5.5 KiB
5.5 KiB
Sztuczna Inteligencja
Temat projektu: Inteligenta Śmieciarka
Zespół: Kacper Borkowski, Adam Borowski, Adam Osiowy
Podprojekt: Adam Borowski
1. Temat podprojektu:
Celem projektu było utworzenie klasyfikatora rodzajów danych wejściowych(śmieci) na podstawie zdjęć. Do tego celu wykorzystano bibliotekę PyTorch. Cały podprojekt opiera się na utworzeniu sieci neuronowej i przetworzeniu inputu przez kolejne jej warstwy.
2. Model sieci:
class Net(nn.Module): # klasa Net dziedziczaca po klasie bazowej nn.Module
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 71 * 71, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 4)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(x.size(0), 16 * 71 * 71)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
- conv1, conv2 – warstwy konwolucyjna, rozmiar filtra 5×5, posiadające 3 kanały wejściowe (RGB) i kanały wyjściowe dla następnych warstw
- pool - operacja
max-poolingu- wyciaganie najwazniejszej informacji z zadanego obszaru obrazu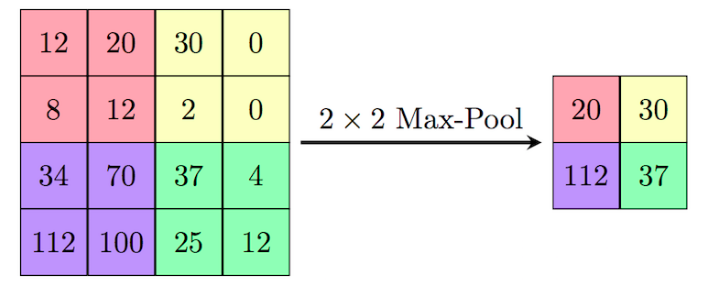
- fc1, fc2, fc3 - warstwy liniowe -
full connection layers- w odróznieniu od warstw konwolucyjnych, każdy neuron dostaje input o neuronie z poprzedniej warstwy. W warstwie konwolucyjnej neurony wiedzą tylko o określonych neuronach z poprzedniego layera
- metoda
forward- metoda forward określa cały przepływ(flow) inputu przez warstwy aż do outputu. W pierwszej części tensor danej wejściowej(tensor zdjęcia) przepuszczany jest przez dwie warstwy konwolucyjne i wykonywana jest na nim wcześniej wspomniana operacjamax-poolingu. W następnej części wypłaszczamy x, wszystkie wymiary przechowujace dane obrazu – 16 kanalow o rozmiarach 71×71 rozciągamy jako jeden długi wektor. Na koniec przepuszczamy tensor przez warstwy liniowe i zwracamy output.
3. Trening:
def train():
net = Net()
trainset = torchvision.datasets.ImageFolder(
root='./resources/zbior_uczacy', transform=transform)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=1, shuffle=True, num_workers=2)
classes = ('glass', 'metal', 'paper', 'plastic')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss))
running_loss = 0.0
print('Finished Training')
PATH = './wytrenowaned.pth'
torch.save(net.state_dict(), PATH)
- na początku zainicjowano sieć, pobrano zbiór uczący i znormalizowano jego wnętrze, aby każde zdjęcie było pod postacią Tensora(tego wymaga model sieci)
- następnie zdefiniowano kryterium do wyznaczania jakości klasyfikacji zdjęć do klas i wyznaczono optymalizator
- potem wchodzimy do pętli i iterujemy po data secie, pobieramy inputy, czyścimy gradienty z poprzedniej iteracji, za pomocą algorytmu propagacji wstecznej liczymy pochodne z utraconej wartości, wyswietlamy w konsoli loss z danej iteracji,
- następnie zapisujemy wytrenowany model
4. Przewidywanie:
def predict(img_path):
net = Net()
PATH = './wytrenowaned.pth'
img = Image.open(img_path)
pil_to_tensor = transforms.ToTensor()(img).unsqueeze_(0)
classes = ('glass', 'metal', 'paper', 'plastic')
net.load_state_dict(torch.load(PATH))
net.eval()
outputs = net(pil_to_tensor)
return classes[torch.max(outputs, 1)[1]]
- zainicjowano sieć, wczytano ścieżke, przetransformowano argument funkcji(zdjecie) do porządanego formatu
- następnie przekazano tensor jako argument do instancji klasy sieci
- w ostatnim kroku za pomocą funkcji
maxwyciągnięto największą wagę i na jej podstawie rozpoznano klasę
5. Integracja w projekcie:
for dom in obiekty["domy"]:
if dom.x == pozX and dom.y == pozY:
while dom.smieci:
smiec = dom.smieci.pop(0)
rodzaj = ""
if osoba == 'kacper':
rodzaj = kacper.przewidz(smiec)
elif osoba == 'adamB':
rodzaj = adamB.predict(smiec)
else:
rodzaj = adamO.przewidz(smiec, rfc)
if rodzaj == "paper":
obiekty["smieciarka"].dodajPapier(smiec)
elif rodzaj == "glass":
obiekty["smieciarka"].dodajSzklo(smiec)
elif rodzaj == "metal":
obiekty["smieciarka"].dodajMetal(smiec)
elif rodzaj == "plastic":
obiekty["smieciarka"].dodajPlastik(smiec)
- zgodnie z wybraną osobą na starcie wykonywana jest odpowiednia funkcja przewidywania na śmieciach w poszczególnych domach
- finalnie zdjęcia posortowanych śmieci znajdują się w kontenerach(folder
smieci w kontenerach)