245 KiB
245 KiB
Algorytm PAM (Partitioning Around Medoids)
Input:
- dane w N wymiarach (zbiór punktów)
- metrykę dystansu (tutaj zakładamy odległość euklidesową)
Output:
- Znalezione skupienia punktów które są bliskie sobie
- Liczba skupień (k) jest wybranym przez użytkownika parametrem
Przykład klasteryzacji:

Algorytm PAM jest bardzo podobny do popularnego k-means
_Główna różnica jest taka że środkiem znalezionego skupienia jest jeden z punktów z danych wejściowych, a w k-means zwykle tak nie jest
Pod względem wydajnościowym PAM jest zwykle wolniejszy niż k-means ale bardziej odporny na obserwacje odstające (dzięki temu że środek grupy musi być jednym z punktów).
Algorytm
- Wybranie losowo _k punktów jako pierwszych medoid
- Przypisanie każdego z punktów w danych do najbliższej medoidy
- Tak długo jak następują zmiany / poprawa dystansów:
- Dla każdej z medoid podmieniamy ją z nie-medoidami i patrzymy, czy nastąpiała poprawa dystansów
- Jeśli tak, to wykonujemy podmianę i zapamiętujemy obecną wartość średniego dystansu
Implementacja PAM (bez numpy)
from __future__ import annotations
from typing import Sequence
# Własna implementacja wielowymiarowych punktów
class Point:
def __init__(self, coordinates : Sequence[float]):
self.coordinates = coordinates
def __str__(self):
return str(['{:.2f}'.format(x) for x in self.coordinates])
def __repr__(self):
return self.__str__()
def distance_to(self, other : Point) -> float: # Dystans euklidesowy
if len(self.coordinates)!=len(other.coordinates): # Punkty muszą mieć te same wymiary
raise ValueError
dist = 0
for x, y in zip(self.coordinates, other.coordinates):
dist+=(x-y)**2
dist = dist**(1/2)
return distpoint_1 = Point([3,3,3])
point_2 = Point([1,1,1])
print(point_1.distance_to(point_2))3.4641016151377544
print(point_1)['3.00', '3.00', '3.00']
Funkcje pomocnicze do generowania wielowymiarowych danych dookoła punktów
Dystans względem każdego z wymiarów
import random
def generate_data(centers : Sequence[Point], data_points : int, x_y_dist_from_center : float) -> Sequence[Point]: # Dystans manhattański
points = []
for x in range(data_points):
center = random.choice(centers)
coords = []
for index in range(len(center.coordinates)):
existing_coord = center.coordinates[index]
coords.append(existing_coord+random.uniform(-x_y_dist_from_center,x_y_dist_from_center))
points.append(Point(coords))
return pointsLosowe punkty w odległości euklidesowej od punktu
- Wybór punktu (centrum)
- Losowanie wektora kierunku + normalizacja
- Mnożenie wektora kierunku przez losową odległość z zakresu (-dystans, dystans)
- Dodanie tego wektora do centrum
def generate_data_sphere(centers : Sequence[Point], data_points : int, dist_from_center : float) -> Sequence[Point]: # Dystans euklidesowy (losowy wektor kierunku * losowy dystans)
points = []
for x in range(data_points):
center = random.choice(centers)
direction_vector = []
for i in range(len(center.coordinates)):
direction_vector.append(random.uniform(-1,1))
direction_vector_length = 0
for i in range(len(direction_vector)):
direction_vector_length+=direction_vector[i]**2
direction_vector_length = direction_vector_length**(1/2)
direction_vector_normalized = [z/direction_vector_length for z in direction_vector]
random_length = random.uniform(-dist_from_center, dist_from_center)
coords_1 = [i*random_length for i in direction_vector_normalized]#direction_vector_normalized*random_length
coords_2 = [x+y for x,y in zip(center.coordinates, coords_1)]
points.append(Point(coords_2))
return pointsimport matplotlib.pyplot as plt
def draw_custom_points(point_list : Sequence[Point]): #2D
x_values = [point.coordinates[0] for point in point_list]
y_values = [point.coordinates[1] for point in point_list]
plt.scatter(x_values, y_values)
plt.show()
generated_points = generate_data([Point([-3,3]), Point([3,3]), Point([0,0])],data_points=50, x_y_dist_from_center=1)
draw_custom_points(generated_points)generated_points_sphere = generate_data_sphere([Point([-3,3]), Point([3,3]), Point([0,0])],data_points=50, dist_from_center=1)
draw_custom_points(generated_points_sphere)generated_points = generate_data([Point([-2,-1]), Point([0,0]), Point([3,0])],data_points=250, x_y_dist_from_center=1)
draw_custom_points(generated_points)generated_points = generate_data_sphere([Point([-2,-1]), Point([0,0]), Point([3,0])],data_points=250, dist_from_center=1)
draw_custom_points(generated_points)Funkcja do wizualizacji grup
def draw_clustering(assignment): # Pojedynczy obraz
for medoid in assignment.keys():
point_list = assignment[medoid]
x_values = [point.coordinates[0] for point in point_list]
y_values = [point.coordinates[1] for point in point_list]
plt.scatter(x_values, y_values, alpha=0.5)
x_values = [point.coordinates[0] for point in assignment.keys()]
y_values = [point.coordinates[1] for point in assignment.keys()]
plt.scatter(x_values, y_values,color='r', marker='*')
plt.show()Implementacja PAM
def medoid_similarity(medoid : Point, other_points : Sequence[Point]) -> float: # Suma dystansów punktów od danej medoidy
distances = 0
for point in other_points:
distances+= medoid.distance_to(point)
return distances
def assign_points_to_medoids(medoids : Sequence [Point], points : Sequence [Point]) -> dict():
assignments = dict()
for i in medoids:
assignments[i] = []
for point in points:
minimum_distance = point.distance_to(medoids[0])
selected_medoid = medoids[0]
for med in medoids[1:]:
new_distance = point.distance_to(med)
if new_distance<minimum_distance:
minimum_distance = new_distance
selected_medoid = med
assignments[selected_medoid].append(point)
return assignments
def evaluate_assignment(assignment): # Suma dystansów wszystkich punktów od swoich medoid
sum_of_distances = 0
for i in assignment.keys():
sum_of_distances+=medoid_similarity(i,assignment[i])
return sum_of_distances
def pam_clustering(points : Sequence[Point], k : int):
# Inicjalizacja
if k<2 or len(points)<k:
raise ValueError
medoids = random.sample(points, k)
assignments = assign_points_to_medoids(medoids, points)
# Aktualizacja
finished = False
counter = 1
while not finished:
print(f"Iteracja #{counter}")
counter+=1
finished = True # Zmienione jeśli zmieni się którakolwiek medoida
old_medoids = list(assignments.keys())
sum_of_distances = evaluate_assignment(assignments)
print(f"Suma dystansów: {sum_of_distances}")
for med in old_medoids:
for p in points:
if p in old_medoids:
continue # Punkt już był medoidą więc go nie podmieniamy
temp_medoids = list(old_medoids)
temp_medoids.remove(med)
temp_medoids.append(p)
temp_assignment = assign_points_to_medoids(temp_medoids, points)
new_distance = evaluate_assignment(temp_assignment)
if new_distance<sum_of_distances:
finished = False
assignments = temp_assignment
return assignmentsassigned = pam_clustering(generated_points, 3)Iteracja #1 Suma dystansów: 434.617796455687 Iteracja #2 Suma dystansów: 264.08951904585876 Iteracja #3 Suma dystansów: 261.2793052260453 Iteracja #4 Suma dystansów: 260.85114450030653 Iteracja #5 Suma dystansów: 260.6058082820335 Iteracja #6 Suma dystansów: 260.4464699552831 Iteracja #7 Suma dystansów: 260.10321768609066 Iteracja #8 Suma dystansów: 196.62056427902047 Iteracja #9 Suma dystansów: 182.11973310593467 Iteracja #10 Suma dystansów: 165.26633815194202 Iteracja #11 Suma dystansów: 164.96801655579426 Iteracja #12 Suma dystansów: 164.76351795007898 Iteracja #13 Suma dystansów: 164.7398575438859 Iteracja #14 Suma dystansów: 127.60705219305643 Iteracja #15 Suma dystansów: 126.90465381027721 Iteracja #16 Suma dystansów: 125.85723677651899 Iteracja #17 Suma dystansów: 125.72984134429592
draw_clustering(assigned)generated_points = generate_data_sphere([Point([-1,-1.5]), Point([-0.5,-0.5]), Point([0.5,0])],data_points=250, dist_from_center=1.5)
draw_custom_points(generated_points)assigned = pam_clustering(generated_points, 3)Iteracja #1 Suma dystansów: 243.98967622114225 Iteracja #2 Suma dystansów: 222.0364217881434 Iteracja #3 Suma dystansów: 216.99784343452706 Iteracja #4 Suma dystansów: 208.83179723203483 Iteracja #5 Suma dystansów: 189.60895077892857 Iteracja #6 Suma dystansów: 188.71433884981388 Iteracja #7 Suma dystansów: 180.490761866527 Iteracja #8 Suma dystansów: 180.19838386092528 Iteracja #9 Suma dystansów: 179.8660553672085 Iteracja #10 Suma dystansów: 179.8536292324992 Iteracja #11 Suma dystansów: 178.97570181315245 Iteracja #12 Suma dystansów: 178.89244011436267 Iteracja #13 Suma dystansów: 178.34753499716496 Iteracja #14 Suma dystansów: 178.19596929138834 Iteracja #15 Suma dystansów: 165.77720257659146 Iteracja #16 Suma dystansów: 164.18186436174895 Iteracja #17 Suma dystansów: 164.0636488364166 Iteracja #18 Suma dystansów: 163.10129112522043 Iteracja #19 Suma dystansów: 162.98527642121257 Iteracja #20 Suma dystansów: 162.30806701011045 Iteracja #21 Suma dystansów: 162.18265851612782 Iteracja #22 Suma dystansów: 161.86121102326487
Dużo iteracji jest "zmarnowane" na bardzo drobne poprawy dystansu
draw_clustering(assigned)import pprint
pprint.pprint(assigned){['-0.41', '-0.55']: [['-0.74', '-0.32'],
['-0.62', '-0.18'],
['-0.26', '0.06'],
['-0.13', '-0.72'],
['-0.53', '-0.36'],
['0.22', '-0.80'],
['-0.64', '-0.34'],
['-0.20', '-1.12'],
['0.38', '-1.42'],
['-0.25', '-0.30'],
['-0.33', '-0.19'],
['-0.70', '-0.90'],
['-1.50', '-0.44'],
['-0.32', '-0.95'],
['-0.17', '-0.70'],
['0.30', '-0.99'],
['-0.42', '-0.62'],
['-1.65', '0.04'],
['-0.41', '-0.55'],
['-0.54', '-0.41'],
['-0.83', '0.36'],
['-0.48', '0.41'],
['0.31', '-0.86'],
['-0.74', '-0.32'],
['-0.37', '-0.37'],
['-0.38', '-0.24'],
['0.02', '-0.51'],
['-0.68', '-0.52'],
['0.10', '-1.06'],
['0.37', '-0.95'],
['-0.59', '0.08'],
['-0.75', '-0.41'],
['-0.53', '-0.74'],
['-0.06', '-0.89'],
['-0.82', '-0.31'],
['-0.28', '0.23'],
['0.14', '-1.08'],
['0.06', '-1.25'],
['-0.49', '-0.64'],
['-0.74', '0.72'],
['-0.80', '0.20'],
['-0.32', '0.06'],
['-0.50', '-0.46'],
['-0.15', '-0.77'],
['-0.20', '-0.63'],
['-0.49', '-0.48'],
['-0.68', '-0.36'],
['-0.60', '-0.55'],
['-0.84', '0.14'],
['-0.22', '-0.65'],
['0.16', '-0.54'],
['0.32', '-1.35'],
['-0.05', '-0.20'],
['0.16', '-1.60'],
['-0.28', '-1.08'],
['-0.22', '-1.19'],
['-0.20', '-0.02'],
['0.32', '-1.18'],
['-0.80', '-0.67'],
['-0.39', '-0.63'],
['-0.77', '-0.99'],
['-0.87', '-0.53'],
['-0.12', '-0.47'],
['-0.82', '-0.27'],
['-0.81', '-0.65'],
['-0.78', '0.33'],
['-0.40', '-1.04'],
['-0.61', '-0.39'],
['-1.56', '-0.37'],
['-0.15', '-0.84'],
['-0.02', '-0.50'],
['-0.15', '0.05'],
['-0.31', '-1.30'],
['-1.23', '-0.34'],
['0.23', '-0.80'],
['-0.46', '-0.62'],
['-0.58', '0.73'],
['-0.54', '-0.57'],
['-0.85', '-0.24'],
['-1.73', '0.12'],
['-0.35', '-0.42'],
['-0.16', '-0.79'],
['-0.25', '-0.87'],
['-0.04', '-1.26'],
['0.53', '-1.59'],
['0.13', '-1.44'],
['-0.65', '-0.66'],
['-0.89', '-0.53']],
['-1.05', '-1.56']: [['-1.39', '-2.23'],
['-1.03', '-1.14'],
['-0.17', '-2.12'],
['-1.22', '-1.40'],
['-0.83', '-1.11'],
['-0.95', '-1.70'],
['-0.99', '-1.38'],
['-1.76', '-2.65'],
['-0.78', '-1.18'],
['-0.84', '-1.28'],
['-0.01', '-1.54'],
['-0.40', '-1.45'],
['-1.36', '-1.15'],
['-0.98', '-1.67'],
['-0.73', '-1.18'],
['-0.24', '-1.62'],
['-1.11', '-1.24'],
['-0.97', '-1.46'],
['-1.69', '-0.75'],
['-2.05', '-1.62'],
['-1.19', '-2.35'],
['-2.12', '-2.34'],
['-1.98', '-0.81'],
['-0.75', '-1.54'],
['-2.02', '-1.88'],
['-0.93', '-0.98'],
['-0.92', '-2.71'],
['-1.05', '-1.26'],
['-1.05', '-1.56'],
['-1.81', '-2.55'],
['-1.11', '-1.03'],
['-2.05', '-2.50'],
['-1.85', '-2.60'],
['-1.02', '-2.33'],
['-1.06', '-1.70'],
['-1.18', '-1.55'],
['-2.17', '-0.78'],
['-1.99', '-2.12'],
['-0.85', '-1.54'],
['-1.01', '-1.87'],
['-1.57', '-0.93'],
['-0.26', '-1.87'],
['-1.27', '-2.81'],
['-0.88', '-1.64'],
['-0.68', '-1.69'],
['-2.13', '-1.31'],
['-1.19', '-1.91'],
['-0.68', '-1.12'],
['-1.29', '-1.21'],
['-1.26', '-1.48'],
['-0.83', '-1.90'],
['-0.85', '-1.42'],
['-1.38', '-2.95'],
['-0.80', '-2.53'],
['-2.05', '-1.16'],
['-1.12', '-1.41'],
['-0.67', '-2.01'],
['-1.14', '-1.38'],
['-0.22', '-2.39'],
['-1.45', '-2.16'],
['-1.11', '-1.18'],
['-1.03', '-1.31'],
['-0.44', '-1.29'],
['-1.92', '-1.58'],
['-1.96', '-0.75'],
['-0.65', '-2.27'],
['-1.13', '-1.39'],
['-2.35', '-1.37'],
['-1.43', '-2.23'],
['-0.51', '-2.86'],
['-0.94', '-1.34'],
['-1.87', '-2.25'],
['-1.10', '-1.76'],
['0.42', '-1.97'],
['-1.46', '-0.97'],
['-0.49', '-2.53'],
['-0.88', '-1.51'],
['-0.82', '-2.45'],
['-1.05', '-1.10'],
['-1.42', '-2.00'],
['-1.93', '-2.25']],
['0.62', '0.16']: [['0.50', '-0.01'],
['1.00', '1.24'],
['0.75', '0.01'],
['0.31', '-0.37'],
['0.98', '1.41'],
['0.23', '1.34'],
['0.01', '0.04'],
['0.84', '-0.42'],
['0.41', '0.25'],
['-0.21', '1.10'],
['1.60', '0.83'],
['0.28', '-0.22'],
['0.51', '0.01'],
['-0.06', '0.87'],
['1.26', '-1.16'],
['1.25', '-0.53'],
['0.44', '0.00'],
['1.08', '1.02'],
['0.52', '-0.78'],
['0.84', '-0.72'],
['0.81', '0.21'],
['-0.30', '0.98'],
['1.11', '0.22'],
['0.57', '-0.45'],
['-0.09', '0.44'],
['1.15', '0.73'],
['1.02', '0.86'],
['0.77', '-0.65'],
['0.07', '0.14'],
['1.45', '0.39'],
['-0.37', '0.94'],
['-0.42', '0.87'],
['0.97', '1.31'],
['0.43', '0.41'],
['0.50', '-0.00'],
['0.55', '0.23'],
['0.42', '0.01'],
['0.26', '-0.20'],
['1.18', '-0.95'],
['0.70', '0.19'],
['0.53', '-0.17'],
['0.49', '-0.04'],
['1.80', '0.23'],
['0.99', '0.51'],
['0.69', '-0.36'],
['1.59', '-0.28'],
['1.18', '-0.76'],
['0.08', '0.29'],
['1.08', '0.23'],
['0.94', '-0.68'],
['-0.07', '0.28'],
['0.94', '-0.65'],
['1.06', '0.60'],
['0.42', '-0.07'],
['1.96', '0.15'],
['0.29', '0.01'],
['0.62', '0.16'],
['0.04', '-0.09'],
['0.25', '1.40'],
['-0.22', '0.68'],
['0.46', '0.03'],
['1.22', '0.12'],
['0.77', '0.07'],
['-0.26', '1.23'],
['0.71', '0.29'],
['0.06', '0.54'],
['0.85', '-0.78'],
['0.17', '0.08'],
['0.71', '1.07'],
['1.31', '0.99'],
['0.28', '0.62'],
['1.38', '0.75'],
['0.68', '-0.63'],
['1.47', '-0.23'],
['0.56', '-0.02'],
['0.50', '0.00'],
['1.07', '0.27'],
['0.53', '1.35'],
['1.06', '-0.01'],
['0.47', '-0.11'],
['0.43', '0.18']]}
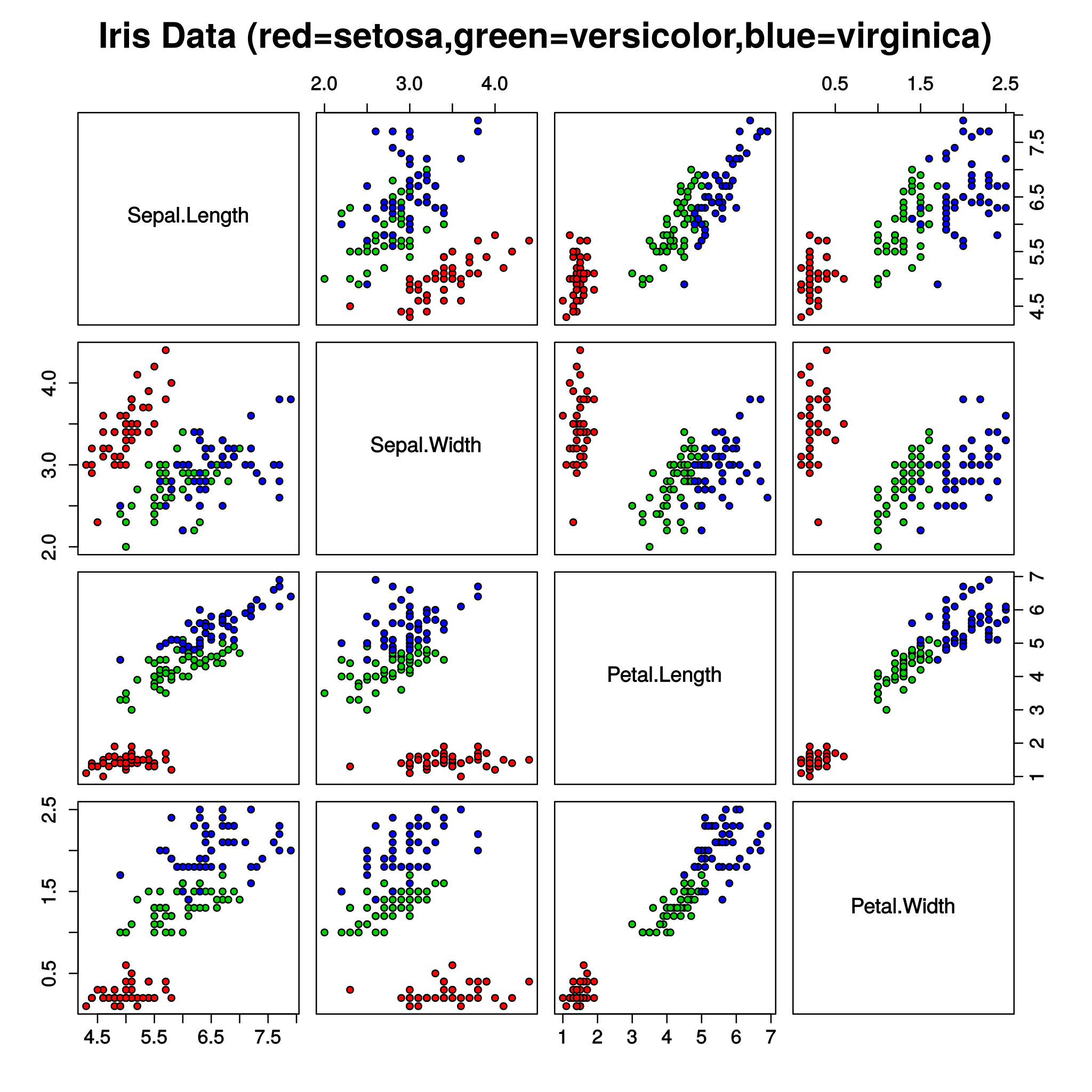
Test na zbiorze danych Iris
import pandas as pd
df = pd.read_csv("Iris.csv")
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 150 non-null int64 1 SepalLengthCm 150 non-null float64 2 SepalWidthCm 150 non-null float64 3 PetalLengthCm 150 non-null float64 4 PetalWidthCm 150 non-null float64 5 Species 150 non-null object dtypes: float64(4), int64(1), object(1) memory usage: 7.2+ KB
W celu łatwiejszej wizualizacji bierzemy pod uwagę tylko dwie zmienne
sepal_length = df["SepalLengthCm"].tolist()
petal_length = df["PetalLengthCm"].tolist()
data_points = [Point([x,y]) for (x,y) in list(zip(sepal_length,petal_length))]
iris_assignments = pam_clustering(data_points, 3)
draw_clustering(iris_assignments)Iteracja #1 Suma dystansów: 208.75650656990624 Iteracja #2 Suma dystansów: 205.49853399261397 Iteracja #3 Suma dystansów: 204.25697334421366 Iteracja #4 Suma dystansów: 200.61634101769542 Iteracja #5 Suma dystansów: 199.7822154497639 Iteracja #6 Suma dystansów: 197.1753293339581 Iteracja #7 Suma dystansów: 141.19412116737692 Iteracja #8 Suma dystansów: 83.09469686229966 Iteracja #9 Suma dystansów: 83.03438870792166 Iteracja #10 Suma dystansów: 82.64480640416339 Iteracja #11 Suma dystansów: 79.97152485282157 Iteracja #12 Suma dystansów: 78.83128830941482 Iteracja #13 Suma dystansów: 77.28460137329213 Iteracja #14 Suma dystansów: 76.44054418397423 Iteracja #15 Suma dystansów: 75.68752087906972 Iteracja #16 Suma dystansów: 75.60046263155463
Prawdziwe klasy dla porównania (pierwsza kolumna, trzeci rząd):
Źródło: Nicoguaro, CC BY 4.0 https://creativecommons.org/licenses/by/4.0, via Wikimedia Commons