21 KiB

Modelowanie języka
06. Ewaluacja modeli języka [wykład]
Filip Graliński (2022)

Ewaluacja modeli języka
Jak już widzimy, możemy mieć różne modele języka. Nawet jeśli pozostajemy tylko na gruncie najprostszych, $n$-gramowych modeli języka, inne prawdopodobieństwa uzyskamy dla modelu digramowego, a inny dla trigramowego. Jedne modele będą lepsze, inne — gorsze. Jak obiektywnie odróżnić dobry model od złego? Innymi słowy, jak ewaluować modele języka?
Ewaluacja zewnętrzna i wewnętrzna
W ewaluacji zewnętrznej (ang. _extrinsic) ewaluację modelu języka sprowadzamy do ewaluacji większego systemu, którego częścią jest model języka, na przykład systemu tłumaczenia maszynowego albo systemu ASR.
Ewaluacja wewnętrzna (ang. _intrinsic) polega na ewaluacji modelu języka jako takiego.
Podział zbioru
Po pierwsze, jak zazwyczaj bywa w uczeniu maszynowym, powinniśmy podzielić nasz zbiór danych. W modelowaniu języka zbiorem danych jest zbiór tekstów w danym języku, czyli korpus języka. Powinniśmy podzielić nasz korpus na część uczącą (_training set) $C = \{w_1\ldots w_N\}$ i testową (_test set) $C' = \{w_1'\ldots w_{N'}'\}$.
Warto też wydzielić osobny „deweloperski” zbiór testowy (_dev set) — do testowania na bieżąco, optymalizacji hiperparametrów itd. Zbiory testowe nie muszą być bardzo duże, np. kilka tysięcy zdań może w zupełności wystarczyć.
Tak podzielony korpus możemy traktować jako wyzwanie modelowania języka.
Przykład wyzwania modelowania języka
Wyzwanie [https://gonito.net/challenge/challenging-america-word-gap-prediction|Challenging America word-gap prediction](https://gonito.net/challenge/challenging-america-word-gap-prediction|Challenging America word-gap prediction) to wyzwanie modelowania amerykańskiej odmiany języka angielskiego, używanej w gazetach w XIX w. i I poł. XX w.
$ git clone git://gonito.net/challenging-america-word-gap-prediction
$ cd challenging-america-word-gap-prediction
$ xzcat train/in.tsv.xz | wc
432022 123677147 836787912
$ xzcat dev-0/in.tsv.xz | wc
10519 3076536 20650825
$ xzcat test-A/in.tsv.xz | wc
7414 2105734 14268877
Dodajmy, że poszczególne zbiory zawierają teksty z różnych gazet. Jest to właściwe podejście, jeśli chcemy mierzyć rzeczywistą skuteczność modeli języka. (Teksty z jednej gazety mogłyby być zbyt proste).
Oto przykład tekstu z wyzwania:
$ xzcat train/in.tsv.xz | head -n 1 | fold
4e04702da929c78c52baf09c1851d3ff ST ChronAm 1919.6041095573314
30.47547 -90.100911 came fiom the last place to this\nplace, and thi
s place is Where We\nWere, this is the first road I ever\nwas on where you can r
ide elsewhere\nfrom anywhere and be nowhere.\nHe says, while this train stops ev
ery-\nwhere, it never stops anywhere un-\nless its somewhere. Well, I says,\nI'm
glad to hear that, but, accord-\ning to your figures, I left myself\nwhere 1 wa
s, which is five miles near-\ner to myself than I was when we\nwere where we are
now.\nWe have now reached Slidell.\nThat's a fine place. The people\ndown there
remind me of bananas-\nthey come and go in bunches. 811-\ndell used to be noted
for her tough\npeople. Now she is noted for be,\ntough steaks. Well, I certainl
y got\none there. When the waiter brought\nit in it was so small I thought. It\n
was a crack in the plate. I skid,\nwaiter what else have you got? +He\nbrought m
e in two codfish and one\nsmelt. I said, waiter have you got\npigs feet? He said
no, rheumatism\nmakes me walk that way. I sald,\nhow is the pumpkin pie?
said\nit's all squash. The best I could get\nin that hotel was a soup sandwich.\
nAfter the table battle the waiter and\nI signed an armistice. I then went\nover
to the hotel clerk and asked for\na room. He said with or without a\nbed? I sai
d, with a bed. He said,\nI don't think I 'have' a bed long\nenough for you. I sa
id, well, I'll\naddtwo feettoitwhenIgetinit.\nHe gave me a lovely room on the\nt
op floor. It was one of those rooms\nthat stands on each side. If you\nhappen to
get up in the middle of\nthe night you want to be sure and\nget up in the middl
e of the room.\nThat night I dreamt I was eating\nflannel cakes. When I woke up
half\nof the blanket was gone. I must\nhave got up on the wrong side of the\nbed
, for next morning I had an awful\nheadache. I told the manager about\nit. He sa
id, you have rheumatic\npains. I said, no, I think it is on,\nof those attic roo
m pains. I nad to\ngetupat5a.m.inthemorningso\nthey could use the sheet to set t
he\nbreakfast table.
Zauważmy, że mamy nie tylko tekst, lecz również metadane (czas i współrzędne geograficzne). W modelowaniu języka można uwzględnić również takie dodatkowe parametry (np. prawdopodobieństwa wystąpienia słowa _koronawirus wzrasta po roku 2019).
Zauważmy również, że tekst zawiera błędy OCR-owe (np. _nad zamiast _had). Czy w takim razie jest to sensowne wyzwanie modelowania języka? Tak, w niektórych przypadkach możemy chcieć modelować tekst z uwzględnieniem „zaszumień” wprowadzanych przez ludzi bądź komputery (czy II prawo termodynamiki!).
Co podlega ocenie?
Ogólnie ocenie powinno podlegać prawdopodobieństwo $P_M(C')$, czyli prawdopodobieństwo przypisane zbiorowi testowemu $C'$ przez model (wyuczony na zbiorze $C$).
Jeśli oceniamy przewidywania, które człowiek lub komputer czynią, to im większe prawdopodobieństwo przypisane do tego, co miało miejsce, tym lepiej. Zatem im wyższe $P_M(C')$, tym lepiej.
Zazwyczaj będziemy rozbijali $P_M(C')$ na prawdopodobieństwa przypisane do poszczególnych słów:
$$P_M(w_1'\dots w_{N'}') = P_M(w'_1)P_M(w'_2|w'1)\dots P_M(w'{N'}|w'1\dots w'{N'-1}) = \prod{i=1}^{N'} P_M(w'_i|w'1\ldots w'{i-1}).$$
Entropia krzyżowa
Można powiedzieć, że dobry model języka „wnosi” informację o języku. Jeśli zarówno nadawca i odbiorca tekstu mają do dyspozycji ten sam model języka…
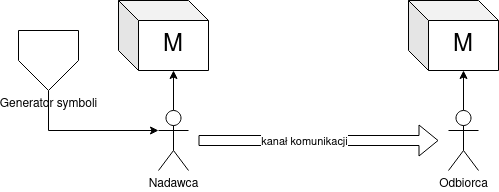
… powinni być w stanie zaoszczędzić na długości komunikatu.
W skrajnym przypadku, jeśli model jest pewny kolejnego słowa, tj. $P_M(w'_i|w'_1\ldots w'{i-1}) = 1$, wówczas w $i$-tym kroku w ogóle nic nie trzeba przesyłać przez kanał komunikacji. Taka sytuacja może realnie wystąpić, na przykład: z prawdopodobieństwem zbliżonym do 1 po wyrazie _Hong wystąpi słowo Kong, a po wyrazie przede — wyraz wszystkim.
Model języka może pomóc również w mniej skrajnym przypadkach, np. jeżeli na danej pozycji w tekście model redukuje cały słownik do dwóch wyrazów z prawdopodobieństwem 1/2, wówczas nadawca może zakodować tę pozycję za pomocą jednego bitu.
Wzór na entropię krzyżową
Przypomnijmy, że symbol o prawdopodobieństwie $p$ można zakodować za pomocą (średnio) $-\log_2(p)$ bitów, tak więc jeśli nadawca i odbiorca dysponują modelem $M$, wówczas można przesłać cały zbiór testowy $C$ za pomocą następującej liczby bitów:
$$-\sum_{i=1}^{N'} log P_M(w'_i|w'_1\ldots w'{i-1}).$$
Aby móc porównywać wyniki dla korpusów dla różnej długości, warto znormalizować tę wartość, tzn. podzielić przez długość tekstu:
$$H(M) = -\frac{\sum_{i=1}^{N'} log P_M(w'_i|w'_1\ldots w'{i-1})}{N'}.$$
Tę wartość nazywamy entropią krzyżową modelu $M$. Entropia krzyżowa mierzy naszą niewiedzę przy założeniu, że dysponujemy modelem $M$. Im niższa wartość entropii krzyżowej, tym lepiej, im bowiem mniejsza nasza niewiedza, tym lepiej.
Entropią krzyżową jest często nazywaną funkcją log loss, zwłaszcza w kontekście jej użycia jako funkcji straty przy uczeniu neuronowych modeli języka (o których dowiemy się później).
Wiarygodność
Innym sposobem mierzenia jakości modelu języka jest odwołanie się do wiarygodności (ang. _likelihood). Wiarygodność to prawdopodobieństwo przypisane zdarzeniom niejako „po fakcie”. Jak już wspomnieliśmy, im wyższe prawdopodobieństwo (wiarygodność) przypisane testowej części korpusu, tym lepiej. Innymi słowy, jako metrykę ewaluacji używać będziemy prawdopodobieństwa:
$$P_M(w_1'\dots w_{N'}') = P_M(w'_1)P_M(w'_2|w'1)\dots P_M(w'{N'}|w'1\dots w'{N'-1}) = \prod{i=1}^{N'} P_M(w'_i|w'1\ldots w'{i-1}),$$
z tym, że znowu warto znormalizować to prawdopodobieństwo względem rozmiaru korpusu. Ze względu na to, że prawdopodobieństwa przemnażamy, zamiast średniej arytmetycznej lepiej użyć średniej geometrycznej:
$$\sqrt[N']{P_M(w_1'\dots w_{N'}')} = \sqrt[N']{\prod_{i=1}^{N'} P_M(w'_i|w'_1\ldots w'{i-1})}.$$
Interpretacja wiarygodności
Co ciekawe, wiarygodność jest używana jako metryka ewaluacji modeli języka rzadziej niż entropia krzyżowa (log loss), mimo tego, że wydaje się nieco łatwiejsza do interpretacji dla człowieka. Otóż wiarygodność to średnia geometryczna prawdopodobieństw przypisanych przez model języka do słów, które rzeczywiście wystąpiły.
Związek między wiarygodnością a entropią krzyżową
Istnieje bardzo prosty związek między entropią krzyżową a wiarygodnością. Otóż entropia krzyżowa to po prostu logarytm wiarygodności (z minusem):
-$$\log_2\sqrt[N']{P_M(w_1'\dots w_N')} = -\frac{\log_2\prod_{i=1}^{N'} P_M(w'_i|w'1\ldots w'{i-1})}{N'} = -\frac{\sum{i=1}^{N'} \log_2 P_M(w'_i|w'1\ldots w'{i-1})}{N'}.$$
„log-proby”
W modelowaniu języka bardzo często używa się logarytmów prawdopodobieństw (z angielskiego skrótowo _log probs), zamiast wprost operować na prawdopodobieństwach:
- dodawanie log probów jest tańsze obliczeniowo niż mnożenie prawdopodobieństw,
- bardzo małe prawdopodobieństwa znajdują się na granicy dokładności reprezentacji liczb zmiennopozycyjnych, log proby są liczbami ujemnymi o „poręczniejszych” rzędach wielkości.
Perplexity
Tak naprawdę w literaturze przedmiotu na ogół używa się jeszcze innej metryki ewaluacji — perplexity. Perplexity jest definiowane jako:
$$\operatorname{PP}(M) = 2^{H(M)}.$$
Intuicyjnie można sobie wyobrazić, że perplexity to liczba możliwości prognozowanych przez model z równym prawdopodobieństwem. Na przykład, jeśli model przewiduje, że w danym miejscu tekstu może wystąpić z równym prawdopodobieństwem jedno z 32 słów, wówczas (jeśli rzeczywiście któreś z tych słów wystąpiło) entropia wynosi 5 bitów, a perplexity — 32.
Inaczej: perplexity to po prostu odwrotność wiarygodności:
$$\operatorname{PP}(M) = \sqrt[N']{P_M(w_1'\dots w_N')}.$$
Perplexity zależy oczywiście od języka i modelu, ale typowe wartości zazwyczaj zawierają się w przedziale 20-400.
Perplexity — przykład
Wyuczmy model języka przy użyciu gotowego narzędzia https://github.com/kpu/kenlm|KenLM. KenLM to zaawansowane narzędzie do tworzenia n-gramowych modeli języka (zaimplementowano w nim techniki wygładzania, które omówimy na kolejnym wykładzie).
Wyuczmy na zbiorze uczącym wspomnianego wyzwania _Challenging America word-gap prediction dwa modele, jeden 3-gramowy, drugi 4-gramowy.
Z powodu, który za chwilę stanie się jasny, teksty w zbiorze uczącym musimy sobie „poskładać” z kilku „kawałków”.
$ cd train
$ xzcat in.tsv.xz | paste expected.tsv - | perl -ne 'chomp;s/\\\\n/ /g;s/<s>/ /g;@f=split/\t/;print "$f[7] $f[0] $f[8]\n"' | lmplz -o 3 --skip-symbols > model3.arpa
$ xzcat in.tsv.xz | paste expected.tsv - | perl -ne 'chomp;s/\\\\n/ /g;s/<s>/ /g;@f=split/\t/;print "$f[7] $f[0] $f[8]\n"' | lmplz -o 4 --skip-symbols > model4.arpa
$ cd ../dev-0
$ xzcat in.tsv.xz | paste expected.tsv - | perl -ne 'chomp;s/\\\\n/ /g;s/<s>/ /g;@f=split/\t/;print "$f[7] $f[0] $f[8]\n"' | query ../train/model3.arpa
Perplexity including OOVs: 976.9905056314793
Perplexity excluding OOVs: 616.5864921901557
OOVs: 125276
Tokens: 3452929
$ xzcat in.tsv.xz | paste expected.tsv - | perl -ne 'chomp;s/\\\\n/ /g;s/<s>/ /g;@f=split/\t/;print "$f[7] $f[0] $f[8]\n"' | query ../train/model4.arpa
Perplexity including OOVs: 888.698932611321
Perplexity excluding OOVs: 559.1231510292068
OOVs: 125276
Tokens: 3452929
Jak widać model 4-gramowy jest lepszy (ma niższe perplexity) niż model 3-gramowy, przynajmniej jeśli wierzyć raportowi programu KenLM.
Entropia krzyżowa, wiarygodność i perplexity — podsumowanie
Trzy omawiane metryki ewaluacji modeli języka (entropia krzyżowa, wiarygodność i perplexity) są ze sobą ściśle związane, w gruncie rzeczy to po prostu jedna miara.
| Metryka | Kierunek | Najlepsza wartość | Najgorsza wartość |
|---|---|---|---|
| entropia krzyżowa | im mniej, tym lepiej | 0 | $\infty$ |
| wiarygodność | im więcej, tym lepiej | 1 | 0 |
| perplexity | im mniej, tym lepiej | 1 | $\infty$ |
Uwaga na zerowe prawdopodobieństwa
Entropia krzyżowa, wiarygodność czy perplexity są bardzo czułe na zbyt dużą pewność siebie. Wystarczy, że dla jednej pozycji w zbiorze przypiszemy zerowe prawdopodobieństwo, wówczas wszystko „eksploduje”. Perplexity i entropia krzyżowa „wybuchają” do nieskończoności, wiarygodność spada do zera — bez względu na to, jak dobre są przewidywania dotyczące innych pozycji w tekście!
W przypadku wiarygodności wiąże się to z tym, że wiarygodność definiujemy jako iloczyn prawdopodobieństwa, oczywiście wystarczy, że jedna liczba w iloczynie była zerem, żeby iloczyn przyjął wartość zero. Co więcej, nawet jeśli pominiemy taki skrajny przypadek, to średnia geometryczna „ciągnie” w dół, bardzo niska wartość prawdopodobieństwa przypisana do rzeczywistego słowa może drastycznie obniżyć wartość wiarygodności (i podwyższyć perplexity).
Słowa spoza słownika
Prostym sposobem przeciwdziałania zerowaniu/wybuchaniu metryk jest przypisywanie każdemu możliwemu słowu przynajmniej niskiego prawdopodobieństwa $\epsilon$. Niestety, zawsze może pojawić się słowa, którego nie było w zbiorze uczącym — słowo spoza słownika (_out-of-vocabulary word, OOV). W takim przypadku znowu może pojawić się zerowy/nieskończony wynik.
Ewaluacja modeli języka w warunkach konkursu
Jeśli używać tradycyjnych metryk ewaluacji modeli języka (perplexity czy wiarygodność), bardzo łatwo można „oszukać” — wystarczy zaraportować prawdopodobieństwo 1! Oczywiście to absurd, bo albo wszystkim innym tekstom przypisujemy prawdopodobieństwo 0, albo — jeśli „oszukańczy” system każdemu innemu tekstowi przypisze prawdopodobieństwo 1 — nie mamy do czynienia z poprawnym rozkładem prawdopodobieństwa.
Co gorsza, nawet jeśli wykluczymy scenariusz świadomego oszustwa, łatwo _samego siebie wprowadzić w błąd. Na przykład przez pomyłkę można zwracać zawyżone prawdopodobieństwo (powiedzmy przemnożone przez 2).
Te problemy stają się szczególnie dokuczliwe, jeśli organizujemy wyzwanie, _konkurs modelowania języka, gdzie chcemy w sposób obiektywny porównywać różne modele języka, tak aby uniknąć celowego bądź nieświadomego zawyżania wyników.
Przedstawimy teraz, w jaki sposób poradzono sobie z tym problemem w wyzwaniu _Challenging America word-gap prediction
Odgadywanie słowa w luce
Po pierwsze, jaka sama nazwa wskazuje, w wyzwaniu _Challenging America word-gap prediction
Mianowicie, w każdym wierszu wejściu (plik in.tsv.xz) w 7. i 8. polu
podany jest, odpowiednio, lewy i prawy kontekst słowa do odgadnięcia.
(W pozostałych polach znajdują się metadane, o których już wspomnieliśmy,
na razie nie będziemy ich wykorzystywać).
W pliku z oczekiwanym wyjściem (expected.tsv), w odpowiadającym
wierszu, podawane jest brakujące słowo. Oczywiście w ostatecznym
teście test-A plik expected.tsv jest niedostępny, ukryty przed uczestnikami konkursu.
Zapis rozkładu prawdopodobieństwa
Dla każdego wiersza wejścia podajemy rozkład prawdopodobieństwa dla słowa w luce w formacie:
wyraz1:prob1 wyraz2:prob2 ... wyrazN:probN :prob0
gdzie wyraz1, …, wyrazN to konkretne wyrazy, prob1, …, probN ich prawdopodobieństwa. Można podać dowolną liczbę wyrazów. Z kolei prob0 to „resztowe” prawdopodobieństwo przypisane do wszystkich pozostałych wyrazów, prawdopodobieństwo to pozwala uniknąć problemów związanych ze słowami OOV, trzeba jeszcze tylko dokonać modyfikacji metryki
Metryka LikelihoodHashed
Metryka LikelihoodHashed jest wariantem metryki Likelihood (wiarygodności) opracowanym z myślą o wyzwaniach czy konkursach modelowania języka. W tej metryce każde słowo wpada pseudolosowo do jednego z $2^{10}=1024$ „kubełków”. Numer kubełka jest wyznaczony na podstawie funkcji haszującej MurmurHash.
Prawdopodobieństwa zwrócone przez ewaluowany model są sumowane w każdym kubełku, następnie ewaluator zagląda do pliku `expected.tsv` i uwzględnia prawdopodobieństwo z kubełka, do którego „wpada” oczekiwane słowo. Oczywiście czasami więcej niż jedno słowo może wpaść do kubełka, model mógł też „wrzucić” do kubełka tak naprawdę inne słowo niż oczekiwane (przypadkiem oba słowa wpadają do jednego kubełka). Tak więc LikelihoodHashed będzie nieco zawyżone w stosunku do Likelihood.
Dlaczego więc taka komplikacja? Otóż LikelihoodHashed nie zakłada żadnego słownika, znika problem słów OOV — prawdopodobieństwa resztowe prob0 są rozkładane równomiernie między wszystkie 1024 kubełki.
Alternatywne metryki
LikelihoodHashed została zaimplementowana w narzędziu ewaluacyjnym https://gitlab.com/filipg/geval|GEval. Są tam również dostępne analogiczne warianty entropii krzyżowej (log loss) i perplexity (LogLossHashed i PerplexityHashed).