46 KiB
Regresja jądrowa
Karolina Oparczyk, Tomasz Grzybowski, Jan Nowak
Regresja jądrowa używana jest jako funkcja wagi do opracowania modelu regresji nieparametrycznej. Nadaje ona niektórym elementom zbioru większą "wagę", która ma wpływ na ostateczny wynik.
Można ją porównać do rysowania krzywej na wykresie punktowym tak, aby była jak najlepiej do nich dopasowana.
Właściwości regresji jądrowej:
- symetryczna - wartość maksymalna leży pośrodku krzywej

- powierzchnia pod krzywą funkcji wynosi 1
- wartość funkcji jądrowej nie jest ujemna
Do implementacji regresji jądrowej można użyć wielu różnych jąder. Przykłady użyte w projekcie:
- jądro Gaussa
\begin{equation}
K(x) = \frac1{h\sqrt{2\pi}}e^{-\frac12(\frac{x - x_i}h)^2}
\end{equation}
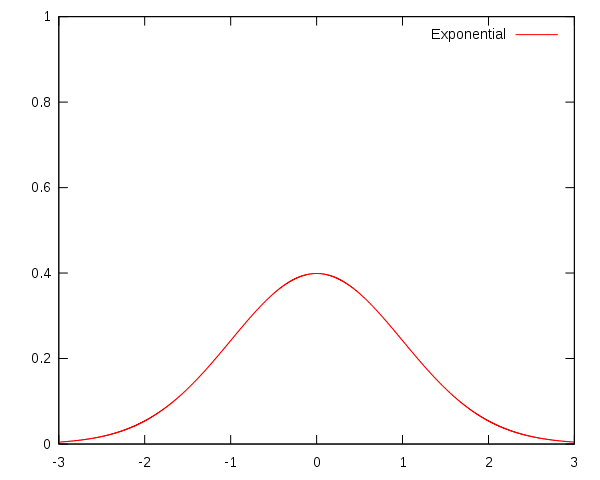
- jądro Epanechnikova
\begin{equation}
K(x) = (\frac34)(1-(\frac{x - x_i}h)^2) \text{ dla } {|x|\leq1}
\end{equation}
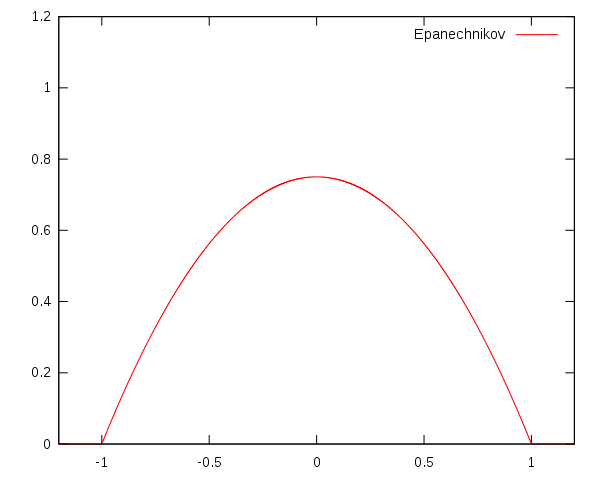
Istotne znaczenie ma nie tylko dobór jądra, ale również parametru wygładzania, czyli szerokości okna. W zależności od niego, punkty są grupowane i dla każdej grupy wyliczana jest wartość funkcji. Jeśli okno będzie zbyt szerokie, funkcja będzie bardziej przypominała prostą (under-fitting). Natomiast jeśli będzie zbyt wąskie, funkcja będzie za bardzo "skakać" (over-fitting).
Wyliczenie wartości funkcji polega na wzięciu średniej ważonej z $y_{i}$ dla takich $x_{i}$, które znajdują się blisko x, dla którego wyznaczamy wartość. Wagi przy $y_{i}$ dla x sumują się do 1 i są wyższe, kiedy $x_{i}$ jest bliżej x oraz niższe w przeciwnym przypadku.
import ipywidgets as widgets
import numpy as np
import plotly.express as px
import plotly.graph_objs as go
import pandas as pd
import KernelRegression
fires_thefts = pd.read_csv('fires_thefts.csv', names=['x','y'])
XXX = np.sort(np.array(fires_thefts.x))
YYY = np.array(fires_thefts.y)
dropdown_bw = widgets.Dropdown(options=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], value=1, description='Szerokość okna')
def interactive_kernel(bw_manual):
fig = px.scatter(x=XXX,y=YYY)
for i in range(0, len(XXX), bw_manual):
fig.add_vline(x=i)
fig.show()
Y_pred_gauss = KernelRegression.ker_reg(XXX, YYY, bw_manual, 'gauss')
Y_pred_epanechnikov = KernelRegression.ker_reg(XXX, YYY, bw_manual, 'epanechnikov')
fig = px.scatter(x=XXX,y=YYY)
fig.add_trace(go.Scatter(x=XXX, y=np.array(Y_pred_gauss), name='Gauss', mode='lines'))
fig.add_trace(go.Scatter(x=XXX, y=np.array(Y_pred_epanechnikov), name='Epanechnikov', mode='lines'))
fig.show()widgets.interact(interactive_kernel, bw_manual=dropdown_bw)interactive(children=(Dropdown(description='Szerokość okna', options=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), value=1)…
<function __main__.interactive_kernel(bw_manual)>
from sklearn.linear_model import LinearRegression
# linear regression
reg = LinearRegression().fit(XXX.reshape(-1, 1), YYY.reshape(-1, 1))
Y_pred_linear = reg.predict(XXX.reshape(-1, 1))
# kernel regression
Y_pred_gauss = KernelRegression.ker_reg(XXX, YYY, bw_manual, 'gauss')
Y_pred_epanechnikov = KernelRegression.ker_reg(XXX, YYY, bw_manual, 'epanechnikov')
fig = px.scatter(x=XXX,y=YYY)
fig.add_trace(go.Scatter(x=XXX, y=np.array(Y_pred_gauss), name='Gauss', mode='lines'))
fig.add_trace(go.Scatter(x=XXX, y=np.array(Y_pred_epanechnikov), name='Epanechnikov', mode='lines'))
fig.add_trace(go.Scatter(x=XXX, y=np.array(Y_pred_linear.flatten().tolist()), name='Linear', mode='lines'))