorytmów sortowania, szybkie wyszukiwanie.
Dziel i zwycięzaj - W strategii tej problem dzieli się rekurencyjnie na dwa lub więcej mniejszych podproblemów tego samego (lub podobnego) typu, tak długo, aż fragmenty staną się wystarczająco proste do bezpośredniego rozwiązania. Przykład: sortowanie przez scalenie
programowanie dynamiczne - technika projektowania algorytmów polegająca na rozwiązywaniu podproblemów i zapamiętywaniu ich wyników. Problem dzielony jest na mniejsze podproblemy. Wyniki rozwiązywania podproblemów są jednak zapisywane w tabeli, dzięki czemu w przypadku natrafienia na ten sam podproblem nie trzeba go ponownie rozwiązywać
rekurencja - odwoływanie się funkcji lub definicji do samej siebie
metoda z powrotami - ogólny algorytm wyszukiwania wszystkich (lub kilku) rozwiązań niektórych problemów obliczeniowych, który stopniowo generuje kandydatów na rozwiązanie, jednak gdy stwierdzi, że znaleziony kandydat c nie może być poprawnym rozwiązaniem, nawraca (ang. backtracks) do punktu, gdzie może podjąć inną decyzję związaną z jego budową. Przykład sprawdzenie czy element jest liściem drzewa\
7. Podstawowe struktury danych: drzewa, kolejki, stosy, listy, kopce, drzewa.
tablica - jest prawdopodobnie najprostszą strukturą danych. Jest to reprezentacja ciągu elementów jakiegoś typu ułożonych w określonej kolejności. Każdy element ma określony indeks (kolejny numer)
drzewo - składa się z wierzchołków (węzłów) i krawędzi, przy czym krawędzie łączą wierzchołki w taki sposób, iż istnieje zawsze dokładnie jedna droga pomiędzy dowolnymi dwoma wierzchołkami. Wierzchołki mogą posiadać rodzica, który jest umieszczony na wyższym poziomie oraz dzieci, które są umieszczone na niższym poziomie. Niektóre dzieci nie posiadają własnych dzieci i są liśćmi.
Binarny zapis drzewa: [4]-[5]-[1]-[9]-[6]-[3]; pierwszy element to korzeń, ostatnie to liście
[4]
.|---|
[5].[1]
.|...|-------|
.|...........|
.|---|.......|
[9].[6].....[3]
Poziom wierzchołka w drzewie jest równy długości drogi łączącej go z korzeniem. Korzeń drzewa jest na poziomie 0.
Wysokość drzewa równa jest maksymalnemu poziomowi drzewa, czyli długości najdłuższej spośród ścieżek prowadzących od korzenia do poszczególnych liści drzewa
kolejka -
FIFO - first in first out - dane dodawane na końcu pobierane z początku (nie ma mozliwości pobierania i dodawania z innego miejsca)
kolejka piorytrtowa - elemnty dodwane są na na końcu (standardowo), z pobierane są względem piorytetu (najmniejszy lub największy), a nie względem długości czekania
LIFO - last in last out - moze być kolejką lub stostem
stos - stktura danych, w której dodajemy elemanty na samą górę i zdjemujemy z góry LIFO (last in last out)
listy - to struktura danych zawierająca tak zwane węzły (node). Węzeł przechowuje jakąś daną, oraz umożliwia dostanie się do kolejnego elementu listy. Taka lista nazywa się listą jednokierunkową. Istnieją również listy dwukierunkowe, w których węzły dodatkowo dają możliwość pobrania poprzedniego elementu, a nie tylko następnego. niemożliwe jest szybkie dostanie się do dowolnego elementu listy. Aby pobrać k-ty element, konieczne jest przejście z pierwszego do drugiego, z drugiego do trzeciego, z trzeciego do czwartego i tak dalej, aż do k-tego
kopce - Drzewo binarne jest kopcem jeżeli jest:
- częściowo uporządkowane, czyli wartości przechowywane w następnikach każdego węzła są mniejsze od wartości w danym węźle (tzw. kopiec maksymalny) lub wartości przechowywane w następnikach każdego węzła są większe od wartości w danym węźle (tzw. kopiec minimalny)
- doskonałe, czyli zrównoważone i wszystkie liście najniższego poziomu znajdują się na jego skrajnych, lewych pozycjach
8. Złożoność czasowa, klasy P i NP, problem P=NP. Redukowalność w czasie wielomianowym, NP-zupełność.
Klasa P - problemy, które potrafimy rozwiązać w czasie co najwyzej wielomianowym
Klasa NP - problemy, których nie znamy rozwiązań w czasie wielomianowym lub mniejszym (czyli zadania o złozoności co najmniej wykładniczej)
P = NP - kazdy problem P jest NP, ale nie wiadomo czy istnieje problem NP który jest P
Redukowalność w czasie wielomianowym - problem, funkcję można obliczyć w czasie wielomianowym.
NP-zupełność - to problem który należy do klasy NP, oraz dowolny problem należący do NP, może być do niego zredukowany w czasie wielomianowym
9. Systemy plików (atrybuty pliku, katalogi, dowiązania twarde i symboliczne).
atrybut pliku - cecha charakterystyczna pliku
Rodzaje:
- archiwalny (A)
- tylko do odczytu (R) - nie mozna zmienic zawartości i usunąć
- ukryty (H) - nie jest widoczny w folderze (explorer plików lub polecenie dir)
- systemowy (S)
katalog - miejsce gdzie są
dowiązania twarde - utworzenie nowej nazwy dla istniejącego pliku. Jeśli wyobrazimy sobie plik jako jego nazwę i dane na które ta nazwa wskazuje to można powiedzieć, że dowiązanie twarde to utworzenie nowej nazwy wskazującej na te same dane; tworzy nową nazwę dla zasobu, zapisując ją w nowej lokalizacji (nie kasując poprzedniej), a sam link nie odwołuje się do pliku samego w sobie, ale tylko do jego zawartości
dowiązania symboliczne - Wskazują one zwyczajnie na jakiś plik. Skasowanie pliku źródłowego spowoduje, że link, dowiązanie, po prostu przestanie działać prawidłowo. Działa podobnie jak skrót w Windows\
10. Współbieżność, synchronizacja procesów: semafory, semafory binarne, monitory, problemy współbieżności (sekcja krytyczna, producent/konsument, czytelnicy i pisarze, n-filozofów).
semofor - mechanizm synchronizacji procesów; wykorzystanie semaforów zapobiega niedozwolonemu wykonywaniu operacji na danych jednocześnie przez większą liczbę procesów; kontroluje ile procesów ma dostep do zasobów; jest to pewna całkowita nieujemna liczba \
semafor binarny - moze tylko podnosić i opuszczać; przyjmuje tylko wartość 0 lub 1
monitory - obiekty, które mogą być uzywany przez wiele wątków
problemy współbiezności:
- sekcja krytyczna - fragment kodu programu, w którym korzysta się z zasobu dzielonego, a co za tym idzie w danej chwili może być wykorzystywany przez co najwyżej jeden wątek
- producent konsument
- czytelnicy i pisarze - problem synchronizacji. Dotyczy on dostępu do jednego zasobu dwóch rodzajów procesów: dokonujących w nim zmian (pisarze) i niedkonujących w nim zmian (czytelników); jednoczesny dostęp moze mieć dwolna liczba czyteników, ale równocześnie z pisarzem dostęp do zasobu nie moze otrzymać inny pisarz
- n-filozofów - teoretyczne wyjaśnienie zakleszczenia i uniemożliwienia innym jednostkom korzystania z zasobów poprzez założenie, że każdy z filozofów bierze po jednym widelcu / po jednej pałeczce (do jedzenia ryżu), a dopiero potem próbuje zdobyć drugi / drugą. Zakłada się, że jedzenie jednym widelcem / jedną pałeczką jest niemożliwe
11. Wirtualizacja: pojęcie i typy wirtualizacji, pojęcie hypervisora.
wirtualizacja - tworzenie oddzielnej warstwy sprzętowej za pomocą oprogramowani. Dzięki temu elementy sprzetowe jednego komputera (procesor, pamięć operacyjna) mozna podzielić na wiele urządzeń wirtualnych (maszyny wirtulane). Kazda taka maszyna ma swój własny system operacyjny typy wirtuaizacji:
- wirtulaizacja stacji roboczej
- wirtualizacja sieci
- wirtualizacja pamięci masowej
- wirtualizacja danych - dane pochodzące z wielu aplikacji są przechowywane w różnych formatach i w wielu miejscach, od chmury, poprzez sprzęt lokalny, wirtualizacja danych umożliwia dowolnej aplikacji uzyskanie dostępu do wszystkich tych danych — niezależnie od źródła, formatu czy lokalizacji
- wirtualizacja aplikacji - umozliwia to korzystanie z aplikacji bez konieczności instalowania go bezpośrednio w systemie operacyjnym uzytkwnika
- wirtualizacja centrów przetwarzania danych
- wirtualizacja procesora
- wirtualizacja procesora graficznego
- wirtualizacja systemu linux
- wirtualizacja chmury
hypervisora - wartwa oprogramowania dzięki, której koordynowane są maszyny wirtualne. Pilnuje by poszczególne maszyny nie wchodziły ze sobą w konflikt. Są dwa typy:
- typ 1 (inaczej "bare-metal")
- typ 2 - aplikacja w istniejącym systemie operacyjnym, najczęściej na urządzeniu końcowym w celu obsługi alternatywnych systemów operacyjnych
12. Podstawowe struktury i elementy języka SQL, indeksy w bazach danych.
SQL - to język zapytań (ang. Structured Query Language), który zapewnia komunikację między
użytkownikiem lub aplikacją, a relacyjną bazą danych. Za pomocą SQLa możemy nie tylko
pobierać dane, ale także je wstawiać i modyfikować oraz tworzyć i modyfikować bazy
danych. Język SQL składa się z zapytań (ang. query)
Podstwawowe elementy w języku: select, from, where, agregaca (sum, avg, min, max przy jednoczesnym zastosowaniu group by), orger by (ASC, DESC), tabele tymczasowe (CTE)
indeksy - struktury zwiększające szybkość wykonywania operacji wyszukiwania. Bazują na drzewach lub wykorzystują funkcję skrótu.; Indeksowanie jest podstawowym mechanizmem wykorzystywanym w celu optymalizacji baz danych MySQL. Gdyby porównać bazę danych do książki, indeksy są czymś w rodzaju spisu treści. Indeksy są zatem pomocniczymi strukturami danych, które znacząco wpływają na szybkość wykonywania się zapytań SQL. Z technicznego punktu widzenia (i mocno uogólniając) indeksy to zbiór wartości typu „klucz – lokalizacja”. Podczas realizowania zapytania optymalizator (SQL Server) najpierw przeszukuje indeks, który jest uporządkowany, a następnie na podstawie indeksu odczytuje odpowiednie rekordy. Indeksy dzielimy na główne (dla kluczy głównych), zgrupowane (dla nieunikalnych wartości grupujące te same wartości), niezgrupowany (podobnie jak zgrupowany tylko pamieta wszystkie pozycje elementów, jest gęstszy). Gwarantuje to logarytmiczny (względem rozmiaru) czas wykonywania podstawowych operacji takich jak wstawianie, wyszukiwanie czy usuwanie elementów.
\
W praktyce indeksy tworzymy dla:
- Kolumn z ograniczeniem PRIMARY KEY.
- Kolumn z ograniczeniem FOREIGN KEY oraz kolumn wykorzystywanych przy łączeniu tabel.
- Kolumn przechowujących dane wykorzystywane jako argument wyszukiwania.
- Kolumn przechowujących często sortowane dane.
13. Normalizacja schematu relacyjnej bazy danych.
Normalizacja to proces organizowania danych w bazie danych. Obejmuje to tworzenie tabel i ustanawianie relacji między tymi tabelami zgodnie z regułami opracowanymi w celu zarówno ochrony danych, jak i zapewnienia większej elastyczności bazy danych przez wyeliminowanie nadmiarowości i niespójnych zależności. https://docs.microsoft.com/pl-pl/office/troubleshoot/access/database-normalization-description
14. Pojęcie transakcji; własności ACID; poziomy izolacji i anomalie.
Transakcja - to zestaw operacji do wykonania, które wykonują sie jedna po drugiej. Do zaistnienia transakcji konieczne jest pomyślne wykonanie wszystkich operacji. W przeciwnym wypadku wszystkie operacje są odrzucane. Nie ma mowy o częściowym wykonaniu.
Załóżmy, że mamy transakcję składającą się z 10 zapytań. Jeżeli ostatnie zapytanie będzie skutkowało błędem, to zmiany dokonane przez poprzednie 9 zapytań zostaną cofnięte, a transakcja nie zostanie zakończona pomyślnie.
ACID - Jednym ze zbiorów zasad definiujących cechy jakie powinny spełniać trasakcje jest ACID.
A - Atomowość (atomicity) oznacza, że każda operacja na bazie danych jest traktowana jako osobny, niepodzielny byt. Co więcej, albo wszystkie operacje zakończą się pomyślnie, albo żadna z nich nie zostanie zaaplikowana. Mówiąc w skrócie – wszystko albo nic.
Transakcja mimo tego, że jest zbiorem działań musi zostać wykonana jako jedna jednostka. Musi odbywać się w jednym momencie i nie może zostać podzielona na podzbiory.
C - Spójność (consistency) ta zasada stoi na straży spójności danych. Każda transakcja zmienia stan bazy z jednego poprawnego stanu na inny stan, również poprawny. Oznacza to także, że transakcja nie może łamać nałożonych na bazę reguł, ograniczeń i wyzwalaczy.
System musi być spójny po zakończeniu transakcji.
I - Izolacja (isolation), równolegle uruchomione transakcje powinny być wyizolowane i nie powinny wpływać na siebie nawzajem. Oznacza to, że powinny się zachowywać tak, jakby były wykonywane sekwencyjnie.
Każda transakcja musi być wykonywana niezależnie od innych transakcji, które mogą być wykonywane w tym samym czasie.
D - Trwałość (durability), zmiany poczynione w trakcie transakcji są permanentne. Oznacza to, że rezultaty transakcji są trwale zapisane w bazie danych niezależnie od dalszych awarii.
Wykonana transakcja musi zostać utrwalona na stałe.
Poziomy izolacji - jak transakcje mogą wpływać na siebie, bardzo mocno, mocno, słabo albo wcale. I w zależności od tego jak wpływają to albo mamy więcej tych zjawisk (niepożądanych zjawisk – dodajmy), albo mniej. (Def 2) definiuje dostęp do określonych zasobów przez wiele równoległych procesów
- READ UNCOMMITTED – możliwy brudny odczyt, odczyt nie dający się powtórzyć i odczyt widmo. Problemem tutaj jest to, że chcesz wykonać jedną transakcje na jakiś danych, ale te dane w między czasie zostały już uprzednio zmodyfikowane przez inną
- READ COMMITTED - jest to domyślna opcja, która powoduje, że we wspomnianym przykładzie zostaną odczytane dane sprzed rozpoczęcia pierwszej transakcji. Podstawową wadą tej opcji jest oczywiście odwrotna sytuacja niż poprzednio – w momencie zatwierdzenia transakcji dane zostaną zmienione czyli nasz pierwotny odczyt będzie nieaktualny.
- REPEATABLE READ - w tym przypadku odczytywane są jedynie dane z zatwierdzonych transakcji, a żadna z transakcji nie może zmodyfikować danych, które zostały odczytane
- SERIALIZABLE - odczyt danych z tabeli za pośrednictwem instrukcji select powoduje zablokowanie danego zakresu. W efekcie żadna inna transakcja nie będzie miała możliwości zmiany danych w tym okresie.
Anomali transakcji -
- brudny odczyt - odczyt wewnątrz transakcji danych, które są zmieniane przez inną transakcję, która nie została zatwierdzona, moze zostać ona wycofana, więc pierwsza transakcja odczytała dane, które juŜ nie istnieją
- utracona modyfikacja - powstaje w sytuacji, gdy dwie transakcje równolegle przystępują do aktualizacji tych samych danych i zmiany, wprowadzone przez jedną z transakcji, zostają nadpisane przez zmiany z drugiej transakcji
- niepowtarzalny odczyt - odczyt zbioru danych, który przy ponownym odczycie tych samych danych daje zupełnie inny rezultat.
- odczyt widmo - występuje, gdy jedna transakcja odczytuje lub aktualizuje tabele, a druga transakcja w tym czasie dodała nowy wiersz, który powinien zostać dodany później, problem podobny do zjawiska poprzedniego
- utracone aktualizacje – do bazy danych zapisywane są dwie różne aktualizacje i druga zmiana powoduje, że pierwsza zostaje utracona
- fantomy - jest powstaje w sytuacji, gdy dwie transakcje równolegle przystępują do aktualizacji tych samych danych i zmiany, wprowadzone przez jedną z transakcji, zostają nadpisane przez zmiany z drugiej transakcji
https://wazniak.mimuw.edu.pl/images/2/25/BD-1st-2.4-lab9.tresc-1.1.pdf
15. Paradygmat programowania obiektowego (Abstrakcja, Hermetyzacja, Polimorfizm, Dziedziczenie, przeciążanie operatorów i metod, klasy abstrakcyjne, interfejsy).
Programowanie obiektowe - paradygmat programowania, w którym programy definiuje się za pomocą obiektów - łączą dane - zmienne, z zachowaniem - metodami.
Abstrakcja - abstrakcyjny obiekt wykonawca, istnieje w systemie bez zdefiniowanych np metod
hermetyzacja - polega na ukrywaniu pewnych danych; np. przy tworzeniu klasy nie chcemy by poszczególne jej składowe mogły być zmienione, poniewaz moze to prowadzić do nieprawidłowego działania aplikacji; dane powinnny być ukryte w naszej klasie, a na zewnatrz powinno być ujewnione jak najmniej
polimorfizm - wielopostaciowość, zapisywanie jednej funkcji pod róznymi postaciami, moze być statyczny (funkacj moze posiadać wiele motod o tej samej nazwie lecz rózniące się parametrami) lub dynamiczny (funckje wirtulane abstarkcyjne)
dziedziczenie - rodzaj relacji pomiędzy dwoma klasami, która pozwala jednemu z nich dziedziczyć kod drugiego
przeciązenie opreatorów - polega na tym, ze operator moze mieć rózne implementacje w zalezności od typów uztych argumentów
przeciązenie metod - najprościej mówiąc jest to tworzenie metod o takich samych nazwach, ale dla różnych parametrach
klasa abstrakcji - klasą, z której nie można utworzyć instancji obiektu https://pl.wikipedia.org/wiki/Klasa_abstrakcyjna
interfejsy - definicja abstrakcyjnego typu posiadającego jedynie funckje, a nie dane\
16. Czas życia obiektów, definiowanie klas, atrybuty, metody, inicjalizacja obiektów, zakres widoczności klas i składowych, organizacja kodu źródłowego, pakiety na przykładzie wybranego języka zorientowanego obiektowo.
17. Typy witryn internetowych: statyczne i dynamiczne, elementy witryny, zasada działania protokołu HTTP.
witryny statyczne - Treść na stronie statycznej jest zapisana w pliku html i tekst widoczny jest prawie zawsze połączony z resztą kodu. Zmiana publikowanej treści wymaga bezpośredniej ingerencji w taki plik
witryny dynamiczne - są połączone z bazą danych (albo plikiem JSON lub z innymi plikami agregującymi informacje), która zawiera treści jakie znajdują się na stronie. Za każdym razem, kiedy ktoś odwiedza stronę, treści te są pobierane a strona jest tworzona niejako w locie
To typ witryny internetowej, w której publikowane treści można modyfikować w zależności od ustawień m.in. typu urządzenia, przeglądarki internetowej z której korzystamy, pory dnia, godziny, strefy czasowej i wielu innych elementów. Umożliwia ona również komunikację dwukierunkową z osobami wchodzącymi na stronę\
protokuł HTTP - (Hypertext Transfer Protocol)
- przesyła zawartości w sieci Web
- określa zasady wymiany informacji i współpracy programów,
- jest to protokół bez stanowy (nie przechowuje dnaych)
- klient (ządania)[przeglądarka internetowa] - serwer (odpowiedzi)
- standardowo korzysta z portu 80
Jak działa !!!!!!!!!!!!!!!!!!!! Klient wysyła zapytanie (GET/path/HTTP/1.0) - serwer w odpowiedzi przesyła dane (plik) adres url - path HTTP/1.0 - wersja protokułu
HTTPS to bezpieczna wersja protokołu HTTP, która implementuje protokół HTTP przy użyciu protokołu Transport Layer Security (TLS) w celu zabezpieczenia bazowego połączenia TCP\
18. Cykl życia oprogramowania z uwzględnieniem różnych modeli. Wyróżnienie składowych procesu rozwoju oprogramowania. Przykładowe modele cyklu życia oprogramowania (model kaskadowy, spiralny (np. RUP), zwinny (np. SCRUM).
model kaskadowy - jest to przykład sekwencyjnego podejścia do wytwarzania oprogramowania. Jest szytwnie określony, nie powinno go się zmianiać i dostosowywać do własnego projketu. Podstawą jest 5 iteracji o nazwach: wymagania, analiza, projektowanie, programowanie, testowanie. Istotnym elementem jest zaplanowanie całego procesu z wyprzedzeniem. Do kolejnej fazy przychodzi się po zakończeniu poprzedniej.
model sprialny - Twórcą jest Barry Boehm. Model ten składa się z czterech głównych faz wykonywanych cyklicznie:
- analizy,
- konstrukcji,
- testowania,
- planowania.
RUP - proces wziął inspirację z modelu spiralnego Barrego Boehma. Powstał przez scalenie metody Rational i Objectory. Proces RUP został zaprojektowany w taki sposób by móc go dostosować do potrzeb własnego projektu. Opiera się na fazach. Jest ich cztery: incepcji, elaboracji, konstrukcji, przekazania. Po kazdej fazie osiąga się kamień milowy i przechodzi do kolejnej. Fazy mozna podzielić na iteracje.
zwinny - (ang. agile) zazwyczaj błędnie jest określany jako metodyka prowadzenia projketów. jest jednak czyś więcej - filozofią postępowania, sposobem myślnia. Powstał w kontrze do kaskadowych metod. Kocnetruje się na efektywnym wykorzystaniu potencjału ludzkiego. Załozenia zwinnego myślenia zostały spisane w Agile Manifesto
Scrum - to zwinne podejście do wywarzania oprogramowania. Są o ramy postępowania, które mozna dostosować do własnego zespołu czy projketu. Podjeście dobrze sprawdzi się w projekcie, gdzie jest duzo zmiana. Cała praca jest podzielona na sprinty, które są waznym elementem tej metody. Wyróznia się trzy role: Scrum Master, Prouct Owner, Członek zaspołu developerskiego. Wykorzystuje się backlog do zapisania zadań.\
19. UML w projektowaniu systemu informatycznego (diagramy klas, sekwencji, maszyny stanowej).
diagram klas - obrazuje pewien zbiór klas, interfejsów i kooperacji oraz związki między nimi. Jest on grafem złożonym z wierzchołków (klas, interfejsów, kooperacji) i łuków (reprezentowanych przez relacje). Diagram klas stanowi opis statyki systemu, który uwypukla związki między klasami, pomijając pozostałe charakterystyki. Najsilniej prezentuje on więc strukturę systemu, stanowiąc podstawę dla jego konstrukcji.
sekwencji - służy do prezentowania interakcji pomiędzy obiektami wraz z uwzględnieniem w czasie komunikatów, jakie są przesyłane pomiędzy nimi. Zasadniczym zastosowaniem diagramów sekwencji jest modelowanie zachowania systemu w kontekście scenariuszy przypadków użycia. Diagramy sekwencji pozwalają uzyskać odpowiedź na pytanie, jak w czasie przebiega komunikacja pomiędzy obiektami.
maszyny stanowej - Diagram maszyny stanowej przedstawia maszynę stanową, która zawiera proste stany i przejścia pomiędzy nimi.
stan - modeluje niezmienną sytuację, w której znajduje się obiekt podczas całego swojego życia. Niezmienna sytuacja obiektu oznacza spełnienie jakiegoś warunku, wykonanie czynności lub oczekiwanie na jakieś zdarzenie
przejście - związek pomiędzy dwoma stanami, wskazujący, że obiekt znajdujący się w pierwszym stanie wykona pewną akcję i przejdzie do drugiego stanu ilekroć znajdzie określone zdarzenie i będą spełnione określone warunki. Przejście jest niepodzielne, tzn. nie można go przerwać, i trwa minimalny okres czasu. Mogą posiadać parametry. Pierwszym dodatkowym parametrem jest zdarzenie uruchamiające.
20. Wzorce architektoniczne (monolit, klient-serwer, aplikacje wielowarstwowe, repozytorium, przetwarzanie wsadowe), wzorce projektowe (MVC, ORM).
monolit - wszystkie problemy dotyczące aplikacji są zawarte w jednym wdrożeniu. Wszystkie wywołania, od interfejsu użytkownika po wywołania bazy danych, znajdują się w tej samej bazie kodu;starsze aplkacje są często implemnetowane jako monolity
klient-serwer - ten typ architektury umozliwa podział zadań, serwer zapewania usług dla klientów, którzy zgłaszają zadania do serwera
aplikacje wielowarstwowe - aplikacje prarycjonują logikę aplikacji na określone warstwy, najczęściej jest to: interfejs uzytkownika, logika biznesowa, dostęp do danych
repozytorium - miejsce, gdzie w sposób uporządkowny przechowywyje się kod oprogramowania
przetwarzanie warstwowe -
wzorce proejktowe - Przykłady: \
- MVC - jest jednym z najczęściej stosowanych wzorców. Model-View-Controller, główne załozenie to podzielenie na 3 moduły
- Model reprezentujący dane (pobieranie z bazy danych)
- Widok reprezentujący interfejs uzytkownika
- Kontrler logika sterująca aplikacją
- ORM - system odwzorowania architektury systemu informatycznego na bazę danych o relacyjnym charakterze (system oparty na podejściu obiektowym, s system bazy danych operuje na relacjach)
21. Rodzaje testów oprogramowania. Testy prowadzone przez programistę (testy jednostkowe, testy modułowe, testy integracyjne). Ciągła integracja. Scenariusze testowe i testy akceptacyjne. Testy użyteczności.
jedostkowe - Jedna z wieu definicji: to kod wykonujący inny kod w kontrolowanych warunkach w ramach jednego precesu w pamięci, w celu weryfikacji (bez ingerencji programisty), ze testowana logika działa w ściśle określony sposób.
odpowiednio i świadomie wykorzystane bardzo pomagają w procesie tworzenia i rozwijania oprogramowania. Ale, co mniej oczywiste – mogą też zaszkodzić!
testujemy pojedynczą część kodu zazwyczaj klasę lub metodę
https://devstyle.pl/2020/06/25/mega-pigula-wiedzy-o-testach-jednostkowych/
modułowe - oznacza to nic innego jak testowanie każdej metody, funkcji, klasy, modułu czy elementu w pojedynczy sposób, testy jedneostkowe metody
integracyjne - testujemy kilka komponentów systemu jednocześnie. Testy integracyjne wykorzystają moduły przetestowane jednostkowo, grupując je w większe agregaty. Kolejnym etapem jest zastosowanie testów zdefiniowanych dla tych agregatów w planie testów integracji. Efektem testów jest zintegrowany system gotowy na testy systemowe
ciągła integracja - praktyka programistyczna, rozwązuje problem budowania, testowania i integracji kodu, podastawą są pojedyncze współdzielone repozytoria. Efektywność tej praktyki zalezy od członków zespołu. Zamiany powinny być wrzucane często przynajmniej raz dziennie, przez co łatwo jest uwzględniać zmiany w kodzie
scenariusze testowe - dokument zawirający zbiór przypadków testowych potrzebnych do sprawdzenia poprawności działania systemu w określonym zakresie. Kazdy scenariusz powinien być odzwierciedleniem dokładnie określonej funkcjonalności. Kazdy scenariusz powinien zawierać: id, wykaz czynności przygotowawczych, przypadek testowy, oczekiwany resultat
testy akceptacyjne - Cele testowania akceptacyjnego to najczęściej:
- budowanie zaufania do systemu;
- sprawdzanie kompletności systemu i jego prawidłowego działania;
- sprawdzanie zgodności zachowania
funkcjonalnego i niefunkcjonalnego systemu ze specyfikacją.
testy mające na celu odpowiedzieć na pytanie czy aplikacja spełnia wymagania biznesowe
testy uzytecznośći - pozwalają dowiedzieć się w jaki sposób serwis, aplikacja są używane, jakie budzą emocje, jakie wywołują reakcje, jakie nastawienia powodują. Jakie przeszkody klienci napotykają, wchodząc na daną stronę/ aplikację. Pozwalają sprawdzić czy uzytkwonicy poprawnie rozumieją funkcje i zakres uzytecznosci strony/ aplikacji \
22. Styl architektoniczny REST.
REST - rozwiązanie architektoniczne, które korzysta z HTTP, nie jest to ścisły i oficjalny standard, a jedynie zbiór reguł
- jendnolity interfejs komunikacyjny - Serwer powinien udostępniać API, które będzie rozumiane przez wszystkie aplikacje komunikujące się z nim. Zwracane dane powinny mieć ten sam format i zakres danych
- podział na aplikację klient-serwer - Rozdzielenie aplikacji pozwala na ich niezależny rozwój i działanie. Taki podział zdecydowanie zwiększa możliwości skalowania, przenośności i rozszerzalność, a obsługa błędów jest znacznie łatwiejsza
- bezstanowość - Po stronie serwera nie powinno być mechanizmów przetrzymujących dane klienta, które byłyby potrzebne do poprawnego działania systemu
- cache danych - zmniejsza obciązenie sieciowe i pamięciowe. Jednym ze sposobów jest mechanizm przegląderek, które lokalnie "zapamiętują" odpowiedzi serwera, opiera się to na GET i POST
- odseparowanie warstw - Komunikacja i wymiana danych między aplikacjami klienckimi, a API nie powinna być obciążona informacjami o zewnętrznych serwisach i usługach, z których serwer korzysta
- wysłanie kodu do apliakcji klienta - API może wysyłać gotowe fragmenty kodu do aplikacji klienckich w celu ich przetworzenia i uruchomienia (np. skrypty JS)
23. Protokoły TCP/UDP oraz IP, przestrzeń adresowa IPv4 i IPv6.
IP - protokół sieciowy, iddentyfikacją jest adresacja IP (kto do kogo na poziomie IP), w nagłówku zawarte są dane: kto, do kogo, TTL, protokół, suma kontrolna, fragmetacja (numer fragmentu), TOS (type of service czy audio, wideo)
UDP - protokół transportowy bez połączeniowe, ramka jest wysyłana, nie wiadomo czy dotrze
TCP - protokół transporowy połączeniowe,ramki są potwierdzane
IPv4 - adresacja ma 32 bity
IPv6 - adresacja ma 128 bitów, posiada obowiązkowu IPsec
Róznią się nagłówkiem, ilość danych jest taka sama jak w IPv4
24. Model warstwowy sieci, enkapsulacja.
Model warstwowy sieci - IOS/OSI (7 warstr)
- aplikacji
- prezentacji
- sesji
- transportu
- sieci
- łącza danych
- fizyczna
Model TCP/IP (4 warstwy)
- aplikacji (sesji, prezentacji, aplikacji)
- transportu [TCP, UDP, ICMP]
- sieci [IP ]
- dostepu do sieci (fizyczna i łącza danych) [MAC adres]
enkapsulacja - zagniezdzanie ramki z wyzszej warstwy w polu danych ramki nizszej warstwy
25. Podstawowe protokoły i usługi sieciowe – ARP, DHCP, DNS, FTP, SMTP, IMAP. POP3, SSH, SNMP
ARP - (Address Resolution Protocol) protokół rozwiązywania adresów MAC i IP; za pomocą tego protokołu host rozsyła zapytania o adresy MAC i odpowiada na zapytanie (ze ma taki MAC adres) [sprawdzenie ARP -a]
DHCP - (Dynamic Host Configuration Protocol) protokół usługi przydzielnia adresacji IP i konfiguracji sieciowej hostowi (maska, gateway, serwery dns, serwery wins) - sprawdzenie ipconfig
DNS - (Domain Name Services) protokół słuzy do rozwiązywania nazw internetowych na adresy IP i odwrotnie; host kontaktuje się z serwerem DNS w celu zamiany nazwy na IP lub odwrotnie
struktura hierarchiczna serwerów DNS np. amu.edu.pl
FTP - (File Tranport Protocol) słuzy do przesyłania plików, działa na zasadzie klient FTP i serwer FTP
SMTP - protokół wysyłania poczty
IMAP - (Internet Message Access Protocol) internetowy protokół pocztowy zaprojektowany jako następca POP3
POP3 - protokół wysyłania poczty
SSH - protokół terminalowy, szyfrowany (telnet jest nie szyfrowany)
SNMP - (Simple Network Management Protocol) prosty protokół zarządzani urządzeniami sieciowymi, SET, GET, WALK bazuje na drzewie elementów OID MIB tree\
DHCP,...,SNMP do kazdej usługi jest przypisany port
a. fizyczne sieci komputerowe: ethernet, wifi; zasada działania podwarstwy MAC;
ethernet - (IEEE 802.3) standard sieci lokalnej obejmujące warstwę dostepu do sieci, ramka sieci ethernetowej ma długość 64-1518, bazuje na wykrywaniu kolizji CSMA/CD; rozwój ethernetu od 10Mb/s do 100GB/s, adresacja MAC
wifi - moze działać w trypie ad-hoc (kazdy z kazdym) lub infrastuktury (bazujące na access pointcie - access point steruje), działają na częstotliwości 2,4Ghz (802.11bg) lub 5Ghz (802.11a), koolejne standardy to 802.11n, 802.11ac, 802.11ax (kolejne zwiększają przepustowość); stsosuje się szyfrowanie danych WEP, WPA, WPA2
podwarstwa MAC - (MAC - Media Access Control) powarstwa warstwy łącza danych, której zadaniem jest zapewnienie niezaleznego od medium dostępu do warstwy fizycznej (np. powietrze, swiatłowód, miedź), adresowanie MAC, ochrona przed błędami
b. struktura Internetu, systemy autonomiczne, rodzaje routingu;
struktura Internetu - to rozległa sieć (WAN) nazwana intersiecią, której komputery/serwery nie posiadają centralnej admnistracji, protokołem komunikacji jest TCP/IP \
systemy autonomiczne - (AS - autonomus system) zbiór zakresów adresacji sieci pod wspólną administracyjną kontolą, w których utrzymywany jest spójny schemat routowania; AS są wykorzystywane w protokołach routingu dynamicznego np. BGP, pierwotnie numeracja AS zawarta była w 2 bajtach \
rodzaje routingu:
- statyczny - ręcznie jest tworzona tablicza routingu (co gdzie jest wysyłane), gdy coś paddnie, to przeba ręcznie zmieniać
- dynamiczny - tablica jest tworzona i modyfikowana przez routery, gdy coś padnie, to routery uczą się na nowo, w zalezności od protokołu do twoorzenia tablicy brane są pod uwagę odległość do celu, przepustowość, obciązene łacza (koszt); algorytmy routingu bazują na stanie łącza lub/i wektorze odległości; znane protokoły routingu to: RIP, IGRP, BGP, OSPF
| docelowa sieć | maska | getway |
|---|
c. metody/ próby zapewnienia jakości w Internecie (głównie na użytek multimediów);
stosuje się qos; stosuje się klasyfikowanie i tagowanie ramek (Tos w IP, na poziomie ethernetu jest to CoS), przez co mozna je piorytetyzować i są szybciej przepuszczane
d. zabezpieczanie sieci komputerowych (SSL/TLS, IPsec, wifi/WEP/WPA).
SSL - (Secure Sockets Layer) protokół ; na warstwie aplikacji
TLS - (Transport Layer Security) na warstwie aplikacji\
IPsec - słuzy do bezpiecznego przesyłania ramek IP w szyfrowanych kanałach IPsec, wykorzystywany do tworzenia tzw. VPN-ów; działa na zasadzie kapsułkowania - pakowanie oryginalnego adresu IP w ranki IPsec\
WEP - protokoły szyfrowania w wifi, statyczny klucz; warstwa dostepu do sieci
WPA - protokoły szyfrowania w wifi, zmienny klucz (zmiania się w trakcie połączenia); warstwa dostepu do sieci\
są to sposoby szyfrowania transmisji danych
26. Reprezentacja zmiennopozycyjna liczb. Błędy w obliczeniach, uwarunkowanie zadania, numeryczna stabilność algorytmów.
Wartość liczby zmianno przecinkowej mozna zapisać za pomocą wzoru:
[-1^{znak} * 2^{wykładnik} * mantysa] \
Zapis liczby zmiennoprzecinkowej zdjęcie
https://www.samouczekprogramisty.pl/assets/images/2017/11/06_IEEE_754_pojedyncza_precyzja.png
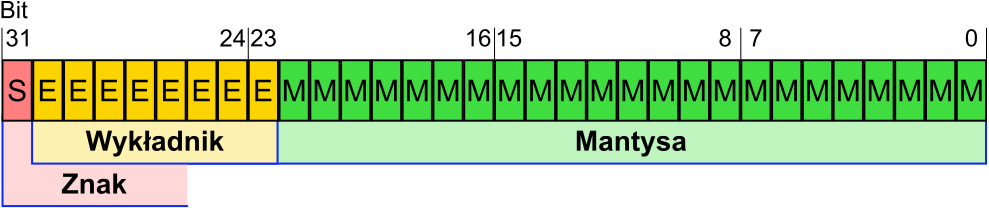{kind=link}
Znak - dodatnia lub ujemna lub 0, jeśli w bit zawiera 0 to liczba jest dodatnia
Wykładnik - wykładnik moze być z zakresu -127 do 128^1, jest zapisywany na 8 bitach, uzywa się kodowania z nadmiarem, wynosi on -127 [bias ] (od zakodowanej liczby nalezy odjąć liczbę 127 aby uzyskać zakodowaną warość)
Mantysa - jest zapisana na 23 bitach, zawiera właściwą liczbę, która zostaje pomnozona przez wykładnik zgodnie ze wzorem
Przykład: liczba 0,0001010110001; po normalizacji to 1,010110001 * 2^{-4}
W znormalizowanej mantysie mamy zawsze jedynkę na początku, zatem ją pomijamy; zatem mając liczbę: 1,010110001 mantysa będzie miała wartość: 0101 1000 1000 0000 0000 000 (zostały uzupełnione zera do 23 miejsc)\
Przykład cały
Liczba: 270,125; binarnie to 100001110,001; po znoramlizowaniu to: 1,00001110001 * 2^{8}
Mamy 11 miejsc, a mantysa powinna mieć 23 więc resztę uzupełniamy zerami, podstać mantysy:
0000 1110 0010 0000 0000 000
Nasz wykładnik to 8, wynika to z przesunięcia normalizacji mantysy. Pamiętając o sposobie kodowania wykładnika dodaję 127. Koduję 135 co daje w zapsie binarnym:\
1000 0111
Naszaa liczba jest dodatnia więc bit znaku to 0\
Cała liczba wygląd atak:
0 1000 0111 0000 1110 0010 0000 0000 000
27. Algorytm Hornera.
Schemat Hornera jest algorytmem służącym do bardzo szybkiego obliczania wartości wielomianu. Redukuje on liczbę mnożeń do minimum.
Pozwala na:
- dzielenie wielomianów przez dwumian x-a
- sprawdzenie czy dana liczba jest pierwiastkiem wielomianu
- obliczanie wartości wielomianu dla pewnego argumentu
https://www.matmana6.pl/schemat-hornera
28. Czym jest sztuczna inteligencja. Sposoby definiowania sztucznej inteligencji. Test Turinga.
sztuczna iteligencja - system lub maszyna, która naśladuje ludzką inteligencję w celu wykonania zadań i moze sukcesywanie usprawniać swoje decyzje w oparciu o zbierane informacje\
sposoby definowania sztucznej inteligencji - \
test Turinga - sposób określania zdolnosći maszyny do posługiwania się językiem naturalnym i pośrednio mający dowodzić opanowania przez nią umiejętności myślenia w sposób podobny do ludzkiego.\ Jezeli maszyna jest inteligentna to znajduący się w drugim pomieszczeniu obserwator nie zdoła odróznić odpowiedzi maszyny od odpowiedzi człowieka
29. Przeszukiwanie przestrzeni stanów. Wybrane algorytmy. Heurystyki.
przeszukiwanie przestrzeniu stanów - czynność mająca na celu znalezienie rozwiązania zadania. Mozna je dzielić na:
- ślepe - nie wykorzystuje informacji o dziedzinie rozwiązywanego problemu
- heurystyczne - wykorzystuje infomacje o dziedzinie rozwiązywanego problemu
Algorytymy:
- przeszukiwanie wszerz - Startując od korzenia (węzeł początkowy) generujemy kolejne węzły poziom po poziomie. Graf budowany jest to momentu znalezienia stanu końcowego
- przeszukiwanie w głąb - z węzła na poziomie j gerneruje się potomka na poziomie j+1, potem j+2 ... . Po dojściu do liścia cofamy się do rodzica, z którego generujemy innego potomka
Heurystyka - metoda znajdowania rozwązań, dla której nie ma gwarancji, znalezienia rozwiązania optymalnego, a często nawet prawidłowego
30. Uczenie maszynowe. Regresja liniowa i logistyczna. Wykorzystanie sztucznych sieci neuronowych w sztucznej inteligencji.
uczenie maszynowe - uczenie komputera jak uczyć się na danych i doskonalić w miarę zdobywania doświadczenia. Takie procesy (uczenie i doskonalenie) nie są zaprogramowane. W uczeniu maszynowym algorytmy są trenowane pod kątem znajdowania wzorców i korelacji w duzych zbiorach danych oraz podejmowania decyzji, tworzenia prognozna podstawie wyników analizy\
regresja linowa - w modelu statystycznym to matody oparte o liniowe kombinacje zmiannych i parametrów dopasowujących model do danych. Dopasuwana linia regresji reprezentuje oczekiwaną wartośc zmiennej y przy wartościach innych zmiennej/ych (takie przewidywanie)\
regresja logistyczna - szczególny przypadek modelu regresji liniowej. Mozna ją zastosować gdy zmianna jest dychotomiczna (przyjmuje tylko dwie wartości)\
sieci neuronowych - system przeznaczony do przetwarzania informacji (budowa jest w pewnym stopniu oparta na rzeczywstym systemie neuronowym)\
31. Automat skończenie stanowy (wersja deterministyczna i niedeterministyczna), język akceptowany przez automat skończenie stanowy.
32. Wyrażenia regularne i języki oznaczane przez te wyrażenia.
wyrazenia regulane - to wzorce opisujący łańcuch symboli, które aparat wyrażeń regularnych próbuje dopasować w tekście wejściowym\
Języki:
- Python
- Ruby
33. Maszyna Turinga - model podstawowy i modele równoważne.
Maszyna Turinga - abstrakcyjny moddel urządzenia przeznaczonej do wykonywania algorytmów. Maszyna składała się z bloku strowania, głowicy odczytującej i zapisującej oraz nieskończonej taśmy (w kazdej komórce taśmy moze zawierać się jeden symbol)
modele równowazny - ?
34. Podstawowe pojęcia: potok graficzny, transformacje liniowe, interpretacja w przestrzeni Euklidesa.
potok graficzny - droga przepływu danych między interfejsem karty graficznej a bufrem ramki zawierającej gotową klatkę animacji 3D. Proces tworzenia kolejnych ramek przebiega sekwencyjnie, przybiera postać animacji, gdzie płynność ruchu zostaje wyś 25 klatek na sekundę
transformacja liniowa - ?
przestrzeń euklidesowa - zbiór punktów, których wzajemnie zalezność da się wyrazić za pomocą odległości i kąta
interpretacja w przestrzeni Euklidesa - ?\
35. Algorytmy grafiki komputerowej: z-bufor, culling, clipping.
z-buforowy - jeśli współrzędna Z danego piksela jest mniejsza od współrzędnej Z zapisanej w buforze, wtedy piksel ten znajduje się bliej obserwatora, czyli mozna go zmodyfikować i ukatualinić wpis w buforze Z. Dzikęki temu uzykuje sie poprawny obraz\
culling - (usuwanie niewidocznych powierzchni) - pierwszych etapów poprzedzających wyświetlanie obrazów, w którym określa się, które z obiektów umieszczonych na scenie są w danym rzucie widoczne\
clipping - (obcinanie) nazwa grupy algorytmów, których celem jest znalezienie części wspólnej obiektu (np. okręgu, odcinka, prostokąta, wielokąta) wyświetlanego w oknie. Ze względu na ograniczone pole widzenia kamery (lub obserwatora), większość elementów jest zwykle niewidoczna. Przetwarzanie ich geometrii przez GPU znacznie spowolniłoby szybkość działania programu, przykładowe algorytmy:
- odrzucenie tynych ścianek
- rysowanie obiektów będących tylko w widoku
36. Model oświetlenia i cieniowania Phonga.
Oświetlenie Phonga - model oświetlenia stosowany w grafice komputerowej, służący do modelowania odbić zwierciadlanych od nieidealnych obiektów, model nie ma podstaw fizycznych, ale dobrze odzwirciedla charkaterrystykę powierzchni
cieniowanie Phonga - technika cienowania wielokątów, w której interpolowany jest wektor normalny do powierzchni. Dla kazdego przetwarzanego piksela wyznaczany jest wektor normalny, a następnie stosuje się wybrany moddel oświetlenia by określić kolor piksela
37. Model jednej próby prostej. Rozkłady teoretyczne. Parametry modelu. Estymatory nieobciążone. Metoda największej wiarogodności.
Model jednej próby prostej
Rozkłąd teoretyczy - (rozkład prawdopodobieństawa) miara probabilistyczna określona na zbiorze wartości pewnej zmiennej losowej (wektora losowego), przypisująca prawdopodobieństwa wartościom tej zmiennej. Formalnie rozkład prawdopodobieństwa można rozpatrywać bez odwołania się do zmiennych losowych\
Metoda największej wiarogodności - polega więc na skonstruowaniu funkcji wiarygodności odpowiadającej zaobserwowanemu zdarzeniu, zależnej od szukanych (estymowanych) parametrów, a następnie na znalezieniu takich wartości tych parametrów, dla których funkcja ta osiąga największą wartość\
Estymatorem nazywamy parametr obliczony dla próby badawczej, na podstawie którego szacujemy prawdziwą wartość parametru w populacji, cel zastosowania: znalezienie parametru rozkładu cechy w populacji.\
Estymator nazywamy nieobciążonym, jeżeli jego wartość oczekiwana jest równa faktycznej wartości parametru\
38. Przedziały ufności. Konstrukcja dokładnych przedziałów ufności. Przybliżone przedziały ufności - metoda bootstrapowa.
przedziały ufnosći - dla danej miary statystycznej informuje nas "na ile możemy ufać danej wartości; pokazuje nam że poszukiwana przez nas rzeczywista wartość mieści się w pewnym przedziale z założonym prawdopodobieństwem.\
przedziały ufności mozna obliczyć przy uzyciu kwartyli?\
metoda bootstrapowa - metoda szacowania (etymacji) wyników wielokrotnego losowania ze zwracaniem z próby. Polega ona na utworzeniu nowego rozkładu wyników na podstawie posiadanych danych, poprzez wilokrotne losowanie wartości z posiadanej próby\
39. Testy statystyczne. Konstrukcja testów statystycznych. Hipotezy, poziom istotności testu, p- wartość.
Testy statystyczne - formuła matematyczna pozwalająca oszacować prawdopodobieńsktwo spełnienia penwej hipotezy statystycznej w populacji na podstwaie próby losowej w tej populacji.\
Testy parametryczne - słuzą do weryfikacji hipotez parametrycznych odnoszących się do parametrów rozkładu badanej cechy w populacji generalnej
- test dwóch średnich
- test dwóch proporcji
Testy nieparametryczne - słuzą do weryfikacji hipotez np. zgodnośc rozkładu cechy z określonym rokłądem prawdopodobieństwa, najczęściej weryfikują sądy o prametrach populacji np. średnia arytmetyczna
- test zgodności chi-kwadrat
- test normalności Shapiro-Wilka
p-wartość - prawdopodobieństwo, że zależność jaką zaobserwowano w losowej próbie z populacji mogła wystąpić przypadkowo, wskutek losowy\
hipotezy - ?\
poziom istotności testu - przyjęte z góry dopuszczalne ryzyko popełnienia błędu I rodzaju (uznania prawdziwej hipotezy zerowej za fałszywą), pozwalające określić, powyżej jakich odchyleń zaobserwowanych w próbie test rozstrzygnie na korzyść hipotezy alternatywnej
40. Symetryczne i asymetryczne protokoły szyfrowania. Algorytmy szyfrowania z kluczem tajnym oraz z kluczem publicznym.
algorytmy symetryczne - to takie, w których kluczb do szyfrowania i deszyfrowania jest ten sam lub jeden mozna w łatwy sposób wyprowadzić z drugiego, przykłady: AES
algorytmy asymetryczne - zawane algorytmami z kluczem jawnym lub publicznym, klucze do szyfrowani i deszyfrowania są rózne i jeden klucz nie mozna wyzczyć z drugiego, przykłady: RSA
41. Algorytmy czasu wielomianowego i wykładniczego ze względu na liczbę bitów danych. Notacja wielkie O.
Algorytmy czasu wielomianowego i wykładniczego ze względu na liczbę bitów danych -
Notacja wielkie O - to notacja przedstawiająca asymptotyczne tempo wzrost, wykorzystywana do zapisywania złozoności obliczeniowej algorytmów.
f(n) = O(g(n)) oznacza, że istnieje taka wartość n0, że dla każdego n większego od n0 jest spełniona nierówność: f(n) ≤ cg(n), gdzie c jest stałą wartością
42. Funkcje jednokierunkowe. Bezpieczeństwo systemów kryptograficznych.
Funcja jednokierunkowa - funkcja, którą łatwo obliczyć, ale za to dużo trudniej obliczyć wartość jej funkcji odwrotnej. Znając wartośc x mozna łatwo oblczyć f(x). Z drugiej strony znając f(x) trudno oobliczyć x
(W sensie ściśle matematycznym nie jest udowodnione, że funkcje jednokierunkowe rzeczywiście istnieją)
Bezpieczeństwo -?