forked from AITech/aitech-ium
20 KiB
20 KiB
Inżynieria uczenia maszynowego
5 czerwca 2024
13. Przygotowanie publikacji naukowej
Abstract
- Umiejętność pisania artykułu naukowego może okazać się przydatna dla osób zajmujących się uczeniem maszynowym.
- Zastosowanie klarownej struktury dokumentu ułatwia jego odbiór jak i tworzenie.
- LaTeX + Overleaf jaka narzędzia do składu artykułu
Introduction
- Uczenie maszynowe i jego zastosowania to prężnie rozwijająca się dziedzina nauki
- Żeby nadążyć za jej rozwojem musimy czytać artykuły naukowe
- A jeśli nasza praca ma charakter badawczy, to warto efekty naszej pracy od zebrać w postaci artykułu i opublikować
- Nasz pracodawca może od nas tego wymagać lub przynajmniej zachęcać
- Dlatego zapoznamy się z:
- Strukturą artykułu naukowego
- Technicznymi aspektami jego tworzenia
Related work
Jak napisać artykuł naukowy z dziedziny ML:
- http://www.isle.org/~langley/papers/craft.ml2k.pdf / https://icml.cc/Conferences/2002/craft.html
- https://www.researchgate.net/publication/337857231_How_to_Write_a_Machine_Learning_Paper_for_not_so_Dummies/comments
- https://towardsdatascience.com/writing-more-successful-machine-learning-research-papers-39863ca9ea90
- https://towardsdatascience.com/tips-for-reading-and-writing-an-ml-research-paper-a505863055cf
Dobre wyjaśnienie struktury artykułu naukowego znajdziemy w napisanym po polsku artykule
Methods
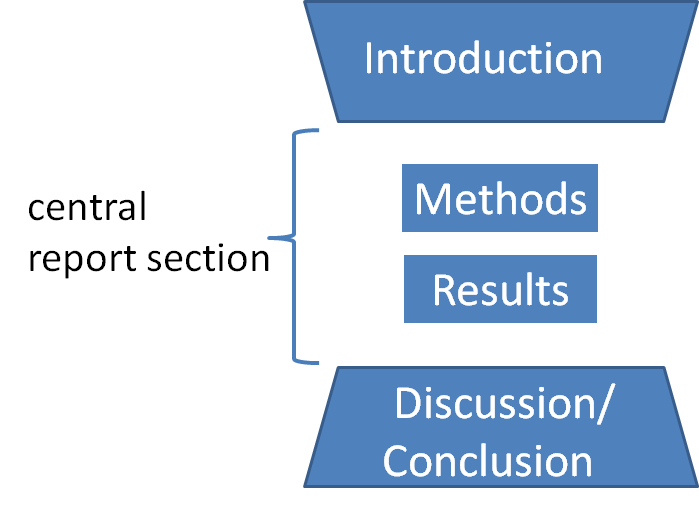
Struktura artykułu naukowego
Struktura (A)IMRaD:
- Abstrakt (Abstract) - Dlaczego, jak,
- Wprowadzenie (Introduction) - "Dlaczego?"
- Related work - "Kontekst naukowy"
- Metody (Method) - "Jak?"
- Wyniki (Results) - "Co?"
- Wnioski (Discussion/Conclusions) - "Interpretacja wyników"
Tytuł
- powinien odzwierciedlać treść artykułu ;)
- nie za długi (< 12 wyrazów)
- lepiej, żeby nie był pytaniem (patrz Prawo nagłówków Betteridge'a, choć niekoniecznie)
- dobry artykuł może mieć krótki, chwytliwy tytuł, szczególnie, jeśli autorzy mają renomę ;) Przykłady:
Abstrakt
- stanowi samodzielną całość - powinien być zrozumiały bez reszty artykułu
- jest bardzo istotny - stanowi "reklamówkę" naszej pracy - ma zachęcić do lektury
- powinien zawierać wszystkie najważniejsz elementy artykułu i mieć podobną strukturę (IMRaD)
Wprowadzenie
- Kontekst badań
- Od ogółu do szczegółu
- Motywacja
- Co chcemy właściwie zbadać - sformułowanie hipotezy badawczej
Related work
- Kontekst naukowy
- Co zrobiono przed nami
- Musimy się do tego odnieść w dalszej części i zaznaczyć co nasze badania wnoszą nowego do dziedziny
- Cytujemy najważniejsze prace
- Najlepiej zacząć szeroko i w przeszłości i stopniowo przechodzili do coraz nowszych i bardziej szczegółowych badań, bliżej związanych z tematyką poruszaną w naszym artykule.
Metody
- Jak przeprowadziliśmy nasze badania/eksperymenty
- Informacje tu zawarte w powinny umożliwić zreprodukowanie naszych wyników innym badaczom
- Opisujemy:
- Dane
- Algorytmy/architekturę
- możemy, choć nie musimy, podać techniczne szczegóły dotyczące implementacji, np. użyty framework. Zazwyczaj jednak kwestie techniczne nie są istotne i możemy od nich abstrahować, a na potrzeby reprodukowalności wyników najlepiej po prostu opublikować kod źródłowy/dane i wspomnieć o tym w artykule
- Procedurę ewaluacji/testowania
- Warto na naszych dancyh przetestować metodą bazową ("baseline") - np. obecny SOTA ("State of the art"), żeby potem móc do niej porównać nasze rozwiązanie.
Wyniki
- Jakie wyniki otrzymaliśmy
- Powstrzymajmy się z ich interpretacją
- Możemy dokonywać porównań, ale z opiniami w stylu "Nasze podejście deklasuje obecny SOTA" (State Of The Art) poczekajmy do następnej sekcji
Konkluzje
- Interpretacja wyników
- Jakie jest ich znaczenie?
- Jak prezentują się w szerszym kontekście
- Tak jak we wprowaszeniu przechodzimy od ogółu do szczegółu (zawężamy perspektywę), tutaj postępujemy odwrotnie - zaczynając od szczegółowej interpretacji przechodzimy do znaczenia wyników w szerszym kontekście
LaTeX
- LaTeX (wym. _latech) to system składu tekstu
- Najbardziej popularny w dziedzinach technicznych
- https://www.latex-project.org//
- Podejście WYSIWYM("What you see is what you mean") w przeciwieństwie do WYSIWIG (What you see is what you get - przykład: Word).
- Piszemy tekst ze znacznikami, kompilujemy, dostajemy gotowy dokument, np. pdf
- Stosowany powszechnie do pisania publikacji naukowych (artykułów, książek jak i rozpraw nukowych)
- Pozwala łatwo zmienić styl/szablon
- W założeniu, podczas pisania skupiamy się na treści i strukturze a LaTeX sam zatroszczy się o wygląd
- Przystępna dokumentacja: https://www.overleaf.com/learn/latex/Learn_LaTeX_in_30_minutes
Struktura
\documentclass[conference]{IEEEtran}
%\documentclass[a4paper]{IEEEconf}
\usepackage[]{graphicx}
% to typeset algorithms
\usepackage{algorithmic}
\usepackage{algorithm}
% to typeset code fragments
\usepackage{listings}
% to make an accent \k be available
\usepackage[OT4,T1]{fontenc}
% provides various features to facilitate writing math formulas and to improve the typographical quality of their output.
\usepackage[cmex10]{amsmath}
\interdisplaylinepenalty=2500
% por urls typesetting and breaking
\usepackage{url}
% for vertical merging table cells
\usepackage{multirow}
% \usepackage[utf8]{inputenc}
\title{Research paper structure in LaTeX}
%\author{}
\name{Tomasz Ziętkiewicz}
\begin{document}
\maketitle
%
\begin{abstract}
This paper is an example of a paper structure in \LaTeX
\end{abstract}
\noindent\textbf{Index Terms}: speech recognition, error correction, post-processing, post-editing, natural language processing
\section{Introduction}
Introductions has always been very important parts of scientific papers...
\section{Related work} \label{sec:related}
Tips on writing research papers can be found in \cite{howtowrite}
\section{Data} \label{sec:data}
Data is prepared using our novel data pipeline presented on figure \ref{fig:data-piepline}
\begin{figure}[htbp]
\centering
\label{fig:data-pipeline}
\includegraphics[scale=0.6]{data-pipeline.pdf}
\caption{Data preparation pipeline}
\end{figure}
Data statistics are shown in Table \ref{tab:data}.
Data sets were randomly divided into training, development, and test subsets in a proportion 8:1:1.
\begin{table}
\caption{Datasets statistics }
\label{tab:data}
\centering
\begin{tabular}{|l|r|r|r|r|r|}
\hline
Language & \textbf{de-DE} & \textbf{es-ES} & \textbf{fr-FR} \\\\
\hline
Sentences & $12 242$ & $16 905$ & $7180$ \\\\
Tokens & $37 955$ & $55 567$ & $28 004$ \\\\
\hline
\end{tabular}
\end{table}
\section{Method} \label{sec:method}
The proposed method consists of ...
\subsection{Data preparation}
To train the model, a lot of data is needed...
\subsection{Architecture}
\section{Results} \label{sec:results}
Table \ref{tab:results} presents averaged results.
The metric used is computes as follows:
\begin{equation}
RMSE = \sqrt{\frac{1}{n}\Sigma_{i=1}^{n}{\Big(\frac{d_i -f_i}{\sigma_i}\Big)^2}}
\end{equation}
where ...
\begin{table}
\begin{tabular}{|l|c|c|c|c|c|}
\hline
& Train & Test & Dev & - & Eval\\\\
\hline
Raw ASR 1best & 9.59 & 12.08 & 12.39 & 45.64 & 27.6\\\\
\hline
lattice oracle WER & 3.75 & 4.72 & 4.93 & 30.71 & 17.7\\\\
\hline
Edit operation tagger (from 1best) & - & 10.7 & - & - & 24.7\\\\
\hline
Absolute WER Reduction & - & $11.42\%$ & - & - & $10.50\%$ \\\\
\hline
Relative WER Reduction & - & $11.42\%$ & - & - & $10.50\%$ \\\\
\hline
\end{tabular}
\label{tab:results}
\caption{Word Error Rates for input data and the proposed system.}
\end{table}
\section{Conclusions} \label{sec:conclusions}
We presented a new approach to ASR errors correction problem. As demonstrated using three independent datasets, correction models trained using this approach are effective even for relatively small training datasets. The method allows to precisely control which errors should be included in the model and which of the included ones should be corrected at the inference time. The evaluations performed on the models show that they can significantly improve the ASR results by reducing the WER by more than $20\%$. All of the models presented offer very good inference latency, making them suitable for use with streaming ASR systems.
The presented method is well suited for industrial applications where the ability to precisely control how the error correction model works, as well as small latency, are crucial.
%\section{Acknowledgements}
\bibliographystyle{IEEEtran}
\bibliography{bibliography}
\end{document}
@book{Hastie2009,
title={The Elements of Statistical Learning: Data Mining, Inference, and Prediction},
author={Hastie, Trevor and Tibshirani, Robert and Friedman, Jerome},
year={2009},
publisher={Springer},
address = {New York, NY},
edition = {2nd}
}
@article{Byon2013,
title = {Wind turbine operations and maintenance: A tractable approximation of dynamic decision-making},
author = {Byon, E.},
journal = { IIE Transactions},
volume = {45},
number = {11},
pages = {1188--1201},
year = {2013}
}
@inproceedings{Breunig2000,
title={{LOF}: Identifying density-based local outliers},
author={Breunig, M. M. and Kriegel, H.-P. and Ng, R. T. and Sander, J.},
booktitle={Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data},
pages={93--104},
year={2000},
organization={ACM}
}
@incollection{Yang2010,
author = "Yang, J. AND Huang, T. S.",
title = "Image super-resolution: {H}istorical overview and future challenges",
booktitle = "Super-Resolution Imaging",
editor = "Milanfar, Peyman",
pages ="3--35",
publisher = "Chapman \& Hall/CRC Press",
address = {Boca Raton, FL},
year = "2010"
}
Overleaf
- Overlaf to serwis/aplikacja webowa umożliwiająca edycję i kompilację dokumentów Latexa on-line, w przeglądarce
- https://www.overleaf.com/
- Działa od ręki, bez potrzeby konfiguracji, instalacji pakietów itp.
- podgląd gotowego dokumentu, automatyczna kompilacja
- edytor z uzupełnianiem składni
- intagracja z Git/GitHub
arXiv.org
- https://arxiv.org/
- baza artykułów, uporządkowanych według kategorii
- umożliwia samodzielne opublikowanie artykułu jeszcze przed wysłaniem go do czasopisma/na konferencję. Artykuły tam dostępne nie są recenzowane, ale jest to sposób na otrzymanie feedbacku od społeczności poza oficjalnym procesem publikacyjnym.
Materiały pomocnicze
- JupyterBook: https://jupyterbook.org/en/stable/intro.html
- The Turing Way: https://the-turing-way.netlify.app/welcome.html
Conclusions
Zadanie [20pkt] - 19 czerwca 2024
- Wybierz konferencję naukową z dziedziny ML/AI/Computer Science.
- 💡 Możesz sugerować się którąś z poniższych list:
- Używając szablonu LaTeX udostępnionego przez organizatorów konferencji, stwórz szkic artykułu naukowego opisującego wyniki eksperymentów ML, które przeprowadziłaś/eś w trakcie zajęć.
- Napisz artykuł używając Overleaf. Udostępnij w arkuszu z zapisami link udostępniający dokument (jak stworzyć taki link)
- Artykuł musi zawierać co najmniej:
- 6 niepustych sekcji (abstract, introduction, related work, method, results, conclusions)
- jedną tabelkę (np. opisującą dane lub wyniki)
- jedną ilustrację (np. jakiś wykres, który tworzyli Państwo na zajęciach)
- 5 cytowań (można np. zacytować artykuły opisujące użytą metodę, zbiory danych, narzędzia. Zazwyczaj popularne biblioteki, datasety podają w README jak należy je cytować)
- 1 wzór matematyczny
- Artykuł nie musi być długi i profesjonalnie napisany, chodzi raczej o zaznajomienie się z formą i strukturą :)
- Artykuł powinien być zgodny z wytycznymi konferencji dotyczącymi formy artykułów (oczywiście poza liczbą stron)Zapewne w napisanym artykule nie opiszą państwo niczego nowatorskiego i wartego publikacji - tutaj udajemy, że zastosowaliśmy metodę po raz pierwszy, osiągnęliśmy nieosiągalne dotąd wyniki itp. Liczy się forma i struktura pracy. Można dodać komentarz wyjaśniający prawdziwy cel artykuły w sekcji/przypisie "Disclaimer", żeby nikt Państwa nie posądzał o pisanie nieprawdy.
